

В этом уроке вы узнаете:
- Как подход, основанный на веерной обработке запросов и сравнении обзоров Google AI, может быть использован для улучшения GEO и SEO.
- Как построить этот рабочий процесс на высоком уровне с помощью шести агентов искусственного интеллекта.
- Как реализовать этот рабочий процесс по оптимизации контента с помощью искусственного интеллекта с помощью CrewAI, интегрированного с Gemini и Bright Data.
- Несколько идей и советов, как еще больше улучшить рабочий процесс.
Давайте погрузимся!
TL;DR
Хотите сразу перейти к готовым файлам проекта? Загляните в проект на GitHub.
Объяснение сравнения веерных запросов и обзоров ИИ для улучшения GEO и SEO
Все мы знаем, что SEO(Search Engine Optimization) – это искусство улучшения видимости сайта в результатах органического поиска. Но сейчас мир переходит на GEO(Generative Engine Optimization).
Если вы не знакомы с GEO, то это стратегия цифрового маркетинга, направленная на то, чтобы сделать контент более заметным в поисковых системах с поддержкой искусственного интеллекта, таких как Google AI Overviews, ChatGPT и другие.
Поскольку LLM по сути являются “черными ящиками”, не существует прямого способа “оптимизировать” веб-страницу под GEO (так же, как SEO было до появления инструментов поиска по объему ключевых слов).
Что вы можете сделать, так это следовать эмпирическому подходу: изучите реальные резюме, созданные ИИ, и веер запросов по вашим целевым ключевым словам. Если по определенному поисковому запросу в результатах ИИ постоянно появляются определенные темы, вам следует оптимизировать контент своей страницы в соответствии с этими темами.
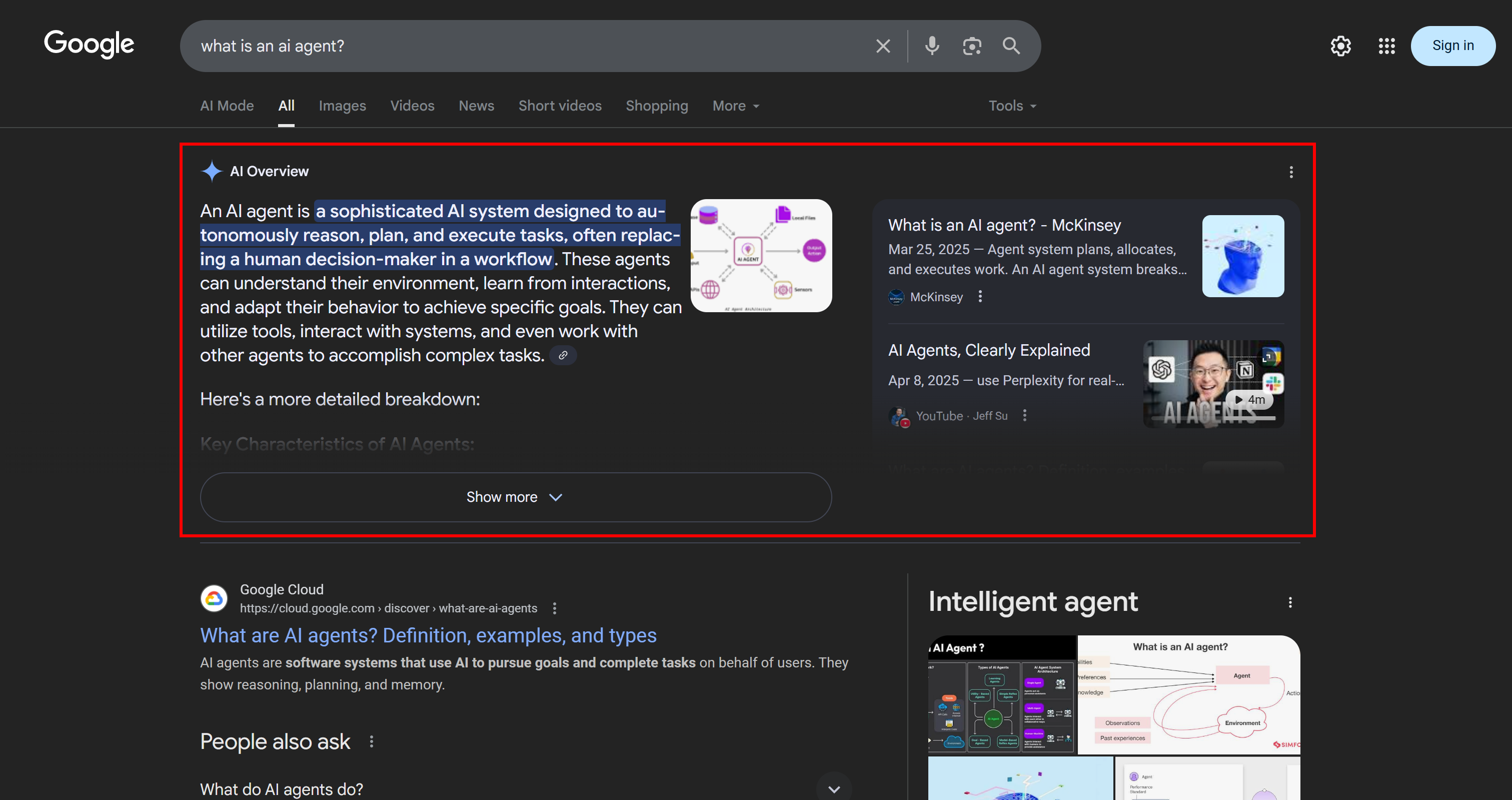
В контексте поиска Google на основе искусственного интеллекта ” веерный запрос” – это техника, которая превращает один запрос пользователя в сеть связанных подзапросов. Вместо того чтобы просто сопоставить исходный запрос с наилучшим ответом, Google AI Mode идет дальше, генерируя и осуществляя поиск сразу по нескольким связанным вопросам.
