

В условиях продолжающегося экспоненциального роста цифровой экономики сбор данных из различных источников, таких как API-интерфейсы, веб-сайты и базы данных, важен как никогда.
Одним из распространенных способов извлечения данных является веб-парсинг. Веб-парсинг предполагает использование автоматизированных инструментов для извлечения веб-страниц, парсинга их контента и получения конкретной информации для дальнейшего анализа и использования. Распространенные варианты использования веб-парсинга включают исследование рынка, мониторинг цен и агрегирование данных.
Внедрение веб-парсинга требует обработки динамического контента, управления сеансами и файлами cookie, обхода мер по борьбе с парсингом и обеспечения соблюдения законодательства. Для решения этих задач необходимы передовые инструменты и методы для эффективного извлечения данных. ChatGPT может помочь справиться с этими трудностями, используя возможности обработки естественного языка для генерации кода и устранения ошибок.
Из этой статьи вы узнаете, как использовать ChatGPT для создания кода парсинга веб-сайтов, использующих в основном статический HTML-контент, и сложных веб-сайтов с более продвинутыми методами генерации страниц.
Предварительные условия
Прежде чем приступить к изучению этого руководства, убедитесь, что выполнены следующие условия:
- Вы знакомы с Python
- Среда Python установлена и настроена на вашем компьютере с помощью Visual Studio Code
- У вас есть аккаунт ChatGPT
При использовании ChatGPT для создания скриптов веб-парсинга выполняйте два основных шага:
- Документируйте каждый шаг, который должен выполнить код, чтобы найти нужную информацию, например, на какие элементы HTML следует нацеливаться, какие текстовые поля заполнять и какие кнопки нажимать. Часто вам нужно скопировать конкретный селектор HTML-элементов. Для этого нажмите правой кнопкой мыши на конкретный элемент страницы, парсинг которого хотите выполнить, а затем выберите «Просмотреть код» (Inspect), и Chrome выделит нужный элемент DOM. Щелкните правой кнопкой мыши и выберите «Копировать» > «Копировать селектор» для копирования пути к HTML-селектору в буфер обмена:
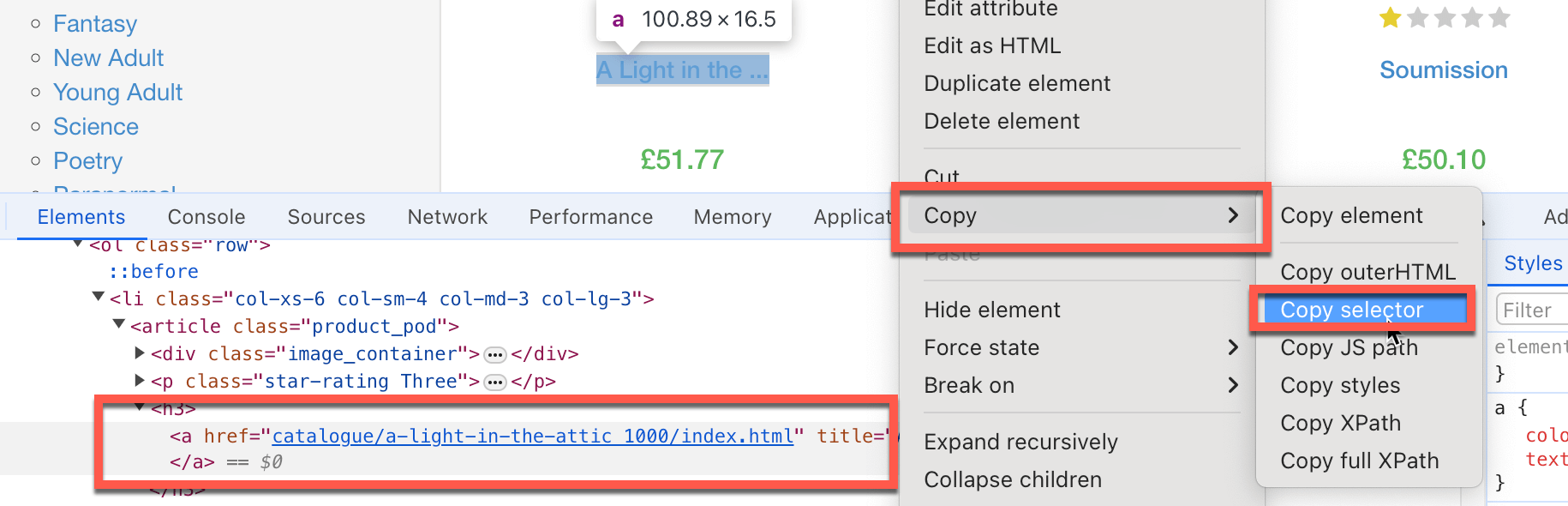 .
