
В этом руководстве вы узнаете:
- Что такое агентная генерация с расширением поиска (RAG) и почему добавление агентных возможностей имеет значение
- Как Bright Data обеспечивает автономный и живой поиск данных в Интернете для систем RAG
- Как обрабатывать и очищать данные, полученные с помощью веб-скраппинга, для создания вложений
- Реализация контроллера агента для организации взаимодействия между векторным поиском и генерацией текста LLM
- Разработка контура обратной связи для сбора информации от пользователей и динамической оптимизации поиска и генерации информации
Давайте погрузимся!
Развитие искусственного интеллекта (ИИ) привело к появлению новых концепций, включая Agentic RAG. Проще говоря, Agentic RAG – это Retrieval Augmented Generation (RAG), в которую интегрированы агенты искусственного интеллекта. Как следует из названия, RAG – это информационно-поисковая система, которая следует линейному процессу: она получает запрос, извлекает релевантную информацию и генерирует ответ.
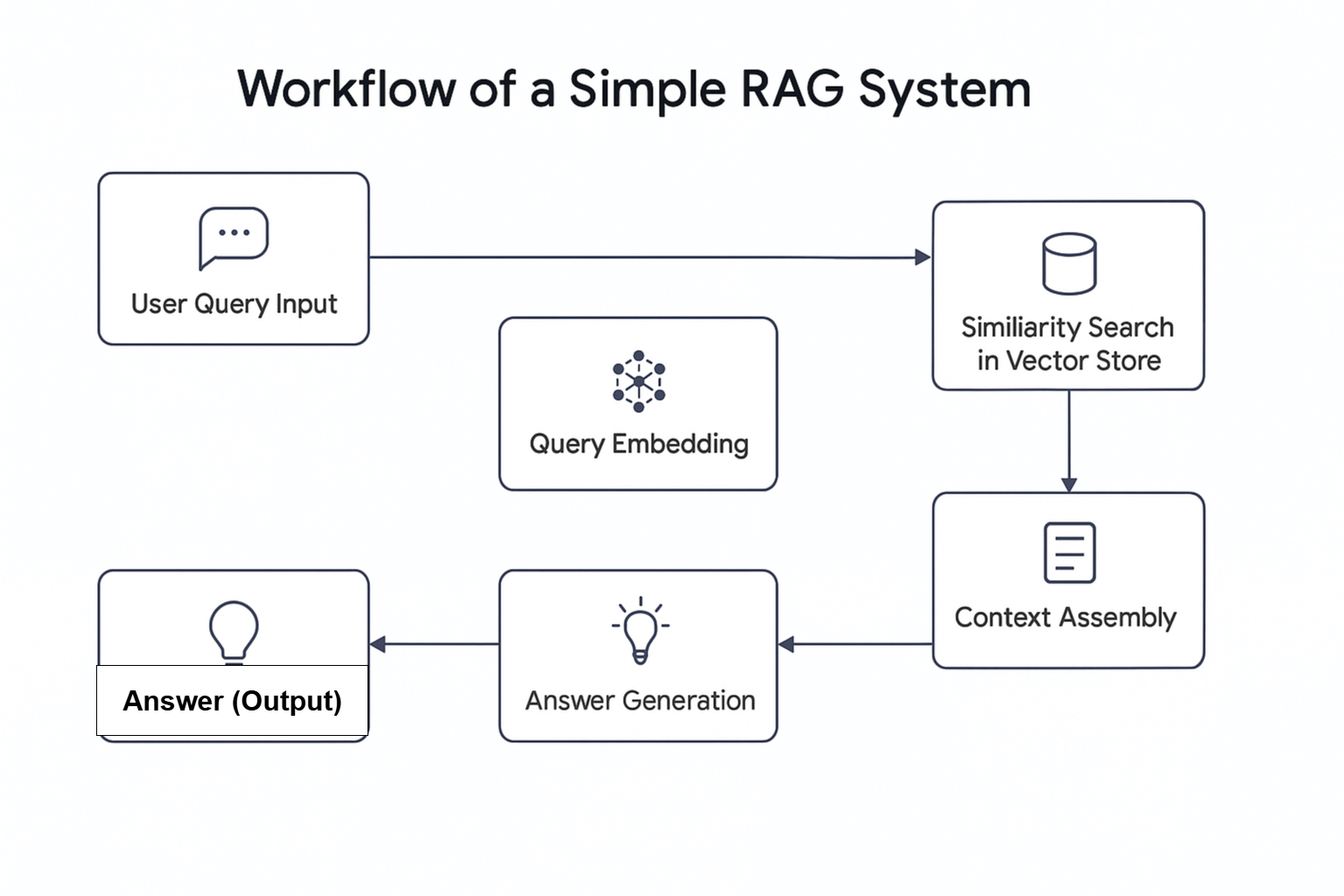
Зачем объединять агентов ИИ с RAG?
Недавнее исследование показало, что почти две трети рабочих процессов, в которых используются агенты искусственного интеллекта, отмечают повышение производительности. Кроме того, около 60 % из них отмечают экономию средств. Таким образом, сочетание агентов искусственного интеллекта с RAG является потенциальной переменой в современных рабочих процессах поиска.
Agentic RAG обладает расширенными возможностями. В отличие от традиционных систем RAG, он может не только получать данные, но и принимать решения о получении информации из внешних источников, например, живых веб-данных, встроенных в базу данных.
В этой статье показано, как построить агентную RAG-систему для поиска новостной информации, используя Bright Data для сбора веб-данных, Pinecone в качестве базы данных векторов, OpenAI для генерации текста и Agno в качестве контроллера агента.
