

В этом учебном пособии вы узнаете:
- Обзор RAG и его механизмов
- Преимущества интеграции данных SERP в GPT-4o с помощью RAG
- Как реализовать чатбота на Python RAG, используя модели OpenAI GPT и данные SERP.
Давайте погрузимся!
Что такое RAG?
RAG, сокращение от Retrieval-Augmented Generation, – это подход ИИ, который сочетает поиск информации с генерацией текста. В рабочем процессе RAG приложение сначала извлекает релевантные данные из внешних источников – например, документов, веб-страниц или баз данных. Затем оно передает данные моделям ИИ, чтобы те могли генерировать более релевантные контексту ответы.
RAG расширяет возможности больших языковых моделей (LLM), таких как GPT, позволяя им получать доступ к актуальной информации и ссылаться на нее помимо исходных данных обучения. Такой подход является ключевым в сценариях, где требуется точная и контекстно-зависимая информация, поскольку он повышает качество и точность ответов, генерируемых ИИ.
Зачем кормить модели ИИ данными SERP
Датой отсечения знаний для GPT-4o является октябрь 2023 года, что означает отсутствие доступа к событиям и информации, появившимся после этого времени. Однако модели GPT-4o могут получать данные из Интернета в режиме реального времени с помощью интеграции поиска Bing. Это помогает им предлагать более актуальную информацию.
Но что делать, если вы хотите, чтобы модель ИИ использовала конкретные источники данных или предпочитала более надежные поисковые системы? Вот тут-то на помощь и приходит RAG!
В частности, передача данных SERP(Search Engine Results Page) моделям ИИ с помощью RAG – отличный способ получить более качественные ответы. Такой подход особенно полезен для задач, требующих актуальной информации или специальных знаний.
Одним словом, передача данных из высокорейтинговых результатов поиска в GPT-4o или GPT-4o mini приводит к получению подробных, точных и контекстуально насыщенных ответов.
RAG с данными SERP с GPT-моделями с помощью Python: Пошаговое руководство
В этом руководстве вы узнаете, как создать чат-бота RAG с использованием GPT-моделей OpenAI. Идея заключается в том, чтобы собрать текст с самых популярных страниц Google по определенному поисковому запросу и использовать его в качестве контекста для GPT-запроса.
Теперь самая большая проблема – это сбор данных SERP. Причина в том, что большинство поисковых систем оснащены продвинутыми антибот-решениями для предотвращения автоматического доступа к их страницам. За подробным руководством обратитесь к нашему руководству о том, как скреативить Google на Python.
Чтобы упростить процесс скрапинга, мы будем использовать SERP API от Bright Data:
Этот премиум-парсер позволяет легко извлекать SERP-страницы из Google, DuckDuckGo, Bing, Yandex, Baidu и других поисковых систем с помощью простых HTTP-запросов.
Затем мы извлечем текстовые данные из возвращенных URL-адресов с помощью безголового браузера. Затем мы будем использовать эту информацию в качестве контекста для модели GPT в рабочем процессе RAG. Если вы хотите получить онлайн-данные непосредственно с помощью ИИ, прочитайте нашу статью о веб-скрейпинге с помощью ChatGPT.
Если вам не терпится изучить код или вы хотите иметь его под рукой, пока будете выполнять следующие шаги, клонируйте репозиторий GitHub, поддерживающий эту статью:
git clone https://github.com/Tonel/rag_gpt_serp_scrapingСледуйте инструкциям в файле README.md, чтобы установить зависимости проекта и запустить его.
Помните, что подход, представленный в этой статье, может быть легко адаптирован к любой другой поисковой системе или LLM.
Примечание: Это руководство относится к Unix и macOS. Если вы являетесь пользователем Windows, вы все равно можете следовать этому руководству, используя подсистему Windows для Linux(WSL).
Шаг #1: Инициализация проекта Python
Убедитесь, что на вашей машине установлен Python 3. В противном случае скачайте и установите его.
Создайте папку для вашего проекта и введите ее в терминале:
mkdir rag_gpt_serp_scraping
cd rag_gpt_serp_scrapingПапка rag_gpt_serp_scraping будет содержать ваш проект Python RAG.
