

Обнаружение данных — это процесс сбора данных из различных источников, их подготовки и анализа, а также извлечения ценной информации. Конечная цель обнаружения данных — понять данные на более глубоком уровне и использовать их для принятия более эффективных решений. Информация, извлеченная в процессе обнаружения данных, может помочь компаниям в выявлении мошенничества, бизнес-планировании, прогнозировании оттока клиентов, оценке рисков, генерации лидов и многом другом.
В этой статье вы узнаете, что такое обнаружение данных, почему оно важно и каковы наиболее распространенные этапы процесса обнаружения данных.
Что такое обнаружение данных и почему оно важно
По оценкам, объем данных, генерируемых ежедневно,к 2025 году достигнет 181 зеттабайта. Такие огромные объемы данных могут быть невероятно полезными, однако для этого нужен способ извлечения из них полезной информации. Именно здесь и приходит на помощь обнаружение данных. Объединяя данные из различных источников и анализируя их, компании могут улучшить процесс принятия решений и свою бизнес-стратегию.
Процесс обнаружения данных
В рамках процесса обнаружения данных обычно выполняется несколько шагов, включая определение цели, сбор данных, подготовку данных, визуализацию данных, анализ данных, интерпретацию и принятие мер:
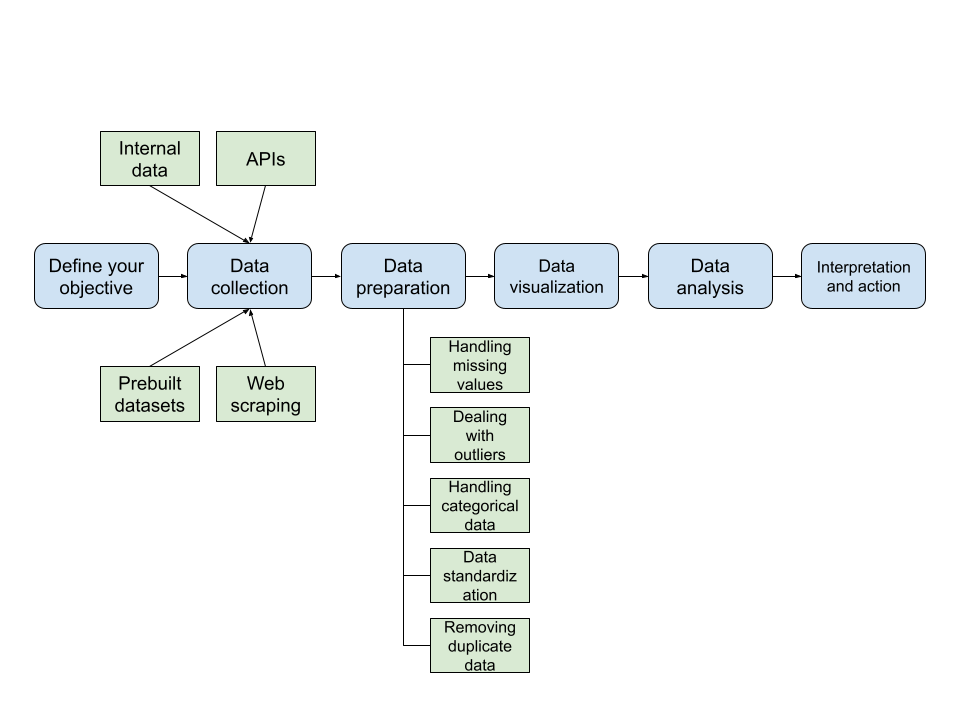
Важно отметить, что обнаружение данных — это высоко итеративный процесс; вы можете перейти с любого этапа процесса к предыдущему, если считаете, что это улучшит конечный результат.
1. Определите свою цель
Иногда это упускается из виду, но определение целей должно быть первым шагом в процессе обнаружения данных. Ваша цель определяет, какие данные вам нужны. Как только вы поймете, чего хотите достичь, у вас будет более четкое представление о том, какие данные следует собирать, как их подготовить, как проанализировать и как извлечь из них ценную информацию.
2. Сбор данных
После определения цели необходимо определить источники данных, которые вы хотите использовать, и собрать их. Для этого существует много различных методов. Например, большинство организаций уже обладают большим количеством полезных данных, которые часто называют первичными данными. Эти данные могут храниться в базах данных, озерах данных, хранилищах данных или чем-то подобном. С внутренними данными поиск источников данных прост, и, как правило, первичные данные являются достоверными.
