

В этом руководстве вы узнаете:
- Почему GPT Vision – отличный выбор для задач извлечения данных, выходящих за рамки традиционных методов синтаксического анализа.
- Как выполнить визуальный веб-скраппинг с помощью GPT Vision в Python.
- Основное ограничение этого подхода и способы его преодоления.
Давайте погрузимся!
Почему стоит использовать GPT Vision для сбора данных?
GPT Vision – это мультимодальная модель ИИ, которая понимает как текст, так и изображения. Эти возможности доступны в последних моделях OpenAI. Передавая GPT Vision изображение, вы можете выполнять визуальное извлечение данных, что идеально подходит для сценариев, в которых традиционный разбор данных не работает.
Обычный парсинг данных подразумевает написание пользовательских правил для получения данных из документов (например, селекторов CSS или выражений XPath для получения данных из HTML-страниц). Проблема заключается в том, что информация может быть визуально встроена в изображения, баннеры или сложные элементы пользовательского интерфейса, к которым невозможно получить доступ с помощью стандартных методов разбора.
GPT Vision поможет вам извлечь данные из этих труднодоступных источников. Два наиболее распространенных варианта использования:
- Визуальный веб-скраппинг: Извлекайте веб-контент непосредственно из скриншотов страниц, не заботясь об изменениях на странице или визуальных элементах на ней.
- Извлечение документов на основе изображений: Получение структурированных данных из скриншотов или сканов локальных файлов, таких как резюме, счета, меню и квитанции.
Если вы хотите использовать невизуальный подход, обратитесь к нашему руководству по веб-скраппингу с помощью ChatGPT.
Как извлечь данные из скриншотов с помощью GPT Vision в Python
В этом пошаговом разделе вы узнаете, как создать скрипт для веб-скрапинга GPT Vision. В деталях скрипт будет автоматизировать эти задачи:
- Используйте Playwright для подключения к целевой веб-странице.
- Сделайте снимок экрана конкретного раздела, из которого вы хотите извлечь данные.
- Передайте снимок экрана в GPT Vision и попросите его извлечь структурированные данные.
- Экспортируйте извлеченные данные в файл JSON.
Целью является конкретная страница товара из “Books to Scrape”:
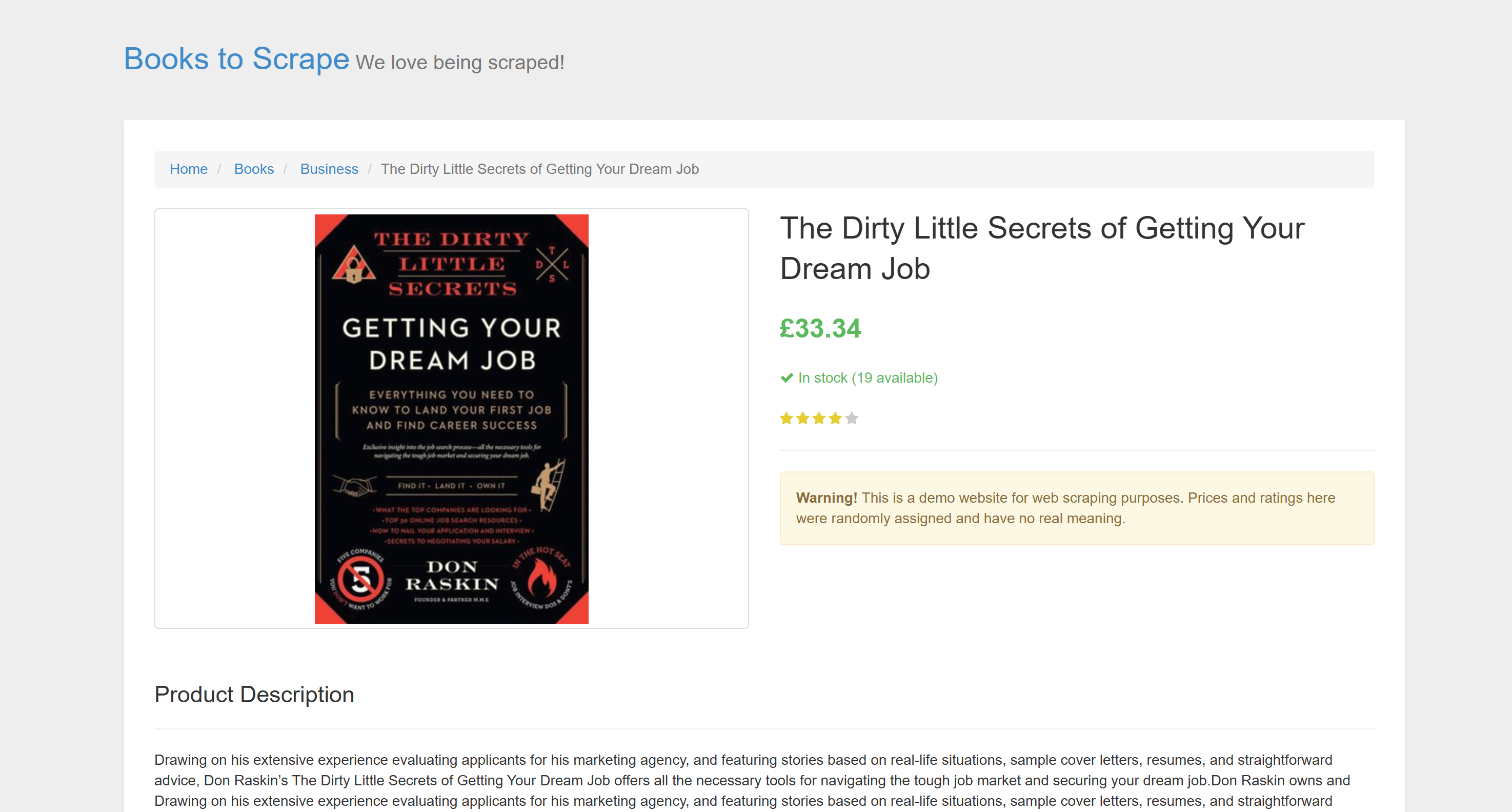
Эта страница идеально подходит для тестирования, потому что на ней явно приветствуются автоматические боты-скреперы. Кроме того, она включает в себя визуальные элементы, такие как виджет звездного рейтинга, с которыми сложно справиться обычными методами парсинга.
Примечание: Для простоты и потому, что OpenAI Python SDK широко распространен, пример фрагмента будет написан на Python. Однако вы можете добиться тех же результатов, используя JavaScript OpenAI SDK или любой другой поддерживаемый язык.
