

Последняя модель ИИ с открытым исходным кодом, Gemma 3, выпущенная Google в марте 2025 года, демонстрирует впечатляющую производительность, не уступающую многим собственным LLM, и при этом эффективно работает на оборудовании с ограниченными ресурсами. Это достижение в области ИИ с открытым исходным кодом работает на различных платформах, предлагая разработчикам по всему миру мощные возможности в доступном формате.
В этом руководстве мы расскажем вам о тонкой настройке Gemma 3 на пользовательском наборе данных вопросов-ответов, полученном из отзывов Trustpilot. Мы используем Bright Data для сбора отзывов покупателей, их обработки в структурированные пары QA и задействуем Unsloth для эффективной тонкой настройки с минимальными вычислениями. К концу работы вы создадите специализированный ИИ-помощник, понимающий специфические вопросы и готовый к размещению на Hugging Face Hub.
Давайте погрузимся!
Понимание Джеммы 3
Семейство Gemma 3 было запущено Google в марте 2025 года с четырьмя параметрами открытого веса – 1B, 4B, 12B и 27B – все они предназначены для работы на одном GPU.
- Модель 1B – это только текст с контекстным окном на 32 тыс. токов.
- Модели 4B, 12B и 27B добавляют мультимодальный ввод (текст + изображение) и поддерживают окно на 128K токенов.
В таблице человеческих предпочтений LMArena Gemma 3-27B-IT опережает такие более крупные модели, как Llama 3 405B и DeepSeek-V3, предлагая самое современное качество без необходимости использования нескольких GPU.

Источник изображения: Представляем вам Джемму 3
Основные характеристики моделей Gemma 3
Вот некоторые примечательные особенности моделей Gemma 3:
- Мультимодальный ввод (текст + изображение) доступен в моделях 4B, 12B и 27B.
- Длинный контекст –до 128K токенов (32K в модели 1B).
- Многоязычные возможности – 35+ языков, поддерживаемых “из коробки”; 140+ языков, прошедших предварительную подготовку.
- Quantization-Aware Training – Официальные версии QAT значительно снижают потребление памяти (примерно в 3 раза) при сохранении высокого качества.
- Вызов функций и структурированный вывод – встроенная поддержка автоматизации вызовов и получения структурированных ответов.
- Эффективность – рассчитана на работу на одном GPU/TPU или даже на потребительских устройствах, от телефонов и ноутбуков до рабочих станций.
- Безопасность (ShieldGemma) – имеет встроенную систему фильтрации контента.
Зачем нужна тонкая настройка Gemma 3?
Тонкая настройка позволяет использовать предварительно обученную модель, такую как Gemma 3, и научить ее новому поведению для конкретной области или задачи, не затрачивая времени и средств на обучение с нуля. Благодаря компактному дизайну и, в вариантах 4B+, мультимодальной поддержке, Gemma 3 легка, доступна и может быть точно настроена даже на оборудовании с ограниченными ресурсами.
Преимущества тонкой настройки включают:
- Специализация по домену – помогает модели понимать отраслевой язык и лучше справляться со специализированными задачами в вашей области.
- Расширение знаний – добавление важных фактов и контекста, которые не были частью исходных обучающих данных модели.
- Уточнение поведения – корректировка реакции модели, чтобы она соответствовала тону вашего бренда или предпочтительному формату вывода.
- Оптимизация ресурсов – достижение высококачественных результатов при использовании значительно меньшего количества вычислительных ресурсов по сравнению с обучением новой модели с нуля.
Пререквизиты
Прежде чем приступить к этому уроку, убедитесь, что у вас есть следующее:
- В вашей системе установленPython 3.9 или выше.
- Базовые знания программирования на языке Python.
- Доступ к вычислительной среде с поддержкой GPU (например, Google Colab, Jupyter Notebook или Kaggle Notebooks).
- Понимание основ машинного обучения и больших языковых моделей (LLM).
- Опыт использования IDE, такой как VS Code или аналогичной.
Вам также понадобятся учетные данные для доступа к внешним службам:
- Учетная запись Hugging Face и токен с доступом для записи.
👉 Создайте токен здесь - Учетная запись Bright Data и токен API.
👉 Зарегистрируйтесь и следуйте инструкциям, чтобы сгенерировать токен. - Учетная запись OpenAI и ключ API.
👉 Получить ключ API можно здесь
💡 Убедитесь, что на вашем аккаунте OpenAI достаточно средств. Управление выставлением счетов здесь, а отслеживание использования здесь.
Создание пользовательского набора данных для тонкой настройки
Тонкая настройка лучше всего работает, когда ваш набор данных точно отражает поведение, которому вы хотите научить модель. Создав собственный набор данных, адаптированный к конкретному случаю использования, вы сможете значительно повысить эффективность работы модели. Помните классическое правило: “Мусор внутрь, мусор наружу”. Вот почему так важно уделять время подготовке наборов данных.
Высококачественный набор данных должен:
- Соответствие конкретному сценарию использования – чем ближе ваш набор данных к целевому приложению, тем более релевантными будут результаты вашей модели.
- Поддерживайте последовательное форматирование – единообразная структура (например, пары “вопрос-ответ”) помогает модели эффективнее изучать шаблоны.
- Включите различные примеры – разнообразие сценариев помогает модели обобщать различные исходные данные.
- Чистота и отсутствие ошибок – устранение несоответствий и шумов не позволит модели уловить нежелательное поведение.
