

Для создания специализированных моделей, понимающих вашу область, часто требуется нечто большее, чем оперативное проектирование или генерация с расширенным поиском (RAG). Общедоступные модели мощны, но им не хватает новейших знаний или специфического вкуса, необходимого для вашего случая использования. Поскольку у нас есть веб-данные, начиная от статей, документации, списков товаров и заканчивая транскриптами видео, этот пробел можно устранить с помощью тонкой настройки.
В этой статье вы узнаете:
- Как собирать и подготавливать специфические для домена веб-данные с помощью скреперов и наборов данных Bright Data.
- Как точно настроить модель GPT с открытым исходным кодом на основе собранных данных.
- Как оценить и развернуть вашу доработанную модель для решения реальных задач.
Давайте погрузимся!
Что такое тонкая настройка
Простыми словами, тонкая настройка – это процесс, когда модель, уже прошедшая предварительное обучение на большом общем наборе данных, адаптируется для успешной работы на новом, часто более специфическом наборе данных или задаче. Когда вы проводите тонкую настройку, вы изменяете веса модели, а не создаете ее с нуля. Изменение весов – это то, что заставляет модель вести себя по-другому или так, как вы хотите.
Веб-данные полезны для тонкой настройки, потому что они дают вам:
- Свежесть: Они постоянно обновляются, чтобы отражать последние тенденции, события и технологии.
- Разнообразие: Доступ к различным стилям написания, источникам, мыслям, что уменьшает предвзятость узких наборов данных.
Процесс тонкой настройки работает так, как показано здесь:
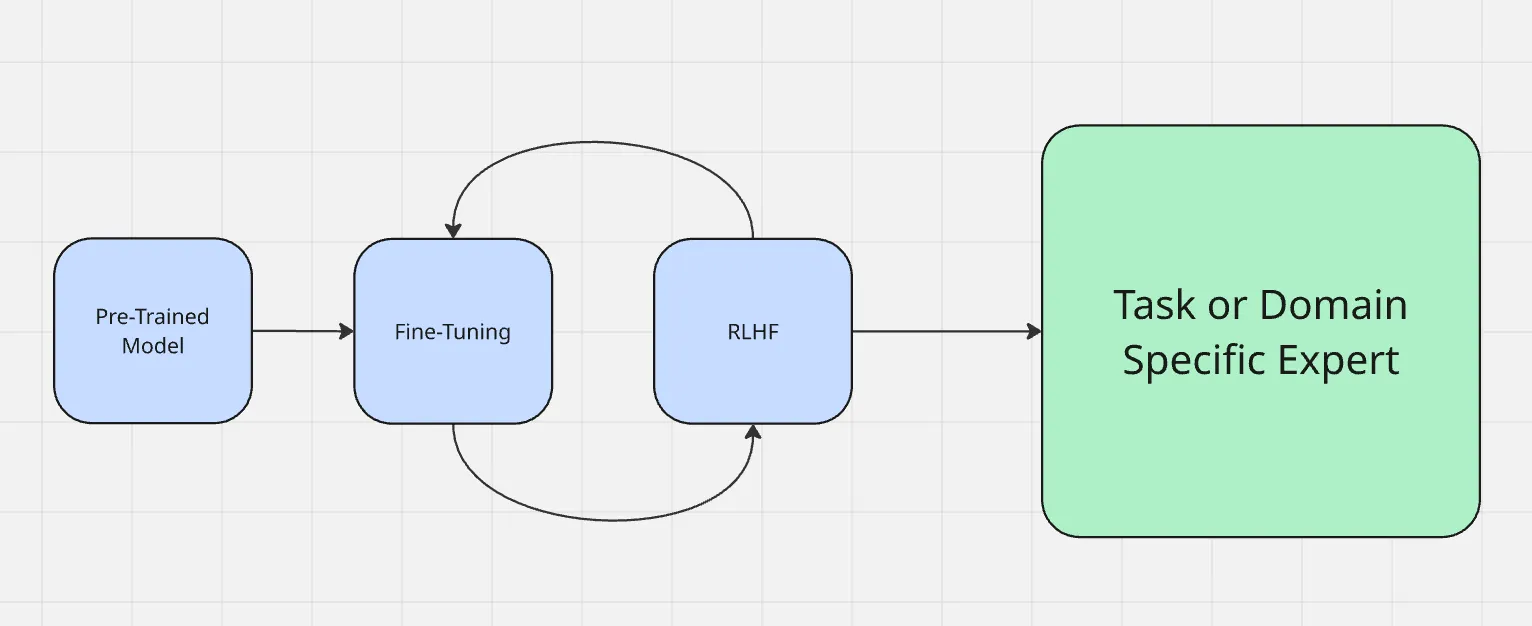
Тонкая настройка отличается от других широко используемых методов адаптации, таких как проектирование подсказок и генерация с расширением поиска. Инженерия подсказок изменяет то, как вы задаете вопросы модели, но не меняет саму модель. RAG добавляет внешний источник знаний во время выполнения, как бы давая контекст чего-то нового. Тонкая настройка, с другой стороны, обновляет непосредственно параметры модели, что делает ее более надежной для получения точных результатов в домене без дополнительного контекста каждый раз.
