

В этом руководстве вы узнаете:
- Что такое нулевая классификация и как она работает
- Плюсы и минусы использования
- Актуальность этой практики в веб-скреппинге
- Пошаговое руководство по реализации классификации по нулевым снимкам в сценарии веб-скрапинга
Давайте погрузимся!
Что такое классификация нулевого выстрела?
Классификация по нулевому выстрелу (Zero-shot classification, ZSC) – это способность предсказывать класс, который модель машинного обучения никогда не видела на этапе обучения. Класс – это определенная категория или метка, которую модель присваивает фрагменту данных. Например, она может присвоить класс “спам” тексту электронного письма или “кошка” изображению.
ZSC можно классифицировать как пример трансферного обучения. Трансферное обучение – это метод машинного обучения, при котором знания, полученные при решении одной проблемы, применяются для решения другой, но смежной проблемы.
Основная идея ZSC уже давно изучена и реализована в нескольких типах нейронных сетей и моделях машинного обучения. Она может быть применена к различным модальностям, включая:
- Текст: Представьте, что у вас есть модель, обученная понимать язык в целом, но вы никогда не показывали ей пример “обзора продукта для экологичной упаковки”. С помощью ZSC вы можете попросить ее определить такие обзоры из кучи текста. Для этого модель понимает значение нужных вам категорий (меток) и сопоставляет их с входным текстом, а не полагается на заранее заученные примеры для каждой конкретной метки.
- Изображения: Модель, обученная на наборе изображений животных (например, кошек, собак, лошадей), может классифицировать изображение зебры как “животное” или даже “полосатое животное, похожее на лошадь”, ни разу не увидев зебру во время обучения.
- Аудио: Модель может быть обучена распознавать такие распространенные городские звуки, как “автомобильный гудок”, “сирена” и “собачий лай”. Благодаря ZSC модель может распознать звук, которому она никогда не обучалась, например “отбойный молоток”, понимая его акустические свойства и соотнося их с известными звуками.
- Мультимодальные данные: ZSC может работать с различными типами данных, например, классифицировать изображение на основе текстового описания класса, который он никогда не видел, или наоборот.
Как работает ZSC?
Классификация с нулевого выстрела становится все более интересной благодаря популярности предварительно обученных LLM. Эти модели обучаются на огромных объемах данных, ориентированных на ИИ, что позволяет им глубоко понимать язык, семантику и контекст.
Для ZSC предварительно обученные модели часто настраиваются на задаче, называемой NLI(Natural Language Inference). NLI предполагает определение взаимосвязи между двумя фрагментами текста: “посылкой” и “гипотезой”. Модель решает, является ли гипотеза следствием (истинной, учитывая посылку), противоречием (ложной, учитывая посылку) или нейтральной (не связанной).
При классификации с нулевым результатом входной текст выступает в качестве предпосылки. Метки категорий-кандидатов рассматриваются как гипотезы. Модель вычисляет, какая “гипотеза” (метка) с наибольшей вероятностью соответствует “предпосылке” (входному тексту). В качестве классификации выбирается метка с наибольшей оценкой энтитета.
Преимущества и ограничения использования классификации по нулевому выстрелу
Пора изучить преимущества и недостатки ZSC.
Преимущества
ZSC обладает рядом эксплуатационных преимуществ, в том числе:
- Адаптация к новым классам: ZSC открывает возможности для классификации данных по невиданным категориям. Это достигается путем определения новых меток без необходимости переобучения модели или сбора специальных обучающих примеров для новых классов.
- Снижение потребности в меченых данных: Метод снижает зависимость от обширных наборов помеченных данных для целевых классов. Это уменьшает потребность в маркировке данных –распространенное “узкое место” в сроках и стоимости проектов машинного обучения.
- Эффективная реализация классификаторов: Новые схемы классификации можно быстро настраивать и оценивать. Это позволяет ускорить циклы итераций в ответ на меняющиеся требования.
Ограничения
Несмотря на свою мощь, классификация по нулевым снимкам имеет ряд ограничений, таких как:
- Вариативность производительности: Модели на основе ZSC могут демонстрировать более низкую точность по сравнению с супервизорными моделями, прошедшими длительное обучение на фиксированных наборах классов. Это происходит потому, что ZSC опирается на семантический вывод, а не на прямое обучение на примерах целевых классов.
- Зависимость от качества модели: Эффективность ZSC зависит от качества и возможностей базовой предварительно обученной языковой модели. Мощная базовая модель обычно приводит к лучшим результатам ZSC.
- Неоднозначность меток и формулировок: Четкость и различимость ярлыков кандидатов влияет на точность. Неоднозначные или плохо сформулированные метки могут привести к неоптимальной производительности.
Актуальность классификации нулевых снимков в веб-скрапинге
Постоянное появление в Сети новой информации, продуктов и тем требует адаптируемых методов обработки данных. Все начинается с веб-скреппинга –автоматизированного процесса извлечения данных с веб-страниц.
