
В этом руководстве вы узнаете:
- Что такое Langflow и почему он стал так популярен.
- Ограничения использования стандартных LLM в приложениях Langflow и способы их преодоления с помощью внешних данных.
- Как создать приложение Langflow AI, интегрированное с Bright Data для веб-доступа к данным.
Давайте погрузимся!
Что такое Langflow?
Langflow – это инструмент с открытым исходным кодом, созданный на Python и JavaScript для создания и развертывания агентов и рабочих процессов на базе ИИ. Имея более 92 тысяч звезд на GitHub, он является одной из самых популярных и широко распространенных библиотек для разработки агентов ИИ.
Langflow работает как платформа визуальной разработки с низким уровнем кодирования. Она позволяет создавать сложные приложения искусственного интеллекта, просто соединяя готовые компоненты с помощью интерфейса drag-and-drop. Такой подход устраняет необходимость в обширном кодировании. Тем не менее, он поддерживает интеграцию пользовательского кода для максимальной гибкости.
Langflow предоставляет широкий спектр возможностей ИИ, включая агентов, LLM, векторные хранилища и интеграцию с любым API, моделью или базой данных.
Почему приложениям искусственного интеллекта нужен доступ к данным
По сравнению с другими фреймворками, Langflow – это визуальная платформа для создания приложений с искусственным интеллектом. Но, как и любая другая система, работающая на LLM, приложения на базе Langflow умны только настолько, насколько умны данные, к которым они имеют доступ.
LLM обучаются на статичных наборах данных и не имеют встроенной информации о событиях в реальном времени или частных бизнес-данных. Это делает их оторванными от современного мира, если только вы не подключите их к свежим, актуальным источникам данных. А Интернет – это самый обширный источник информации.
Чтобы преодолеть эти ограничения LLM, Langflow позволяет подключаться к гибким веб-конвейерам данных. Этот паттерн является основополагающим в таких важных случаях использования, как:
- Рабочие процессы RAG, в которых полученные данные улучшают результаты LLM.
- Конвейеры данных, в которых данные извлекаются и очищаются перед анализом.
- Агенты ИИ, которым необходимы внешние знания для выполнения таких задач, как ответы на запросы, обобщение документов или выполнение веб-поиска.
Получение точных публичных данных из Интернета – задача не из легких. Вам нужна инфраструктура, которая может:
- Подключайтесь практически к любому сайту (даже к тем, которые защищены технологией защиты от подделок).
- Надежное извлечение необходимых данных.
- Верните его в структурированном виде, в формате AI.
Именно это и обеспечивает Bright Data. Объединив Langflow с инструментами Bright Data, ваше приложение для искусственного интеллекта получит мощные возможности, включая:
- Веб-скраппинг в реальном времени в обход защиты от ботов.
- Извлечение структурированных данных с таких ведущих платформ, как Amazon, LinkedIn, Zillow и др.
- Доступ к результатам поисковых систем для получения данных SERP в режиме реального времени на основе запросов.
- Визуальный захват данных с помощью автоматических полностраничных скриншотов.
Вы можете подключиться к Bright Data напрямую через пользовательский компонент Langflow. Это означает, что вам не нужно создавать или поддерживать сложную логику бэкенда. Просто подключите компонент к своему потоку, и все готово!
Создание приложения для искусственного интеллекта на Langflow с веб-доступом к данным благодаря Bright Data
В этом пошаговом руководстве вы используете Langflow для создания агента искусственного интеллекта, способного получать живые веб-данные, интегрируя его с Bright Data.
Не забывайте, что представленная здесь настройка ИИ-агента – это лишь один из простых примеров того, что можно создать благодаря этой интеграции. Существует бесчисленное множество других приложений для искусственного интеллекта, которые можно создать с помощью интеграции Bright Data × Langflow. Для вдохновения изучите наш список возможных вариантов использования.
Следуйте приведенному ниже руководству, чтобы создать ИИ-агент на базе Bright Data в Langflow!
Пререквизиты
Чтобы следовать этому руководству, убедитесь, что вы соответствуете следующим требованиям:
- Не менее двухъядерного процессора и 2 ГБ оперативной памяти (рекомендуется: многоядерный процессор и не менее 4 ГБ оперативной памяти).
- Python версии 3.10 – 3.12 для Windows или 3.10 – 3.13 для macOS/Linux, установленный локально.
- Пакет
uvустановлен локально. - Ключ API Bright Data.
- API-ключ для подключения к одному из поддерживаемых LLM (здесь мы будем использовать Gemini, который можно бесплатно использовать через API).
Не волнуйтесь, если у вас нет ключа API Bright Data, так как в процессе обучения вам будет предложено пройти процесс настройки.
Чтобы установить uv, выполните следующую команду:
pip install uvЕсли вы являетесь пользователем Windows, вам также потребуется Microsoft Visual C++ 14.0 или выше. Загрузите его и следуйте руководству поддержки для завершения установки.
Шаг № 1: Настройка Langflow
Сначала создайте папку для вашего проекта Langflow и перейдите в нее:
mkdir langflow-agent
cd langflow-agentПапка langflow-agent будет служить каталогом вашего проекта Langflow.
В папке проекта создайте виртуальную среду Python с помощью uv:
uv venv venvЗатем на macOS/Linux активируйте его с помощью:
source venv/bin/activateАналогично, в Windows выполните команду:
venvScriptsactivateАктивировав виртуальную среду, установите Langflow в среду проекта:
uv pip install langflowЭто займет некоторое время, так что наберитесь терпения.
После завершения установки убедитесь, что все работает, запустив приложение с помощью этой команды:
uv run langflow runПодождите, пока LangFlow инициализирует локальный сервер. Как только он будет готов, он должен быть доступен на этой странице в вашем браузере:
http://localhost:7860Откройте его, и если все прошло как надо и вы впервые используете Langflow, вы увидите этот интерфейс:
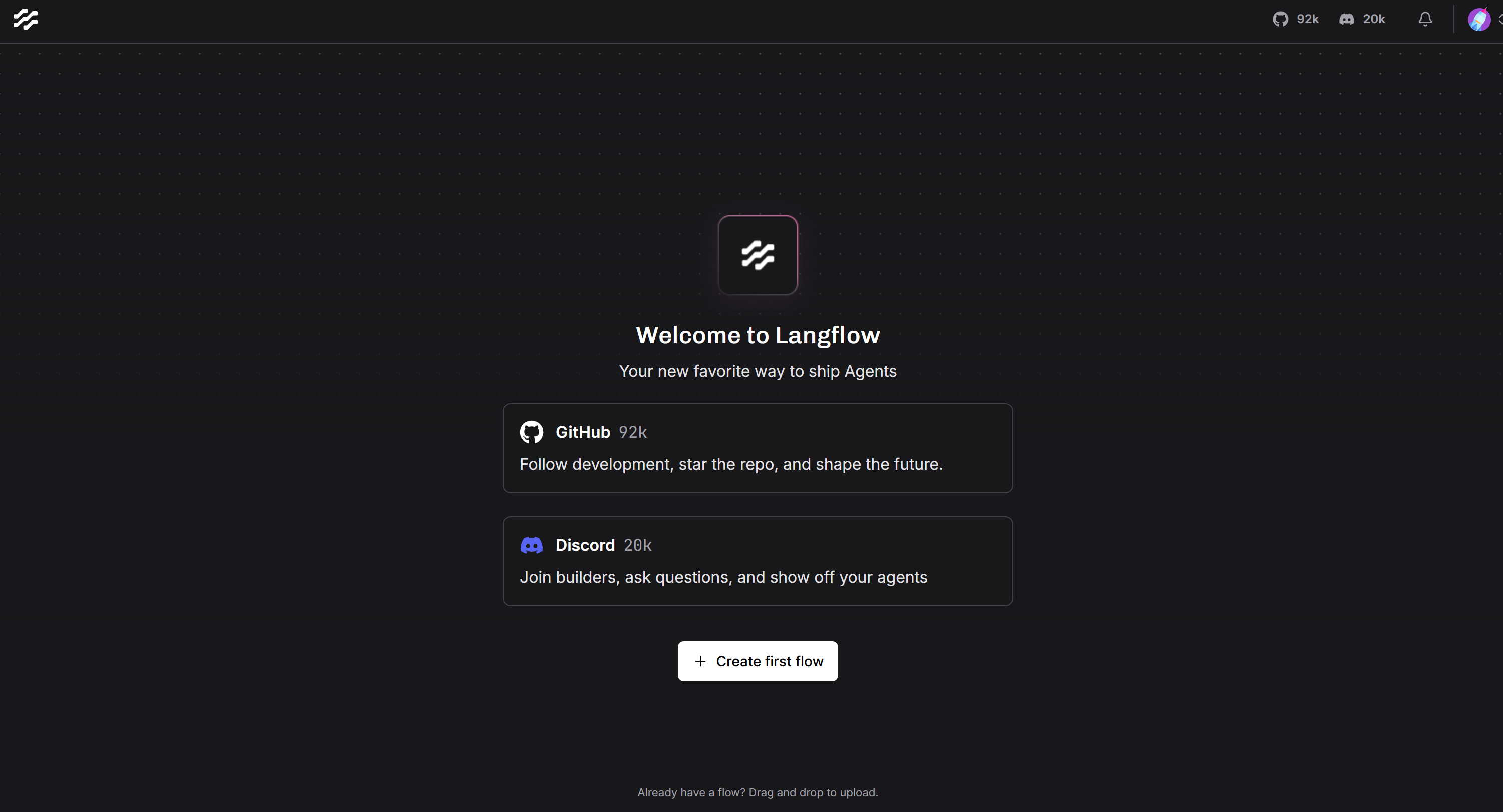
Если вы столкнулись с какими-либо ошибками, обратитесь к официальному руководству по установке.
