
В этой статье вы узнаете:
- Что такое конвейеры ИИ Vertex.
- Почему в них можно интегрировать SERP API от Bright Data для проверки фактов (и многих других случаев использования).
- Как построить конвейер проверки фактов в Vertex ИИ с использованием SERP API от Bright Data для получения актуального контекста веб-поиска.
Давайте погрузимся!
Что такое конвейеры ИИ Vertex?
Vertex ИИ Pipelines – это управляемая служба в Google Cloud, которая автоматизирует, организует и воспроизводит сквозные рабочие процессы машинного обучения.
Этот сервис позволяет разбить сложные процессы ML, такие как обработка данных, обучение и развертывание, на ряд модульных компонентов, которые можно отслеживать, версионировать и запускать в бессерверной среде.
Одним словом, Vertex ИИ Pipelines упрощает жизненный цикл MLOps, облегчая создание повторяемых и масштабируемых систем ML.
Построение конвейера проверки фактов в Vertex ИИ: зачем и как
LLM, безусловно, сильны, но их знания статичны. Поэтому LLM, обученный в 2024 году, не знает о вчерашних движениях фондового рынка, вчерашних спортивных результатах и т. д. Это приводит к “несвежим” или “галлюцинированным” ответам.
Чтобы решить эту проблему, вы можете создать систему, которая будет “подпитывать” LLM актуальными данными из Интернета. Прежде чем LLM сгенерирует ответ, он получает внешнюю информацию, чтобы убедиться, что его вывод основан на текущих фактах. В этом и заключается суть RAG(Retrieval-Augmented Generation)!
Сейчас Gemini предоставляет инструмент для подключения моделей Gemini к Google Search. Однако этот инструмент не готов к производству, имеет проблемы с масштабируемостью и не дает вам полного контроля над источником данных для обоснования. Посмотрите на этот инструмент в действии в нашем агенте по оптимизации контента GEO/SEO.
Более профессиональная и гибкая альтернатива – SERP API от Bright Data. Этот API позволяет программно выполнять поисковые запросы к поисковым системам и получать полное содержимое SERP API. Другими словами, он дает вам надежный источник свежего, проверенного контента, который можно интегрировать в рабочие процессы LLM. Откройте для себя все, что он может предложить, изучив его документацию.
Например, вы можете интегрировать SERP API в Vertex ИИ Pipelines как часть конвейера проверки фактов. Это будет состоять из трех этапов:
- Извлечение запросов: LLM читает входной текст и выделяет основные фактические утверждения, преобразуя их в запросы, которые можно искать в Google.
- Получение контекста веб-поиска: Этот компонент берет эти запросы и вызывает SERP API Bright Data, чтобы получить результаты поиска в режиме реального времени.
- Проверка фактов: На последнем этапе LLM из исходного текста и полученного поискового контекста составляется отчет о проверке фактов.
Примечание: Это лишь один из многих возможных вариантов использования SERP API в конвейере данных/ML.
Как интегрировать SERP API от Bright Data для веб-поиска в конвейер ИИ Vertex
В этом разделе мы рассмотрим все шаги, необходимые для реализации конвейера проверки фактов в конвейерах ИИ Vertex. Для этого будет использоваться SERP API компании Bright Data, который будет использоваться для получения фактического контекста веб-поиска.
Помните, что проверка фактов – это лишь один из многих вариантов использования (например, обнаружение новостей, обобщение контента, анализ тенденций или помощь в проведении исследований), в которых вы можете использовать SERP API в узле конвейера ИИ Vertex. Таким образом, вы можете легко адаптировать эту реализацию ко многим другим сценариям.
Чтобы это выяснить, выполните следующие шаги!
Предварительные условия
Чтобы следовать этому разделу руководства, убедитесь, что у вас есть:
- Аккаунт Google Cloud Console.
- Аккаунт Bright Data с активным ключом API (в идеале с правами администратора).
Следуйте официальному руководству Bright Data, чтобы узнать , как получить свой ключ API. Храните его в надежном месте, так как он вам скоро понадобится.
Шаг № 1: Создание и настройка нового проекта Google Cloud
Войдите в Google Cloud Console и создайте новый проект. Также убедитесь, что биллинг включен (можно использовать бесплатную пробную версию).
В этом примере назовем проект Google Cloud “Bright Data SERP API Pipeline” и зададим идентификатор проекта bright-data-pipeline:
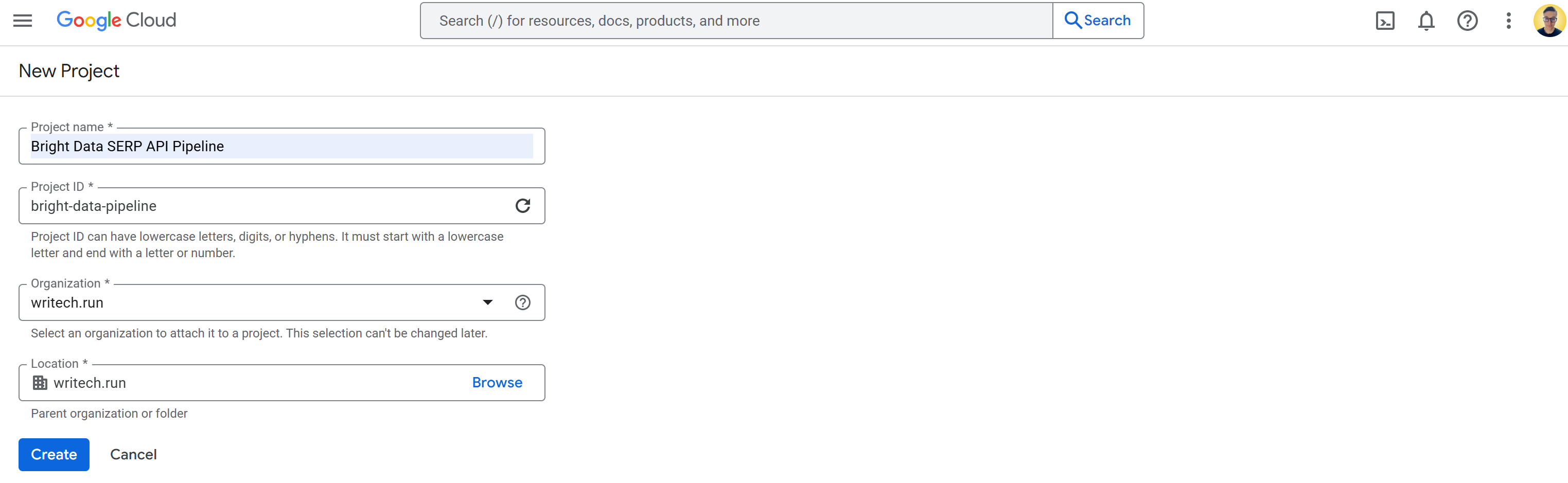
Когда проект будет создан, выберите его, чтобы начать работу над ним. Теперь у вас должно появиться вот такое представление:
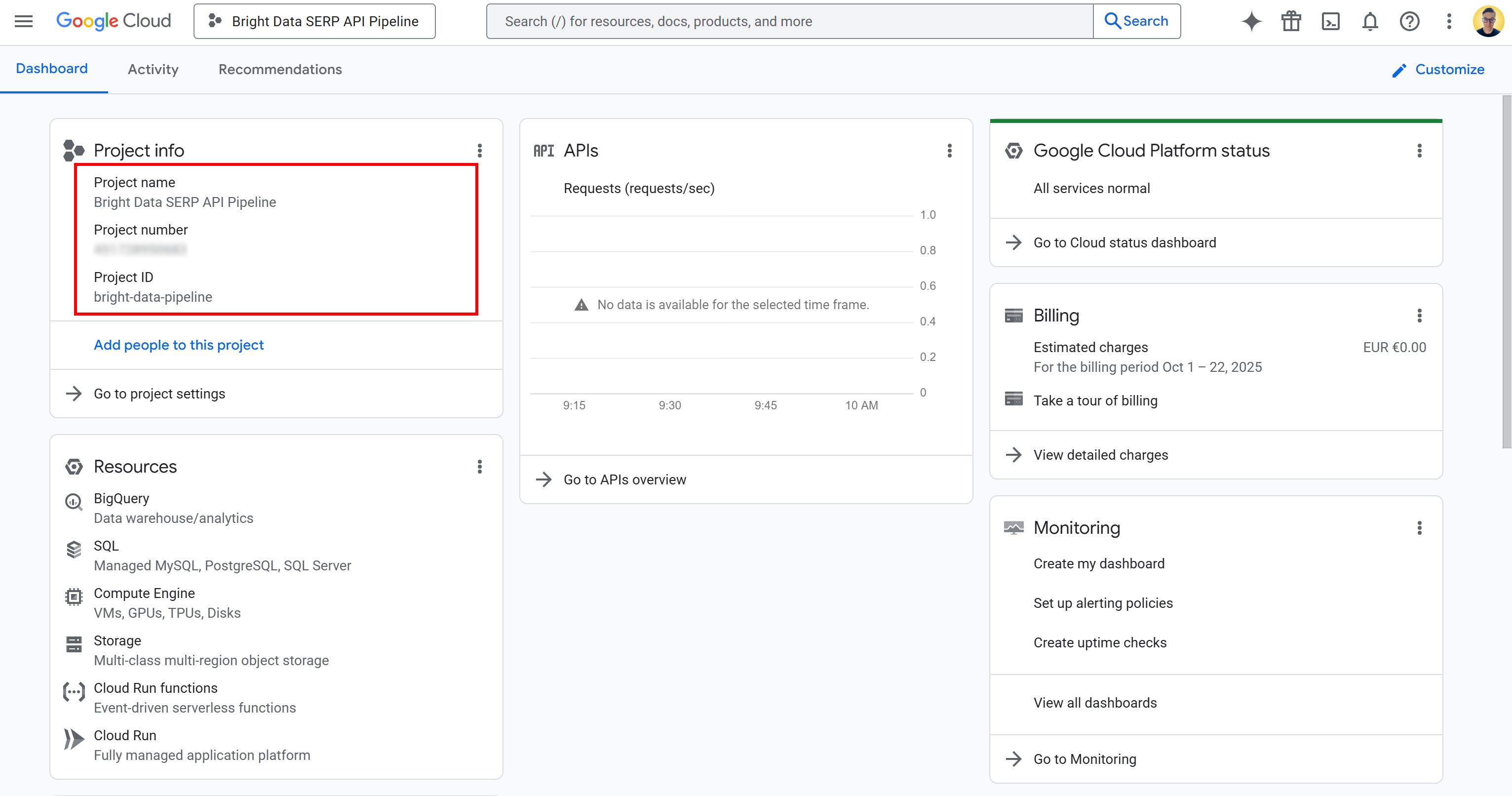
На этой странице вы можете найти название проекта, номер проекта и идентификатор проекта. Номер и идентификатор проекта понадобятся вам позже в учебнике, поэтому запишите их и храните в надежном месте.
Теперь, когда ваш проект Google Cloud готов, следующий шаг – активировать необходимые API. В строке поиска введите “API и службы”, перейдите на страницу и нажмите кнопку “Включить API и службы”:

Найдите и включите следующие API:
Эти два API необходимы для использования и разработки с ИИ Vertex в Vertex ИИ Workbench.