Обзор ярких данных
Независимо от того, получаете ли вы данные из живого потока или используете подготовленные данные из своей базы данных, качество результатов работы системы Agentic RAG зависит от качества получаемых данных. Именно здесь Bright Data становится незаменимым помощником.
Bright Data предоставляет надежные, структурированные и актуальные веб-данные для широкого круга пользователей. С помощью API Web Scraper от Bright Data, который имеет доступ к более чем 120 доменам, веб-скреппинг становится эффективным как никогда. Он справляется с такими распространенными проблемами, как запрет IP-адресов, CAPTCHA, cookies и другие формы обнаружения ботов.
Чтобы начать работу, зарегистрируйтесь в бесплатной пробной версии, затем получите ключ API и идентификатор набора данных для домена, который вы хотите соскрести. Получив их, вы можете приступать к работе.
Ниже описаны шаги по получению свежих данных с такого популярного домена, как BBC News:
- Создайте учетную запись Bright Data, если вы еще этого не сделали. Можно воспользоваться бесплатной пробной версией.
- Перейдите на страницу Web Scrapers. В разделе Библиотека веб-скреперов изучите доступные шаблоны скреперов.
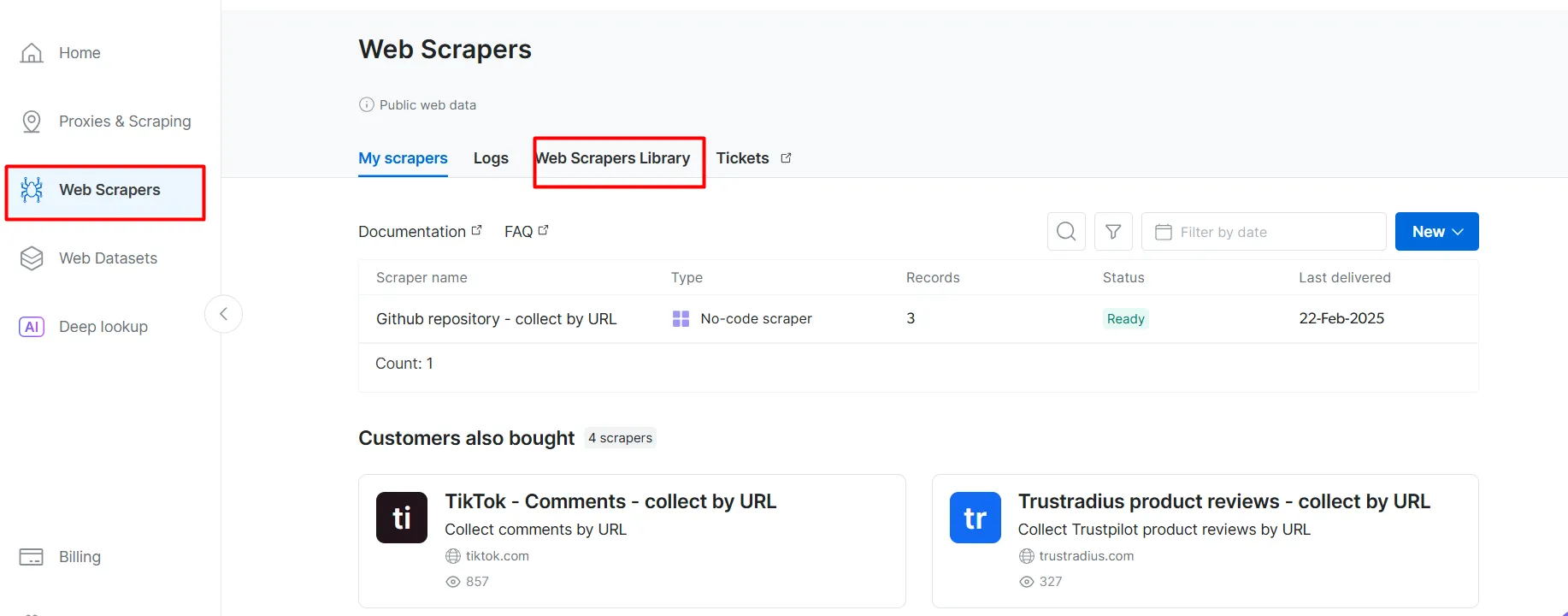
- Найдите целевой домен, например BBC News, и выберите его.
