

Создание надежного решения для извлечения данных из веб-страниц начинается с правильной инфраструктуры. В этом руководстве вы создадите одностраничное приложение, которое принимает URL-адрес любой публичной веб-страницы и запрос на естественном языке. Затем оно выполняет соскоб, парсинг и возвращает чистый, структурированный JSON, полностью автоматизируя процесс извлечения.
Этот стек объединяет инфраструктуру Bright Data для защиты от ботов, защищенный бэкэнд Supabase и инструменты быстрой разработки Lovable в единый рабочий процесс.
Что вы будете строить
Вот полный конвейер данных, который вам предстоит построить – от ввода данных пользователем до вывода и хранения структурированного JSON:
User Input
↓
Authentication
↓
Database Logging
↓
Edge Function
↓
Bright Data Web Unlocker (Bypasses anti-bot protection)
↓
Raw HTML
↓
Turndown (HTML → Markdown)
↓
Clean structured text
↓
Google Gemini AI (Natural language processing)
↓
Structured JSON
↓
Database Storage
↓
Frontend Display
↓
User ExportВот краткий обзор того, как выглядит готовое приложение:
Аутентификация пользователей: Пользователи могут безопасно регистрироваться или входить в систему с помощью экрана аутентификации на базе Supabase.
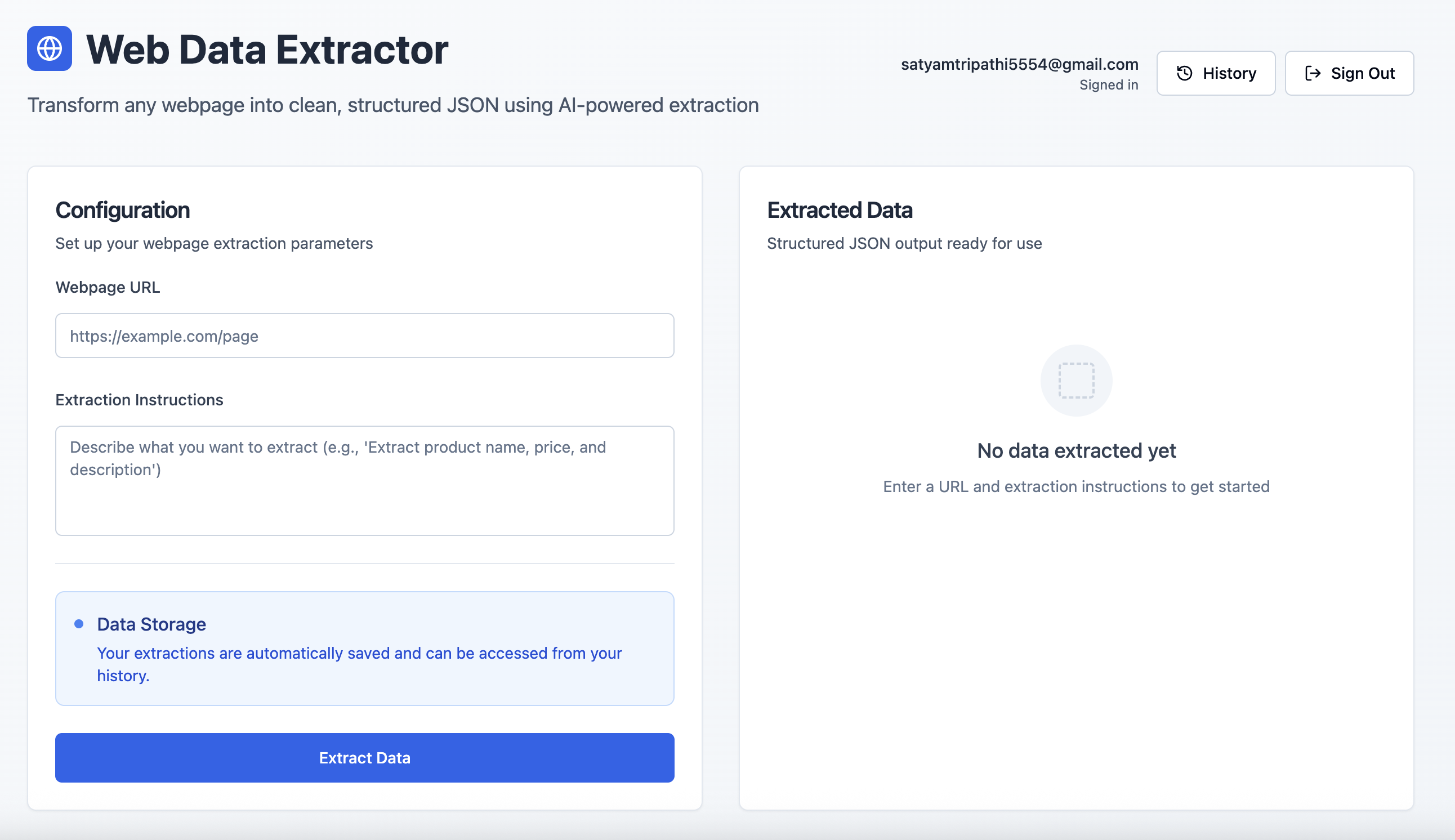
Интерфейс извлечения данных: После входа в систему пользователи могут ввести URL-адрес веб-страницы и запрос на естественном языке для извлечения структурированных данных.