В отличие от генерации с расширением поиска (RAG), которая обогащает модель внешним контекстом во время выполнения, тонкая настройка адаптирует саму модель. Если вы хотите глубже разобраться в компромиссах, посмотрите статью RAG vs Fine-Tuning.
Почему стоит использовать веб-данные для тонкой настройки
Веб-данные представлены в самых разных форматах (статьи, объявления о товарах, сообщения на форумах, транскрипты видео и даже текст, полученный из видео), что дает преимущество, с которым не могут сравниться ни статические, ни синтетические наборы данных. Такое разнообразие помогает модели эффективнее обрабатывать различные типы входных данных.
Приведем несколько примеров различных контекстов, в которых веб-данные могут проявить себя с лучшей стороны:
- Данные социальных сетей: Токены с социальных платформ помогают моделям понимать неформальную лексику, сленг и тенденции реального времени, что очень важно для таких приложений, как анализ настроений или чат-боты.
- Структурированные наборы данных: Токены из структурированных источников, таких как каталоги товаров или финансовые отчеты, позволяют получить точное понимание специфики области, что очень важно для рекомендательных систем или финансовых прогнозов.
- Нишевый контекст: Стартапы и специализированные приложения выигрывают от токенов, полученных из релевантных наборов данных, адаптированных к их сценариям использования, таких как юридические документы для юридических технологий или медицинские журналы для медицинского ИИ.
Веб-данные вносят естественное разнообразие и контекст, повышая реалистичность и устойчивость точно настроенной модели.
Стратегии сбора данных
Крупномасштабные скреперы и поставщики наборов данных, такие как Bright Data, позволяют быстро и надежно собирать огромные объемы веб-контента. Это позволяет создавать наборы данных, специфичные для конкретного домена, не тратя месяцы на ручной сбор.
Bright Data создала самую диверсифицированную и надежную в отрасли инфраструктуру сбора веб-данных, состоящую из нескольких различных сетевых точек и источников. При этом веб-данные не ограничиваются простым текстом. Bright data может собирать мультимодальные данные, такие как метаданные, атрибуты продуктов и видео-транскрипты, которые помогают модели узнать более богатый контекст.
Следует избегать сбора данных с помощью необработанных фрагментов, поскольку они почти всегда содержат шум, нерелевантный контент или артефакты форматирования. Фильтрация, удаление дубликатов и структурированная очистка – важные шаги, которые помогут обеспечить повышение производительности обучающего набора данных, а не внести в него путаницу.
Подготовка веб-данных к тонкой настройке
- Преобразование необработанных данных в структурированные пары вход/выход. Необработанные данные редко бывают готовы к обучению в готовом виде. Первый шаг заключается в преобразовании данных в структурированные пары вход/выход. Например, документация о тонкой настройке может быть отформатирована в запрос типа “Что такое тонкая настройка?” с исходным ответом в качестве целевого вывода. Такая структура обеспечивает обучение модели на четко определенных примерах, а не на неорганизованном тексте.
- Работа с различными форматами: JSON, CSV, транскрипты, веб-страницы. Веб-данные обычно поступают в различных форматах, таких как JSON из API, CSV, необработанный HTML или транскрипты из видео. Стандартизация веб-данных в единый формат, например JSONL, упрощает управление ими и их использование в обучающих конвейерах.
- Упаковка наборов данных для эффективного обучения. Для улучшения результатов и процесса обучения наборы данных часто “упорядочиваются”, то есть несколько коротких примеров объединяются в одну последовательность, чтобы сократить количество потраченных впустую лексем и оптимизировать использование памяти GPU при тонкой настройке.