Начнем с сырых отзывов, таких как этот:

И преобразуйте их в структурированные пары “вопрос-ответ”, например, так:

Этот набор данных научит Gemma 3 извлекать информацию из отзывов клиентов, определять шаблоны настроений и давать действенные рекомендации.
Этапы настройки
#1 Установите библиотеки: Откройте среду проекта и установите все необходимые библиотеки Python, перечисленные в файле requirements.txt. Это можно сделать, выполнив следующую команду в терминале или блокноте:
pip install -r requirements.txt#2 Настройте переменные окружения: Создайте файл .env в корневом каталоге проекта и надежно сохраните в нем ключи API.
OPENAI_API_KEY="your_openai_key_here"
HF_TOKEN="your_hugging_face_token_here"Шаг 1: Сбор данных с помощью Bright Data
Важнейшим первым шагом является поиск данных. Чтобы создать набор данных для тонкой настройки, мы соберем необработанные данные об отзывах с Trustpilot. Благодаря надежной защите Trustpilot от ботов, мы будем использовать API Trustpilot Scraper от Bright Data. Этот API эффективно управляет ротацией IP-адресов, разрешением CAPTCHA и обработкой динамического контента, позволяя эффективно собирать структурированные отзывы в масштабе, минуя сложности создания собственного решения для скрапинга.
Вот сценарий на языке Python, который пошагово показывает, как использовать API Bright Data для сбора отзывов:
import time
import json
import requests
from typing import Optional
# --- Configuration ---
API_KEY = "YOUR_API_KEY" # Replace with your Bright Data API key
DATASET_ID = "gd_lm5zmhwd2sni130p" # Replace with your Dataset ID
TARGET_URL = "https://www.trustpilot.com/review/hubspot.com" # Target company page
OUTPUT_FILE = "trustpilot_reviews.json" # Output file name
HEADERS = {"Authorization": f"Bearer {API_KEY}"}
TIMEOUT = 30 # Request timeout in seconds
# --- Functions ---
def trigger_snapshot() -> Optional[str]:
"""Triggers a Bright Data snapshot collection job."""
print(f"Triggering snapshot for: {TARGET_URL}")
try:
resp = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
headers=HEADERS,
params={"dataset_id": DATASET_ID},
json=[{"url": TARGET_URL}],
timeout=TIMEOUT,
)
resp.raise_for_status() # Raise HTTPError for bad responses (4xx or 5xx)
snapshot_id = resp.json().get("snapshot_id")
print(f"Snapshot triggered successfully. ID: {snapshot_id}")
return snapshot_id
except requests.RequestException as e:
print(f"Error triggering snapshot: {e}")
except json.JSONDecodeError:
print(f"Error decoding trigger response: {resp.text}")
return None
def wait_for_snapshot(snapshot_id: str) -> Optional[list]:
"""Polls the API until snapshot data is ready and returns it."""
check_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}"
print(f"Waiting for snapshot {snapshot_id} to complete...")
while True:
try:
resp = requests.get(
check_url,
headers=HEADERS,
params={"format": "json"},
timeout=TIMEOUT,
)
resp.raise_for_status()
# Check if response is the final data (list) or status info (dict)
if isinstance(resp.json(), list):
print("Snapshot data is ready.")
return resp.json()
else:
pass
except requests.RequestException as e:
print(f"Error checking snapshot status: {e}")
return None # Stop polling on error
except json.JSONDecodeError:
print(f"Error decoding snapshot status response: {resp.text}")
return None # Stop polling on error
print("Data not ready yet. Waiting 30 seconds...")
time.sleep(30)
def save_reviews(reviews: list, output_file: str) -> bool:
"""Saves the collected reviews list to a JSON file."""
try:
with open(output_file, "w", encoding="utf-8") as f:
json.dump(reviews, f, indent=2, ensure_ascii=False)
print(f"Successfully saved {len(reviews)} reviews to {output_file}")
return True
except (IOError, TypeError) as e:
print(f"Error saving reviews to file: {e}")
return False
except Exception as e:
print(f"An unexpected error occurred during saving: {e}")
return False
def main():
"""Main execution flow for collecting Trustpilot reviews."""
print("Starting Trustpilot review collection process...")
snapshot_id = trigger_snapshot()
if not snapshot_id:
print("Failed to trigger snapshot. Exiting.")
return
reviews = wait_for_snapshot(snapshot_id)
if not reviews:
print("Failed to retrieve reviews from snapshot. Exiting.")
return
if not save_reviews(reviews, OUTPUT_FILE):
print("Failed to save the collected reviews.")
else:
print("Review collection process completed.")
if __name__ == "__main__":
main()Этот сценарий выполняет следующие действия:
- Аутентификация: Он использует ваш
API_KEYдля аутентификации с Bright Data API через заголовокавторизации. - Триггер сбора: Он отправляет POST-запрос для запуска сбора данных “моментального снимка” для указанного
TARGET_URL(в данном случае страница Trustpilot компании HubSpot), связанного с вашимDATASET_ID. - Ждать завершения: Периодически опрашивает API, используя возвращенный
snapshot_id, чтобы проверить, завершен ли сбор данных. - Получение данных: Как только API укажет, что данные готовы, скрипт извлекает данные обзора в формате JSON.
- Сохранить вывод: Сохраняет собранный список объектов отзывов в структурированный JSON-файл
(trustpilot_reviews.json).