.
- Создайте конкретные и подробные подсказки ChatGPT для генерации кода парсинга.
- Выполните и протестируйте сгенерированный код.
Парсинг веб-сайтов со статическим HTML с помощью ChatGPT
Теперь, когда вы знакомы с общим рабочим процессом, давайте воспользуемся ChatGPT для парсинга некоторых веб-сайтов со статическими элементами HTML. Для начала вы выполните парсинг названия книг и цен с сайта https://books.toscrape.com.
Прежде всего вам необходимо определить элементы HTML, содержащие нужные вам данные:
- Селектор названия книги:
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a. - Селектор цены книги: *
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color.
Затем вам нужно создать конкретные и подробные подсказки ChatGPT для генерации кода парсинга. Для этого необходимо попросить ChatGPT установить все необходимые пакеты Python, помочь ему извлечь HTML-селекторы (которые вы указали ранее), а затем попросить его сохранить данные в виде файла Excel.
Не забудьте выбрать GPT-4o в качестве версии ChatGPT.
В ChatGPT можно ввести что-то вроде этого:
Вы эксперт по парсингу веб-страниц, использующий библиотеку Python Beautiful Soup и все необходимые инструменты автоматизации. Я хочу, чтобы вы создали подробный пошаговый скрипт для парсинга
https://books.toscrape.com. Сделайте следующее:
- Установите все необходимые пакеты Python.
- Извлеките название книги с HTML-селектором
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > aи цену книги (только число и ничего больше) с селектором#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color.- Извлеките список всех названий книг и цен и сохраните его в файле Excel.
- Выполните парсинг только первой страницы.
Обратите внимание: возможно, вы получите немного другой ответ.
В ответе ChatGPT предлагает вам выполнить следующую команду для установки библиотеки Beautiful Soup, которая выполняет веб-парсинг и библиотеки pandas, комплексной библиотеки анализа данных, в которой данные хранятся в формате Excel:
pip3 install requests beautifulsoup4 pandas openpyxl
Вы заметите, что ChatGPT также предлагает установить openpyxl, но здесь в этом нет необходимости.
ChatGPT также предоставляет следующий код для веб-парсинга:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL of the website
url = 'https://books.toscrape.com'
# Send a GET request to the website
response = requests.get(url)
if response.status_code == 200:
# Parse the HTML content of the page
soup = BeautifulSoup(response.content, 'html.parser')
# Initialize lists to store the titles and prices
book_titles = []
book_prices = []
# Extract the first book title and price using the provided selectors
book_title_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a"
book_price_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color"
title_element = soup.select_one(book_title_selector)
price_element = soup.select_one(book_price_selector)
if title_element and price_element:
book_titles.append(title_element.get('title'))
book_prices.append(price_element.text.strip()[1:])
# Extract all book titles and prices on the first page
books = soup.select('section > div:nth-child(2) > ol > li')
for book in books:
title = book.select_one('h3 > a')
price = book.select_one('div.product_price > p.price_color')
if title and price:
book_titles.append(title.get('title'))
book_prices.append(price.text.strip()[1:])
# Create a DataFrame from the lists
df = pd.DataFrame({
'Title': book_titles,
'Price': book_prices
})
# Save the DataFrame to an Excel file
df.to_excel('books_scraped.xlsx', index=False)
print('Data has been successfully scraped and saved to books_scraped.xlsx')
else:
print('Failed to retrieve the webpage')
Этот код импортирует модуль requests , который выполняет HTTP-вызовы на веб-сайт, являющийся объектом парсинга. Он также импортирует пакеты pandas, которые хранят очищенные данные в файлах Excel. Код определяет базовый URL-адрес веб-сайта и конкретные HTML-селекторы, на которые он нацеливается для получения запрошенных данных.