- Баланс между специфическими и общими веб-данными. Поиск баланса имеет большое значение. Избыток данных по одному домену может сделать модель узкой и неглубокой, в то время как слишком большое количество общих данных может привести к размыванию специализированных знаний. Лучшие результаты обычно достигаются за счет сочетания сильной базы общих веб-данных с примерами, относящимися к конкретной области.
Выбор базовой модели
Выбор правильной базовой модели напрямую влияет на то, насколько хорошо будет работать ваша система, прошедшая тонкую настройку. Универсального решения не существует, особенно учитывая разнообразие предложений в каждом семействе моделей. В зависимости от типа данных, желаемых результатов и бюджета одна модель может подходить вам больше, чем другая.
Чтобы выбрать подходящую модель для начала работы, следуйте этому контрольному списку:
- Какая модальность или модальности потребуются вашей модели?
- Насколько велики ваши входные и выходные данные?
- Насколько сложны задачи, которые вы пытаетесь решить?
- Насколько важна производительность по сравнению с бюджетом?
- Насколько важна безопасность ИИ-ассистента для вашего сценария использования?
- Есть ли у вашей компании существующие договоренности с Azure или GCP?
Например, если вы имеете дело с очень длинными видео или текстами (часами и сотнями тысяч слов), оптимальным выбором может стать Gemini 1.5 pro, обеспечивающая контекстное окно до 1 млн лексем.
Несколько моделей с открытым исходным кодом являются сильными кандидатами для тонкой настройки веб-данных, включая модели Gemma 3, Llama 3.1, Mistral 7B или Falcon. Меньшие версии практичны для большинства проектов по тонкой настройке, в то время как более крупные модели подходят, когда требуется высокий охват и точность. Вы также можете ознакомиться с этим руководством по адаптации Gemma 3 для тонкой настройки.
Тонкая настройка с помощью ярких данных
Чтобы продемонстрировать, как веб-данные способствуют тонкой настройке, давайте рассмотрим пример с использованием Bright Data в качестве источника. В этом примере мы используем API Scraper компании Bright Data для сбора информации о товарах с Amazon и последующей точной настройки модели Llama 4 на Hugging Face.
Шаг № 1: Сбор набора данных
Используя API веб-скребка Bright Data, вы можете получить структурированные данные о товарах (название, продукты, описания, отзывы и т. д.) с помощью всего нескольких строк Python.
Цель этого шага – создать небольшой проект, который:
- активирует виртуальную среду Python
- Вызывает API веб-скребка Bright Data
- Сохраняет результаты в amazon-data.json
Необходимые условия
- Python 3.10+
- API-токен Bright Data
- Идентификатор коллектора Bright Data (из приборной панели Bright Data) /cp/scrapers
- OPENAI_API_KEY, поскольку мы будем настраивать модель GPT-4.
Создайте папку проекта
mkdir web-scraper u0026u0026 cd web-scrapper
Создайте и активируйте виртуальную среду
Активируйте виртуальную среду, и вы должны увидеть (venv) в начале приглашения командной строки.
//macOS/Linux (bash or zsh):npython3 -m venv venvnsource venv/bin/activatennWindowsnpython -m venv venvn.venvScriptsActivate.ps1
Установите зависимости
Это библиотека для выполнения веб-запросов HTTP.
pip install requests
После этого вы будете готовы получить интересующие вас данные с помощью API скрепера от Bright Data.
Определите логику скрапинга
Следующий фрагмент запустит коллектор Bright Data (например, продукты Amazon), опросит его до завершения скрапинга и сохранит результаты в локальный JSON-файл.
Замените свой api ключ в строке api ключа здесь
import requestsnimport jsonnimport timenndef trigger_amazon_products_scraping(api_key, urls):n url = u0022https://api.brightdata.com/datasets/v3/triggeru0022nn params = {n u0022dataset_idu0022: u0022gd_l7q7dkf244hwjntr0u0022,n u0022include_errorsu0022: u0022trueu0022,n u0022typeu0022: u0022discover_newu0022,n u0022discover_byu0022: u0022best_sellers_urlu0022,n }n data = [{u0022category_urlu0022: url} for url in urls]nn headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022,n u0022Content-Typeu0022: u0022application/jsonu0022,n }nn response = requests.post(url, headers=headers, params=params, json=data)nn if response.status_code == 200:n snapshot_id = response.json()[u0022snapshot_idu0022]n print(fu0022Request successful! Response: {snapshot_id}u0022)n return response.json()[u0022snapshot_idu0022]n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)nndef poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):n snapshot_url = fu0022https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=jsonu0022n headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022n }nn print(fu0022Polling snapshot for ID: {snapshot_id}...u0022)nn while True:n response = requests.get(snapshot_url, headers=headers)nn if response.status_code == 200:n print(u0022Snapshot is ready. Downloading...u0022)n snapshot_data = response.json()nn with open(output_file, u0022wu0022, encoding=u0022utf-8u0022) as file:n json.dump(snapshot_data, file, indent=4)nn print(fu0022Snapshot saved to {output_file}u0022)n returnn elif response.status_code == 202:n print(Fu0022Snapshot is not ready yet. Retrying in {polling_timeout} seconds...u0022)n time.sleep(polling_timeout)n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)n breaknnif __name__ == u0022__main__u0022:n BRIGHT_DATA_API_KEY = u0022your_api_keyu0022n urls = [n u0022https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-productsu0022n ]n snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)n poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, u0022amazon-data.jsonu0022)
Запустите код
python3 web_scraper.py
Вы должны увидеть:
- Напечатан идентификатор моментального снимка
- Соскоб завершен.