Каждый обзор в результирующем JSON-файле содержит подробную информацию, например:
{
"review_id": "680af52fb0bab688237f75c5",
"review_date": "2025-04-25T04:36:31.000Z",
"review_rating": 1,
"review_title": "Cancel Auto Renewal Doesn't Work",
"review_content": "I was with Hubspot for almost 3 years...",
"reviewer_name": "Steven Barrett",
"reviewer_location": "AU",
"is_verified_review": false,
"review_date_of_experience": "2025-04-19T00:00:00.000Z",
// Additional fields omitted for brevity
}Узнайте, как найти лучшие данные для обучения LLM с помощью нашего руководства: Лучшие источники данных для обучения LLM.
Шаг 2: Преобразование JSON в Markdown
После сбора необработанных данных обзоров следующим шагом будет их преобразование в чистый, читаемый формат, пригодный для обработки. Мы будем использовать Markdown, который предлагает легкую структуру простого текста, уменьшающую шум при токенизации, потенциально улучшающую производительность тонкой настройки и обеспечивающую последовательное разделение между различными разделами контента.
Чтобы выполнить преобразование, просто запустите этот скрипт 👉 convert-trustpilot-json-to-markdown.py
Этот сценарий считывает данные в формате JSON из результатов Шага 1 и генерирует файл в формате Markdown, содержащий структурированную сводку и отдельные отзывы покупателей.
Вот пример структуры вывода в формате Markdown:
# HubSpot Review Summary
[Visit Website](https://www.hubspot.com/)
**Overall Rating**: 2.3
**Total Reviews**: 873
**Location**: United States
**Industry**: Electronics & Technology
> HubSpot is a leading growth platform... Grow Better.
---
### Review by Steven Barrett (AU)
- **Posted on**: April 25, 2025
- **Experience Date**: April 19, 2025
- **Rating**: 1
- **Title**: *Cancel Auto Renewal Doesn't Work*
I was with Hubspot for almost 3 years... Avoid.
[View Full Review](https://www.trustpilot.com/reviews/680af52fb0bab688237f75c5)
---Узнайте , почему агенты искусственного интеллекта предпочитают Markdown, а не HTML, прочитав наше руководство.
Шаг 3: разбивка и обработка документа
Когда документ в формате Markdown готов, следующий важный шаг – разбить его на более мелкие и удобные фрагменты. Это важно, потому что большие языковые модели (LLM) имеют ограничения на количество входных лексем, и тонкая настройка часто лучше всего работает с примерами соответствующей длины. Кроме того, обработка этих фрагментов может улучшить их ясность и связность для модели.
Для разбиения Markdown-файла мы используем RecursiveCharacterTextSplitter от LangChain. Этот метод рекурсивно разбивает текст на основе списка разделителей, что помогает сохранить связанные фрагменты текста вместе. Чтобы сохранить контекст, который может пересекаться с точками разбиения, мы применяем перекрытие между последовательными фрагментами. Для этого процесса мы используем размер фрагмента 1 024 символа с перекрытием в 256 символов.
После разбиения каждый фрагмент по желанию передается в LLM (например, GPT-4o) для улучшения общей ясности и связности, при этом строго сохраняется исходный смысл текста обзора. Этот шаг улучшения направлен на то, чтобы сделать структуру данных и содержание каждого чанка оптимально понятными для последующего процесса тонкой настройки.
Каждому обработанному фрагменту присваивается уникальный идентификатор, и он сохраняется в файле формата JSON Lines (.jsonl), подготавливая его к следующему этапу конвейера.
Вот функция Python, использующая LLM для улучшения наглядности:
def improve_review_chunk(text: str, client: OpenAI, model: str = "gpt-4o") -> str:
prompt = """Improve this review's clarity while preserving its meaning:
{text}
Return only the improved text without additional commentary."""
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": text}
]
)
return response.choices[0].message.contentПолный код этого шага можно найти здесь 👉 split-markdown-into-chunks.py
На выходе получается файл JSON Lines, в котором каждая строка представляет собой фрагмент обзора с уникальным идентификатором и потенциально улучшенным содержимым обзора:
[
{
"id": "f8a3b1c9-e4d5-4f6a-8b7c-2d9e0a1b3c4d", // Unique chunk ID
"review": "# HubSpot Review Summarynn[Visit Website](https://www.hubspot.com/)...n---nn### Review by Steven Barrett (AU)n- **Posted on**: April 25, 2024...n- **Rating**: 1n- **Title**: *Cancel Auto Renewal Doesn't Work*nnI was with Hubspot for almost 3 years... [Text continues - may be improved]" // Chunk content (potentially refined)
},
// ... more chunk objects
]Шаг 4: Создание пар QA
На последнем этапе подготовки данных обработанные фрагменты отзывов преобразуются в структурированные пары “вопрос-ответ” (QA), подходящие для тонкой настройки языковой модели. Мы используем GPT-4o от OpenAI для генерации одной пары QA для каждого фрагмента в файле .jsonl, созданном на этапе 3.
Для каждого фрагмента скрипт вызывает API OpenAI с помощью тщательно продуманной системной подсказки:
SYSTEM_PROMPT = """
You are an expert at transforming customer reviews into insightful question–answer pairs. For each review, generate exactly 1 high-quality QA pair.
PURPOSE:
These QA pairs will train a customer service AI to understand feedback patterns about HubSpot products and identify actionable insights.
