

В этом руководстве вы узнаете:
- Все, что нужно знать для начала работы с Веб-скрейпингом Baidu.
- Самые популярные и эффективные подходы к скраппингу Baidu.
- Как создать собственный парсер Baidu с нуля на Python.
- Как получить результаты поисковых систем с помощью SERP API от Bright Data.
- Как предоставить агентам ИИ доступ к поисковым данным Baidu с помощью Web MCP.
Давайте погрузимся!
Знакомство с Baidu SERP
Прежде чем предпринимать какие-либо действия, потратьте некоторое время на то, чтобы понять, как устроен Baidu SERP (Search Engine Results Page), какие данные он содержит, как получить к ним доступ и так далее.
URL-адреса Baidu SERP и система обнаружения ботов
Откройте Baidu в своем браузере и начните выполнять поиск. Например, найдите “яркие данные”. Вы должны получить URL-адрес, подобный этому:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=bright%20data&fenlei=256&oq=ai%2520model&rsv_pq=970a74b9001542b3&rsv_t=7f84gPOmZQIjrqRcld6qZUI%2FiqXxDExphd0Tz5ialqM87sc5Falk%2B%2F3hxDs&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=12&rsv_sug1=1&rsv_sug7=100&rsv_btype=t&inputT=1359&rsv_sug4=1358Среди всех этих параметров запроса важными являются следующие:
- Базовый URL:
https://www.baidu.com/s. - Параметр поискового запроса:
wd.
Другими словами, вы можете получить те же результаты с более коротким URL:
https://www.baidu.com/s?wd=bright%20data.Кроме того, Baidu структурирует свои URL для пагинации с помощью параметра запроса pn. В частности, на второй странице добавляется &pn=10, а затем на каждой последующей странице это значение увеличивается на 10. Например, если вы хотите отсканировать 3 страницы с ключевым словом “bright data”, ваши SERP URL будут такими:
https://www.baidu.com/s?wd=bright%20data -> страница 1
https://www.baidu.com/s?wd=bright%20data&pn=10 -> страница 2
https://www.baidu.com/s?wd=bright%20data&pn=20 -> страница 3Теперь, если вы попытаетесь получить доступ к такому URL напрямую, используя простой GET HTTP-запрос в HTTP-клиенте, например Postman, вы, скорее всего, увидите что-то вроде этого:
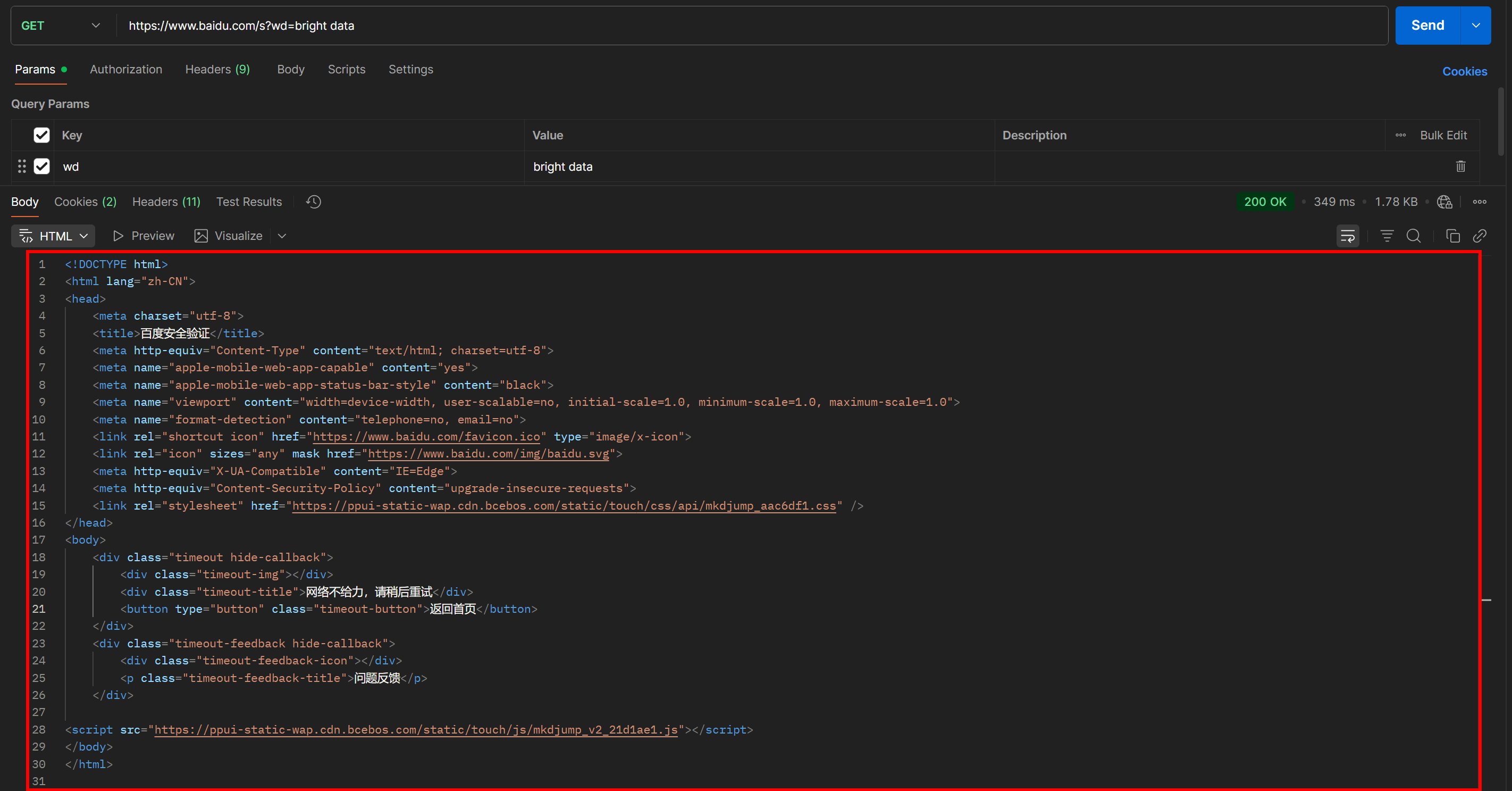
Как вы можете видеть, Baidu возвращает страницу с сообщением “网络不给力,请稍后重试” (что переводится как “Сеть не работает, пожалуйста, повторите попытку позже”, но на самом деле является анти-бот страницей).
Это происходит даже в том случае, если вы включаете заголовок User-Agent, который обычно необходим для задач веб-скрейпинга. Другими словами, Baidu обнаруживает, что ваш запрос автоматизирован, и блокирует его, требуя дополнительной проверки человеком.
Это ясно показывает, что для скрапинга Baidu необходим инструмент автоматизации браузера (например, Playwright или Puppeteer). Простой комбинации HTTP-клиента и HTML-парсера будет недостаточно, так как она будет постоянно вызывать блокировки антибота.