Потрясающе! Ваша установка LangFlow теперь работает.
Шаг №2: Настройте Bright Data
Чтобы предоставить своему приложению искусственного интеллекта возможность получать данные из Интернета, необходимо подключить его к инфраструктуре искусственного интеллекта Bright Data.
Bright Data предлагает множество решений для сбора данных, но в этом руководстве мы сосредоточимся на них:
- Web Unlocker: Продвинутый API для скраппинга, который обходит защиту от ботов и возвращает любую веб-страницу в формате HTML или Markdown.
Примечание: Интеграция с другими инструментами Bright Data, такими как API Web Scraper, также возможна, но это руководство посвящено Web Unlocker общего назначения.
Чтобы использовать Web Unlocker в приложении Langflow, сначала необходимо:
- Настройте зону Web Unlocker в своей учетной записи Bright Data.
- Создайте свой API-токен Bright Data для аутентификации запросов.
Следуйте приведенным ниже инструкциям, чтобы сделать и то, и другое! В качестве справочной информации изучите официальную документацию.
Во-первых, если у вас еще нет учетной записи Bright Data, зарегистрируйтесь бесплатно. Если у вас есть, войдите в систему и откройте панель управления. Нажмите кнопку “Прокси и скрапинг”:
Вы будете перенаправлены на страницу “Прокси и инфраструктура скрапинга”:
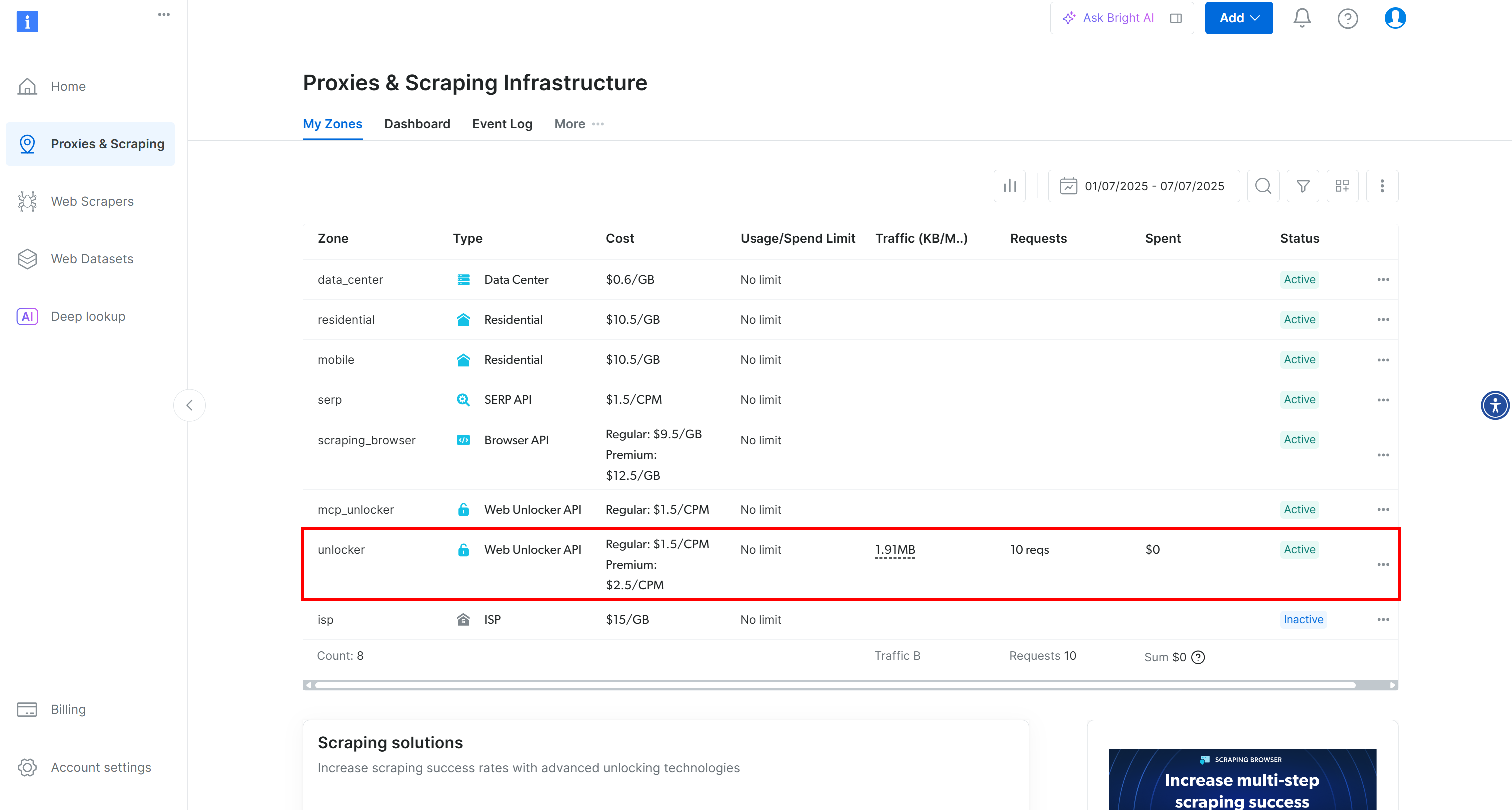
Если у вас уже есть зона Web Unlocker, вы увидите ее в списке на этой странице. В данном примере зона уже существует и называется "unblocker" (запомните это имя, так как оно понадобится вам позже).