GUIDELINES FOR QUESTIONS:
- Make questions general and applicable to similar situations
- Phrase from a stakeholder perspective (e.g., "What feature gaps are causing customer frustration?")
- Focus on product features, usability, pricing, or service impact
GUIDELINES FOR ANSWERS:
- Provide analytical responses (3–5 sentences)
- Extract insights without quoting verbatim
- Offer actionable recommendations
- Maintain objectivity and clarity
FORMAT REQUIREMENTS:
- Start with "Q: " followed by your question
- Then "A: " followed by a plain-text answer
"""Скрипт включает встроенные механизмы ограничения скорости и повторных попыток для обработки временных прерываний API и обеспечения стабильного выполнения. Полную реализацию можно найти в generate-qa-pairs.py.
Выходные данные сохраняются в виде массива JSON, где каждый объект содержит сгенерированную пару вопросов и ответов, связанных идентификатором исходного чанка:
[
{
"id": "82d53a10-9f37-4d03-8d3b-38812e39ecdc",
"question": "How can pricing and customer support issues impact customer satisfaction and retention for HubSpot?",
"answer": "Pricing concerns, particularly when customers feel they are overpaying for services they find unusable or unsupported, can significantly impact customer satisfaction and retention..."
}
// ... more QA pairs
]После создания настоятельно рекомендуется отправить полученный набор данных QA в Hugging Face Hub. Это сделает его легкодоступным для тонкой настройки и обмена. Пример опубликованного набора данных можно посмотреть здесь: trustpilot-reviews-qa-dataset.
Тонкая настройка Gemma 3 с помощью Unsloth: Шаг за шагом
Теперь, когда мы подготовили наш пользовательский набор данных Q&A, давайте настроим модель Gemma 3. Мы будем использовать Unsloth, библиотеку с открытым исходным кодом, которая обеспечивает значительный прирост памяти и скорости обучения LoRA/QLoRA по сравнению со стандартными реализациями Hugging Face. Эти оптимизации делают тонкую настройку таких моделей, как Gemma 3, более доступной на однопроцессорных установках, при условии, что GPU имеет достаточно VRAM.
| Джемма 3 Размер | Примерное количество требуемой памяти VRAM* | Подходящие платформы |
|---|---|---|
| 4B | ~15 ГБ | Бесплатный Google Colab (T4), Kaggle (P100 16 ГБ) |
| 12B | ≥24 ГБ | Colab Pro+ (A100/A10), RTX 4090, A40 |
| 27B | 22-24 ГБ (с 4-битным QLoRA, размер партии = 1); ~40 ГБ в противном случае | A100 40 ГБ, H100, многопроцессорные системы |
Примечание: требования к VRAM могут варьироваться в зависимости от размера партии, длины последовательности и конкретных методов квантования. Для модели 27B требуется 4-битный QLoRA и небольшой размер партии (например, 1 или 2); для более высоких размеров партии или менее агрессивного квантования потребуется значительно больше VRAM (~40 ГБ+).
Новичкам рекомендуется начать с модели 4B на бесплатном ноутбуке Colab, поскольку она обеспечивает комфортную загрузку, обучение и развертывание Unsloth. Переход на модели 12B или 27B следует рассматривать только при наличии доступа к GPU с большим объемом памяти или платным облачным уровням.
Чтобы изменить тип времени выполнения в Google Colab и выбрать GPU T4, выполните следующие действия:
- Нажмите на меню Runtime в верхней части экрана.
- Выберите Изменить тип времени выполнения.
- В появившемся диалоговом окне в разделе Аппаратный ускоритель выберите GPU.
- Нажмите кнопку Сохранить, чтобы применить изменения.

Шаг 1: Настройка среды
Сначала установите необходимые библиотеки. Если вы работаете в среде Colab или Jupyter, вы можете выполнить эти команды прямо в ячейке кода.
%%capture
!pip install --no-deps unsloth vllm
import sys, re, requests; modules = list(sys.modules.keys())
for x in modules: sys.modules.pop(x) if "PIL" in x or "google" in x else None
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29.post3 peft "trl==0.15.2" triton cut_cross_entropy unsloth_zoo
!pip install sentencepiece protobuf datasets huggingface_hub hf_transfer
# vLLM requirements - vLLM breaks Colab due to reinstalling numpy
f = requests.get("https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/requirements/common.txt").content
with open("vllm_requirements.txt", "wb") as file:
file.write(re.sub(rb"(transformers|numpy|xformers)[^n]{1,}n", b"", f))
!pip install -r vllm_requirements.txtВот краткое объяснение основных установленных пакетов:
unsloth: Обеспечивает основные оптимизации для более быстрого и более эффективного с точки зрения памяти обучения и загрузки LLM с использованием таких техник, как слитые ядра.peft: Методы параметрической эффективной тонкой настройки (как LoRA). Позволяют обучать только небольшое количество дополнительных параметров вместо полной модели.trl: Transformer Reinforcement Learning. ВключаетSFTTrainer, который упрощает процесс контролируемой тонкой настройки.bitsandbytes: Включает квантование k-бит (4 и 8 бит), значительно уменьшая объем памяти модели.ускорить: Библиотека Hugging Face для плавного запуска обучения PyTorch на различных аппаратных установках (один GPU, несколько GPU и т. д.).datasets: Библиотека Hugging Face для эффективной загрузки, обработки и управления наборами данных.transformers: основная библиотека Hugging Face для предварительно обученных моделей, токенизаторов и утилит.huggingface_hub: Утилиты для взаимодействия с Hugging Face Hub (вход, загрузка, выгрузка).vllm(необязательно): Быстрый механизм вывода LLM. Может быть установлен отдельно, если это необходимо для развертывания.