Обзор технологического стека
Вот описание нашего стека и стратегических преимуществ, которые дает каждый компонент.
- Bright Data: Веб-скраппинг часто сталкивается с блокировками, CAPTCHA и расширенным обнаружением ботов. Bright Data специально создан для решения этих проблем. Он предлагает:
- Автоматическая ротация прокси-серверов
- Решение проблемы CAPTCHA и защита от ботов
- Глобальная инфраструктура для согласованного доступа
- Рендеринг JavaScript для динамического контента
- Автоматизированная обработка ограничений скорости
В этом руководстве мы будем использовать Web Unlocker от Bright Data – специально разработанный инструмент, который надежно извлекает полный HTML даже из самых защищенных страниц.
- Supabase:Supabase обеспечивает безопасную основу для современных приложений:
- Встроенные средства авторизации и обработки сеансов
- База данных PostgreSQL с поддержкой реального времени
- Функции Edge Functions для бессерверной логики
- Безопасное хранение ключей и контроль доступа
- Lovable: Lovable оптимизирует разработку с помощью инструментов, основанных на искусственном интеллекте, и встроенной интеграции с Supabase. Она предлагает:
- Генерация кода на основе искусственного интеллекта
- Бесшовные леса front-end/backend
- React + Tailwind UI из коробки
- Быстрое создание прототипов для готовых к производству приложений
- Google Gemini AI:Gemini превращает необработанный HTML в структурированный JSON с помощью подсказок на естественном языке. Он поддерживает:
- Точное понимание и разбор содержимого
- Поддержка большого ввода для полностраничного контекста
- Масштабируемое, экономически эффективное извлечение данных
Необходимые условия и настройка
Перед началом разработки убедитесь, что у вас есть доступ к следующему:
- Учетная запись Bright Data
- Зарегистрируйтесь на сайте brightdata.com
- Создайте зону Web Unlocker
- Получите ключ API из настроек учетной записи
- Аккаунт Google AI Studio
- Посетите Google AI Studio
- Создайте новый ключ API
- Проект Supabase
- Зарегистрируйтесь на сайте supabase.com
- Создайте новую организацию, затем создайте новый проект
- На приборной панели проекта перейдите в раздел Edge Functions → Secrets → Add New Secret. Добавьте такие секреты, как
BRIGHT_DATA_API_KEYиGEMINI_API_KEYс соответствующими значениями
- Любимый аккаунт
- Зарегистрируйтесь на сайте lovable.dev
- Перейдите в свой профиль → Настройки → Интеграции
- В разделе Supabase нажмите Подключить Supabase.
- Авторизуйте доступ к API и свяжите его с организацией Supabase, которую вы только что создали.
Создание приложения шаг за шагом с помощью подсказок Lovable
Ниже приведен структурированный, основанный на подсказках процесс разработки приложения для извлечения данных из Интернета, начиная с фронтенда и заканчивая бэкендом, базой данных и интеллектуальным парсингом.
Шаг №1 – настройка фронтенда
Начните с разработки чистого и интуитивно понятного пользовательского интерфейса.
Build a modern web data extraction app using React and Tailwind CSS. The UI should include:
- A gradient background with card-style layout
- An input field for the webpage URL
- A textarea for the extraction prompt (e.g., "Extract product title, price, and ratings")
- A display area to render structured JSON output
- Responsive styling with hover effects and proper spacingШаг №2 – подключение Supabase и добавление аутентификации
Чтобы связать проект Supabase, выполните следующие действия:
- Нажмите на значок Supabase в правом верхнем углу Lovable
- Выберите Connect Supabase
- Выберите организацию и проект, которые вы ранее создали
Lovable автоматически интегрирует ваш проект Supabase. После подключения воспользуйтесь подсказкой ниже, чтобы включить аутентификацию:
Set up complete Supabase authentication:
- Sign up and login forms using email/password
- Session management and auto-persistence
- Route protection for unauthenticated users
- Sign out functionality
- Create user profile on signup
- Handle all auth-related errorsLovable сгенерирует необходимые схемы SQL и триггеры – просмотрите и утвердите их, чтобы завершить процесс аутентификации.