Однако внутренних данных часто недостаточно для получения полезных аналитических выводов. Обычно необходимо также собирать данные из различных внешних источников. Один из вариантов — использовать API, которые многие компании и организации предоставляют для обмена своими данными. Некоторые известные примеры — API Google, API Instagram, API Zillow, API Reddit и API YouTube. Некоторые API бесплатны, но за многие нужно платить. Прежде чем изучать другие методы сбора данных, рекомендуется проверить, предлагает ли источник API, так как это может значительно упростить процесс.
Однако большинство веб-данных недоступно через API. В этом случае вы все равно можете собирать данные с помощьюВеб-скрейпинга, который позволяет получать данные с веб-страницы и хранить их в формате, более удобном для анализа данных, например CSV.
Вы можете выполнять Веб-скрейпинг самостоятельно, написав собственные скрипты, которые извлекают нужные вам данные. Однако для этого требуются навыки Веб-скрейпинга, и это может занять много времени. Кроме того, вам придется иметь дело с механизмами защиты от веб-парсинга, используемыми веб-сайтами. Альтернативой является использование готовых инструментов для мгновенного веб-парсинга, таких какBright Data Web Scraper API. Такие инструменты довольно просты в использовании, не требуют навыков программирования и могут быть очень эффективны в борьбе с механизмами защиты от веб-парсинга.
Если вы ищете еще более простое решение, вы можете попробовать найти готовые наборы данных, которые можно приобрести. Такие наборы данных тщательно собираются из надежных источников, анализируются, очищаются и структурируются удобным для пользователя образом. Например, Bright Data предлагаетболее сотни готовых наборов данныхиз некоторых из самых популярных источников, таких как Amazon, Instagram, X (Twitter), LinkedIn и Walmart. Он также позволяет вамсоздавать наборы данных на заказс помощью автоматизированной платформы.
Как правило, вы часто используете комбинацию этих источников данных или даже некоторые, которые не упомянуты (такие как данные в реальном времени, публичные наборы данных или опросы). Это потому, что ни один источник данных обычно не содержит всех необходимых вам данных.
3. Подготовка данных
После того, как вы получили данные, следующим шагом является их подготовка к анализу. Обычно данные, собранные из различных источников, не имеют именно того формата, который вам нужен. Вам необходимо унифицировать формат,провести парсинг данных, обработать отсутствующие значения, удалить дубликаты, обработать выбросы, обработать категориальные данные, стандартизировать или нормализовать данные и решить любые другие проблемы, которые вы обнаружите.
Необработанные данные обычно содержат определенные недостатки, такие как отсутствующие данные. В этом случае вы можете просто отбросить экземпляры, в которых отсутствуют некоторые данные. Однако более распространенным методом является вменение отсутствующих значений (особенно в случаях, когда у вас не так много данных).
Существуют различные методы вменения отсутствующих значений, такие как вменение медианы, вменение среднего значения или более сложные методы, такие как многомерное вменение по цепочке уравнений (MICE). Еще одна потенциальная проблема с числовыми данными — переменные с разными диапазонами. В этом случае может быть полезно нормализовать (масштабировать данные в диапазоне от 0 до 1) или стандартизировать (масштабировать данные до среднего значения 0 и стандартного отклонения 1) данные. Выбор между этими двумя методами зависит от статистической техники, которую вы используете на этапе анализа данных, а также от распределения ваших данных.
Низкое качество данных может привести к низкому качеству результатов и выводов. Цель этого этапа — обработать исходные данные и получить чистые, высококачественные данные, готовые к анализу.
4. Визуализация данных
После очистки данных вы можете создать различные диаграммы, которые помогут вам изучить данные. Визуализация данных полезна, поскольку иногда легче увидеть выводы из визуализированных данных, чем из данных в таблицах. Существует бесчисленное множество типов диаграмм, и все они могут демонстрировать разные аспекты данных. Некоторые из наиболее популярных — гистограмма (подходит для сравнения значений), линейный график (подходит для отображения тенденции за определенный период), круговая диаграмма (подходит для отображения структуры категории), бокс-плот (подходит для обобщения данных и выявления выбросов), гистограмма (подходит для проверки распределения данных) и тепловые карты (подходят для анализа корреляций).
Существует множество инструментов, которые могут помочь вам в использовании упомянутых выше методов визуализации данных. Некоторые из наиболее популярных —Power BIиTableau. Эти инструменты удобны в использовании, идеально подходят для создания панелей мониторинга и отчетов, а также отлично подходят для совместной работы и обмена информацией.