Шаг 2: Аутентификация с помощью обнимающихся лиц
Вам нужно будет войти в Hugging Face Hub из своей среды, чтобы загрузить модель и, возможно, позже загрузить доработанный результат.
import os
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get('HF_TOKEN')
if not hf_token:
raise ValueError("Please set your HF_TOKEN environment variable before running.")
try:
login(hf_token)
print("Successfully logged in to Hugging Face Hub.")
except Exception as e:
print(f"Error logging in to Hugging Face Hub: {e}")В Google Colab наиболее безопасным способом управления токеном Hugging Face является вкладка “Секреты”:
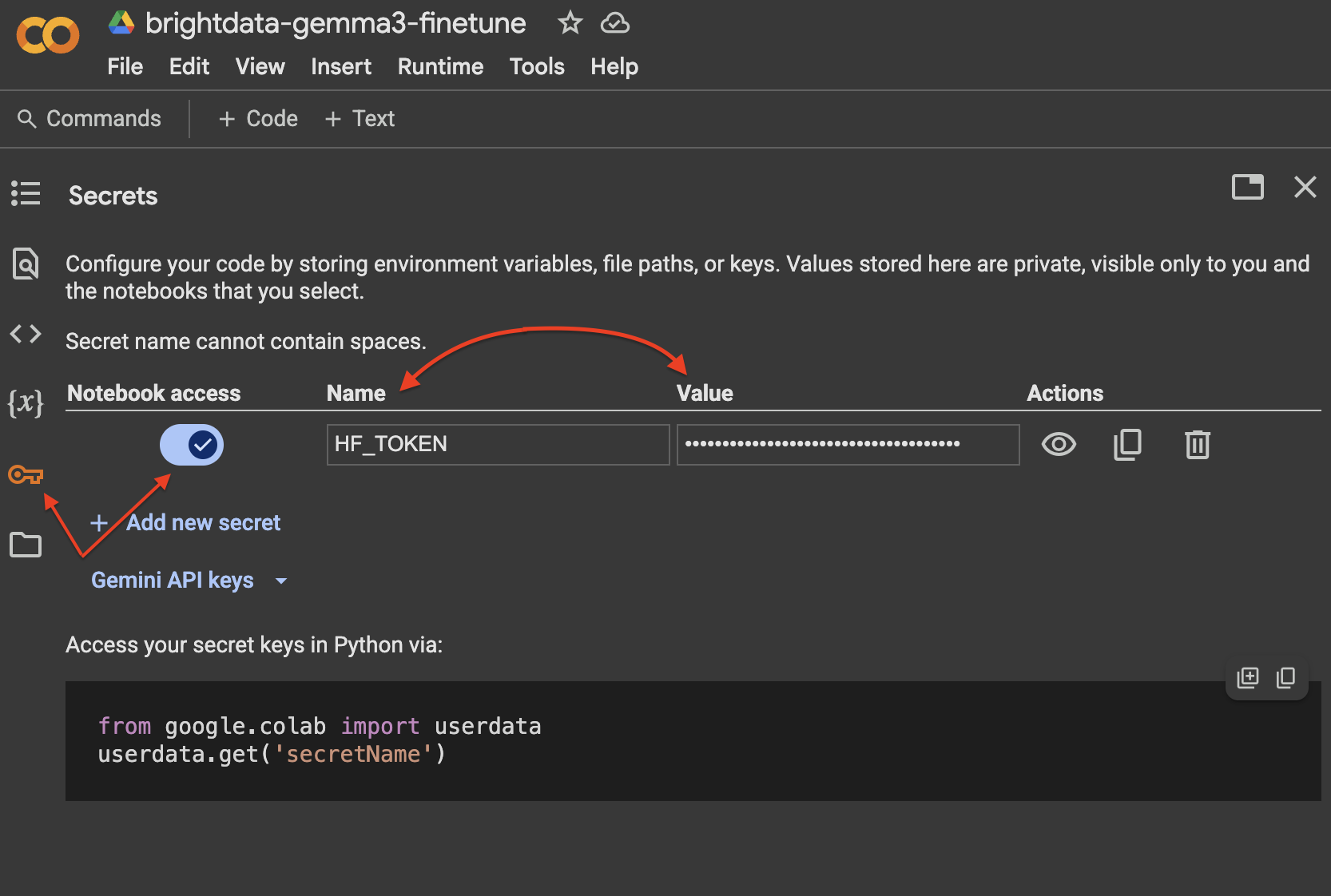
Шаг 3: Загрузка модели и токенизатора
Чтобы начать тонкую настройку, мы эффективно загрузим модель Gemma 3, настроенную на инструкции, с помощью FastModel от Unsloth. Для этого примера мы будем использовать модель unsloth/gemma-3-4b-it, которая представляет собой 4-битную квантованную версию, оптимизированную Unsloth для того, чтобы уложиться в ограничения памяти типичных графических процессоров Colab.
Посмотрите коллекцию Gemma 3 от Unsloth на Hugging Face. В нее вошли модели размеров 1B, 4B, 12B и 27B, доступные в форматах GGUF, 4-bit и 16-bit.
from unsloth import FastModel
from unsloth.chat_templates import get_chat_template
import torch # Import torch for checking CUDA
# Ensure CUDA is available
if not torch.cuda.is_available():
raise RuntimeError("CUDA is not available. A GPU is required for this tutorial.")