Следуйте приведенным ниже инструкциям, чтобы узнать, как соскабливать веб-данные с помощью GPT Vision!
Пререквизиты
Прежде чем приступить к работе, убедитесь, что у вас есть:
- На вашем компьютере установленPython 3.8 или выше.
- Ключ API OpenAI для доступа к API GPT Vision.
Чтобы получить свой ключ API OpenAI, следуйте официальному руководству.
Приведенные ниже справочные сведения также помогут вам извлечь максимум пользы из этой статьи:
- Базовое понимание автоматизации браузера, в частности, с помощью Playwright.
- Знакомство с принципами работы GPT Vision.
Примечание: Для этого подхода требуется инструмент автоматизации браузера, например Playwright. Причина в том, что вам нужно отобразить целевую страницу в браузере. Затем, когда страница загрузится, вы можете сделать скриншот интересующего вас раздела. Это можно сделать с помощью Playwright Screenshots API.
Шаг #1: Создайте свой проект Python
Выполните следующую команду в терминале, чтобы создать новую папку для вашего проекта скрапбукинга:
mkdir gpt-vision-scrapergpt-vision-scraper/ будет служить основной папкой проекта для создания вашего веб-скрепера с помощью GPT Vision.
Перейдите в эту папку и создайте в ней виртуальную среду Python:
cd gpt-vision-scraper
python -m venv venvОткройте папку проекта в предпочитаемой вами IDE Python. Подойдет Visual Studio Code с расширением Python или PyCharm Community Edition.
В папке проекта создайте файл scraper.py:
gpt-vision-scraper
├─── venv/
└─── scraper.py # <------------На данный момент scraper.py – это просто пустой файл. Вскоре он будет содержать логику для визуального скрапинга LLM через GPT Vision.
Затем активируйте виртуальную среду в терминале. В Linux или macOS запустите:
source venv/bin/activateАналогично, в Windows выполните команду:
venv/Scripts/activateОтлично! Теперь ваша среда Python готова к визуальному скраппингу с помощью GPT Vision.
Примечание: В следующих шагах будет показано, как установить необходимые зависимости. Если вы предпочитаете установить их все сразу, выполните эту команду:
pip install playwright openaiЗатем:
python -m playwright installОтлично! Теперь ваша среда Python готова.
Шаг № 2: Подключение к целевому сайту
Сначала нужно указать Playwright посетить целевой сайт с помощью управляемого браузера. В активированной виртуальной среде установите Playwright с помощью:
pip install playwright Затем завершите установку, загрузив необходимые двоичные файлы браузера:
python -m playwright installДалее импортируйте Playwright в свой сценарий и используйте функцию goto() для перехода на целевую страницу:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Screenshotting logic...