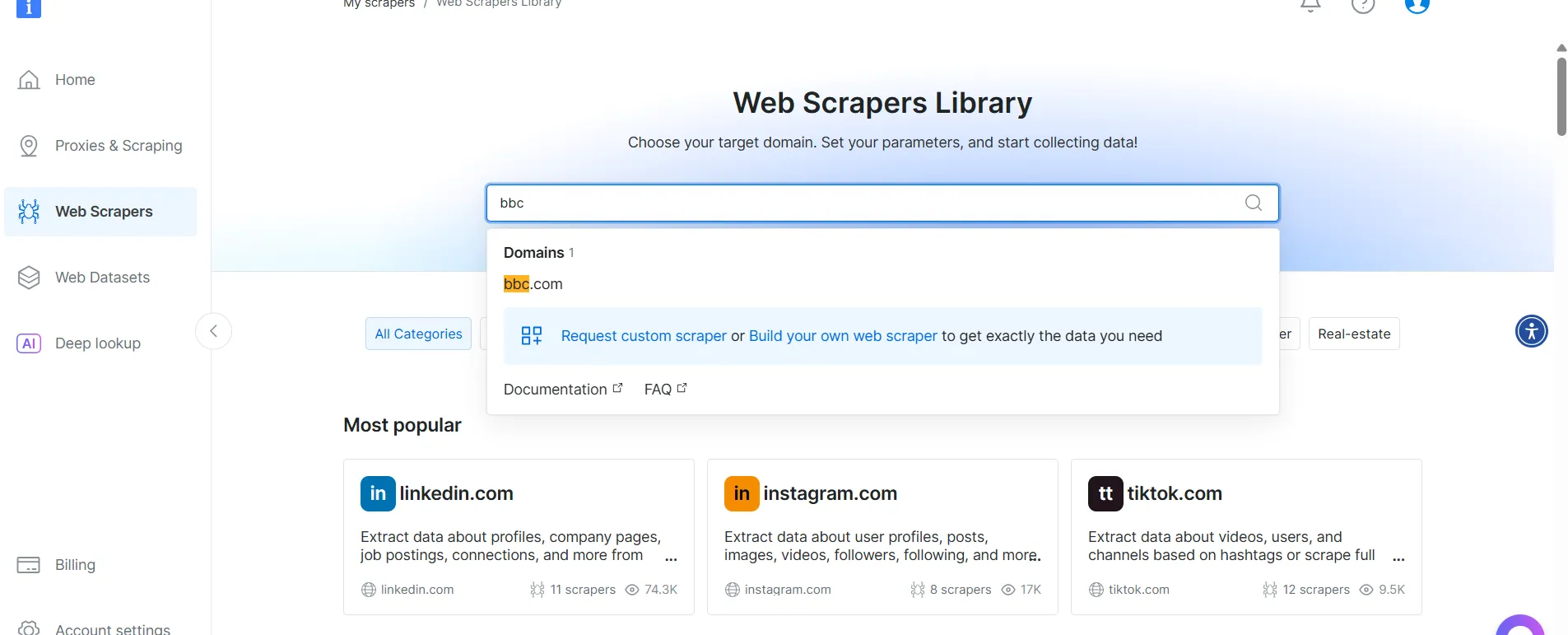
- В списке скреперов BBC News выберите BBC News – собирать по URL. Этот скрепер позволяет получать данные без входа в домен.
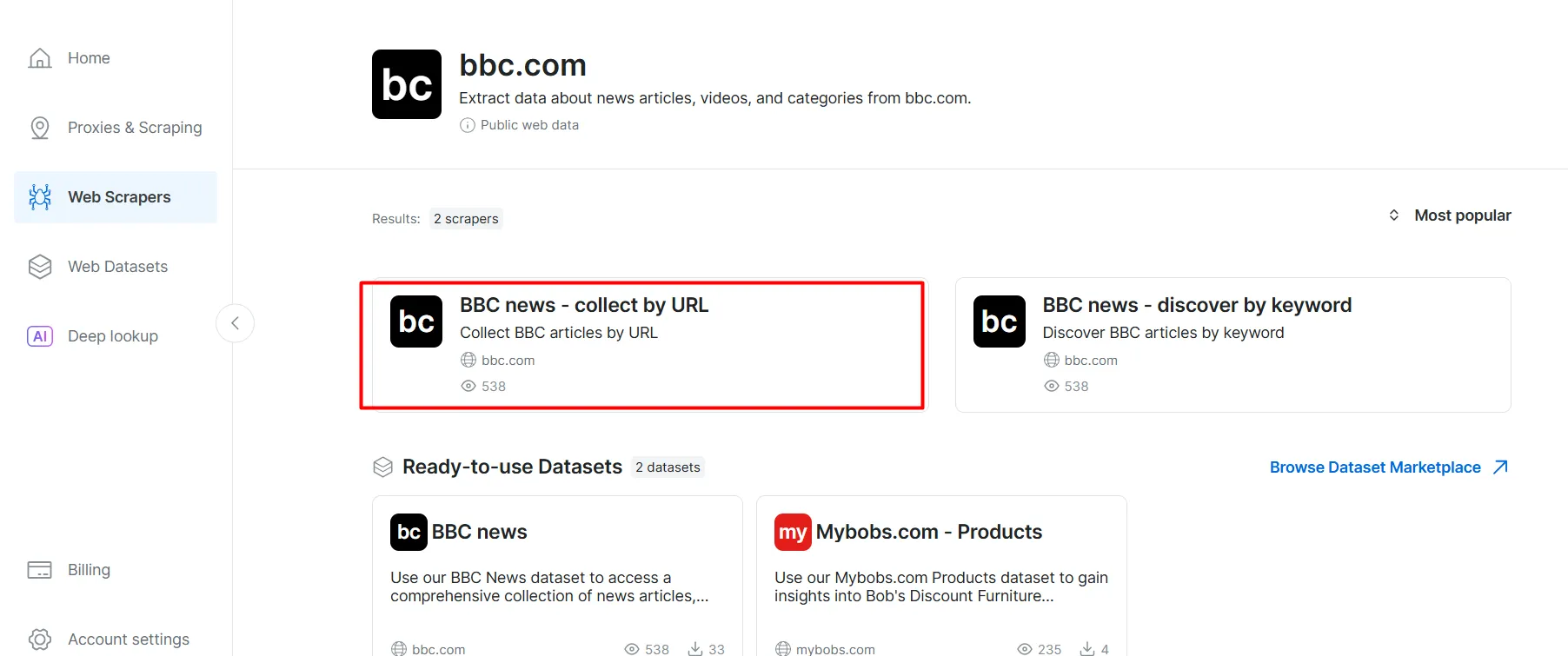
- Выберите опцию Scraper API. No-Code Scraper помогает извлекать наборы данных без кода.