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"CUDA device name: {torch.cuda.get_device_name(0)}")
model, tokenizer = FastModel.from_pretrained(
model_name="unsloth/gemma-3-4b-it", # Using the 4B instruction-tuned model optimized by Unsloth
max_seq_length=2048, # Set max context length
load_in_4bit=True, # Enable 4-bit quantization
full_finetuning=False, # Use PEFT (LoRA)
token=hf_token, # Pass your Hugging Face token
)
# Apply the correct chat template for Gemma 3
tokenizer = get_chat_template(tokenizer, chat_template="gemma-3")
print("Model and Tokenizer loaded successfully.")Что происходит в этом коде:
FastModel.from_pretrained(): Оптимизированный загрузчик моделей Unsloth.model_name="unsloth/gemma-3-4b-it": Указывает вариант модели для загрузки. Мы выбираем версию 4B instruction-tuned(it), предварительно оптимизированную Unsloth.max_seq_length=2048: Устанавливает максимальное количество лексем, которые модель может обрабатывать одновременно. Настройте этот параметр в зависимости от длины фрагментов данных и желаемого контекстного окна, чтобы сбалансировать использование памяти и возможность обработки более длинных входных данных.load_in_4bit=True: необходимо для обучения на ограниченной VRAM. Это загружает веса модели с 4-битной точностью, используяbitsandbytes.full_finetuning=False: Указывает Unsloth подготовить модель к тонкой настройке PEFT/LoRA, то есть будут обучены только слои адаптера, а не все параметры модели.get_chat_template(tokenizer, chat_template="gemma-3"): Обертывает токенизатор для автоматического форматирования подсказок в ожидаемый формат чата Gemma 3(<start_of_turn>usern...n<end_of_turn><start_of_turn>modeln...n<end_of_turn>). Это очень важно для правильной настройки моделей следования инструкциям и обеспечения того, чтобы модель научилась генерировать ответы в ожидаемых разговорных оборотах.
Шаг 4: Загрузка и подготовка набора данных для обучения
Мы загружаем набор данных, который мы ранее загрузили в Hugging Face Hub, а затем преобразуем его в формат чата, ожидаемый токенизатором и тренером.
from datasets import load_dataset
from unsloth.chat_templates import standardize_data_formats, train_on_responses_only # train_on_responses_only imported earlier
# 1. Load the dataset from Hugging Face Hub
dataset_name = "triposatt/trustpilot-reviews-qa-dataset" # Replace with your dataset name
dataset = load_dataset(dataset_name, split="train")
print(f"Dataset '{dataset_name}' loaded.")
print(dataset)
# 2. Normalize any odd formats (ensure 'question' and 'answer' fields exist)
dataset = standardize_data_formats(dataset)
print("Dataset standardized.")
# 3. Define a function to format examples into chat template
def formatting_prompts_func(examples):
"""Formats question-answer pairs into Gemma 3 chat template."""
questions = examples["question"]
answers = examples["answer"]
texts = []
for q, a in zip(questions, answers):
# Structure the conversation as a list of roles and content
conv = [
{"role": "user", "content": q},
{"role": "assistant", "content": a},
]
# Apply the chat template
txt = tokenizer.apply_chat_template(
conv,
tokenize=False, # Return string, not token IDs
add_generation_prompt=False # Don't add the model's start tag at the end yet
)
# Gemma 3 tokenizer adds <bos> by default, which the trainer will re-add
# We remove it here to avoid double <bos> tokens
txt = txt.removeprefix(tokenizer.bos_token)
texts.append(txt)
return {"text": texts}
# 4. Apply the formatting function to the dataset
dataset = dataset.map(formatting_prompts_func, batched=True, remove_columns=["question", "answer"])
print("Dataset formatted with chat template.")
print(dataset) # Inspect the new 'text' columnВ этом коде:
load_dataset(): Получает наш набор данных Q&A из Hugging Face Hub.standardize_data_formats(): Обеспечивает согласованность названий полей в разных наборах данных, в частности, в данном случае ищет ‘question’ и ‘answer’.formatting_prompts_func(): Эта критически важная функция обрабатывает партии наших пар вопросов и ответов. Она использует методtokenizer.apply_chat_template()для преобразования их в строки, правильно отформатированные для тонкой настройки инструкций Gemma 3. Этот формат включает специальные лексемы поворота, такие как<start_of_turn>usernи<start_of_turn>modeln, которые необходимы модели для понимания структуры разговора. Мы удаляем начальную лексему<bos>, посколькуSFTTrainerдобавляет свою собственную.dataset.map(...): Эффективно применяет функциюformatting_prompts_funcко всему набору данных, создавая новый столбец ‘text’, содержащий отформатированные строки, и удаляя исходные столбцы.