- Сохранено в amazon-data.json (…items)
Процесс автоматически создает данные, которые содержат наши отсканированные данные. Это ожидаемая структура данных:
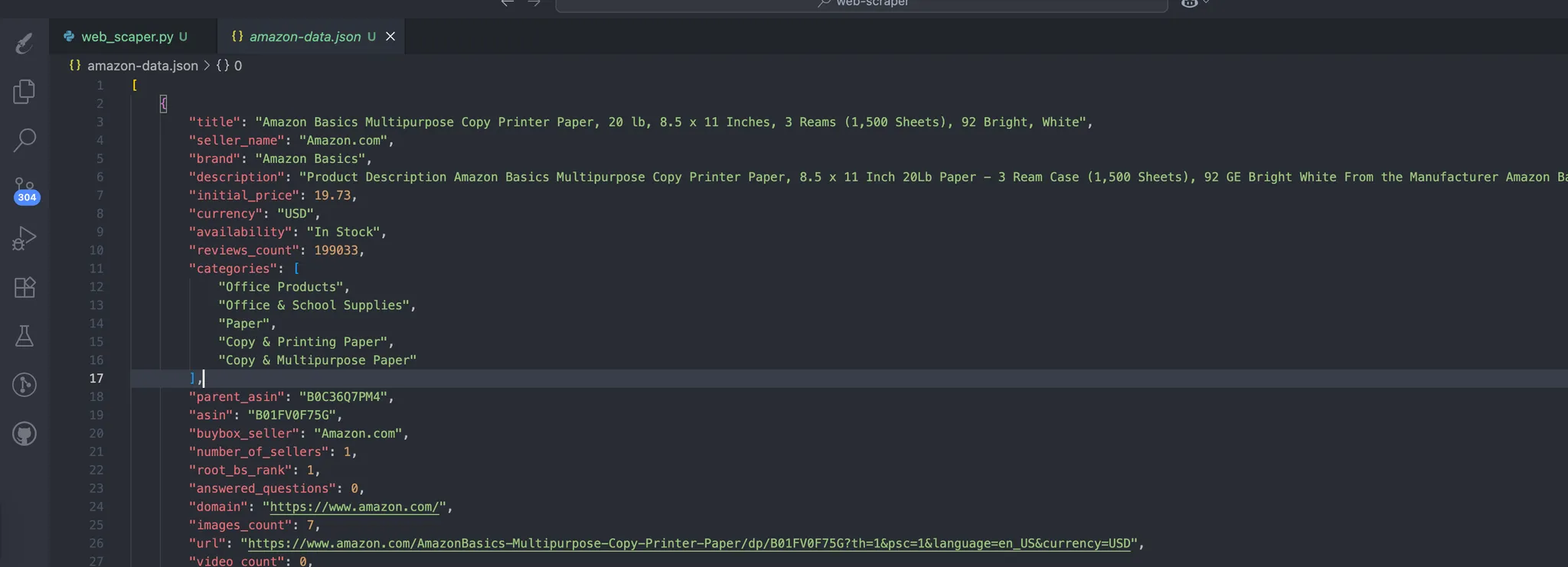
Шаг №2: Превращение JSON в обучающие пары
Создайте файл prepare_pair.py в корне проекта со следующим фрагментом, чтобы структурировать наши данные в формате JSONL и сделать их готовыми к шагу тонкой настройки.