Как видно из приведенного ниже примера, режим Google AI Mode обычно возвращает около 10 связанных ссылок с краткими аннотациями, чтобы помочь вам глубже изучить тему:
Вот что такое веерный вывод запросов Google, который можно определить в более простых терминах как набор связанных подзапросов, созданных на основе одного поиска ИИ.
Если определенные темы постоянно повторяются в веерных запросах и обзорах ИИ, имеет смысл создать страницу контента, посвященную им. В качестве положительного побочного эффекта такой подход может также улучшить традиционное SEO, поскольку такие системы, как Google, скорее всего, повысят в SERP страницы, которые уже демонстрируют хорошие результаты в результатах поиска с использованием ИИ.
Теперь, когда вы поняли основы, погрузитесь в технические особенности этого подхода к GEO!
Как построить многоагентную систему оптимизации ГЕО
Как вы можете себе представить, внедрение агента искусственного интеллекта для поддержки рабочего процесса оптимизации контента GEO – непростая задача. Одним из эффективных подходов является использование мультиагентной системы, основанной на шести специализированных агентах:
- Скребок заголовков: Извлекает основной заголовок или название из веб-страницы, задав ее URL.
- Исследователь веерной выдачи запросов Google: Использует извлеченный заголовок для вызова инструмента поиска Google, доступного в Gemini, и генерирует веерный вывод запроса.
- Экстрактор основного запроса Google: Разбирает веер запросов, чтобы определить и извлечь основной Google-подобный поисковый запрос.
- Google AI Overview Retriever: Использует основной запрос для выполнения поиска Google SERP и извлекает из него раздел AI Overview.
- Сумматор веерного вывода запросов: Сокращает содержимое веера запросов (обычно довольно длинное) в оптимизированное резюме в формате Markdown, выделяя ключевые темы.
- ИИ-оптимизатор контента: Сравнивает веерную сводку запросов с обзором Google AI для выявления закономерностей и повторяющихся тем. Генерирует выходной документ в формате Markdown, содержащий полезные сведения для оптимизации контента GEO.
Некоторые из описанных выше агентов достаточно универсальны и могут быть реализованы с помощью большинства LLM (например, Google Main Query Extractor, Query Fan-Out Summarizer и AI Content Optimizer). Однако другие агенты требуют более специализированных возможностей и доступа к конкретным моделям или инструментам.
Например, агенту Google Main Query Extractor необходим доступ к инструменту google_search, который доступен только в моделях Gemini. Аналогично, агент Title Scraper должен получить доступ к содержимому веб-страницы, чтобы извлечь заголовок. Эта задача может оказаться непростой, поскольку на многих веб-сайтах действуют меры, препятствующие использованиюAI. Чтобы избежать проблем, можно интегрировать Title Scraper с Web Unlocker. Этот API Bright Data извлекает контент в виде необработанного HTML или оптимизированного для AI формата Markdown, минуя все блокировки.
Так же, как и для ретривера Google AI Overview, для выполнения поискового запроса и соскабливания AI Overview в режиме реального времени требуется такой инструмент, как Bright Data SERP API.
Другими словами, благодаря Gemini и инфраструктуре ИИ Bright Data вы можете реализовать этот сценарий использования GEO/SEO. Теперь вам нужна система создания агентов ИИ для организации работы этих агентов, как показано на этой сводной диаграмме:
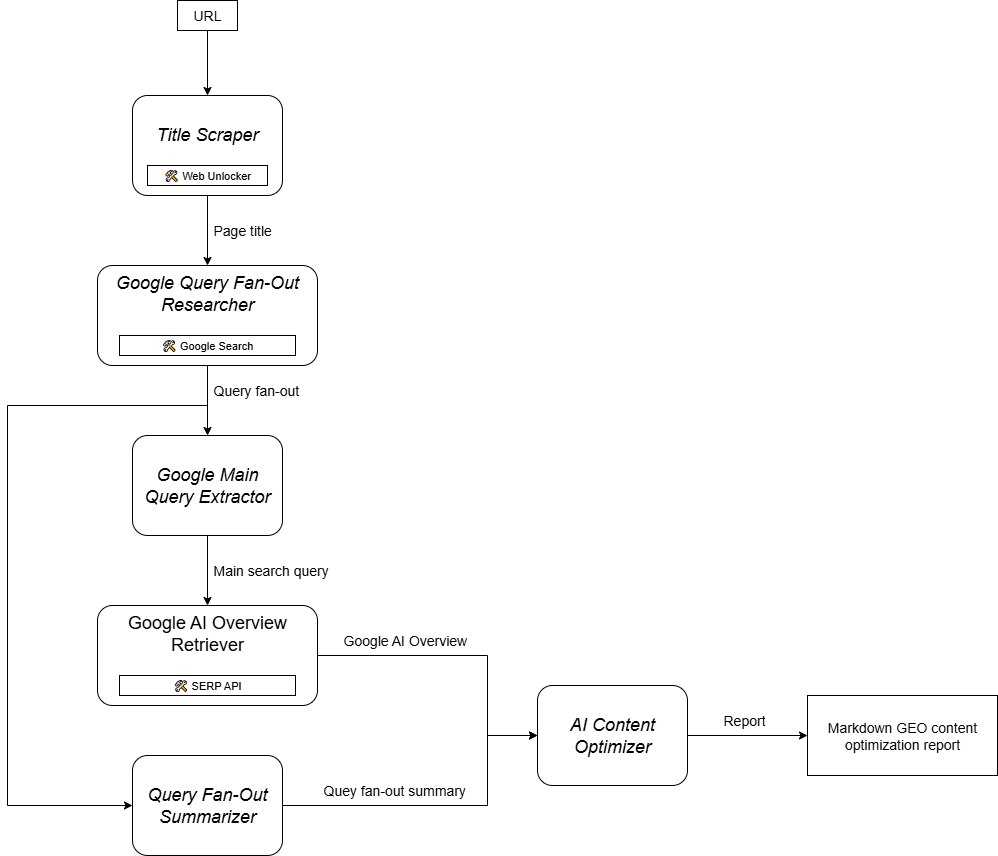
Поскольку CrewAI специально разработан для оркестровки мультиагентных систем, он является идеальной основой для создания и управления этим рабочим процессом.
