
В этом уроке вы узнаете:
- Что такое Cursor и почему он стал таким популярным.
- Основные причины для добавления в Cursor MCP-сервера, такого как сервер Bright Data.
- Как подключить Cursor к Bright Data Web MCP.
- Как добиться тех же результатов в Visual Studio Code.
Давайте погрузимся!
Что такое Cursor?
Cursor – это редактор кода на базе ИИ, созданный как форк Visual Studio Code. Его основной функцией, как и любого другого текстового редактора, является предоставление интерфейса для написания кода. Однако его особенностью является встроенная глубокая интеграция ИИ.
Вместо базового автозаполнения Cursor использует LLms, чтобы понять всю вашу кодовую базу и контекст. Это позволяет ему предоставлять такие интеллектуальные функции, как:
- Разговорные подсказки: Опишите, что вам нужно, на простом английском языке, и Cursor напишет или отредактирует код за вас.
- Многострочный автозаполнитель: Он предлагает и завершает целые блоки кода, а не только отдельные строки.
- Рефакторинг, управляемый ИИ: Cursor может интеллектуально оптимизировать, очищать и исправлять ваш код, основываясь на контексте всего проекта.
- Помощь в отладке: Попросите ИИ найти и объяснить ошибки в вашем коде.
Cursor превращает обычный редактор кода в проактивного, высокоинтеллектуального парного программиста. Он поддерживает множество LLM от различных поставщиков и включает встроенную поддержку инструментов через MCP.
Зачем добавлять Web MCP от Bright Data в Cursor
За кулисами Cursor опирается на известные модели LLM. Хотя его интеграция более глубокая и отточенная, чем у большинства инструментов, он все равно сталкивается с тем же основным ограничением, что и любой LLM: знания ИИ статичны!
В конце концов, данные для обучения ИИ отражают моментальный снимок во времени. Это быстро устаревает, особенно в таких быстро развивающихся областях, как разработка программного обеспечения. А теперь представьте, что агент ИИ Cursor может:
- получать последние учебники и документацию по рабочим процессам RAG,
- обращаться к живым руководствам во время написания кода и
- просматривать веб-сайты в режиме реального времени с той же легкостью, с какой он может перемещаться по локальным файлам.
Именно это вы получаете, подключая Cursor к Web MCP от Bright Data!
Web MCP предлагает доступ к 60+ инструментам для ИИ, созданным для взаимодействия с веб-сайтами в режиме реального времени и сбора данных. Все они работают на основе богатой инфраструктуры ИИ Bright Data.
Даже на бесплатном уровне ваш агент Cursor уже может получить доступ к двум мощным инструментам:
| Инструмент | Описание |
|---|---|
search_engine |
Получение результатов поиска из Google, Bing или Yandex в формате JSON или Markdown. |
scrape_as_markdown |
Соскребает любую веб-страницу в чистый формат Markdown, минуя обнаружение ботов и CAPTCHA. |
Помимо этого, Web MCP включает инструменты для автоматизации облачных браузеров и получения структурированных данных с таких платформ, как Amazon, YouTube, LinkedIn, TikTok, Google Maps и многих других.
Вот лишь несколько примеров того, что становится возможным при расширении Cursor с помощью Web MCP от Bright Data:
- Получение последних ссылок на API или учебники по фреймворкам, а затем автоматическая генерация рабочего кода или проектных лесов.
- Мгновенно получайте актуальные результаты поисковых систем и вставляйте их в документацию или комментарии к коду.
- Собирайте живые веб-данные для создания реалистичных тестовых макетов, аналитических панелей или автоматизированных конвейеров контента.
Чтобы изучить весь спектр возможностей, ознакомьтесь с документацией Bright Data MCP.
Как интегрировать Web MCP в Cursor для улучшения опыта кодирования ИИ
В этом пошаговом разделе вы увидите, как подключить локальный серверный экземпляр Bright Data Web MCP к Cursor. Такая настройка позволяет расширить возможности ИИ с помощью более 60 инструментов, доступных непосредственно в вашей IDE.
В деталях мы используем инструменты Web MCP для создания бэкенда Express с имитированным API, который возвращает реальные данные с Amazon. Это лишь один пример из множества вариантов использования, поддерживаемых этой интеграцией.
Следуйте инструкциям ниже!
Предварительные условия
Чтобы следовать этому руководству, убедитесь, что у вас есть:
- Учетная запись Cursor (достаточно тарифного плана Free).
- Учетная запись Bright Data с активным ключом API.
Не беспокойтесь о настройке Bright Data прямо сейчас. Вы будете проходить этот процесс по ходу статьи!
Базовое понимание того, как функционирует MCP, как работает Cursor и инструменты, предоставляемые Web MCP, также будут полезны.
Шаг № 1: Начало работы с Cursor
Установите версию Cursor для вашей операционной системы, откройте ее и войдите в систему под своей учетной записью.
Если вы запускаете приложение впервые, завершите работу мастера настройки.
После этого вы должны увидеть что-то вроде этого:
Отлично! Теперь откройте папку с проектом и приготовьтесь использовать встроенный агент кодирования ИИ, расширенный с помощью Web MCP.
Шаг №2: Настройте ваш LLM
На данный момент Cursor использует модель Claude 4.5 по умолчанию (в режиме “Авто”). Если вас это устраивает, переходите к следующему разделу. Помните, что Claude также может быть интегрирован с Web MCP.