Если у вас еще нет нужной зоны, прокрутите страницу вниз до карточки “Web Unlocker API” и нажмите “Создать зону”:
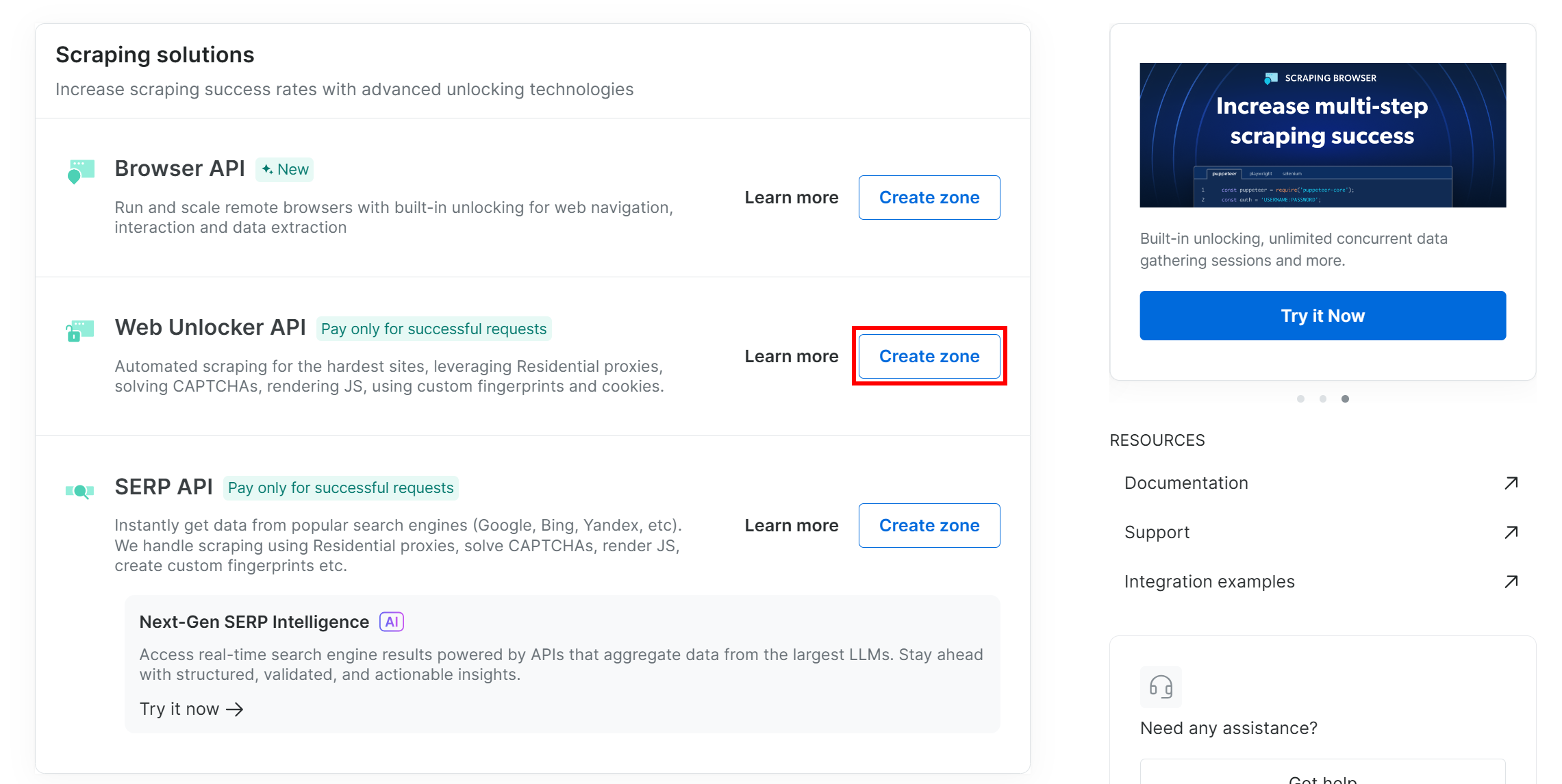
Дайте своей зоне имя (например, “разблокировщик”), включите дополнительные функции для лучшей производительности и нажмите кнопку “Добавить”:
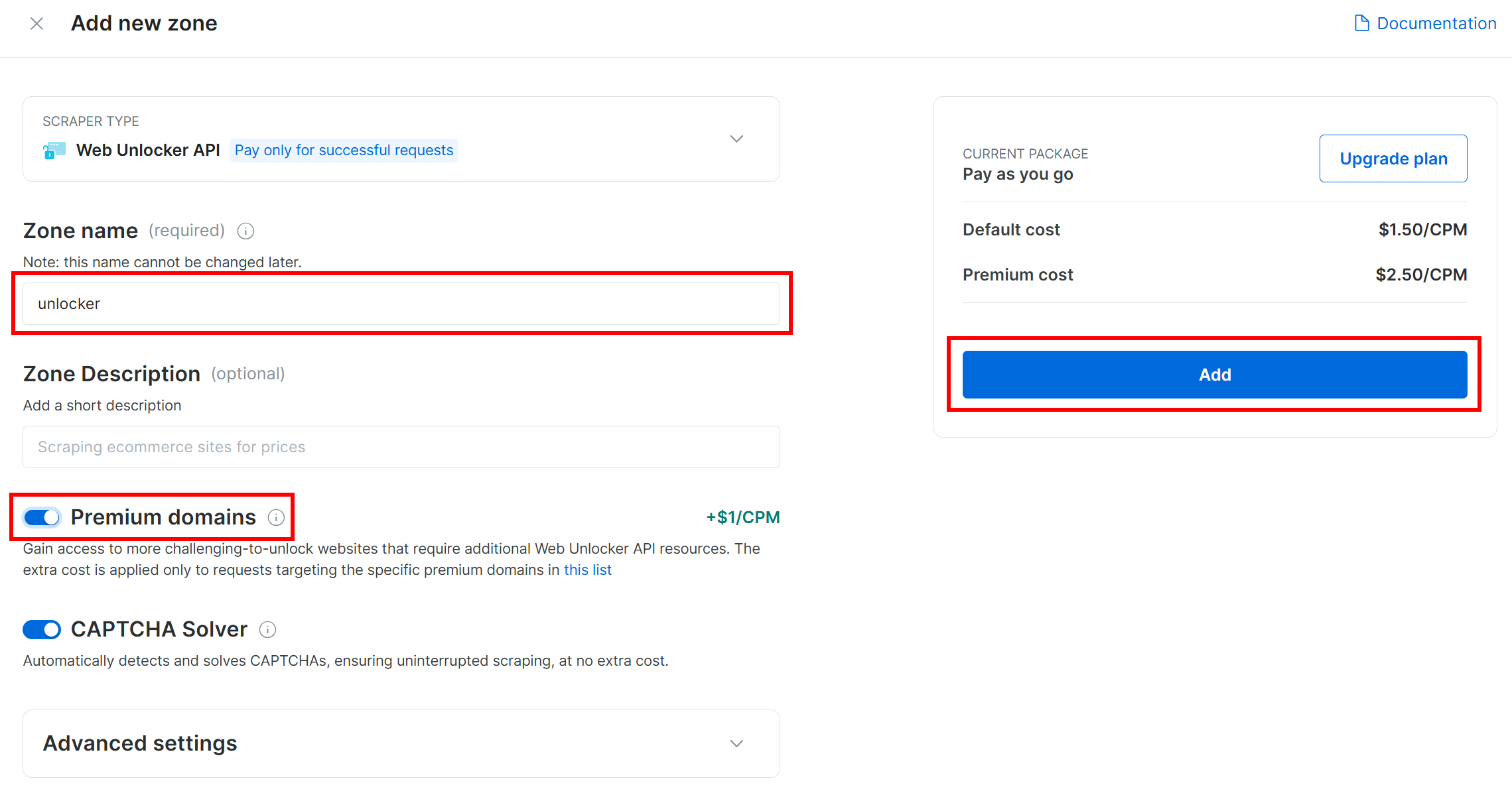
После создания вы попадете на страницу подробной информации о зоне. Убедитесь, что переключатель установлен в положение “Активно”, что подтверждает готовность продукта к использованию:
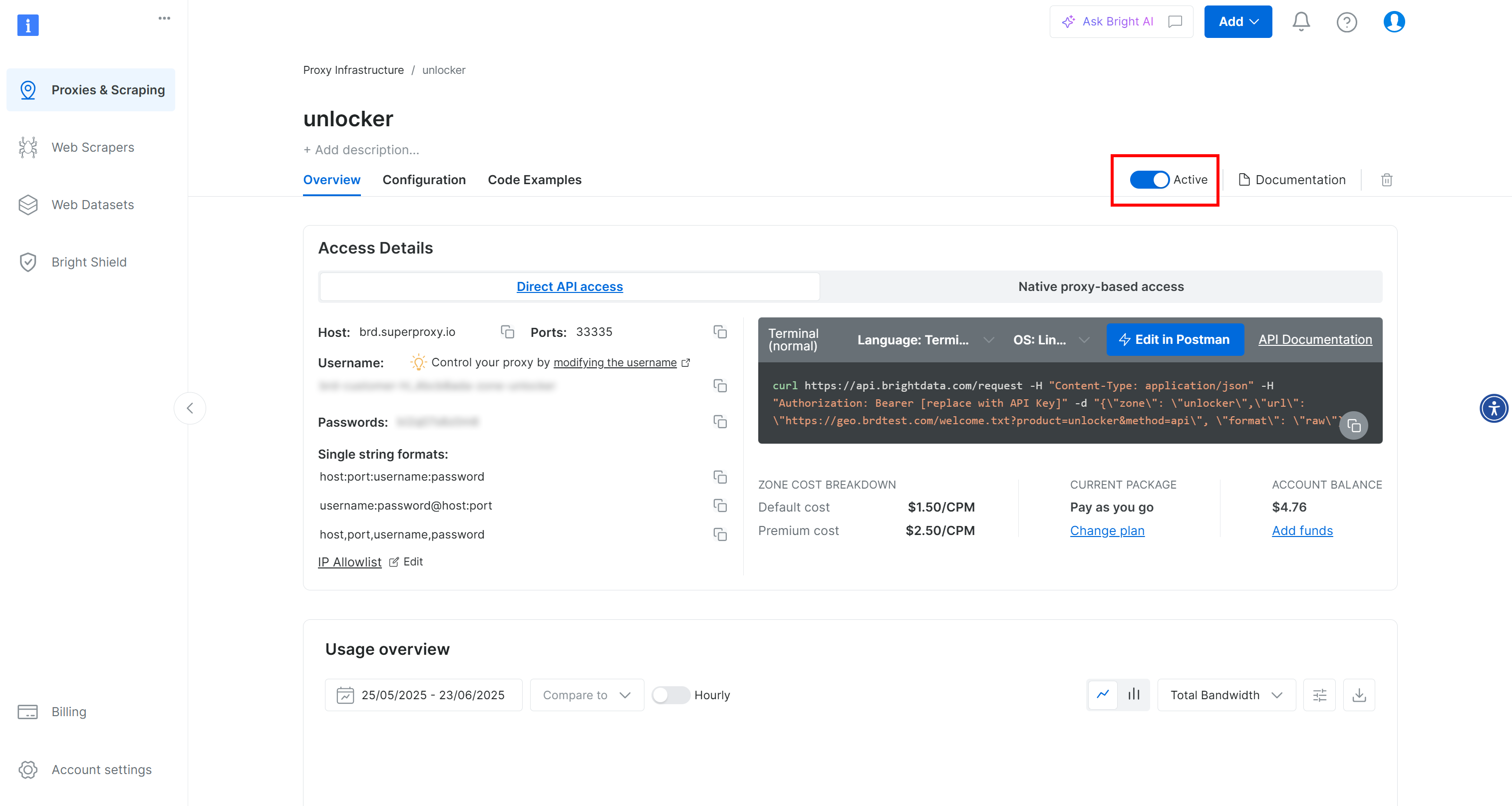
Теперь следуйте официальной документации Bright Data, чтобы сгенерировать свой ключ API. Как только вы его получите, храните его в надежном месте, так как он вам скоро понадобится.
Отлично! Вы готовы интегрировать Bright Data с Langflow с помощью пользовательского компонента.
Шаг № 3: Инициализация нового пустого потока