Реализация многоагентной системы оптимизации содержимого ГСО в CrewAI с использованием Gemini и Bright Data
Следуя приведенным ниже инструкциям, вы узнаете, как создать мультиагентную систему, обеспечивающую повторяющийся рабочий процесс оптимизации веб-страниц для поисковых систем, управляемых искусственным интеллектом. Систематически анализируя веерные запросы и обзоры ИИ, этот подход поможет вам выявить высокоприоритетные темы и структурировать контент для достижения более высоких рейтингов, управляемых ИИ.
Приведенный ниже код написан на Python с использованием CrewAI, с интеграцией Bright Data и Gemini для обеспечения агентов необходимыми инструментами и возможностями.
Пререквизиты
Чтобы следовать этому руководству, убедитесь, что у вас есть:
- Python 3.10+ установлен локально.
- Ключ API Gemini (кредиты не требуются).
- Учетная запись Bright Data.
Не волнуйтесь, если у вас нет учетной записи Bright Data. Вас проинструктируют о том, как его создать.
Кроме того, очень важно иметь некоторое представление о том, как работает CrewAI. Прежде чем приступить к работе, мы рекомендуем ознакомиться с официальной документацией.
Шаг №1: Настройка приложения CrewAI
Для установки CrewAI требуется uv. Вы можете установить его глобально с помощью следующей команды:
pip install uvКроме того, следуйте официальному руководству по установке для вашей операционной системы.
Затем установите CrewAI в глобальном масштабе на свою систему:
uv tool install crewai Теперь создайте новый проект CrewAI под названием ai_content_optimization_agent:
crewai create crew ai_content_optimization_agentВам будет предложено выбрать поставщика ИИ. Поскольку текущий рабочий процесс работает на Gemini, выберите вариант 3:
Затем выберите модель Gemini:
Вы можете выбрать любую из доступных моделей, так как далее в статье вы будете ее заменять. Поэтому это не так важно.
Продолжайте вводить свой API-ключ Gemini:

После этого шага ваш проект в структуре папок ai_content_optimization_agent/ будет выглядеть следующим образом:
ai_content_optimization_agent/
├── .gitignore
├── knowledge/
├── pyproject.toml
├── README.md
├── .env
└── src/
└── ai_content_optimization_agent/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yamlЗагрузите проект в вашу любимую Python IDE и ознакомьтесь с ним. Просмотрите текущие файлы и обратите внимание, что .env уже содержит выбранную модель Gemini и ваш ключ API Gemini:
MODEL=<SELECTED_GEMINI_MODEL>
GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>Если вы не знакомы с файлами в CrewAI или столкнулись с проблемами, обратитесь к официальному руководству по установке.
Перейдите в папку проекта в терминале:
cd ai_content_optimization_agentЗатем инициализируйте виртуальную среду Python внутри нее:
python -m venv .venv Примечание: Виртуальная среда должна иметь имя .venv. В противном случае команда crewai run для запуска рабочего процесса CrewAI будет выполнена неудачно.
В Linux и macOS активируйте виртуальную среду с помощью:
source .venv/bin/activateВ качестве альтернативы в Windows выполните команду:
.venvScriptsactivateГотово! Теперь у вас есть пустой проект CrewAI.
Шаг № 2: Интеграция Gemini
Как уже говорилось, по умолчанию CrewAI добавляет выбранную модель Gemini в файл .env. Чтобы настроить последнюю модель, перезапишите переменную окружения MODEL в файле .env следующим образом:
MODEL=gemini/gemini-2.5-flashТаким образом, ваши агенты ИИ, организованные с помощью CrewAI, смогут подключаться к gemini-2.5-flash. На момент написания статьи это самая последняя модель Gemini Flash. Кроме того, она имеет очень щедрые ограничения скорости при запросе через API (как в этой интеграции CrewAI).
В файле crew.py загрузите имя MODEL из окружения, используя:
MODEL = os.getenv("MODEL")Эта переменная будет использоваться позже для установки LLM в агентах.
Не забудьте импортировать os из стандартной библиотеки Python:
import osКруто! Настройка Близнецов закончена.
Шаг № 3: Установка и настройка инструментов CrewAI Bright Data Tools
Извлечение заголовка из веб-страницы с помощью искусственного интеллекта – непростая задача. Большинство LLM не могут напрямую получить доступ к содержимому веб-страниц. И даже если у них есть встроенные инструменты для этого, они часто терпят неудачу из-за продвинутых мер по борьбе со скраппингом, таких как отпечатки пальцев браузера и CAPTCHA. Те же проблемы возникают и при “живом” скраппинге SERP, поскольку Google активно препятствует автоматизированному скраппингу.
Именно здесь Bright Data становится основополагающим фактором. К счастью, она официально поддерживается инструментами Bright Data от CrewAI.