# Close the browser and release its resources
browser.close()Если вы не знакомы с этим API, прочитайте нашу статью о веб-скрапинге с помощью Playwright.
Потрясающе! Теперь у вас есть сценарий Playwright, который успешно подключается к целевой странице. Пора сделать снимок экрана.
Шаг № 3: Сделайте скриншот страницы
Прежде чем писать логику для создания скриншота, имейте в виду, что OpenAI взимает плату в зависимости от использования токенов. Другими словами, чем больше скриншот, тем больше вы потратите.
Чтобы сократить расходы, лучше всего ограничить скриншот только HTML-элементами, содержащими интересующие вас данные. Это возможно, поскольку Playwright поддерживает скриншоты на основе узлов. Сужение скриншота также поможет GPT Vision сосредоточиться на релевантном содержимом, что снижает риск возникновения галлюцинаций.
Начните с открытия целевой страницы в браузере и ознакомления с ее структурой. Затем щелкните правой кнопкой мыши на содержимом и выберите “Inspect”, чтобы открыть DevTools браузера:
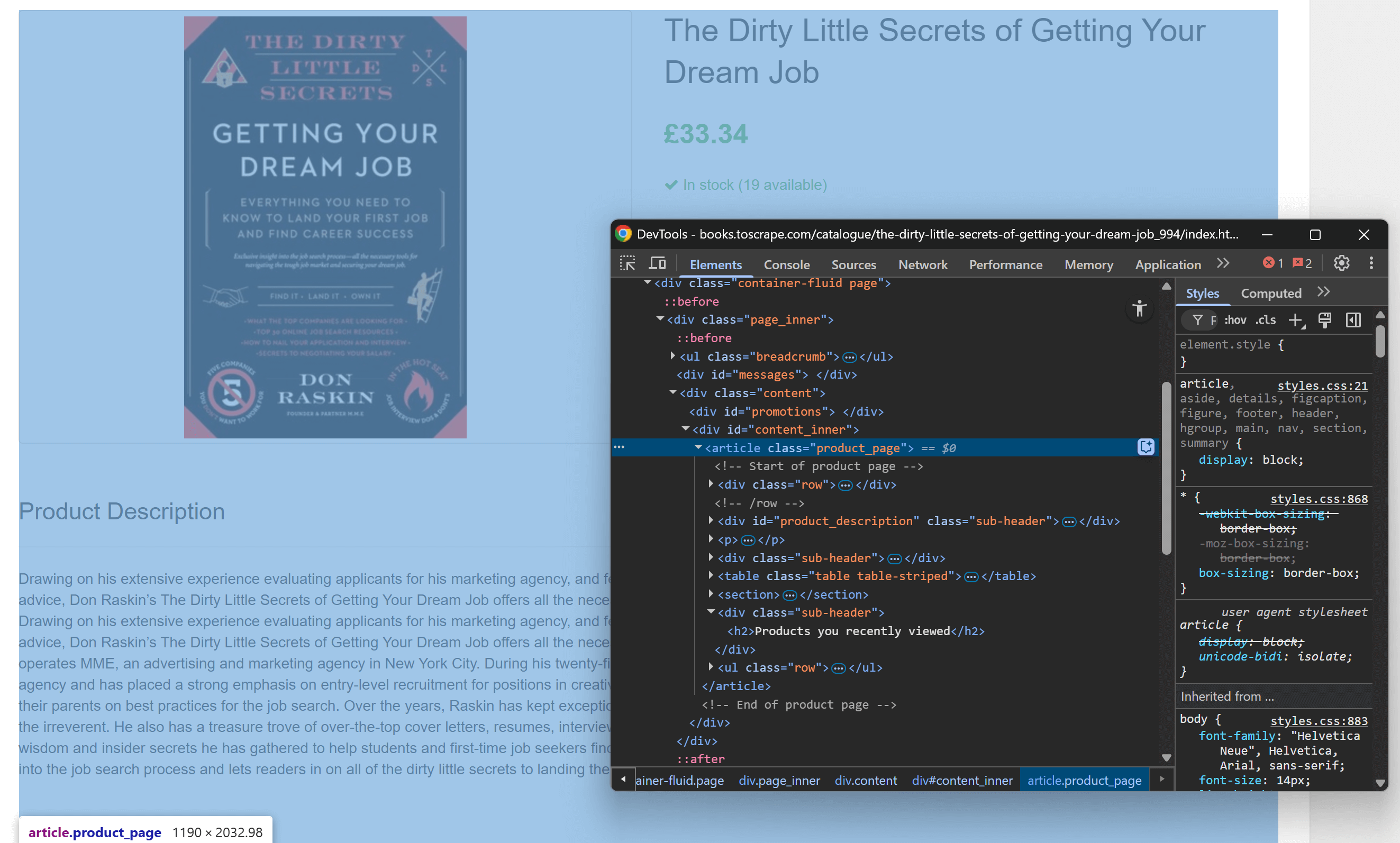
Вы заметите, что большая часть релевантного содержимого содержится в HTML-элементе .product_page.