import json, random, osnnINPUT = u0022amazon-data.jsonu0022nOUTPUT = u0022pairs.jsonlu0022nSYSTEM = u0022You are an expert copywriter. Generate concise, accurate product descriptions.u0022nndef make_example(item):n title = item.get(u0022titleu0022) or item.get(u0022nameu0022) or u0022Unknown productu0022n brand = item.get(u0022brandu0022) or u0022Unknown brandu0022n features = item.get(u0022featuresu0022) or item.get(u0022bulletsu0022) or []n features_str = u0022, u0022.join(features) if isinstance(features, list) else str(features)n target = item.get(u0022descriptionu0022) or item.get(u0022aboutu0022) or u0022u0022n user = fu0022Write a crisp product description.nTitle: {title}nBrand: {brand}nFeatures: {features_str}nDescription:u0022n assistant = target.strip()[:1200] # keep it tightn return {u0022systemu0022: SYSTEM, u0022useru0022: user, u0022assistantu0022: assistant}nndef main():n if not os.path.exists(INPUT):n raise SystemExit(fu0022Missing {INPUT}u0022)n data = json.load(open(INPUT, u0022ru0022, encoding=u0022utf-8u0022))n pairs = [make_example(x) for x in data if isinstance(x, dict)]n random.shuffle(pairs)n with open(OUTPUT, u0022wu0022, encoding=u0022utf-8u0022) as out:n for ex in pairs:n out.write(json.dumps(ex, ensure_ascii=False) + u0022nu0022)n print(fu0022Wrote {len(pairs)} examples to {OUTPUT}u0022)nnif __name__ == u0022__main__u0022:n main()
Выполните следующую команду:
python3 prepare_pairs.py
В результате в файле должен появиться следующий результат:
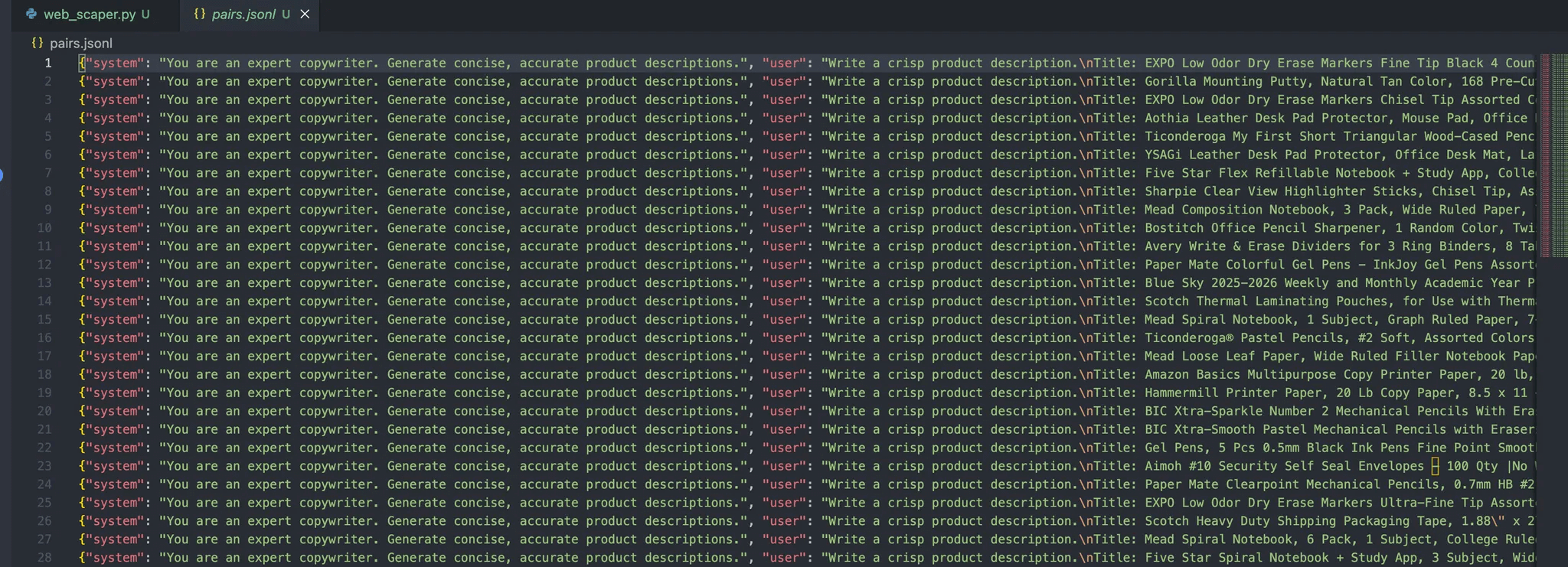
Каждое сообщение в этом объекте содержит три роли:
- Система: Обеспечивает начальный контекст для помощника.