Если вы хотите изменить модель по умолчанию, найдите “Настройки курсора” и выберите эквивалентную опцию:
В открывшейся вкладке перейдите на вкладку “Модели”:
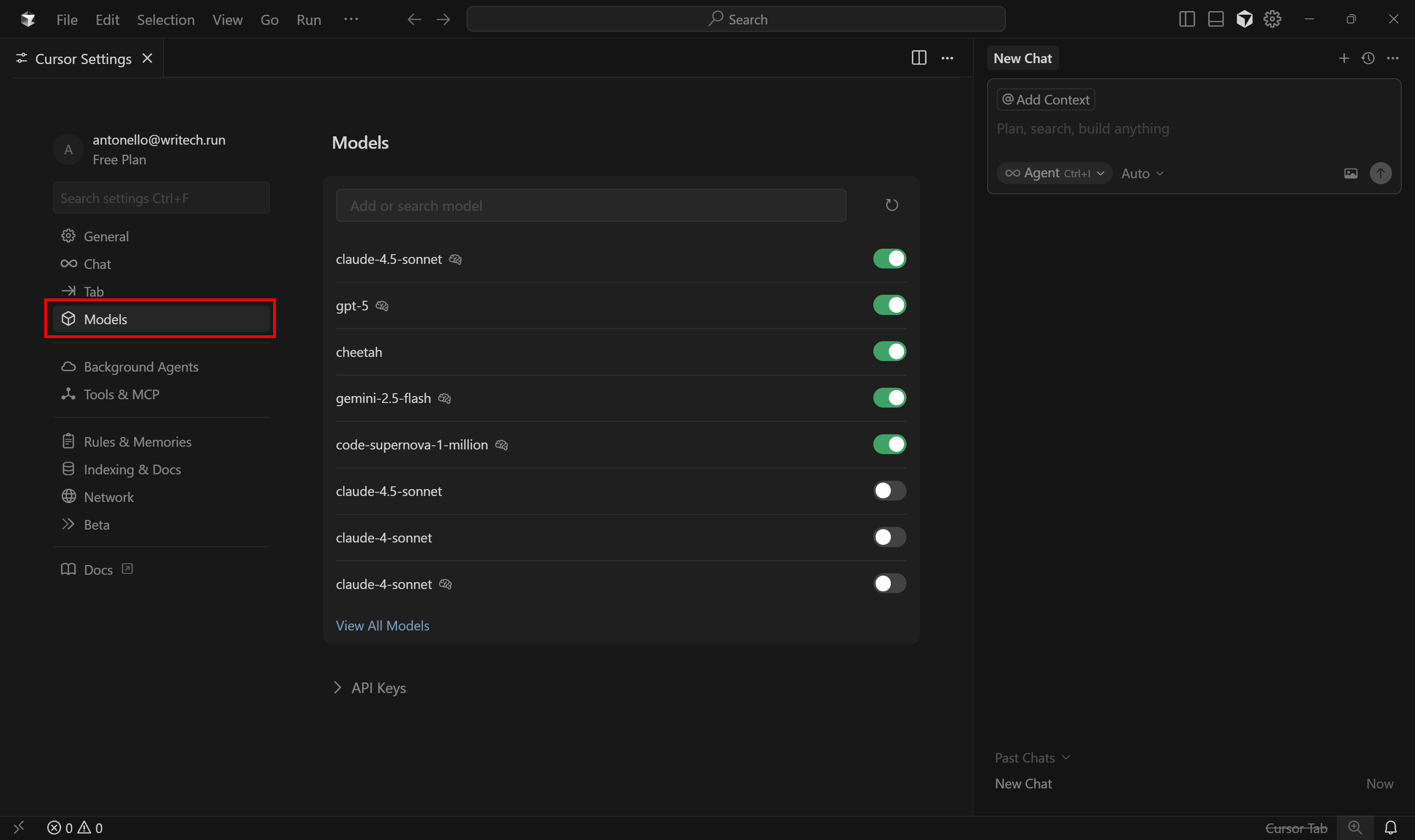
Здесь вы можете настроить, какой ИИ должен использовать агент LLM Cursor. Помните, что бесплатные пользователи могут выбрать только GPT-4.1 и “Авто” в качестве премиум-моделей.
Чтобы изменить модель на GTP 4.1, выполните поиск по слову “gpt”, найдите модель “gpt-4.1” и включите ее:
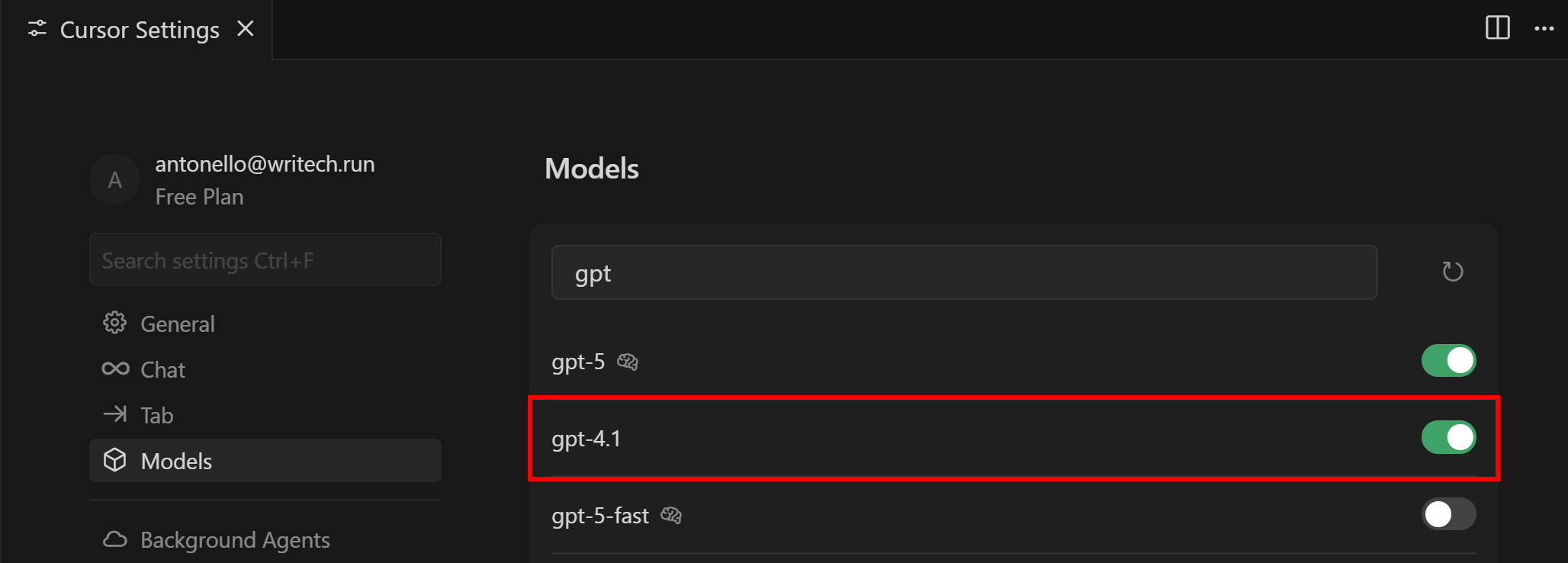
Если у вас есть подписка Pro или Business, вы можете включить любые другие поддерживаемые LLM. Кроме того, вы можете указать собственный ключ API для выбранного провайдера.