Шаг № 3 – определение схемы базы данных Supabase
Создайте необходимые таблицы для регистрации и хранения активности извлечения:
Create Supabase tables for storing extractions and results:
- extractions: stores URL, prompt, user_id, status, processing_time, error_message
- extraction_results: stores parsed JSON output
Apply RLS policies to ensure each user can only access their own dataШаг #4 – создание функции Supabase Edge Function
Эта функция управляет основной логикой сбора, преобразования и извлечения данных:
Create an Edge Function called 'extract-web-data' that:
- Fetches the target page using Bright Data's Web Unlocker
- Converts raw HTML to Markdown using Turndown
- Sends the Markdown and prompt to Google Gemini AI (gemini-2.0-flash-001)
- Returns clean structured JSON
- Handles CORS, errors, and response formatting
- Requires GEMINI_API_KEY and BRIGHT_DATA_API_KEY as Edge Function secrets
Below is a reference implementation that handles HTML fetching using Bright Data, markdown conversion with Turndown, and AI-driven extraction with Gemini:
import { GoogleGenerativeAI } from '@google/generative-ai';
import TurndownService from 'turndown';
interface BrightDataConfig {
apiKey: string;
zone: string;
}
// Constants
const GEMINI_MODEL = 'gemini-2.0-flash-001';
const WEB_UNLOCKER_ZONE = 'YOUR_WEB_UNLOCKER_ZONE';
export class WebContentExtractor {
private geminiClient: GoogleGenerativeAI;
private modelName: string;
private htmlToMarkdownConverter: TurndownService;
private brightDataConfig: BrightDataConfig;
constructor() {
const geminiApiKey: string = 'GEMINI_API_KEY';
const brightDataApiKey: string = 'BRIGHT_DATA_API_KEY';
try {
this.geminiClient = new GoogleGenerativeAI(geminiApiKey);
this.modelName = GEMINI_MODEL;
this.htmlToMarkdownConverter = new TurndownService();
this.brightDataConfig = {
apiKey: brightDataApiKey,
zone: WEB_UNLOCKER_ZONE
};
} catch (error) {
console.error('Failed to initialize WebContentExtractor:', error);
throw error;
}
}
/**
* Fetches webpage content using Bright Data Web Unlocker service
*/
async fetchContentViaBrightData(targetUrl: string): Promise<string | null> {
try {
// Append Web Unlocker parameters to the target URL
const urlSeparator: string = targetUrl.includes('?') ? '&' : '?';
const requestUrl: string = `${targetUrl}${urlSeparator}product=unlocker&method=api`;
const apiResponse = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': `Bearer ${this.brightDataConfig.apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: this.brightDataConfig.zone,
url: requestUrl,
format: 'raw'
})
});
if (!apiResponse.ok) {
throw new Error(`Web Unlocker request failed with status: ${apiResponse.status}`);
}
const htmlContent: string = await apiResponse.text();
return htmlContent && htmlContent.length > 0 ? htmlContent : null;
} catch (error) {
console.error('Failed to fetch webpage content:', error);
return null;
}
}
/**
* Converts HTML to clean Markdown format for better AI processing
*/
async convertToMarkdown(htmlContent: string): Promise<string | null> {
try {
const markdownContent: string = this.htmlToMarkdownConverter.turndown(htmlContent);
return markdownContent;
} catch (error) {
console.error('Failed to convert HTML to Markdown:', error);
return null;
}
}
/**
* Uses Gemini AI to extract specific information from markdown content
* Uses low temperature for more consistent, factual responses
*/
async extractInformationWithAI(markdownContent: string, userQuery: string): Promise<string | null> {
try {
const aiPrompt: string = this.buildAIPrompt(userQuery, markdownContent);
const aiModel = this.geminiClient.getGenerativeModel({ model: this.modelName });
const aiResult = await aiModel.generateContent({
contents: [{ role: 'user', parts: [{ text: aiPrompt }] }],
generationConfig: {
maxOutputTokens: 2048,
temperature: 0.1,
}
});
const response = await aiResult.response;
return response.text();
} catch (error) {
console.error('Failed to extract information with AI:', error);
return null;
}
}
private buildAIPrompt(userQuery: string, markdownContent: string): string {
return `You are a data extraction assistant. Below is some content in markdown format extracted from a webpage.
Please analyze this content and extract the information requested by the user.