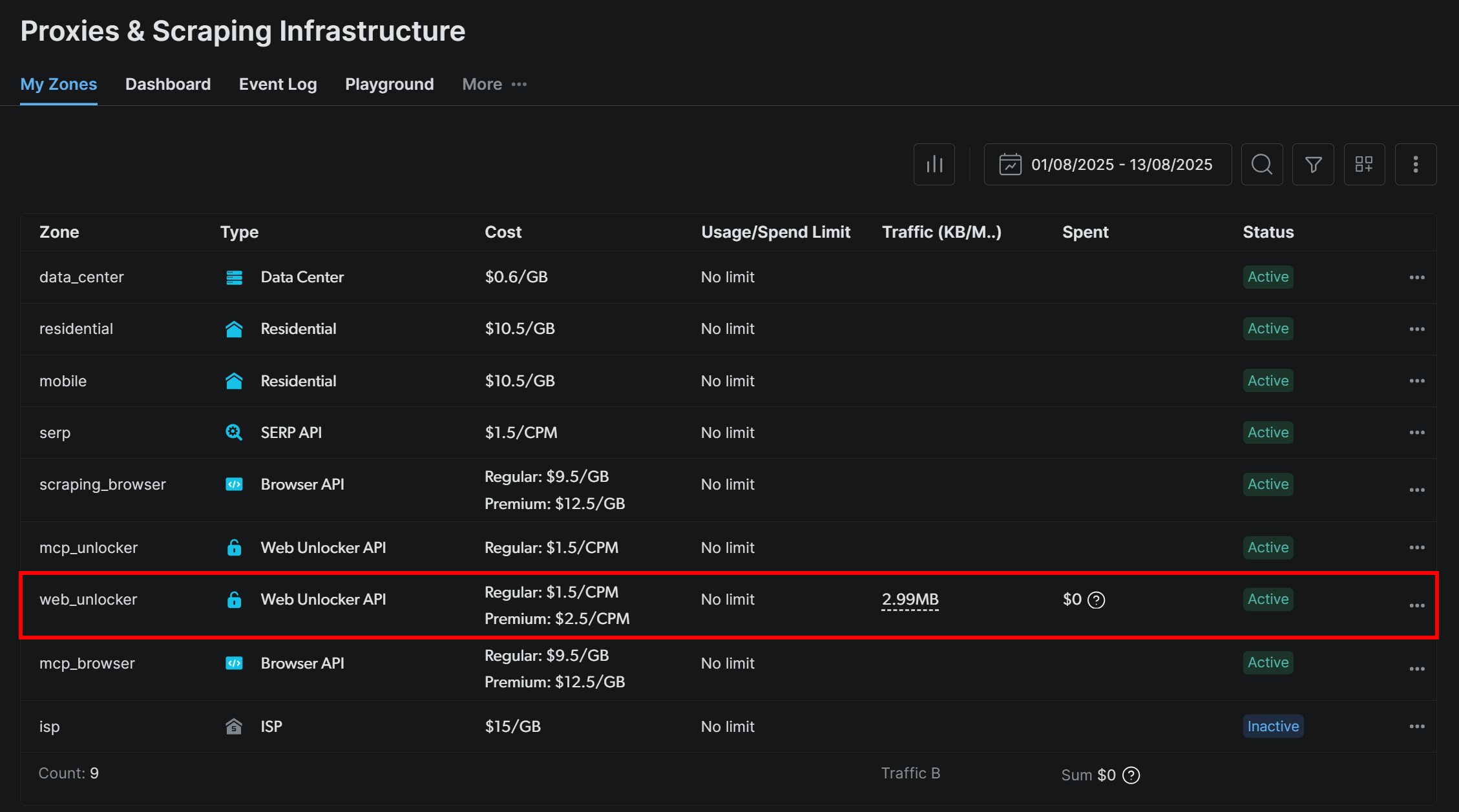
Чтобы начать работу, зарегистрируйте учетную запись Bright Data (или войдите в нее, если она у вас уже есть). Затем перейдите на приборную панель своего профиля и следуйте официальным инструкциям по настройке зоны Web Unlocker:
Убедитесь, что зона установлена в положение “Активная”:
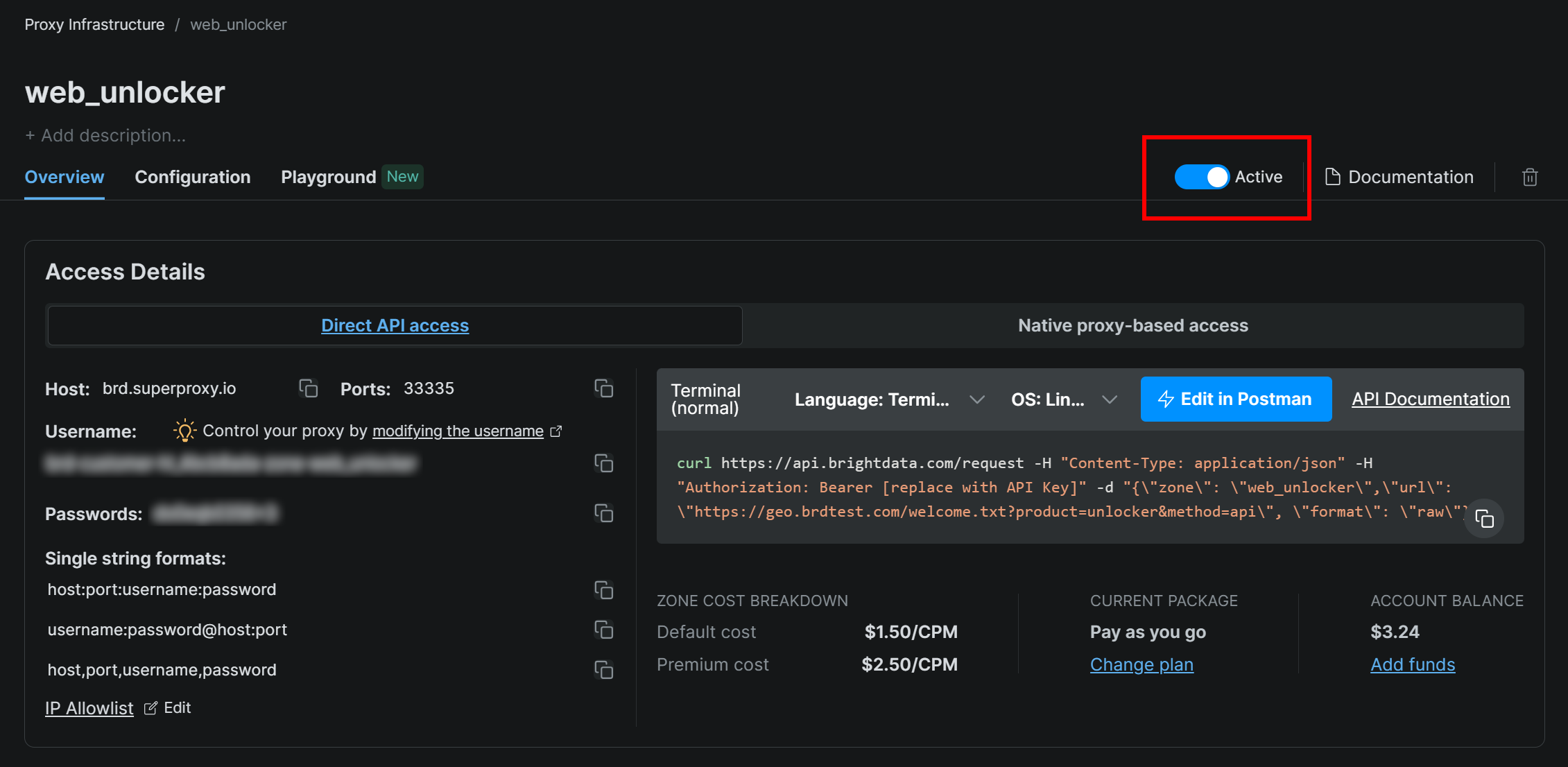
В данном случае имя зоны Web Unlocker будет "web_unlocker", но вы можете назвать ее как угодно. Запомните это имя, так как оно вам скоро понадобится.
После завершения настройки следуйте официальному руководству, чтобы сгенерировать ключ API Bright Data. Храните его в надежном месте, так как он вам скоро понадобится.
Теперь в активированной виртуальной среде установите требования к инструменту CrewAI Bright Data:
pip install crewai[tools] aiohttp requestsЧтобы интеграция работала, добавьте учетные данные Bright Data в файл .env с помощью следующих двух env:
BRIGHT_DATA_API_KEY="<BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_ZONE="<YOUR_BRIGHT_DATA_ZONE>"Замените и на реальный ключ API Bright Data и имя зоны Web Unlocker соответственно.
Далее в файле crew.py импортируйте инструменты Bright Data:
from crewai_tools import BrightDataWebUnlockerTool, BrightDataSearchToolИнициализируйте их, как показано ниже:
web_unlocker_tool = BrightDataWebUnlockerTool()
serp_search_tool = BrightDataSearchTool()Теперь вы можете предоставлять своим агентам возможности разблокировки веб-сайтов и поиска SERP, просто передавая им эти инструменты. Фантастика!
Шаг № 4: Создание агента для скребка заголовков
Теперь у вас есть все необходимое для создания своего первого агента. Начните с агента Title Scraper, который отвечает за извлечение заголовка из веб-страницы.
Чтобы получить заголовок страницы, есть два основных способа:
- Получение текстового содержимого из HTML-элемента
<h1>. - Если
<h1>отсутствует, попросите ИИ вывести заголовок страницы из остального содержимого страницы.
Не забывайте, что для этого требуется интеграция инструмента Web Unlocker. В crew.py определите агента и задачу CrewAI следующим образом:
@agent
def title_scraper_agent(self) -> Agent:
return Agent(
config=self.agents_config["title_scraper_agent"],