Далее откройте панель “Новый чат” справа. Нажмите на выпадающий список “Авто”, отключите его и выберите опцию “gpt-4.1”:
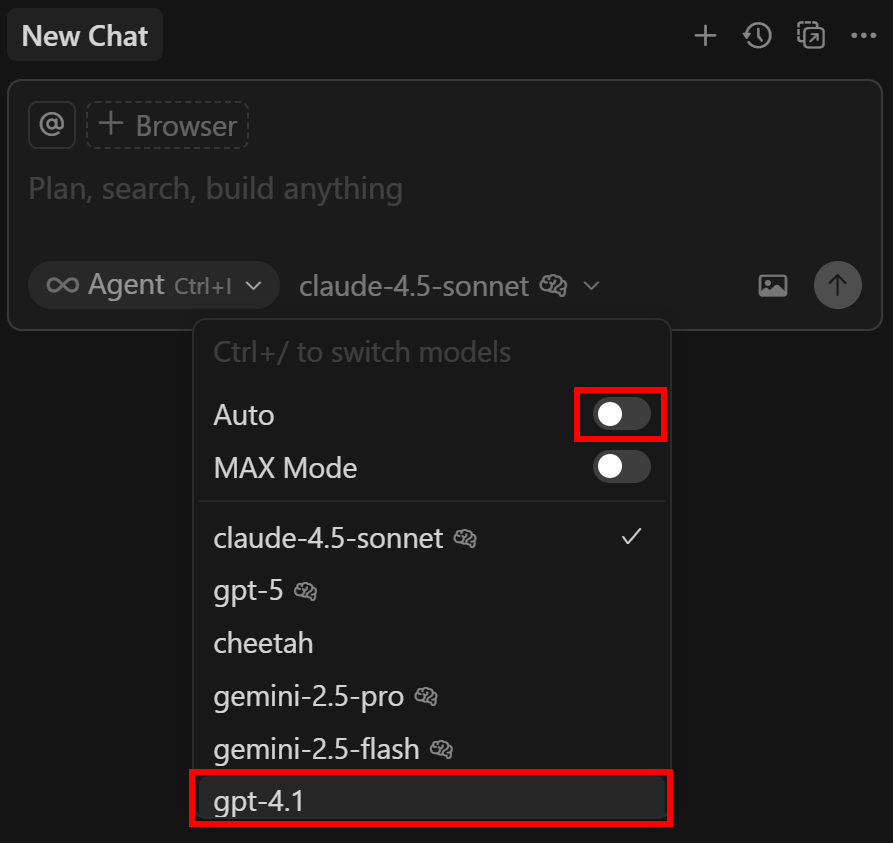
Готово! Теперь Cursor работает через настроенный вами LLM.
Шаг № 3: Протестируйте Web MCP от Bright Data на своей машине
Прежде чем подключать Cursor к Web MCP Bright Data, убедитесь, что вы действительно можете запустить сервер локально. Это необходимо, поскольку сервер MCP будет настроен через STDIO.
Начните с регистрации в Bright Data. В противном случае, если у вас уже есть учетная запись, просто войдите в нее. Для быстрой настройки следуйте инструкциям в разделе “MCP” на панели управления:
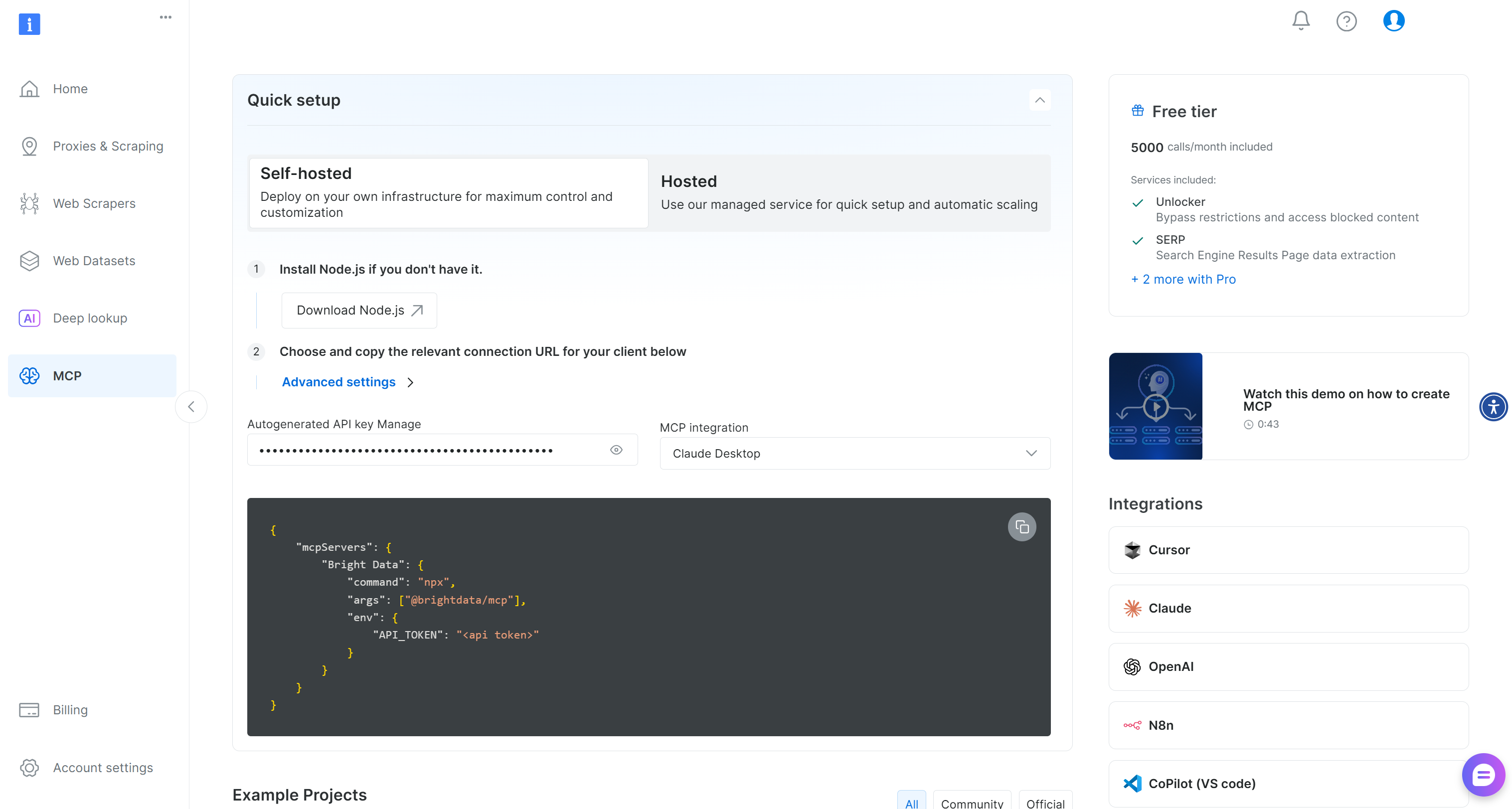
Для получения более подробной информации см. инструкции ниже.
Сначала сгенерируйте свой ключ API Bright Data и сохраните его в надежном месте. Он понадобится вам на следующем этапе. Мы предположим, что ваш API-ключ имеет права администратора, так как это упрощает интеграцию Web MCP.
Теперь установите Web MCP глобально на вашу машину с помощью этой команды npm:
npm install -g @brightdata/mcpУбедитесь, что MCP-сервер работает, запустив его:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" npx -y @brightdata/mcpИли, эквивалентно, в PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"; npx -y @brightdata/mcpЗамените место <YOUR_BRIGHT_DATA_API> своим API-токеном Bright Data. Эти команды устанавливают необходимую переменную окружения API_TOKEN и запускают Web MCP локально через пакет @brightdata/mcp.
В случае успеха вы должны увидеть вывод, подобный этому:

При первом запуске Web MCP создает две зоны по умолчанию в вашей учетной записи Bright Data:
mcp_unlocker: Зона для Web Unlocker.mcp_browser: Зона для Browser API.
Web MCP полагается на эти два сервиса Bright Data для работы своих 60+ инструментов.