Затем код вызывает веб-сайт и помещает его контент в виде объекта BeautifulSoup под названием soup. Код выбирает значения названия и цены книги в виде списков из объекта soup с помощью HTML-селекторов. Наконец, код создает pandas DataFrame из названия книги и прайс-листа и сохраняет его в виде файла Excel.
Далее необходимо сохранить код в файл с именем books_scraping.py и запустить команду python3 books_scraping.py из командной строки. Этот код создает файл Excel с именем books_scraped.xlsx в каталоге, где находится books_scraping.py:

Теперь, когда вы рассмотрели один пример, давайте перейдем к этому уроку и другому простому веб-сайту https://quotes.toscrape.com, который содержит коллекцию цитат.
Опять же, давайте начнем с определения последовательности шагов.
Если вы используете Chrome, найдите следующие HTML-селекторы:
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.textдля парсинга цитатыbody > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > smallдля идентификации автора
После того как вы определили желаемые HTML-селекторы для парсинга, вы можете составить подробное приглашение, подобное приведенному ниже, для создания кода парсинга:
Вы эксперт по веб-парсингу, использующий библиотеку Python Beautiful Soup и все необходимые инструменты автоматизации. Я хочу, чтобы вы создали подробный пошаговый скрипт для парсинга
https://quotes.toscrape.com. Пожалуйста, сделайте следующее:
- Установите все необходимые пакеты Python.
- Извлеките цитату, в которой есть HTML-селектор
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text, and the author name, which has the selectorbody > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small.- Извлеките список всех цитат и авторов и сохраните его в файл Excel.
- Выполните парсинг только первой страницы.
После ввода этой информации ChatGPT должен предоставить вам следующую команду для установки библиотек Beautiful Soup, pandas и openpyxl:
pip3 install requests beautifulsoup4 pandas openpyxl
ChatGPT также должен предоставить следующий код для веб-парсинга:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Step 1: Fetch the web page content
url = "https://quotes.toscrape.com"
response = requests.get(url)
html_content = response.text
# Step 2: Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")
Сохраните этот код в файле с именем quotes_scraping.py и запустите команду python3 books_scraping.py из командной строки. Этот код создает файл Excel с именем quotes_scraped.xlsx в каталоге, где находится quotes_scraping.py. Откройте сгенерированный файл Excel, который должен выглядеть следующим образом:

Парсинг сложных веб-сайтов
Парсинг сложных веб-сайтов может быть непростой задачей, поскольку динамический контент часто загружается с помощью JavaScript, а такие инструменты, как requests и BeautifulSoup , не могут обрабатывать его. Для доступа ко всем данным на этих сайтах могут потребоваться такие взаимодействия, как нажатие кнопок или прокрутка. Чтобы решить эту проблему, вы можете использовать WebDriver, который отображает страницы как браузер и имитирует взаимодействие пользователей, обеспечивая доступ ко всему контенту так же, как его получает обычный пользователь.
Например, Yelp — это краудсорсинговый сайт с отзывами о компаниях. Yelp использует динамическую генерацию страниц и должен имитировать несколько взаимодействий пользователей. Здесь вы будете использовать ChatGPT для создания кода парсинга, который извлекает список компаний Стокгольма и их рейтинги.
