

В этой статье вы узнаете о важности маркировки данных и о том, как выглядит этот процесс. Вы также рассмотрите некоторые примеры использования маркировки данных и откроете для себя методы повышения эффективности.
Важная роль маркировки данных в машинном обучении
Маркировка данных — это процесс тегирования или аннотирования данных, который обеспечивает базовую информацию, необходимую моделям контролируемого обучения для обучения и прогнозирования. Присваивая точные метки обучающим данным, вы позволяете моделям идентифицировать закономерности, понимать взаимосвязи и точно прогнозировать результаты.
По сути, маркировка данных учит модели идентифицировать различные вещи. Без правильно маркированных данных эти модели с трудом различали бы различные объекты. В машинном обучении, особенно в обучении с учителем, маркировка данных важна, потому что она напрямую влияет на то, насколько хорошо модель обучается и насколько точны ее прогнозы при применении к новым, невиданным данным.
Типы маркировки данных
Поскольку машинное обучение предполагает использование большого количества данных для обучения моделей, и чаще всего эти данные поступают из различных источников (включая книги, стоковые изображения и общедоступные аудио-/видеозаписи), их маркировка может включать в себя несколько различных процессов.
Обработка естественного языка
Обработка естественного языка (NLP) фокусируется на обработке данных, содержащих человеческий язык, таких как письменный текст или записанная речь. Эта техника, основанная на ML, помогает компьютерам понимать и интерпретировать такие данные. NLP также может автоматизировать маркировку данных с помощью таких техник, какраспознавание именованных сущностей (NER)для идентификации сущностей (например,имен, дат), классификация текста для категоризации данных и анализ тональности для маркировки эмоций или мнений:
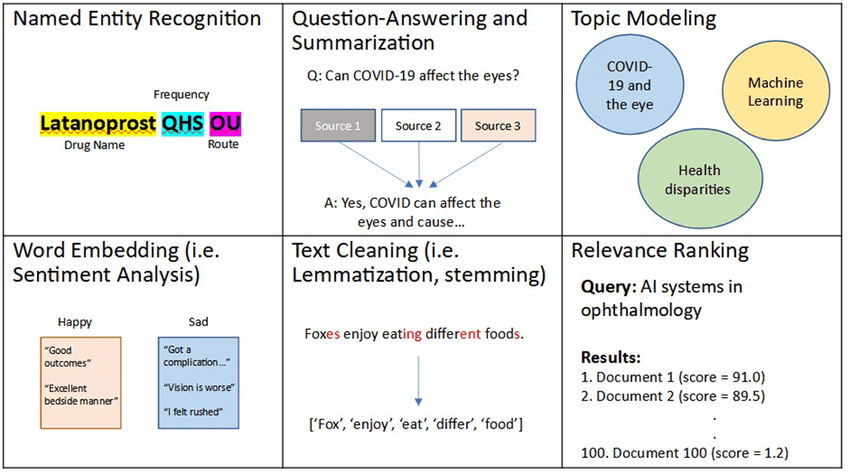
NLP использует предварительно обученные модели ML для прогнозирования и маркировки похожих паттернов в новых данных, что может значительно сократить объем ручной работы.
Компьютерное зрение
Компьютерное зрение — это подраздел искусственного интеллекта (ИИ), который позволяет компьютерам объективно интерпретировать данные изображений. Это означает, что вместо того, чтобы просто обрабатывать изображения как файлы с определенным расширением, компьютеры с помощью компьютерного зрения могут идентифицировать объекты и места (даже действия человека) на изображениях. Они могут сегментировать части изображений на основе инструкций, а также помогать классифицировать изображения по заданным критериям (например,помечать каждое изображение, на котором есть яблоко).
Предварительно обученные модели ML помогают в автоматической маркировке данных, предсказывая метки для новых, похожих данных. Это ускоряет процесс маркировки и повышает согласованность крупномасштабных наборов данных, которые используются для обучения моделей ML.
Обработка аудио
Обработка аудио означает анализ (и, при желании, изменение) звуковых файлов с целью извлечения полезной информации, такой как речь, музыка или окружающие звуки. Для сбора информации из аудиофайлов используются различные методы, такие как шумоподавление, извлечение характеристик (например, высота тона, частота) и преобразование аудио в текст с помощью распознавания речи.