Затем загрузите каталог проекта в вашу любимую Python IDE. Подойдет PyCharm Community Edition или Visual Studio Code с расширением Python.
Внутри rag_gpt_serp_scraping добавьте пустой файл app.py. В нем будет содержаться логика скрапинга и RAG.
Затем инициализируйте виртуальную среду Python в каталоге проекта:
python3 -m venv envАктивируйте виртуальную среду командой ниже:
source ./env/bin/activateПотрясающе! Теперь вы полностью готовы к работе.
Шаг №2: Установка необходимых библиотек
Зависимости, используемые в этом проекте Python RAG, основанном на моделях GPT, следующие:
python-dotenv: для загрузки переменных окружения из файла .env. Она будет использоваться для безопасного управления конфиденциальными учетными данными, такими как учетные данные Bright Data и ключи OpenAI API.requests: Для выполнения HTTP-запросов к SERP API Bright Data. Для получения дополнительной информации см. наше руководство по использованию прокси с помощью Requests.langchain-community: Это часть фреймворка LangChain, набора инструментов для создания LLM путем объединения в цепочку совместимых компонентов. Он будет использоваться для получения текста со страниц Google SERP и его очистки для создания релевантного контента для RAG.openai: Официальная клиентская библиотека Python для API OpenAI. Она будет использоваться для взаимодействия с моделями GPT для генерации ответов на естественном языке на основе заданных входных данных и контекста RAG.streamlit: Фреймворк для создания интерактивных веб-приложений на Python. Он пригодится для создания пользовательского интерфейса, в котором пользователи смогут вводить поисковые запросы Google и подсказки ИИ, а также динамически просматривать результаты.
В активированной виртуальной среде запустите приведенную ниже команду для установки всех зависимостей:
pip install python-dotenv requests langchain-community openai streamlitБолее подробно, мы будем использовать AsyncChromiumLoader из langchain-community, который требует следующих зависимостей:
pip install --upgrade --quiet playwright beautifulsoup4 html2textДля правильной работы Playwright также требуется установить браузеры:
playwright installУстановка всех этих библиотек займет некоторое время, так что наберитесь терпения.
Фантастика! Вы готовы к написанию логики на Python.
Шаг № 3: Подготовьте проект
В app.py добавьте следующие импорты:
from dotenv import load_dotenv
импорт os
импорт запросов
from langchain_community.document_loaders import AsyncChromiumLoader
из langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
import streamlit as stЗатем создайте файл .env в папке проекта для хранения всех ваших учетных данных. Теперь структура вашего проекта будет выглядеть так, как показано ниже:
Используйте приведенную ниже функцию в app.py, чтобы указать python-dotenv загрузить переменные окружения из .env:
load_dotenv()Теперь вы можете импортировать переменные окружения из .env или из системы:
os.environ.get("<ENV_NAME>")Здесь же мы импортировали стандартную библиотеку os Python.
Шаг № 4: Настройка SERP API
Как уже говорилось во введении, мы будем использовать SERP API компании Bright Data для получения контента со страниц результатов поисковых систем и использования его в нашем рабочем процессе Python RAG. В частности, мы будем извлекать текст из URL-адресов веб-страниц, возвращаемых SERP API.
Чтобы настроить SERP API, обратитесь к официальной документации. В качестве альтернативы следуйте приведенным ниже инструкциям.
Если вы еще не создали учетную запись, зарегистрируйтесь на сайте Bright Data. После входа в систему перейдите на панель управления вашей учетной записью:

Там нажмите кнопку “Получить продукты прокси”.