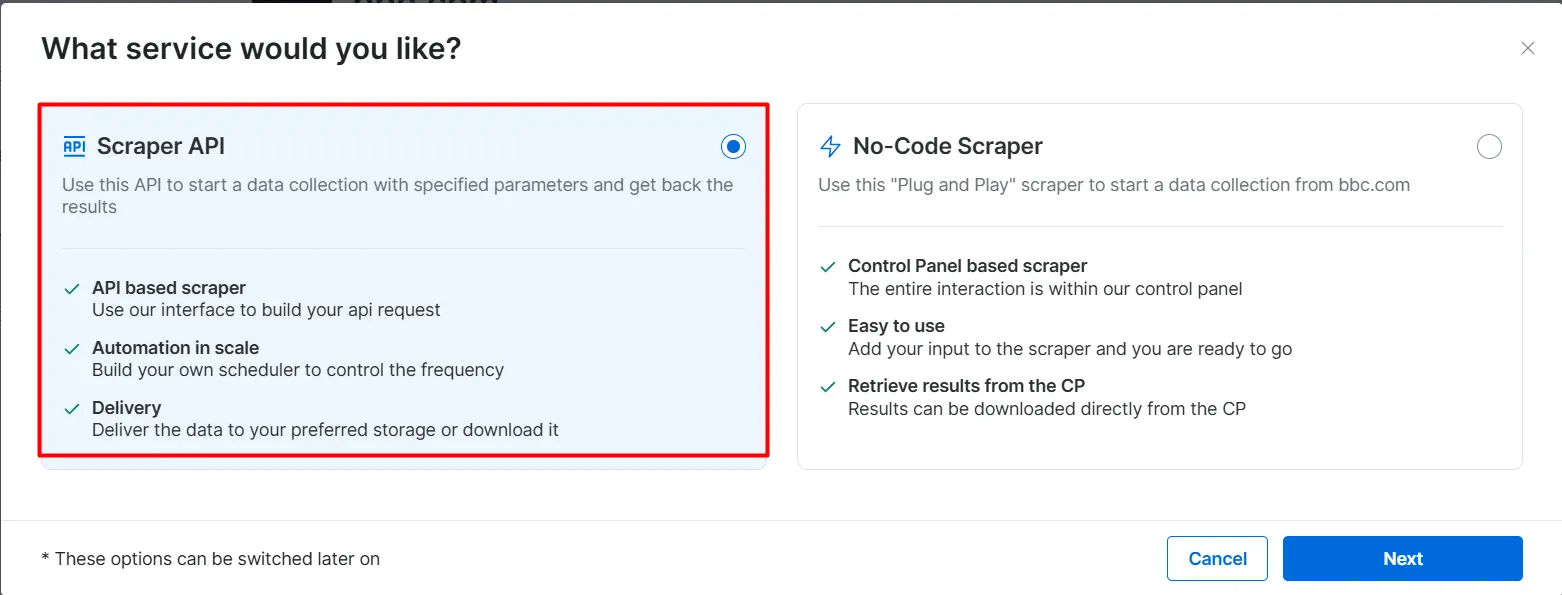
- Нажмите на кнопку API Request Builder, затем скопируйте
API-ключ,URL-адрес набора данных BBCиdataset_id. Вы будете использовать их в следующем разделе при создании рабочего процесса Agentic RAG.
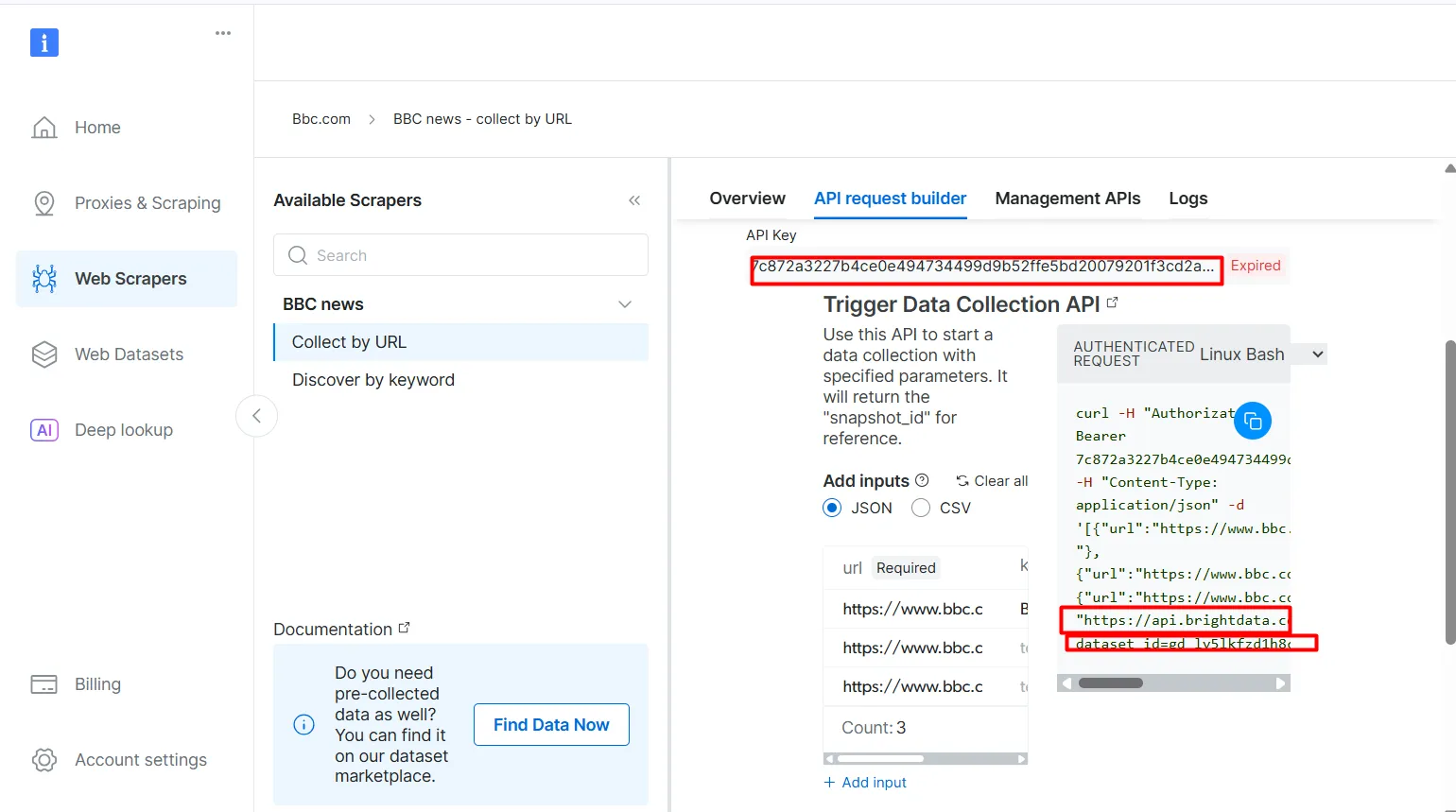
API-ключ и dataset_id необходимы для включения агентских возможностей в ваш рабочий процесс. Они позволяют встраивать живые данные в векторную базу данных и поддерживать запросы в реальном времени, даже если поисковый запрос не совпадает напрямую с предварительно проиндексированным содержимым.
Пререквизиты
Прежде чем приступить к работе, убедитесь, что у вас есть все необходимое:
- Учетная запись Bright Data
- Ключ API OpenAI Зарегистрируйтесь на сайте OpenAI, чтобы получить ключ API:
- Ключ API Pinecone Обратитесь к документации Pinecone и следуйте инструкциям в разделе ” Получение ключа API”.
- Базовое понимание Python Вы можете установить Python с официального сайта
- Базовое понимание концепций RAG и агентов
Структура агентурного RAG
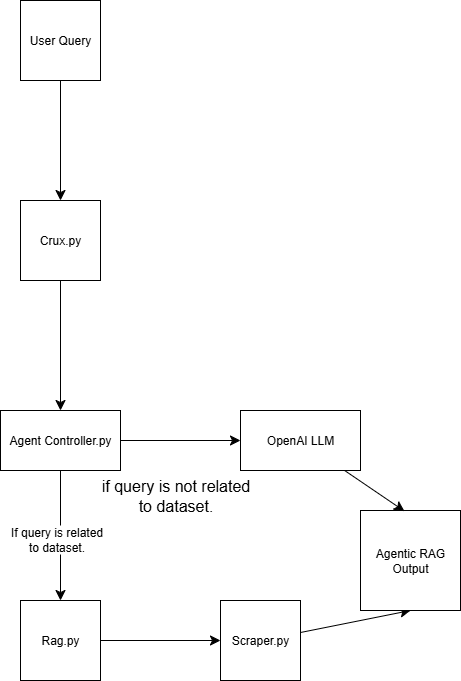
Эта система Agentic RAG построена с использованием четырех скриптов:
scraper.py Получает веб-данные с помощью Bright Data.
rag.py Встраивает данные в векторную базу данных (Pinecone) Примечание: Векторная (числовая встраиваемая) база данных используется потому, что в ней хранятся неструктурированные данные, обычно генерируемые моделью машинного обучения. Этот формат идеально подходит для поиска по сходству в задачах поиска.
agent_controller.py Содержит логику управления. Она определяет, использовать ли предварительно обработанные данные из базы векторов или полагаться на общие знания из GPT, в зависимости от характера запроса