Шаг 5: Настройка LoRA и тренажера
Теперь мы настроим параметры PEFT (LoRA) и SFTTrainer из библиотеки trl. LoRA работает путем введения небольших обучаемых матриц в ключевые слои предварительно обученной модели. При тонкой настройке обновляются только эти небольшие матрицы-адаптеры, что значительно сокращает количество параметров для обучения и, соответственно, минимизирует потребление памяти.
from trl import SFTTrainer, SFTConfig
import torch
# 1. Configure LoRA
model = FastModel.get_peft_model(
model,
r=8, # LoRA rank (a common value) - lower rank means fewer parameters, higher means more expressive
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj", # Attention layers
"gate_proj", "up_proj", "down_proj" # MLP layers
],
# Set True if you want to fine-tune language layers (recommended for text tasks)
# and Attention/MLP modules (where LoRA is applied)
finetune_language_layers=True,
finetune_attention_modules=True,
finetune_mlp_modules=True,
# finetune_vision_layers=False, # Only relevant for multimodal models (12B/27B)
lora_alpha=8, # LoRA scaling factor (often set equal to r)
lora_dropout=0, # Dropout for LoRA layers
bias="none", # Don't train bias terms
use_gradient_checkpointing="unsloth", # Memory optimization
random_state=1000, # Seed for reproducibility
use_rslora=False, # Rank-Stabilized LoRA (optional alternative)
# modules_to_save=["embed_tokens", "lm_head"], # Optional: train embedding/output layers
)
print("Model configured for PEFT (LoRA).")
# 2. Configure the SFTTrainer
# Determine a reasonable max_steps based on dataset size and epochs
# For demonstration, a small number of steps is used (e.g., 30)
# For a real use case, calculate steps = (dataset_size / batch_size / grad_accum) * num_epochs
dataset_size = len(dataset)
per_device_train_batch_size = 2 # Adjust based on your GPU VRAM
gradient_accumulation_steps = 4 # Accumulate gradients to simulate larger batch size (batch_size * grad_accum = 8)
num_train_epochs = 3 # Example: 3 epochs
# Calculate total training steps
total_steps = int((dataset_size / per_device_train_batch_size / gradient_accumulation_steps) * num_train_epochs)
# Ensure max_steps is not 0 if dataset is small or calculation results in < 1 step
max_steps = max(30, total_steps) # Set a minimum or calculate properly
print(f"Calculated total training steps for {num_train_epochs} epochs: {total_steps}. Using max_steps={max_steps}")
sft_config = SFTConfig(
dataset_text_field="text", # The column in our dataset containing the formatted chat text
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
warmup_steps=max(5, int(max_steps * 0.03)), # Warmup for first few steps (e.g., 3% of total steps)
max_steps=max_steps, # Total number of training steps
learning_rate=2e-4, # Learning rate
logging_steps=max(1, int(max_steps * 0.01)), # Log every 1% of total steps (min 1)
optim="adamw_8bit", # 8-bit AdamW optimizer (memory efficient)
weight_decay=0.01, # L2 regularization
lr_scheduler_type="linear", # Linear learning rate decay
seed=3407, # Random seed
report_to="none", # Disable reporting to platforms like W&B unless needed
output_dir="./results", # Directory to save checkpoints and logs
)
# 3. Build the SFTTrainer instance
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
eval_dataset=None, # Optional: provide a validation dataset
args=sft_config,
)
print("SFTTrainer built.")
# 4. Mask out the input portion for training
# This teaches the model to only generate the assistant’s response
# It prevents the model from just copying the user’s prompt
# Pass the literal prefixes for instruction and response turns from the chat template
trainer = train_on_responses_only(
trainer,
instruction_part="<start_of_turn>usern", # Literal string before user content
response_part="<start_of_turn>modeln", # Literal string before model content
)
print("Trainer configured to train only on responses.")В этом коде:
FastModel.get_peft_model(): Конфигурирует загруженную модель для тонкой настройки LoRA с указанными параметрами.r– ранг LoRA, управляющий размером матриц адаптеров.target_modulesуказывает, какие слои модели (например, внимание и проекции MLP) получат эти адаптеры.lora_alpha– масштабный коэффициент.use_gradient_checkpointing– техника экономии памяти, предоставляемая Unsloth.SFTConfig(): Определяет гиперпараметры обучения дляSFTTrainer.per_device_train_batch_sizeиgradient_accumulation_stepsработают вместе, чтобы определить эффективный размер партии, используемой для вычисления градиентов.max_stepsустанавливает общее количество итераций обучения.learning_rate,optim,weight_decayиlr_scheduler_typeуправляют процессом оптимизации.dataset_text_fieldсообщает тренеру, в каком столбце набора данных содержатся отформатированные примеры обучения.SFTTrainer(): Инстанцирует тренажер, объединяющий настроенную модель LoRA, подготовленный набор данных, токенизатор и аргументы для обучения, определенные вSFTConfig.train_on_responses_only(): Утилитная функция (частьtrlи совместима с Unsloth), которая изменяет расчет потерь тренера. Она устанавливает, что потери будут вычисляться только на лексемах, соответствующих ожидаемому ответу модели(<start_of_turn>modeln...), игнорируя лексемы подсказки пользователя(<start_of_turn>usern...). Это необходимо для того, чтобы научить модель генерировать релевантные ответы, а не просто повторять или дополнять вводимую подсказку. Мы приводим точные префиксы строк, используемые в шаблоне чата для разграничения этих разделов.
Шаг 6: Обучение модели
Когда все готово, мы можем приступить к тонкой настройке. Метод trainer.train() выполняет цикл обучения на основе конфигураций, заданных в SFTConfig.
# Optional: clear CUDA cache before training
torch.cuda.empty_cache()
print("Starting training...")
