

Препятствием №1 для агентского веба по-прежнему является “старый веб” – динамический, перегруженный JS, CAPTCHA, платные стены, всплывающие окна, дросселирование и беспорядочный HTML, который агенты не могут надежно разобрать. Именно поэтому мы создали Web MCP: чтобы агенты могли получать доступ и взаимодействовать со старым вебом. Именно поэтому мы решили сделать дополнительный шаг и предоставить основные возможности бесплатно.
Как ведущий разработчик и сопровождающий Web MCP компании Bright Data, мы сразу поняли, что это не “обычный” MCP. Большинство MCP-серверов оборачивают один SaaS/API (например, Gmail, HubSpot, GitHub), что представляет собой аккуратную, структурированную проблему: одна схема и модель авторизации, предсказуемые входы и выходы, повторяющиеся действия с документированными ошибками.
Но Web MCP охватывает весь интернет.
Он интегрируется с открытым вебом, где каждый сайт – это свой собственный смещаемый “API”, страницы рендерятся на стороне клиента, появляется бесконечная прокрутка, а CAPTCHA или дросселирование могут менять поведение от минуты к минуте. Web MCP поглощает этот хаос с помощью устойчивой навигации и выборки, управляемых сессий и контроля регионов, а также извлечения, которое очищает беспорядочный HTML в пригодный для использования JSON/Markdown.
Что такое Web MCP
Web MCP позволяет вашему агенту просматривать реальные веб-страницы. Он обрабатывает страницы с JS-рендерингом и CAPTCHA, а затем возвращает чистый текст, который может использовать ваша модель. Считайте это “доступом в Интернет для агентов”, упакованным в инструменты MCP.
Почему бесплатно? Бесплатный тарифный план дает вам все, что нужно, чтобы начать создавать и тестировать без лишних затрат (плюс достаточно для повседневного использования). Он включает 5 000 запросов в месяц для режима Rapid, открывающего два повседневных инструмента: результаты поиска и “соскоб в формате Markdown”. Этого вполне достаточно для большинства агентов, чтобы находить страницы и надежно их читать.
Вы можете перейти на Pro позже, когда будете готовы к кликам, прокрутке, скриншотам и структурированному извлечению JSON (установите PRO_MODE в локальной версии или добавьте &pro=1 в удаленной).
Быстрый старт и документация
Учебные пособия
- Веб-скраппинг с помощью серверов MCP (как сделать)
- Прохождение Gemini CLI + Web MCP
- OpenAI Codex CLI + Web MCP
Проектирование сервера MCP в масштабе сети
В то время как “обычные” MCP предлагают детерминированные инструменты на основе фиксированных API, Web MCP предлагает отказоустойчивые инструменты в хаотичном интернете, чтобы агенты могли действовать надежно. Правильное решение этой задачи сопряжено как с большими инженерными проблемами, так и с реальной ответственностью.
Доставка MCP для всей сети означала, что мы должны были соответствовать трем строгим стандартам:
- Будьте легкими и умными, чтобы не тратить жетоны только на подключение.
- Масштабируемость и производительность – чтобы он работал при производственных нагрузках, а не только в демонстрационных версиях.
- Обеспечьте безопасность и соответствие нормативным требованиям, чтобы команды могли развертывать с уверенностью.
1) Быть легкими и умными (эффективность токенов без отупения)
Изначально мы поставляли MCP с 60+ инструментами, но первые пользователи сообщили нам ценную информацию: ~90% обращений агентов использовали только два инструмента – поиск и scrape-as-markdown.
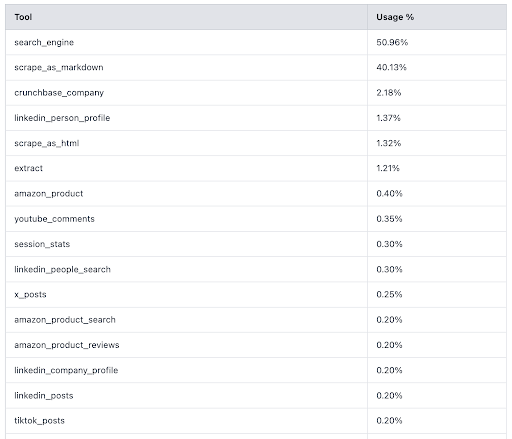
Тем не менее, типичные MCP перечисляют десятки инструментов. В MCP первым шагом является /list/tools. При 60+ инструментах одно только это рукопожатие стоило ~17 000 жетонов 🤯, прежде чем выполнялась какая-либо реальная работа. Кроме того, это путало модели и приводило к неправильному выбору инструментов, что делало работу медленнее и менее последовательной.