tools=[web_unlocker_tool], # <--- Web Unlocker tool integration
verbose=True,
llm=MODEL,
)
@task
def scrape_title_task(self) -> Task:
return Task(
config=self.tasks_config["scrape_title_task"],
agent=self.title_scraper_agent(),
max_retries=3,
)Поскольку эта задача связана с вызовом стороннего инструмента, имеет смысл включить логику повторных попыток (до 3 раз) с помощью параметра max_retries. Это предотвратит сбой всего рабочего процесса из-за временных проблем с сетью или ошибок инструмента. Такую же логику следует применять ко всем остальным задачам, которые зависят от сторонних сервисов (через инструменты) или включают сложные операции искусственного интеллекта, которые могут завершиться неудачей из-за ошибок обработки LLM.
Далее в файле конфигурации agents.yaml определите агент Title Scraper следующим образом:
title_scraper_agent:
role: "Title Scraper"
goal: "Extract the main H1 heading or title from a given web page URL."
backstory: "You are an expert scraper with a specialization in identifying and extracting the main heading (H1) or title of a webpage."Затем в файле tasks.yaml опишите его основную задачу следующим образом:
scrape_title_task:
description: |
1. Visit the URL: '{url}'.
2. Scrape the page's full content using the Bright Data Web Unlocker tool (using the Markdown data format).
3. Locate and extract only the text within the `<h1>` tag. If no `<h1>` tag is present, infer a title from the page content.
4. Output the extracted text as a plain string.
expected_output: "The plain string containing the extracted text from the specified URL."Обратите внимание, как эта задача считывает URL из входных данных CrewAI благодаря синтаксису {url}. Вы увидите, как заполнить этот входной аргумент в одном из следующих шагов.
Отлично! Создание агента Title Scraper завершено. Теперь вы примените аналогичную логику для определения всех оставшихся агентов.
Шаг #5: Внедрение агента Google Query Fan-Out Researcher
CrewAI не предоставляет встроенный способ доступа к инструменту поиска Google, доступному в моделях Gemini. Вместо этого вам нужно определить пользовательскую интеграцию Gemini LLM , как показано в официальном репозитории интеграций Gemini CrewAI.