Это приведет вас на страницу ниже, где вам нужно будет нажать на строку “SERP API”:

На странице продукта SERP API установите флажок “Активировать зону”, чтобы включить продукт:
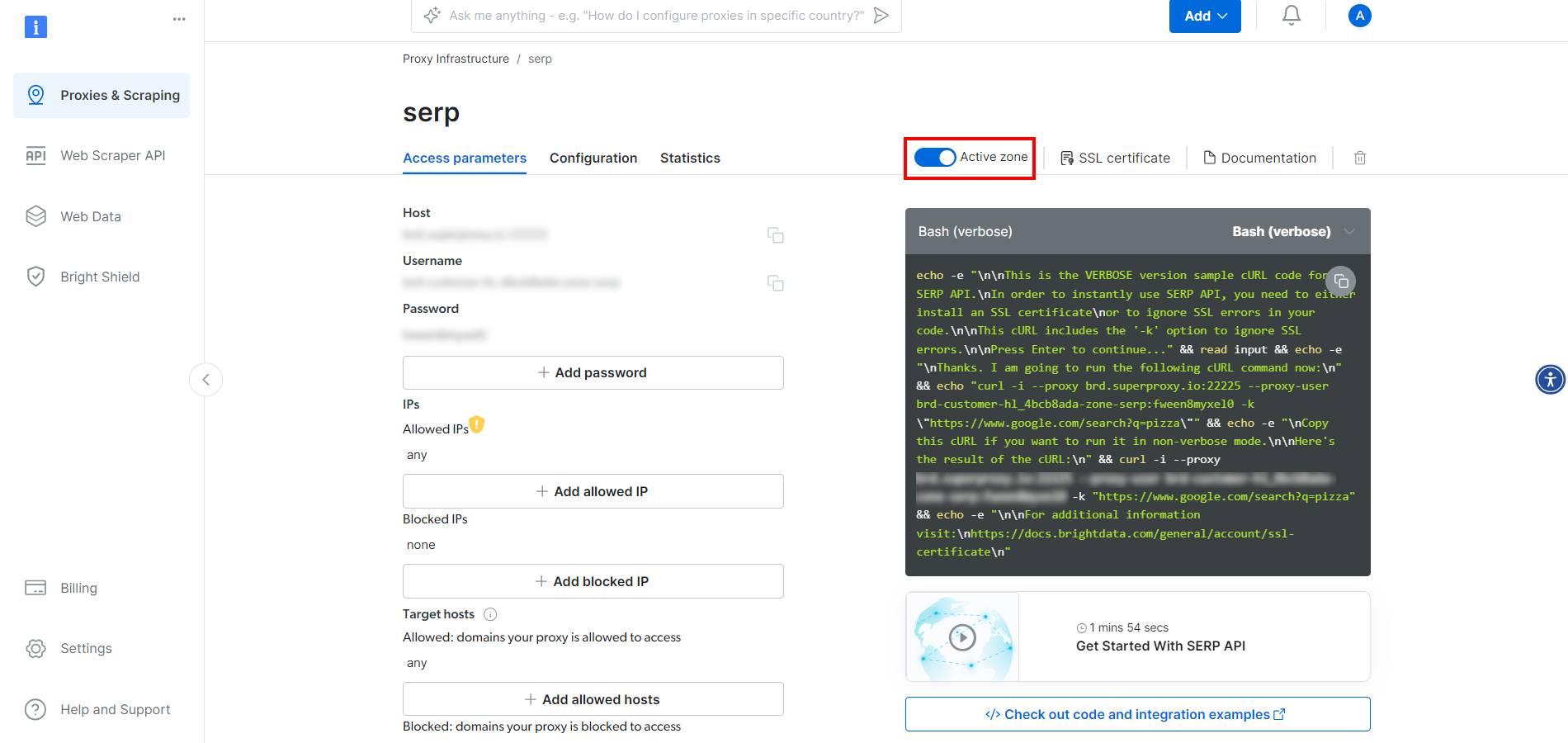
Теперь скопируйте хост, порт, имя пользователя и пароль SERP API в разделе “Параметры доступа” и добавьте их в файл .env:
BRIGHT_DATA_SERP_API_HOST="<ВАШ_ХОСТ>"
BRIGHT_DATA_SERP_API_PORT=<ВАШ_ПОРТ>
BRIGHT_DATA_SERP_API_USERNAME="<ВАШЕ_ИМЯ_ПОЛЬЗОВАТЕЛЯ>"
BRIGHT_DATA_SERP_API_PASSWORD="<ВАШ_ПАРОЛЬ>"Замените местоимения <YOUR_XXXX> на значения, предоставленные Bright Data на странице SERP API.