Примечание: Конвейер также зависит от нескольких других API, которые обычно включены по умолчанию. В случае возникновения проблем убедитесь, что они также включены:
- “Cloud Resource Manager API”
- “API облачного хранилища”
- “API использования сервисов”
- “Compute Engine API”
- “Gemini for Google Cloud API”
- “Cloud Logging API”
Если какие-либо из них отключены, включите их вручную, прежде чем продолжить.
Готово! Теперь у вас есть проект Google Cloud.
Шаг № 2: Настройка ведра облачного хранилища
Для запуска конвейеров ИИ Vertex необходимо ведро облачного хранилища. Это связано с тем, что Vertex ИИ должен хранить артефакты конвейера, такие как промежуточные данные, файлы моделей, журналы и метаданные, созданные в ходе выполнения конвейера. Другими словами, настроенное ведро выступает в качестве рабочего пространства, в котором компоненты трубопровода считывают и записывают данные.
Чтобы создать ведро, выполните поиск “Облачное хранилище” в Google Cloud Console. Откройте первый результат, выберите “Ведра” в левом меню, а затем нажмите кнопку “Создать”:
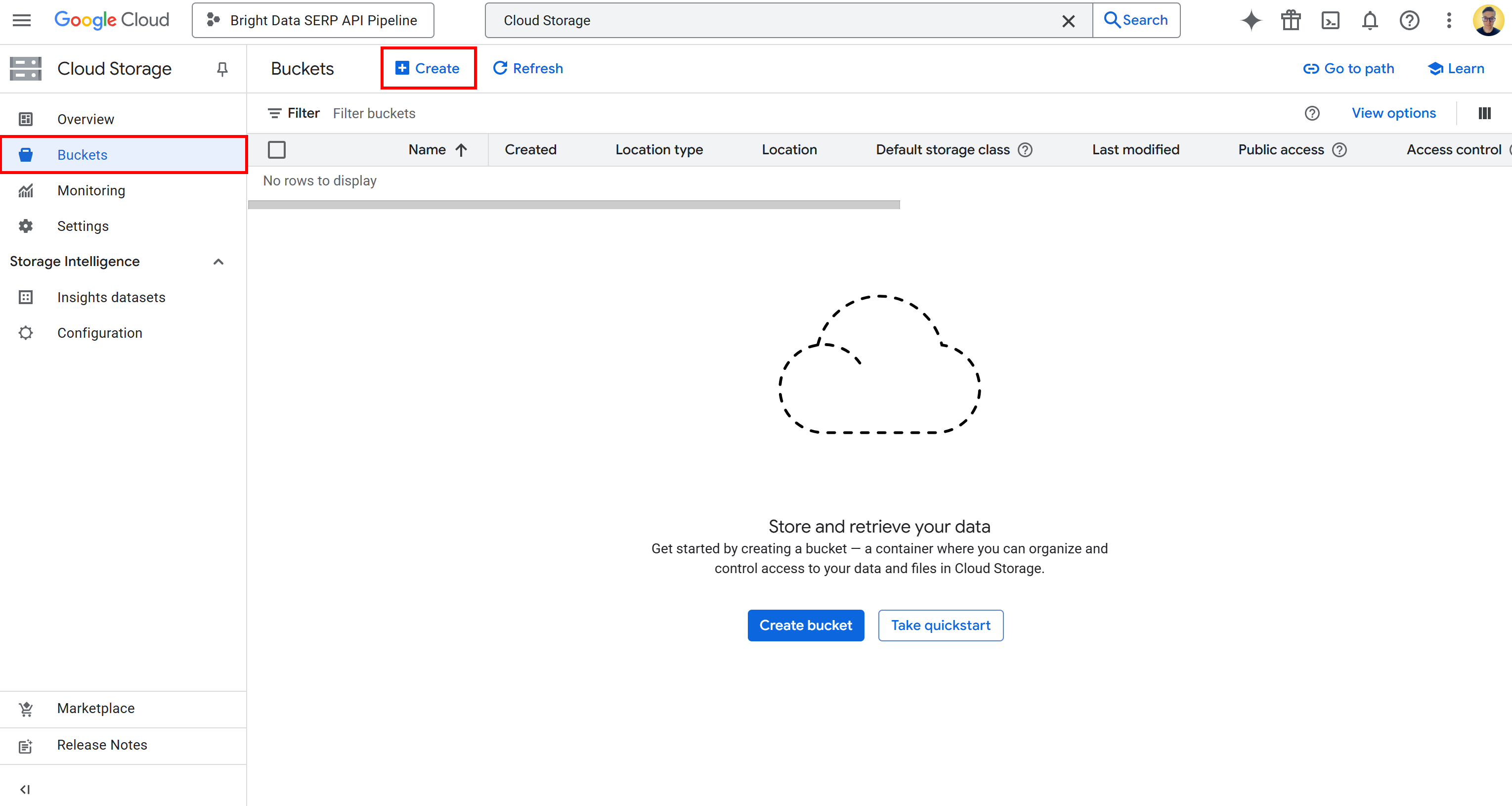
В форме создания ведра:
- Дайте ему глобально уникальное имя, например
bright-data-pipeline-artifacts. - Выберите тип и регион расположения. Для простоты мы рекомендуем выбрать вариант “us (несколько регионов в США)”.
После создания запишите имя ведра, поскольку оно понадобится вам позже при настройке трубопровода. Теперь вы должны увидеть что-то вроде этого:
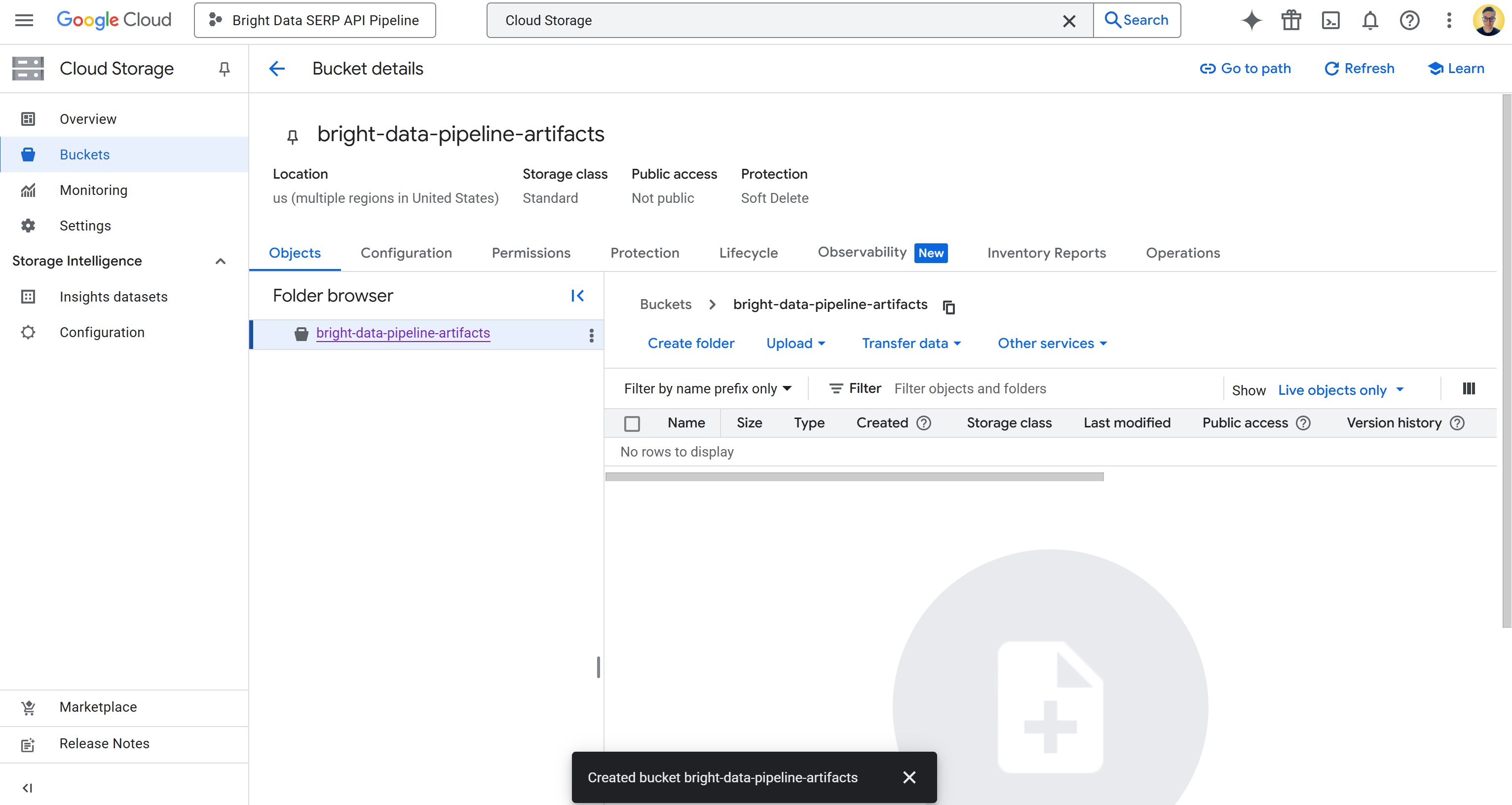
В данном случае имя ведра следующее:
bright-data-pipeline-artifacts . А URI ведра – это:
gs://bright-data-pipeline-artifactsПоскольку вы выбрали мультирегион “us”, вы можете получить доступ к этому ведру через любой поддерживаемый регион us-*. Это включает в себя us-central1, us-east1, …, us-west1… и т. д. Мы рекомендуем установить us-central1.
Теперь вам нужно дать Vertex ИИ разрешение на чтение и запись данных в вашем ведре. Для этого щелкните по названию ведра, чтобы открыть страницу его подробностей, а затем перейдите на вкладку “Разрешения”:
Нажмите кнопку “Предоставить доступ” и добавьте новое правило разрешения следующим образом:

- Принципал:
<YOUR_GC_PROJECT_NUMBER>[email protected] - Роль:
Администратор хранилища
(Важно: Для производственных сред назначайте только минимально необходимые роли. Использование полного доступа “Администратор хранилища” просто для простоты в данной настройке).
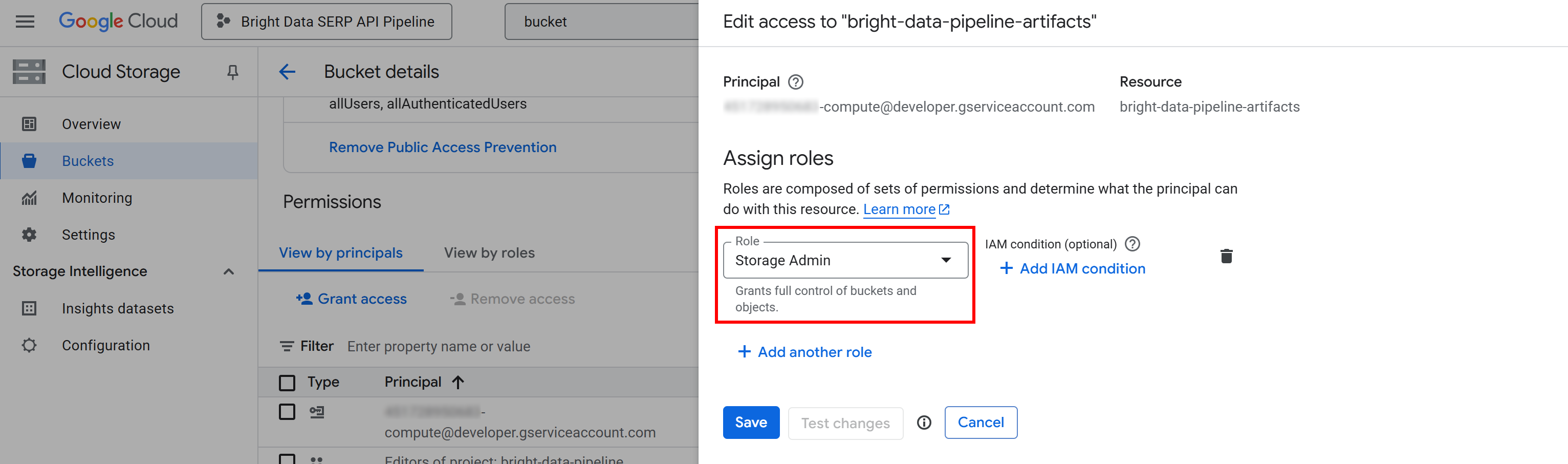
Нажмите “Сохранить”, чтобы подтвердить новую роль, которая предоставляет службе Compute Engine вашего проекта возможность доступа и управления объектами в вашем ведре Cloud Storage.