Данные, доступные в поисковой выдаче Baidu
Теперь сосредоточьтесь на SERP Baidu по запросу “яркие данные”, отображаемом в вашем браузере. Вы должны увидеть что-то вроде этого:
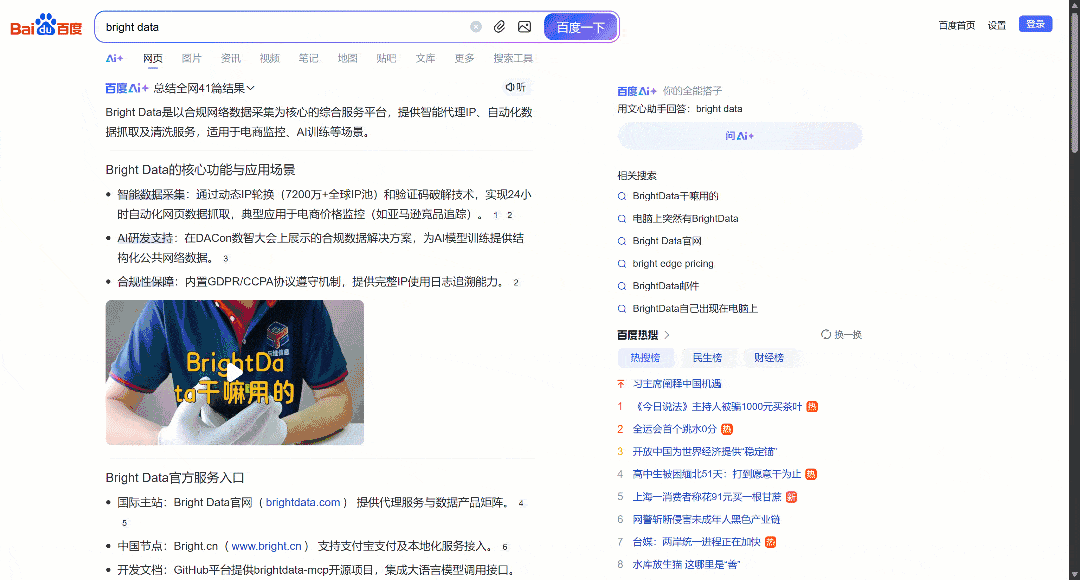
Каждая страница Baidu SERP разделена на две колонки. Левая колонка содержит обзор ИИ (см. раздел “Как соскабливать обзоры ИИ“), за которым следуют результаты поиска. В нижней части этой колонки находится раздел “相关搜索” (“Related Searches”), а под ним – элементы постраничной навигации.
Правая колонка содержит “百度热搜” (“Baidu Hot Searches”), где показаны трендовые или наиболее популярные темы на Baidu.(Примечание: эти трендовые результаты не обязательно связаны с вашими поисковыми запросами).
Это все основные данные, которые можно извлечь из поисковой выдачи Baidu. В этом руководстве мы сосредоточимся только на результатах поиска, которые, как правило, являются самой важной информацией!
Основные подходы к скраппингу Baidu
Существует несколько способов получения данных о результатах поиска Baidu. Сравните основные из них в сводной таблице ниже:
| Подход | Сложность интеграции | Требования | Ценообразование | Риск блоков | Масштабируемость |
|---|---|---|---|---|---|
| Создание собственного парсера | Средний/Высокий | Навыки программирования на Python + навыки автоматизации браузера | Бесплатно (может потребоваться анти-бот браузеры, чтобы избежать блокировки) | Возможно | Ограничено |
| Использование SERP API компании Bright Data | Низкий | Любой HTTP-клиент | Платный | Нет | Неограниченное количество |
| Интеграция сервера Web MCP | Низкая | Фреймворк или платформа для агентов ИИ, поддерживающая MCP | Доступен бесплатный уровень, затем платный | Нет | Неограниченное количество |
Вы узнаете, как реализовать каждый из подходов, по мере прохождения руководства!
Примечание 1: Независимо от выбранного вами метода, целевой поисковый запрос, используемый в этом руководстве, будет “яркие данные”. Это означает, что вы увидите, как получить результаты поиска Baidu именно по этому запросу.
Примечание 2: Мы будем считать, что у вас уже установлен Python и вы знакомы с веб-скриптами на Python.
Подход № 1: Создание собственного парсера
Используйте фреймворк для автоматизации браузера или HTTP-клиент в сочетании с парсером HTML, чтобы создать парсер Baidu с нуля.
👍 Плюсы:
- Полный контроль над логикой парсинга данных, возможность извлекать именно то, что вам нужно.
- Гибкость и возможность настройки под ваши нужды.
👎 Минусы:
- Требует усилий по настройке, кодированию и обслуживанию.
- При масштабном использовании может столкнуться с блокировкой IP-адресов, CAPTCHA, ограничениями скорости и другими проблемами веб-скрейпинга.
Подход № 2: Использование SERP API от Bright Data
Используйте SERP API от Bright Data– премиум-решение, позволяющее запрашивать запросы к Baidu (и другим поисковым системам) через простую в обращении конечную точку HTTP. Оно обеспечивает все меры по борьбе с ботами и масштабирование. Эти и многие другие функции делают его одним из лучших SERP API и поисковых API на рынке.
👍 Плюсы:
- Высокая масштабируемость и надежность, опирающаяся на сеть прокси из 150M+ IP.
- Никаких запретов по IP или проблем с CAPTCHA.
- Работает с любым HTTP-клиентом (включая визуальные инструменты вроде Postman или Insomnia).
👎 Минусы:
- Платный сервис.
Подход № 3: Интеграция веб-сервера MCP
Предоставьте агенту ИИ бесплатный доступ к результатам поиска Baidu с помощью Web MCP от Bright Data, который подключается к SERP API и Web Unlocker под капотом Bright Data.
👍 Плюсы:
- Интеграция в рабочие процессы ИИ и агентов.
- Доступен бесплатный уровень.
- Не требуется логика парсинга данных (об этом позаботится ИИ).
👎 Минусы:
- Ограниченный контроль над поведением LLM.
Подход №1: Создание собственного парсера Baidu на Python с помощью Playwright
Выполните следующие шаги, чтобы создать собственный скрипт веб-скрейпинга Baidu на Python.
Как упоминалось ранее, для скрапинга Baidu требуется автоматизация браузера, поскольку простые HTTP-запросы будут заблокированы. В этом разделе руководства мы будем использовать Playwright, одну из лучших библиотек для автоматизации браузера в Python.
Шаг #1: Настройте ваш проект для скрапинга
Начните с открытия терминала и создания новой папки для вашего проекта парсера Baidu:
mkdir baidu-scraperПапка baidu-scraper/ будет содержать все файлы для вашего проекта скраппинга.
Далее перейдите в каталог проекта и создайте в нем виртуальное окружение Python:
cd baidu-scraper
python -m venv .venvТеперь откройте папку с проектом в выбранной вами среде разработки Python. Мы рекомендуем Visual Studio Code с расширением Python или PyCharm Community Edition.
Добавьте новый файл с именем scraper.py в корень каталога проекта. Структура вашего проекта должна выглядеть следующим образом:
baidu-scraper/
├── .venv/
└── scraper.pyЗатем активируйте виртуальную среду в терминале. В Linux или macOS выполните команду:
source .venv/bin/activateАналогично, в Windows выполните:
.venv/Scripts/activateПосле активации виртуальной среды установите Playwright с помощью pip через пакет playwright:
pip install playwrightЗатем установите необходимые зависимости Playwright (например, двоичные файлы браузера):
python -m playwright installГотово! Теперь ваша среда Python готова к созданию вашего парсера Baidu.
Шаг №2: Инициализация сценария Playwright
В файле scraper.py импортируйте Playwright и используйте его синхронный API для запуска управляемого экземпляра браузера Chromium:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Инициализируем экземпляр Chromium в режиме headless
browser = p.chromium.launch(headless=True) # установите headless=False, чтобы увидеть браузер для отладки
page = browser.new_page()
# Логика скрапинга...
# Закрываем браузер и освобождаем его ресурсы
browser.close()Приведенный выше фрагмент составляет основу вашего парсера Baidu.