Обратите внимание, что хост в “Параметрах доступа” имеет следующий формат:
brd.superproxy.io:33335Вы должны разделить его следующим образом:
BRIGHT_DATA_SERP_API_HOST="brd.superproxy.io"
BRIGHT_DATA_SERP_API_PORT=33335Потрясающе! Теперь вы можете использовать SERP API в Python.
Шаг #5: Реализация логики скрапинга SERP
В app.py добавьте следующую функцию для получения первого количества_урлов URL со страницы Google SERP:
def get_google_serp_urls(query, number_of_urls=5):
# выполнить запрос SERP API от Bright Data
# с автопарсингом JSON
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
порт = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
имя пользователя = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
пароль = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{имя пользователя}:{пароль}@{хост}:{порт}"
прокси = {"http": proxy_url, "https": proxy_url}
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# получение разобранного JSON-ответа
response_data = response.json()
# извлечь число "number_of_urls" из
# URL-адресов Google SERP из ответа
google_serp_urls = []
if "organic" in response_data:
for item in response_data["organic"]:
if "link" in item:
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls]Выполняется HTTP GET-запрос к SERP API с поисковым запросом, указанным в аргументе query. Параметр запроса brd_json=1 гарантирует, что SERP API разберет результаты в JSON в формате, приведенном ниже:
{
"general": {
"search_engine": "google",
"results_cnt": 1980000000,
"search_time": 0.57,
"language": "en",
"mobile": false,
"basic_view": false,
"search_type": "text",
"page_title": "пицца - поиск Google",
"code_version": "1.90",
"timestamp": "2023-06-30T08:58:41.786Z"
},
"input": {
"original_url": "https://www.google.com/search?q=pizza&brd_json=1",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12) AppleWebKit/608.2.11 (KHTML, like Gecko) Version/13.0.3 Safari/608.2.11",
"request_id": "hl_1a1be908_i00lwqqxt1"
},
"organic": [
{
"link": "https://www.pizzahut.com/",
"display_link": "https://www.pizzahut.com",
"title": "Pizza Hut | Delivery & Carryout - No One OutPizzas The Hut!",
"image": "опущено для краткости...",
"image_alt": "пицца от www.pizzahut.com",
"image_base64": "опущено для краткости...",
"rank": 1,
"global_rank": 1
},
{
"link": "https://www.dominos.com/en/",
"display_link": "https://www.dominos.com ' ...",
"title": "Domino's: Доставка и вынос пиццы, пасты, курицы и многое другое",
"description": "Заказывайте пиццу, пасту, сэндвичи и многое другое в Domino's онлайн на вынос или с доставкой. Просматривайте меню, находите местоположение, отслеживайте заказы. Подпишитесь на электронную почту Domino's ...",
"image": "опущено для краткости...",
"image_alt": "пицца от www.dominos.com",
"image_base64": "опущено для краткости...",
"rank": 2,
"global_rank": 3
},
// опущено для краткости...
],
// опущено для краткости...
}Последние несколько строк функции извлекают каждый SERP URL из полученных JSON-данных, выбирают только первые number_of_urls URL и возвращают их в виде списка.
Пора извлечь текст из этих URL!
Шаг № 6: Извлечение текста из URL-адресов SERP
Определите функцию, которая извлекает текст из каждого URL SERP:
def extract_text_from_urls(urls, number_of_words=600):
# поручаем безголовому экземпляру Chrome посетить указанные URL
# с указанным пользовательским агентом
loader = AsyncChromiumLoader(
url,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# обработайте извлеченные HTML-документы, чтобы извлечь из них текст
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# убедитесь, что каждый текстовый документ HTML содержит только число
# number_of_words words words
извлеченный_текстовый_список = []
для doc_transformed в docs_transformed:
# разбиваем текст на слова и соединяем первые количество_слов
words = doc_transformed.page_content.split()[:number_of_words]
извлеченный_текст = " ".join(words)
# игнорировать пустые текстовые документы
if len(extracted_text) != 0:
extracted_text_list.append(extracted_text)
return extracted_text_listЭта функция:
- Загружает веб-страницы с URL-адресов, переданных в качестве аргумента, используя экземпляр браузера Chrome без головы.