Мы узнали, что стоимость токена во время рукопожатия отпугивает пользователей гораздо больше, чем задержка при выполнении, и что обработка CAPTCHA – это ставка на стол: без нее слишком много реальных страниц просто не работали.
Наш ответ: два режима.
Быстрый режим (по умолчанию)
Ровно два инструмента:
search_engine→ возвращает результаты SERPscrape_as_markdown→ извлекает любой URL в виде чистого, дружественного LLM Markdown
Почти нулевое рукопожатие: минимум метаданных инструмента, минимум путаницы
Охватывает подавляющее большинство задач поиска и извлечения информации
Быстрая и подходит для использования в режиме реального времени
Почему scrape_as_markdown имеет значение
Большинство “веб-интеграций” останавливаются на этом этапе из-за CAPTCHA и блоков, которые ломаются в современном вебе.scrape_as_markdown:
- Работает на сайтах, перегруженных JS (полный рендеринг)
- Автоматическое решение CAPTCHA
- Возвращает чистый Markdown, который LLM переваривает гораздо лучше, чем сырой HTML
Если вам нужен структурированный JSON (например, данные о товарах), перейдите на Pro и используйте вертикальные скребки.
Профессиональный режим (по желанию)
- Полная поверхность ~60 инструментов (электронная коммерция, социальные сети, новости, недвижимость, финансы, LinkedIn/HR и многое другое)
- Использует API Web Scraper от Bright Data для возврата структурированного JSON, если этого требует рабочий процесс.
- Вы соглашаетесь, если вертикальная структура оправдывает стоимость токенов.
Результат: более быстрые старты, меньшее количество жетонов и более счастливые агенты, выбравшие правильный инструмент.
Как включить Pro
- Удаленные/хостинговые: добавьте
&pro=1к URL-адресу подключения. - STDIO/self-hosted: установить
PRO_MODE = true
2) Быть масштабируемым и производительным (рассчитанным на реальный трафик).
Мы не допускаем оркестровки на горячий путь, поэтому время запроса поступает с целевого сайта, а не из Web MCP.
Обзор архитектуры:
- Одиночная торцевая головка MCP с двухрежимной поверхностью инструмента
- Безголовая оркестровка браузера для страниц с большим количеством JS или если требуется любое взаимодействие с целевым сайтом
- Автоматическое решение CAPTCHA и устойчивое управление сессиями
- Настраиваемый параллелизм и изоляция каждого аккаунта
На практике:
- Низкая нагрузка на квитирование (режим Rapid) → минимальное время запуска
- Надежный скраппинг на реальных сайтах с большим количеством JS
- Оперативный резерв для пакетных заданий и агентов с высокой частотой кадров
3) Обеспечьте безопасность и соответствие требованиям (на основе программы GDPR компании Bright Data).
Web MCP – это тонкая обертка над API Bright Data, поэтому вы наследуете конфиденциальность, безопасность и управление платформы (GDPR/CCPA) вместо того, чтобы заново внедрять средства контроля в своем агенте. Подробнее в нашем Центре доверия.
Вы работаете с проверенной инфраструктурой и политиками Bright Data – той же самой, которую используют производственные клиенты, – а уровень MCP остается минимальным. Юридическая поддержка платформы подтверждена победами в судебных делах с Meta и X Corp, поддерживающих ответственный доступ к публичным веб-данным.
Что (намеренно) не входит в состав Web MCP
Web MCP не добавляет свои собственные уровни изоляции, резидентности, PII-redaction или ограничения скорости; эти защитные механизмы обрабатываются API/политиками Bright Data и/или должны быть реализованы в вашем агенте/приложении в соответствии с вашей степенью риска.
Легкий быстрый старт
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agent
client = MultiServerMCPClient({
"brightdata": {
"url": "https://mcp.brightdata.com/sse?token=<API_TOKEN>", # add &pro=1 to opt into Pro
"transport": "sse",
}
})
tools = await client.get_tools() # Rapid mode returns the slim, high-value set
agent = create_react_agent("openai:gpt-4.1", tools)
# Your agent can now search and extract live sites reliably:
resp = await agent.ainvoke({"messages": "Find the latest guidance on US passport renewal fees and summarize the changes."})Свобода означает “никаких оправданий”.
Если ваш агент не подключен к живому Интернету, он будет уверенно ошибаться при выполнении важных задач. С помощью бесплатного уровня Web MCP вы можете исправить это уже сегодня.