Параметр headless=True указывает Playwright на запуск Chromium без видимого графического интерфейса. По результатам тестирования, эта настройка не вызывает обнаружения ботов Baidu. Таким образом, она хорошо подходит для скраппинга. Однако при разработке или отладке кода лучше установить headless=False, чтобы можно было наблюдать за происходящим в браузере в реальном времени.
Отлично! Теперь подключитесь к SERP Baidu и начните получать результаты поиска.
Шаг № 3: Посещение целевой поисковой системы
Как было показано выше, создание URL-адреса Baidu SERP не представляет собой ничего сложного. Вместо того чтобы поручать Playwright имитировать взаимодействие с пользователем (например, вводить текст в поле поиска и отправлять его), гораздо проще создать URL SERP программно и указать Playwright перейти непосредственно к нему.
Вот логика построения URL Baidu SERP для поискового запроса “bright data”:
# Базовый URL страницы поиска Baidu
base_url = "https://www.baidu.com/s"
# Ключевое слово/ключевая фраза для поиска
search_query = "bright data"
params = {"wd": search_query}
# Построение URL-адреса поисковой выдачи Baidu
url = f"{base_url}?{urlencode(params)}"Не забудьте импортировать функцию urlencode() из стандартной библиотеки Python:
from urllib.parse import urlencodeТеперь поручите браузеру, управляемому Playwright, перейти по сгенерированному URL с помощью функции goto():
page.goto(url)Если вы запустите скрипт в режиме headful (с headless=False) в отладчике, то увидите, как в окне Chromium загрузится страница Baidu SERP:
Потрясающе! Это именно тот SERP, который вы будете искать дальше.
Шаг № 4: Подготовка к соскабливанию всех результатов SERP
Прежде чем погрузиться в логику скраппинга, необходимо изучить структуру SERP Baidu. Во-первых, поскольку страница содержит множество элементов результатов поиска, вам понадобится список для хранения извлеченных данных. Поэтому начните с инициализации пустого списка:
serp_results = []Затем откройте целевую страницу Baidu SERP в окне инкогнито (для обеспечения чистоты сеанса) в вашем браузере:
https://www.baidu.com/s?wd=bright%20dataЩелкните правой кнопкой мыши на одном из элементов результатов поиска и выберите “Inspect”, чтобы открыть DevTools браузера:
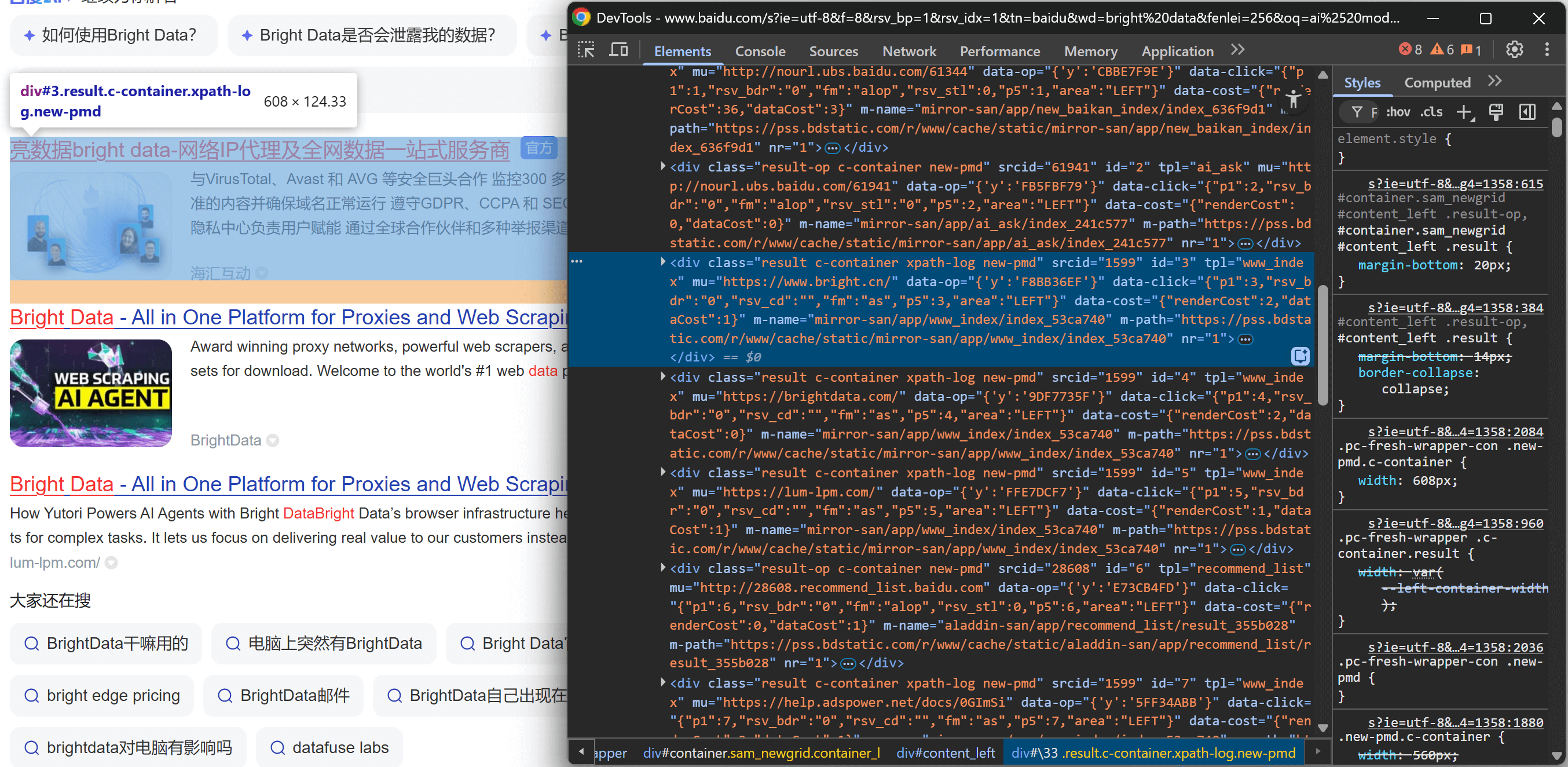
Посмотрев на структуру DOM, вы заметите, что каждый элемент результатов поиска имеет класс result. Это означает, что вы можете выбрать все результаты поиска на странице с помощью CSS-селектора .result.
Примените этот селектор в своем сценарии Playwright:
search_result_elements = page.locator(".result")Примечание: Если вы не знакомы с этим синтаксисом, прочитайте наше руководство по веб-скрейпингу в Playwright.
Наконец, выполните итерацию по каждому выбранному элементу:
for search_result_element in search_result_elements.all():
# Логика парсинга данных...Приготовьтесь применить логику парсинга данных для извлечения результатов поиска Baidu и заполнения списка serp_results:
Отлично! Теперь вы близки к завершению рабочего процесса по извлечению результатов поиска Baidu.
Шаг № 5: Соскребаем данные о результатах поиска
Осмотрите HTML-структуру элемента SERP на странице результатов Baidu. На этот раз сосредоточьтесь на его вложенных элементах, чтобы определить данные, которые вы хотите извлечь.