- Использует BeautifulSoupTransformer для обработки HTML каждой страницы и извлечения текста из определенных тегов (например, <p>, <h1>, <strong> и т. д.), опуская ненужные теги (например, <a>) и комментарии.
- Ограничивает извлеченный текст для каждой веб-страницы количеством слов, заданным аргументом
number_of_words. - Возвращает список извлеченных текстов из каждого URL.
Следует помнить, что тегов [“p”, “em”, “li”, “strong”, “h1”, “h2”] достаточно для извлечения текста с большинства веб-страниц. Однако в некоторых специфических сценариях вам может понадобиться изменить этот список HTML-тегов. Также может потребоваться увеличить или уменьшить целевое количество слов для каждого элемента текста.
Например, рассмотрим веб-страницу ниже:
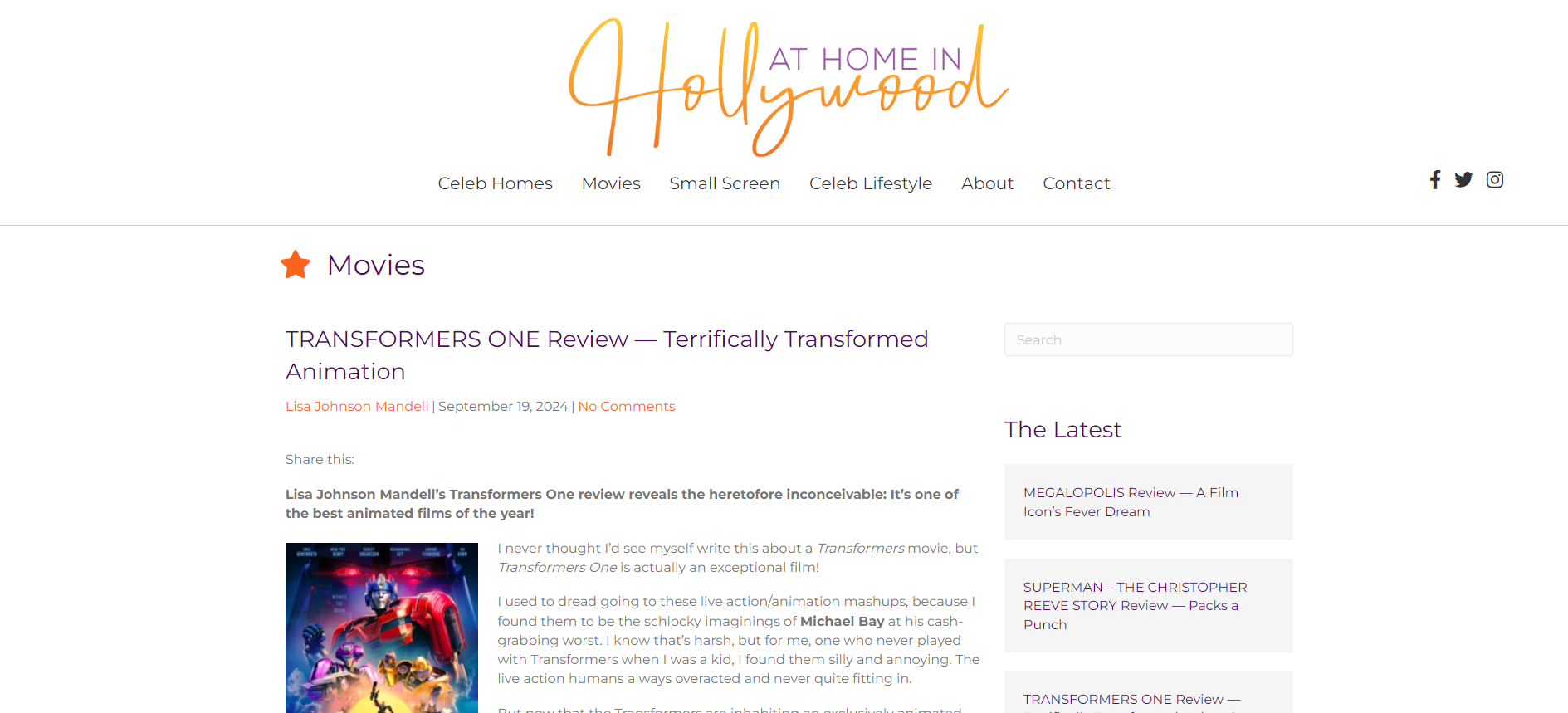
Если применить эту функцию к данной странице, то получится такой текстовый массив:
["Рецензия Лизы Джонсон Манделл на "Трансформеры-1" раскрывает немыслимое доселе: Это один из лучших анимационных фильмов года! Я никогда не думала, что буду писать такое о фильме про трансформеров, но "Трансформеры-1" - это действительно исключительный фильм! ..."]Невероятно! Даже если он не идеален, он все равно очень качественный по меркам моделей ИИ.