Поскольку этот элемент может быть динамически загружен или раскрыт с помощью JavaScript, вам следует дождаться его появления перед захватом:
product_page_element = page.locator(".product_page")
product_page_element.wait_for()По умолчанию функция wait_for() будет ждать до 30 секунд, пока элемент не появится в DOM. Этот микрошаг очень важен, так как вы не хотите делать скриншот пустой или невидимой секции.
Теперь используйте метод screenshot() для выбранного локатора, чтобы сделать снимок экрана только этого элемента:
product_page_element.screenshot(path=SCREENSHOT_PATH)Здесь SCREENSHOT_PATH – это переменная, содержащая имя выходного файла, например:
SCREENSHOT_PATH = "product_page.png"Хранить эту информацию в переменной – хорошая идея, поскольку вскоре она вам снова понадобится.
Если вы запустите скрипт, он создаст файл с именем product_page.png, содержащий:
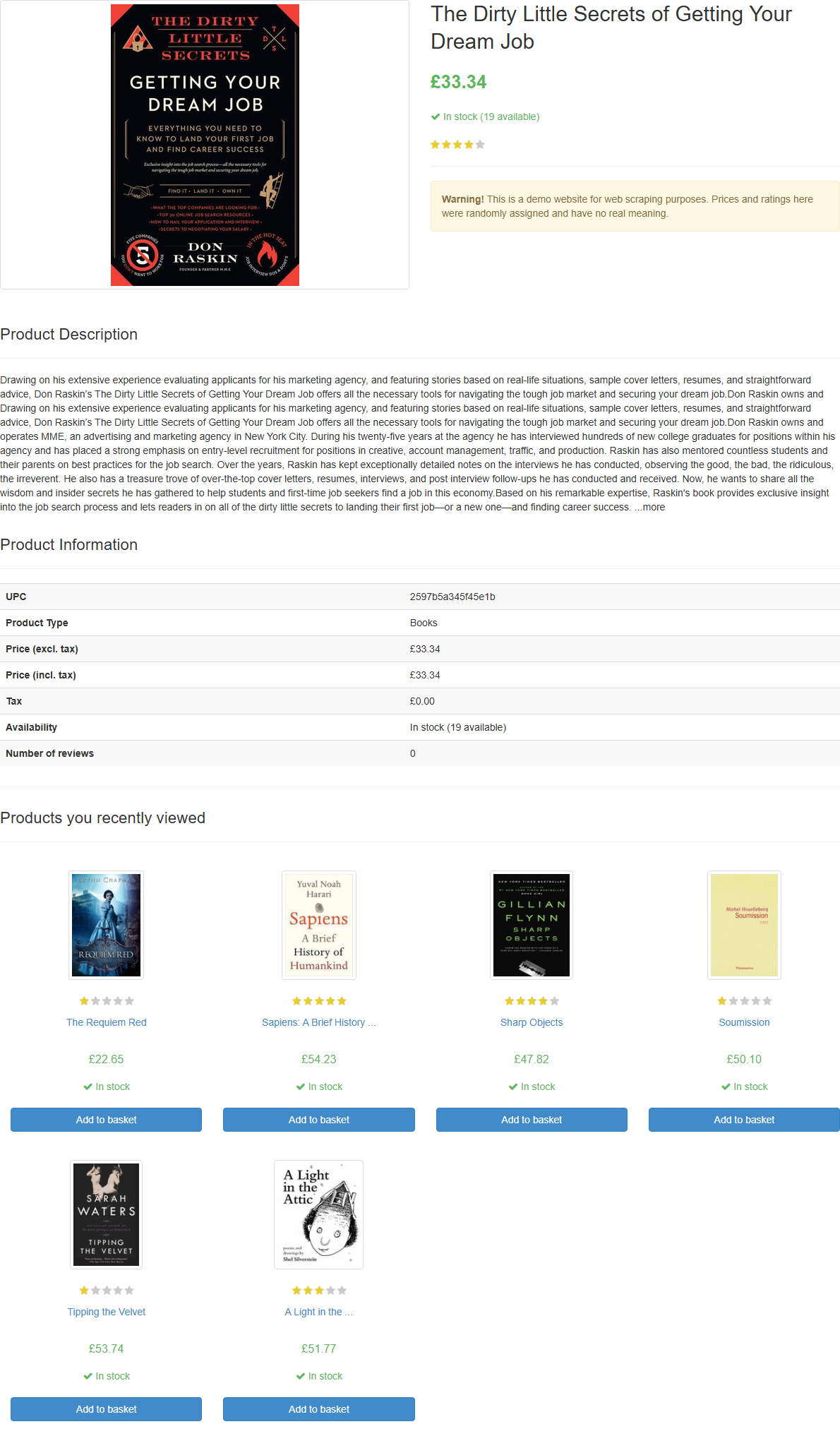
Примечание: Лучше всего сохранить снимок экрана в файл, потому что позже вы можете захотеть проанализировать его, используя другие методы или модели.