Прежде чем продолжить, необходимо создать новый поток Langflow. Вернитесь на локальный сервер Langflow и нажмите кнопку “Создать первый поток”:
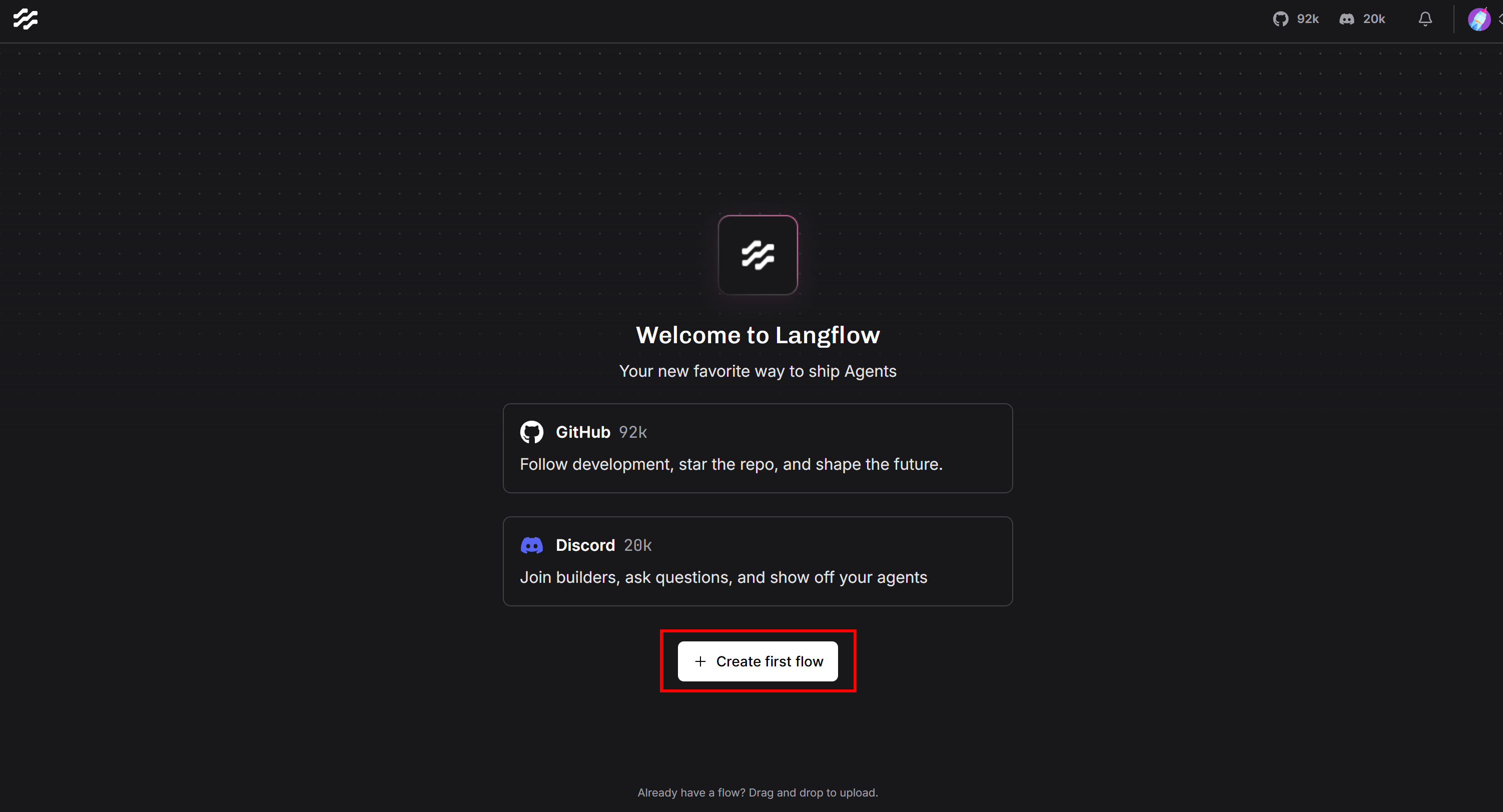
Появится следующее модальное окно. Нажмите кнопку “Пустой поток” в правом нижнем углу:
Дайте своему потоку имя, например “Langflow x Bright Data AI App”. После создания вы увидите чистый холст, как показано здесь:
На холсте вы можете добавлять и соединять компоненты, чтобы создать свое AI-приложение. Отличная работа!
Шаг #4: Определите пользовательский компонент Bright Data
Самый простой способ интегрировать Langflow с Bright Data – создать пользовательский компонент. Это позволит вашему агенту искусственного интеллекта собирать веб-данные с помощью API Bright Data Web Unlocker.
В Langflow пользовательские компоненты – это классы Python, определяемые:
- Входы: Данные или параметры, которые требуются вашему компоненту.
