

В этом учебном пособии вы узнаете:
- Как может работать помощник по поиску работы в LinkedIn на базе ИИ.
- Как создать его, интегрировав данные о вакансиях LinkedIn из Bright Data с рабочим процессом на базе OpenAI.
- Как улучшить и расширить этот рабочий процесс до надежного помощника по поиску работы.
Ознакомиться с итоговыми файлами проекта можно здесь.
Давайте погрузимся!
Объяснение рабочего процесса ИИ-помощника по поиску работы в LinkedIn
Прежде всего, вы не сможете создать ИИ-помощника по поиску работы в LinkedIn без доступа к данным объявлений о вакансиях в LinkedIn. Именно здесь в игру вступает Bright Data!
Благодаря LinkedIn Jobs Scraper вы можете получить данные о публичных объявлениях о вакансиях из LinkedIn с помощью веб-скреппинга. Вы получаете опыт, аналогичный поиску на портале LinkedIn Jobs. Но вместо веб-страницы вы получаете структурированные данные о вакансиях непосредственно в формате JSON или CSV.
Учитывая эти данные, вы можете попросить искусственный интеллект оценить каждую вакансию с учетом ваших навыков и желаемой должности, на которую вы претендуете. В общих чертах это то, что делает для вас ИИ-помощник LinkedIn Job.
Технические шаги
Для реализации ИИ-помощника по поиску работы в LinkedIn необходимо выполнить следующие шаги:
- Загрузка аргументов CLI: Разбор аргументов командной строки для получения параметров времени выполнения. Это обеспечивает гибкость выполнения и легкую настройку без изменения кода.
- Загрузите переменные окружения: Загрузите ключи OpenAI и Bright Data API из переменных окружения. Они необходимы для подключения к сторонним интеграциям, обеспечивающим работу этого AI.
- Загрузить файл конфигурации: Считывание конфигурационного файла JSON, содержащего параметры поиска работы, данные профиля кандидата и описание желаемой работы. Эта информация о конфигурации служит руководством для поиска вакансий и оценки ИИ.
- Соскоб вакансий из LinkedIn: Получение отфильтрованных в соответствии с конфигурацией объявлений о вакансиях из LinkedIn Jobs Scraper API.
- Оценка вакансий с помощью искусственного интеллекта: отправьте каждую партию объявлений о работе в OpenAI. ИИ оценивает их от
0до100на основе вашего профиля и желаемой работы. Он также добавляет короткий комментарий, объясняющий каждый балл, чтобы помочь вам понять качество соответствия. - Разверните вакансии с оценками и комментариями ИИ: ****Смешайте сгенерированные ИИ оценки и комментарии с исходными объявлениями о работе, обогатив каждую запись о работе этими новыми полями, сгенерированными ИИ.
- Экспортируйте данные о работе с оценками: Экспортируйте обогащенные данные о работе в CSV-файл для дальнейшего анализа и обработки.
- Печать совпадений с лучшими вакансиями: Отобразите лучшие вакансии прямо в консоли с основными деталями, обеспечивая немедленное понимание наиболее актуальных возможностей.
Посмотрите, как реализовать этот рабочий процесс с использованием ИИ на Python!
Как использовать OpenAI и Bright Data для создания рабочего процесса ИИ для поиска работы в LinkedIn
В этом руководстве вы узнаете, как построить рабочий процесс с использованием искусственного интеллекта, который поможет вам найти работу в LinkedIn. Данные о вакансиях в LinkedIn будут получены от Bright Data, а возможности искусственного интеллекта будут предоставлены OpenAI. Обратите внимание, что вы можете использовать и любой другой LLM.
К концу этого раздела у вас будет полный рабочий процесс ИИ на Python, который можно будет запускать из командной строки. Он будет определять лучшие вакансии в LinkedIn, экономя ваше время и силы на изнурительном и энергозатратном процессе поиска работы.
Давайте создадим ИИ-помощника для поиска работы в LinkedIn!
Предварительные условия
Чтобы следовать этому руководству, убедитесь, что у вас есть следующее:
- Локально установлен Python 3.8 или выше (мы рекомендуем использовать последнюю версию).
- Ключ API Bright Data.
- API-ключ OpenAI.
Если у вас еще нет ключа API Bright Data, создайте учетную запись Bright Data и следуйте официальному руководству по настройке. Аналогично, следуйте официальным инструкциям OpenAI, чтобы получить ключ OpenAI API.
Шаг № 0: Настройте ваш проект на Python
Откройте терминал и создайте новую директорию для вашего ИИ-ассистента по поиску работы в LinkedIn:
mkdir linkedin-job-hunting-ai-assistant/В папке linkedin-job-hunting-ai-assistant будет храниться весь код Python для вашего рабочего процесса ИИ.
Далее перейдите в каталог проекта и инициализируйте в нем виртуальное окружение:
cd linkedin-job-hunting-ai-assistant/
python -m venv venvТеперь откройте проект в вашей любимой Python IDE. Мы рекомендуем Visual Studio Code с расширением Python или PyCharm Community Edition.
Внутри папки проекта создайте новый файл с именем assistant.py. Ваша структура каталогов должна выглядеть следующим образом:
linkedin-job-hunting-ai-assistant/
├── venv/
└──── assistant.pyАктивируйте виртуальную среду в терминале. В Linux или macOS выполните команду:
source venv/bin/activateАналогично, в Windows запустите эту команду:
venv/Scripts/activateВ следующих шагах вам будет предложено установить необходимые пакеты Python. Если вы предпочитаете установить их все сейчас, в активированной виртуальной среде, выполните команду:
pip install python-dotenv requests openai pydanticВ частности, требуются следующие библиотеки:
python-dotenv: Загружает переменные окружения из файла.env, что упрощает безопасное управление ключами API.pydantic: Помогает проверять и разбирать конфигурационный файл на структурированные объекты Python.requests: Обрабатывает HTTP-запросы для вызова API, таких как Bright Data, и получения данных.openai: Предоставляет клиент OpenAI для взаимодействия с языковыми моделями OpenAI для оценки заданий ИИ.
Примечание: Мы устанавливаем библиотеку openai здесь, потому что этот учебник полагается на OpenAI в качестве поставщика языковых моделей. Если вы планируете использовать другого поставщика LLM, убедитесь, что установили соответствующий SDK или зависимости.
Все готово! Теперь ваша среда разработки Python готова к построению рабочего процесса ИИ с использованием OpenAI и Bright Data.