Список текстовых элементов, возвращаемый функцией extract_text_from_urls(), представляет собой RAG-контекст для модели OpenAI.
Шаг № 7: Генерируем подсказку RAG
Определите функцию, которая преобразует запрос подсказки ИИ и текстовый контекст в конечную подсказку RAG:
def get_openai_prompt(request, text_context=[]):
# подсказка по умолчанию
prompt = request
# добавьте контекст к подсказке, если он присутствует
if len(text_context) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f "Ответьте на запрос, используя только приведенный ниже контекст.nnContext:n{context_string}nnRequest: {request}"
return promptПодсказки, возвращаемые предыдущей функцией при указании контекста RAG, имеют такой формат:
Ответьте на запрос, используя только приведенный ниже контекст.
Контекст:
Bla bla bla...
--------
Бла-бла-бла...
--------
Бла-бла-бла...
Запрос: <Ваш_запрос>Шаг #8: Выполните GPT-запрос
Сначала инициализируем клиент OpenAI в верхней части файла app.py:
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))Это зависит от переменной окружения OPENAI_API_KEY, которую вы можете определить непосредственно в окружении вашей системы или в файле .env:
OPENAI_API_KEY="<ВАШ_API_KEY>"
Замените <YOUR_API_KEY> значением вашего ключа OpenAI API. Если вы не знаете, как его получить, следуйте официальному руководству.
Далее напишите функцию, которая использует официальный клиент OpenAI для выполнения запроса к модели ИИ GPT-4o mini:
def interrogate_openai(prompt, max_tokens=800):
# опрашиваем модель OpenAI с заданным запросом
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "пользователь", "содержание": подсказка}],
max_tokens=max_tokens,
)
return response.choices[0].message.contentОбратите внимание, что вы можете настроить любую другую модель GPT, поддерживаемую API OpenAI.
Если вызвать запрос, возвращенный функцией get_openai_prompt(), который включает в себя указанный текстовый контекст, функция interrogate_openai() успешно выполнит генерацию с дополнением поиска, как и предполагалось.
Шаг #9: Создание пользовательского интерфейса приложения
Используйте Streamlit для создания простой формы пользовательского интерфейса, в которой пользователи могут указать:
- Поисковый запрос Google для передачи в SERP API
- Подсказку ИИ для отправки в GPT-4o mini.
Достичь этого можно с помощью следующих строк кода:
with st.form("prompt_form"):
# инициализируем результаты вывода
result = ""
final_prompt = ""
# текстовая область для ввода пользователем поискового запроса Google
google_search_query = st.text_area("Google Search:", None)
# текстовая область для ввода запроса ИИ
request = st.text_area("Подсказка ИИ:", None)
# кнопка для отправки формы
submitted = st.form_submit_button("Отправить")
# если форма отправлена
if submitted:
# извлекаем URL-адреса SERP Google по заданному поисковому запросу
google_serp_urls = get_google_serp_urls(google_search_query)
# извлечение текста из соответствующих HTML-страниц
извлеченный_текст_списка = извлечь_текст_из_урлов(google_serp_urls)
# сгенерируйте подсказку ИИ, используя извлеченный текст в качестве контекста
final_prompt = get_openai_prompt(request, extracted_text_list)
# опрашиваем модель OpenAI с помощью сгенерированного запроса
result = interrogate_openai(final_prompt)
# выпадающий список, содержащий сгенерированную подсказку
final_prompt_expander = st.expander("ИИ Final Prompt:")
final_prompt_expander.write(final_prompt)
# записать результат из модели OpenAI
st.write(result)Вот и все! Скрипт на Python RAG готов.