- Пользователь: Ввод данных пользователем.
- Ассистент: ответ ассистента.
Шаг № 3: Загрузка файла для доработки
Как только файл готов, следующие шаги сводятся к подключению его к конвейеру тонкой настройки OpenAI с помощью следующих действий:
Установите зависимости OpenAI
pip install openai
Создайте upload.py для загрузки вашего набора данных.
Этот скрипт будет считывать данные из файла pairs.jsonl, который у нас уже есть .
from openai import OpenAInclient = OpenAI(api_key=u0022your_api_key_hereu0022)nnwith open(u0022pairs.jsonlu0022, u0022rbu0022) as f:n uploaded = client.files.create(file=f, purpose=u0022fine-tuneu0022)nnprint(uploaded)
Выполните следующую команду:
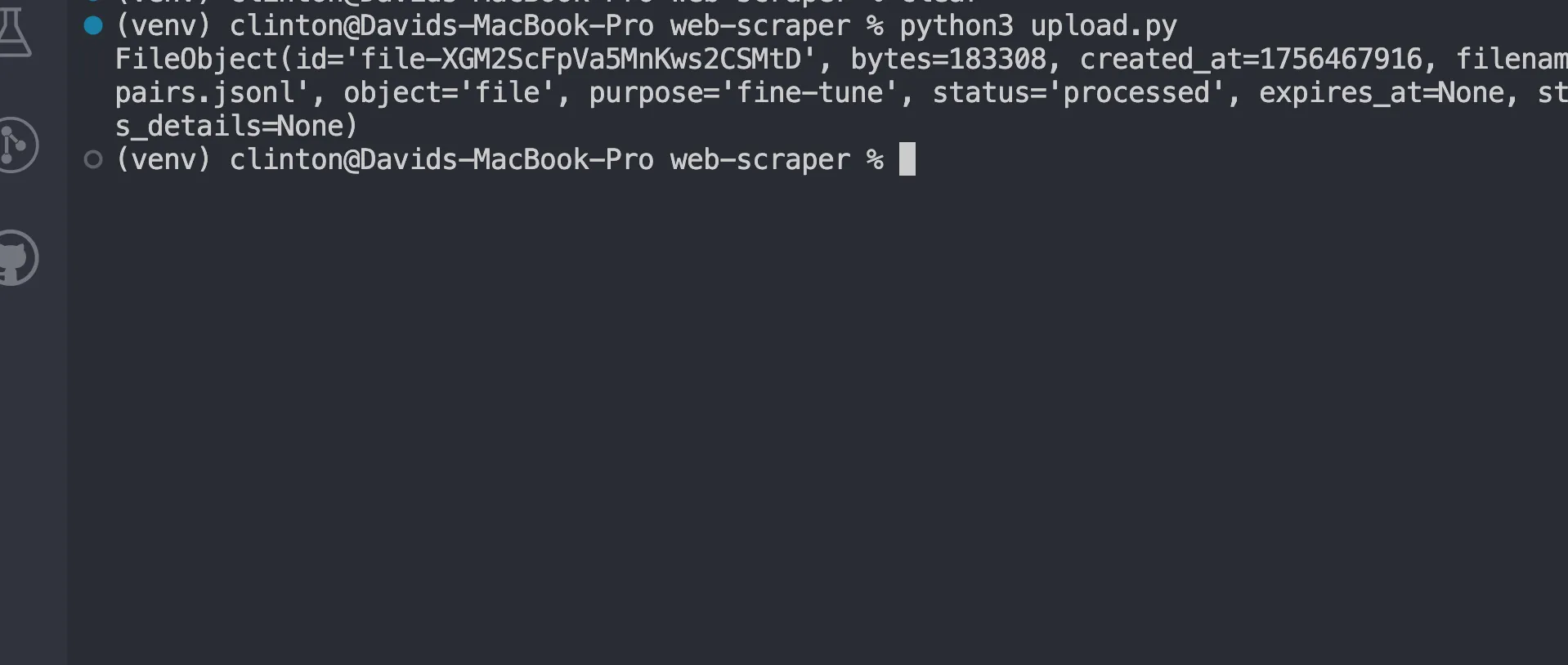
python3 upload.py
Теперь вы должны увидеть ответ, похожий на:
Тонкая настройка модели
Создайте файл fine-tune.py и замените FILE_ID на id загруженного файла, который мы получили из нашего ответа выше, и запустите файл:
from openai import OpenAInclient = OpenAI()nn# replace with your uploaded file idnFILE_ID = u0022file-xxxxxxu0022nnjob = client.fine_tuning.jobs.create(n training_file=FILE_ID,n model=u0022gpt-4o-mini-2024-07-18u0022n)nnprint(job)
Это должно дать нам такой ответ:
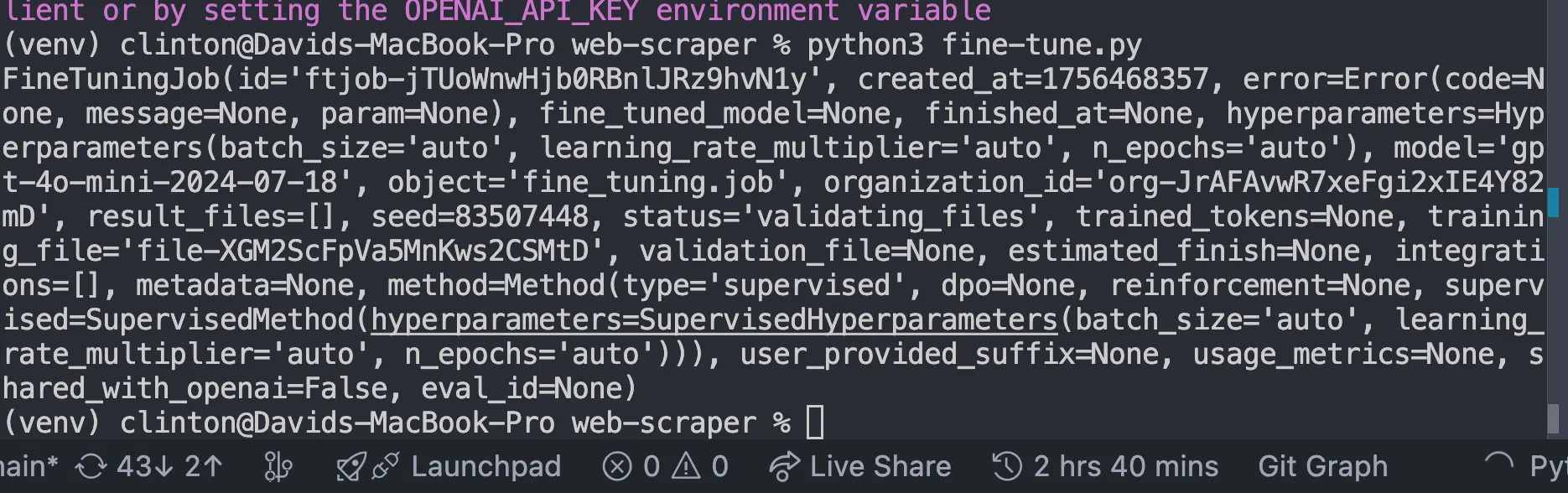
Мониторинг до окончания обучения
После того как вы запустили работу по тонкой настройке, модели нужно время, чтобы обучиться на вашем наборе данных. В зависимости от размера набора данных это может занять от нескольких минут до нескольких часов.
Но не стоит гадать, когда она будет готова; вместо этого напишите и запустите этот код в файле monitor.py