Начните с изучения раздела заголовка:
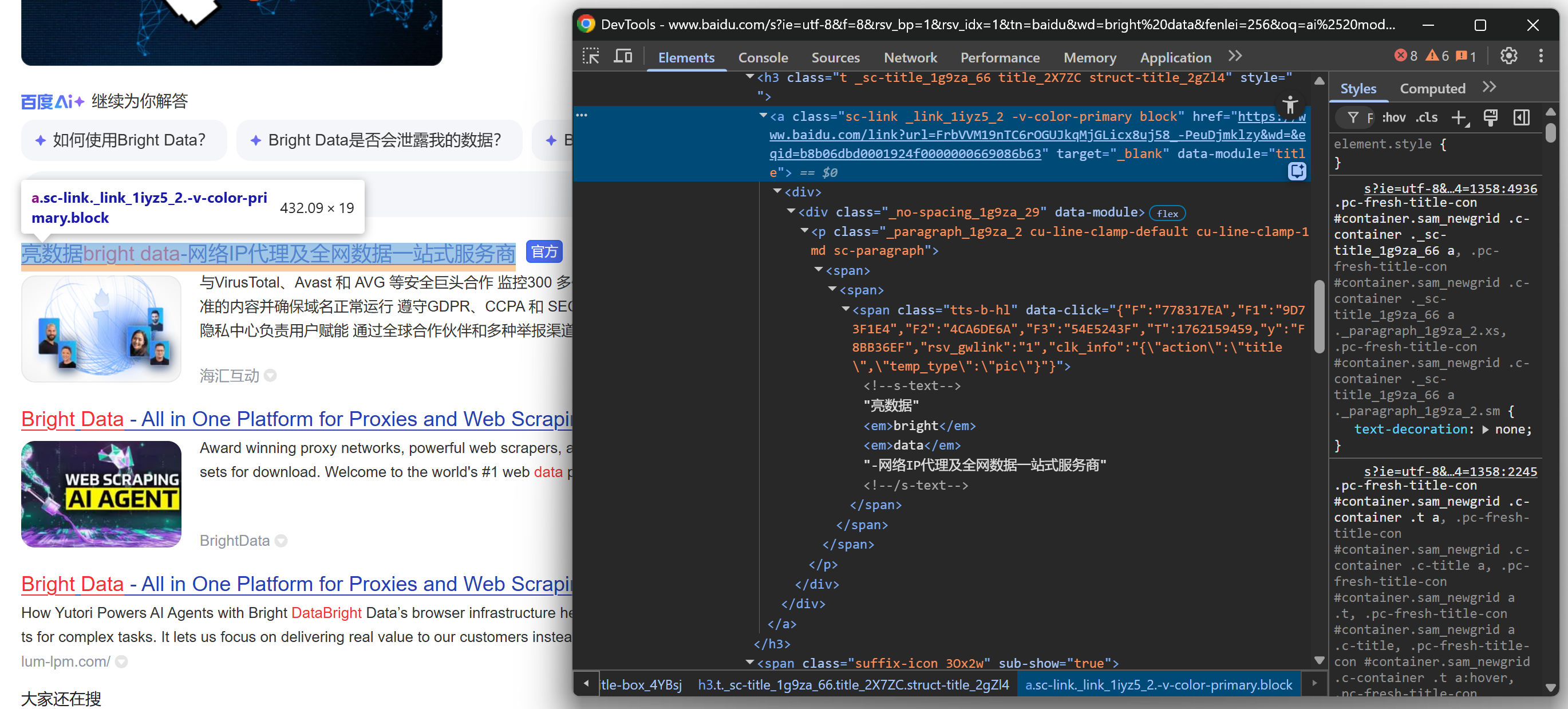
Продолжите изучение, заметив, что некоторые результаты отображают метку “官方” (“Официальный”):
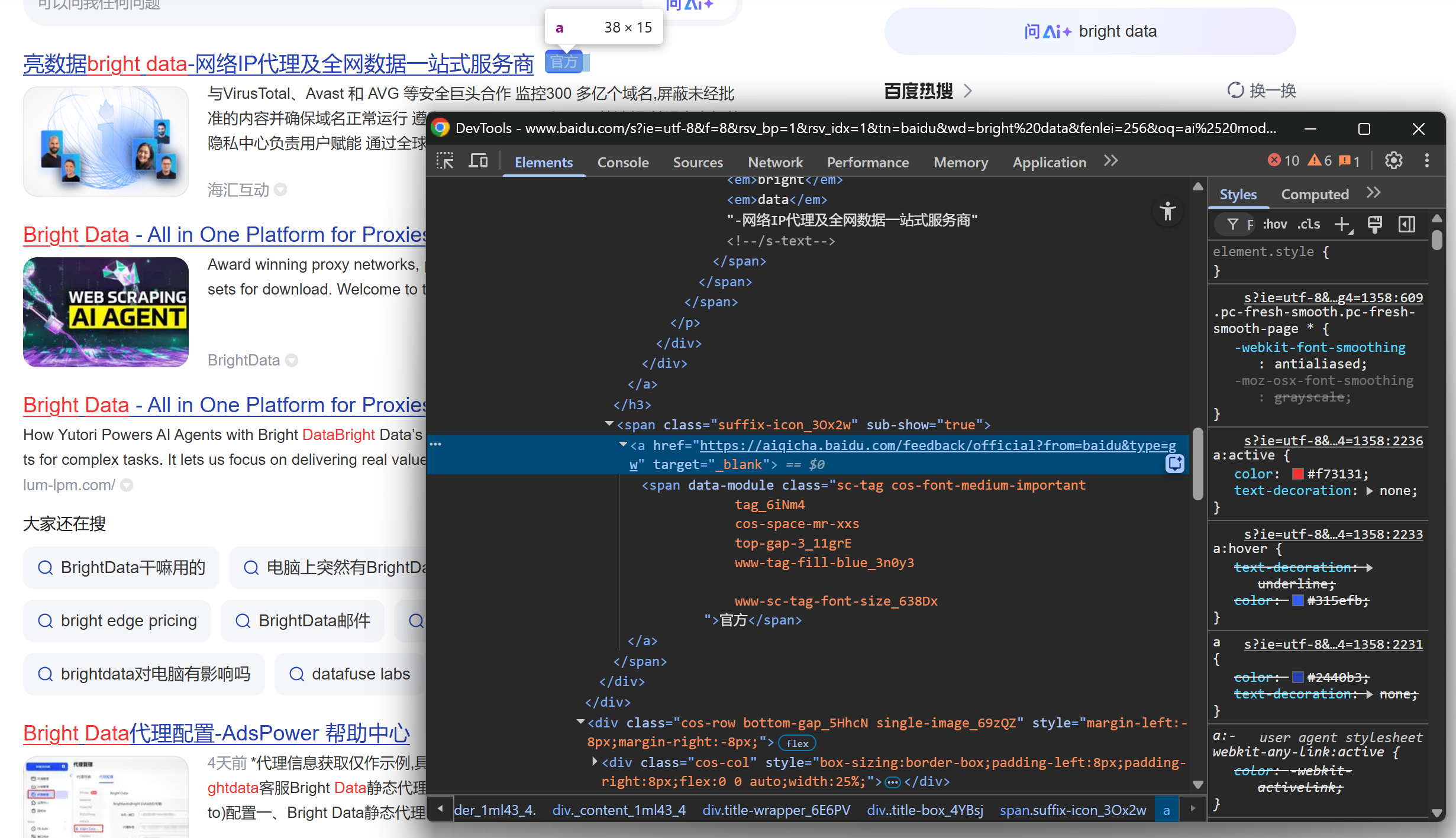
Затем сосредоточьтесь на изображении результатов SERP:
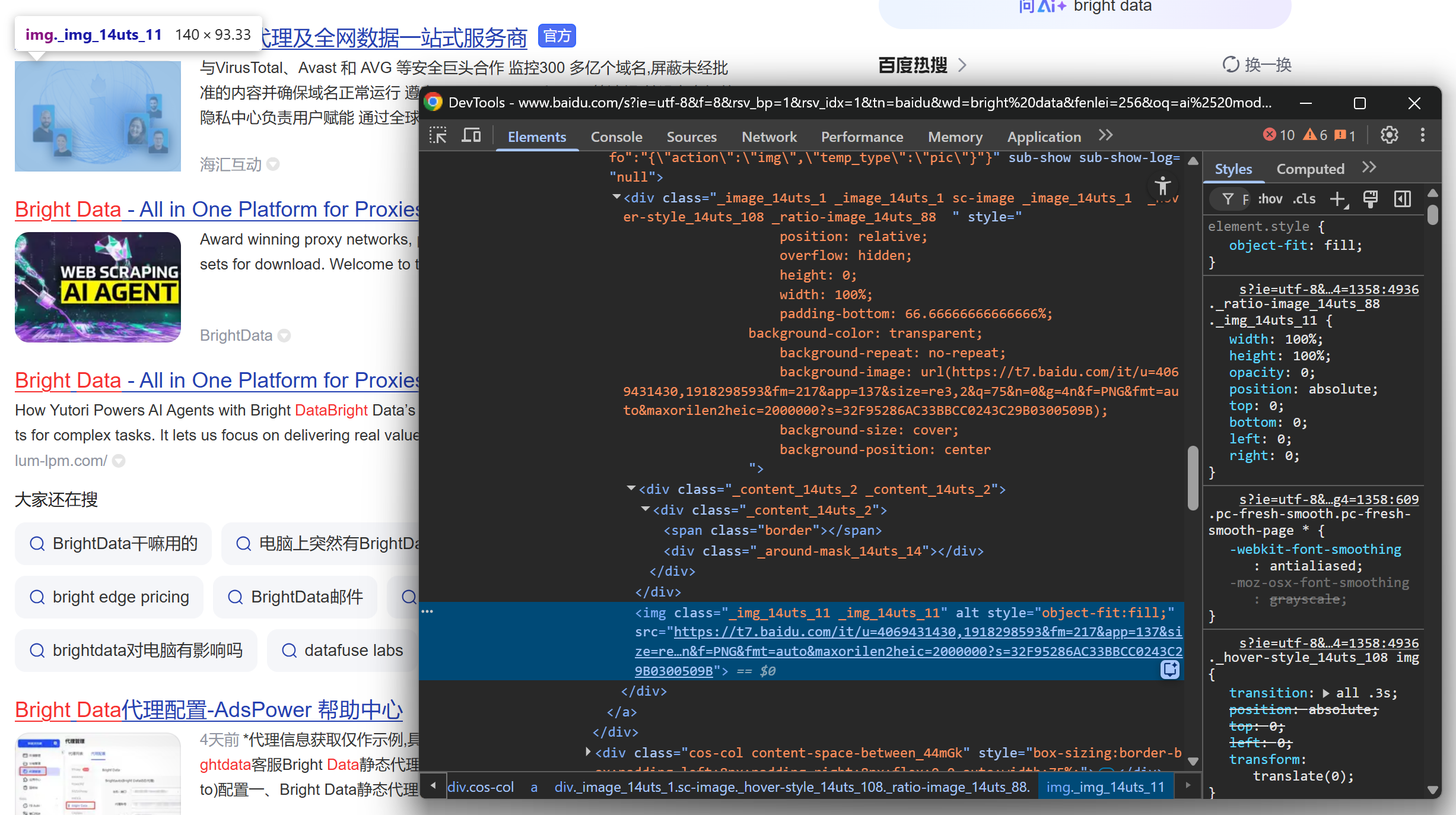
И в завершение посмотрите на описание/аннотацию:
Из этих вложенных элементов можно извлечь следующие данные:
- URL-адрес результата из атрибута
hrefэлемента.sc-link. - Заголовок результата из текста элемента
.sc-link. - Описание/реферат результата из текста
[data-module='abstract']. - Изображение результата из атрибута
srcэлементаimgвнутри.sc-image. - Фрагмент результата из текста
.result__snippet. - Официальный ярлык в элементе
<a>,hrefкоторого начинается сhttps://aiqicha.baidu.com/feedback/official(если присутствует).
Используйте API локатора Playwright для выбора элементов и извлечения нужных данных:
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0Помните, что не все элементы SERP одинаковы. Чтобы избежать ошибок, всегда проверяйте, существует ли элемент (.count() > 0), прежде чем обращаться к его атрибутам или тексту.
Потрясающе! Вы только что определили логику парсинга данных Baidu SERP.
Шаг № 6: Сбор данных о результатах поиска
Завершите цикл for, создав словарь для каждого результата поиска и добавив его в список serp_results:
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"image": image.strip() if image else "",
"official": official
}
serp_results.append(serp_result)Замечательно! Логика работы с Веб-скрейпингом Baidu завершена. Осталось экспортировать полученные данные для дальнейшего использования.
Шаг № 7: Экспорт результатов поиска в CSV
На этом этапе результаты поиска Baidu хранятся в списке Python. Чтобы сделать эти данные пригодными для использования другими командами или инструментами, экспортируйте их в CSV-файл с помощью встроенной в Python библиотеки csv:
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Динамически считываем имена полей из первого элемента
fieldnames = list(serp_results[0].keys())
# Инициализация CSV-писателя
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Напишите заголовок и заполните выходной CSV-файл
writer.writeheader()
writer.writerows(serp_results)Не забудьте импортировать csv:
import csvТаким образом, ваш парсер Baidu сгенерирует выходной файл с именем baidu_serp_results.csv, содержащий все результаты поиска в формате CSV. Миссия выполнена
Шаг № 8: Соберите все вместе
Окончательный код, содержащийся в файле scraper.py, выглядит следующим образом:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
импортировать csv
# Где хранить полученные данные
serp_results = []
with sync_playwright() as p:
# Инициализируем экземпляр Chromium в режиме headless
browser = p.chromium.launch(headless=True) # установите headless=False, чтобы увидеть браузер для отладки
page = browser.new_page()
# Базовый URL страницы поиска Baidu
base_url = "https://www.baidu.com/s"
# Ключевое слово/ключевая фраза для поиска
search_query = "яркие данные"
params = {"wd": search_query}
# Построение URL-адреса поисковой выдачи Baidu
url = f"{base_url}?{urlencode(params)}"
# Переход на целевую страницу в браузере
page.goto(url)
# Выберите все элементы результатов поиска
search_result_elements = page.locator(".result")
for search_result_element in search_result_elements.all():
# Логика парсинга данных
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0
# Наполните новый объект результатов поиска данными, полученными в результате поиска
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"image": image.strip() if image else "",
"official": official
}
# Добавляем в список отсканированный результат SERP Baidu
serp_results.append(serp_result)
# Закройте браузер и освободите его ресурсы
browser.close()
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Динамически считываем имена полей из первого элемента
fieldnames = list(serp_results[0].keys())
# Инициализация CSV-писателя
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Напишите заголовок и заполните выходной CSV-файл
writer.writeheader()
writer.writerows(serp_results)Вот это да! Всего за 70 строк кода вы создали скрипт для сбора данных Baidu.
Протестируйте скрипт с помощью:
python scraper.pyНа выходе вы получите файл baidu_serp_results.csv в папке проекта. Откройте его, чтобы увидеть структурированные данные, извлеченные из результатов поиска Baidu:

Примечание: Чтобы извлечь дополнительные результаты, повторите процесс, используя параметр запроса pn для обработки пагинации.
И вуаля! Вы успешно преобразовали неструктурированные результаты поиска Baidu в структурированный CSV-файл.