Без этого разрешения конвейер ИИ Vertex не сможет читать и записывать данные во время выполнения, что приведет к ошибкам 403 Forbidden, как показано ниже:
google.api_core.exceptions.Forbidden: 403 GET https://storage.googleapis.com/storage/v1/b/bright-data-pipeline-artifacts?fields=name&prettyPrint=false: <YOUR_GC_PROJECT_NUMBER>[email protected] не имеет доступа storage.buckets.get к ведру облачного хранилища Google. Разрешение 'storage.buckets.get' запрещено для ресурса (или он может не существовать).Потрясающе! Ведро облачного хранилища Google настроено.
Шаг № 3: Настройка разрешений IAM
Как и в случае с ведром Cloud Storage, вам также необходимо предоставить учетной записи службы Compute Engine вашего проекта соответствующие разрешения IAM.
Эти разрешения позволят ИИ Vertex создавать и управлять заданиями конвейера от вашего имени. Без них конвейер не будет иметь права запускать и контролировать выполнение в рамках проекта Google Cloud.
Чтобы настроить их, найдите в Google Cloud Console раздел “IAM & Admin” и откройте страницу.
Нажмите кнопку “Предоставить доступ”, а затем добавьте следующие две роли к учетной записи службы Compute Engine по умолчанию (т. е. <YOUR_GC_PROJECT_NUMBER>[email protected]):
- “Пользователь учетной записи службы”
- “Пользователь ИИ Vertex”.
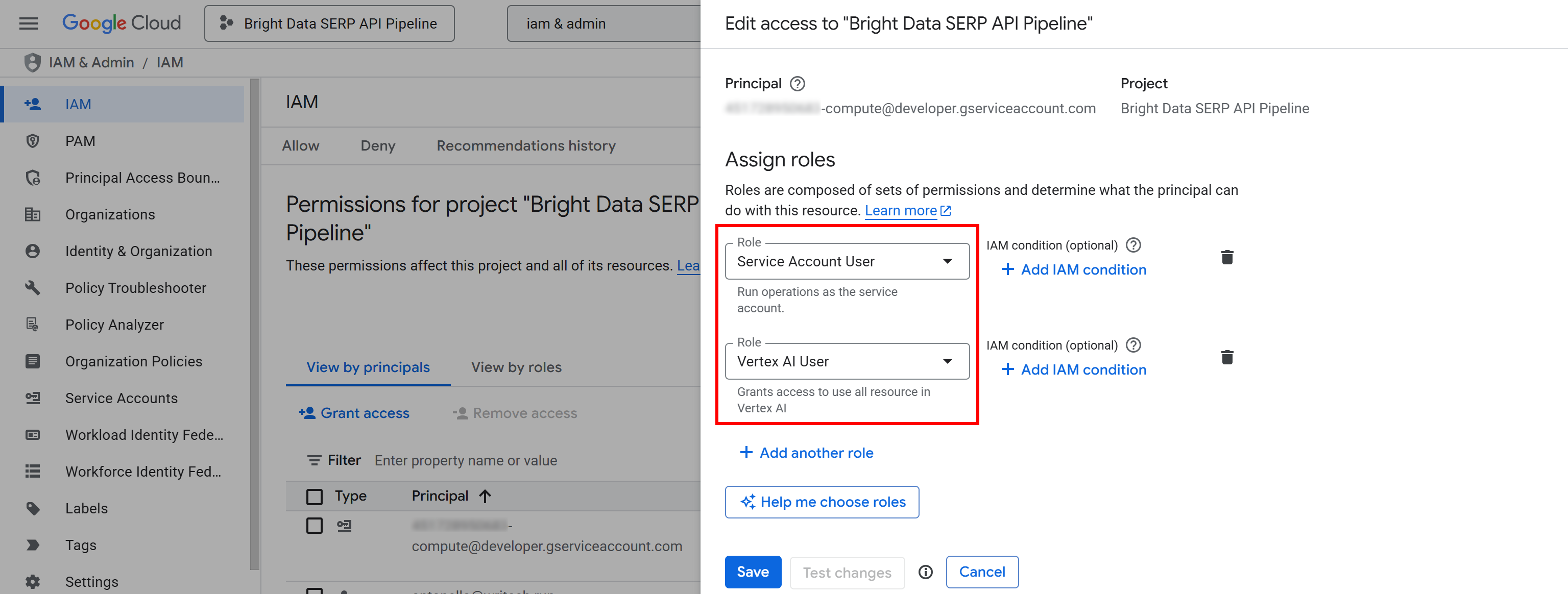
После назначения ролей нажмите кнопку “Сохранить”. Таким образом, ваш конвейер ИИ Vertex сможет использовать вычислительные ресурсы вашего проекта и запускать управляемые рабочие нагрузки.
Короче говоря, это дает Google Cloud понять, что конвейеры ИИ Vertex уполномочены действовать от имени учетной записи службы вычислений вашего проекта. Без этих разрешений при попытке запустить задание конвейера вы столкнетесь с ошибкой 403 Forbidden, как показано ниже:
403 POST https://us-central1-aiplatform.googleapis.com/v1/projects/bright-data-pipeline/locations/us-central1/pipelineJobs?pipelineJobId=XXXXXXXXXXXXXXXXXXXXXXX&%24alt=json%3Benum-encoding%3Dint: Permission 'aiplatform.pipelineJobs.create' denied on resource '//aiplatform.googleapis.com/projects/bright-data-pipeline/locations/us-central1' (or it may not exist). [{'@type':'type.googleapis.com/google.rpc.ErrorInfo','reason': 'IAM_PERMISSION_DENIED', 'domain': 'aiplatform.googleapis.com', 'metadata': {'resource': 'projects/bright-data-pipeline/locations/us-central1', 'permission': 'aiplatform.pipelineJobs.create'}}].Все готово! Теперь IAM настроен и готов к выполнению конвейера ИИ Vertex.
Шаг № 4: Начало работы с Vertex ИИ Workbench
Чтобы упростить разработку, вы будете создавать наш конвейер ИИ Vertex непосредственно в облаке, без необходимости локальной настройки.
В частности, вы будете использовать Vertex ИИ Workbench, полностью управляемую среду разработки на основе JupyterLab в рамках платформы Google Cloud для ИИ Vertex. Она создана для поддержки всех рабочих процессов науки о данных, от создания прототипов до развертывания моделей.
Примечание: Прежде чем приступить к работе, убедитесь, что включен “API блокнотов”, поскольку этот API необходим для работы Vertex ИИ Workbench.
Чтобы получить доступ к Vertex ИИ Workbench, найдите “Vertex ИИ Workbench” в Google Cloud Console и откройте страницу. Далее на вкладке “Экземпляры” нажмите “Создать новый”, чтобы запустить новый экземпляр:
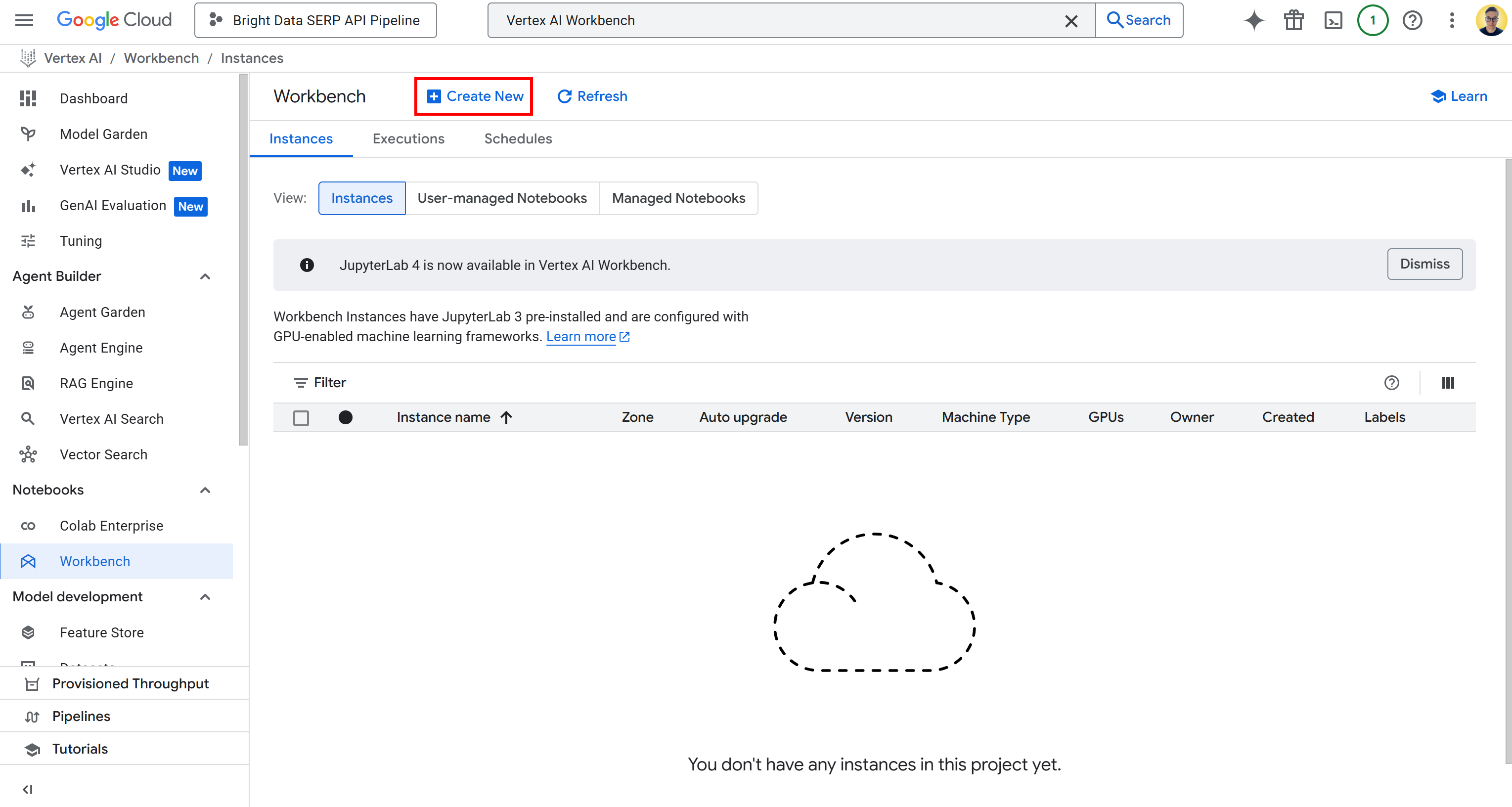
Примечание: Хотя Vertex ИИ Workbench поддерживает Jupyter 4 для новых экземпляров, во всех средах по умолчанию используется JupyterLab 3. Эта версия уже поставляется с предустановленными новейшими библиотеками и драйверами NVIDIA GPU и Intel. Таким образом, для данного руководства следует использовать JupyterLab 3.