Фантастика! Со скриншотами покончено.
Шаг #4: Настройка OpenAI в Python
Чтобы использовать GPT Vision для веб-скрапинга, вы можете воспользоваться OpenAI Python SDK. В активированной виртуальной среде установите пакет openai:
pip install openaiЗатем импортируйте клиент OpenAI в файле scraper.py:
from openai import OpenAIПродолжите инициализацию экземпляра клиента OpenAI:
client = OpenAI()Это позволит вам легче подключаться к API OpenAI, включая API Vision. По умолчанию конструктор OpenAI() ищет ваш ключ API в переменной окружения OPENAI_API_KEY. Установка этой переменной является рекомендуемым способом безопасной настройки аутентификации.
Для целей разработки или тестирования вы можете добавить ключ непосредственно в код:
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
client = OpenAI(api_key=OPENAI_API_KEY)Замените на ваш реальный ключ OpenAI API.
Замечательно! Настройка OpenAI завершена, и вы готовы использовать GPT Vision для веб-скрапинга.
Шаг #5: Отправьте запрос на скрапирование GPT Vision
GPT Vision принимает входные изображения в нескольких форматах, включая публичные URL-адреса изображений. Поскольку вы работаете с локальным файлом, вы должны отправить изображение на сервер OpenAI, преобразовав его в Base64-кодированную строку.
Чтобы преобразовать файл скриншота в Base64, напишите следующий код:
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8") Это требует импорта из стандартной библиотеки Python:
import base64Теперь передайте закодированное изображение в GPT Vision для визуального веб-скреппинга:
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)Примечание: В приведенном примере используется модель gpt-4.1, но вы можете использовать любую модель OpenAI, поддерживающую визуальные возможности.
Обратите внимание, что GPT Vision напрямую интегрирован в API Responses. Это означает, что вам не нужно настраивать ничего особенного. Просто включите изображение в формате Base64, используя "type": "input_image", и все готово.
Выше использован запрос на поиск:
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.Вы можете не знать точной структуры целевой страницы, поэтому подсказки должны быть довольно общими (но при этом направленными на достижение цели). Здесь мы явно указали модели игнорировать не интересующие нас разделы. Также мы попросили вернуть JSON-объект с чистыми, хорошо структурированными именами ключей.
Обратите внимание, что API-запрос OpenAI Responses настроен на работу в режиме JSON. Так вы можете гарантировать, что модель будет выдавать данные в формате JSON. Чтобы эта функция работала, ваш запрос должен содержать инструкцию для возврата данных в JSON, например:
Return the data in JSON format using lowercase snake_case attribute names.В противном случае запрос завершится неудачей:
openai.BadRequestError: Error code: 400 - {
'error': {
'message': "Response input messages must contain the word 'json' in some form to use 'text.format' of type 'json_object'.",
'type': 'invalid_request_error',
'param': 'input',
'code': None
}
}После успешного завершения запроса вы можете получить доступ к разобранным структурированным данным с помощью:
json_product_data = response.output_textВ качестве опции можно разобрать полученную строку и преобразовать ее в словарь Python:
import json
product_data = json.loads(json_product_data)Логика разбора данных GPT Vision завершена! Осталось только экспортировать собранные данные в локальный JSON-файл.
Шаг № 6: Экспорт собранных данных
Запишите выходную строку JSON, полученную в результате вызова GPT Vision API:
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)В результате будет создан файл product.json, содержащий визуально извлеченные данные.
Отлично! Теперь ваш веб-скрепер на базе GPT Vision готов.
Шаг №7: Соберите все вместе
Ниже приведен окончательный код scraper.py:
from playwright.sync_api import sync_playwright
from openai import OpenAI
import base64
# Where to store the page screenshot
SCREENSHOT_PATH = "product_page.png"
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Wait for the product page element to be on the DOM
product_page_element = page.locator(".product_page")
product_page_element.wait_for()
# Take a full screenshot of the element
product_page_element.screenshot(path=SCREENSHOT_PATH)
# Close the browser and release its resources
browser.close()
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot from the filesystem
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the data extraction request via GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)
# Extract the output data and export it to a JSON file
json_product_data = response.output_text
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)Вот это да! Менее чем за 65 строк кода вы только что выполнили визуальный веб-скраппинг с помощью GPT Vision.