crux.py Действует как ядро системы Agentic RAG. Он хранит ключи API и инициализирует рабочий процесс.
В конце демонстрации ваша агентурная тряпичная структура будет выглядеть так:
Создание агентурного RAG с помощью ярких данных
Шаг 1: Создайте проект
1.1 Создайте новый каталог проекта
Создайте папку для своего проекта и перейдите в нее:
mkdir agentic-rag
cd agentic-rag
1.2 Откройте проект в Visual Studio Code
Запустите Visual Studio Code и откройте только что созданную директорию:
.../Desktop/agentic-rag> code .
1.3 Настройка и активация виртуальной среды
Чтобы создать виртуальную среду, выполните команду:
python -m venv venv
Кроме того, в Visual Studio Code следуйте подсказкам в руководстве по средам Python, чтобы создать виртуальную среду.
Чтобы активировать среду:
- В Windows:
.venv\\\Scripts\\\activate - На macOS или Linux:
source venv/bin/activate
Шаг 2: Внедрение Bright Data Retriever
2.1 Установите библиотеку requests в файл scraper.py
pip install requests
2.2 Импортируйте следующие модули
import requests
import json
import time
2.3 Настройка учетных данных
Используйте ключ API Bright Data, URL-адрес набора данных и идентификатор dataset_id, которые вы скопировали ранее.
def trigger_bbc_news_articles_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # ID of the BBC web scraper
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
2.4 Настройка логики ответа
Введите в запрос URL-адреса страниц, которые вы хотите отсканировать. В данном случае речь идет о статьях, связанных со спортом.