По сути, вам нужно создать класс, который расширяет класс CrewAI LLM. Он будет подключаться к Gemini и включать инструмент google_search. Вы можете поместить этот класс в файл под названием gemini_google_search_llm.py в пользовательской подпапке llms/ (или поместить класс непосредственно в начало crew.py).
Определите свой пользовательский класс интеграции Gemini LLM следующим образом:
# src/ai_content_optimization_agent/llms/gemini_google_search_llm.py
from crewai import LLM
import os
from typing import Any, Optional
# Define a custom Gemini LLM integration with Google Search grounding
class GeminiWithGoogleSearch(LLM):
"""
A Gemini-specific LLM that has the "google_search" tool enabled.
"""
def __init__(self, model: str | None = None, **kwargs):
if not model:
# Use a default Gemini model.
model = os.getenv("MODEL")
super().__init__(model, **kwargs)
def call(
self,
messages: str | list[dict[str, str]],
tools: list[dict] | None = None,
callbacks: list[Any] | None = None,
available_functions: dict[str, Any] | None = None,
from_task: Optional[Any] = None,
from_agent: Optional[Any] = None,
) -> str | Any:
if not tools:
tools = []
# LiteLLM will throw a warning if it sees `google_search`,
# so you must use camel case here
tools.insert(0, {"googleSearch": {}})
return super().call(
messages=messages,
tools=tools,
callbacks=callbacks,
available_functions=available_functions,
from_task=from_task,
from_agent=from_agent,
)Это позволит вам получить доступ к инструменту поиска Google в настроенной модели Gemini.
Примечание: Инструмент Google Search включает в себя некоторую квоту на бесплатном уровне API, поэтому вы можете использовать его в своем приложении без необходимости приобретения премиум-плана.
Затем в файле crew.py импортируйте класс GeminiWithGoogleSearch:
from .llms.gemini_google_search_llm import GeminiWithGoogleSearchИспользуйте его, чтобы указать агента Query Fan-Out Researcher следующим образом:
@agent
def query_fanout_researcher_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_researcher_agent"],
verbose=True,
llm=GeminiWithGoogleSearch(MODEL), # <--- Gemini integration with the Google Search tool
)
@task
def google_search_task(self) -> Task:
return Task(
config=self.tasks_config["google_search_task"],
context=[self.scrape_title_task()],
agent=self.query_fanout_researcher_agent(),
max_retries=3,
markdown=True,
output_file="output/query_fanout.md",
)Обратите внимание, что LLM, используемый в классе Agent, является экземпляром пользовательского класса GeminiWithGoogleSearch. Поскольку задача генерации веерного вывода запросов производит ценный вывод для отладки и дальнейшего анализа, вам следует экспортировать его в пользовательский файл вывода. В данном случае полученный результат будет храниться в файле output/query_fanout.md.
Также обратите внимание, что контекст основной задачи агента – это выход основной задачи предыдущего агента в рабочем процессе. Таким образом, текущий агент будет иметь доступ к результату, полученному агентом Title Scraper. В частности, он будет использовать его в качестве входных данных при выполнении веерного поиска с помощью инструмента Google Search.
Затем в файле agents.yaml добавьте:
query_fanout_researcher_agent:
role: "Google Query Fan-Out Researcher"
goal: "Given a title, perform a comprehensive web search to get the query fan-out."
backstory: "You are an AI research assistant, powered by the Google Search tool from Gemini."И в файле tasks.yaml:
google_search_task:
description: |
1. Use the title from the previous task as your search query.
2. Perform a web search using the Google Search tool.
3. Return the results from the Google Search tool.
expected_output: "The output from the Google Search tool in Markdown format."Если вам интересно, как выглядит веерный вывод запроса, ниже приведен небольшой фрагмент из реальной выдачи инструмента google_search:
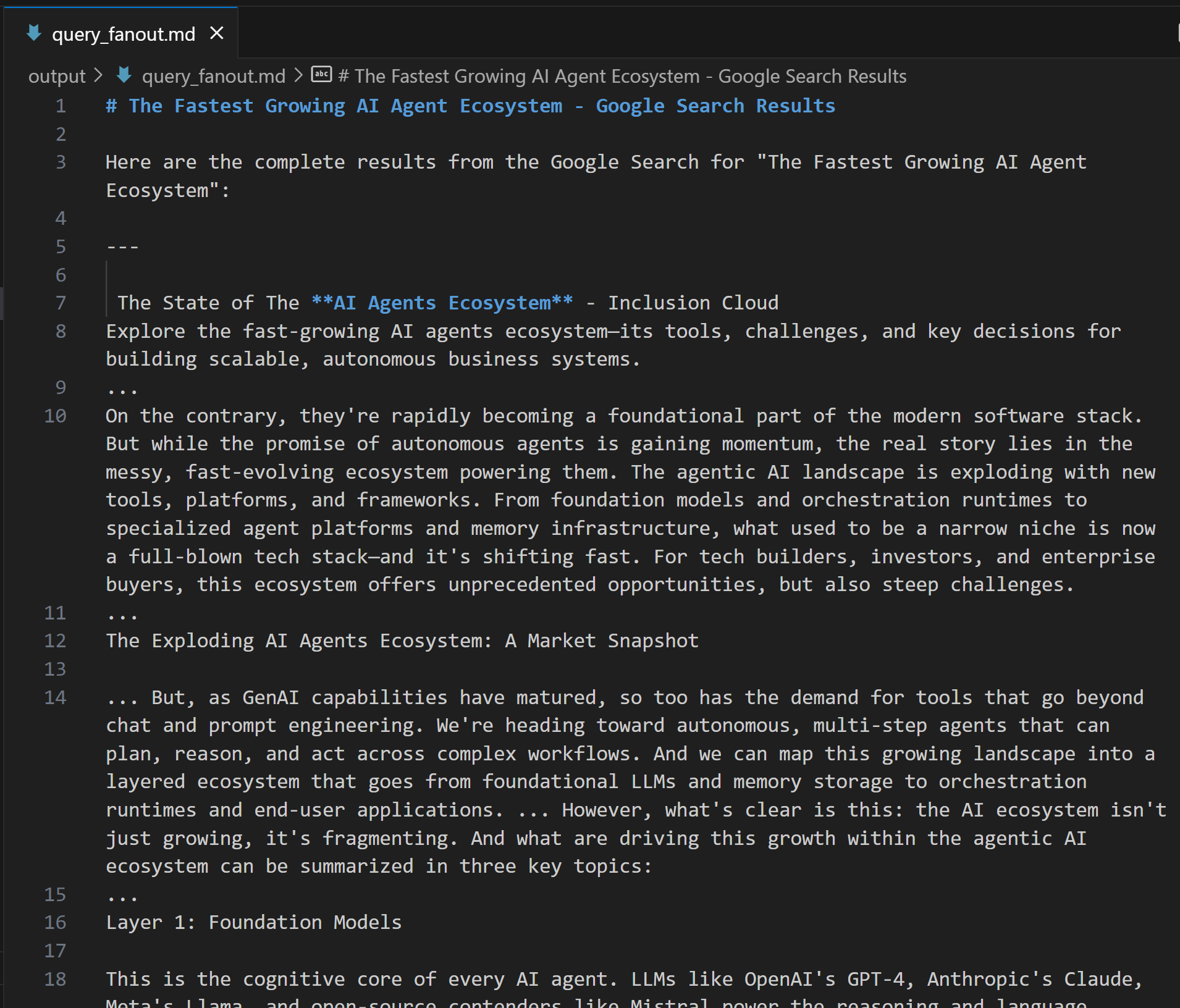
Отлично! Агент Google Query Fan-Out Researcher готов.
Шаг #6: Определите оставшихся агентов
Как и раньше, определите оставшихся агентов в crew.py:
@agent
def main_query_extractor_agent(self) -> Agent:
return Agent(
config=self.agents_config["main_query_extractor_agent"],
verbose=True,
llm=MODEL,
)
@task
def main_query_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["main_query_extraction_task"],
context=[self.google_search_task()],
agent=self.main_query_extractor_agent(),
)