- Выходные данные: Данные, которые ваш компонент возвращает нижележащим узлам.
- Логика: Внутренняя обработка для преобразования входных данных в выходные.
В частности, ваш пользовательский компонент Langflow x Bright Data должен:
- Примите в качестве входных данных (для аутентификации) ключ API Bright Data и имя зоны Web Unlocker.
- Получите целевой URL-адрес веб-страницы, которую вы хотите соскоблить.
- Выполните запрос к API Web Unlocker, настроенный на возврат страницы в формате Markdown (который идеально подходит для использования в искусственном интеллекте).
- Верните полученное содержимое в качестве выходных данных.
Все вышеперечисленное можно реализовать с помощью следующего пользовательского компонента Python:
from langflow.custom import Component
from langflow.io import SecretStrInput, StrInput, Output
from langflow.schema import Data
import httpx
# A Langflow custom component must extend Component
class BrightDataComponent(Component):
# The component name shown in the Langflow UI
display_name = "Bright Data"
# The description in the component details
description = "Retrieve data from the web in Markdown format using Bright Data"
icon = "sparkles" # UI icon identifier
name = "BrightData" # Internal name used by Langflow
# --- INPUTS ---
# Define the inputs required by the component
inputs = [
SecretStrInput(
name="api_key",
display_name="Bright Data API Key",
required=True,
info="Your Bright Data API key from the dashboard"
),
StrInput(
name="zone",
display_name="Web Unlocker Zone Name",
info="The name of the Web Unlocker zone to connect to (e.g., 'web_unlocker')",
required=True
),
StrInput(
name="url",
display_name="Target URL",
info="The URL to transform into Markdown data",
tool_mode=True
),
]
# --- OUTPUT ---
# Define the output returned by the component
outputs = [
Output(
name="web_data",
display_name="Web Data Result",
method="get_web_data" # The name of the method used to generate the output
)
]
# --- LOGIC ---
# This method retrieves web data from Bright Data and returns it
def get_web_data(self) -> Data:
try:
# Bright Data Web Unlocker API endpoint
url = "https://api.brightdata.com/request"
# Request headers including API key for authentication
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Payload specifying the zone, URL, and output format
payload = {
"zone": self.zone,
"url": self.url,
"format": "raw",
"data_format": "markdown"
}
# Send the POST request with a 180-second timeout
with httpx.Client(timeout=180.0) as client:
response = client.post(url, json=payload, headers=headers)
# Raise an error if HTTP status code is not 2xx
response.raise_for_status()
# Extract contains the Markdown-formatted web data
markdown_data = response.text
return Data(data={"data": markdown_data})
# Handle timeout errors
except httpx.TimeoutException:
error_msg = "The Web Unlocker request timed out"
return Data(data={"error": error_msg, "data": None})
# Handle other HTTP errors (e.g., 4xx, 5xx)
except httpx.HTTPStatusError as e:
error_msg = f"Request failed with status {e.response.status_code}: {e.response.text}"
return Data(data={"error": error_msg, "data": None})Компонент BrightDataComponent принимает следующие входные данные:
- Ваш ключ API Bright Data.
- Имя вашей зоны Web Unlocker.
- URL-адрес страницы, которую вы хотите соскоблить.
Затем он использует HTTPX Python-клиент для отправки запроса к Web Unlocker API, настроенного на возврат ответа в формате Markdown. Представление страницы в формате Markdown, возвращенное API, становится выходом компонента.
Примечание: Мы использовали HTTPX, потому что это библиотека HTTP-клиента по умолчанию, доступная в Langflow. Чтобы узнать о ней больше, прочитайте наше руководство по использованию HTTPX для веб-скрапинга.
Фантастика! Посмотрите, как добавить этот компонент в поток и позволить агенту ИИ использовать его результаты.
Шаг #5: Добавьте пользовательский компонент Bright Data
Чтобы зарегистрировать определенный ранее компонент, нажмите на кнопку “Новый пользовательский компонент” в левом нижнем углу. На холсте появится новый типовой компонент “Hello, World”. Наведите на него курсор и нажмите на раздел “Код”, чтобы настроить его логику:
В появившемся редакторе кода вставьте полный исходный код класса BrightDataComponent:
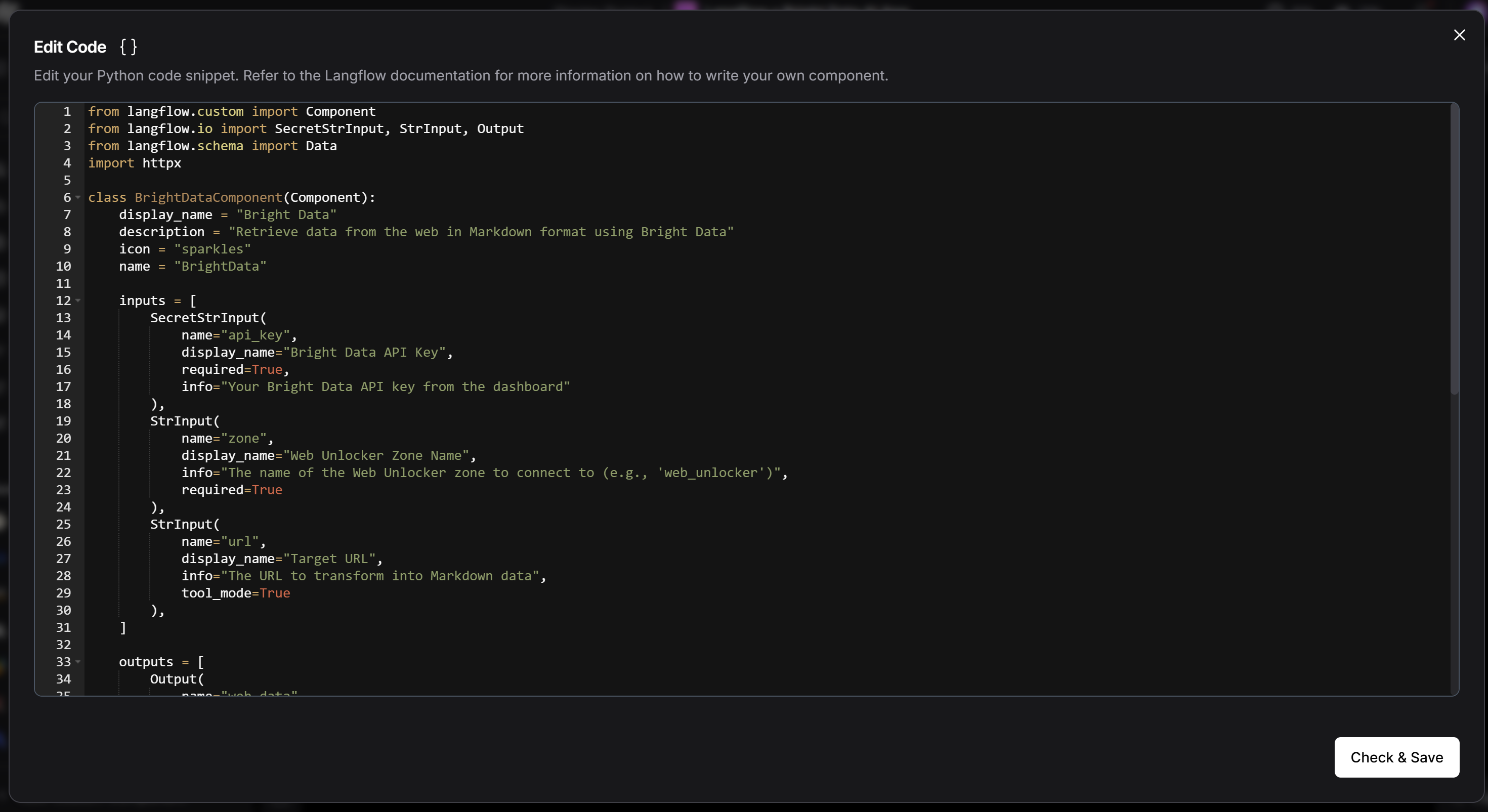
Нажмите кнопку “Проверить и сохранить”. Теперь вы должны увидеть, что общий “Пользовательский компонент” заменен вашим компонентом Bright Data:
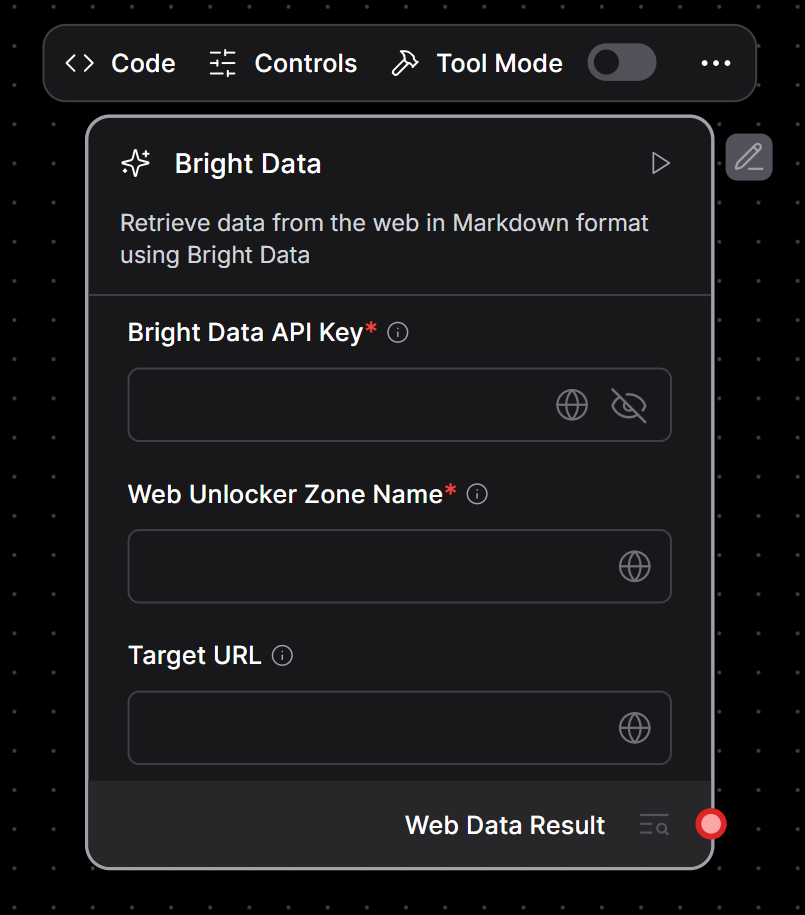
Как вы можете видеть, пользовательский компонент placeholder был обновлен вашим пользовательским компонентом для интеграции с Bright Data.
Примечание: Вам не нужно вручную создавать компонент Bright Data в каждом потоке.
Просто сохраните ваш пользовательский компонент в файле Python и загрузите его автоматически, используя метод, описанный в документации Langflow.
Замечательно! Теперь ваш поток искусственного интеллекта может интегрироваться с Bright Data для получения веб-данных.
Шаг № 6: Подключите агент искусственного интеллекта к ярким данным
Вы можете использовать компонент Bright Data непосредственно в своем приложении Langflow или превратить его в инструмент, с которым могут взаимодействовать агенты ИИ. Превратив его в инструмент, вы дадите агенту возможность получать живой контент с любой веб-страницы в удобном для ИИ формате Markdown. Другими словами, вы позволяете своему ИИ получать доступ и информацию в реальном времени с любого сайта.
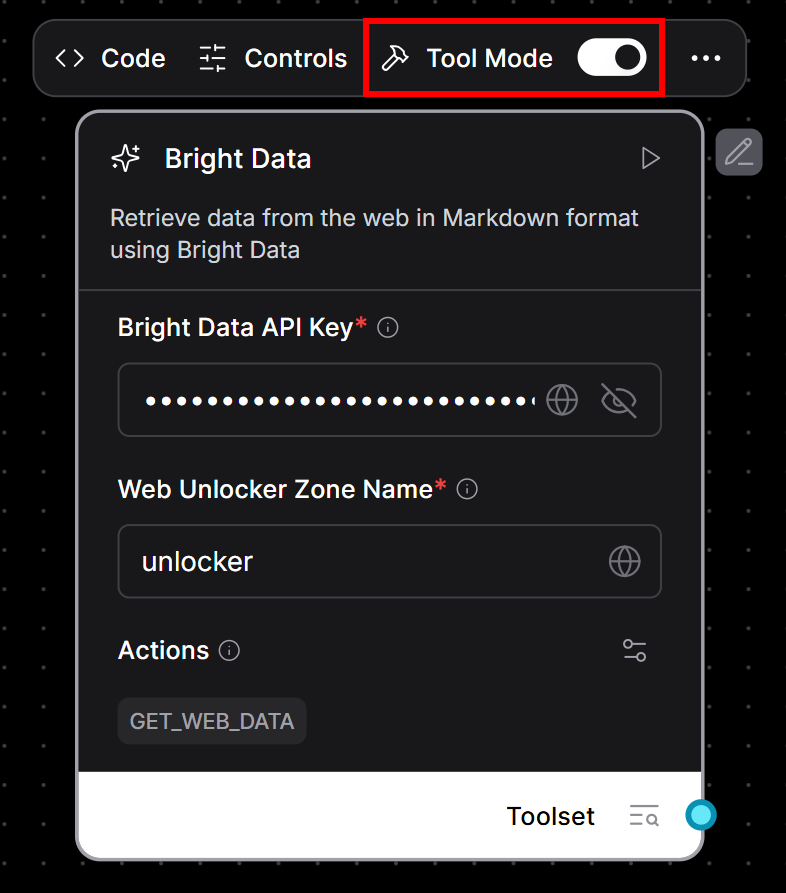
Чтобы сделать Яркий компонент инструментом:
- Наведите курсор на компонент Bright Data.
- Включите переключатель “Режим инструмента”, чтобы включить его.
- Заполните необходимые поля:
- Ваш ключ API Bright Data.
- Имя вашей зоны Web Unlocker (например,
"unlocker").
Вот что вы теперь должны увидеть:
Теперь, когда ваш компонент Bright Data готов как инструмент, подключите его к агенту искусственного интеллекта:
- В левой боковой панели найдите компонент “Агенты > Агент”.
- Перетащите его на холст.