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "BRIGHT DATA KEY" # Replace it with your Bright Data's Web Scraper API key
# URLs of BBC articles to retrieve data from
urls = [
"<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"<https://www.bbc.com/sport/formula1/articles/cgenqvv9309o>",
"<https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo>",
"<https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o>",
"<https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo>",
"<https://www.bbc.com/sport/football/articles/c807p94r41do>",
"<https://www.bbc.com/sport/football/articles/crgglxwge10o>",
"<https://www.bbc.com/sport/tennis/articles/cy700xne614o>",
"<https://www.bbc.com/sport/tennis/articles/c787dk9923ro>",
"<https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo>"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")
2.5 Запуск кода
После запуска скрипта в папке проекта появится файл с именем news-data.json. Он содержит отсканированные данные о статьях в структурированном формате JSON.
Вот пример содержимого JSON-файла:
[
{
"id": "c9dj0elnexyo",
"url": "<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"author": "BBC",
"headline": "Max Verstappen: Red Bull adviser Helmut Marko has 'great concern' about world champion's future with team",
"topics": [
"Formula 1"
],
"publication_date": "2025-04-14T13:42:08.154Z",
"content": "Saudi Arabian Grand PrixVenue: Jeddah Dates: 18-20 April Race start: 18:00 BST on SundayCoverage: Live radio commentary of practice, qualifying and race online and BBC 5 Sports Extra; live text updates on the BBC Sport website and app; Red Bull motorsport adviser Helmut Marko says he has \\"great concern\\" about Max Verstappen's future with the team in the context of their current struggles.AdvertisementThe four-time champion finished sixth in the Bahrain Grand Prix on Sunday, while Oscar Piastri scored McLaren's third win in four races so far this year.Dutchman Verstappen is third in the drivers' championship, eight points behind leader Lando Norris of McLaren.Marko told Sky Germany: \\"The concern is great. Improvements have to come in the near future so that he has a car with which he can win again.\\"We have to create a basis with a car so that he can fight for the world championship.\\"Verstappen has a contract with Red Bull until 2028. But Marko told BBC Sport this month that it contains a performance clause that could allow him to leave the team.; The wording of this clause is not known publicly but it effectively says that Red Bull have to provide Verstappen with a winning car.Verstappen won the Japanese Grand Prix a week before Bahrain but that victory was founded on a pole position lap that many F1 observers regarded as one of the greatest of all time.Because overtaking was next to impossible at Suzuka, Verstappen was able to hold back the McLarens of Norris and Piastri and take his first win of the year.Verstappen has qualified third, fourth and seventh for the other three races in Australia, China and Bahrain.The Red Bull is on average over all qualifying sessions this year the second fastest car but 0.214 seconds a lap slower than the McLaren.Verstappen has complained all year about balance problems with the Red Bull, which is unpredictable on corner entry and has mid-corner understeer.Red Bull team principal Christian Horner admitted after the race in Bahrain that the car's balance problems were fundamentally similar to the ones that made the second half of last year a struggle for Verstappen.He won just twice in the final 13 races of last season, but managed to win his fourth world title because of the huge lead he built up when Red Bull were in dominant form in the first five races of the season.Horner also said the team were having difficulties with correlation between their wind tunnel and on-track performance. Essentially, the car performs differently on track than the team's simulation tools say it should.; Verstappen had a difficult race in Bahrain including delays at both pit stops, one with the pit-lane traffic light system and one with fitting a front wheel.At one stage he was running last, and he managed to snatch sixth place from Alpine's Pierre Gasly only on the last lap.Verstappen said that the hot weather and rough track surface had accentuated Red Bull's problems.He said: \\"Here you just get punished a bit harder when you have big balance issues because the Tarmac is so aggressive.\\"The wind is also quite high and the track has quite low grip, so everything is highlighted more.\\"Just the whole weekend struggling a bit with brake feeling and stopping power, and besides that also very poor grip. We tried a lot on the set-up and basically all of it didn't work, didn't give us a clear direction to work in.\\"Verstappen has said this year that he is \\"relaxed\\" about his future.Any decision about moving teams for 2026 is complicated by the fact that F1 is introducing new chassis and engine rules that amount to the biggest regulation change in the sport's history, and it is impossible to know which team will be in the best shape.But it is widely accepted in the paddock that Mercedes are looking the best in terms of engine performance for 2026.Mercedes F1 boss Toto Wolff has made no secret of his desire to sign Verstappen.The two parties had talks last season but have yet to have any discussions this season about the future.",
"videos": [],
"images": [
{
"image_url": "<https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/bfc4/live/d3cc7850-1931-11f0-869a-33b652e8958c.jpg>",
"image_description": "Main image"
},
Теперь, когда у вас есть данные, следующий шаг – внедрить их.
Шаг 3: Настройка вкраплений и векторного хранилища
3.1 Установите необходимые библиотеки в файл rag.py
pip install openai pinecone pandas
3.2 Импорт необходимых библиотек
import json
import time
import re
import openai
import pandas as pd
from pinecone import Pinecone, ServerlessSpec
3.3 Настройка ключа OpenAI
Используйте OpenAI для генерации вкраплений из поля text_for_embedding.
# Configure your OpenAI API key here or pass to functions
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI API key
3.4 Настройка ключа API Pinecone и параметров индекса
Настройте окружение Pinecone и определите конфигурацию индекса.
pinecone_api_key = "PINECONE_API_KEY" # Replace with your Pinecone API key
index_name = "news-articles"
dimension = 1536 # OpenAI embedding dimension for text-embedding-ada-002 (adjust if needed)
namespace = "default"
3.5 Инициализация клиента и индекса Pinecone
Убедитесь, что клиент и индекс правильно инициализированы для хранения и извлечения данных.