[Дополнительно] Используйте службу удаленного браузера, чтобы избежать блокировок
Парсер, показанный выше, отлично подходит для небольших проектов, но он не будет хорошо масштабироваться. Baidu начнет блокировать запросы, если увидит слишком много трафика с одного и того же IP, возвращая страницы ошибок или проблем. Запуск множества локальных экземпляров Chromium также требует больших ресурсов (много оперативной памяти) и трудно координируется.
Более масштабируемым и простым в управлении решением является подключение экземпляра Playwright к удаленному браузерно-сервисному решению для скрапинга, например Bright Data’s Browser API. Это обеспечивает автоматическую ротацию прокси, обработку CAPTCHA и обход антиботов, реальные экземпляры браузеров, чтобы избежать проблем с отпечатками пальцев, и неограниченное масштабирование.
Следуйте руководству по настройке Bright Data Browser API, и в итоге вы получите строку подключения WSS, которая будет выглядеть следующим образом:
wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222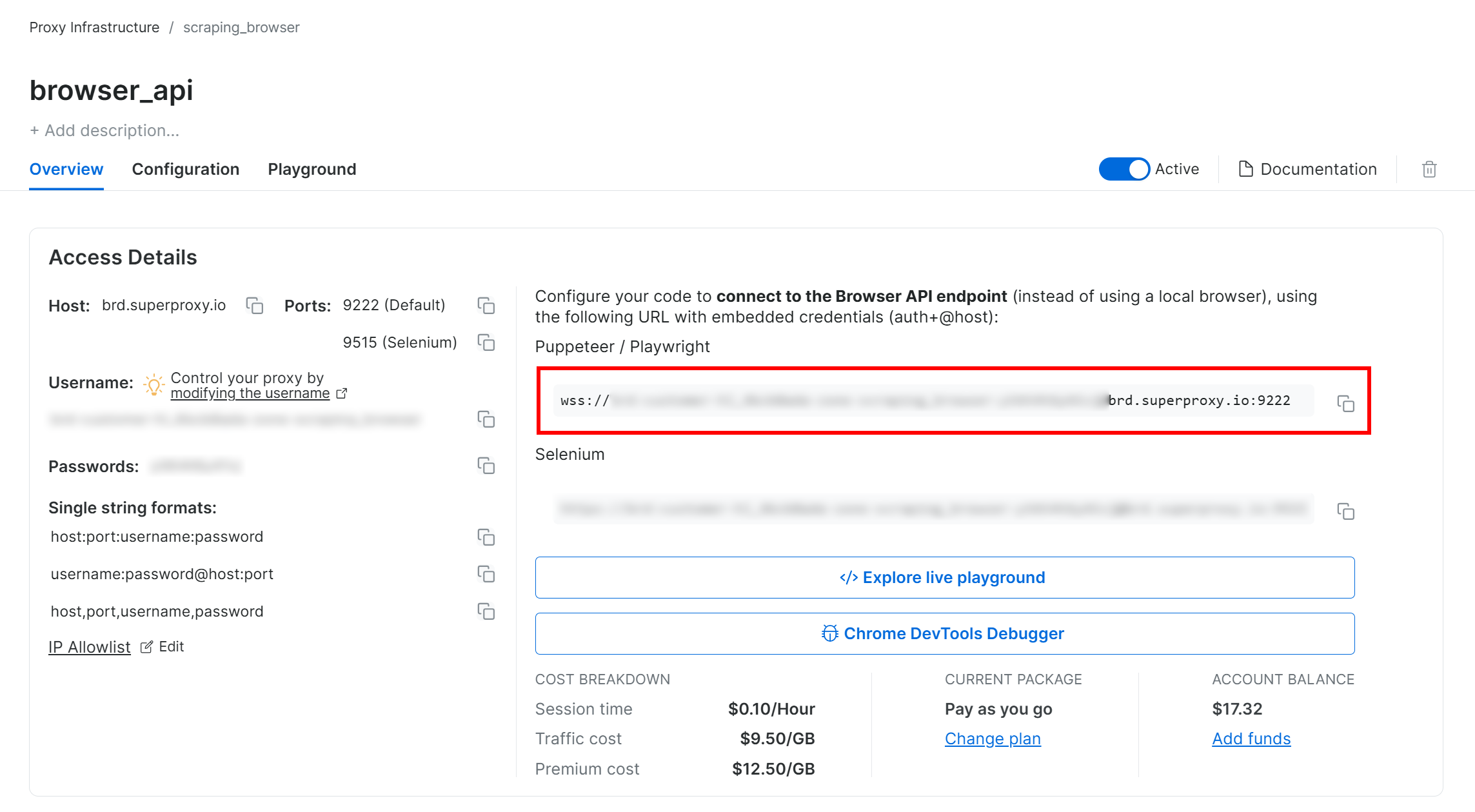
Используйте этот WSS URL для подключения Playwright к удаленным экземплярам браузера через CDP(Chrome DevTools Protocol):
wss_url = "wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222"
браузер = playwright.chromium.connect_over_cdp(wss_url)
page = browser.new_page()
# ...Теперь ваши запросы Playwright к Baidu будут направляться через удаленную инфраструктуру Browser API компании Bright Data, которая опирается на 150-миллионную сеть резидентных прокси и реальные экземпляры браузеров. Это гарантирует свежий IP-адрес для каждой сессии и реалистичный отпечаток браузера.
Подход № 2: Использование SERP API от Bright Data
В этой главе мы рассмотрим, как использовать универсальный SERP API от Bright Data для программного получения результатов поиска.
Примечание: Для простоты мы предполагаем, что у вас уже есть проект на Python с установленной библиотекойrequests.
Шаг № 1: Настройте зону SERP API в вашем аккаунте Bright Data
Начнем с настройки продукта SERP API в Bright Data для поиска результатов поиска Baidu. Сначала создайте учетную запись Bright Data – или войдите в нее, если она у вас уже есть.
Для более быстрой настройки вы можете обратиться к официальному руководству Bright Data по SERP API “Быстрый старт”. В противном случае продолжайте выполнять следующие шаги.
