

Веб-скреппинг переживает переломный момент, поскольку традиционным методам мешают сложные средства защиты от ботов, а разработчикам приходится постоянно исправлять хрупкие скрипты. Хотя они все еще работают, их ограничения очевидны, особенно рядом с современными инфраструктурами для скраппинга, основанными на искусственном интеллекте, которые обеспечивают устойчивость и масштабируемость. Поскольку к 2030 году рынок ИИ-агентов вырастет с 7,84 млрд долларов до 52,62 млрд долларов, будущее доступа к данным за интеллектуальными, автономными системами.
Объединив фреймворк автономного агента CrewAI с надежной инфраструктурой Bright Data, вы получите стек для скраппинга, учитывающий причины и преодолевающий барьеры против ботов. В этом руководстве вы создадите агента для скраппинга на базе ИИ, который будет предоставлять надежные данные в режиме реального времени.
Ограничения старой школы скрапинга
Традиционный скраппинг хрупок – он опирается на статичные селекторы CSS или XPath, которые ломаются при любом изменении внешнего интерфейса. Основные проблемы включают:
- Защита от ботов. CAPTCHA, дросселирование IP-адресов и отпечатки пальцев блокируют простые краулеры.
- Страницы с большим количеством JavaScript. React, Angular и Vue строят DOM в браузере, поэтому необработанные HTTP-вызовы пропускают большую часть контента.
- Неструктурированный HTML. Непоследовательный HTML и разрозненные встроенные данные требуют серьезного разбора и постобработки перед использованием.
- Узкие места при масштабировании. Организация прокси-серверов, повторных попыток и постоянных исправлений превращается в изнурительную и бесконечную операционную нагрузку.
Как CrewAI + Bright Data оптимизируют скраппинг
Создание автономного скрепера основывается на двух составляющих: адаптивном “мозге” и устойчивом “теле”.
- CrewAI (The Brain). Мультиагентная среда выполнения с открытым исходным кодом, в которой вы создаете “команду” агентов, способных планировать, рассуждать и координировать сквозные задания по скраппингу.
- Bright Data MCP (The Body). Шлюз с живыми данными, который направляет каждый запрос через стек Bright Data Unlocker – ротация IP-адресов, решение CAPTCHA и запуск безголовых браузеров – так что LLM получают чистый HTML или JSON за один раз. Реализация Bright Data является ведущим в отрасли источником надежных данных для агентов ИИ.
Вместе это сочетание мозга и тела позволяет вашим агентам думать, находить и адаптироваться практически на любой площадке.
Что такое CrewAI?
CrewAI – это фреймворк с открытым исходным кодом для организации совместной работы агентов ИИ. Вы определяете роль, цель и инструменты каждого агента, а затем объединяете их в команду для выполнения многоэтапных рабочих процессов.
Основные компоненты:
- Агент. Работник, управляемый LLM, с ролью, целью и необязательной предысторией, дающей модели контекст области.
- Задача. Одно задание, хорошо спланированное для одного агента, плюс ожидаемый_вывод, который служит критерием качества.
- Инструмент. Любой вызываемый объект, который может вызвать агент – HTTP-выборка, запрос к БД или конечная точка MCP компании Bright Data для скраппинга.
- Экипаж. Совокупность агентов и их заданий, работающих над достижением одной цели.
- Процесс. План выполнения – последовательный, параллельный или иерархический – который управляет порядком выполнения задач, делегированием и повторными попытками.
Это отражает работу настоящей команды: специалисты занимаются своими делами, передают результаты вперед и при необходимости эскалируют.
Что такое контекстный протокол модели (MCP)?
MCP – это открытый стандарт JSON-RPC 2.0, позволяющий агентам ИИ вызывать внешние инструменты и источники данных через единый структурированный интерфейс. Подумайте об этом как о порте USB-C для моделей – один разъем, множество устройств.
Сервер MCP от Bright Data воплощает этот стандарт в жизнь, подключая агента непосредственно к стеку скраппинга Bright Data, что делает веб-скраппинг с MCP не только более мощным, но и гораздо более простым, чем традиционные стеки:
- Обход антиботов. Запросы проходят через Web Unlocker и пул из 150M+ вращающихся жилых IP, охватывающих 195 стран.
- Поддержка динамических сайтов. Специально разработанный браузер Scraping Browser отображает JavaScript, поэтому агенты видят полностью загруженный DOM.
- Структурированные результаты. Многие инструменты возвращают чистый JSON, избавляя вас от необходимости использовать собственные парсеры.
Сервер публикует 50+ готовых инструментов – от общих URL-адресов до скреперов для конкретного сайта, – чтобы ваш агент CrewAI мог одним вызовом получить цены на товары, данные SERP или снимки DOM.