# Initialize Pinecone client and index
pc = Pinecone(api_key=pinecone_api_key)
# Check if index exists
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
pinecone_index = pc.Index(index_name)
print(pinecone_index)
3.6 Очистка, загрузка и предварительная обработка данных
# Text cleaning helper
def clean_text(text):
text = re.sub(r"\\s+", " ", text)
return text.strip()
# Load and preprocess `news-data.json`
def load_and_prepare_data(json_path="news-data.json"):
with open(json_path, "r", encoding="utf-8") as f:
news_data = json.load(f)
df = pd.DataFrame(news_data)
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
df["id"] = df["id"].astype(str)
return df
Примечание: Вы можете повторно запустить
scraper.py, чтобы убедиться, что ваши данные актуальны.
3.7 Генерирование вкраплений с помощью OpenAI
Создайте вкрапления из предварительно обработанного текста с помощью модели вкраплений OpenAI.
# New embedding generation via OpenAI API
def openai_generate_embeddings(texts, model="text-embedding-ada-002"):
openai.api_key = OPENAI_API_KEY
# OpenAI endpoint accepts a list of strings and returns list of embeddings
response = openai.embeddings.create(
input=texts,
model=model
)
embeddings = [datum.embedding for datum in response.data]
return embeddings
3.8 Обновление Pinecone с помощью вкраплений
Отправьте сгенерированные вкрапления в Pinecone, чтобы поддерживать базу векторов в актуальном состоянии.
# Embed and upsert to Pinecone
def embed_and_upsert(json_path="news-data.json", namespace=namespace):
df = load_and_prepare_data(json_path)
texts = df["text_for_embedding"].tolist()
print(f"Generating embeddings for {len(texts)} texts using OpenAI...")
embeddings = openai_generate_embeddings(texts)
df["embedding"] = embeddings
records = []
for row in df.itertuples():
records.append((
row.id,
row.embedding,
{
"url": getattr(row, "url", ""), # safe get url if present
"text": row.text_for_embedding
}
))
pinecone_index.upsert(vectors=records, namespace=namespace)
print(f"Upserted {len(records)} records to Pinecone index '{index_name}'.")
Примечание: Вам нужно выполнить этот шаг только один раз, чтобы заполнить базу данных. После этого вы можете закомментировать эту часть кода.
3.9 Инициализация функции поиска Pinecone
def pinecone_search(index, query, namespace=namespace, top_k=3, score_threshold=0.8, embedding_model=None):
# OpenAI embedding here
query_embedding = openai_generate_embeddings([query])[0]
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=namespace,
include_metadata=True,
)
filtered = []
for match in results.matches:
if match.score >= score_threshold:
filtered.append({
"score": match.score,
"url": match.metadata.get("url", ""),
"text": match.metadata.get("text", ""),
})
return filtered
Примечание:
Порог оценки определяет минимальный балл сходства для того, чтобы результат считался релевантным. Вы можете настроить это значение в соответствии с вашими потребностями. Чем выше показатель, тем точнее результат.
3.10 Генерируйте ответы с помощью OpenAI
Используйте OpenAI для генерации ответов на основе контекста, полученного с помощью Pinecone.
# OpenAI answer generation
def openai_generate_answer(openai_api_key, query, context=None):
import openai
openai.api_key = openai_api_key
prompt_context = ""
if context:
prompt_context = "\\n\\nContext:\\n" + "\\n\\n".join(context)
prompt = f"Answer the following question: {query}" + prompt_context
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=256,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
return answer
3.11 (Дополнительно) Выполните простой тест для запроса и печати результатов
Включите код с поддержкой CLI, который позволит вам запустить базовый тест. Тест поможет убедиться в работоспособности вашей реализации и покажет предварительный просмотр данных, хранящихся в базе данных.
def search_news_and_answer(openai_api_key, query):
results = pinecone_search(pinecone_index, query)
if results:
print(f"Found {len(results)} relevant documents.")
print("Top documents:")
for doc in results:
print(f"Score: {doc['score']:.4f}")
print(f"URL: {doc['url']}")
print(f"Text (excerpt): {doc['text'][:250]}...\\n")
answer = openai_generate_answer(openai_api_key, query, [r["text"] for r in results])
print("\\nGenerated answer:\\n", answer)
if __name__ == "__main__":
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI key here or pass via arguments/env var
test_query = "What is wrong with Man City?"
search_news_and_answer(OPENAI_API_KEY, test_query)
Совет: Вы можете управлять объемом отображаемого текста, нарезая результат, например:
[:250].
Теперь ваши данные хранятся в базе данных векторов. Это означает, что у вас есть два варианта запросов:
- Извлечь из базы данных
- Используйте общий ответ, сгенерированный OpenAI
Шаг 4: Создание контроллера агента
4.1 В файле agent_controller.py
Импортируйте необходимую функциональность из rag.py.
from rag import openai_generate_answer, pinecone_search
4.2 Реализуйте извлечение сосновых шишек
Добавьте логику для получения соответствующих данных из векторного хранилища Pinecone.
def agent_controller_decide_and_act(
pinecone_api_key,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
print(f"Agent received query: {query}")
try:
print("Trying Pinecone retrieval...")
results = pinecone_search(pinecone_index, query, namespace=namespace)
if results:
print(f"Found {len(results)} matching documents in Pinecone.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
return answer
else:
print("No good matches found in Pinecone. Falling back to OpenAI generator.")
except Exception as e:
print(f"Pinecone retrieval failed: {e}")
4.3 Реализуйте обратный ответ OpenAI
Создайте логику для генерации ответа с помощью OpenAI, когда не удается найти релевантный контекст.
try:
print("Generating answer from OpenAI without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
return answer
except Exception as e:
print(f"OpenAI generation failed: {e}")
return "Sorry, I am currently unable to answer your query."