Шаг № 10: Соберите все вместе
Ваш файл app.py должен содержать следующий код:
from dotenv import load_dotenv
импортировать os
импорт запросов
from langchain_community.document_loaders import AsyncChromiumLoader
из langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
import streamlit as st
# загрузите переменные окружения из файла .env
load_dotenv()
# инициализируйте клиент API OpenAI с помощью вашего ключа API
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def get_google_serp_urls(query, number_of_urls=5):
# выполняем запрос SERP API от Bright Data
# с автопарсингом JSON
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
порт = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
имя пользователя = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
пароль = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{имя пользователя}:{пароль}@{хост}:{порт}"
прокси = {"http": proxy_url, "https": proxy_url}
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# получение разобранного JSON-ответа
response_data = response.json()
# извлечь число "number_of_urls" из
# URL-адресов Google SERP из ответа
google_serp_urls = []
if "organic" in response_data:
for item in response_data["organic"]:
if "link" in item:
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls]
def extract_text_from_urls(urls, number_of_words=600):
# поручить экземпляру Chrome без головы посетить указанные URL-адреса
# с указанным пользовательским агентом
loader = AsyncChromiumLoader(
url,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# обработайте извлеченные HTML-документы, чтобы извлечь из них текст
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# убедитесь, что каждый текстовый документ HTML содержит только число
# number_of_words words words
извлеченный_текстовый_список = []
для doc_transformed в docs_transformed:
# разбиваем текст на слова и соединяем первые количество_слов
words = doc_transformed.page_content.split()[:number_of_words]
извлеченный_текст = " ".join(words)
# игнорировать пустые текстовые документы
if len(extracted_text) != 0:
extracted_text_list.append(extracted_text)
return extracted_text_list
def get_openai_prompt(request, text_context=[]):
# подсказка по умолчанию
подсказка = запрос
# добавьте контекст к подсказке, если он присутствует
if len(text_context) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f "Ответьте на запрос, используя только приведенный ниже контекст.nnContext:n{context_string}nnRequest: {request}"
return prompt
def interrogate_openai(prompt, max_tokens=800):
# опросить модель OpenAI с заданной подсказкой
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "пользователь", "содержание": подсказка}],
max_tokens=max_tokens,
)
return response.choices[0].message.content
# создайте форму в приложении Streamlit для ввода данных пользователем
с st.form("prompt_form"):
# инициализируем результаты вывода
result = ""
final_prompt = ""
# текстовая область для ввода пользователем поискового запроса Google
google_search_query = st.text_area("Google Search:", None)
# текстовая область для ввода запроса ИИ
request = st.text_area("Подсказка ИИ:", None)
# кнопка для отправки формы
submitted = st.form_submit_button("Отправить")
# если форма отправлена
if submitted:
# извлекаем URL-адреса Google SERP по заданному поисковому запросу
google_serp_urls = get_google_serp_urls(google_search_query)
# извлечение текста из соответствующих HTML-страниц
извлеченный_текст_списка = извлечь_текст_из_урлов(google_serp_urls)
# сгенерируйте подсказку ИИ, используя извлеченный текст в качестве контекста
final_prompt = get_openai_prompt(request, extracted_text_list)
# опрашиваем модель OpenAI с помощью сгенерированного запроса
result = interrogate_openai(final_prompt)
# выпадающий список, содержащий сгенерированную подсказку
final_prompt_expander = st.expander("ИИ Final Prompt")
final_prompt_expander.write(final_prompt)
# записать результат из модели OpenAI
st.write(result)Можете ли вы в это поверить? Менее чем за 150 строк кода вы можете реализовать RAG с помощью Python!