В форме создания экземпляра оставьте все значения конфигурации по умолчанию, включая тип машины по умолчанию (он должен быть n1-standard-4). Этой машины более чем достаточно для данного руководства.
Нажмите кнопку “Создать” и имейте в виду, что на инициализацию и запуск экземпляра уйдет несколько минут. Как только он будет готов, вы увидите новую запись в таблице “Экземпляры” со ссылкой “Открыть JupyterLab”. Нажмите на нее:
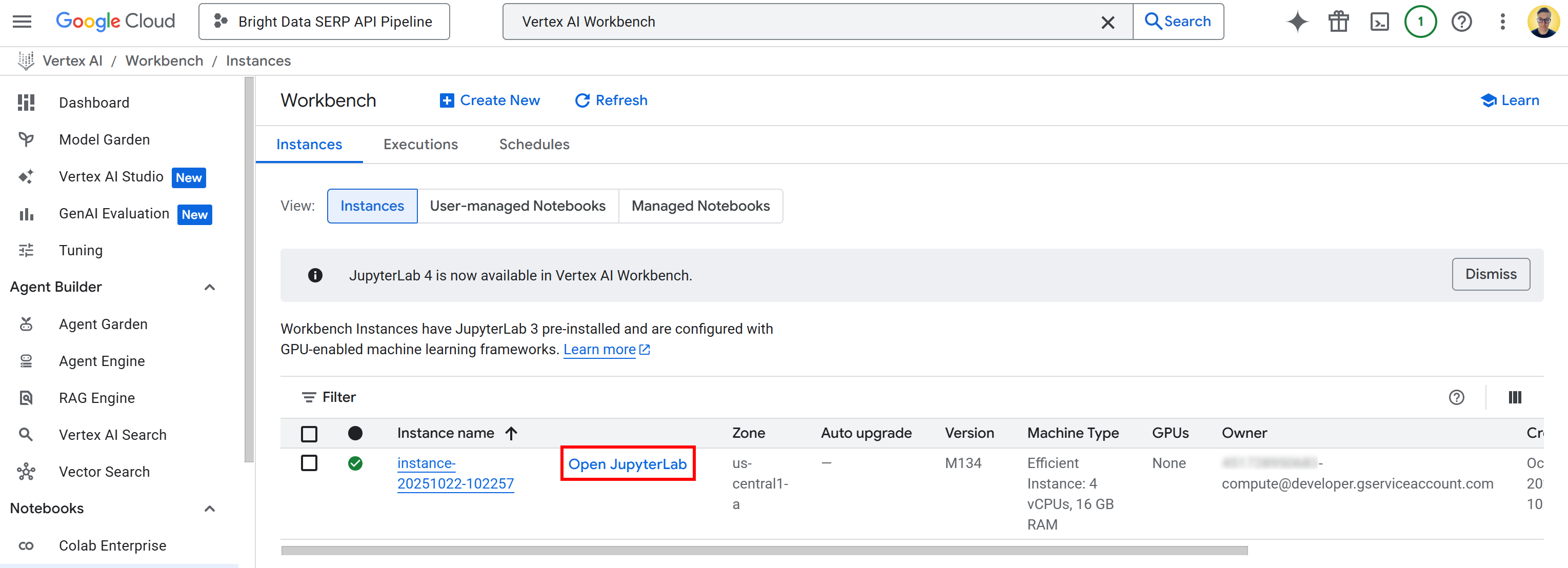
Вы будете перенаправлены в облачную среду JupyterLab, полностью размещенную на Google Cloud:
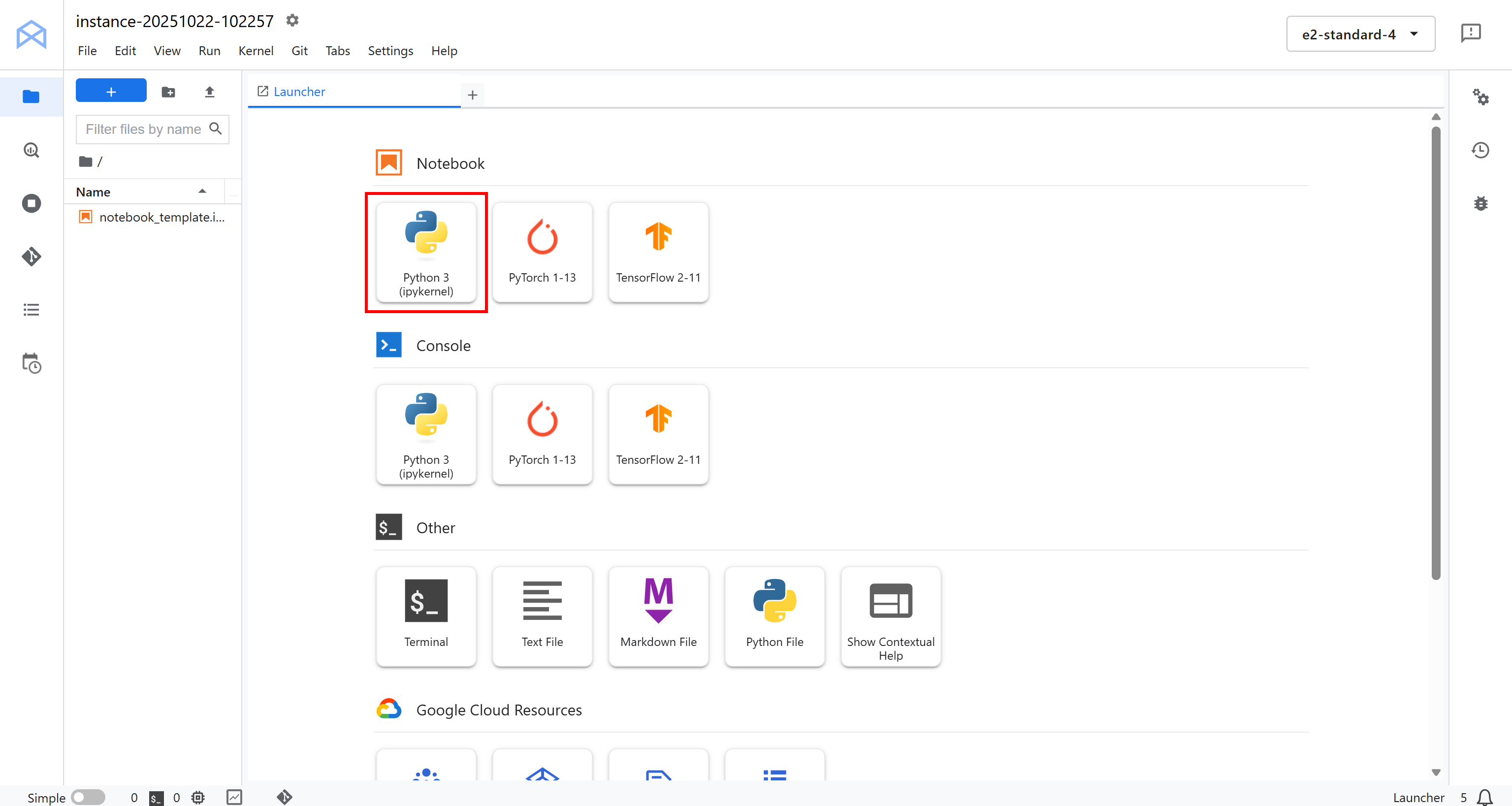
Здесь нажмите “Python 3 (ipykernel)” в разделе “Блокнот”, чтобы создать новый блокнот. Этот блокнот будет служить вам средой разработки для написания и тестирования конвейера ИИ Vertex, интегрированного с Bright Data:

Фантастика! Вы готовы начать кодирование и создание логики для конвейера данных Vertex ИИ.
Шаг № 5: Установка и инициализация необходимых библиотек Python
В своем блокноте добавьте и запустите следующую ячейку, чтобы установить все библиотеки Python, которые понадобятся вам для этого проекта:
!pip install kfp google-cloud-aiplatform google-genai brightdata-sdk --quiet --upgradeЭто может занять несколько минут, так что наберитесь терпения, пока среда все установит.
Здесь описано, что делает каждая библиотека и зачем она нужна:
kfp: Это Kubeflow Pipelines SDK, который позволяет определять, компилировать и запускать конвейеры машинного обучения программно на Python. В комплект входят декораторы и классы для создания компонентов конвейера.google-cloud-aiplatform: Vertex ИИ SDK для Python. Он предоставляет все необходимое для прямого взаимодействия с сервисами ИИ Vertex в Google Cloud, включая обучение моделей, развертывание конечных точек и запуск конвейеров.google-genai: Google Generative ИИ SDK, который позволяет использовать и оркестровать Gemini и другие генеративные модели (также в Vertex ИИ). Это полезно, поскольку конвейер включает задачи LLM.(Помните: Vertex ИИ SDK теперь устарел).brightdata-sdk: Bright Data SDK, используемый для подключения и получения данных в реальном времени через SERP API Bright Data или другие веб-источники данных непосредственно из вашего конвейера.
После установки всех библиотек импортируйте их и инициализируйте Vertex ИИ SDK с помощью следующего кода в выделенной ячейке:
import kfp
из kfp.dsl import component, pipeline, Input, Output, Artifact
из kfp import compiler
из google.cloud import aiplatform
from typing import List
# Замените на секреты вашего проекта
PROJECT_ID = "<ВАШ_GC_PROJECT_ID>"
REGION = "<ВАШ_РЕГИОН>" # (например, "us-central1")
BUCKET_URI = "<ВАШ_BUCKET_URI>" # (например, "gs://bright-data-pipeline-artifacts")
# Инициализация SDK Vertex ИИ
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=BUCKET_URI)Функция aiplatform.init() настраивает среду Python для взаимодействия с ИИ Vertex. Она устанавливает проект, регион и ведро хранения, чтобы все последующие операции с ИИ Vertex, такие как создание конвейеров, обучение заданий или развертывание моделей, автоматически использовали правильный контекст.
Короче говоря, эта единственная строка кода соединяет сеанс работы с ноутбуком с проектом Google Cloud и указывает Vertex ИИ, где хранить артефакты конвейера и временные данные. Отлично!
Шаг № 6: Определите компонент извлечения запросов
Помните, что конвейер ИИ Vertex строится из компонентов, где компонент – это просто функция Python, выполняющая одну конкретную задачу. Как объяснялось ранее, этот конвейер будет состоять из трех компонентов.
Давайте начнем с первого – компонента extract_queries!
Компонент extract_queries:
- Принимает на вход текст для проверки фактов.
- Использует модель Gemini (через библиотеку
google-genai) для создания списка поисковых запросов, которые могут быть использованы в Google и помогут проверить фактические утверждения в этом тексте. - Возвращает этот список в виде массива Python
(List[str]).