Выполните скребок GPT Vision с помощью:
python scraper.pyСкрипт займет некоторое время, а затем запишет файл product.json в папку вашего проекта. Откройте его, и вы увидите:
{
"title": "The Dirty Little Secrets of Getting Your Dream Job",
"price_gbp": "£33.34",
"availability": "In stock (19 available)",
"rating": "4/5",
"description": "Drawing on his extensive experience evaluating applicants for his marketing agency, and featuring stories based on real-life situations, sample cover letters, resumes, and straightforward advice, Don Raskin’s The Dirty Little Secrets of Getting Your Dream Job offers all the necessary tools for navigating the tough job market and securing your dream job... [omitted for brevity]",
"product_information": {
"upc": "2597b5a345f45e1b",
"product_type": "Books",
"price_excl_tax": "£33.34",
"price_incl_tax": "£33.34",
"tax": "£0.00",
"availability": "In stock (19 available)"
}
}Обратите внимание, как он успешно извлек всю информацию о продукте на странице, включая оценку отзыва, из чисто визуального элемента:

И вуаля! GPT Vision смог преобразовать снимок экрана в аккуратно структурированный JSON-файл.
Следующие шаги
Чтобы улучшить работу скрепера GPT Vision, воспользуйтесь следующими настройками:
- Сделайте его многоразовым: Переделайте скрипт так, чтобы он принимал целевой URL, CSS-селектор элемента, который нужно дождаться, и запрос LLM из CLI. Таким образом, вы сможете скрапировать разные страницы, не изменяя код.
- Защитите свой ключ API: вместо того чтобы жестко кодировать свой ключ API OpenAI, сохраните его в файле
.envи загрузите с помощью пакетаpython-dotenv. Или же задайте его в качестве глобальной переменной окружения с именемOPENAI_API_KEY. Оба способа помогут защитить ваши учетные данные и обезопасить кодовую базу.
Преодоление самого большого ограничения визуального веб-скрапинга
Основная проблема такого подхода к веб-скреппингу заключается в этапе создания скриншотов. Если на сайте-песочнице вроде “Книги для скрапа” он работает безупречно, то реальные сайты представляют собой совсем другую реальность.
На многих современных веб-сайтах применяются меры по борьбе со скраппингом, которые могут заблокировать ваш скрипт до того, как вы получите доступ к странице. Даже если ваш скрапер успешно получит доступ к странице, вам может быть выдана ошибка или запрос на проверку человеком. Например, это происходит при использовании ванильного Playwright на таких сайтах, как G2.com:

Эти проблемы могут быть вызваны отпечатками браузера, репутацией IP-адреса, ограничением скорости, проблемами с CAPTCHA и многим другим.
Самый надежный способ обойти такие блокировки – использовать специальный API для разблокировки веб-приложений!
Web Unlocker от Bright Data – это мощная конечная точка для скраппинга, которая опирается на прокси-сеть из более чем 150 миллионов IP-адресов. В частности, он предлагает подмену отпечатков пальцев, рендеринг JavaScript, возможность решения CAPTCHA и многие другие функции. Он даже поддерживает захват скриншотов, что означает, что вы можете полностью отказаться от ручной логики создания скриншотов в Playwright.