Если вы хотите проверить, что эти зоны были настроены, зайдите на страницу “Прокси и Скрейпинг-инфраструктура” в своем аккаунте Bright Data. Вы должны заметить две зоны в таблице:
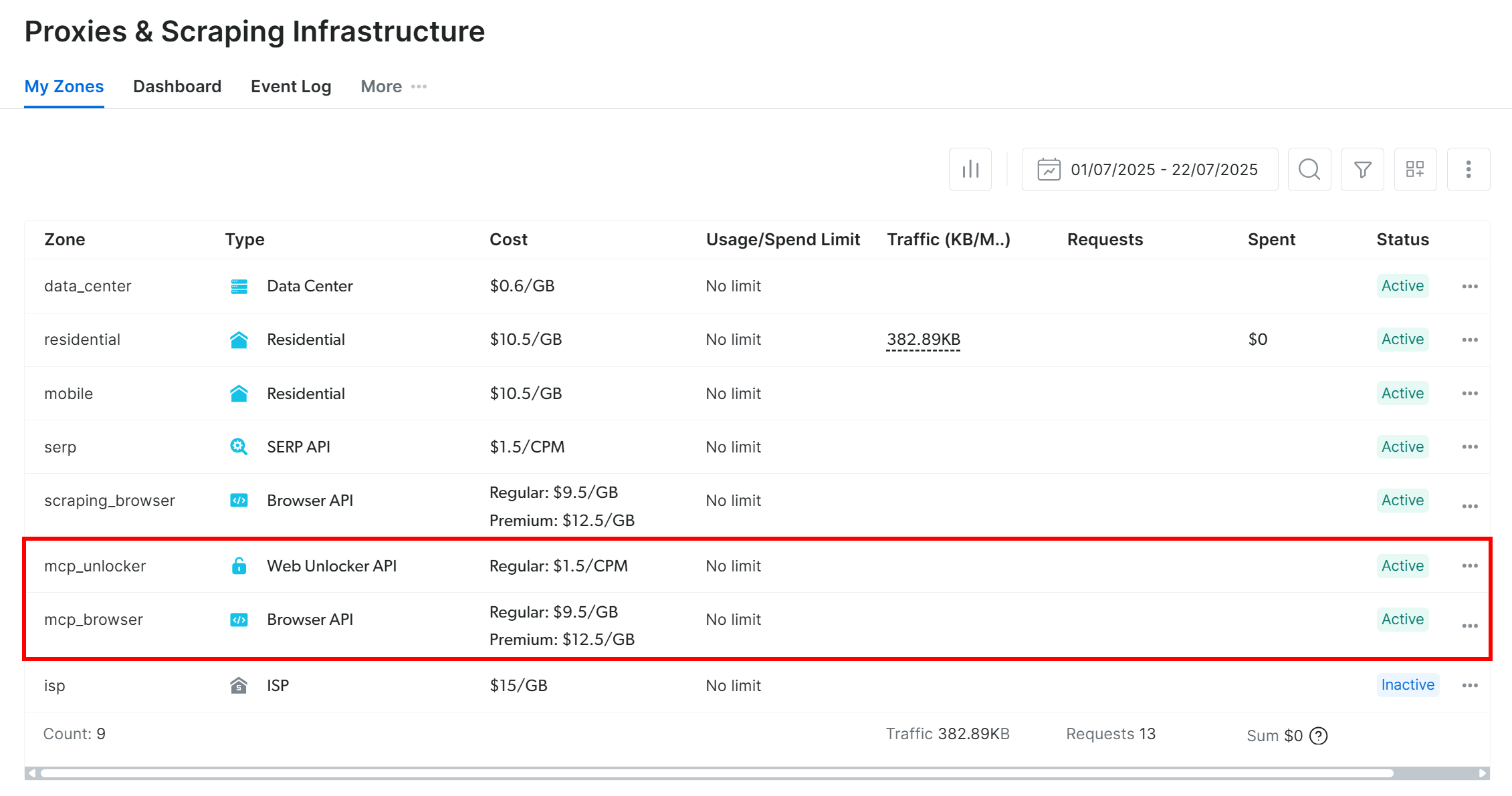
Примечание: Если ваш API-токен не имеет прав администратора, эти две зоны не будут созданы автоматически. В этом случае определите их вручную и задайте через переменные окружения, как описано на GitHub.
Помните, что на бесплатном уровне Web MCP открывает только инструменты search_engine и scrape_as_markdown (и их пакетные версии). Чтобы разблокировать все остальные инструменты, включите режим Pro **, установив переменную окружения PRO_MODE="true":
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpИли, в Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpРежим Pro открывает все 60+ инструментов, но он не включен в бесплатный уровень, а значит, за него придется платить дополнительно.
Потрясающе! Вы только что убедились, что веб-сервер MCP работает локально. Завершите процесс MCP, поскольку вы собираетесь настроить Cursor на его запуск и подключение к нему.
Шаг #4: Настройка Web MCP в Cursor
Начните с поиска “>mcp” и выберите опцию “Вид: Открыть настройки MCP”:
В разделе “Инструменты и MCP” нажмите кнопку “Добавить пользовательский MCP”:
В результате откроется следующий файл конфигурации mcp.json:
Как видите, по умолчанию он пуст. Для интеграции Web MCP от Bright Data заполните его следующим образом:
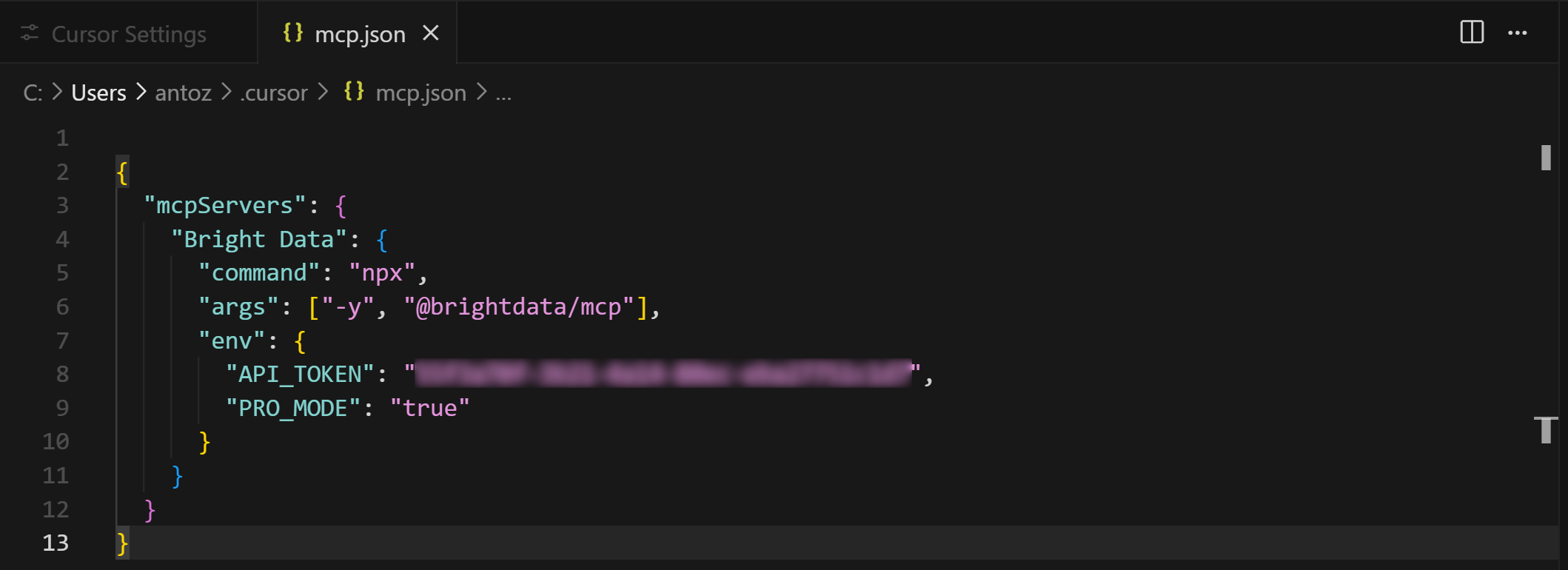
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<ВАШ_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}Затем сохраните файл с помощью Ctrl + S (или Cmd + S на macOS):
Приведенная выше конфигурация повторяет команду npx, которую мы тестировали ранее, используя переменные окружения для передачи учетных данных и настроек:
- Требуется
API_TOKEN. Установите его на ключ API Bright Data, который вы сгенерировали ранее. PRO_MODEявляется необязательной. Удалите его, если вы не собираетесь включать режим Pro.