Шаг 5: Соберите все вместе
5.1 В файле crux.py
Импортируйте все необходимые функции из файла agent_controller.py.
from rag import pinecone_index # Import Pinecone index & embedding model
from rag import openai_generate_answer, pinecone_search # Import helper functions if needed
from agent_controller import agent_controller_decide_and_act # Your orchestration function
5.2 Предоставление ключей API
Убедитесь, что ваши API-ключи OpenAI и Pinecone установлены правильно.
# Your actual API keys here - replace with your real keys
PINECONE_API_KEY = "PINECONE_API_KEY"
OPENAI_API_KEY = "OPENAI_API_KEY"
5.3 Введите запрос в функцию main()
Определите ввод подсказки в функции main().
def main():
query = "What is the problem with Man City?"
answer = agent_controller_decide_and_act(
pinecone_api_key=PINECONE_API_KEY,
openai_api_key=OPENAI_API_KEY,
pinecone_index=pinecone_index,
query=query,
namespace="default"
)
print("\\nAgent's answer:\\n", answer)
if __name__ == "__main__":
main()
5.4 Вызов агента RAG
Запустите логику Agentic RAG. Вы увидите, как она обрабатывает запрос, сначала проверяя его релевантность, а затем обращаясь к базе данных векторов.

Agent received query: What exactly is the problem with Man City Women Team?
Trying Pinecone retrieval...
Found 1 matching documents in Pinecone.
Agent's answer:
The problems with the Man City Women Team this season include a significant injury crisis, managerial upheaval, and poor performances in key games. Key players such as Vivianne Miedema, Khadija Shaw, Lauren Hemp, and Alex Greenwood have been sidelined due to injuries, which has severely impacted the team's performance and highlighted a lack of squad depth. Interim manager Nick Cushing suggests that the number of injuries is not solely down to bad luck or bad practice and calls for an examination of the situation.
Попробуйте протестировать его с помощью запроса, который не соответствует вашей базе данных, например:
def main():
query = "Why Sleep?"
Агент определяет, что в Pinecone не найдено подходящих вариантов, и переходит к генерации общего ответа с помощью OpenAI.

Agent received query: Why Sleep?
Trying Pinecone retrieval...
No good matches found in Pinecone. Falling back to OpenAI generator.
as a car crash), or it can harm you over time.
For example, ongoing sleep deficiency can raise your risk for some chronic health problems. It also can affect how well you think, react, work, learn, and get along with as a car crash), or it can harm you over time.
Совет: Вы можете распечатать оценку релевантности (score_threshold) для каждой подсказки, чтобы понять уровень доверия агента.
Вот и все! Вы успешно создали свой Agentic RAG.
Шаг 6 (необязательный):Контур обратной связи и оптимизация
Вы можете усовершенствовать свою систему, внедрив петлю обратной связи для улучшения обучения и индексации с течением времени.
6.1 Добавьте функцию обратной связи
В файле agent_controller.py создайте функцию, которая запрашивает у пользователя обратную связь после показа ответа. Вы можете вызвать эту функцию в конце основного бегуна в crux.py.
def collect_user_feedback():
feedback = input("Was the answer helpful? (yes/no): ").strip().lower()
comments = input("Any comments or corrections? (optional): ").strip()
return feedback, comments
6.2 Реализация логики обратной связи
Создайте новую функцию в файле agent_controller.py, которая повторно запускает процесс поиска, если отзывы отрицательные. Затем вызовите эту функцию в crux.py:
def agent_controller_handle_feedback(
feedback,
comments,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
if feedback == "no":
print("Feedback: answer not helpful. Retrying with relaxed retrieval parameters...")
# Relaxed retrieval - increase number of docs and lower score threshold
results = pinecone_search(
pinecone_index,
query,
namespace=namespace,
top_k=5,
score_threshold=0.3
)
if results:
print(f"Found {len(results)} documents after retry.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
print("\\nNew answer based on feedback:\\n", answer)
return answer
else:
print("No documents found even after retry. Generating answer without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
print("\\nAnswer generated without retrieval:\\n", answer)
return answer
else:
print("Thank you for your positive feedback!")
return None
Заключение и дальнейшие шаги
В этой статье вы построили автономную агентную систему RAG, которая объединяет Bright Data для веб-скрапинга, Pinecone в качестве векторной базы данных и OpenAI для генерации текста. Эта система закладывает основу, которую можно расширить для поддержки множества дополнительных функций, таких как:
- Интеграция векторных баз данных с реляционными и нереляционными базами данных
- Создание пользовательского интерфейса с помощью Streamlit
- Автоматизация поиска данных в Интернете для поддержания актуальности учебных данных
- Усовершенствование логики поиска и рассуждений агентов
Как показывает практика, качество работы системы Agentic RAG в значительной степени зависит от качества исходных данных. Компания Bright Data сыграла ключевую роль в обеспечении надежности и свежести веб-данных, что необходимо для эффективного поиска и генерации.
Рассмотрите возможность дальнейшего усовершенствования этого рабочего процесса и использования Bright Data в своих будущих проектах для поддержания стабильного качества исходных данных.