Реализуйте это следующим образом:
@component(
base_image="python:3.10",
packages_to_install=["google-genai"],
)
def extract_queries(
input_text: str,
проект: str,
location: str,
) -> List[str]:
from google import genai
from google.genai.types import GenerateContentConfig, HttpOptions
from typing import List
импортировать json
# Инициализация Google Gen ИИ SDK с интеграцией Vertex
client = genai.Client(
vertexai=True,
project=project,
location=location,
http_options=HttpOptions(api_version="v1")
)
# Выходная схема, которая представляет собой массив строк
response_schema = {
"type": "ARRAY",
"items": {
"type": "STRING"
}
}
# Подсказка для экстрактора запросов
prompt = f"""
Вы - профессиональный специалист по проверке фактов. Ваша задача - прочитать следующий текст и извлечь из него
список конкретных поисковых запросов, которые можно найти в Гугле.
для проверки основных фактических утверждений.
Верните *только* список строк на языке Python, и ничего больше.
Пример:
Ввод: "Эйфелева башня, построенная в 1889 году Гюставом Эйфелем, имеет высоту 300 метров".
Выходные данные: ["когда была построена Эйфелева башня", "кто построил Эйфелеву башню", "какой высоты Эйфелева башня"].
Вот текст для проверки фактов:
---
"{input_text}"
---
"""
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=GenerateContentConfig(
# Заставьте модель возвращать массив строк в формате JSON
response_mime_type="application/json",
response_schema=response_schema,
),
)
# В 'response.text' будет надежно содержаться JSON-строка, соответствующая схеме (например, '["query_1", ..., "query_n"]')
query_list: List[str] = json.loads(response.text.strip())
return query_listПомните, что компоненты KFP должны быть самодостаточными. Это означает, что все импорты должны быть объявлены внутри функции компонента, а не глобально.
Обратите внимание, что параметры vertexai=True, project=project и location=location в genai.Client() необходимы для подключения клиента google-genai к вашему окружению ИИ Vertex. Они гарантируют, что настроенная модель будет работать в том же регионе и проекте, что и ваш конвейер.
Что касается выбора модели, то здесь следует использовать Gemini 2.5 Flash, поскольку она легкая и быстрая. В любом случае, при необходимости вы можете установить другую модель Gemini для более высокой точности.
Один компонент создан, осталось еще два!
Шаг № 7: Создание компонента SERP API Context Retriever на базе веб-поиска
Теперь, когда вы составили список запросов, пригодных для использования в Google, пришло время поискать контекст в Интернете. Для этого воспользуйтесь SERP API от Bright Data, который позволяет программно соскребать результаты поиска (по умолчанию Google) в структурированном и масштабируемом виде.
Самый простой способ получить доступ к SERP API из Python – это официальный SDK Bright Data с открытым исходным кодом. Эта библиотека предоставляет вам простые методы для вызова продуктов Bright Data, включая SERP API. Подробнее о ней можно узнать из документации.
В частности, компонент fetch_web_search_context:
- Принимает список поисковых запросов, сформированный на предыдущем шаге.
- Использует Bright Data SDK для параллельного вызова SERP API для каждого запроса.
- Получает результаты поиска (по умолчанию от Google).
- Сохраняет все результаты в виде артефакта JSON – файла, который могут использовать другие компоненты конвейера.
Создайте такой компонент в специальной ячейке блокнота следующим образом:
@component(
base_image="python:3.10",
packages_to_install=["brightdata-sdk"],
)
def fetch_web_search_context(
запросы: List[str],
api_key: str,
output_file: Output[Artifact],
):
"""
Принимает список запросов, выполняет поиск по каждому из них с помощью Bright Data SDK,
и записывает все результаты в виде артефакта в формате JSON.
"""
from brightdata import bdclient
import json
# Инициализация клиента Bright Data SDK
client = bdclient(api_token=api_key)
# Вызов SERP API по входным запросам
результаты = client.search(
queries,
data_format="markdown"
)
# Запись результатов в файл артефакта
with open(output_file.path, "w") as f:
json.dump(results, f)Обратите внимание, что SERP API был настроен на возврат содержимого в формате Markdown, который идеально подходит для включения в LLM.
Кроме того, поскольку результат работы этого компонента может быть довольно большим, лучше всего хранить его в виде артефакта. Артефакты хранятся в вашем ведре Google Cloud Storage и позволяют компонентам конвейера ИИ Vertex эффективно передавать данные друг другу, не перегружая память и не превышая лимиты на передачу данных.
Вот и все! Благодаря возможностям веб-поиска Bright Data у вас теперь есть поисковый контекст с поддержкой Google, готовый к использованию в качестве исходных данных для следующего компонента, где LLM будет выполнять проверку фактов.
Шаг № 8: Реализация компонента проверки фактов
Как и в случае с компонентом извлечения запросов, этот шаг также включает вызов LLM. Однако вместо генерации запросов этот компонент использует результаты веб-поиска, собранные на предыдущем этапе, в качестве контекстного доказательства для проверки фактов исходного входного текста.
По сути, он запускает рабочий процесс в стиле RAG на основе SERP, где найденный веб-контент направляет процесс проверки модели.
В новой ячейке блокнота определите компонент fact_check_with_web_search_context следующим образом:
@component(
base_image="python:3.10",
packages_to_install=["google-genai"],
)
def fact_check_with_web_search_context(
input_text: str,
web_search_context_file: Input[Artifact],
проект: str,
location: str,
) -> str:
import json
из google import genai
# Загрузите контекст веб-поиска из артефакта
with open(web_search_context_file.path, "r") as f:
web_search_context = json.load(f)
client = genai.Client(
vertexai=True,
project=project,
location=location
)
prompt = f"""
Вы - ИИ, проверяющий факты. Сравните оригинальный текст с поисковым контекстом JSON
и подготовьте отчет о проверке фактов в формате Markdown.
[Original Text]
"{input_text}"
[Контекст веб-поиска]
"{json.dumps(web_search_context)}"
"""
response = client.models.generate_content(
model="gemini-2.5-pro",
contents=prompt
)
return response.textЭта задача более сложная и требует рассуждений на основе нескольких источников доказательств. Поэтому лучше использовать более мощную модель, например Gemini 2.5 Pro.
Отлично! Теперь вы определили все три компонента, из которых состоит ваш конвейер ИИ Vertex.
Шаг № 9: Определение и компиляция конвейера
Соедините все три компонента в единый конвейер Kubeflow. Каждый компонент будет выполняться последовательно, причем выход одного шага станет входом следующего.
Вот как определить конвейер:
@pipeline(
name="bright-data-fact-checker-pipeline",
description="Получает контекст SERP для проверки фактов в текстовом документе."
)
def fact_check_pipeline(
input_text: str,
bright_data_api_key: str,
проект: str = PROJECT_ID,
location: str = REGION,
):
# Шаг 1: Извлечение из входного текста запросов, пригодных для проверки в Google
step1 = extract_queries(
input_text=input_text,
project=project,
location=локация
)
# Шаг 2: Получение результатов SERP Bright Data по поисковым запросам
step2 = fetch_web_search_context(
queries=step1.output,
bright_data_api_key=bright_data_api_key
)
# Шаг 3: Выполните проверку фактов, используя контекст веб-поиска, полученный ранее
step3 = fact_check_with_web_search_context(
input_text=input_text,
web_search_context_file=step2.outputs["output_file"],
project=project,
location=location
) По сути, эта функция объединяет три компонента, которые вы создали ранее. Она начинает с генерации запросов на проверку фактов, затем получает результаты поиска по каждому запросу с помощью SERP API Bright Data и, наконец, запускает модель Gemini для проверки утверждений на основе собранных доказательств.
Далее необходимо скомпилировать конвейер в спецификацию JSON, которую сможет выполнить ИИ Vertex:
compiler.Compiler().compile(
pipeline_func=fact_check_pipeline,
package_path="fact_check_pipeline.json"
)Эта команда преобразует ваше определение трубопровода на языке Python в файл спецификации трубопровода в формате JSON под названием fact_check_pipeline.json.
Этот JSON-файл представляет собой чертеж, которому доверяет Vertex ИИ Pipelines, чтобы понять, как организовать рабочий процесс. В нем описывается каждый компонент, его входы и выходы, зависимости, образы контейнеров и порядок выполнения.
При запуске этого JSON-файла в Vertex ИИ Google Cloud автоматически создает инфраструктуру, запускает каждый компонент в нужном порядке и обрабатывает передачу данных между этапами. Конвейер готов!
Шаг № 10: Запуск конвейера
Предположим, вы хотите протестировать конвейер ИИ Vertex на заведомо ложном утверждении, таком как:
“Париж – столица Германии, в которой в качестве валюты используется иена”.
Добавьте следующую ячейку в свой блокнот Jupyter. Эта ячейка определяет логику запуска конвейера:
TEXT_TO_CHECK = """
Париж - столица Германии, в которой в качестве валюты используется иена.
"""
# Замените на свой ключ API Bright Data
BRIGHT_DATA_API_KEY = "<ВАШ_BRIGHT_DATA_API_KEY>"
print("Запуск задания конвейера...")
# Определите задание конвейера
job = aiplatform.PipelineJob(
display_name="fact-check-pipeline-run",
template_path="fact_check_pipeline.json",
pipeline_root=BUCKET_URI,
parameter_values={
"input_text": TEXT_TO_CHECK,
"bright_data_api_key": BRIGHT_DATA_API_KEY
}
)
# Запуск задания
job.run()
print("nЗадание отправлено! Вы можете просмотреть его ход в пользовательском интерфейсе ИИ Vertex.")Этот код создает новое задание Vertex ИИ Pipeline, указывая JSON трубопровода, скомпилированный ранее(fact_check_pipeline.json), ваше хранилище bucket в качестве корня трубопровода и параметры, необходимые для этого конкретного запуска (например, входной текст для проверки и ваш ключ API Bright Data).
После запуска этой ячейки ИИ Vertex автоматически организует весь конвейер в облаке.
Примечание по безопасности: в этом примере для простоты ключ API Bright Data жестко закодирован непосредственно в блокноте, но это небезопасно для производственных сред. В реальной среде следует хранить и извлекать такие важные учетные данные, как ключи API, с помощью Google Cloud Secret Manager, чтобы избежать случайного раскрытия (например, в журналах).
Чтобы запустить конвейер, выделите все ячейки и нажмите кнопку “▶” в блокноте Jupyter. Вы получите этот результат на последней ячейке:
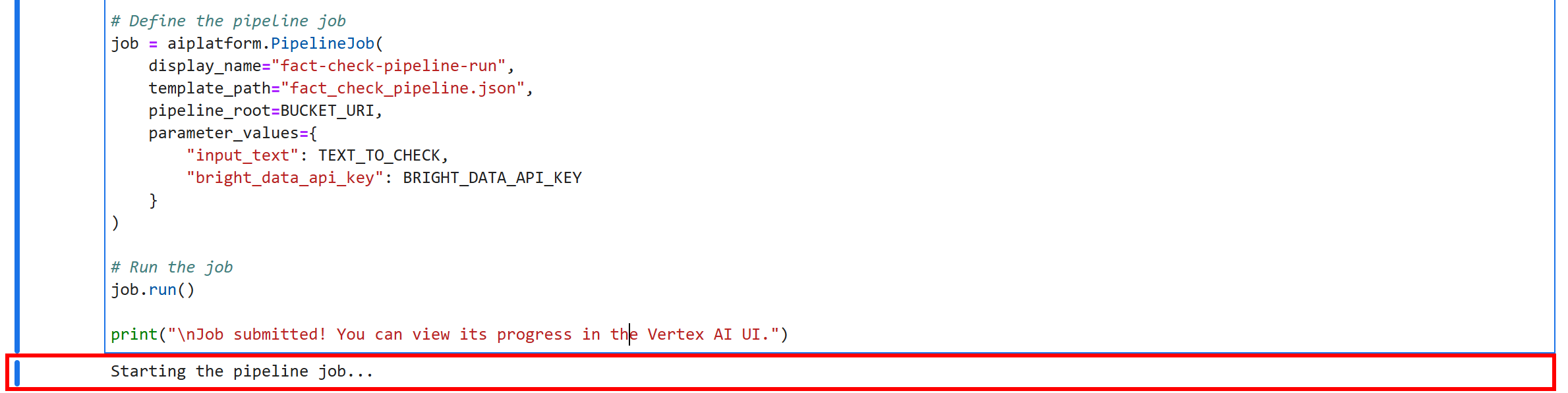
Это означает, что ваш конвейер проверки фактов Vertex ИИ успешно работает. Вот это да!