Шаг № 1: Загрузка аргументов CLI
ИИ-скрипт для поиска работы в LinkedIn требует несколько аргументов. Чтобы его можно было использовать повторно и настраивать без изменения кода, их следует получать через CLI.
Если говорить подробно, то вам понадобятся следующие аргументы CLI:
--config_file: Путь к JSON-файлу конфигурации, содержащему параметры поиска работы, данные профиля кандидата и желаемое описание работы. По умолчанию этоconfig.json.--batch_size: Количество заданий, которые нужно отправить в ИИ для оценки за один раз. По умолчанию –5.--jobs_number: Максимальное количество записей о заданиях, которые должен возвращать Bright Data LinkedIn Jobs Scraper. По умолчанию20.--output_csv: имя выходного CSV-файла, содержащего обогащенные данные о вакансиях с оценками ИИ и комментариями. По умолчанию –jobs_scored.csv.
Прочитайте эти аргументы из интерфейса командной строки с помощью следующей функции:
def parse_cli_args():
# Разбор аргументов командной строки для опций конфигурации и времени выполнения
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Путь к JSON-файлу конфигурации")
parser.add_argument("--jobs_number", type=int, default=20, help="Ограничить количество заданий, возвращаемых Bright Data Scraper API")
parser.add_argument("--batch_size", type=int, default=5, help="Количество заданий для оценки в каждой партии")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Имя выходного CSV-файла")
return parser.parse_args()Не забудьте импортировать argparse из стандартной библиотеки Python:
import argparseОтлично! Теперь у вас есть доступ к аргументам из CLI.
Шаг №2: Загрузка переменных окружения
Настройте свой скрипт на чтение секретов из переменных окружения. Чтобы упростить загрузку переменных окружения, используйте пакет python-dotenv. Активировав виртуальную среду, установите его, выполнив команду:
pip install python-dotenvДалее в файле assistant.py импортируйте библиотеку и вызовите load_dotenv() для загрузки переменных окружения:
from dotenv import load_dotenv
load_dotenv()Теперь ваш помощник может считывать переменные из локального файла .env. Итак, добавьте файл .env в корень каталога вашего проекта:
linkedin-job-hunting-ai-assistant/
├── venv/
├──── .env # <-----------
└──── assistant.pyОткройте файл .env и добавьте в него параметры OPENAI_API_KEY и BRIGHT_DATA_API_KEY:
OPENAI_API_KEY="<ВАШ_OPENAI_API_KEY>"
BRIGHT_DATA_API_KEY="<ВАШ_BRIGHT_DATA_API_KEY>"Замените место <YOUR_OPENAI_API_KEY> на ваш реальный ключ API OpenAI. Аналогично, замените место <YOUR_BRIGHT_DATA_API_KEY> на ваш ключ API Bright Data.
Затем добавьте эту функцию в свой скрипт, чтобы загрузить эти две переменные окружения:
def load_env_vars():
# Считываем необходимые API-ключи из окружения и проверяем их наличие
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
если missing:
raise EnvironmentError(
f "Отсутствуют необходимые переменные окружения: {', '.join(missing)}n"
"Пожалуйста, задайте их в вашем .env или окружении."
)
return openai_api_key, brightdata_api_keyДобавьте необходимый импорт из стандартной библиотеки Python:
import osЗамечательно! Теперь вы надежно загрузили сторонние секреты интеграции с помощью переменных окружения.
Шаг № 3: Загрузка файла конфигурации
Теперь вам нужен программный способ сообщить своему помощнику, какие вакансии вас интересуют. Чтобы результаты были точными, помощник также должен знать ваш опыт работы и то, какую работу вы ищете.
Чтобы избежать жесткого кодирования этой информации непосредственно в коде, имеет смысл считывать ее из конфигурационного файла JSON. В частности, этот файл должен содержать:
location: Географическое местоположение, в котором вы хотите искать работу. Это определяет основную область, в которой будут собраны объявления о вакансиях.ключевое слово: конкретные слова или фразы, связанные с названием вакансии или ролью, которую вы ищете, например “Python Developer”. Используйте кавычки, чтобы обеспечить точное совпадение.страна: Двухбуквенный код страны (например,USдля США,FRдля Франции), чтобы сузить поиск вакансий до конкретной страны.временной_диапазон: Временные рамки, в которые были размещены объявления о работе, для фильтрации недавних или актуальных вакансий (например,за последнюю неделю,за последний месяци т. д.).тип_работы: Тип занятости для фильтрации, напримерFull-time,Part-timeи т. д.experience_level (уровень опыта): Необходимый уровень профессионального опыта, напримерначальный уровень,младшийи т. д.удаленный: Фильтр вакансий по режиму работы (например,удаленный,на местеилигибридный).компания: Сосредоточить поиск на вакансиях определенной компании или работодателя.selective_search (выборочный поиск): Если включено, исключает объявления о вакансиях, названия которых не содержат указанных ключевых слов, чтобы получить более целенаправленные результаты.jobs_to_not_include: Список конкретных идентификаторов вакансий, которые следует исключить из результатов поиска, что полезно для удаления дубликатов или нежелательных объявлений.location_radius (радиус местоположения): Определяет, насколько далеко вокруг указанного местоположения должен распространяться поиск, включая близлежащие районы.profile_summary: краткое описание вашего профессионального профиля. Эта информация используется искусственным интеллектом для оценки соответствия каждой вакансии.Желаемая_работа_кратко: краткое описание типа работы, которую вы ищете, чтобы помочь искусственному интеллекту оценивать объявления о вакансиях на основе соответствия.