Другими словами, Cursor будет использовать конфигурацию в mcp.json для выполнения команды npx, показанной ранее. Он запустит локальный процесс Web MCP, подключится к нему и получит доступ к открытым инструментам.
Закройте вкладку mcp.json, поскольку интеграция Cursor + Bright Data Web MCP завершена!
Примечание: Если вы предпочитаете не использовать STDIO и хотите использовать SSE или потоковый HTTP, имейте в виду, что Bright Data Web MCP также предоставляет возможность удаленного сервера.
Шаг № 5: Проверка доступности инструмента из интеграции MCP
Пришло время проверить, успешно ли Cursor подключился к серверу Web MCP и может ли он получить доступ ко всем своим инструментам.
Для этого вернитесь в раздел “Инструменты и MCP” на вкладке “Настройки Cursor”. Теперь вы должны увидеть настроенную опцию “Яркие данные”, в которой перечислены все доступные инструменты:
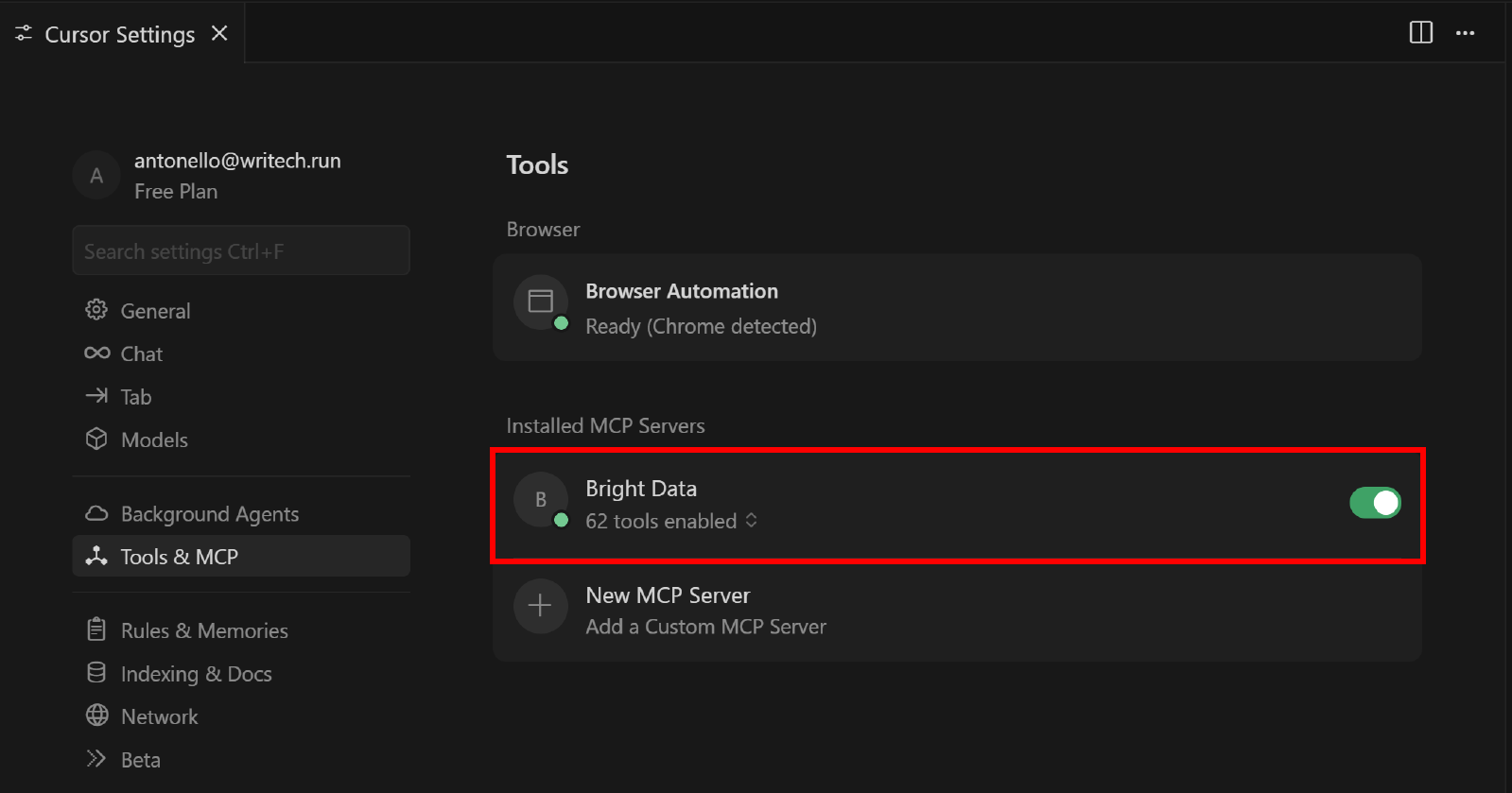
Разверните выпадающий список “N включенных инструментов” (где N – количество включенных инструментов), чтобы просмотреть все доступные инструменты:
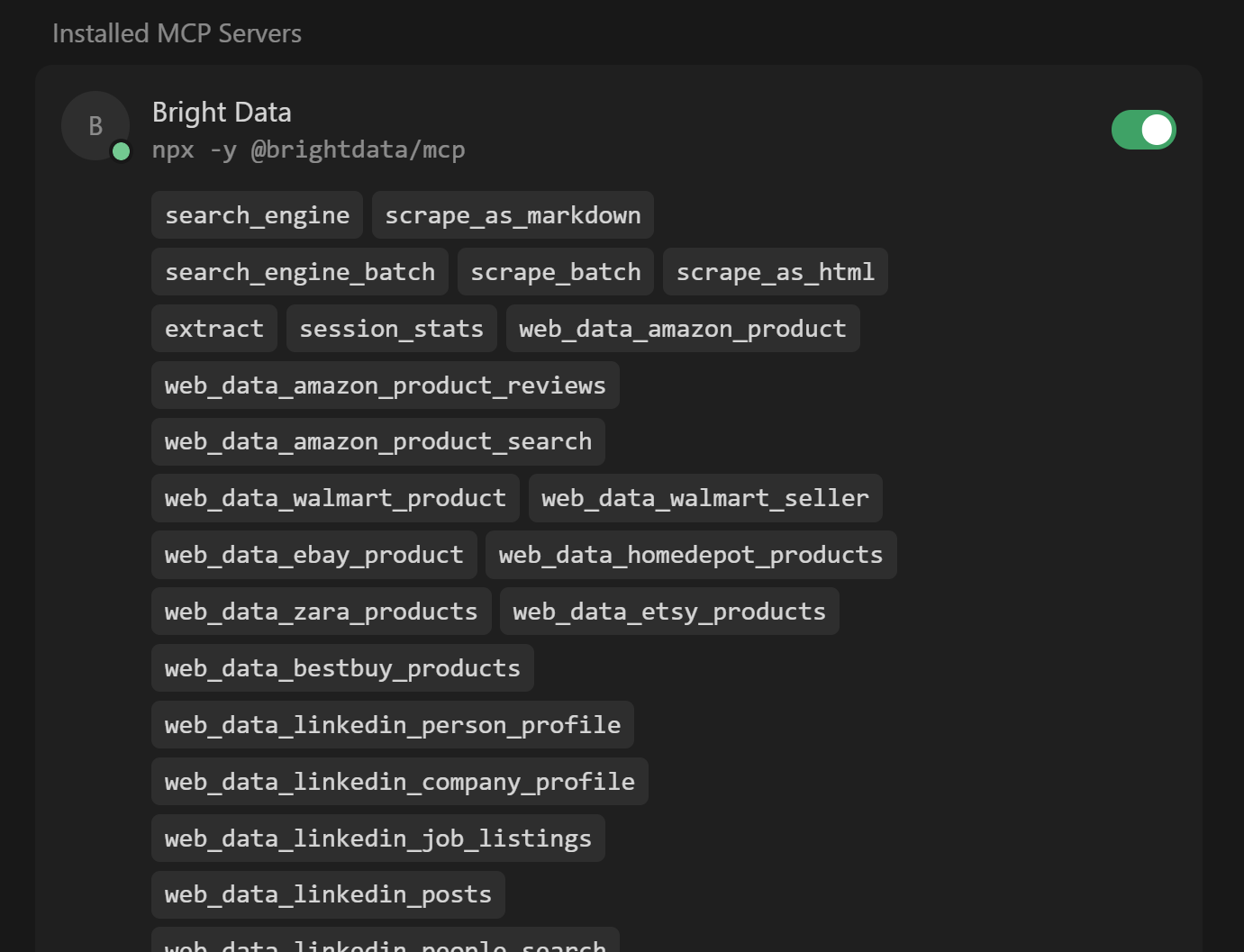
Обратите внимание, что Cursor автоматически подключается к серверу и извлекает 60 с лишним инструментов.
Если Pro Mode отключен, вы увидите только 4/5 бесплатных инструментов. Здесь вы также можете активировать или деактивировать инструменты по своему усмотрению. По умолчанию все они активированы.
После подтверждения закройте вкладку “Настройки курсора”. Приготовьтесь воспользоваться этими инструментами для расширенного опыта кодирования с помощью ИИ!
Шаг № 6: Запуск задачи с помощью усовершенствованного агента кодирования ИИ
Чтобы проверить возможности агента кодирования Cursor, вам понадобится задание, в котором будут задействованы только что настроенные функции получения веб-данных.
Например, предположим, что вы создаете бэкэнд на Express.js для приложения электронной коммерции. Вы хотите поиздеваться над API, который возвращает данные о реальных товарах Amazon.
Добейтесь этого с помощью такой подсказки:
Соскребите данные со следующих товаров Amazon:
1. https://www.amazon.com/Clean-Skin-Club-Disposable-Sensitive/dp/B07PBXXNCY/