# Use mixed precision training for efficiency
# Unsloth automatically handles float16/bf16 based on GPU capabilities and model
with torch.amp.autocast(device_type="cuda", dtype=torch.float16): # Or torch.bfloat16 if supported
trainer.train()
print("Training finished.")Тренер будет выводить информацию о ходе обучения, включая потери при обучении. Вы должны наблюдать, как убыток уменьшается с каждым шагом, что указывает на то, что модель обучается на данных. Общее время обучения зависит от размера набора данных, размера модели, гиперпараметров и конкретного используемого GPU. Для нашего примера набора данных и модели 4B на GPU T4 обучение на 200 шагов должно завершиться относительно быстро (например, менее 15-30 минут, в зависимости от точных настроек и объема данных).
Шаг 7: Проверка уточненной модели (вывод)
После обучения давайте протестируем нашу отлаженную модель и посмотрим, насколько хорошо она отвечает на вопросы, основанные на данных об отзывах Trustpilot, на которых она была обучена. Мы будем использовать метод model.generate с TextStreamer для получения более интерактивного результата.
from transformers import TextStreamer
# Define some test questions related to the dataset content
questions = [
"What are common issues or complaints mentioned in the reviews?",
"What do customers like most about the product/service?",
"How is the customer support perceived?",
"Are there any recurring themes regarding pricing or value?"
# Add more questions here based on your dataset content
]
# Set up a streamer for real-time output
# skip_prompt=True prevents printing the input prompt again
# skip_special_tokens=True removes chat template tokens from output
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
print("n--- Testing Fine-Tuned Model ---")
# Iterate through questions and generate answers
for idx, q in enumerate(questions, start=1):
# Build the conversation prompt in the correct Gemma 3 chat format
conv = [{"role": "user", "content": q}]
# Apply the chat template and add the generation prompt token
# add_generation_prompt=True includes the <start_of_turn>model tag
prompt = tokenizer.apply_chat_template(
conv,
add_generation_prompt=True,
tokenize=False
)
# Tokenize the prompt and move to GPU
inputs = tokenizer([prompt], return_tensors="pt", padding=True).to("cuda")
# Display the question
print(f"n=== Question {idx}: {q}n")
# Generate the response with streaming
# Pass the tokenized inputs directly to model.generate
_ = model.generate(
**inputs,
streamer=streamer, # Use the streamer for token-by-token output
max_new_tokens=256, # Limit the response length
temperature=0.7, # Control randomness (lower=more deterministic)
top_p=0.95, # Nucleus sampling
top_k=64, # Top-k sampling
use_cache=True, # Use cache for faster generation
# Add stopping criteria if needed, e.g., stopping after <end_of_turn>
# eos_token_id=tokenizer.eos_token_id,
)
# Add a separator after each answer
print("n" + "="*40)
print("n--- Testing Complete ---")Ответы модели смотрите на изображении ниже:

🔥 Отлично, все работает!
Успешный процесс тонкой настройки означает, что модель генерирует ответы, которые являются более аналитическими и непосредственно вытекают из содержания отзывов, на которых она была настроена, отражая стиль и понимание, присутствующие в вашем пользовательском наборе данных, а не общие ответы.
Шаг 8: Сохранение и продвижение отлаженной модели
Наконец, сохраните настроенные адаптеры LoRA и токенизатор. Вы можете сохранить их локально, а также отправить в Hugging Face Hub для удобства обмена, версионирования и развертывания.
# Define local path and Hub repository ID
new_model_local = "gemma-3-4b-trustpilot-qa-adapter" # Local directory name
new_model_online = "YOUR_HF_USERNAME/gemma-3-4b-trustpilot-qa" # Hub repo name
# 1. Save locally
print(f"Saving model adapter and tokenizer locally to '{new_model_local}'...")
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
print("Saved locally.")
# 2. Push to Hugging Face Hub
print(f"Pushing model adapter and tokenizer to Hugging Face Hub '{new_model_online}'...")
model.push_to_hub(new_model_online, token=hf_token)
tokenizer.push_to_hub(new_model_online, token=hf_token)Доработанная модель теперь доступна на Hugging Face Hub:

Заключение
Это руководство демонстрирует сквозной подход к тонкой настройке Gemma 3 от Google для практического случая: генерации аналитических ответов на основе отзывов покупателей. Мы рассмотрели весь рабочий процесс – от сбора высококачественных, специфичных для конкретной области данных с помощью API веб-скрепера Bright Data, структурирования их в формат QA с помощью обработки на базе LLM до тонкой настройки модели Gemma 3 4B с помощью библиотеки Unsloth на ограниченном по ресурсам оборудовании.
В результате получается специализированный LLM, умеющий извлекать идеи и интерпретировать настроения из необработанных данных обзоров, преобразуя их в структурированные ответы, пригодные к действию. Этот метод хорошо поддается адаптации – вы можете применить тот же рабочий процесс для тонкой настройки Gemma 3 (или других подходящих LLM) на различных наборах данных, специфичных для конкретной области, чтобы создать ИИ-помощников, адаптированных к различным потребностям.
Для дальнейшего изучения стратегий извлечения данных с помощью искусственного интеллекта обратите внимание на эти дополнительные ресурсы:
- Веб-скраппинг с помощью LLaMA 3
- Веб-скраппинг с помощью серверов MCP
- Скраппинг на основе искусственного интеллекта с помощью LLM-Scraper
- ScrapeGraphAI для веб-скрапинга LLM
Более подробную информацию об оптимизации и примеры использования Unsloth можно найти в коллекции блокнотов Unsloth.