Обработка аудио может оптимизировать маркировку данных путем автоматической транскрипции речи в текст, идентификации говорящих, обнаружения событий (например,выстрелов, сигналов тревоги) и классификации звуков. Это особенно полезно при аннотировании больших наборов аудиоданных, поскольку снижает необходимость вручную просматривать часы или даже дни необработанных аудиоданных для отметки событий, говорящих и других точек интереса.
Крупные языковые модели
Новейшим элементом в этом списке является большая языковая модель (LLM). LLM — это тип модели ИИ, обученной на огромных объемах данных для понимания и генерации языка, похожего на человеческий. LLM могут выполнять широкий спектр задач, связанных с естественным языком, таких как перевод, резюмирование, завершение текста и ответы на вопросы.
LLM могут генерировать метки для текстовых данных (например, настроение, категоризация тем), предлагать теги на основе шаблонов в данных и даже уточнять или исправлять ручные аннотации. Кроме того, многие LLM могут обрабатывать входные изображения и помогать вам маркировать объекты на изображениях.
Помимо маркировки данных, LLM могут быстро собирать данные из Интернета для обучения ваших моделей машинного обучения. Веб-скрейпинг с помощью ИИ, который объединяет вашу обычную настройку веб-скрейпинга с LLM, чтобы быстро понять структуру веб-сайтов и доступные данные, может помочь вам просеять большие объемы данных, собранных из Интернета, понять эти данные и даже маркировать их на лету. ИИ-Веб-скрейпинг также может анализировать структуру Document Object Model (DOM) веб-сайта для сбора данных и делать скриншоты веб-сайта в том виде, в котором он отображается пользователям. Затем инструменты ИИ-Веб-скрейпинга могут обрабатывать эти скриншоты для сбора данных. Если вы хотите узнать больше об ИИ-Веб-скрейпинге, ознакомьтесь с этой статьей в блоге «Как использовать AI для Веб-скрейпинга».
Подходы к маркировке данных
Данные могут быть представлены в самых разных форматах, и для каждого из этих форматов существуют методы, которые необходимо использовать для маркировки данных. Подход к маркировке данных варьируется в зависимости от компании и проекта. Вот некоторые из наиболее распространенных способов, которые команды используют для решения задач маркировки данных:
Внутренняя маркировка
Когда команды маркируют данные внутри компании, это называется внутренней маркировкой. Внутренняя маркировка обычно используется, когда требуется точность, контроль и экспертные знания в данной области.
Если вам нужны качество и согласованность, этот метод идеально подходит. Благодаря специальной команде профессионалов метки данных являются высокоспецифичными для области данных и проекта, что дополнительно способствует точности обученных моделей. Кроме того, поскольку метки данных создаются внутри компании, данные остаются конфиденциальными и защищенными.
Однако основным недостатком этого подхода является его не масштабируемость. Размер внутренних команд, работающих над такими задачами, обычно ограничен, поэтому получение полезного количества помеченных данных является трудоемкой и дорогостоящей задачей.
Синтетическая маркировка
Синтетическая маркировка использует метаданные; она относится к генерации маркированных данных из существующих наборов данных с использованием ML.
Основным преимуществом синтетической маркировки является ее масштабируемость и экономическая эффективность. Искусственно генерируя данные, можно быстро создать большие наборы данных без затрат времени и средств, связанных со сбором реальных примеров. Кроме того, синтетические данные позволяют моделировать редкие события или крайние случаи, которые могут быть сложными или небезопасными для фиксации в реальной жизни.
Однако минус заключается в том, что синтетические метки могут не полностью отражать сложность реальных сценариев, что может повлиять на точность и производительность моделей. Создание высококачественных синтетических данных требует опыта в области методов машинного обучения, что усложняет и без того простой процесс. Кроме того, качество данных, генерируемых в этом процессе, в значительной степени зависит от исходных обучающих данных используемой модели.
Программная маркировка
Программная маркировка означает использование правил, алгоритмов или скриптов для автоматизации процесса маркировки. Обычно она используется при работе с крупными наборами данных, когда ручная маркировка занимает слишком много времени, а также когда данные могут быть структурированы с помощью четких, основанных на правилах шаблонов, таких как классификация текста или анализ тональности.
Самым большим преимуществом программной маркировки является ее скорость и масштабируемость. Автоматизированные методы могут обрабатывать огромные объемы данных гораздо быстрее, чем люди, что значительно сокращает ручной труд и позволяет быстро расширять наборы данных. Этот подход особенно эффективен для простых, повторяющихся задач маркировки, где можно применять последовательные правила.