Эти поля в точности соответствуют аргументам, требуемым API Bright Data LinkedIn для поиска объявлений о работе “по ключевым словам” (который является частью решения LinkedIn Jobs Scraper):
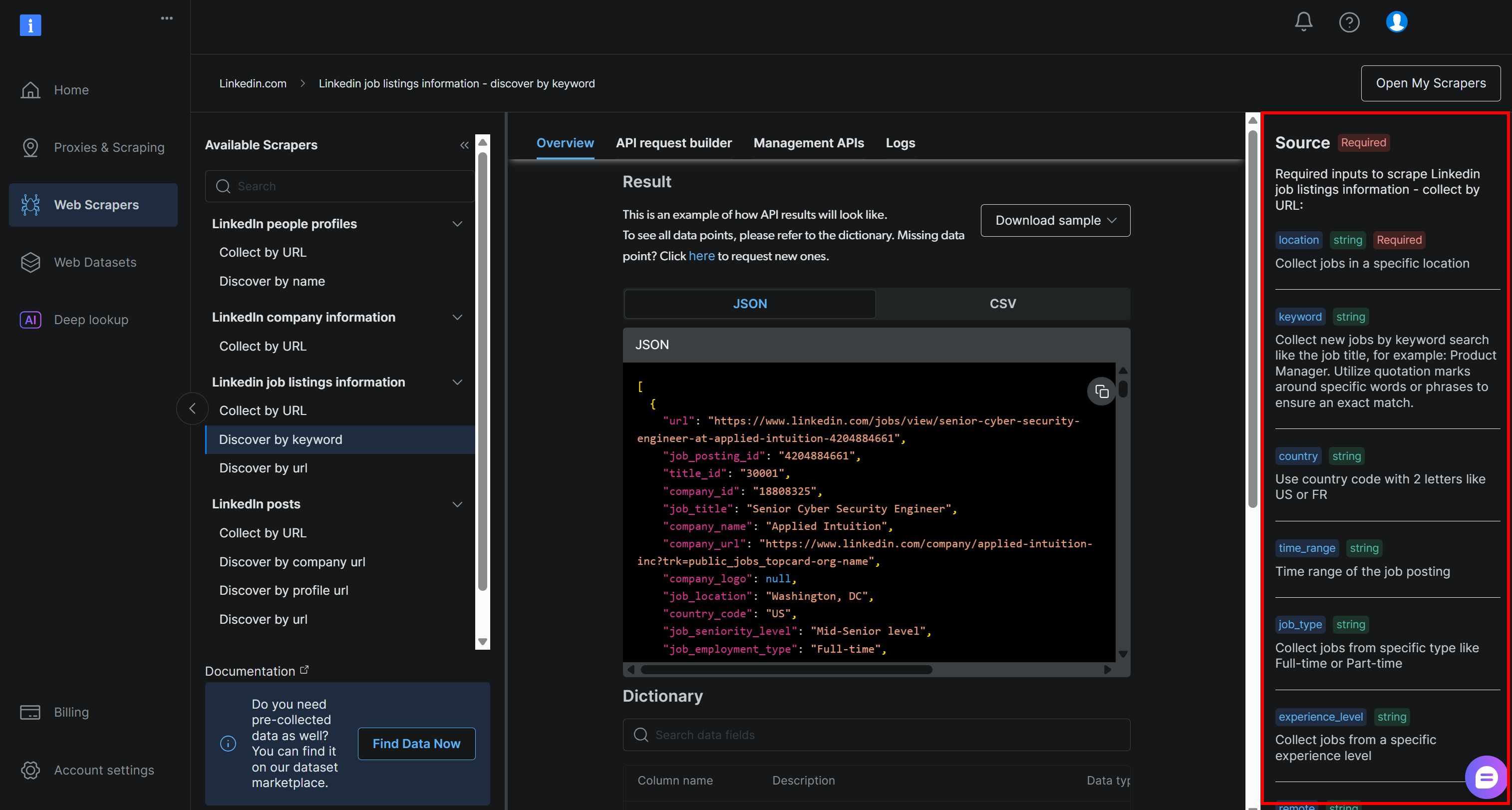
Более подробную информацию об этих полях и о том, какие значения они могут принимать, можно найти в официальной документации.
Последние два поля(profile_summary и desired_job_summary) описывают, кто вы в профессиональном плане и что вы ищете. Они будут переданы искусственному интеллекту для оценки каждого объявления о работе, возвращаемого Bright Data.
Чтобы было проще работать с конфигурационным файлом в коде, неплохо было бы сопоставить его с моделью Pydantic. Сначала установите Pydantic в ваше виртуальное окружение:
pip install pydanticЗатем определите модель Pydantic, отображающую JSON-конфигурационный файл, как показано ниже:
class JobSearchConfig(BaseModel):
location: str
ключевое слово: Optional[str] = None
страна: Optional[str] = None
временной_диапазон: Необязательно[str] = Нет
тип_работы: Необязательно[str] = Нет
опыт_уровень: Необязательно[str] = Нет
удаленный: Необязательно[str] = Нет
компания: Необязательно[str] = Нет
selective_search: Необязательно[bool] = Поле(по умолчанию=Ложь)
jobs_to_not_include: Optional[List[str]] = Field(default_factory=list)
location_radius: Optional[str] = None
# Дополнительные поля
profile_summary: str # Резюме профиля кандидата для AI-скоринга
desired_job_summary: str # Описание желаемой работы для AI-скорингаОбратите внимание, что только первое и два последних поля конфигурации являются обязательными.
Далее создайте функцию для чтения JSON-конфигураций из пути к файлу --config_file. Десериализуйте его в экземпляр JobSearchConfig:
def load_and_validate_config(filename: str) -> JobSearchConfig:
# Загрузить JSON файл конфигурации
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Конфигурационный файл '{filename}' не найден.")
try:
# Десериализуем входные JSON-данные в экземпляр JobSearchConfig
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f "Ошибка десериализации конфигурации:n{e}")
return configНа этот раз вам понадобятся эти импорты:
from pydantic import BaseModel, Field, ValidationError
из typing import Optional, List
импортировать jsonПотрясающе! Теперь ваш файл конфигурации правильно прочитан и десериализован, как и предполагалось.
Шаг № 4: Соскоб вакансий из LinkedIn
Пришло время использовать загруженную ранее конфигурацию для вызова Bright Data LinkedIn Jobs Scraper API.
Если вы не знакомы с тем, как работают API веб-скрапера Bright Data, стоит сначала ознакомиться с документацией.
Вкратце, API Web Scraper предоставляют конечные точки API, которые позволяют получать публичные данные с определенных доменов. За кулисами Bright Data инициализирует и запускает на своих серверах готовую задачу скрапинга. Эти API обеспечивают ротацию IP-адресов, CAPTCHA и другие меры для эффективного и этичного сбора публичных данных с веб-страниц. После завершения задачи собранные данные разбираются в структурированный формат и предоставляются вам в виде снимка.
Таким образом, общий рабочий процесс выглядит следующим образом:
- Запуск вызова API для начала задачи веб-скрапинга.
- Периодически проверяйте, готов ли снимок, содержащий отсканированные данные.
- Получение данных из снимка, как только он становится доступен.
