

Google Flights — это широко используемый сервис бронирования авиабилетов, который предоставляет множество данных, включая цены на авиабилеты, расписание и сведения об авиакомпаниях. К сожалению, Google не предлагает публичного API для доступа к этим данным. Однако веб-парсинг может стать отличной альтернативой извлечению этих данных.
В этой статье я покажу вам, как создать надежный парсер Google Flights с помощью Python. Мы рассмотрим каждый шаг, чтобы убедиться, что все понятно.
Зачем парсить Google Flights?
Парсинг данных Google Flights дает ряд преимуществ, в том числе:
- Отслеживание цен на авиабилеты с течением времени
- Анализ ценовых трендов
- Определение наилучшего времени для бронирования авиабилетов
- Сравнение цен на разные даты и авиакомпании
Путешественникам это позволяет найти лучшие предложения и сэкономить деньги. Бизнесу это помогает в анализе рынка, конкурентной разведке и разработке эффективных ценовых стратегий.
Создание парсера Google Flights
Созданный нами парсер позволит вам ввести такие данные, как аэропорт вылета, пункт назначения, дату поездки и тип билета (в одну сторону или туда и обратно). Если вы бронируете поездку туда и обратно, вам также необходимо указать дату возвращения. Обо всем остальном позаботится парсер: он загрузит все доступные рейсы, выполнит парсинг данных и сохранит результаты в JSON-файле для дальнейшего анализа.
Если вы новичок в веб-парсинге на Python, ознакомьтесь с этим руководством, чтобы приступить к делу.
1. Какие данные можно извлечь из Google Flights?
Google Flights предоставляет множество данных, включая названия авиакомпаний, время вылета и прибытия, общую продолжительность, количество остановок, цены на билеты и данные о воздействии на окружающую среду (например, выбросы CO2).
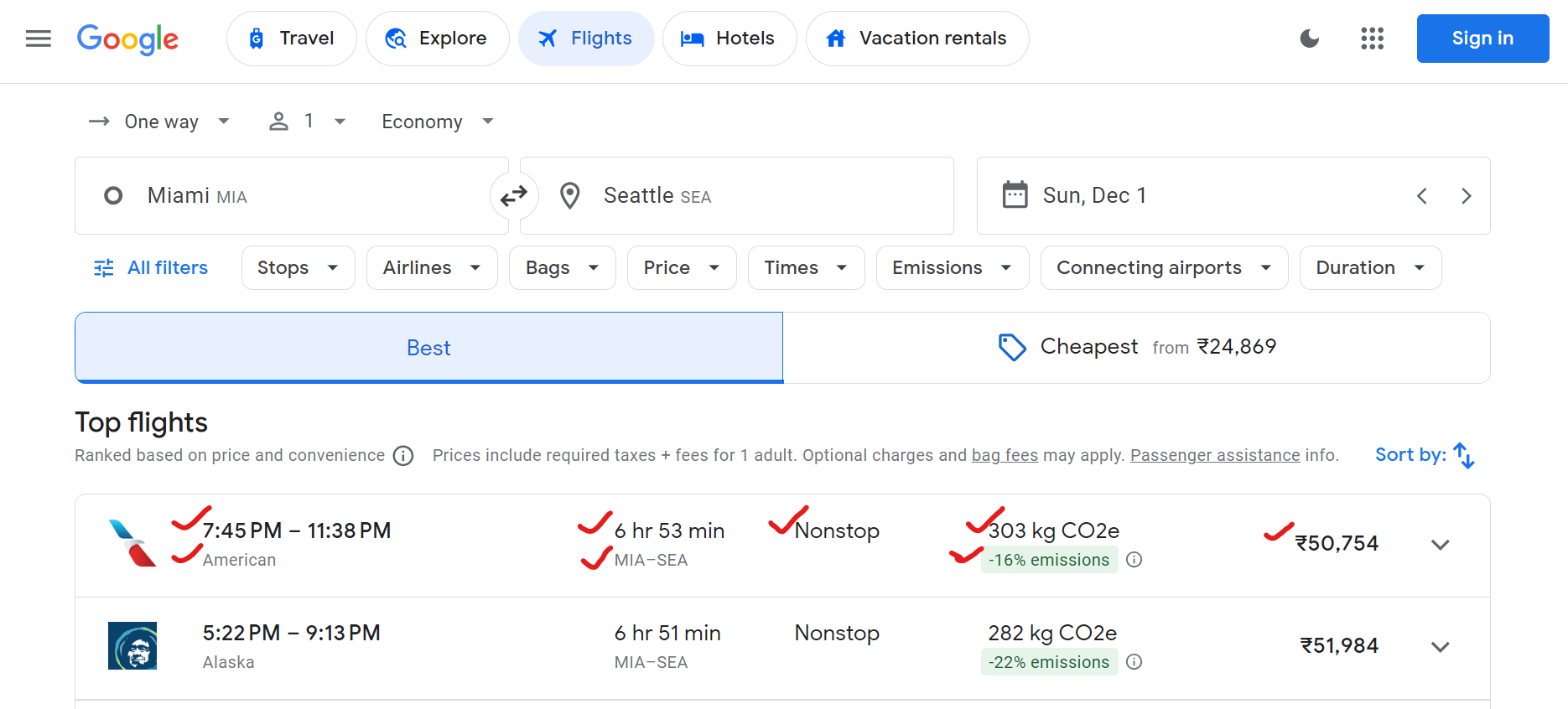
Вот пример данных, которые можно парсить:
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
}
2. Настройка среды
Сначала настроим среду в вашей системе для запуска парсера.
# Create a virtual environment (optional)
python -m venv flight-scraper-env
# Activate the virtual environment
# On Windows:
.flight-scraper-envScriptsactivate