@agent
def ai_overview_retriever_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_overview_retriever_agent"],
tools=[serp_search_tool], # <--- SERP API tool integration
verbose=True,
llm=MODEL,
)
@task
def ai_overview_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["ai_overview_extraction_task"],
context=[self.main_query_extraction_task()],
agent=self.ai_overview_retriever_agent(),
max_retries=3,
markdown=True,
output_file="output/ai_overview.md",
)
@agent
def query_fanout_summarizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_summarizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def query_fanout_summarization_task(self) -> Task:
return Task(
config=self.tasks_config["query_fanout_summarization_task"],
context=[self.google_search_task()],
agent=self.query_fanout_summarizer_agent(),
markdown=True,
output_file="output/query_fanout_summary.md",
)
@agent
def ai_content_optimizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_content_optimizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def compare_ai_overview_task(self) -> Task:
return Task(
config=self.tasks_config["compare_ai_overview_task"],
context=[self.query_fanout_summarization_task(), self.ai_overview_extraction_task()],
agent=self.ai_content_optimizer_agent(),
max_retries=3,
markdown=True,
output_file="output/report.md",
)Соответственно, в приведенном выше коде указывается:
- Агент Google Main Query Extractor и его основная задача.
- Агент Google AI Overview Retriever и его основная задача.
- Агент Query Fan-Out Summarizer и его основная задача.
- Агент AI Content Optimizer и его основная задача.
Дополните определения агентов, добавив эти строки в файл agents.yaml:
main_query_extractor_agent:
role: "Google Main Query Extractor"
goal: "Extract the main Google-like search query from a provided query fan-out."
backstory: "You are an AI assistant specialized in parsing query fan-outs and identifying the main, concise search query suitable for Google searches."
ai_overview_retriever_agent:
role: "Google AI Overview Retriever"
goal: "Given a query fan-out, extract the main search query and use it to perform a SERP search on Google to retrieve the AI Overview section."
backstory: "You are an AI SERP search assistant with the ability to retrieve SERPs from Google."
query_fanout_summarizer_agent:
role: "Query Fan-Out Summarizer"
goal: "Generate a concise and structured summary from the provided query fan-out."
backstory: "You are an AI summarization expert focused on condensing query fan-outs into clear, actionable summaries in Markdown format."
ai_content_optimizer_agent:
role: "AI Content Optimizer"
goal: "Compare a summary generated from a query fan-out with the Google AI Overview, identify patterns and similarities, and generate a list of action items based on common topics."
backstory: "You are an AI assistant that analyzes content summaries and AI overviews to find recurring themes, patterns, and actionable insights to optimize content strategies."Добавьте эти строки в файл tasks.yaml:
main_query_extraction_task:
description: |
1. From the provided query fan-out, extract the main search query.
2. Transform the search query into a concise, Google-like keyphrase that users would type into Google.
expected_output: "A short, clear, Google-style search query."
ai_overview_extraction_task:
description: |
1. Use the search query from the previous task to perform a SERP search on Google via the Bright Data SERP Search tool by setting the `brd_ai_overview` argument to 2.
2. Retrieve and return an aggregated Markdown version of the AI Overview section from the search results.
3. After all attempts, if none of the responses contain a Google AI Overview, generate one based on the results from the SERP API, and include a note indicating it was generated.
expected_output: "The AI Overview section Markdown format (either retrieved from the SERP API or generated if unavailable)."
query_fanout_summarization_task:
description: |
1. Generate a summary from the query fan-out received as input.
expected_output: "A Markdown summary containing the main information from the query fan-out."
compare_ai_overview_task:
description: |
1. Compare the previously generated summary with the Google AI Overview provided as input.
2. Identify patterns and similarities (such as sub-topics or recurring themes), as well as differences between the two sources.