Вы можете реализовать описанную выше логику с помощью всего нескольких строк кода:
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Запуск поиска вакансий в Bright Data LinkedIn
url = "https://api.brightdata.com/datasets/v3/trigger"
заголовки = {
"Authorization": f "Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Яркие данные "Информация о вакансиях в Linkedin - поиск по ключевым словам" ID набора данных
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Подготовьте полезную нагрузку для Bright Data API на основе пользовательской конфигурации
data = [{
"location": config.location,
"ключевое слово": config.keyword или "",
"страна": config.country или "",
"time_range": config.time_range или "",
"job_type": config.job_type или "",
"experience_level": config.experience_level или "",
"remote": config.remote или "",
"company": config.company или "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include или "",
"location_radius": config.location_radius или "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f "Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("Из триггера Bright Data не возвращается идентификатор snapshot_id.")
print(f "Поиск работы в LinkedIn сработал! Идентификатор моментального снимка: {snapshot_id}")
# Опрашиваем конечную точку моментального снимка до тех пор, пока данные не будут готовы или не произойдет таймаут
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "Bearer {brightdata_api_key}"}
print(f "Опрос снэпшота для ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# Снимок готов: возвращаем JSON-данные о вакансиях
print("Снимок готов")
return snap_resp.json()
elif snap_resp.status_code == 202:
# Снимок еще не готов: подождите и повторите попытку
print(f "Снимок еще не готов. Повторная попытка через {polling_timeout} секунд...")
time.sleep(polling_timeout)
else:
raise RuntimeError(f "Опрос моментального снимка не удался: {snap_resp.status_code} - {snap_resp.text}")Эта функция запускает скребок LinkedIn Jobs Scraper компании Bright Data, используя параметры поиска из файла конфигурации, гарантируя, что вы получите только те объявления, которые соответствуют вашим критериям. Затем она опрашивает, пока снимок данных не будет готов, и, как только он будет доступен, возвращает объявления в формате JSON. Обратите внимание, что аутентификация осуществляется с помощью ключа API Bright Data, загруженного ранее из переменных окружения.
Снимок, полученный с помощью LinkedIn Jobs Scraper, будет содержать списки вакансий в формате JSON, как показано ниже:
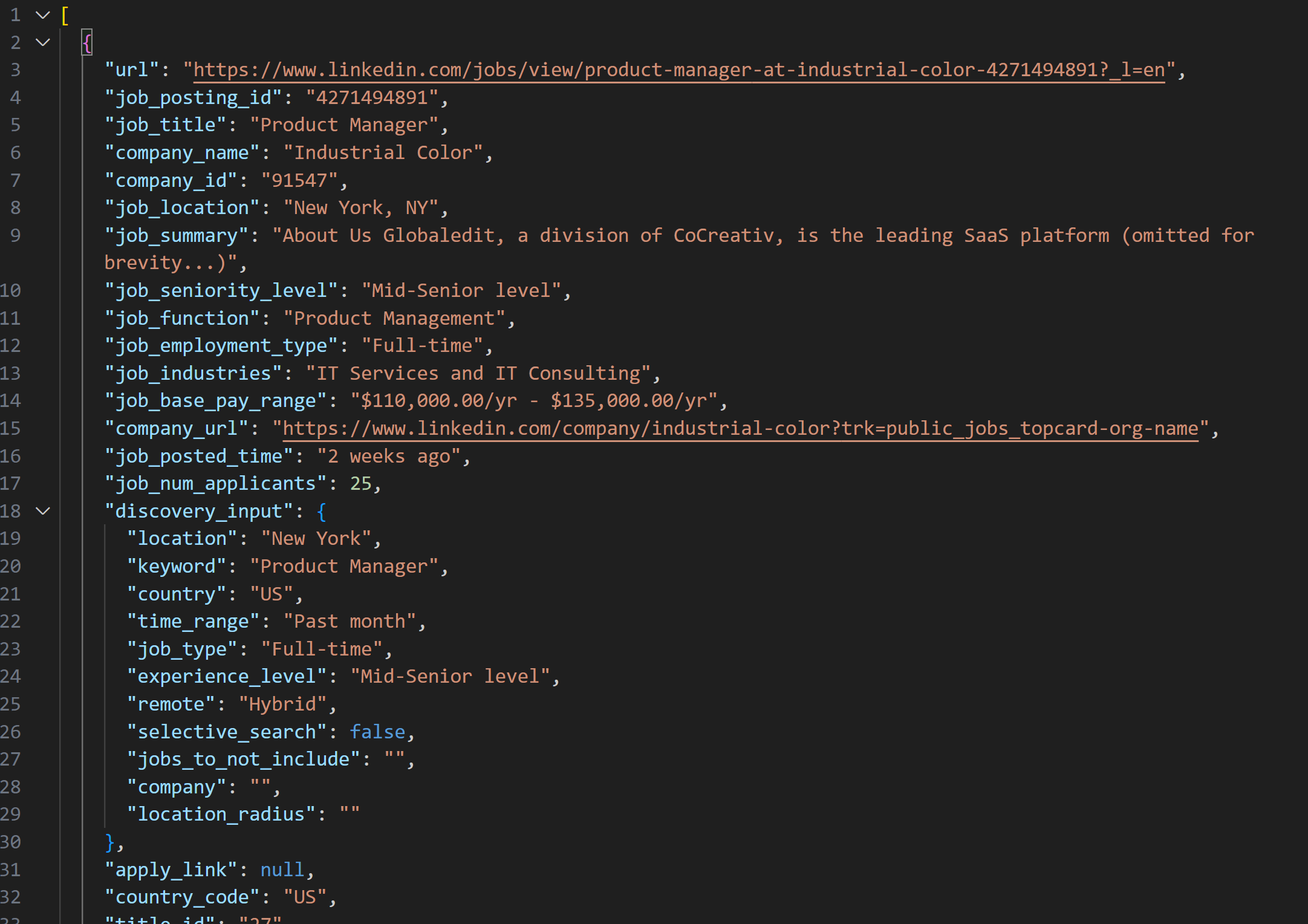
Примечание: созданный JSON-снимок содержит ровно до --jobs_number вакансий. В данном случае он содержит 20 вакансий.
Чтобы вышеописанная функция работала, необходимо установить requests:
pip install requestsПодробнее о том, как это работает, читайте в нашем продвинутом руководстве по Python HTTP Requests.
Далее не забудьте импортировать ее вместе с time из стандартной библиотеки Python:
import requests
import timeПотрясающе! Вы только что интегрировались с Bright Data, чтобы собрать свежие и конкретные данные о вакансиях в LinkedIn.