2. https://www.amazon.com/Neutrogena-Cleansing-Towelettes-Waterproof-Alcohol-Free/dp/B00U2VQZDS/
3. https://www.amazon.com/Medicube-Zero-Pore-Pads-Dual-Textured/dp/B09V7Z4TJG/
Затем сохраните собранные данные в локальный JSON-файл. Затем создайте простой проект Express.js с конечной точкой, которая принимает ASIN (представляющий продукт Amazon) и возвращает соответствующие данные, считанные из файла JSON.Предположим, что вы работаете в режиме Pro. Выполните приведенное выше приглашение в Курсоре.
Вот что произошло дальше, шаг за шагом:
- LLM, настроенный в Cursor, определяет
web_data_amazon_productкак инструмент для получения данных о продуктах Amazon. - Для каждого из трех продуктов Amazon в подсказке запрашивается разрешение на запуск
web_data_amazon_productдля получения данных. - Вы предоставляете разрешение для каждого инструмента, запуская асинхронные задачи сбора данных (которые под капотом вызывают Bright Data Amazon Скрапер).
- Полученные данные для каждого продукта отображаются в формате JSON.
- GPT-4.1 обрабатывает полученные данные и заполняет ими файл
products.json. - Cursor создает структуру проекта npm, определяя
package.json, и файлindex.jsс логикой сервера Express. - У вас запросят разрешение на установку зависимостей проекта через
npm install. В результате появится файлpackage.jsonв папкеnode_modules/. - Запрашивается разрешение на запуск сервера с помощью
npm start.
Примечание: Даже если это не было явно указано в подсказке, GPT-4.1 также решил спросить об установке зависимостей проекта и настройке сервера. Это было приятное дополнение!
В этом примере итоговый результат будет иметь следующую структуру проекта:
your-project/
├──── node_modules/
├──── index.js
├──── package.json
├──── package-lock.json
└── products.jsonОтлично! Давайте проверим результат, чтобы убедиться, что он достиг поставленной цели.
Шаг № 7: Изучите выходной проект
По мере того как агент кодирования ИИ создавал файлы, они появлялись в левой колонке Cursor.
Отказ от ответственности: ваши файлы могут отличаться от тех, что показаны ниже, поскольку разные прогоны ИИ могут давать разные результаты.