Традиционные методы машинного обучения требуют ручной категоризации или частого переобучения для обработки новых классов в отсканированных данных, что неэффективно в масштабе. Вместо этого классификация с нулевого снимка решает проблемы, связанные с динамическим характером веб-контента, позволяя:
- Динамическая категоризация разнородных данных: Данные, полученные из различных источников, могут быть классифицированы в режиме реального времени с использованием определенного пользователем набора меток, соответствующих текущим аналитическим задачам.
- Адаптация к изменяющимся информационным ландшафтам: Новые категории или темы могут быть включены в схему классификации немедленно, без необходимости длительных циклов перестройки модели.
Таким образом, типичными случаями использования ZSC в веб-скреппинге являются:
- Динамическая категоризация контента: При соскабливании контента, например новостных статей или списков товаров с нескольких доменов, ZSC может автоматически распределять элементы по заранее определенным или новым категориям.
- Анализ настроения для новых предметов: Для анализа отзывов покупателей о новых продуктах или данных социальных сетей, связанных с новыми брендами, ZSC может проводить анализ настроений, не требуя обучающих данных по настроениям, характерным для данного продукта или бренда. Это позволяет своевременно отслеживать восприятие бренда и оценивать отзывы покупателей.
- Выявление новых тенденций и тем: Определив метки-гипотезы, представляющие потенциальные новые тенденции, ZSC можно использовать для анализа текстов, взятых с форумов, блогов или социальных сетей, чтобы выявить растущую распространенность этих тем.
Практическая реализация классификации по нулевому выстрелу
В этом учебном разделе вы узнаете, как применить классификацию по нулевой точке к данным, полученным из Сети. Целевым сайтом будет “Хоккейные команды: Формы, поиск и пагинация“:

Сначала веб-скрепер извлечет данные из приведенной выше таблицы. Затем LLM классифицирует их с помощью ZSC. В этом уроке вы будете использовать DistilBart-MNLI из Hugging Face: легкий LLM семейства BART.
Выполните следующие шаги и узнайте, как достичь желаемой цели ZSC!
Необходимые условия и зависимости
Чтобы повторить этот урок, на вашей машине должен быть установлен Python 3.10.1 или выше.
Предположим, вы назвали главную папку своего проекта zsc_project/. По окончании этого шага папка будет иметь следующую структуру:
zsc_project/
├── zsc_scraper.py
└── venv/Где:
zsc_scraper.py– это файл на языке Python, содержащий логику кодирования.venv/содержит виртуальную среду.
Вы можете создать каталог виртуальной среды venv/ следующим образом:
python -m venv venvЧтобы активировать его, в Windows выполните команду:
venvScriptsactivateАналогично, в macOS и Linux выполните команду:
source venv/bin/activateВ активированной виртуальной среде установите зависимости с помощью:
pip install requests beautifulsoup4 transformers torchЭтими зависимостями являются:
requests: Библиотека для выполнения веб-запросов HTTP.beautifulssoup4: Библиотека для разбора HTML- и XML-документов и извлечения из них данных. Узнайте больше в нашем руководстве по веб-скраппингу BeautifulSoup.трансформаторы: Библиотека от Hugging Face, которая предоставляет тысячи предварительно обученных моделей.torch: PyTorch, фреймворк машинного обучения с открытым исходным кодом.
Замечательно! Теперь у вас есть все необходимое для извлечения данных с целевого сайта и выполнения ZSC.
Шаг №1: Первоначальная установка и настройка
Инициализируйте файл zsc_scraper.py, импортировав необходимые библиотеки и задав некоторые переменные:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process Приведенный выше код выполняет следующие действия:
- Определяет целевой веб-сайт для соскоба с помощью
BASE_URL. CANDIDATES_LABELSхранит список строк, определяющих категории, которые модель классификации нулевого выстрела будет использовать для классификации отсканированных данных. Модель попытается определить, какая из этих меток лучше всего описывает каждый фрагмент данных команды.- Определяет максимальное количество страниц для сканирования и максимальное количество данных команд для получения.
Отлично! У вас есть все, что нужно, чтобы начать работу с классификацией с нулевым результатом в Python.