Шаг № 5: Оценка вакансий с помощью искусственного интеллекта
Теперь пришло время попросить ИИ (например, модели OpenAI) оценить каждую выскобленную вакансию.
Цель – присвоить оценку от 0 до 100 баллов вместе с коротким комментарием в зависимости от того, насколько соответствует вакансия:
- Вашему опыту работы
(profile_summary) - желаемой должности
(desired_job_summary).
Чтобы сократить количество обращений к API и ускорить работу, имеет смысл обрабатывать задания партиями. В частности, вы будете оценивать несколько --batch_size- заданий за раз.
Начните с установки пакета openai:
pip install openaiЗатем импортируйте OpenAI и инициализируйте клиент:
from openai import OpenAI
# ...
# Инициализация клиента OpenAI
client = OpenAI()Обратите внимание, что вам не нужно вручную передавать ключ API в конструктор OpenAI. Библиотека автоматически считывает его из переменной окружения OPENAI_API_KEY, которую вы уже задали.
Приступайте к созданию функции оценки заданий с помощью ИИ:
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Сконструировать подсказку для ИИ, чтобы он оценил совпадения вакансий на основе профиля кандидата
prompt = f"""
"Вы - эксперт по подбору персонала. Учитывая следующий профиль кандидата:n"
"{profile_summary}nn"
"Желаемое описание вакансии:n{desired_job_summary}nn"
"Оцените каждую вакансию от 0 до 100 баллов по тому, насколько она соответствует профилю и желаемой должности.n"
"Для каждой вакансии добавьте короткий комментарий (не более 50 слов), объясняющий оценку и качество соответствия.n"
"Возвращаем массив объектов с ключами 'job_posting_id', 'score' и 'comment'.nn"
"Jobs:n{json.dumps(jobs_batch)}n"
"""
сообщения = [
{ "role": "system", "content": "Вы полезный помощник по подбору заданий."}
{ "роль": "пользователь", "content": prompt}
]
# Используйте API OpenAI для разбора структурированного ответа в модель JobScoresResponse
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Возвращает список заданий, получивших оценки
return response.output_parsed.scoresЗдесь используется новая модель gpt-5-mini, чтобы OpenAI оценивал каждую выскобленную вакансию от 0 до 100 баллов вместе с коротким поясняющим комментарием.
Чтобы убедиться, что ответ всегда возвращается именно в том формате, который вам нужен, вызывается метод parse(). Этот метод применяет структурированную модель вывода, определенную здесь с помощью следующих моделей Pydantic:
class JobScore(BaseModel):
job_posting_id: str
оценка: int = Field(..., ge=0, le=100)
комментарий: str
class JobScoresResponse(BaseModel):
scores: List[JobScore].По сути, ИИ будет возвращать структурированные JSON-данные, как показано ниже:
{
"scores": [
{
"job_posting_id": "4271494891",
"score": 80,
"comment": "Сильный подход к SaaS-продуктам, сквозное владение, API и кросс-функциональная работа - соответствует вашему стартапу PM и опыту работы с клиентами. Роль рассчитана на 2-4 года, так что для ваших 7 лет она немного младше."
},
// опущено для краткости...
{
"job_posting_id": "4273328527",
"score": 65,
"comment": "Продуктовая роль с большим акцентом на данные/технику; agile и кросс-функциональные обязанности соответствуют, но предпочтителен опыт работы в количественной/технической области (финансы/статистическое моделирование), что может быть более слабым подходом."
}
]
}Метод parse() преобразует ответ в формате JSON в экземпляр JobScoresResponse. После этого вы сможете программно получить доступ к оценкам и комментариям в своем коде.
Примечание: Если вы предпочитаете использовать другой провайдер LLM, обязательно скорректируйте приведенный выше код для работы с выбранным вами провайдером.
Вот и все! Оценка заданий с помощью ИИ завершена.
Шаг № 6: Расширение заданий с помощью ИИ-акцентов и комментариев
Взгляните на необработанный JSON-вывод, возвращенный ИИ, показанный ранее. Вы можете увидеть, что каждая оценка работы содержит поле job_posting_id. Оно соответствует идентификатору, который LinkedIn использует для идентификации объявлений о работе.
Поскольку эти идентификаторы также присутствуют в данных моментального снимка, созданного скребком Bright Data LinkedIn Jobs Scraper, вы можете использовать их для:
- Найти оригинальные объекты объявлений о работе из массива отсканированных вакансий.
- Обогатить объект вакансии, добавив оценку и комментарий, сгенерированные искусственным интеллектом.
Этого можно добиться с помощью следующей функции:
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Где хранить обогащенные данные
extended_jobs = []
# Комбинируем исходные задания с оценками ИИ и комментариями
for score_obj in all_scores:
matched_job = None
для job в jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
if matched_job:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# Сортировка расширенных заданий по баллам ИИ (сначала самые высокие)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobsКак видите, для решения этой задачи достаточно пары циклов for. Перед тем как вернуть обогащенные данные, отсортируйте список в порядке убывания по ai_score. Таким образом, наиболее подходящие задания окажутся вверху – их будет легко и быстро обнаружить.
Круто! Теперь ваш ИИ-ассистент для поиска работы в LinkedIn практически готов к работе!
Шаг № 7: Экспорт данных о найденных вакансиях
Используйте встроенный в Python пакет csv, чтобы экспортировать собранные и обогащенные данные о вакансиях в CSV-файл.
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Динамически получаем имена полей из первого элемента массива
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Запись расширенных данных о заданиях с оценками AI в CSV
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
для job в extended_jobs:
writer.writerow(job)
print(f "Экспортировано {len(extended_jobs)} заданий в {output_csv}") Приведенная выше функция будет вызвана, если заменить output_csv на CLI-аргумент --output_csv.
Не забудьте импортировать csv:
import csvОтлично! Теперь ИИ-ассистент по поиску работы в LinkedIn экспортирует данные, обогащенные ИИ, в выходной CSV-файл.