3. Generate a list of action items based on the comparison, focusing on topics that appear in both the Google AI Overview and the initial summary.
4. Produce a summary table to compare the patterns, similarities, and differences, containing these columns: Aspect, Query Fan-Out Summary, Google AI Overview, Similarities/Patterns, Differences.
expected_output: |
A comparison report in Markdown that highlights patterns, similarities, and a list of action items derived from the query fan-out.
The document must with a summary table presenting the main similarities and differences, and then all remaining content.Посмотрите, как задача ai_overview_extraction_task включает технические спецификации для получения обзора ИИ в ответе SERP API. Узнайте больше в официальной документации.
Замечательно! Все ваши агенты ИИ в рабочем процессе оптимизации контента GEO теперь созданы. Далее пришло время добавить экипаж для их управления.
Шаг #7: Объедините всех агентов в экипаж
Внутри crew.py определите новую функцию Crew для последовательного запуска агентов:
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)Потрясающе! Класс AiContentOptimizationAgent в файле crew.py завершен. Вам остается только запустить его метод crew() в файле main.py, чтобы запустить рабочий процесс.
Шаг #8: Определите поток выполнения
Переопределите файл main.py на:
- Считайте входной URL из терминала с помощью функции Python
input(). - Используйте предоставленный URL-адрес для создания требуемых входных данных агента.
- Инициализируйте экземпляр
AiContentOptimizationAgentи вызовите его методcrew(), передав объект ввода с заполненным полем{url}. - Запустите рабочий процесс ИИ.
Реализуйте всю вышеописанную логику в файле main.py следующим образом:
#!/usr/bin/env python
import warnings
from ai_content_optimization_agent.crew import AiContentOptimizationAgent
warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd")
def run():
# Read URL from the terminal
url = input("Please enter the URL to process: ").strip()
if not url:
raise ValueError("No URL provided. Exiting.")
# Build the required agent input
inputs = {
"url": url,
}
try:
print(f"Analyzing '${url}' for AI content optimization...")
# Run the multi-agent workflow
AiContentOptimizationAgent().crew().kickoff(inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while running the crew: {e}")Шаг № 9: Проверьте своего агента
В активированной виртуальной среде перед запуском агента установите необходимые зависимости с помощью:
crewai installЗатем запустите свою многоагентную систему оптимизации GEO:
crewai runВам будет предложено ввести URL-адрес:

В этом примере в качестве входных данных мы будем использовать страницу с сайта CrewAI:
https://www.crewai.com/ecosystem
На этой странице представлены основные участники экосистемы агентов искусственного интеллекта.
Запустите агента на этой странице, и вы увидите следующий результат:
GIF выше был ускорен, но это то, что происходит шаг за шагом:
- Агент Title Scraper собирает заголовок страницы с помощью инструмента Bright Data Web Unlocker. В результате получается
"Самая быстрорастущая экосистема агентов искусственного интеллекта"(именно так, как показано на скриншоте страницы). - Google Query Fan-Out Researcher генерирует веерный вывод запросов из инструмента
google_search. При этом в папкеoutput/создается файлquery_fanout.md. - Google Main Query Extractor определяет основной Google-подобный поисковый запрос из веера запросов. Результат –
"рост экосистемы агентов искусственного интеллекта". - Google AI Overview Retriever получает AI Overview для поискового запроса через Bright Data SERP API. Результаты хранятся в файле
ai_overview.md. - Агент Query Fan-Out Summarizer сжимает содержимое веерного вывода запроса в подробный Markdown-конспект в
query_fanout_summary.md. - AI Content Optimizer сравнивает веерную сводку запросов с обзором Google AI для создания окончательного
отчета.md.
По окончании выполнения папка output/ должна содержать следующие четыре файла:
Откройте файл report.md в режиме предварительного просмотра в Visual Studio Code и пролистайте его:

Как видите, он содержит подробный отчет в формате Markdown, который поможет вам оптимизировать содержимое заданной входной страницы для GEO (и SEO)!
Теперь используйте этот агент на URL-адресах веб-страниц, которые вы хотите улучшить для AI ранжирования, и вы улучшите свое GEO и SEO позиционирование.
И вуаля! Миссия выполнена.
Следующие шаги
Созданный выше агент по оптимизации контента с помощью искусственного интеллекта уже достаточно мощный, но его всегда можно улучшить. Одна из идей – добавить еще одного агента в начало рабочего процесса, который будет принимать карту сайта в качестве входных данных (опционально используя regex для фильтрации URL-адресов, например, чтобы выбрать только записи в блоге). Этот агент может передавать URL-адреса существующему рабочему процессу, возможно, параллельно, позволяя одновременно анализировать несколько страниц для оптимизации контента AI.
В общем, имейте в виду, что вы можете экспериментировать с инструкциями в agents.yaml и tasks.yaml, чтобы настроить поведение каждого из шести агентов в соответствии с вашим конкретным случаем использования. Для выполнения этих настроек не требуется никаких продвинутых технических навыков!
Заключение
В этой статье вы узнали, как использовать возможности Bright Data по интеграции ИИ для построения сложного многоагентного рабочего процесса для оптимизации GEO/SEO в CrewAI.
Представленная здесь схема работы с искусственным интеллектом идеально подходит для тех, кто ищет программный способ улучшить содержимое веб-страниц как для традиционных поисковых систем, так и для поиска с помощью искусственного интеллекта.
Для создания подобных расширенных рабочих процессов изучите весь спектр решений для получения, проверки и преобразования живых веб-данных в инфраструктуре Bright Data AI.
Создайте бесплатную учетную запись Bright Data сегодня и начните экспериментировать с нашими веб-инструментами, поддерживающими искусственный интеллект!