Шаг № 2: Получение URL-адресов страниц
Начните с изучения элемента пагинации на целевой странице:
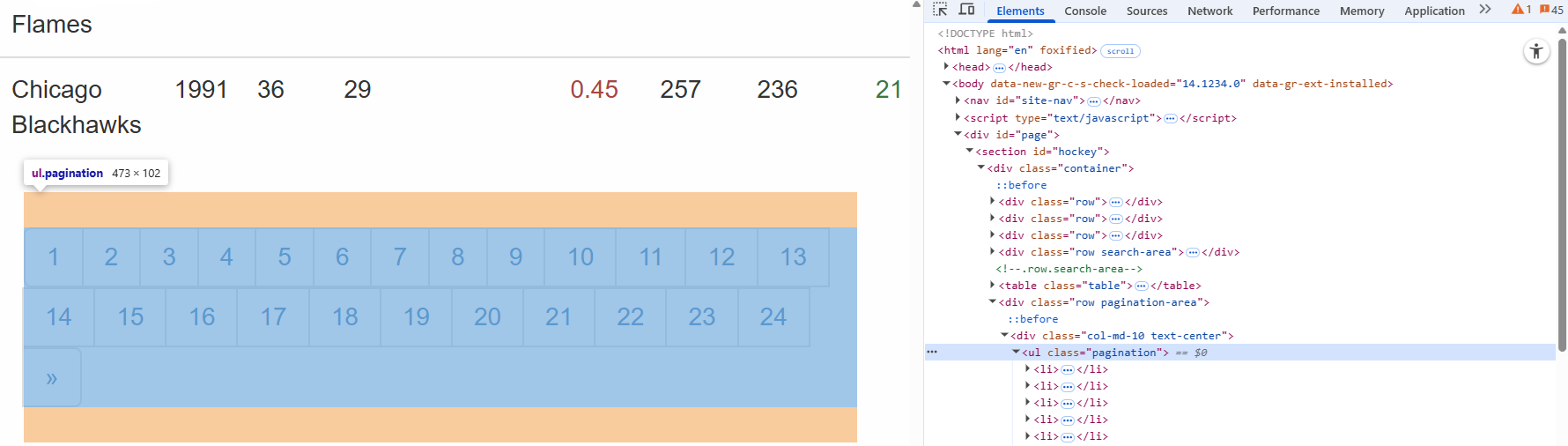
Здесь вы можете заметить, что URL-адреса пагинации содержатся в HTML-узле .pagination.
Определите функцию для поиска всех уникальных URL-адресов страниц из раздела пагинации сайта:
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urlsЭта функция:
- Отправляет HTTP-запрос на целевой сайт с методом
get(). - Управляет пагинацией с помощью метода
select()из BeautifulSoup. - Итерация по каждой странице, обеспечивая последовательный порядок, с помощью цикла
for. - Возвращает список всех уникальных полностраничных URL-адресов.
Круто! Вы создали функцию для получения URL-адресов веб-страниц, с которых нужно соскоблить данные.
Шаг № 3: соскоб данных
Начните с изучения элемента пагинации на целевой странице:

Здесь вы видите, что данные команд, которые нужно отсканировать, содержатся в HTML-узле .table.
Создайте функцию, которая принимает URL-адрес одной страницы, получает ее содержимое и извлекает статистику команды:
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_dataЭта функция:
- Извлекает данные из строк таблицы с помощью метода
select(). - Обрабатывает каждую строку команды с помощью цикла
for row in table_rows:. - Возвращает найденные данные в виде списка.
Отличная работа! Вы создали функцию для получения данных с целевого сайта.
Шаг № 4: Организуйте процесс
Скоординируйте весь рабочий процесс в следующих шагах:
- Загрузите модель классификации
- Получите URL-адреса страниц, которые необходимо исследовать
- Соскребайте данные с каждой страницы
- Классифицируйте отсканированный текст с помощью ZSC
Добейтесь этого с помощью следующего кода:
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")Этот код:
- Загружает предварительно обученную модель с помощью метода
pipeline()и задает ей задачу"zero-shot-classification". - Вызывает предыдущие функции и выполняет собственно ZSC.
Отлично! Вы создали функцию, которая организует все предыдущие шаги и выполняет фактическую классификацию нулевых снимков.
Шаг #5: Соберите все вместе и запустите код
Ниже показано, что теперь должен содержать файл zsc_scraper.py:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process per page
# Fetch page URLs
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urls
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_data
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")Очень хорошо! Вы завершили свой первый проект ZSC.
Запустите код с помощью следующей команды:
python zsc_scraper.pyЭто ожидаемый результат:

Как видите, модель правильно отнесла отсканированные данные к “Записи исторических спортивных данных”. Это было бы невозможно без нулевой классификации. Миссия выполнена!
Заключение
В этой статье вы узнали, что такое классификация по нулевым снимкам и как применить ее в контексте веб-скреппинга. Веб-данные постоянно меняются, и вы не можете ожидать, что предварительно обученный LLM будет знать все заранее. ZSC помогает преодолеть этот разрыв, динамически классифицируя новую информацию без переобучения.
Однако настоящая проблема заключается в получении свежих данных, посколькуне все веб-сайты легко поддаются сканированию. Именно здесь на помощь приходит компания Bright Data, предлагающая набор мощных инструментов и услуг, предназначенных для преодоления препятствий, возникающих при соскабливании данных. К ним относятся.
- Web Unlocker: API, позволяющий обойти защиту от скаппинга и получить чистый HTML с любой веб-страницы с минимальными усилиями.
- Браузер для скрапинга: Облачный, управляемый браузер с рендерингом JavaScript. Он автоматически обрабатывает CAPTCHA, отпечатки пальцев браузера, повторные попытки и многое другое за вас. Он легко интегрируется с Panther или Selenium PHP.
- API для веб-скреперов: Конечные точки для программного доступа к структурированным веб-данным с десятков популярных доменов.
Чтобы узнать о сценарии машинного обучения, также изучите наш центр искусственного интеллекта.
Зарегистрируйтесь на сайте Bright Data прямо сейчас и начните бесплатную пробную версию, чтобы протестировать наши решения для сбора информации!