Начните с изучения файла products.json:
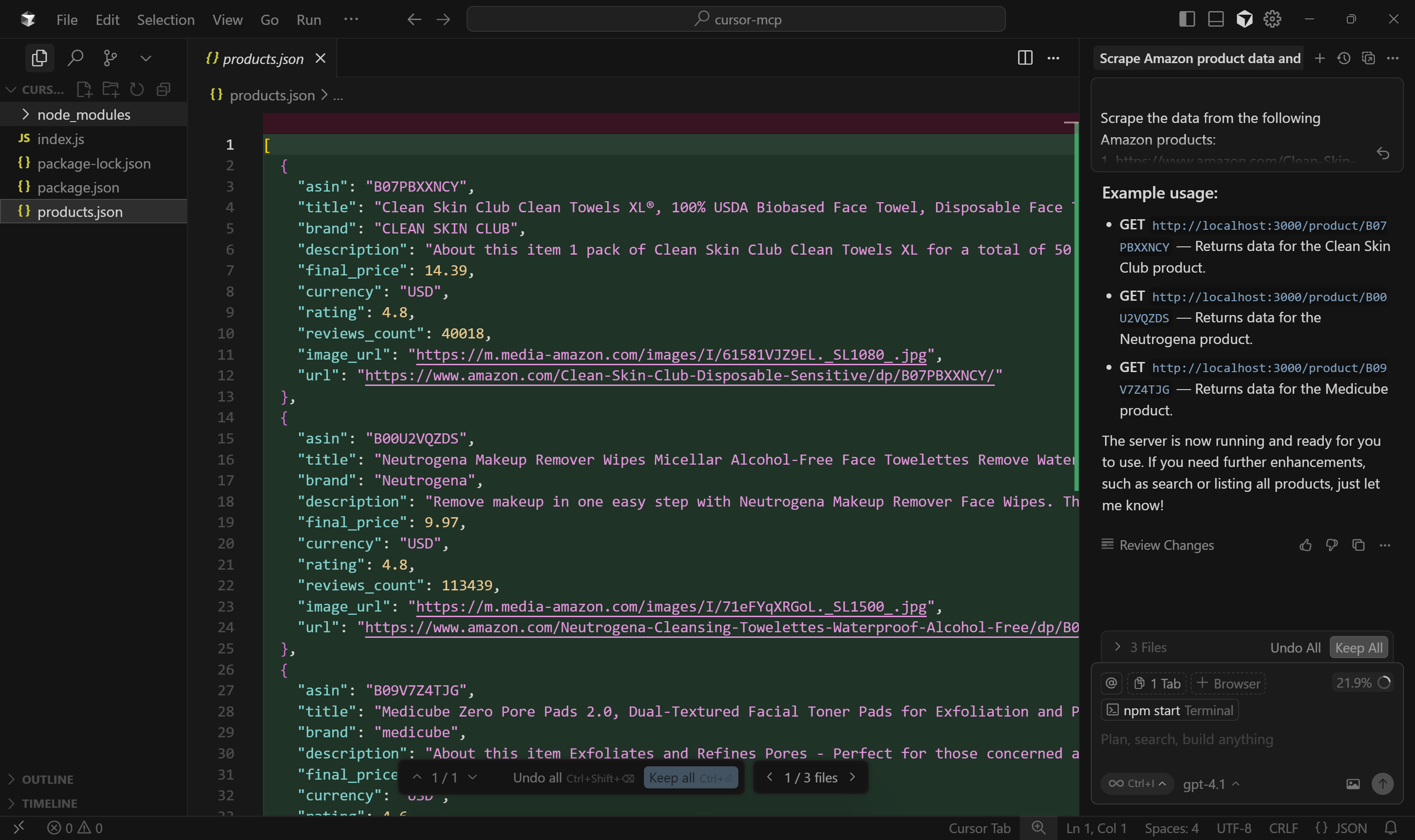
Как вы можете видеть, он содержит упрощенную версию данных, полученных инструментом web_data_amazon_product:
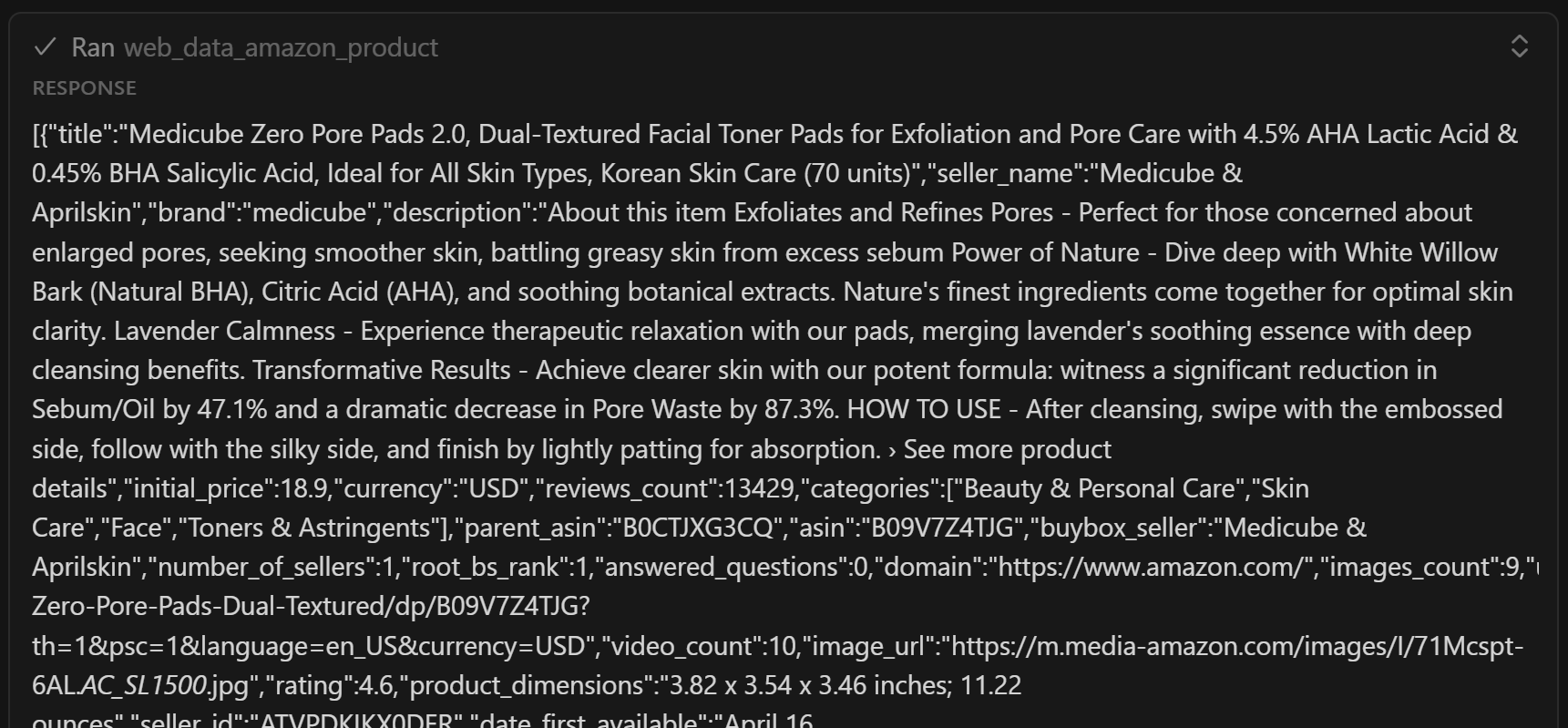
Важно: web_data_amazon_product на самом деле возвращает все данные о товаре со страницы Amazon, а не только несколько полей. Тем не менее, ИИ решил включить только самые важные поля. При некоторой оптимизации запроса вы можете указать ИИ включать все поля, если хотите.