Однако ключевым недостатком является более низкая точность по сравнению с ручной маркировкой, особенно при работе со сложными или аномальными данными, которые могут не вписываться в заранее определенные правила. Кроме того, данные, маркированные с помощью этого метода, должны часто проверяться и уточняться для обеспечения качества, что все еще может потребовать значительного вмешательства человека.
Аутсорсинг
Аутсорсинг предполагает привлечение внешних поставщиков или компаний для выполнения задач по маркировке данных. Этот подход используется, когда внутренние команды не имеют достаточных ресурсов или когда проекты требуют крупномасштабной маркировки, которую необходимо выполнить быстро и эффективно.
Аутсорсинг является экономически эффективным при обработке больших объемов данных. Благодаря аутсорсингу внешним организациям команды могут масштабировать свои усилия по маркировке без значительных инвестиций в создание и обучение внутренних специалистов. Кроме того, это освобождает внутренние ресурсы для сосредоточения на основных задачах и разработке проектов.
Однако качество аутсорсинговой маркировки может варьироваться, поскольку внешние команды редко обладают таким же уровнем экспертизы в данной области или пониманием требований конкретного проекта. Существуют также потенциальные риски, связанные с конфиденциальностью и безопасностью данных, поскольку конфиденциальная информация должна передаваться третьим сторонам.
Краудсорсинг
Краудсорсинг предполагает распределение задач по маркировке данных среди большой и разнообразной группы неспециалистов через такие платформы, какAmazon Mechanical Turk. Обычно он используется для задач, которые можно разбить на простые единицы большого объема, такие как тегирование изображений или базовая классификация текста.
Основным преимуществом краудсорсинга является его масштабируемость и скорость. Используя большую распределенную рабочую силу, команды могут быстро маркировать большие наборы данных при относительно низких затратах, что делает его эффективным вариантом для простых задач маркировки, не требующих специальных знаний.
Однако качество и точность меток, полученных с помощью краудсорсинга, могут быть нестабильными, поскольку работники могут не обладать специальными знаниями в данной области. Обеспечение единообразия и точности меток может быть сложной задачей, и часто требуются меры контроля качества, такие как дублирование и валидация. Несмотря на свою экономическую эффективность, краудсорсинг может не подходить для сложных задач маркировки, требующих специальных знаний, или в ситуациях, когда конфиденциальность данных имеет критическое значение.
Использование надежных наборов данных
В то время как ручные, программные и краудсорсинговые методы предоставляют различные подходы к маркировке, доступ к предварительно маркированным высококачественным наборам данных может значительно повысить масштабируемость. Надежные наборы данных, такие какте, которые предлагает Bright Data, предоставляют готовое решение для сбора данных в больших объемах, обеспечивая согласованность и точность, а также сокращая время и усилия, необходимые для маркировки.
Используя надежные наборы данных в своем рабочем процессе, вы можете ускорить разработку моделей, сосредоточиться на усовершенствовании алгоритмов и поддерживать высокие стандарты качества данных, что в конечном итоге оптимизирует процесс маркировки для получения более эффективных результатов машинного обучения.
Проблемы при маркировке данных
Независимо от того, какой метод и подход вы выберете, при работе над задачами маркировки данных вы столкнетесь с проблемами.
Несбалансированные наборы данных
Одной из наиболее распространенных проблем являются несбалансированные наборы данных, в которых определенные классы или категории имеют значительно меньше примеров, чем другие. Это может привести к появлению предвзятых моделей, которые хорошо работают с большинством классов, но плохо — с меньшинством. Для обеспечения достаточного представления всех категорий необходимо либо собрать больше данных, либо сгенерировать синтетические образцы, что может быть трудоемким и ресурсоемким процессом.
Шумовые метки
Шумовые метки возникают, когда данные маркируются неверно, будь то из-за ручной ошибки, неоднозначности в рекомендациях по маркировке или несоответствий в краудсорсинговой работе. Шумовые метки могут значительно ухудшить производительность модели, поскольку она может научиться неверным шаблонам или ассоциациям. Вы можете решить эту проблему с помощью таких методов, как проверка меток, избыточность и уточнение критериев маркировки, которые могут увеличить время и стоимость процесса маркировки.
Проблемы масштабирования
По мере роста объема данных, необходимых для обучения моделей, необходимо иметь возможность масштабировать процесс маркировки. Традиционные методы ручной маркировки не всегда практичны, а даже автоматизированные методы, такие как программная или аутсорсинговая маркировка, имеют ограничения, такие как снижение точности или проблемы с конфиденциальностью данных. Для достижения масштабируемости и качества маркировки необходимо найти баланс между автоматизацией и контролем со стороны человека, что может быть сложно в управлении.