После входа в систему перейдите в раздел “Прокси и скрапинг” в своей учетной записи Bright Data, чтобы перейти на страницу продуктов:
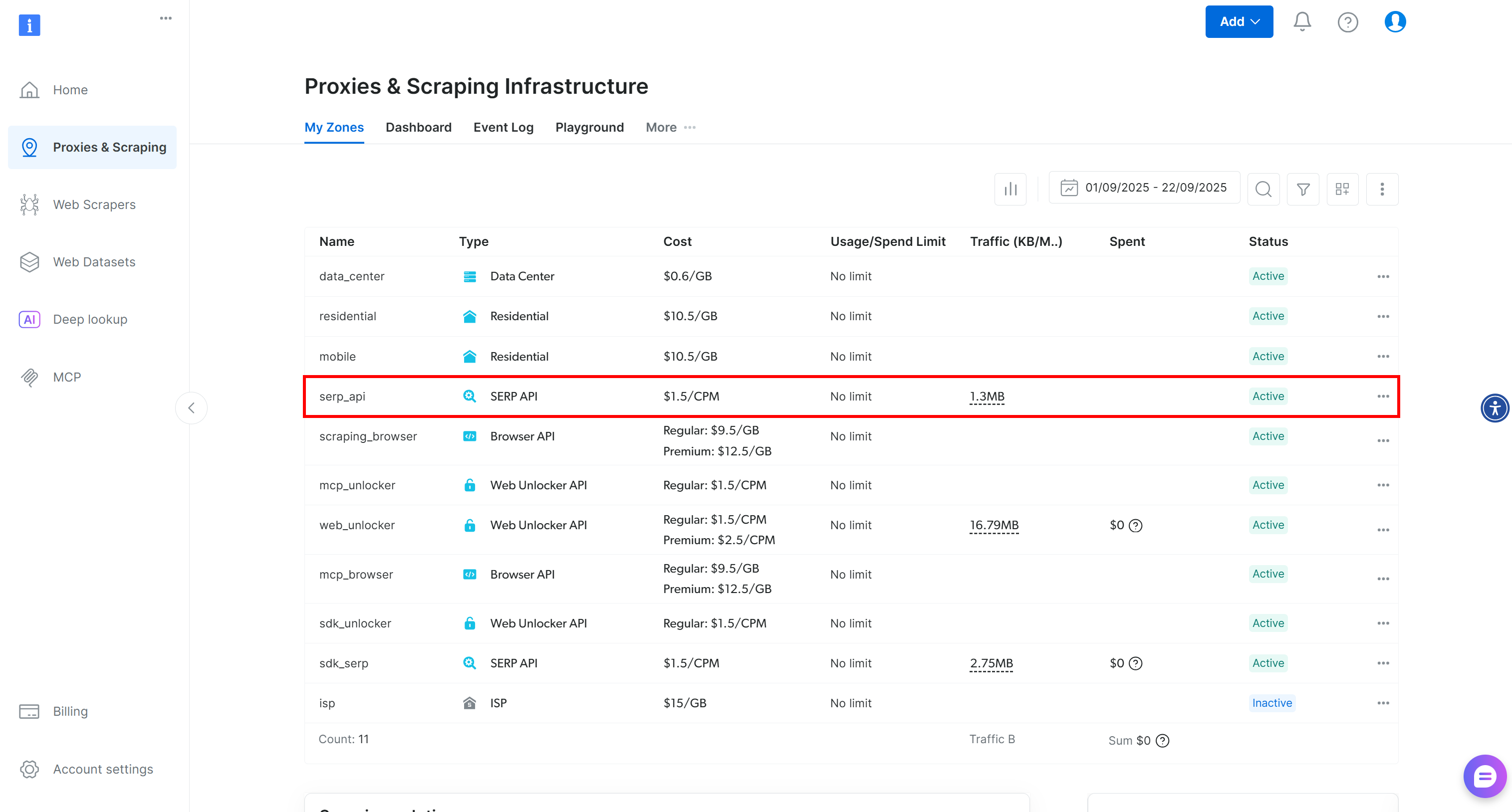
Посмотрите на таблицу “Мои зоны”, где перечислены настроенные вами продукты Bright Data. Если активная зона SERP API уже существует, вы готовы к работе. Просто скопируйте имя зоны (например, serp_api), поскольку оно понадобится вам позже.
Если зоны SERP API не существует, прокрутите страницу вниз до раздела “Решения для скрапинга” и нажмите “Создать зону” на карточке “SERP API”:
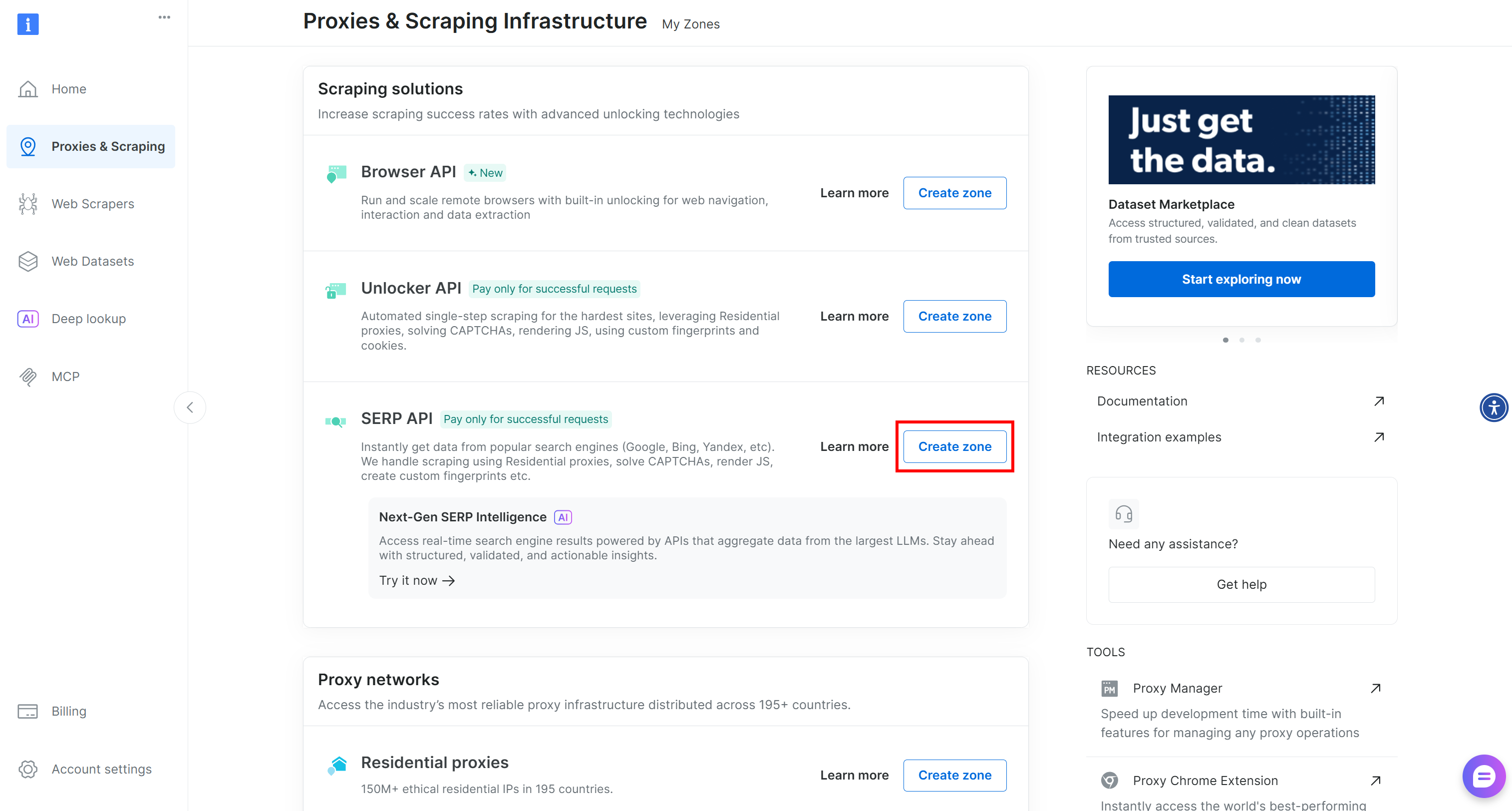
Дайте вашей зоне имя (например, serp-api) и нажмите кнопку “Добавить”:
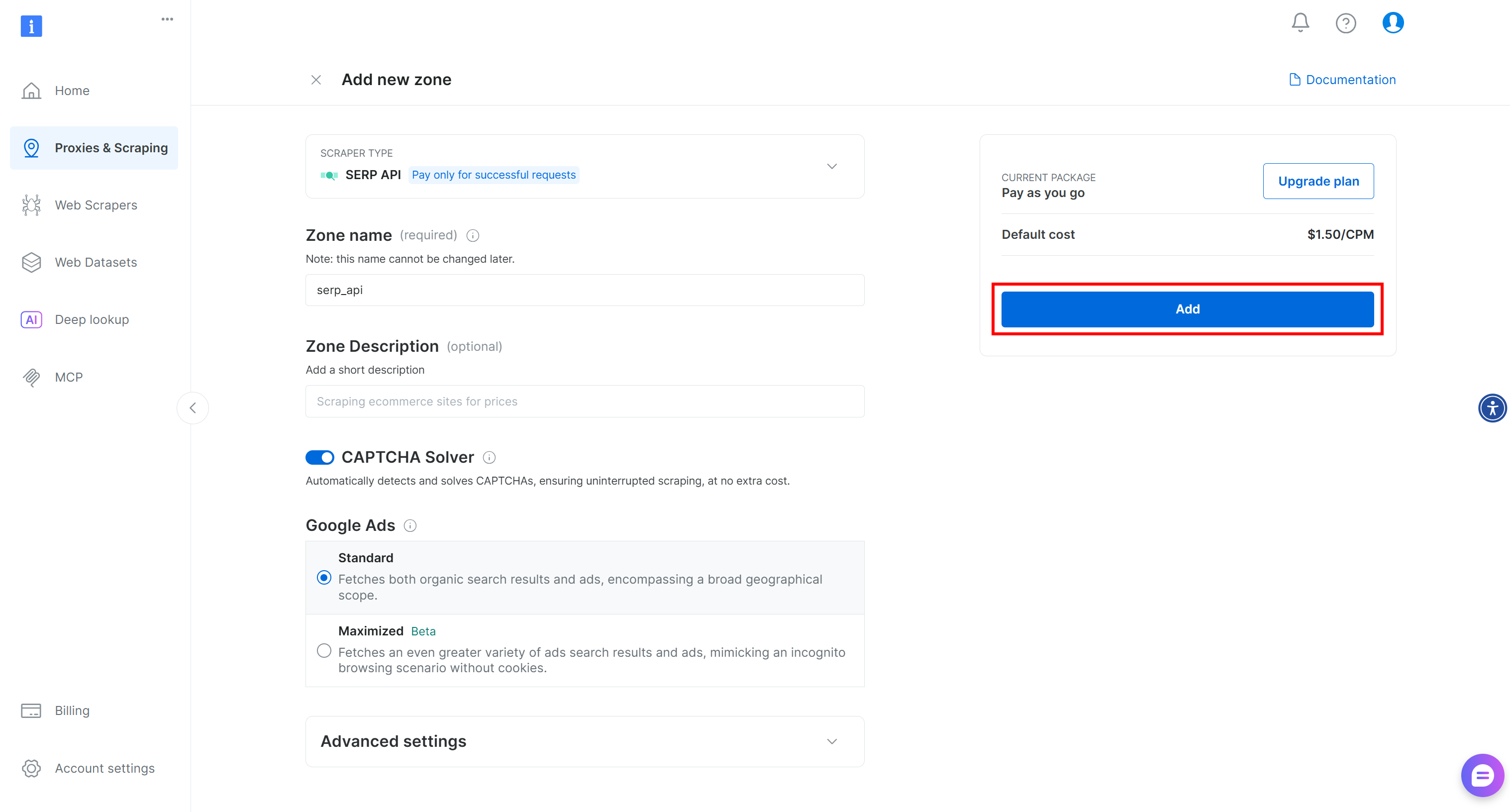
Затем перейдите на страницу продукта зоны и убедитесь, что она включена, переключив переключатель на “Активно”:
Отлично! Теперь ваша зона SERP API от Bright Data успешно настроена и готова к использованию.
Шаг № 2: Получение ключа API Bright Data
Рекомендуемый способ аутентификации запросов к SERP API – это использование ключа API Bright Data. Если вы еще не сгенерировали его, следуйте официальному руководству Bright Data по созданию ключа API.
При выполнении POST-запроса к SERP API включите свой ключ API в заголовок авторизации следующим образом:
"Авторизация: Bearer <YOUR_BRIGHT_DATA_API_KEY>".Потрясающе! Теперь у вас есть все необходимое для вызова SERP API Bright Data из Python-скрипта с помощью requests илилюбого другого Python HTTP-клиента.
Теперь давайте соберем все вместе!
Шаг № 3: Вызов SERP API
Воспользуйтесь SERP API Bright Data в Python, чтобы получить результаты поиска Baidu по ключевому слову “bright data”:
# pip install requests
импортировать запросы
from urllib.parse import urlencode
# Учетные данные Bright Data (TODO: замените их на свои значения)
bright_data_api_key = "< ВАШ_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>" # (например, "serp_api")
# Базовый URL страницы поиска Baidu
base_url = "https://www.baidu.com/s"
# Ключевое слово/ключевая фраза для поиска
search_query = "яркие данные"
params = {"wd": search_query}
# Построение URL-адреса Baidu SERP
url = f"{base_url}?{urlencode(params)}"
# Отправляем POST-запрос к SERP API компании Bright Data
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Авторизация": f "Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"Зона": bright_data_serp_api_zone_name,
"url": url,
"format": "raw"
}
)
# Получение полностью отрендеренного HTML
html = response.text