- Настройте агент на использование предпочтительного LLM (в этом примере мы будем использовать Gemini, выбрав бесплатную модель
gemini-2.5-flashи вставив свой API-ключ Gemini). - Подключите выход компонента Bright Data “Tools” к входу компонента Agent:
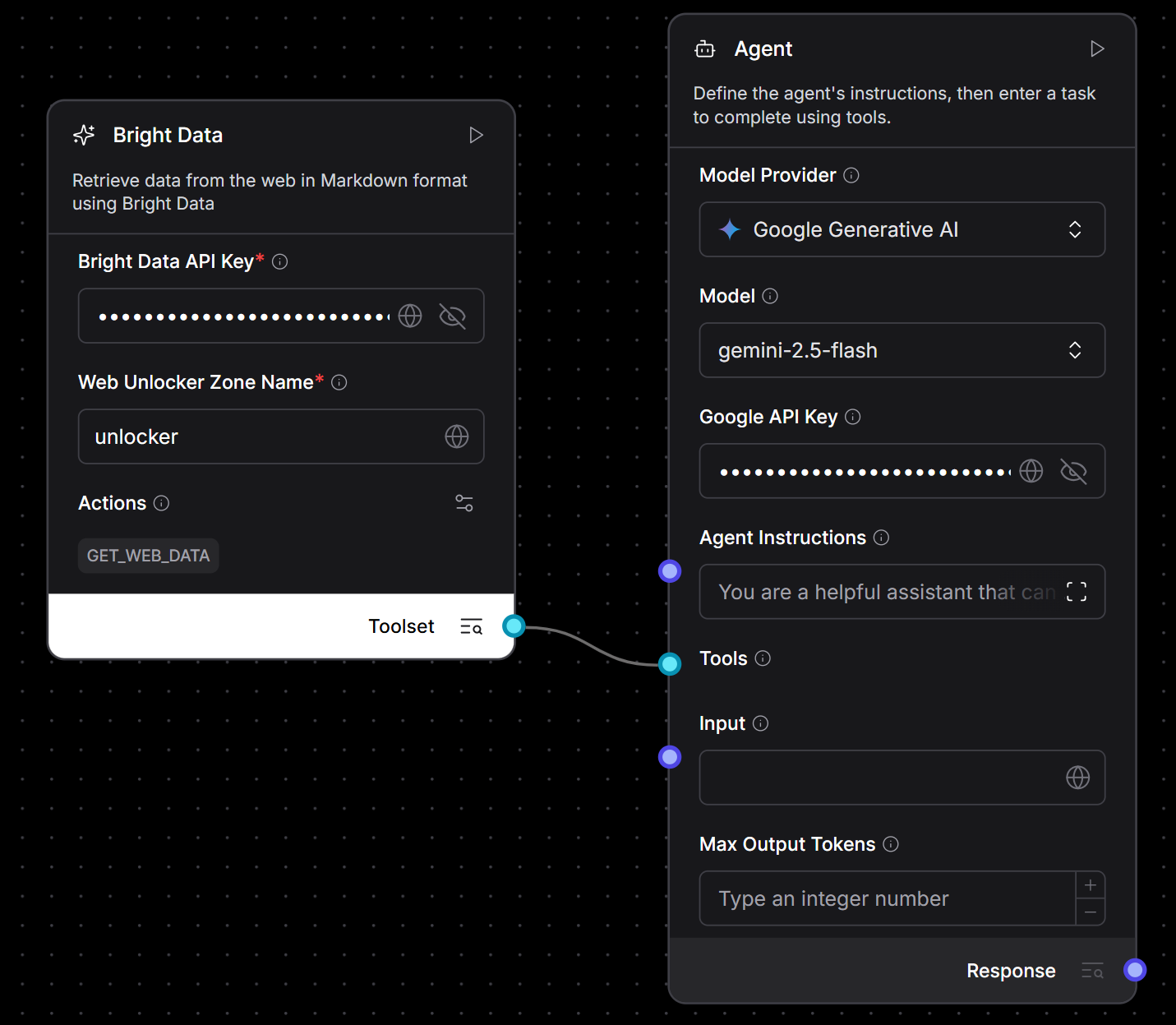
Вот и все! Ядро вашего приложения искусственного интеллекта теперь полностью подключено. Вы только что создали агента на базе Gemini, который может динамически получать живой веб-контент, используя инфраструктуру скрапинга Bright Data.
Шаг №7: Завершите поток
Чтобы ваш поток ИИ был полностью функциональным, ему нужен компонент ввода и компонент вывода. Поэтому подключите компонент Input Chat к своему агенту ИИ, а компонент Output Chat – к его ответу.
После этого ваш поток должен выглядеть следующим образом:
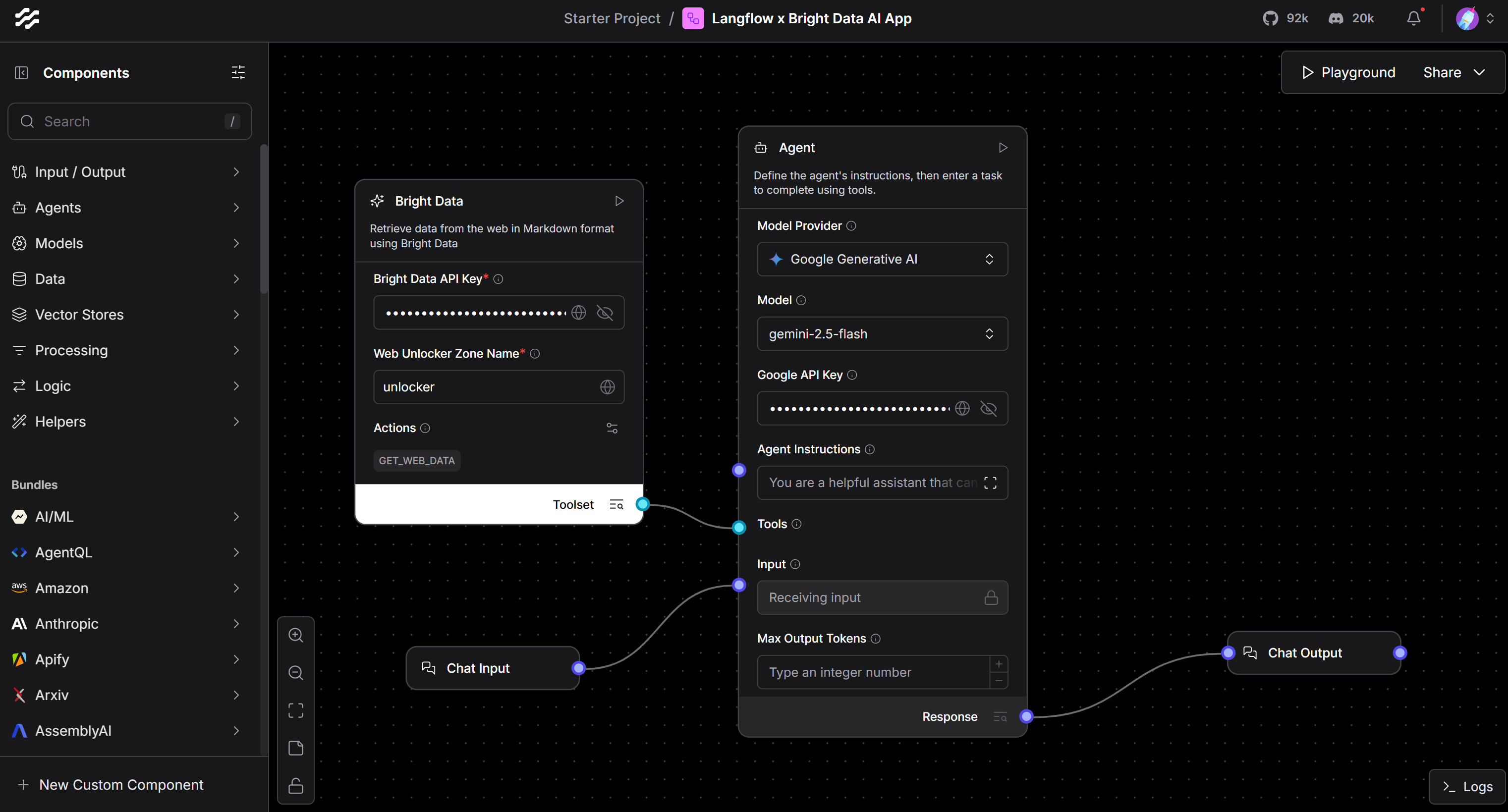
Вышеописанная настройка дает вам чатоподобный интерфейс для взаимодействия с агентом ИИ.
Вот и все! Ваше приложение Langflow × Bright Data AI завершено и готово к использованию.