# On macOS/Linux:
source flight-scraper-env/bin/activate
# Install required packages
pip install playwright tenacity asyncio
# Install Playwright browsers
playwright install chromium
Playwright идеально подходит для автоматизации браузеров и взаимодействия с динамическими веб-страницами, такими как Google Flights. Мы используем Tenacity для реализации механизма повторных попыток.
Если вы новичок в области Playwright, обязательно ознакомьтесь с руководством по парсингу веб-страниц с помощью Playwright.
3. Определение классов данных
Используя класс данных Python, вы можете аккуратно структурировать параметры поиска и данные о рейсах.
from dataclasses import dataclass
from typing import Optional
@dataclass
class SearchParameters:
departure: str
destination: str
departure_date: str
return_date: Optional[str] = None
ticket_type: str = "One way"
@dataclass
class FlightData:
airline: str
departure_time: str
arrival_time: str
duration: str
stops: str
price: str
co2_emissions: str
emissions_variation: str
Здесь класс SearchParameters хранит данные поиска рейсов, такие как вылет, пункт назначения, даты и тип билета, а класс FlightData содержит данные о каждом рейсе, включая авиакомпанию, цену, выбросы CO2 и другие важные сведения.
4. Логика парсера в классе FlightScraper
Основная логика парсинга заключена в классе FlightScraper. Вот подробная разбивка:
4.1 Определение селекторов CSS
Для извлечения данных вам необходимо найти определенные элементы на странице Google Flights. Это делается с помощью селекторов CSS. Вот как определяются селекторы в классе FlightScraper:
class FlightScraper:
SELECTORS = {
"airline": "div.sSHqwe.tPgKwe.ogfYpf",
"departure_time": 'span[aria-label^="Departure time"]',
"arrival_time": 'span[aria-label^="Arrival time"]',
"duration": 'div[aria-label^="Total duration"]',
"stops": "div.hF6lYb span.rGRiKd",
"price": "div.FpEdX span",
"co2_emissions": "div.O7CXue",
"emissions_variation": "div.N6PNV",
}
Эти селекторы ориентированы на название авиакомпании, время полета, продолжительность, остановки, цены и данные о выбросах.
Название авиакомпании:

Время отправления:

Время прибытия:

Продолжительность полета:

Количество остановок:

Цена:

CO2e:

Вариация выбросов CO2:

4.2 Заполнение формы поиска
Метод _fill_search_form имитирует заполнение формы поиска данными об отправлении, пункте назначения и дате:
async def _fill_search_form(self, page, params: SearchParameters) -> None:
# First, let's pick our ticket type
ticket_type_div = page.locator("div.VfPpkd-TkwUic[jsname='oYxtQd']").first
await ticket_type_div.click()
await page.wait_for_selector("ul[aria-label='Select your ticket type.']")
await page.locator("li").filter(has_text=params.ticket_type).nth(0).click()
# Now, let's fill in our departure and destination
from_input = page.locator("input[aria-label='Where from?']")
await from_input.click()
await from_input.fill("")
await page.keyboard.type(params.departure)
# ... rest of the form filling code
4.3 Загрузка всех результатов
Google Flights использует разбиение на страницы для загрузки рейсов. Вам нужно нажать кнопку «Показать больше рейсов», чтобы загрузить все доступные рейсы:
async def _load_all_flights(self, page) -> None:
while True:
try:
more_button = await page.wait_for_selector(
'button[aria-label*="more flights"]', timeout=5000
)
if more_button:
await more_button.click()
await page.wait_for_timeout(2000)
else:
break
except:
break
4.4 Извлечение данных о рейсе
После загрузки рейсов вы можете выполнить парсинг сведений о рейсах:
async def _extract_flight_data(self, page) -> List[FlightData]:
await page.wait_for_selector("li.pIav2d", timeout=30000)
await self._load_all_flights(page)
flights = await page.query_selector_all("li.pIav2d")
flights_data = []
for flight in flights:
flight_info = {}
for key, selector in self.SELECTORS.items():
element = await flight.query_selector(selector)
flight_info[key] = await self._extract_text(element)
flights_data.append(FlightData(**flight_info))
return flights_data
5. Добавление механизма повтора
Чтобы сделать наш парсер более надежным, добавьте логику повторных попыток, используя библиотеку tenacity:
@retry(stop=stop_after_attempt(3), wait=wait_fixed(5))
async def search_flights(self, params: SearchParameters) -> List[FlightData]:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) ..."
)
# ... rest of the search implementation
6. Сохранение результатов парсинга
Сохраните данные о рейсах после парсинга в файл JSON для дальнейшего анализа.
def save_results(self, flights: List[FlightData], params: SearchParameters) -> str:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = (
f"flight_results_{params.departure}_{params.destination}_{timestamp}.json"
)
output_data = {
"search_parameters": {
"departure": params.departure,
"destination": params.destination,
"departure_date": params.departure_date,
"return_date": params.return_date,
"search_timestamp": timestamp,
},
"flights": [vars(flight) for flight in flights],
}
filepath = os.path.join(self.results_dir, filename)
with open(filepath, "w", encoding="utf-8") as f:
json.dump(output_data, f, indent=2, ensure_ascii=False)
return filepath
7. Запуск парсера
Вот как запустить парсер Google Flights:
async def main():
scraper = FlightScraper()
params = SearchParameters(
departure="MIA",
destination="SEA",
departure_date="2024-12-01",
# return_date="2024-12-30",
ticket_type="One way",
)
try:
flights = await scraper.search_flights(params)
print(f"Successfully found {len(flights)} flights")
except Exception as e:
print(f"Error during flight search: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())
Окончательные результаты
После запуска парсера ваши данные о рейсах будут сохранены в файле JSON, который выглядит следующим образом:
{
"search_parameters": {
"departure": "MIA",
"destination": "SEA",
"departure_date": "2024-12-01",
"return_date": null,
"search_timestamp": "20241027_172017"