Допустим, вы хотите извлечь средний рейтинг звезд со страницы продавца G2 компании Bright Data:
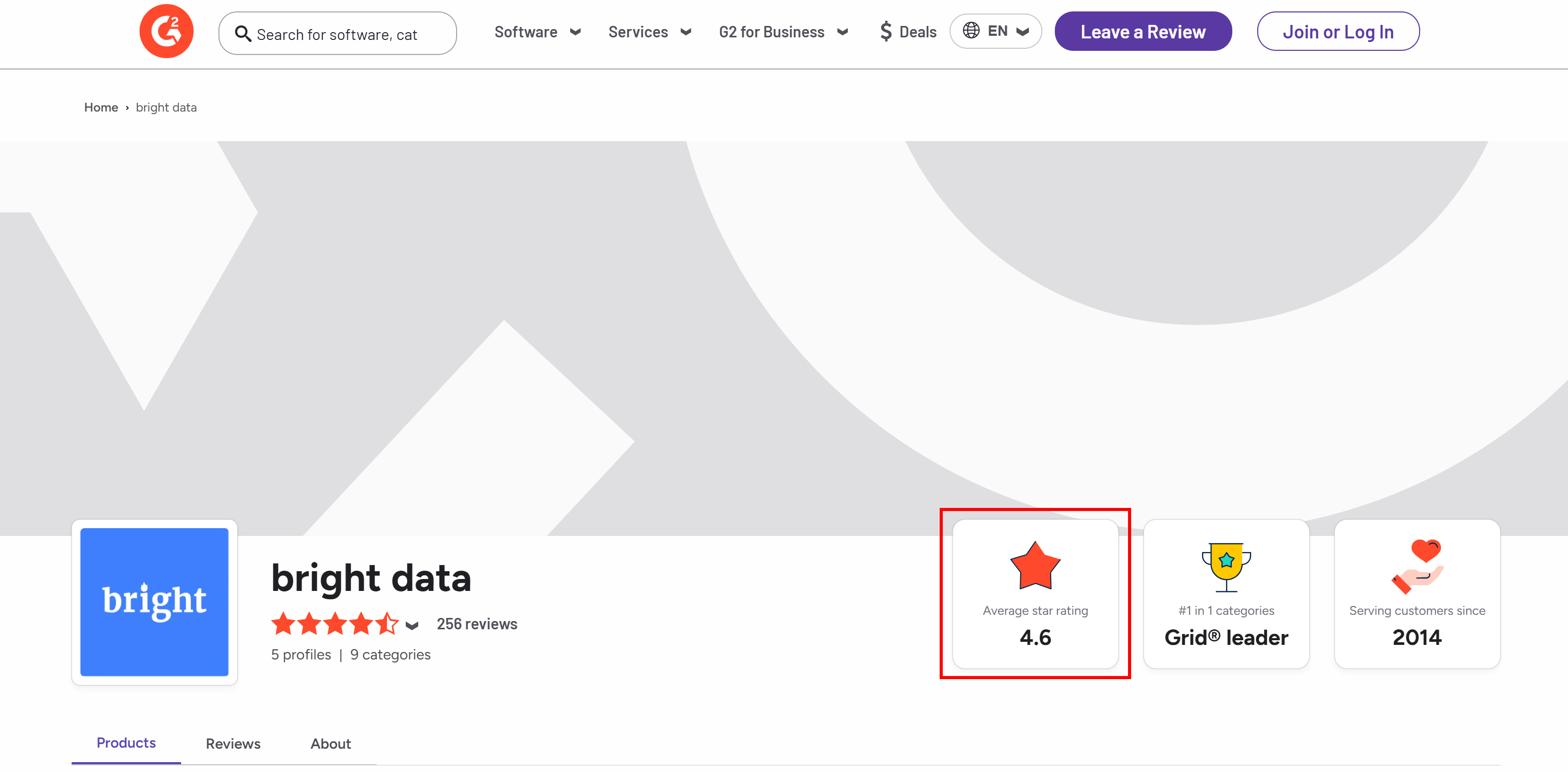
Чтобы начать работу, настройте Web Unlocker, как описано в документации, и получите свой API-ключ Bright Data. Используйте GPT Vision вместе с Web Unlocker следующим образом:
# pip install requests
import requests
from openai import OpenAI
import base64
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
# Get a screenshot of the target page using Bright Data Web Unlocker
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": "web_unlocker", # Replace with your Web Unlocker zone name
"url": "https://www.g2.com/sellers/bright-data", # Your target page
"format": "raw",
"data_format": "screenshot" # Enable the screenshotting mode
}
response = requests.post(url, headers=headers, json=payload)
# Where to store the scraped screenshot
SCREENSHOT_PATH = "screenshot.png"
# Save the screenshot to a file (e.g., for further analysis in the future)
with open(SCREENSHOT_PATH, "wb") as f:
f.write(response.content)
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot file and convert its contents to Base64
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the scraping request using GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Return the average star rating from the following image.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
)