from openai import OpenAInclient = OpenAI()nnjobs = client.fine_tuning.jobs.list(limit=1)nprint(jobs)
Затем запустите файл с помощью python3 [manage.py](http://manage.py) в терминале, и он должен показать такие подробности, как:
- Удалось или не удалось провести обучение.
- Сколько лексем было обучено
- ID новой точно настроенной модели.
В этом разделе вы должны двигаться дальше только тогда, когда в поле статуса будет написано
u0022succeededu0022
Пообщаться с вашей точно настроенной моделью
После завершения работы у вас будет своя собственная модель GPT. Чтобы использовать ее, откройте chat.py, обновите MODEL_ID на тот, который был получен в результате выполнения задания по тонкой настройке, и запустите файл:
from openai import OpenAInclient = OpenAI()nn# replace with your fine-tuned model idnMODEL_ID = u0022ft:gpt-4o-mini-2024-07-18:your-org::custom123u0022nnwhile True:n user_input = input(u0022User: u0022)n if user_input.lower() in [u0022quitu0022, u0022qu0022]:n breaknn response = client.chat.completions.create(n model=MODEL_ID,n messages=[n {u0022roleu0022: u0022systemu0022, u0022contentu0022: u0022You are a helpful assistant fine-tuned on domain data.u0022},n {u0022roleu0022: u0022useru0022, u0022contentu0022: user_input}n ]n )n print(u0022Assistant:u0022, response.choices[0].message.content)
Этот шаг доказывает, что тонкая настройка сработала. Вместо того чтобы использовать базовую модель общего назначения, вы теперь обращаетесь к модели, обученной специально для ваших данных.