Шаг № 11: Мониторинг выполнения конвейера
Чтобы проверить состояние задания конвейера, перейдите на страницу конвейеров ИИ Vertex в облачной консоли Google для вашего проекта:
https://console.cloud.google.com/vertex-ai/pipelines?project={PROJECT_ID}Таким образом, в данном случае URL-адрес следующий:
https://console.cloud.google.com/vertex-ai/pipelines?project=bright-data-pipelineВставьте URL-адрес в браузер, и вы увидите страницу, похожую на эту:
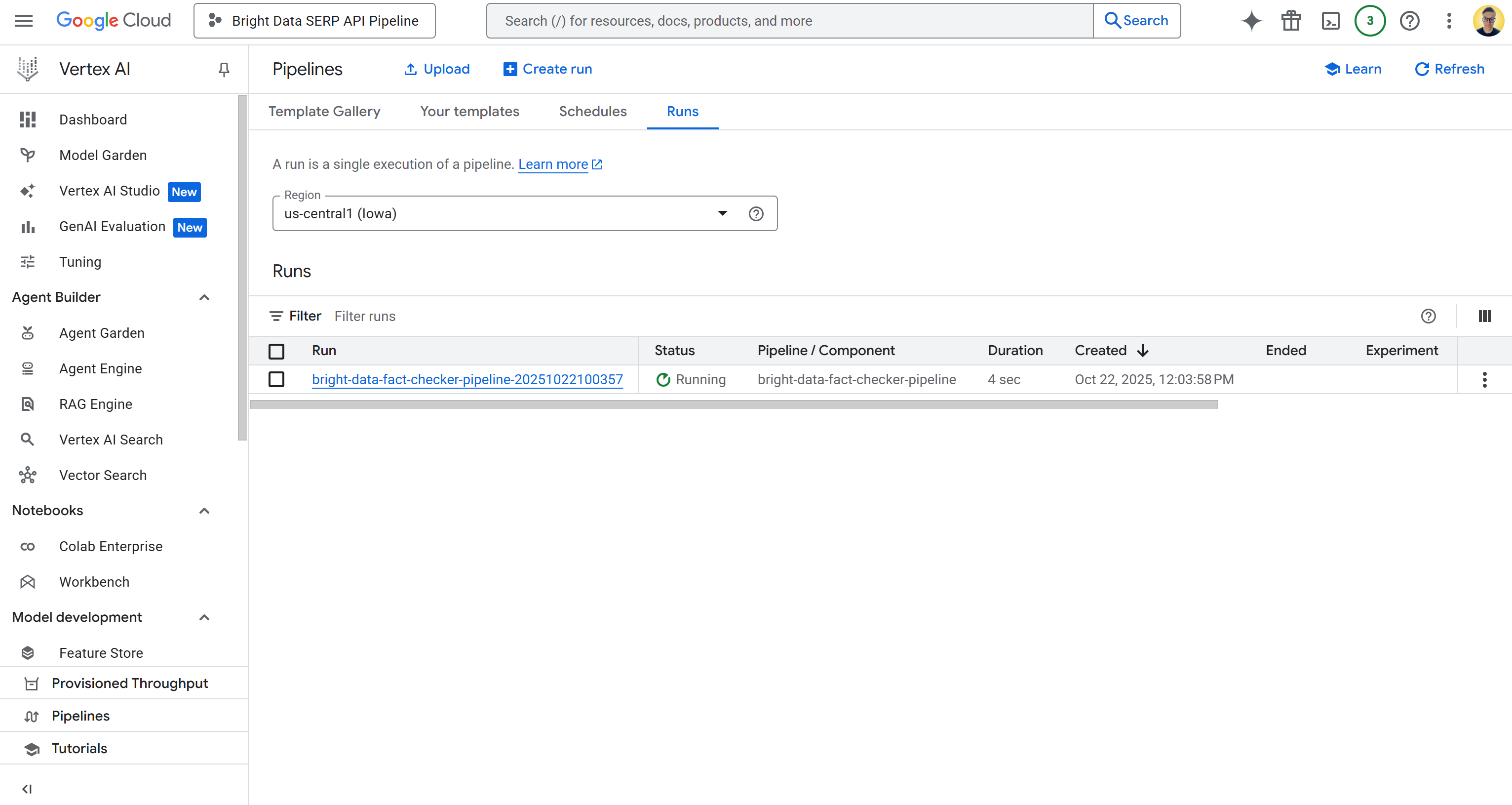
Щелкните по первой записи в таблице “Runs”, чтобы открыть страницу выполнения задания трубопровода:
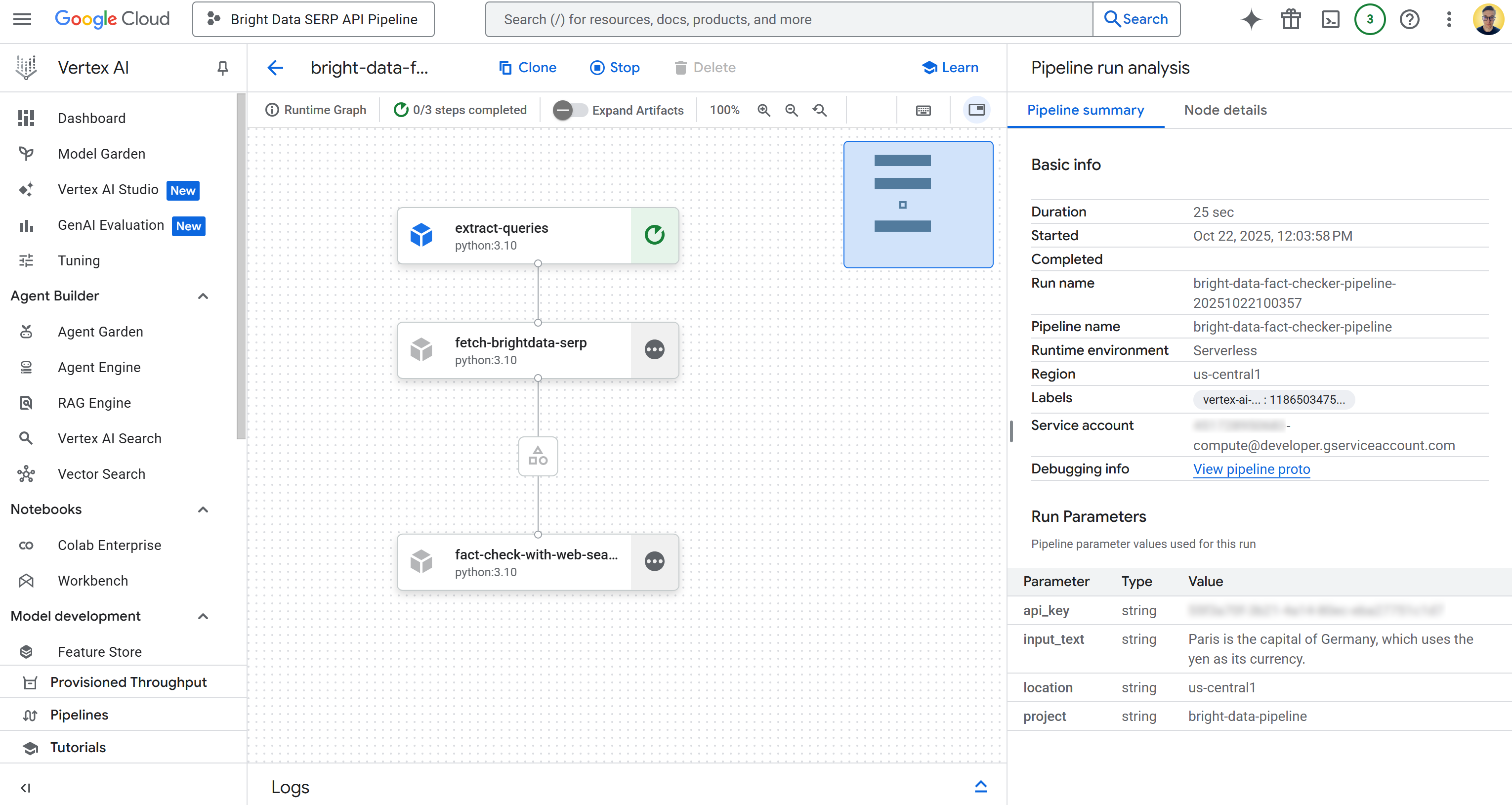
Здесь вы можете наглядно увидеть компоненты, из которых состоит ваш трубопровод. Вы также можете проверить состояние каждого узла, просмотреть подробные журналы и проследить за потоком данных от начала до конца конвейера в процессе его выполнения.