Давайте начнем парсинг Yelp с документирования следующих шагов:
- Найдите селектор текстового поля местоположения, которое будет использовать скрипт; в данном случае это
#search_location. Введите «Stockholm» в поле поиска местоположения, а затем найдите селектор кнопок поиска; в данном случае это#header_find_form > div.y-css-1iy1dwt > button. Нажмите кнопку поиска, чтобы увидеть результаты поиска. Поиск может занять несколько секунд. Найдите селектор, содержащий название компании, (например,#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a):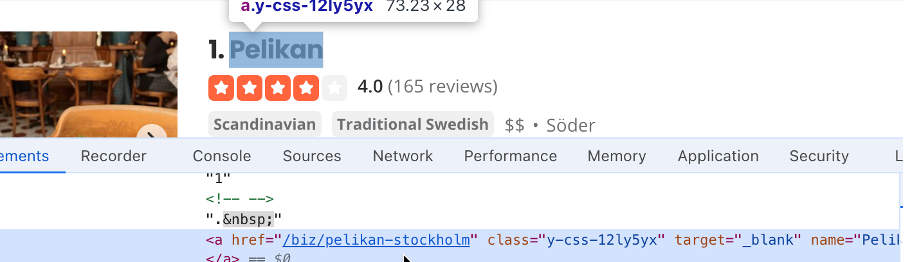
- Найдите селектор, содержащий оценку компании (например,
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv):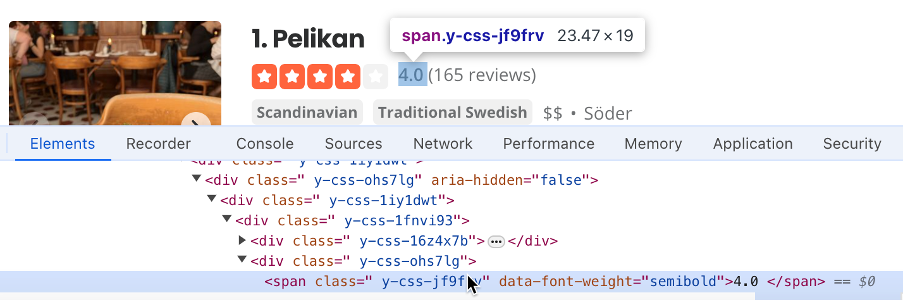
- Найдите селектор кнопки «Открыто сейчас» (Open Now). Здесь это
#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span: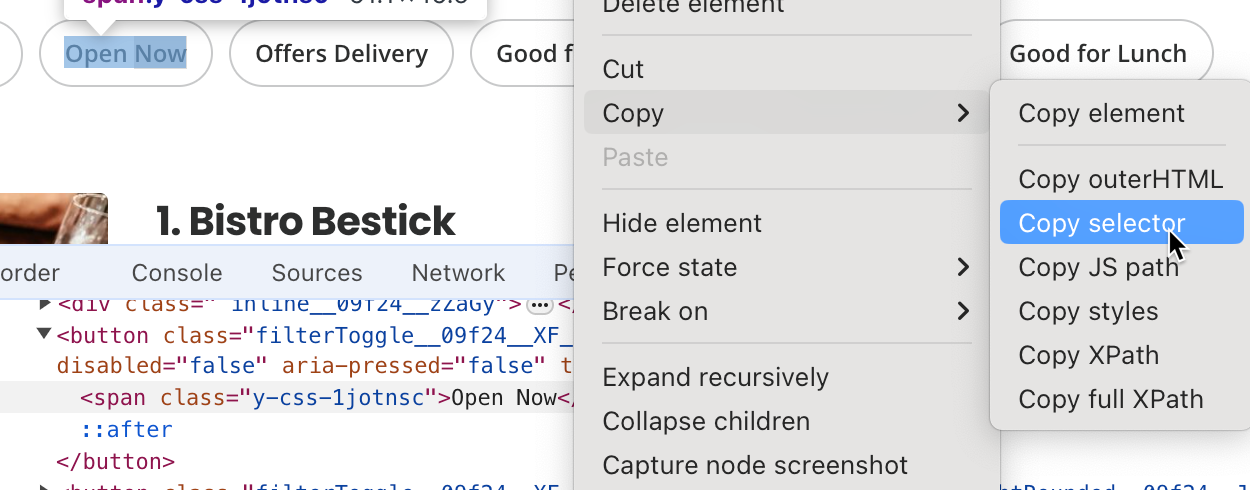
- Сохраните копию веб-страницы, чтобы ее можно было загрузить позже, вместе с подсказкой ChatGPT, чтобы помочь ChatGPT понять контекст запросов. В Chrome вы можете сделать это, нажав на три точки в правом верхнем углу, а затем выбрав «Сохранить и поделиться» > «Сохранить страницу как…»:
Затем, используя извлеченные ранее значения селектора, вам необходимо составить подробную подсказку, которая поможет ChatGPT создать скрипт парсинга:
Вы эксперт по веб-парсингу. Я хочу, чтобы вы выполнили парсинг https://www.yelp.com/ и извлекли определенную информацию. Перед парсингом выполните следующие действия:
- Очистите поле с помощью селектора
#search_location.- Введите «Stockholm» в поле поиска с помощью селектора
#search_location.- Нажмите кнопку с селектором
#header_find_form > div.y-css-1iy1dwt > button.- Подождите несколько секунд, пока страница загружает результаты поиска.