Если вам нужны высококастомизированные визуализации, вы можете обратиться к библиотекам Python, таким какMatplotlibилиseaborn. Эти библиотеки требуют навыков программирования и имеют гораздо более крутой кривой обучения по сравнению с Power BI и Tableau. Однако они позволяют использовать определенные типы визуализаций и обеспечивают широкие возможности настройки:
По сути, визуализация данных помогает вам лучше понять данные, с которыми вы работаете, включая скрытые закономерности, взаимосвязи между переменными и аномалии в данных.
5. Анализ данных
Анализ данных тесно связан с визуализацией данных. Фактически, эти два этапа часто выполняются одновременно в рамках комплексного процесса, называемого исследовательским анализом данных.
Анализ данных позволяет вам более глубоко изучить данные, создать описательную и сводную статистику и обобщить все это в комплексных отчетах. Подобно визуализации данных, цель этого этапа — выявить тенденции, закономерности, взаимосвязи и аномалии.
Существует множество методов извлечения информации из данных. Статистический анализ — один из популярных методов, который обычно анализирует данные с помощью описательной статистики (подходит для обобщения характеристик данных) и инференционной статистики (подходит для прогнозирования на основе выборки). Машинное обучение (ML) также является популярным методом и использует контролируемое обучение (работает с классификациями и регрессиями на основе помеченных данных), неконтролируемое обучение (использует такие методы, как кластеризация и уменьшение размерности на непомеченных данных) и обучение с подкреплением (обучается через взаимодействие с окружающей средой). Все это можно выполнить с помощью библиотек Python, таких какpandas,NumPy иscikit-learn.
6. Интерпретация и действия
После анализа данных пришло время обобщить все выявленные закономерности и интерпретировать их. На основе анализа данных и визуализации данных должны быть извлечены ценные выводы. Эти выводы должны быть применимы на практике и приводить к принятию более эффективных решений. Вы можете прийти к этим выводам, определив закономерности, имеющие отношение к вашим бизнес-целям, понять, почему они возникают, расставить их по приоритетам и продолжать отслеживать, как эти закономерности развиваются.
На этом этапе вы можете вернуться к поставленным целям и проверить, были ли они достигнуты. Если нет, вы можете вернуться к любому из предыдущих этапов и попытаться их улучшить. Это может означать сбор дополнительных данных, их подготовку по-другому или дальнейший анализ данных и поиск дополнительных выводов.
Методы обнаружения данных
Процесс обнаружения данных может быть ручным или автоматизированным. Оба метода имеют свои преимущества и недостатки.
Ручной поиск данных
Как следует из названия, ручной поиск данных подразумевает, что процесс поиска данных выполняется человеком. Это означает, что человек собирает данные, унифицирует форматы, готовит их для дальнейшего анализа, а также визуализирует и анализирует данные. Для успешного выполнения этой задачи человек, осуществляющий ручной поиск данных, должен быть знаком с инструментами и методами анализа данных, различными статистическими методами и инструментами визуализации данных; должен обладать некоторыми техническими навыками, такими как кодирование; и должен иметь знания в той области, в которой он работает.
При ручном обнаружении данных человек имеет возможность извлечь из данных некоторые ценные сведения, которые машина может упустить, например, некоторые взаимосвязи между переменными, определенные тенденции или причины аномалий. Если в данных есть аномалия, человек может исследовать причины, лежащие в ее основе, в то время как машина обычно может только сообщить о ней. Однако выполнение процесса обнаружения данных вручную требует сложного набора навыков и происходит гораздо медленнее, чем автоматическое обнаружение данных.
Автоматическое обнаружение данных
Благодаря огромным достижениям в области искусственного интеллекта (ИИ) и машинного обучения (ML) процесс обнаружения данных может быть в значительной степени автоматизирован. В случае автоматического обнаружения данных программное обеспечение ИИ выполняет многие из описанных ранее шагов.
Инструменты ИИ, такие как DataRobot, Alteryx и Altair RapidMiner, могут автоматически подготавливать данные, включая унификацию форматов, обработку отсутствующих значений, а также обнаружение аномалий и выбросов. Такие инструменты также быстрее, чем ручной поиск данных, и не требуют столь большого опыта.
Следует иметь в виду, что инструменты ИИ могут быть сложными, дорогостоящими, в значительной степени зависящими от качества данных и часто требующими обслуживания; кроме того, результаты, полученные с помощью инструментов ИИ, могут быть более сложными для интерпретации. Все эти факторы следует учитывать при выборе между автоматизированным и ручным обнаружением данных.