Шаг № 8: Печать лучших совпадений с вакансиями
Чтобы получить немедленную обратную связь в терминале, не открывая выходной CSV-файл, напишите функцию для печати ключевых деталей из 3 лучших совпадений вакансий:
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** Top {top} job matches ***")
for job in extended_jobs[:3]:
print(f "URL: {job.get('url', 'N/A')}")
print(f "Название: {job.get('job_title', 'N/A')}")
print(f "AI Score: {job.get('ai_score')}")
print(f "AI Comment: {job.get('ai_comment', 'N/A')}")
print("-" * 40)Шаг № 9: Соберите все вместе
Объедините все функции из предыдущих шагов в основную логику помощника по поиску работы LinkedIn:
# Получение параметров времени выполнения из CLI
args = parse_cli_args()
try:
# Загрузить ключи API из среды
_, brightdata_api_key = load_env_vars()
# Загрузка файла конфигурации поиска заданий
config = load_and_validate_config(args.config_file)
# Получение заданий
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs found!")
except Exception as e:
print(f"[Error] {e}")
return
all_scores = []
# Обрабатываем задания партиями, чтобы не перегружать API и обрабатывать большие наборы данных
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f "Скоринг партии {i // args.batch_size + 1} с {len(batch)} заданиями...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # Чтобы избежать срабатывания ограничений скорости API
# Объединить баллы в отсканированные задания
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Сохранить результаты в CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Выведите верхние совпадения заданий с ключевой информацией для быстрого просмотра
print_top_jobs(extended_jobs)Невероятно! Осталось только просмотреть полный код помощника и убедиться, что он работает так, как ожидалось.
Шаг № 10: Полный код и первый запуск
Ваш финальный файл assistant.py должен содержать:
# pip install python-dotenv requests openai pydantic
import argparse
from dotenv import load_dotenv
импортировать os
from pydantic import BaseModel, Field, ValidationError
из typing import Optional, List
импортировать json
импорт запросов
импортировать время
from openai import OpenAI
импортировать csv
# Загрузите переменные окружения из файла .env
load_dotenv()
# Модели Pydantic, поддерживающие проект
class JobSearchConfig(BaseModel):
# Источник: https://docs.brightdata.com/api-reference/web-scraper-api/social-media-apis/linkedin#discover-by-keyword
расположение: str
ключевое слово: Optional[str] = None
страна: Необязательно[str] = Нет
временной_диапазон: Необязательно[str] = Нет
тип_работы: Необязательно[str] = Нет
опыт_уровень: Необязательно[str] = Нет
удаленный: Необязательно[str] = Нет
компания: Необязательно[str] = Нет
selective_search: Необязательно[bool] = Поле(по умолчанию=Ложь)
jobs_to_not_include: Optional[List[str]] = Field(default_factory=list)
location_radius: Optional[str] = None
# Дополнительные поля
profile_summary: str # Резюме профиля кандидата для AI-скоринга
desired_job_summary: str # Описание желаемой работы для AI-скоринга
class JobScore(BaseModel):
job_posting_id: str
score: int = Field(..., ge=0, le=100)
комментарий: str
class JobScoresResponse(BaseModel):
scores: List[JobScore]
def parse_cli_args():
# Разбор аргументов командной строки для конфигурации и опций времени выполнения
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Путь к JSON-файлу конфигурации")
parser.add_argument("--jobs_number", type=int, default=20, help="Ограничить количество заданий, возвращаемых Bright Data Scraper API")
parser.add_argument("--batch_size", type=int, default=5, help="Количество заданий для оценки в каждой партии")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Имя выходного CSV-файла")
return parser.parse_args()
def load_env_vars():
# Считываем необходимые API-ключи из окружения и проверяем их наличие
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
если missing:
raise EnvironmentError(
f "Отсутствуют необходимые переменные окружения: {', '.join(missing)}n"
"Пожалуйста, задайте их в вашем .env или окружении."
)
return openai_api_key, brightdata_api_key
def load_and_validate_config(filename: str) -> JobSearchConfig:
# Загрузка JSON-файла конфигурации
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Конфигурационный файл '{filename}' не найден.")
try:
# Дериелизация входных JSON-данных в экземпляр JobSearchConfig
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f "Ошибка десериализации конфигурации:n{e}")
return config
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Запуск поиска вакансий в Bright Data LinkedIn
url = "https://api.brightdata.com/datasets/v3/trigger"
заголовки = {
"Authorization": f "Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Яркие данные "Информация о вакансиях в Linkedin - поиск по ключевым словам" ID набора данных
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Подготовьте полезную нагрузку для Bright Data API на основе пользовательской конфигурации
data = [{
"location": config.location,
"ключевое слово": config.keyword или "",
"страна": config.country или "",
"time_range": config.time_range или "",
"job_type": config.job_type или "",
"experience_level": config.experience_level или "",
"remote": config.remote или "",
"company": config.company или "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include или "",
"location_radius": config.location_radius или "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f "Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("Из триггера Bright Data не возвращается идентификатор snapshot_id.")
print(f "Поиск работы в LinkedIn сработал! Идентификатор моментального снимка: {snapshot_id}")
# Опрашиваем конечную точку моментального снимка до тех пор, пока данные не будут готовы или не произойдет таймаут
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "Bearer {brightdata_api_key}"}
print(f "Опрос снэпшота для ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# Снимок готов: возвращаем JSON-данные о вакансиях
print("Снимок готов")
return snap_resp.json()
elif snap_resp.status_code == 202:
# Снимок еще не готов: подождите и повторите попытку
print(f "Снимок еще не готов. Повторная попытка через {polling_timeout} секунд...")
time.sleep(polling_timeout)
else:
raise RuntimeError(f "Опрос моментального снимка не удался: {snap_resp.status_code} - {snap_resp.text}")
# Инициализация клиента OpenAI
client = OpenAI()
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Сконструировать подсказку для ИИ, чтобы он оценил соответствие вакансий на основе профиля кандидата
prompt = f"""
"Вы - эксперт по подбору персонала. Учитывая следующий профиль кандидата:n"
"{profile_summary}nn"
"Желаемое описание вакансии:n{desired_job_summary}nn"
"Оцените каждую вакансию от 0 до 100 баллов по тому, насколько она соответствует профилю и желаемой должности.n"
"Для каждой вакансии добавьте короткий комментарий (не более 50 слов), объясняющий оценку и качество соответствия.n"
"Возвращаем массив объектов с ключами 'job_posting_id', 'score' и 'comment'.nn"
"Jobs:n{json.dumps(jobs_batch)}n"
"""
сообщения = [
{ "role": "system", "content": "Вы полезный помощник по подбору заданий."}
{ "роль": "пользователь", "content": prompt}
]
# Используйте API OpenAI для разбора структурированного ответа в модель JobScoresResponse
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Возвращает список заданий, получивших оценки
return response.output_parsed.scores
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Где хранить обогащенные данные
extended_jobs = []
# Комбинируем исходные задания с оценками ИИ и комментариями
for score_obj in all_scores:
matched_job = None
для job в jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
if matched_job:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# Сортировка расширенных заданий по баллам ИИ (сначала самые высокие)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobs
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Динамически получаем имена полей из первого элемента массива
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Запись расширенных данных о заданиях с оценками AI в CSV
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
для job в extended_jobs:
writer.writerow(job)
print(f "Экспортировано {len(extended_jobs)} заданий в {output_csv}")
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** Топ {топ} совпадений заданий ***")
for job in extended_jobs[:3]:
print(f "URL: {job.get('url', 'N/A')}")
print(f "Название: {job.get('job_title', 'N/A')}")
print(f "AI Score: {job.get('ai_score')}")
print(f "AI Comment: {job.get('ai_comment', 'N/A')}")
print("-" * 40)
def main():
# Получение параметров времени выполнения из CLI
args = parse_cli_args()
try:
# Загрузите ключи API из окружения
_, brightdata_api_key = load_env_vars()
# Загрузка файла конфигурации поиска заданий
config = load_and_validate_config(args.config_file)
# Получение заданий
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs found!")