- Нажмите кнопку «Открыто сейчас» (Open Now)с селектором
#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span, чтобы отфильтровать компании, которые работают в текущий момент.- Создайте список с названиями компаний. Название компании имеет следующий селектор:
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a.- Создайте список с отзывами о компаниях. Отзывы содержат селектор:
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv.- Создайте файл Excel с названиями компаний и отзывами о них.
- Обязательно установите все соответствующие пакеты Python.
- Используйте WebDriver от Selenium для автоматизации процесса.
- Обратитесь к прилагаемой копии HTML-страницы результатов, чтобы получить представление о формате HTML.
После ввода этой информации ChatGPT предложит вам установить Selenium, фреймворк веб-автоматизации, поддерживающий WebDriver, и pandas:
pip3 install selenium pandas
ChatGPT также предоставляет вам код для парсинга вместе с пояснениями:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
import time
# Initialize the WebDriver
driver = webdriver.Chrome()
try:
# Open Yelp
driver.get('https://www.yelp.com/')
# Clear the location search box
location_box = driver.find_element(By.CSS_SELECTOR, '#search_location')
location_box.clear()
# Enter "Stockholm" in the location search box
location_box.send_keys('Stockholm')
# Click the search button
search_button = driver.find_element(By.CSS_SELECTOR, '#header_find_form > div.y-css-1iy1dwt > button')
search_button.click()
# Wait for search results to load
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#main-content'))
)
# Click on "Open Now" filter
open_now_button = driver.find_element(By.CSS_SELECTOR, '#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span')
open_now_button.click()
# Wait for the filter results to load
time.sleep(5)
# Extract business names and reviews
business_names = []
business_reviews = []
businesses = driver.find_elements(By.CSS_SELECTOR, '#main-content > ul > li')
for business in businesses:
try:
name = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a').text
review = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv').text
business_names.append(name)
business_reviews.append(review)
except Exception as e:
print(f"Error extracting data for a business: {e}")
# Create a DataFrame and save to Excel
df = pd.DataFrame({'Business Name': business_names, 'Reviews': business_reviews})
df.to_excel('stockholm_businesses.xlsx', index=False)
print("Data saved to stockholm_businesses.xlsx")
finally:
# Close the WebDriver
driver.quit()
Сохраните этот скрипт и запустите его с помощью Python в Visual Studio Code. Вы заметите, что код запускает Chrome, переходит на Yelp, очищает текстовое поле местоположения, вводит слово «Stockholm», нажимает кнопку поиска, фильтрует компании, которые работают в текущий момент, а затем закрывает страницу. После этого результат парсинга сохраняется в файле Excel stockholm_bussinsess.xlsx:

Весь исходный код этого руководства доступен на сайте GitHub.
Заключение
Из этого урока вы узнали, как использовать ChatGPT для извлечения определенной информации с веб-сайтов со статическим рендерингом HTML и более сложных веб-сайтов с динамической генерацией страниц, внешними ссылками JavaScript и взаимодействиями с пользователями.
Хотя выполнить парсинг такого веб-сайта, как Yelp, было просто, на самом деле веб-парсинг сложных HTML-структур может оказаться непростой задачей, и вы, скорее всего, столкнетесь с банами IP-адресов и капчами.
Чтобы упростить задачу, Bright Data предлагает широкий спектр услуг по сбору данных, включая продвинутые прокси-сервисы, помогающие обойти запреты на IP-адреса, Web Unlocker для обхода и устранения капч, API-интерфейсы для веб-парсинга, обеспечивающие автоматическое извлечение данных, и Scraping Browser для эффективного извлечения данных.
Зарегистрируйтесь сейчас и откройте для себя все продукты, которые предлагает Bright Data. Начните бесплатное опробование сегодня!