Классификация данных
С концепцией обнаружения данных связана концепция классификации данных. С помощью классификации данных можно разделить данные на категории по заранее определенным критериям и правилам. Некоторые из распространенных способов классификации данных на основе этих критериев включают разделение по типу данных (структурированные, неструктурированные, полуструктурированные), уровню конфиденциальности (общедоступные, внутренние, конфиденциальные), способу использования данных (операционные, исторические, аналитические) и источнику данных (внешние и внутренние). Это может помочь компаниям отслеживать большие объемы собираемых данных.
Существуют различные методы, которые можно использовать для классификации данных. Более простые методы заключаются в использовании классификации на основе правил, при которой данные можно классифицировать на основе определенных ключевых слов или шаблонов. Более сложный метод заключается в использовании некоторых популярных алгоритмов машинного обучения, таких как нейронные сети, деревья решений или линейные модели.
Безопасность и соответствие
Безопасность и соблюдение нормативных требований, таких какОбщий регламент по защите данных (GDPR),Закон о защите прав потребителей штата Калифорния (CCPA) илиЗакон о переносимости и подотчетности в сфере медицинского страхования (HIPAA), имеют решающее значение для компаний, которые работают с данными. Однако по мере роста объема данных в организации становится все труднее обеспечить безопасность и соблюдение нормативных требований.
Обнаружение данных может помочь в этом, поскольку позволяет выявлять риски безопасности и пробелы в соблюдении нормативных требований. С помощью обнаружения данных организации могут выявлять конфиденциальные данные в незащищенных местах, обнаруживать аномалии или данные, хранящиеся дольше, чем необходимо. Некоторые инструменты, такие какVaronis,Collibra иBigID, могут помочь в обеспечении безопасности данных.
В предыдущем разделе упоминалось, что классификация данных может помочь в обеспечении соответствия требованиям. Этого можно достичь путем обучения моделей классификации ИИ для выявления рисков безопасности и данных, не соответствующих требованиям. Модели ИИ могут быть контролируемыми, такими как нейронные сети и машины градиентного усиления, но также и неконтролируемыми, такими как обнаружение аномалий. Интегрируясь в существующие системы безопасности, ИИ может улучшить обнаружение угроз, возможности реагирования и уровень безопасности. ИИ также может помочь в анализе больших объемов данных и выявлении закономерностей, которые человек может упустить; он может предсказывать потенциальные уязвимости, а также обнаруживать необычное поведение.
Инструменты для обнаружения данных
Существует множество инструментов, помогающих в обнаружении данных. Такие инструменты позволяют даже людям без опыта программирования выполнять процесс обнаружения данных. Эти инструменты могут помочь в автоматической подготовке, анализе или автоматической визуализации данных. Однако инструменты для обнаружения данных также могут значительно улучшить процесс сбора данных, в основном за счет автоматизации Веб-скрейпинга.
Например,API Bright Data Web Scraperпозволяет сканировать популярные веб-сайты. Он прост в использовании, обладает высокой масштабируемостью и имеет все функции, которые ожидаются от мгновенного Веб-скрейпинга. Если вы предпочитаете получить готовый набор данных, вы можете выбрать один изболее чем ста наборов данных, доступных в Bright Data.
Источник данных, который вы выберете, зависит от доступности данных, а также от ваших потребностей и предпочтений. Если вы можете найти готовый набор данных, содержащий нужные вам данные, то получить этот набор данных будет быстрее, чем пытаться собрать данные самостоятельно. Если наборы данных недоступны, вы можете проверить, доступны ли данные через API, так как это, как правило, быстрее, чем сбор данных. Однако, если API нет, вам, вероятно, придется собирать данные самостоятельно, либо вручную, либо с помощью автоматического Веб-скрейпинг.
Заключение
В этой статье вы узнали о важности обнаружения данных и о том, как осуществляется процесс обнаружения данных. Вы также узнали о нескольких методах обнаружения данных и о некоторых инструментах, которые можно использовать для обнаружения данных.
Bright Dataпредлагает несколько решений для обнаружения данных, таких какпрокси-сервисы, API для веб-скрепера и наборы данных. Эти инструменты могут значительно помочь вам на этапе сбора данных в процессе обнаружения данных. Попробуйте Bright Data бесплатно уже сегодня!






