

В этом руководстве по анализу данных с помощью Python вы увидите:
- Зачем использовать Python для анализа данных
- Общие библиотеки для анализа данных с помощью Python
- Пошаговое руководство по анализу данных в Python
- Процесс, которому необходимо следовать при анализе данных
Давайте погрузимся!
Зачем использовать Python для анализа данных
Анализ данных обычно выполняется с помощью двух основных языков программирования:
- R: больше подходит для исследователей и статистиков.
- Питон: Лучшее для всех остальных профессионалов
В частности, ниже перечислены основные причины, по которым стоит использовать Python для анализа данных:
- Небольшая кривая обучения: Python имеет простой и понятный синтаксис, что делает его доступным как для новичков, так и для экспертов.
- Универсальность: Python может работать с различными типами и форматами данных, включая CSV, Excel, JSON, базы данных SQL, Parquet и другие. Кроме того, он подходит для решения самых разных задач – от простой очистки данных до сложных приложений машинного обучения и глубокого обучения.
- Масштабируемость: Python масштабируется и может справиться как с небольшими наборами данных, так и с масштабными задачами по обработке данных. Например, такие библиотеки, как Dask и PySpark, помогут вам справиться с большими данными без особых усилий.
- Поддержка сообщества: Python имеет большое и активное сообщество разработчиков и специалистов по обработке данных, которые вносят свой вклад в его экосистему.
- Интеграция машинного обучения и ИИ: Python является основным языком для машинного обучения и искусственного интеллекта, а такие библиотеки, как TensorFlow, PyTorch и Keras, поддерживают передовую аналитику и предиктивное моделирование.
- Воспроизводимость и совместная работа: Блокноты Jupyter помогают делиться фрагментами анализа данных и воспроизводить их, что очень важно для совместной работы в области науки о данных.
- Уникальное окружение для разных целей: Python предоставляет возможность использовать одну и ту же среду для разных целей. Например, вы можете использовать один и тот же блокнот Jupyter Notebook для сбора данных из Интернета и их последующего анализа. В этой же среде можно делать прогнозы с помощью моделей машинного обучения.
Общие библиотеки для анализа данных с помощью Python
Python широко используется в аналитике, в том числе благодаря широкой экосистеме библиотек. Вот наиболее распространенные библиотеки для анализа данных на Python:
- NumPy: Для численных вычислений и работы с многомерными массивами.
- Pandas: Для работы с данными и их анализа, особенно с табличными данными.
- Matplotlib и Seaborn: Для визуализации данных и создания наглядных графиков.
- SciPy: Для научных вычислений и расширенного статистического анализа.
- Plotly: Для создания анимированных графиков.
Посмотрите на них в действии в следующем разделе!
Анализ данных с помощью Python: A Complete Example
Теперь вы знаете, зачем использовать Python для анализа данных и какие библиотеки поддерживают эту задачу. Следуйте этому пошаговому руководству, чтобы узнать, как выполнять анализ данных с помощью Python.
В этом разделе вы проанализируете информацию о недвижимости Airbnb, полученную из бесплатного набора данных Bright Data.
Требования
Чтобы следовать этому руководству, на вашем компьютере должен быть установлен Python 3.6 или выше.
Шаг 1: Настройка среды и установка зависимостей
Предположим, вы назвали главную папку своего проекта data_analysis/. По завершении этого шага папка будет иметь следующую структуру:
data_analysis/
├── analysis.ipynb
└── venv/Где:
analysis.ipynb– это блокнот Jupyter, содержащий весь код анализа данных на языке Python.venv/содержит виртуальную среду Python.
Вы можете создать каталог виртуальной среды venv/ следующим образом:
python -m venv venvЧтобы активировать его в Windows, выполните команду:
venvScriptsactivateЭквивалентно, на macOS/Linux выполните команду:
source venv/bin/activateВ активированной виртуальной среде установите все необходимые библиотеки:
pip install pandas jupyter matplotlib seaborn numpyЧтобы создать файл analysis.ipynb, сначала нужно войти в папку data_analysis/:
cd data_analysisЗатем инициализируйте новый блокнот Jupyter Notebook с помощью этой команды:
jupyter notebookТеперь вы можете получить доступ к приложению Jupyter Notebook на сайте http://locahost:8888 в браузере.
Создайте новый файл, нажав на опцию “New > Python 3 (ipykernel)”:

По умолчанию новый файл будет называться untitled.ipynb. Вы можете переименовать его в приборной панели следующим образом:

Отлично! Теперь вы полностью готовы к анализу данных с помощью Python.
Шаг 2: Загрузите данные и откройте их
Набор данных, используемый в этом руководстве, взят с рынка наборов данных Bright Data. Чтобы загрузить его, бесплатно зарегистрируйтесь на платформе и перейдите на свою панель управления. Затем пройдите по пути “Web Datasets > Dataset”, чтобы попасть на рынок наборов данных:

Прокрутите страницу вниз и найдите карточку “Информация о недвижимости Airbnb”:

Чтобы загрузить набор данных, нажмите на опцию “Загрузить образец > Загрузить как CSV”:

Теперь вы можете переименовать загруженный файл, например, в airbnb.csv. Чтобы открыть CSV-файл в Jupyter Notebook, напишите в новой ячейке следующее:
import pandas as pd
# Open CSV
data = pd.read_csv("airbnb.csv")
# Show head
data.head()В этом фрагменте:
- Метод
read_csv()открывает CSV-файл как набор данных pandas. - Метод
head()показывает первые 5 строк набора данных.
Ниже приведен ожидаемый результат:

Как видите, в этом наборе данных 45 столбцов. Чтобы увидеть их все, нужно передвинуть полосу вправо. Однако в данном случае количество столбцов велико, и только прокрутка полосы вправо не позволит вам увидеть все столбцы, поскольку некоторые из них будут скрыты.
Чтобы действительно представить себе все столбцы, введите в отдельную ячейку следующее:
# Show all columns
pd.set_option("display.max_columns", None)
# Display the data frame
print(data)Шаг 3: Управление NaNs
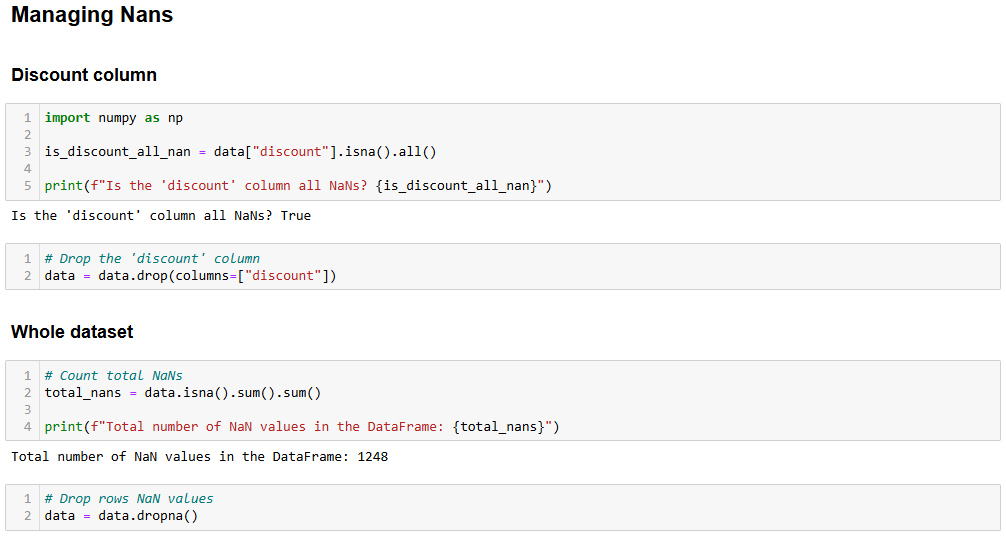
В вычислительной технике NaN означает “не число”. При анализе данных в Python вы можете столкнуться с наборами данных с пустыми значениями, строками, в которых должны быть числа, или ячейками, уже помеченными как NaN (см., например, столбец скидок на изображении выше).
Поскольку ваша цель – анализ данных, вы должны правильно обрабатывать NaN. У вас есть три основных способа сделать это:
- Удалите все строки, содержащие
NaN. - Замените
NaNв столбце средним значением, вычисленным по другим числам того же столбца. - Поиск новых данных для обогащения исходного набора данных.
Для простоты будем придерживаться первого подхода.
Сначала нужно проверить, все ли значения столбца "Скидка" являются NaN. Если это так, то можно удалить весь столбец. Чтобы проверить это, напишите в новой ячейке следующее:
import numpy as np
is_discount_all_nan = data["discount"].isna().all()
print(f"Is the 'discount' column all NaNs? {is_discount_all_nan}")В этом фрагменте метод isna().all() анализирует NaNsстолбца discount, который был отфильтрован из набора данных с помощью data["discount"].
В результате вы получите True, что означает, что столбец discount **** можно отбросить, так как все его значения – NaN. Чтобы добиться этого, напишите:
data = data.drop(columns=["discount"])Оригинальный набор данных был заменен новым набором данных без колонки скидок.
Теперь вы можете проанализировать весь набор данных и посмотреть, есть ли в строках еще NaN, как показано ниже:
total_nans = data.isna().sum().sum()
print(f"Total number of NaN values in the data frame: {total_nans}")Результат, который вы получите, будет следующим:
Total number of NaN values in the data frame: 1248Это означает, что в кадре данных есть еще 1248 NaN. Чтобы отбросить строки, содержащие хотя бы один NaN, введите:
data = data.dropna()Теперь кадр данных не содержит NaNи готов к анализу данных на Python без опасений, что результаты будут искажены.
Чтобы убедиться, что процесс прошел успешно, вы можете написать:
print(data.isna().sum().sum())Ожидаемый результат – 0.
Шаг 4: Исследование данных
Прежде чем визуализировать данные Airbnb, вам нужно с ними ознакомиться. Хорошая практика – начать с визуализации статистики вашего набора данных, например, так:
# Show statistics of the entire dataset
statistics = data.describe()
# Print statistics
print(statistics)Это ожидаемый результат:
price ratings lat long guests
count 182.000000 182.000000 182.000000 182.000000 182.000000
mean 147.523352 4.804505 6.754955 -68.300942 6.554945
std 156.574795 0.209834 27.795750 24.498326 3.012818
min 16.000000 4.000000 -21.837300 -106.817450 2.000000
25% 50.000000 4.710000 -21.717270 -86.628968 4.000000
50% 89.500000 4.865000 30.382710 -83.479890 6.000000
75% 180.750000 4.950000 30.398860 -43.925480 8.000000
max 1003.000000 5.000000 40.481580 -43.801300 16.000000
property_id host_number_of_reviews host_rating hosts_year
count 1.820000e+02 182.000000 182.000000 182.000000
mean 1.323460e+17 3216.879121 4.776099 7.324176
std 3.307809e+17 4812.876819 0.138849 2.583280
min 3.089381e+06 2.000000 4.290000 1.000000
25% 3.107102e+07 73.000000 4.710000 6.000000
50% 4.375321e+07 3512.000000 4.710000 9.000000
75% 4.538668e+07 3512.000000 4.890000 9.000000
max 1.242049e+18 20189.000000 5.000000 11.000000
host_response_rate total_price
count 182.000000 182.000000
mean 98.538462 859.317363
std 8.012156 1498.684990
min 25.000000 19.000000
25% 100.000000 111.500000
50% 100.000000 350.000000
75% 100.000000 934.750000
max 100.000000 13165.000000 Метод describe() сообщает статистику, относящуюся к столбцам с числовыми значениями. Это самый первый способ начать понимать свои данные. Например, столбец host_rating сообщает следующую интересную статистику:
- Всего в наборе данных 182 отзыва (значение
count). - Максимальная оценка – 5, минимальная – 4,29, а средняя – 4,77.
Тем не менее, приведенная выше статистика может вас не удовлетворить. Поэтому попробуйте изобразить диаграмму рассеяния для столбца host_rating, чтобы увидеть, есть ли какая-нибудь интересная закономерность, которую вы, возможно, захотите исследовать позже. Вот как можно создать диаграмму рассеяния с помощью seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
# Define figure size
plt.figure(figsize=(15, 10))
# Plot the data
sns.scatterplot(data=data, x="host_rating", y="listing_name")
# Labeling
plt.title("HOST RATINGS SCATTERPLOT", fontsize=20)
plt.xlabel("Host ratings", fontsize=16)
plt.ylabel("Houses", fontsize=16)
# Show plot
plt.show()Приведенный выше фрагмент выполняет следующие действия:
- Определяет размер изображения (в дюймах) с помощью метода
figure(). - Создает диаграмму рассеяния с помощью seaborn через метод
scatterplot(), настроенный на:Polylang placeholder do not modify
Это ожидаемый результат:

Отличный сюжет, но мы можем сделать лучше!
Шаг 5: Преобразование и визуализация данных
Предыдущая диаграмма рассеивания показывает, что в рейтингах ведущих нет определенной закономерности. Однако большинство рейтингов превышает 4,7 балла.
Представьте, что вы планируете отпуск и хотите остановиться в одном из лучших мест. Вы можете задать себе вопрос: “Сколько стоит проживание в доме с рейтингом не ниже 4,8?”
Чтобы ответить на этот вопрос, сначала нужно преобразовать данные!
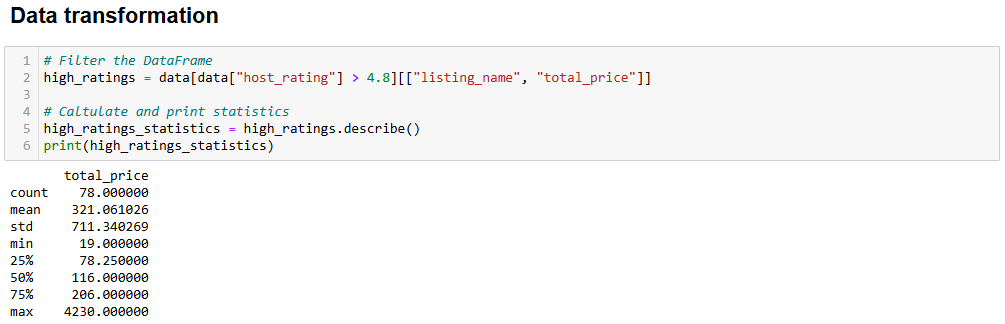
Преобразование, которое вы можете сделать, заключается в создании нового фрейма данных, где рейтинг больше 4,8. Он будет содержать столбец listing_n``ame с названиями квартир и столбец total_price с их ценами.
Получите это подмножество и покажите его статистику с помощью:
# Filter the DataFrame
high_ratings = data[data["host_rating"] > 4.8][["listing_name", "total_price"]]
# Caltulate and print statistics
high_ratings_statistics = high_ratings.describe()
print(high_ratings_statistics)Приведенный выше фрагмент создает новый кадр данных под названием high_ratings следующим образом:
data["host_rating"] > 4.8Фильтрует значения больше 4.8 в столбцеhost_ratingsиз набораданных.[["listing_name", "total_price"]]выбирает только столбцыlisting_nameиtotal_priceиз рамки данныхhigh_ratings.
Ниже приведен ожидаемый результат:
total_price
count 78.000000
mean 321.061026
std 711.340269
min 19.000000
25% 78.250000
50% 116.000000
75% 206.000000
max 4230.000000Статистика показывает, что средняя общая цена выбранных квартир составляет $321, при минимуме в $19 и максимуме в $4230. Это требует дальнейшего анализа!
Визуализируйте диаграмму цен на дома с высоким рейтингом с помощью того же сниппета, который вы использовали ранее. Все, что вам нужно сделать, это изменить переменные, используемые в диаграмме, следующим образом:
# Define figure size
plt.figure(figsize=(12, 8))
# Plot the data
sns.scatterplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show grid for better visualization
sns.set_style("ticks", {'axes.grid': True})
# Show plot
plt.show()И вот какой сюжет получился в результате:

Этот график демонстрирует два интересных факта:
- Цены в основном не превышают 500 долларов.
- Цены на “Целую хижину в Севиервилле” и “Целую хижину в Пиджеоне” значительно превышают 1000 долларов.
Лучшим способом визуализации ценового диапазона является бокс-график. Вот как это можно сделать:
# Define figure size
plt.figure(figsize=(15, 10))
# Plotting the boxplot
sns.boxplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES - BOXPLOT', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show plot
plt.show()На этот раз результирующий график будет таким:

Если вы задаетесь вопросом, почему один и тот же дом может стоить по-разному, вспомните, что вы отфильтровали оценки пользователей. Это означает, что разные пользователи платили по-разному и оставляли разные оценки.
Кроме того, значительный разброс цен на “Хижину в Севиервилле”, варьирующийся от менее 1000 до более 4000 долларов, может быть связан с продолжительностью пребывания. В исходном наборе данных есть столбец travel_details, в котором содержится информация о продолжительности пребывания. Широкий диапазон цен может указывать на то, что некоторые пользователи снимали дом на длительный срок. Более глубокий анализ с помощью Python может помочь раскрыть больше информации об этом!
Шаг 6: Дальнейшие исследования с помощью корреляционной матрицы
Анализ данных в Python – это задавание вопросов и поиск ответов в имеющихся данных. Один из эффективных способов задать эти вопросы – визуализация корреляционной матрицы.
Корреляционная матрица – это таблица, которая показывает коэффициенты корреляции для различных переменных. Наиболее часто используемым коэффициентом корреляции является коэффициент корреляции Пирсона (PCC), который измеряет линейную корреляцию между двумя переменными. Его значения варьируются от -1 до +1, что означает:
- +1: Если значение одной переменной увеличивается, то другая увеличивается линейно.
- -1 : Если значение одной переменной увеличивается, то другая линейно уменьшается.
- 0: Вы не можете ничего сказать о линейной связи двух переменных (это требует нелинейного анализа).
В статистике значения линейной корреляции определяют следующим образом:
- 0,1-0,5: низкая корреляция.
- 0,6-1: высокая корреляция.
- 0: корреляция отсутствует.
Чтобы отобразить корреляционную матрицу для фрейма данных, введите следующее:
# Set the images dimensions
plt.figure(figsize=(12, 10))
# Labeling
plt.title('CORRELATION MATRIX', fontsize=20)
plt.xticks(fontsize=16) # x-axis font size
plt.yticks(fontsize=16) # y-axis font size
# Applying mask
mask = np.triu(np.ones_like(numeric_data.corr()))
dataplot = sns.heatmap(numeric_data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})
#Add this code before creating the correlation matrix
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# Correlation matrix
dataplot = sns.heatmap(data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})Приведенный выше фрагмент выполняет следующие действия:
- Метод
np.triu()используется для диагонализации матрицы. Это используется для лучшей визуализации матрицы, чтобы она отображалась в виде треугольника, а не квадрата. - Метод
sns.heatmap()создает тепловую карту. Он также используется для лучшей визуализации. Внутри него находится методdata.corr(), который фактически вычисляет коэффициенты Пирсона для каждого столбцаданныхкадра.
Ниже приведен результат, который вы получите:

Основная идея при интерпретации корреляционной матрицы – найти переменные с высокой степенью корреляции, поскольку именно они станут отправной точкой для нового и более глубокого анализа. Например:
- Переменные
latиlongимеют корреляцию -0,98. Это ожидаемо, так как широта и долгота сильно коррелируют при определении конкретного места на Земле. - Переменные
host_ratingиlongимеют корреляцию -0,69. Это интересный результат, который означает, что рейтинг хоста сильно коррелирует с переменной longitude. Таким образом, похоже, что дома, расположенные в определенном районе мира, имеют высокие рейтинги хозяев. - Переменные
latиlongимеют, соответственно, 0,63 и -0,69 корреляции сценой. Этого достаточно, чтобы сказать, что цена за день сильно зависит от местоположения.
При анализе также следует искать некоррелированные переменные. Например, коэффициент переменных is_supperhost и price равен -0,18, что означает, что суперхосты не имеют самых высоких цен.
Теперь, когда основные понятия ясны, настала ваша очередь исследовать и анализировать данные!
Шаг 7: Соберите все вместе
Так будет выглядеть окончательный вариант Jupyter Notebook для анализа данных с помощью Python:







Обратите внимание на наличие различных ячеек, каждая из которых имеет свой выход.
Процесс анализа данных с помощью Python
В приведенном выше разделе вы познакомились с процессом анализа данных с помощью Python. Хотя может показаться, что это был пошаговый подход, обусловленный возможностями, на самом деле он был построен на следующих лучших практиках:
- Поиск данных: Если вам повезло, и нужные вам данные содержатся в базе данных, то вам повезло! Если нет, то вам нужно получить их с помощью популярных методов поиска данных, таких каквеб-скраппинг.
- Очистка данных: Обработка
NaNs, агрегирование данных и применение первых фильтров к исходному набору данных. - Исследование данных: Исследование данных – иногда его еще называют обнаружением данных – являетсянаиболее важной частью анализа данных с помощью Python. Она требует построения базовых графиков, которые помогут вам понять, как структурированы ваши данные и следуют ли они определенным закономерностям.
- Работа с данными: После того как вы уловили основные идеи, лежащие в основе анализируемых данных, вам предстоит ими манипулировать. Эта часть требует фильтрации наборов данных и часто объединения более двух наборов данных в один (как если бы вы выполняли объединение таблиц в SQL).
- Визуализация данных: Это заключительная часть, в которой вы визуально представите свои данные, построив несколько графиков на наборах данных, которыми вы манипулировали.
Заключение
В этом руководстве по анализу данных с помощью Python вы узнали, почему следует использовать Python для анализа данных и какие общие библиотеки можно использовать для этой цели. Вы также прошли через пошаговое руководство и узнали, как нужно действовать, если вы хотите выполнить анализ данных на Python.
Вы видели, что Jupyter Notebook помогает создавать подмножества данных, визуализировать их и открывать мощные идеи. При этом все данные остаются структурированными в единой среде. Где же найти готовые к использованию наборы данных? Bright Data поможет вам!
Bright Data управляет крупной, быстрой и надежной прокси-сетью, которую используют многие компании из списка Fortune 500 и более 20 000 клиентов. Она используется для этичного извлечения данных из Сети и их предложения на обширном рынке наборов данных, который включает в себя:
- Бизнес-данные: Данные из таких ключевых источников, как LinkedIn, CrunchBase, Owler и Indeed.
- Наборы данных по электронной коммерции: Данные из Amazon, Walmart, Target, Zara, Zalando, Asos и многих других.
- Наборы данных о недвижимости: Данные с таких сайтов, как Zillow, MLS и др.
- Наборы данных социальных сетей: Данные из Facebook, Instagram, YouTube и Reddit.
- Наборы финансовых данных: Данные из Yahoo Finance, Market Watch, Investopedia и др.
Создайте бесплатную учетную запись Bright Data сегодня и изучите наши наборы данных.