# Логика парсинга здесь...Для другого примера посмотрите проект “Bright Data SERP API Python Project” на GitHub.
Bright Data SERP API обрабатывает рендеринг JavaScript, интегрируется с прокси-сетью для автоматической ротации IP-адресов и управляет мерами по борьбе со скрейпингом, такими как отпечатки пальцев браузера, CAPTCHA и другими. Это означает, что вы не столкнетесь со страницей ошибки “网络不给力,请稍后重试” (“Сеть не работает, пожалуйста, повторите попытку позже”), которую вы обычно получаете при скраппинге Baidu с помощью базового HTTP-клиента, как запросы.
Проще говоря, переменная html содержит полностью отрисованную страницу результатов поиска Baidu. Убедитесь в этом, распечатав HTML с помощью команды:
print(html)Вы получите результат, как показано ниже:
Отсюда вы можете разобрать HTML, как показано в первом подходе, чтобы извлечь нужные вам данные поиска Baidu. Как и было обещано, Bright Data SERP API предотвращает блокировку и позволяет достичь неограниченной масштабируемости!
Подход № 3: Интеграция веб-сервера MCP
Помните, что SERP API (и многие другие продукты Bright Data) также доступны через инструмент search_engine в Bright Data Web MCP.
Этот сервер Web MCP с открытым исходным кодом предоставляет ИИ удобный доступ к решениям Bright Data по поиску веб-скрейпинга, включая веб-скрейпинг Baidu. В частности, инструменты search_engine и scrape_as_markdown доступны в бесплатном уровне Web MCP, что дает вам возможность бесплатно использовать их в агентах ИИ или рабочих процессах.
Чтобы интегрировать Web MCP в ваше решение по ИИ, вам понадобится только локально установленный Node.js и конфигурационный файл следующего вида:
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<ВАШ_BRIGHT_DATA_API_KEY>"
}
}
}
}Например, эта настройка работает с Claude Desktop и Code (и многими другими библиотеками и решениями для ИИ). Ознакомьтесь с другими интеграциями в документации.
Кроме того, вы можете подключиться через удаленный сервер Bright Data без каких-либо локальных предварительных условий.
Благодаря этой интеграции ваши рабочие процессы или агенты на базе ИИ смогут автономно получать данные SERP из Baidu (или других поддерживаемых поисковых систем) и обрабатывать их на лету.
Заключение
В этом руководстве вы рассмотрели три рекомендуемых метода скрапинга Baidu:
- Использование собственного парсера.
- Использование SERP API Baidu.
- С помощью Bright Data Web MCP.
Как было показано, наиболее надежным способом масштабного скрапинга Baidu и предотвращения блокировок является использование структурированного решения для скрапинга. Оно должно быть подкреплено передовой технологией обхода ботов и надежной сетью прокси, такой как продукты Bright Data.
Создайте бесплатную учетную запись Bright Data и начните изучать наши решения для скрапинга уже сегодня!