Именно здесь вы увидите, как ваши результаты воплощаются в жизнь.
Вы можете ожидать таких результатов, как:
u002du002d- Generating Descriptions with Fine-Tuned Model using Synthetic Test Data u002du002d-nnPROMPT for item: ErgoPro-EL100nGENERATED (Fine-tuned):n**Introducing the ErgoPro-EL100: The Ultimate Executive Ergonomic Office Chair**nnExperience the pinnacle of comfort and support with the ComfortLuxe ErgoPro-EL100, designed to elevate your work experience. This premium office chair boasts a high-back design that cradles your upper body, providing unparalleled lumbar support and promoting a healthy posture.nnThe breathable mesh fabric ensures a cool and comfortable seating experience, while the synchronized tilt mechanism allows for seamless adjustments to your preferred working position. The padded armrests provide additional support and comfort, reducing strain on your shoulders and wrists.nnBuilt to last, the ErgoPro-EL100 features a heavy-duty nylon base that ensures stability and durability. Whether you're working long hours or simplynu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002dnnPROMPT for item: HeightRise-FD20nGENERATED (Fine-tuned):n**Elevate Your Productivity with FlexiDesk's HeightRise-FD20 Adjustable Standing Desk Converter**nnTake your work to new heights with FlexiDesk's HeightRise-FD20, the ultimate adjustable standing desk converter. Designed to revolutionize your workspace, this innovative converter transforms any desk into a comfortable and ergonomic standing station.nn**Experience the Benefits of Standing**nnThe HeightRise-FD20 features a spacious dual-tier surface, perfect for holding your laptop, monitor, and other essential work tools. The smooth gas spring lift allows for effortless height adjustments, ranging from 6 to 17 inches, ensuring a comfortable standing position that suits your needs.nn**Durable and Reliable**nnWith a sturdy construction and non-slip rubber feetnu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002d
Заключение
При работе с тонкой настройкой в веб-масштабе важно реалистично подходить к ограничениям и рабочим процессам:
- Требования к ресурсам: Обучение на больших и разнообразных наборах данных требует вычислений и хранения данных. Если вы экспериментируете, начните с меньших фрагментов данных, прежде чем масштабировать их.
- Итерация должна быть постепенной: Вместо того чтобы выбрасывать миллионы записей в первой попытке, доработайте их на меньшем наборе данных. Используйте результаты, чтобы выявить пробелы или ошибки в конвейере предварительной обработки.
- Рабочие процессы развертывания: Относитесь к доработанным моделям как к любому другому программному артефакту. Версируйте их, по возможности интегрируйте в CI/CD и поддерживайте возможность отката на случай, если новая модель окажется неэффективной.
К счастью, Bright Data предлагает вам множество сервисов для сбора и создания наборов данных , готовых к работе с искусственным интеллектом:
- Scraping Browser: Браузер, совместимый с Playwright, Selenium и Puppeter, со встроенными возможностями разблокировки.
- API-интерфейсы веб-скраперов: Предварительно настроенные API для извлечения структурированных данных из 100+ основных доменов.
- Web Unlocker: Универсальный API, позволяющий разблокировать сайты с защитой от ботов.
- SERP API: Специализированный API, который разблокирует результаты поисковых систем и извлекает полные данные SERP.
- Данные для моделей фундамента: Доступ к совместимым наборам данных веб-масштаба для предварительного обучения, оценки и тонкой настройки.
- Поставщики данных: Связь с надежными поставщиками для получения высококачественных наборов данных, готовых для ИИ, в масштабе.
- Пакеты данных: Получайте готовые к использованию наборы данных – структурированные, обогащенные и аннотированные.
Тонкая настройка больших языковых моделей с помощью веб-данных открывает мощные возможности для специализации в конкретной области. Интернет предоставляет свежий, разнообразный и мультимодальный контент – от статей и обзоров до стенограмм и структурированных метаданных, – с которым не могут сравниться только наборы данных.
Создайте учетную запись Bright Data, чтобы бесплатно протестировать нашу инфраструктуру данных с поддержкой искусственного интеллекта!