Шаг № 8: тестирование приложения с искусственным интеллектом
Чтобы запустить приложение с искусственным интеллектом, нажмите кнопку “Playground” в правом верхнем углу интерфейса Langflow:

Вот что вы должны увидеть:
Вы получаете опыт в стиле ChatGPT, но с собственным агентом искусственного интеллекта. Чтобы убедиться, что все работает, попробуйте ввести запрос, например:
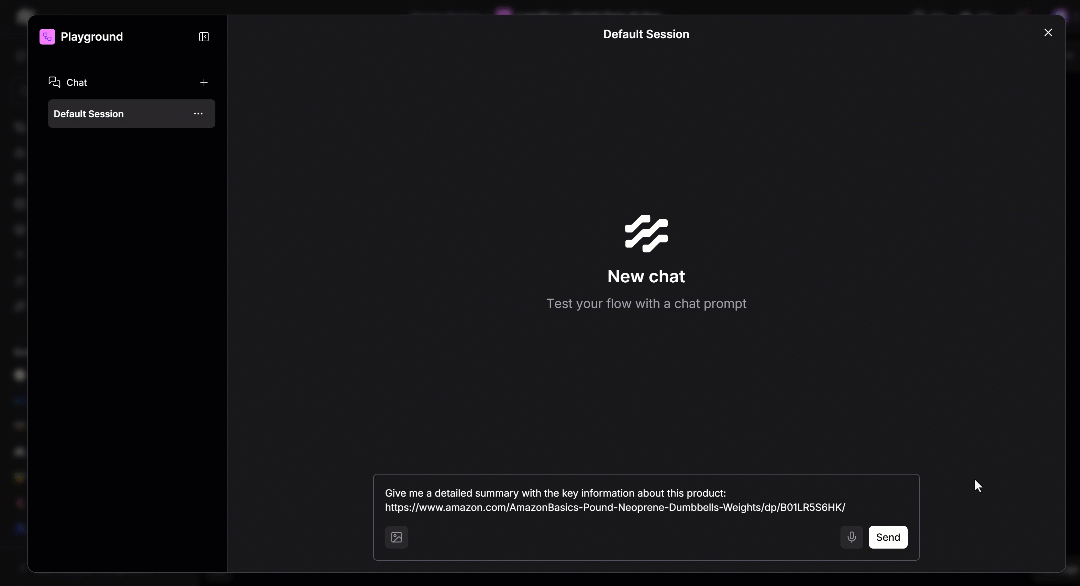
Give me a detailed summary with the key information about this product:
https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/Ниже описано, что будет происходить за кулисами:
- Подсказка передается из Chat Input в компонент AI Agent.
- Агент использует настроенный LLM (в данном случае Gemini) и запускает необходимый инструмент, поступающий из компонента Bright Data.
- Агент получает отсканированный веб-контент, обрабатывает его и передает окончательный ответ в Chat Output (он соответствует ответу, который вы увидите в чате).
Приведенная выше подсказка – отличный тест, поскольку Gemini сам по себе не может скреативить такие сайты, как Amazon, из-за их защиты от ботов. Web Unlocker от Bright Data решает эту проблему, обходя CAPTCHA Amazon, извлекая данные со страницы и предоставляя их в формате Markdown, пригодном для AI.
Запустите приглашение и вот что вы должны увидеть:
Чтобы подтвердить, что агент использовал Bright Data, раскройте выпадающий список “Доступ к web_get_data”:
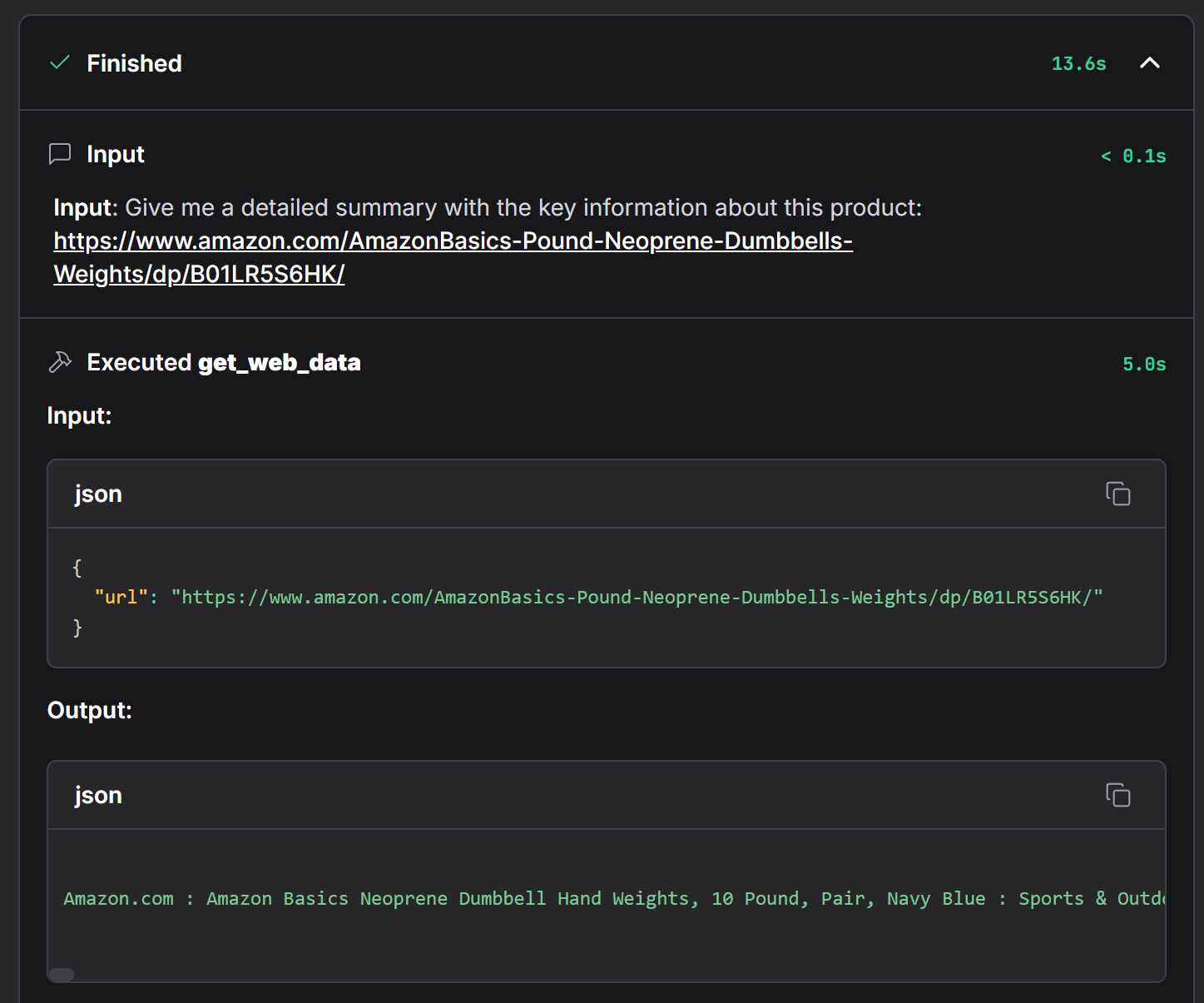
Здесь показаны все подробности вызова функции get_web_data, которая является основным методом компонента Bright Data. Здесь вы можете убедиться, что данные были успешно получены со страницы товара Amazon.
Вот неполный скриншот фактического результата, полученного агентом ИИ:

Каждая часть информации в этом сгенерированном искусственным интеллектом обзоре является реальной, а не галлюцинацией, в чем вы можете убедиться, посетив оригинальную страницу Amazon:
И вуаля! Вы только что создали и протестировали приложение искусственного интеллекта с веб-доступом к данным с помощью Langflow и Bright Data.
Следующие шаги
Теперь, когда ваша интеграция запущена, вот следующие шаги, которые вы можете предпринять:
- Разверните агент одним из официально поддерживаемых способов– в облаке или на собственном сервере.
- Расширьте интеграцию, подключив другие продукты Bright Data, например API Web Scraper или API SERP. Для этого просто измените логику в вашем
BrightDataComponent, чтобы вызывать различные API Bright Data , как описано в официальной документации. - Комбинируйте компоненты для создания более сложных сценариев использования, включая конвейеры RAG, рабочие процессы данных, потоки автоматизации ИИ и многое другое.
- Подключите своего агента искусственного интеллекта к серверу Bright Data MCP, чтобы интегрировать его с 50+ инструментами из коробки.
Заключение
В этой статье вы узнали, как использовать Langflow для создания агента искусственного интеллекта с веб-доступом к данным. Это стало возможным благодаря пользовательской интеграции с инструментами Bright Data. Такая настройка дает вашему LLM возможность получать и обрабатывать данные практически с любого веб-сайта в режиме реального времени.
Не забывайте, что мы представили здесь лишь базовый пример. Если вы планируете создать более продвинутых агентов, вам понадобятся инструменты для получения, проверки и преобразования живых веб-данных в информацию, оптимизированную для использования ИИ. Именно такие инструменты вы найдете в инфраструктуре ИИ Bright Data.
Создайте бесплатную учетную запись Bright Data и начните экспериментировать с нашими инструментами для поиска данных с помощью искусственного интеллекта!