Далее откройте index.js, чтобы увидеть серверную логику Express.js:
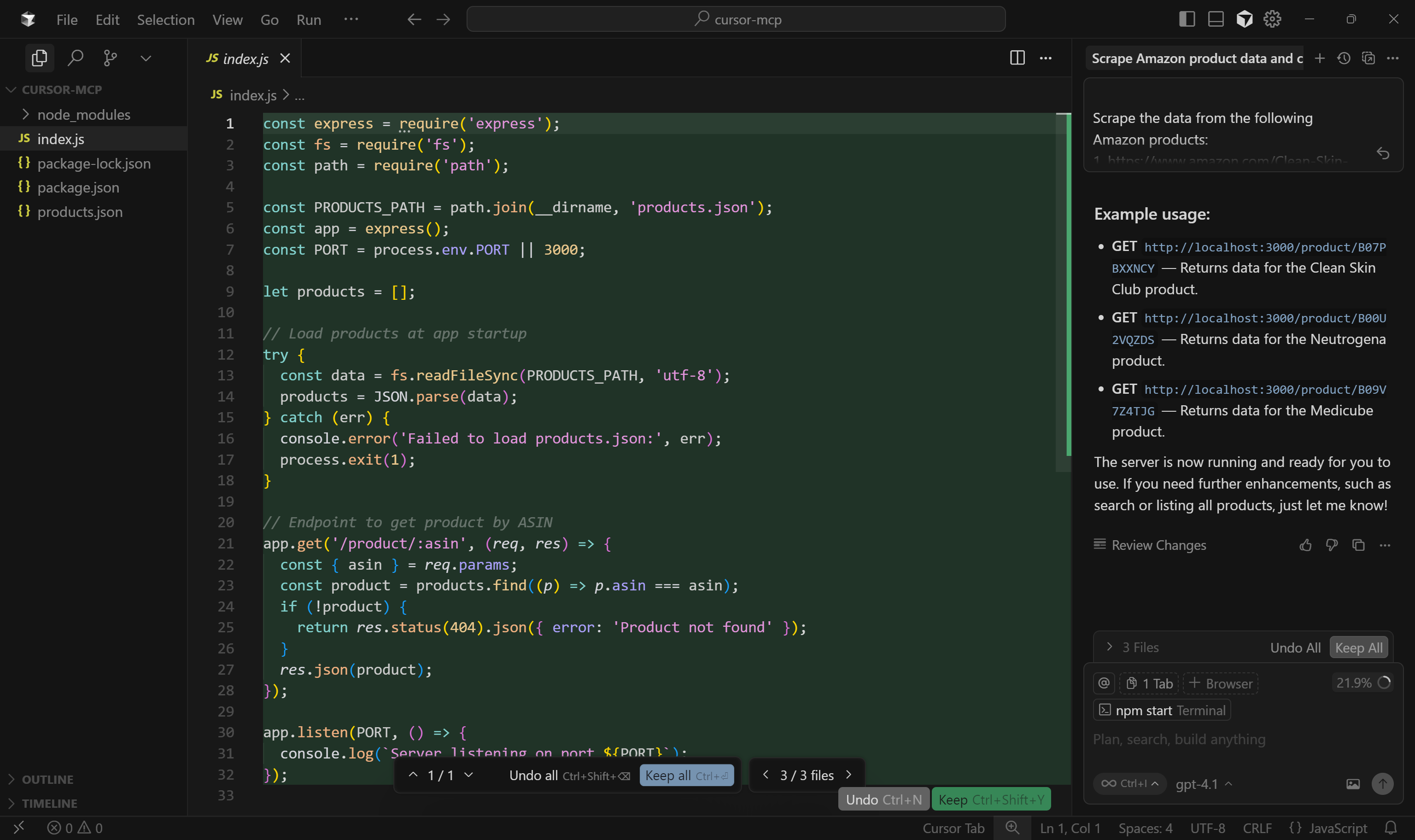
В частности, имитируемая конечная точка для получения данных о товаре использует путь /product/:asin.
Продолжите осмотр остальных файлов, но все они должны быть в порядке. Итак, нажмите кнопку “Keep All”, чтобы подтвердить сгенерированный ИИ вывод, и приготовьтесь к тестированию вашего проекта!
Шаг № 8: Тестирование готового проекта
Ваше приложение Express.js уже должно быть запущено, так как GPT-4.1 запросил разрешение на запуск npm start. Если оно не было запущено, вы можете запустить его вручную с помощью:
npm startТеперь ваш бэкенд Express.js должен быть запущен по адресу http://localhost.
Далее выполните следующую команду cURL для проверки конечной точки GET /product/:asin:
curl "http://localhost/ product/B07PBXXNCYГде B07PBXXNCY – это ASIN одного из товаров Amazon, упомянутых в подсказке.
Вы должны увидеть что-то вроде этого:

Замечательно! Эти данные были правильно сгенерированы в файл products.json. Результат соответствует (упрощенной версии) данных с оригинальной страницы Amazon.
Если вы когда-нибудь пытались получить данные о товарах с Amazon, вы знаете, насколько сложной может быть эта задача из-за их пресловутой Amazon CAPTCHA и других мер защиты от ботов. Конечно, один только ванильный GPT-4.1 не может получить данные с Amazon на лету.
Это демонстрирует мощь сочетания Web MCP и Cursor. Итак, это был всего лишь очень простой пример. Однако с помощью 60+ доступных инструментов и правильных подсказок вы сможете работать с более сложными сценариями прямо в вашей IDE!
И вуаля! Бэкенд Express с имитированной конечной точкой API успешно создан благодаря интеграции Cursor + Bright Data Web MCP.
[Дополнительно] Альтернативные подходы в Visual Studio Code
Если вы хотите добиться Cursor-подобного опыта в Visual Studio Code, используйте такие расширения, как Cline или Roo Code.
В частности, для интеграции Web MCP в VS Code обратитесь к этим руководствам:
- Добавление Web MCP от Bright Data в Roo Code в Visual Studio Code
- Веб-скрейпинг в Cline с помощью MCP-сервера Bright Data
Заключение
В этой статье вы узнали, как использовать все преимущества интеграции MCP в Cursor. Агент кодирования ИИ, встроенный в IDE, уже полезен, но он становится гораздо более способным и ресурсоемким после подключения к Web MCP Bright Data.
Эта интеграция дает Cursor возможность выполнять живой веб-поиск, извлекать структурированные данные, потреблять динамические потоки данных и даже автоматизировать взаимодействие с браузером. И все это непосредственно из среды кодирования.
Чтобы построить еще более продвинутые рабочие процессы на базе ИИ, изучите полный набор услуг и решений для работы с данными, доступных в экосистеме ИИ Bright Data.
Создайте бесплатную учетную запись Bright Data сегодня и начните экспериментировать с нашими инструментами для работы с веб-данными, готовыми к ИИ!