print(response.output_text)Выполните приведенный выше скрипт, и он выдаст результат, похожий на:
The average star rating from the image is 4.6.Это верная информация, что вы можете подтвердить визуально в сгенерированном файле screenshot.png, возвращенном Web Unlocker:
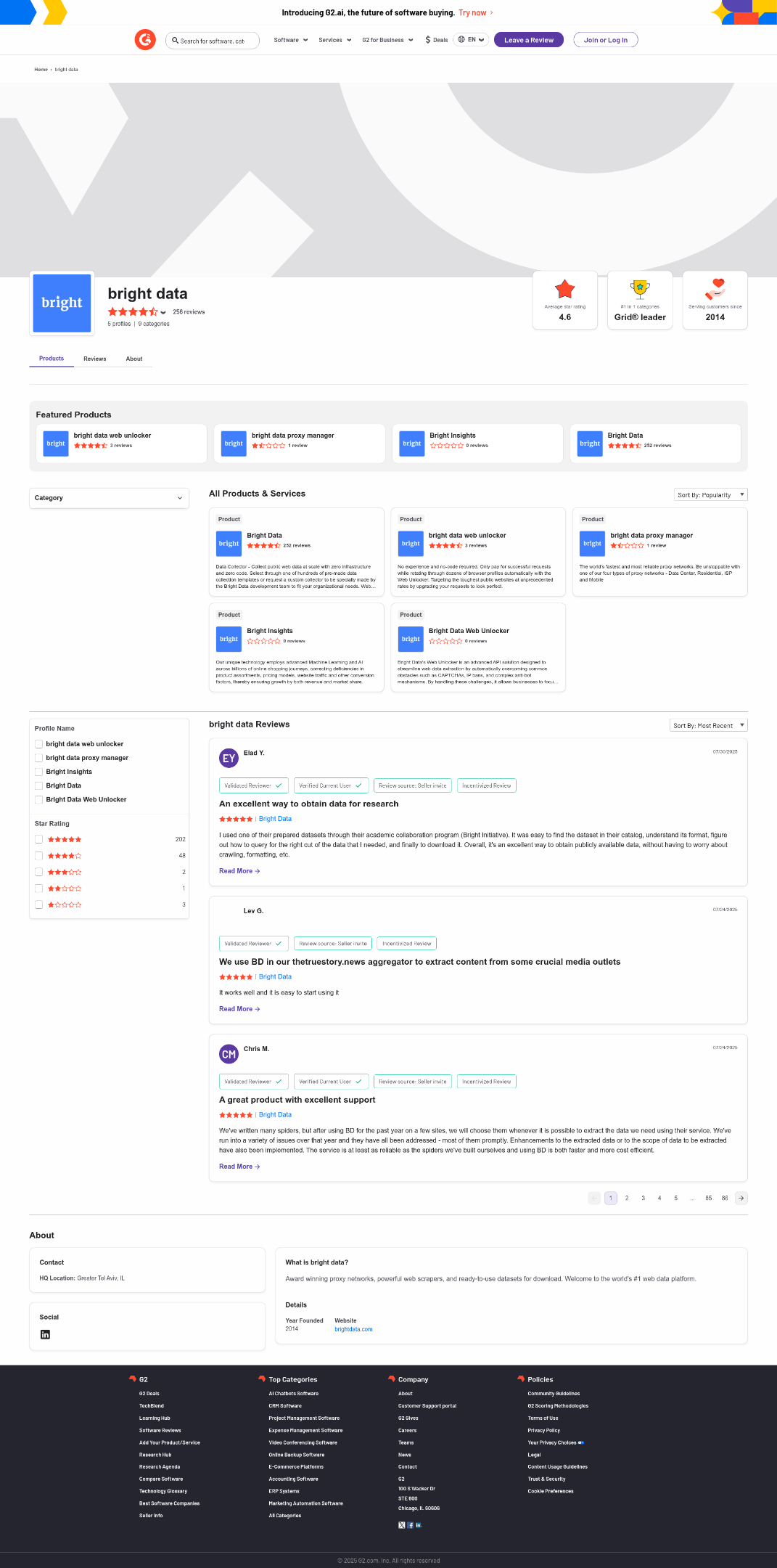
Обратите внимание, что с помощью Web Unlocker вы можете получить полностью разблокированный HTML страницы или даже получить ее содержимое в формате Markdown, оптимизированном для AI.
И вот так – больше никаких блоков, никаких головных болей. Теперь у вас есть веб-скрепер производственного класса на базе GPT Vision, который работает даже на защищенных веб-сайтах.
Посмотрите, как OpenAI SDK и Web Unlocker работают вместе в более сложном сценарии скраппинга.
Заключение
В этом уроке вы узнали, как объединить GPT Vision с возможностями снятия скриншотов из Playwright, чтобы создать веб-скрепер на базе ИИ. Самая большая проблема (например, блокировка при снятии скриншотов) была решена с помощью API Bright Data Web Unlocker.
Как уже говорилось, сочетание GPT Vision с функцией скриншотов, предоставляемой Web Unlocker API, позволяет визуально извлекать данные с любого веб-сайта. И все это без написания собственного кода парсинга. Это лишь один из множества сценариев, охватываемых продуктами и услугами Bright Data в области искусственного интеллекта.
Создайте бесплатную учетную запись Bright Data и экспериментируйте с нашими решениями для работы с данными!