except Exception as e:
print(f"[Error] {e}")
return
all_scores = []
# Обрабатываем задания партиями, чтобы не перегружать API и обрабатывать большие наборы данных
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f "Скоринг партии {i // args.batch_size + 1} с {len(batch)} заданиями...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # Чтобы избежать срабатывания ограничений скорости API
# Объединить баллы в отсканированные задания
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Сохранить результаты в CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Выведите верхние совпадения заданий с ключевой информацией для быстрого просмотра
print_top_jobs(extended_jobs)
if __name__ == "__main__":
main()Предположим, вы менеджер по продуктам с 7-летним опытом работы, который ищет гибридную вакансию в Нью-Йорке. Настройте свой файл config.json следующим образом:
{
"location": "New York",
"keyword": "Product Manager",
"country": "США",
"time_range": "Последний месяц",
"job_type": "Полная занятость",
"experience_level": "Средний-старший уровень",
"remote": "Гибридный",
"profile_summary": "Опытный менеджер по продукту с 7 годами работы в технологических стартапах, специализирующийся на agile-методологиях и кросс-функциональном руководстве командой.",
"desired_job_summary": "Ищу должность менеджера по продукту на полный рабочий день с упором на SaaS-продукты и разработку, ориентированную на клиента."
}Затем вы можете запустить помощника по поиску работы в LinkedIn с помощью:
python assistant.pyНеобязательно: Для индивидуального запуска напишите что-то вроде:
python assistant.py --config_file=config.json --batch_size=10 --jobs_number=40 --output_csv=results.csvЭта команда запускает ассистент, используя указанный вами файл config.json. Он обрабатывает задания партиями по 10, извлекает до 40 объявлений о вакансиях из Bright Data и сохраняет обогащенные результаты с оценками AI и комментариями в файл results.csv.
Теперь, если вы запустите помощника с аргументами CLI по умолчанию, в терминале вы увидите примерно следующее:
Поиск работы в LinkedIn запущен! ID моментального снимка: s_me6x0s3qldm9zz0wv
Опрос моментального снимка для идентификатора: s_me6x0s3qldm9zz0wv
Снапшот еще не готов. Повторная попытка через 10 секунд...
# Опущено для краткости...
Снимок еще не готов. Повторная попытка через 10 секунд...
Снимок готов
Найдено 20 заданий!
Партия 1 с 5 заданиями...
Партия 2 с 5 заданиями...
Партия 3 с 5 заданиями...
Партия 4 с 5 заданиями...
Экспортировано 20 заданий в файл jobs.csvТогда вывод с 3 лучшими совпадениями заданий будет выглядеть примерно так:
*** Топ-3 совпадения заданий ***
URL: https://www.linkedin.com/jobs/view/product-manager-growth-at-yext-4267903356?_l=en
Название: Менеджер по продуктам, рост
Оценка ИИ: 92
Комментарий AI: Отличная кандидатура: SaaS-ориентированный менеджер по развитию с целями, ориентированными на клиента, продуктовым ростом, экспериментами и межфункциональным сотрудничеством - прямое соответствие опыту кандидата и желаемой роли.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-industrial-color-4271494891?_l=en
Название: Менеджер по продукту
Оценка AI: 90
Комментарий AI: Сильное соответствие: SaaS-продукт, API/интеграции, agile и кросс-функциональное лидерство. Единственное небольшое несоответствие - указанные 2-4 года (у вас 7), что, вероятно, делает вас слишком квалифицированным, но очень применимым.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-resourceful-talent-group-4277945862?_l=en
Название: Менеджер по продукту
Оценка AI: 88
Комментарий AI: Очень похожая роль в SaaS/интеграции с agile-практиками и итерациями, ориентированными на клиента. Рекрутер указал срок 2-4 года, но ваш 7-летний опыт работы в стартапе в качестве руководителя и кросс-функциональное лидерство вполне подходят.
----------------------------------------Откройте созданный файл jobs_scored.csv. В основных колонках вы увидите:
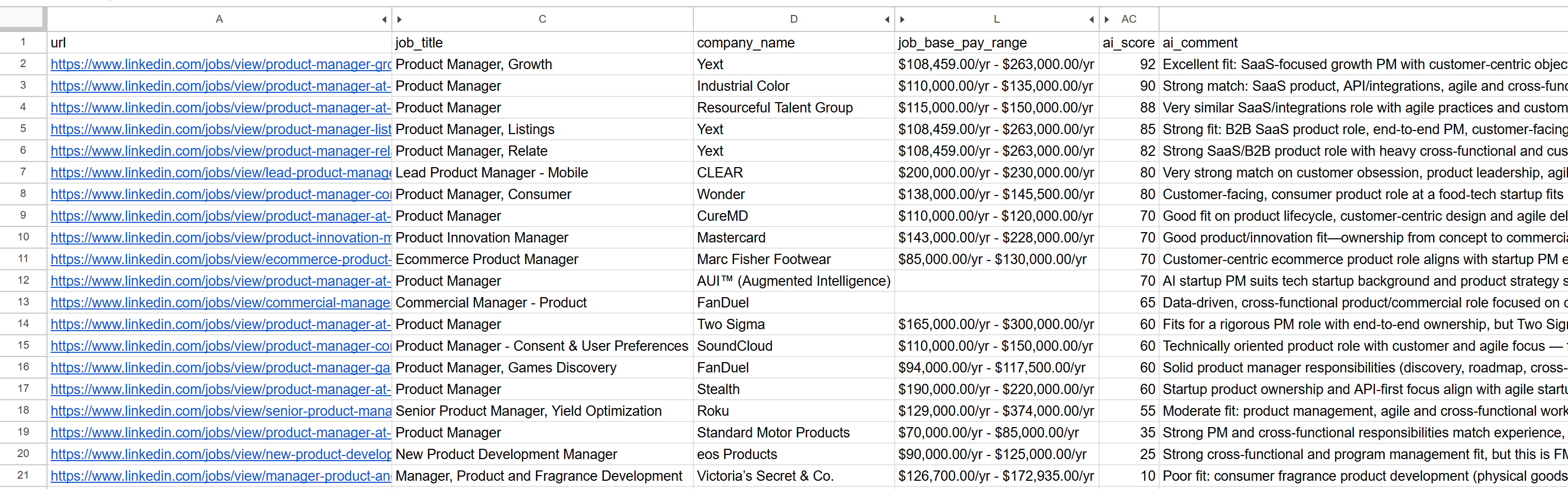
Обратите внимание, как каждая работа была оценена и прокомментирована искусственным интеллектом. Это поможет вам сосредоточиться только на тех работах, где у вас есть реальные шансы на успех!