Динамические данные
В большинстве реальных приложений данные постоянно меняются/развиваются, что делает необходимым постоянное обновление маркированных наборов данных. Это особенно актуально в таких областях, как мониторинг в реальном времени или автономное вождение. Для поддержания актуальности и релевантности наборов данных необходимо внедрить эффективные конвейеры для постоянной маркировки и валидации, что добавляет еще один уровень сложности к процессу маркировки.
Лучшие практики маркировки данных
Есть несколько методов, которые следует иметь в виду, чтобы эффективно маркировать данные с помощью высококачественных меток.
Аудит меток
Первый и наиболее очевидный передовой метод — это аудит меток. Он включает в себя проверку подмножества помеченных образцов с целью выявления ошибок, несоответствий или неоднозначностей в процессе маркировки. Когда ошибки обнаруживаются на ранней стадии, команды могут уточнить рекомендации и предоставить целевую обратную связь, обеспечив точность всего набора данных.
Перенос обучения
Подобно программной маркировке, но с более человеческим подходом, перенос обучения предполагает использование командами предварительно обученных моделей для помощи в маркировке новых наборов данных. Модели могут предсказывать и предлагать метки на основе своих предыдущих знаний, что ускоряет и повышает эффективность маркировки больших наборов данных.
Активное обучение
Активное обучение фокусируется на выборе наиболее информативных или неопределенных образцов для маркировки человеком. Уделяя приоритетное внимание этим образцам, команды могут повысить эффективность своих усилий по маркировке и применять человеческий опыт там, где он приносит наибольшую пользу. Такой подход помогает быстрее совершенствовать модели, минимизируя при этом общую нагрузку по маркировке.
Консенсус
Методы консенсуса могут использоваться в условиях краудсорсинга или аутсорсинга для повышения точности маркировки. В таких методах один и тот же образец маркируется несколькими метками, и окончательная метка определяется на основе согласия между несколькими метками. Существует множество настроек и способов определения консенсуса, таких как использование системы голосования по принципу большинства или отсеивание представленных аннотаций на основе заранее установленных правил.
Примеры использования маркировки данных
Теперь, когда вы знаете, как маркировать данные, давайте рассмотрим некоторые из наиболее распространенных примеров использования ML:
- анализ настроений
- модели могут быть обучены
Используйте Bright Data для маркировки данных
Как упоминалось ранее, Bright Data предлагаетвысококачественные наборы данных, которые значительно повышают точность и эффективность процесса маркировки данных. Благодаря своим обширным возможностям по сбору данных, Bright Data предоставляет командам ИИ актуальные, обширные, разнообразные и точно маркированные наборы данных, которые необходимы для обучения моделей.
Наборы данных Bright Data адаптированы к различным областям, что гарантирует получение моделями точной, специфичной для данной области информации для оптимальной производительности. Они также могут помочь вам уменьшить количество ошибок маркировки и достичь более высокого уровня производительности и эффективности моделей. Вы можете использовать эти наборы данных в их первоначальном виде в своих основных упражнениях по обучению ML или использовать их для помощи в синтетической или программной маркировке.
Наборы данных Bright Data также помогают масштабировать процессы маркировки. Имея доступ к крупномасштабным структурированным наборам данных из различных областей, таких как социальные сети, недвижимость и электронная коммерция, команды ИИ могут ускорить процесс маркировки, сократив необходимость ручной работы и ускорив циклы разработки. Такая масштабируемость позволяет компаниям обрабатывать огромные объемы данных, что необходимо для создания решений ИИ.
Заключение
Маркировка данных — важный этап в разработке моделей машинного обучения, обеспечивающий структурированную информацию, необходимую алгоритмам для обучения и точных прогнозов. В этой статье были рассмотрены различные методы и подходы к маркировке данных, а также ключевые случаи их использования, такие как анализ тональности (когда текст маркируется эмоциями) и обнаружение мошенничества (когда аномалии помечаются для выявления подозрительной деятельности).
Узнайте, как Bright Data может помочь вам в ваших проектах, предоставляя данные для ИИ в виде готовых к использованию наборов данных. Зарегистрируйтесь сейчас и начните свое путешествие в мир данных с бесплатной пробной версии!