Шаг № 11: Протестируйте приложение
Запустите ваше RAG-приложение на Python с помощью:
streamlit run app.pyВ терминале вы должны увидеть следующий вывод:
Теперь вы можете просмотреть ваше приложение Streamlit в браузере.
Локальный URL: http://localhost:8501
Сетевой URL: http://172.27.134.248:8501Следуя инструкциям, зайдите на сайт http://localhost:8501 в браузере. Ниже показано то, что вы должны увидеть:
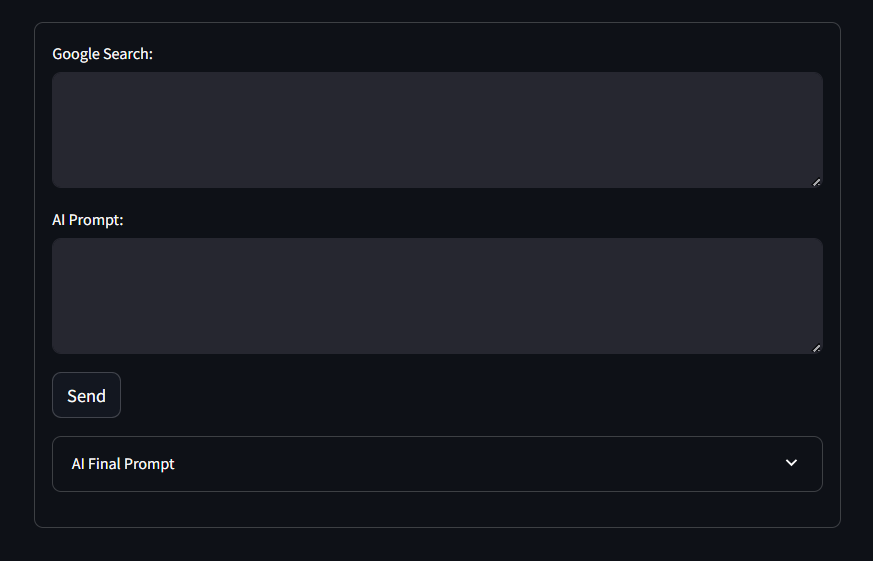
Как вы можете заметить, форма содержит текстовые области ввода “Google Search:” и “ИИ Prompt:”, определенные в коде, а также кнопку “Отправить” и выпадающий список “ИИ Final Prompt”.
Протестируйте приложение, используя поисковый запрос Google, как показано ниже:
Transformers One reviewИ ИИ предлагает следующее:
Напишите рецензию на фильм "Трансформеры-1Нажмите “Отправить” и подождите, пока приложение обработает запрос. Через несколько секунд вы должны получить такой результат:

Ого! Неплохая рецензия…
Если вы развернете выпадающий список “ИИ Final Prompt”, то увидите полный запрос, используемый приложением для RAG.
И вуаля! Вы только что реализовали чатбот RAG на Python с GPT-4o mini, используя данные SERP.
Заключение
В этом уроке вы узнали, что такое RAG и как его можно реализовать, снабжая модели ИИ данными SERP. В частности, вы научились создавать на Python RAG-чатбот, который собирает данные SERP и использует их в GPT-моделях для повышения точности результатов.
Основной проблемой при таком подходе является соскабливание данных поисковых систем, таких как Google:
- Они часто изменяют структуру своих страниц SERP.
- Они защищены одними из самых сложных мер защиты от ботов.
- Одновременное извлечение больших объемов данных SERP является сложной задачей и может стоить больших денег.
Как показано здесь, SERP API от Bright Data позволяет получать данные SERP в режиме реального времени от всех основных поисковых систем без особых усилий. Это поддерживает RAG и многие другие приложения. Получите бесплатную пробную версию прямо сейчас!
Зарегистрируйтесь сейчас, чтобы узнать, какие из сервисов прокси или продуктов скраппинга Bright Data лучше всего подходят для ваших нужд. Начните с бесплатной пробной версии!