И вуаля! Благодаря этому рабочему процессу поиска работы в LinkedIn, основанному на искусственном интеллекте, найти следующую работу еще никогда не было так просто.
Следующие шаги
Созданный здесь помощник по поиску работы в LinkedIn работает как чат, но есть несколько усовершенствований, которые стоит изучить:
- Избегайте повторной оценки одних и тех же вакансий: Чтобы оценивать разные вакансии при каждом запуске скрипта, задайте массив
jobs_to_not_includeв файлеconfig.json. Он должен содержатьидентификаторы job_posting_ids заданий, которые помощник уже проанализировал. Например, чтобы исключить текущие отсканированные задания, ваш конфиг может выглядеть следующим образом:
{
"location": "Нью-Йорк",
"keyword": "Product Manager",
"country": "США",
"time_range": "Последний месяц",
"job_type": "Полная занятость",
"experience_level": "Средний-старший уровень",
"remote": "Гибридный",
"jobs_to_not_include": ["4267903356", "4271494891", "4277945862", "4267906118", "4255405781", "4267537560", "4245709356", "4265355147", "4277751182", "4256914967", "4281336197", "4232207277", "4273328527", "4277435772", "4253823512", "4279286518", "4224506933", "4250788498", "4256023955", "4252894407"], // <--- ПРИМЕЧАНИЕ: ID вакансий, которые необходимо исключить.
"profile_summary": "Опытный менеджер по продукту с 7 годами работы в технологических стартапах, специализирующийся на agile-методологиях и кросс-функциональном руководстве командой.",
"desired_job_summary": "Ищу должность менеджера по продукту на полный рабочий день с упором на SaaS-продукты и разработку, ориентированную на клиента."
}- Автоматизируйте периодические запуски скриптов: Запланируйте регулярный запуск скрипта (например, ежедневный) с помощью таких инструментов, как Cron. В этом случае не забудьте задать правильный аргумент
time_range(например, “Past 24 hours”) и обновить списокjobs_to_not_include, чтобы исключить задания, которые вы уже оценивали. Это поможет вам сосредоточиться на свежих объявлениях. - Используйте специальную модель судьи ИИ: Вместо общей модели GPT-5 рассмотрите возможность использования специализированной модели искусственного интеллекта, точно настроенной на подбор и оценку вакансий. Это простое изменение может значительно повысить точность и релевантность оценок вакансий.
Заключение
В этой статье вы узнали, как использовать возможности поиска вакансий в LinkedIn от Bright Data для создания помощника по поиску работы на базе ИИ.
Созданный здесь рабочий процесс с искусственным интеллектом идеально подходит для тех, кто ищет новую работу и хочет максимально увеличить свои шансы, сосредоточившись только на лучших возможностях. Он поможет вам сэкономить время и силы, подавая заявки на вакансии, которые действительно соответствуют их карьерным целям и имеют более высокие шансы быть принятыми на работу.
Чтобы построить более сложные рабочие процессы, изучите весь спектр решений для получения, проверки и преобразования живых веб-данных в инфраструктуре Bright Data AI.
Создайте бесплатную учетную запись Bright Data и начните экспериментировать с нашими инструментами для работы с данными, готовыми к искусственному интеллекту!
Вопросы и ответы
В приведенном выше примере в качестве источника данных используется LinkedIn, но вы можете легко расширить сценарий для работы с Indeed или любыми другими источниками объявлений о вакансиях, доступными через Bright Data. Для получения более подробной информации об интеграции с Indeed обратитесь к статье Indeed Jobs Scraper.
Этот рабочий процесс с использованием искусственного интеллекта опирается на OpenAI благодаря его широкому распространению и популярности. Однако вы можете легко адаптировать этот рабочий процесс для работы с другими LLM-провайдерами, такими как Gemini, Anthropic, Cohere, или любой другой доступной по API большой языковой моделью.
Данные, возвращаемые скребком LinkedIn Jobs Scraper, настолько качественны и хорошо структурированы, что вы можете обрабатывать их для скоринга, используя LLM напрямую. Поэтому вам не обязательно нужна сложность автономного агента с возможностью рассуждать и принимать решения.
Тем не менее, если вы хотите создать более продвинутый ИИ-агент для поиска работы в LinkedIn, вы можете рассмотреть следующую мультиагентную архитектуру:
Агент для поиска работы: ИИ-агент, интегрированный в инфраструктуру Bright Data (с помощью инструментария или MCP), который вызывает API LinkedIn Jobs Scraper, чтобы постоянно получать и обновлять объявления о вакансиях.
Агент, оценивающий вакансии: Агент, специализирующийся на оценке и подсчете баллов вакансий на основе профиля и предпочтений кандидата с помощью LLM.
Агент-оркестрант: Агент верхнего уровня, который координирует работу двух других агентов, многократно запуская циклы поиска и оценки данных до тех пор, пока не будет получено желаемое количество релевантных объявлений с высоким баллом.
Вы даже можете запрограммировать агента, чтобы он автоматически подавал заявки на эти вакансии за вас. Если вы собираетесь создать подобную систему поиска работы в LinkedIn, мы рекомендуем использовать мультиагентную платформу, например CrewAI.