USER REQUEST: ${userQuery}
MARKDOWN CONTENT:
${markdownContent}
Please provide a clear, structured response based on the user's request. If the requested information is not available in the content, please indicate that clearly.`;
}
/**
* Main extraction workflow: fetches webpage → converts to markdown → extracts with AI
*/
async extractDataFromUrl(websiteUrl: string, extractionQuery: string): Promise<string | null> {
try {
const htmlContent: string | null = await this.fetchContentViaBrightData(websiteUrl);
if (!htmlContent) {
console.error('Could not retrieve HTML content from URL');
return null;
}
const markdownContent: string | null = await this.convertToMarkdown(htmlContent);
if (!markdownContent) {
console.error('Could not convert HTML to Markdown');
return null;
}
const extractedInformation: string | null = await this.extractInformationWithAI(markdownContent, extractionQuery);
return extractedInformation;
} catch (error) {
console.error('Error in extractDataFromUrl:', error);
return null;
}
}
}
/**
* Example usage of the WebContentExtractor
*/
async function runExtraction(): Promise<void> {
const TARGET_WEBSITE_URL: string = 'https://example.com';
const DATA_EXTRACTION_QUERY: string = 'Extract the product title, all available prices, ...';
try {
const contentExtractor = new WebContentExtractor();
const extractionResult: string | null = await contentExtractor.extractDataFromUrl(TARGET_WEBSITE_URL, DATA_EXTRACTION_QUERY);
if (extractionResult) {
console.log(extractionResult);
} else {
console.log('Failed to extract data from the specified URL');
}
} catch (error) {
console.error(`Application error: ${error}`);
}
}
// Execute the application
runExtraction().catch(console.error);Преобразование необработанного HTML в Markdown перед отправкой в Gemini AI имеет несколько ключевых преимуществ. Он удаляет ненужный шум HTML, повышает производительность ИИ за счет более чистого и структурированного ввода и сокращает использование токенов, что позволяет ускорить и удешевить обработку.
Важное замечание: Lovable отлично справляется с созданием приложений на основе естественного языка, но не всегда знает, как правильно интегрировать внешние инструменты, такие как Bright Data или Gemini. Чтобы обеспечить точную реализацию, включите в подсказки пример рабочего кода. Например, метод fetchContentViaBrightData The в подсказке выше демонстрирует простой случай использования Web Unlocker от Bright Data.
Bright Data предлагает несколько API, включая Web Unlocker, SERP API и Scraper API, каждый из которых имеет свою конечную точку, метод аутентификации и параметры. Когда вы настраиваете продукт или зону на панели управления Bright Data, на вкладке “Обзор” представлены фрагменты кода на конкретных языках (Node.js, Python, cURL), адаптированные к вашей конфигурации. Используйте эти фрагменты как есть или адаптируйте их под логику вашей Edge Function.
Шаг № 5 – подключение фронтенда к Edge Function
Когда функция Edge Function будет готова, интегрируйте ее в приложение React:
Connect the frontend to the Edge Function:
- On form submission, call the Edge Function
- Log the request in the database
- Update status (processing/completed/failed) after the response
- Show processing time, status icons, and toast notifications
- Display the extracted JSON with loading statesШаг № 6 – добавление истории извлечения
Предоставьте пользователям возможность просматривать предыдущие запросы:
Create a history view that:
- Lists all extractions for the logged-in user
- Displays URL, prompt, status, duration, and date
- Includes View and Delete options
- Expands rows to show extracted results
- Uses icons for statuses (completed,failed,processing)
- Handles long text/URLs gracefully with a responsive layoutШаг #7 – Полировка пользовательского интерфейса и финальные улучшения
Усовершенствуйте опыт с помощью полезных штрихов пользовательского интерфейса:
Polish the interface:
- Add toggle between "New Extraction" and "History"
- Create a JsonDisplay component with syntax highlighting and copy button
- Fix responsiveness issues for long prompts and URLs
- Add loading spinners, empty states, and fallback messages
- Include feature cards or tips at the bottom of the pageЗаключение
Эта интеграция объединяет лучшие достижения современной веб-автоматизации: безопасные потоки пользователей с Supabase, надежный скраппинг с Bright Data и гибкий парсинг с помощью искусственного интеллекта с Gemini – и все это с помощью интуитивно понятного конструктора Lovable, основанного на чате и обеспечивающего высокопроизводительный рабочий процесс с нулевым кодом.
Готовы создать свою собственную систему? Начните с сайта brightdata.com и изучите решения Bright Data для сбора данных, обеспечивающие масштабируемый доступ к любому объекту без лишних проблем с инфраструктурой.