Шаг № 12: Изучите выходные данные
После завершения работы конвейера на каждом узле появится отметка, означающая успешное завершение:
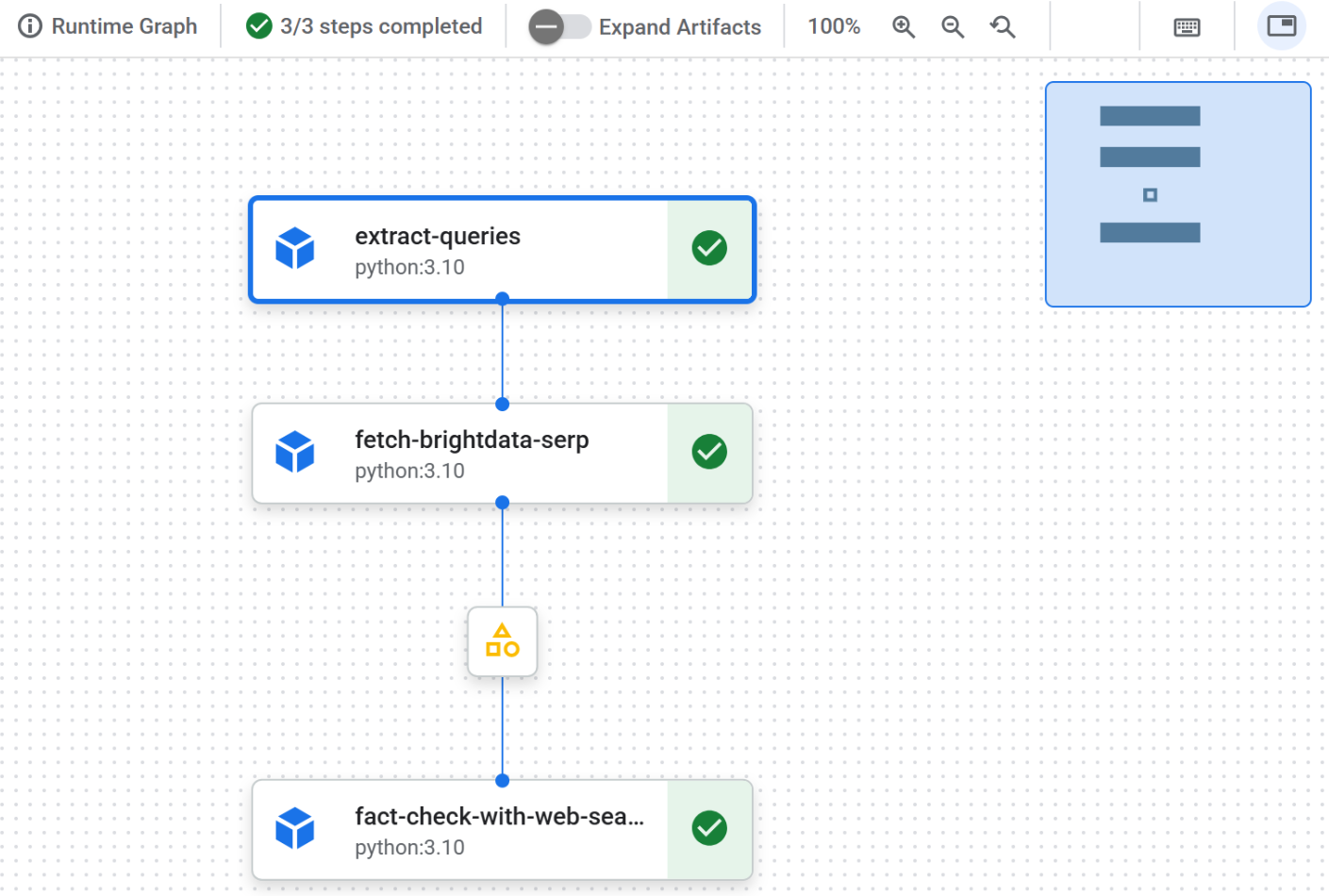
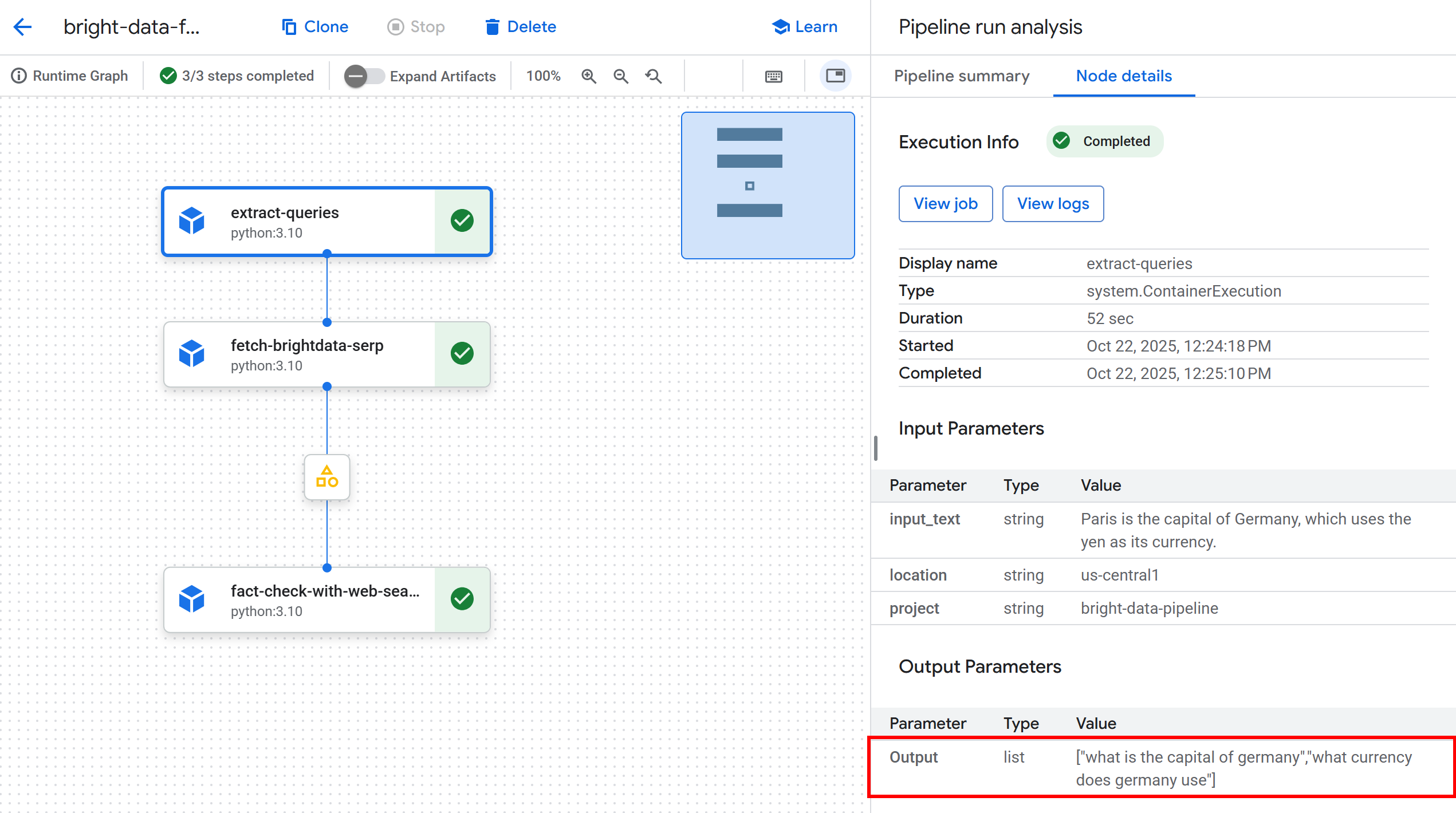
Щелкните по первому узлу, чтобы просмотреть извлеченные из входного текста запросы, пригодные для использования в Google. В этом примере были получены следующие запросы:
"какая столица Германии""какая валюта используется в Германии".
Эти запросы отлично подходят для проверки фактических утверждений во входном тексте:
Далее щелкните на узле артефакта между вторым и третьим узлом. Вы получите ссылку на JSON-файл, сохраненный в настроенном ведре облачного хранилища Google (в данном случае bright-data-pipeline-artifacts).
Вы также можете получить доступ к нужной странице напрямую, перейдя к ведру в Cloud Console:
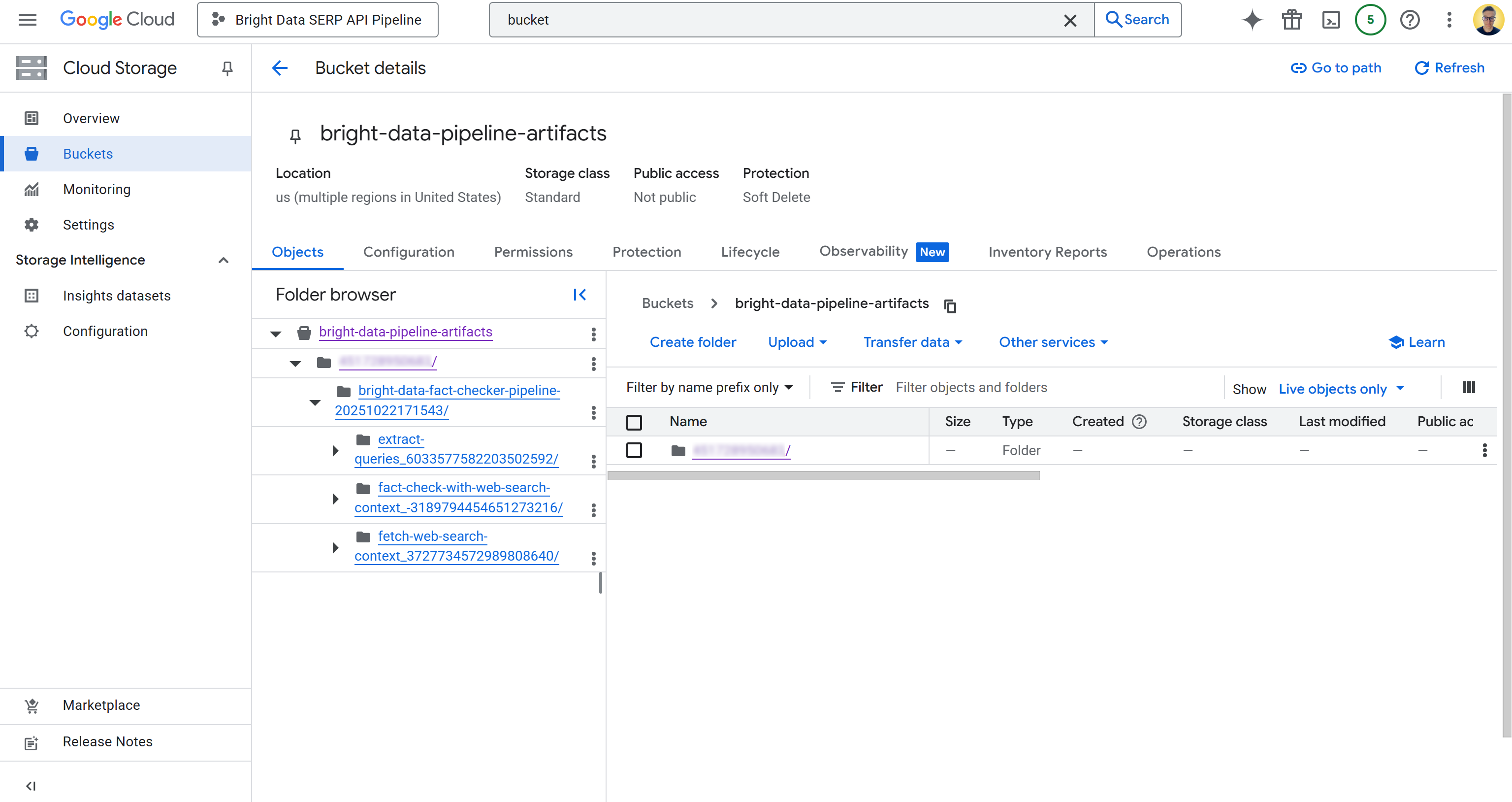
Внутри ведра вы увидите папку для каждого компонента. Если говорить подробнее, то папка компонента fetch_web_search_context содержит JSON-файл с контекстом веб-поиска, полученным через SERP API, который хранится в виде массива строк в формате Markdown:
Если вы загрузите и откроете этот файл, то увидите примерно следующее:

Это содержимое – представление в формате Markdown поисковых запросов, полученных для каждого идентифицированного поискового запроса.