},
"flights": [
{
"airline": "American",
"departure_time": "7:45 PM",
"arrival_time": "11:38 PM",
"duration": "6 hr 53 min",
"stops": "Nonstop",
"price": "₹50,755",
"co2_emissions": "303 kg CO2e",
"emissions_variation": "-16% emissions"
},
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
},
{
"airline": "Alaska",
"departure_time": "9:00 AM",
"arrival_time": "12:40 PM",
"duration": "6 hr 40 min",
"stops": "Nonstop",
"price": "₹62,917",
"co2_emissions": "325 kg CO2e",
"emissions_variation": "-10% emissions"
}
]
}
Полный код можно найти в моем GitHub Gist.
Типичные проблемы при масштабировании парсинга Google Flights
При масштабировании парсинга данных Google Flights часто возникают такие проблемы, как блокировка IP-адресов и капчи . Например, если вы отправляете слишком много запросов за короткое время с помощью парсера, веб-сайты могут заблокировать ваш IP-адрес. Чтобы избежать этого, вы можете использовать ручную ротацию IP-адресов или выбрать один из лучших прокси-сервисов. Если вы не уверены, какой тип прокси-сервера лучше всего подходит для вашего варианта использования, ознакомьтесь с нашим руководством по лучшим прокси-серверам для веб-парсинга.
Еще одна проблема связана с капчами. Веб-сайты часто используют их, когда подозревают трафик ботов, и блокируют ваш парсер до тех пор, пока капча не будет решена. Обработка вручную занимает много времени и сложна.
Итак, каково решение? Давайте углубимся в это дальше!
Решение — инструменты веб-парсинга от Bright Data
Bright Data предлагает ряд решений, предназначенных для эффективного упрощения и масштабирования ваших усилий по веб-персингу. Давайте рассмотрим, как Bright Data может помочь вам преодолеть эти распространенные проблемы.
1. Резидентные прокси-серверы
Резидентные прокси-серверы от Bright Data дают вам возможность получать доступ к сложным целевым веб-сайтам и выполнять их парсинг. Резидентные прокси-серверы позволяют направлять запросы веб-парсинга через законные резидентные соединения. На целевых веб-сайтах ваши запросы будут выглядеть как исходящие от подлинных пользователей в определенном регионе или районе. В результате, резидентные прокси-серверы являются эффективным решением для доступа к веб-страницам, защищенным от парсинга с помощью блокировки IP-адресов.
2. Web Unlocker
Web Unlocker от Bright Data идеально подходит для парсинга проектов, сталкивающихся с капча или ограничениями. Вместо того чтобы вручную решать эти проблемы, Web Unlocker обрабатывает их автоматически, адаптируясь к изменению блоков сайта с высокой вероятностью успеха (обычно 100%). Вы просто отправляете один запрос, а Web Unlocker позаботится обо всем остальном.
3. Scraping Browser
Scraping Browser от Bright Data — еще один мощный инструмент для разработчиков, использующих headless-браузеры, такие как Puppeteer или Playwright. В отличие от традиционных headless-браузеров, Scraping Browser автоматически выполняет распознавание капч, подмену цвифровых отпечатков браузера, повторные попытки и многое другое, поэтому вы можете сосредоточиться на сборе данных, не беспокоясь об ограничениях сайта.
Заключение
В этой статье обсуждалось, как парсить данные Google Flights с помощью Python и Playwright. Хотя ручной парсинг может быть эффективным, она часто сопряжен с такими проблемами, как блокировка IP-адресов и необходимость постоянного обновления скриптов. Чтобы упростить и улучшить сбор данных, рассмотрите возможность использования решений Bright Data, таких как резидентные прокси, Web Unlocker и Scraping Browser.
Зарегистрируйтесь и получите бесплатную пробную версию Bright Data уже сегодня!
Кроме того, ознакомьтесь с нашими руководствами по парсингу других сервисов Google, таких как Данные результатов поиска Google, Google Trends, Google Scholarи Google Карты.