Вернувшись в пользовательский интерфейс конвейера ИИ Vertex, нажмите на узел вывода, чтобы просмотреть общие результаты:
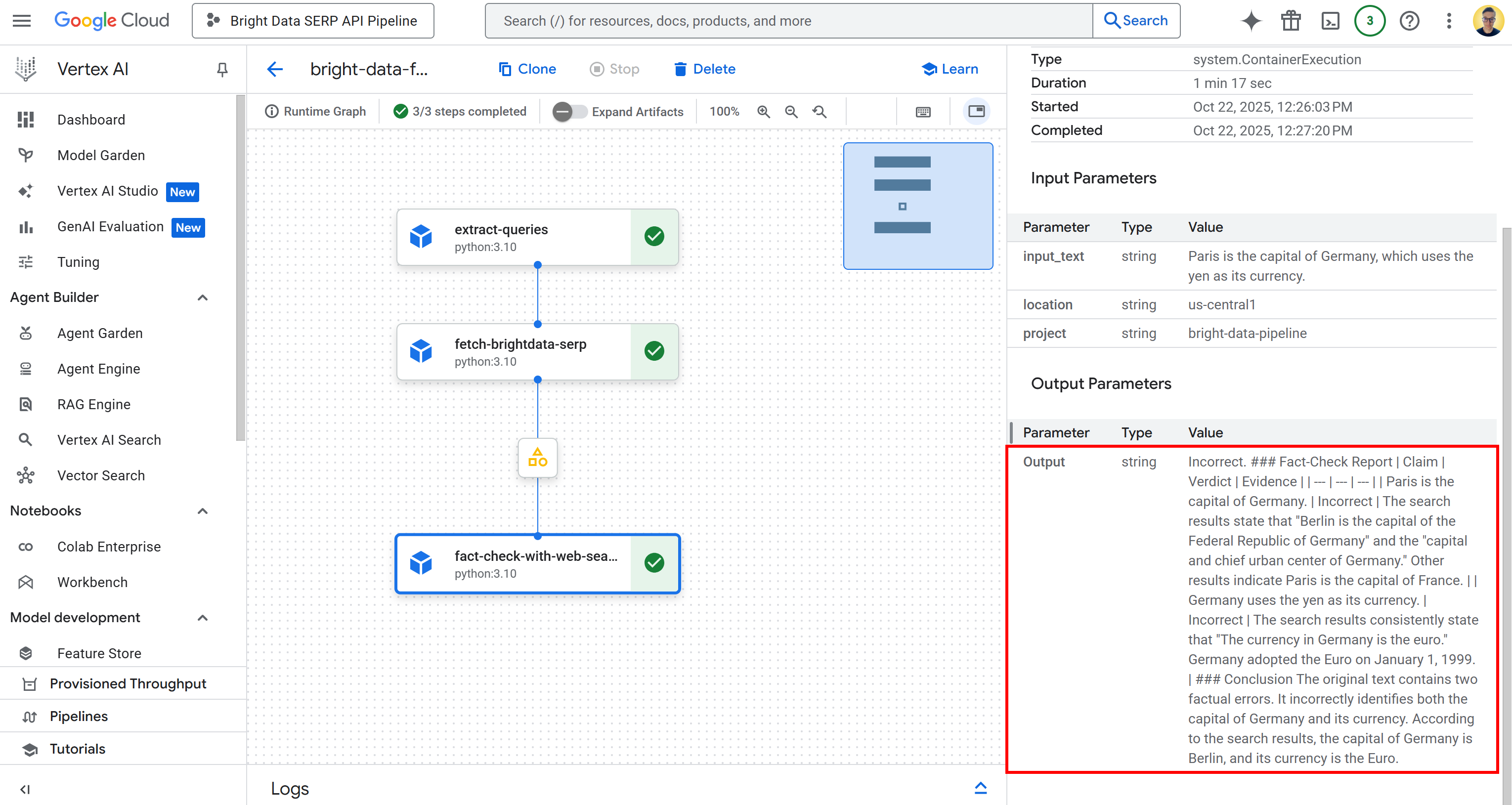
Как вы можете видеть, результатом является подробный отчет о проверке фактов в формате Markdown. Этот же результат сохраняется в файле executor_output.json в папке bucket для запуска конвейера. Загрузите его и откройте в IDE, например Visual Studio Code, чтобы просмотреть его:
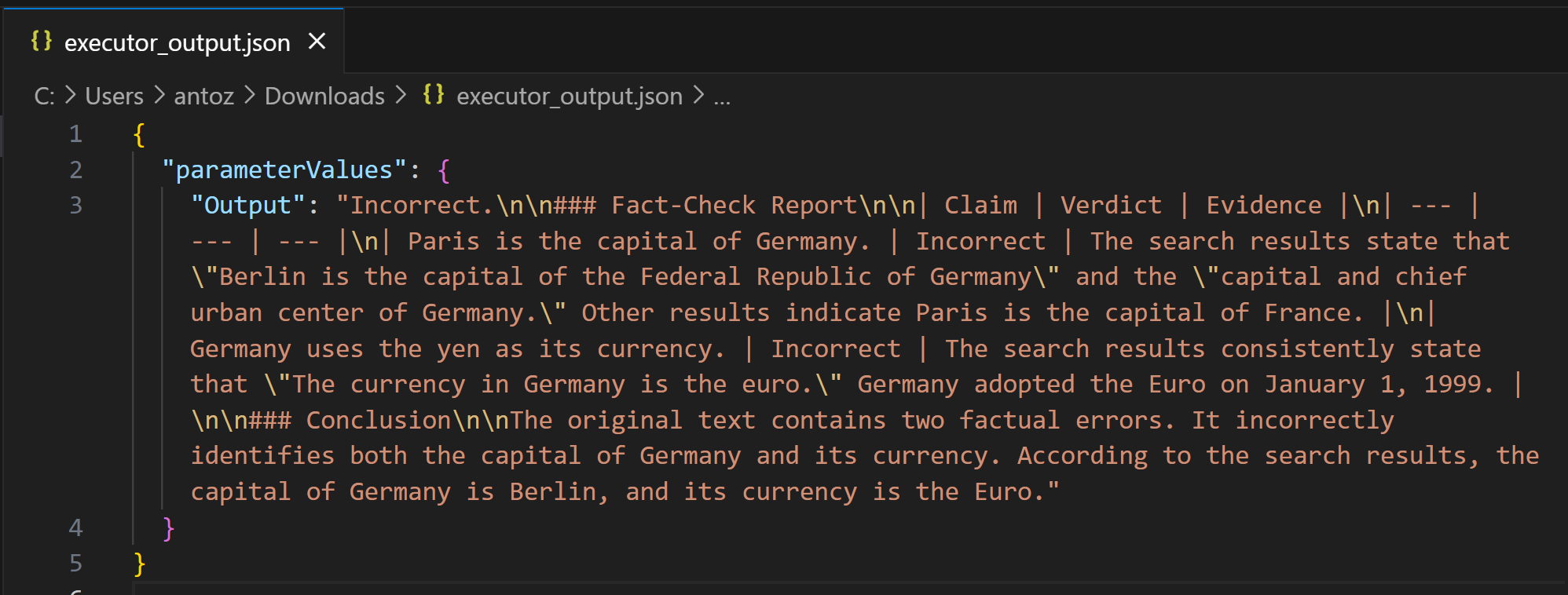
Скопируйте строку Markdown в файл .md (например, report.md), чтобы просмотреть ее более наглядно:
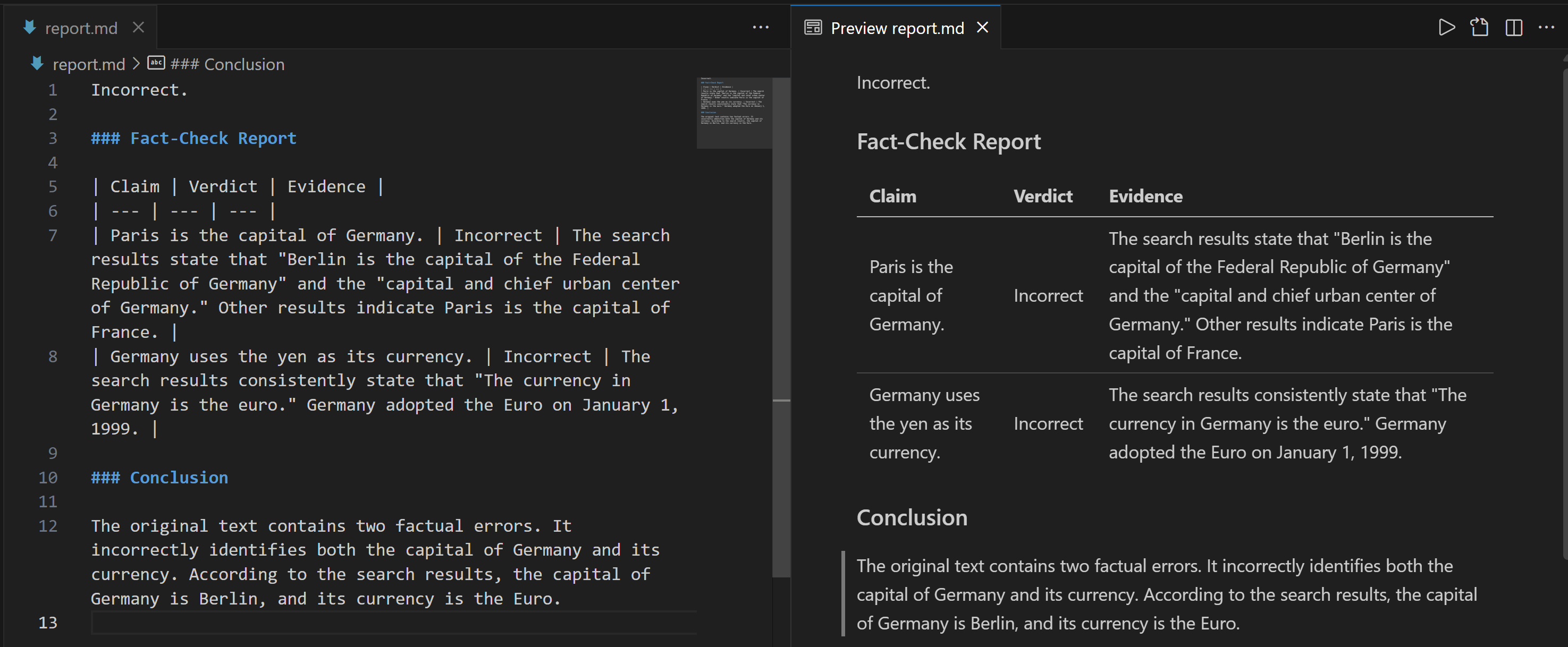
В отчете содержится подробная информация о том, какие части входного утверждения были неверными и каковы проверенные факты.
И вуаля! Это демонстрирует возможности интеграции веб-поиска Bright Data для извлечения контекстной информации в конвейере ИИ Vertex на основе RAG.
Следующие шаги
Не забывайте, что это был лишь простой пример, демонстрирующий возможность использования данных веб-поиска Bright Data в конвейере ИИ Vertex. В реальных сценариях эти компоненты, скорее всего, будут частью гораздо более длинного и сложного конвейера.
Входные данные могут поступать из различных источников, таких как деловые документы, внутренние отчеты, базы данных, файлы и т. д. Кроме того, рабочий процесс может включать множество других этапов и не обязательно закончится только подготовкой отчета о проверке фактов.
Заключение
В этой статье вы узнали, как использовать SERP API от Bright Data для получения контекста веб-поиска в рамках конвейера ИИ Vertex. Представленный здесь рабочий процесс ИИ идеально подходит для тех, кто хочет создать программный, надежный конвейер проверки фактов для обеспечения точности своих данных.
Чтобы создать аналогичные передовые рабочие процессы ИИ, изучите весь спектр решений для получения, проверки и преобразования живых веб-данных с помощью инфраструктуры ИИ Bright Data.
Создайте бесплатную учетную запись Bright Data сегодня и начните экспериментировать с нашими инструментами для работы с веб-данными, готовыми к ИИ!