Создание вашего первого агента по скрапбукингу с искусственным интеллектом
Давайте создадим агента CrewAI, который извлекает данные со страницы товара Amazon и возвращает их в виде структурированного JSON. Вы можете легко перенаправить этот же стек на другой сайт, изменив всего несколько строк.
Пререквизиты
- Python 3.11 – рекомендуется для обеспечения стабильности.
- Node.js + npm – требуется для запуска сервера Bright Data MCP; загрузить с официального сайта.
- Виртуальное окружение Python – позволяет изолировать зависимости; см. документацию
venv. - Учетная запись Bright Data – зарегистрируйтесь и создайте токен API (доступны бесплатные пробные кредиты).
- Ключ API Google Gemini – создайте ключ в Google AI Studio (нажмите + Создать ключ API). Бесплатный уровень позволяет выполнять 15 запросов в минуту и 500 запросов в день. Биллинговый профиль не требуется.
Обзор архитектуры
Environment Setup → LLM Config → MCP Server Init →
Agent Definition → Task Definition → Crew Execution → JSON OutputШаг 1. Настройка и импорт среды
mkdir crewai-bd-scraper && cd crewai-bd-scraper
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
from dotenv import load_dotenv
load_dotenv() # Load credentials from .envШаг 2. Настройка ключей и зон API
Создайте файл .env в корне проекта:
BRIGHT_DATA_API_TOKEN="…"
WEB_UNLOCKER_ZONE="…"
BROWSER_ZONE="…"
GEMINI_API_KEY="…"Вам потребуется:
- API-токен. Сгенерируйте новый API-токен.
- Зона Web Unlocker. Создайте новую зону Web Unlocker. Если этот параметр не указан, для вас будет создана зона по умолчанию под названием
mcp_unlocker. - Зона Browser API. Создайте новую зону Browser API. Необходима только для целей с большим количеством JavaScript. Скопируйте строку имени пользователя, показанную на вкладке ” Обзор” зоны.
- Ключ API Google Gemini. Уже создан в разделе Предварительные условия.
Шаг 3. Конфигурация LLM (Gemini)
Настройте LLM (Gemini 1.5 Flash) на детерминированный вывод:
llm = LLM(
model="gemini/gemini-1.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
temperature=0.1,
)Шаг 4. Настройка Bright Data MCP
Настройте сервер Bright Data MCP. Это указывает CrewAI, как запустить сервер и передать учетные данные:
server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)Это запускает *npx @brightdata/mcp* как подпроцесс и выставляет 50+ инструментов (≈ 57 на момент написания статьи) через стандарт MCP.
Шаг 5. Определение агента и задачи
Здесь мы определяем личность агента и конкретную работу, которую он должен выполнять. Эффективные реализации CrewAI следуют правилу 80/20: 80 % усилий тратится на разработку задачи, 20 % – на определение агента.
def build_scraper_agent(mcp_tools):
return Agent(
role="Senior E-commerce Data Extractor",
goal=(
"Return a JSON object with snake_case keys containing: title, current_price, "
"original_price, discount, rating, review_count, last_month_bought, "
"availability, product_id, image_url, brand, and key_features for the "
"target product page. Ensure strict schema validation."
),
backstory=(
"Veteran web-scraping engineer with years of experience reverse-"
"engineering Amazon, Walmart, and Shopify layouts. Skilled in "
"Bright Data MCP, proxy rotation, CAPTCHA avoidance, and strict "
"JSON-schema validation."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
def build_scraping_task(agent):
return Task(
description=(
"Extract product data from https://www.amazon.in/dp/B071Z8M4KX "
"and return it as structured JSON."
),
expected_output="""{
"title": "Product name",
"current_price": "$99.99",
"original_price": "$199.99",
"discount": "50%",
"last_month_bought": 150,
"rating": 4.5,
"review_count": 1000,
"availability": "In Stock",
"product_id": "ABC123",
"image_url": "https://example.in/image.jpg",
"brand": "BrandName",
"key_features": ["Feature 1", "Feature 2"],
}""",
agent=agent,
)Вот что делает каждый параметр:
- роль – краткое название должности, которое CrewAI вводит в каждый системный запрос.
- goal – цель северной звезды; CrewAI сравнивает ее после каждого цикла, чтобы решить, стоит ли останавливаться.
- предыстория – контекст домена, определяющий тон и уменьшающий галлюцинации.
- tools – Список объектов
BaseTool(например, MCPsearch_engine,scrape_as_markdown). - llm – модель, которую CrewAI использует для каждого цикла “думать → планировать → действовать → отвечать”.
- max_iter – жесткое ограничение на количество внутренних циклов агента (по умолчанию 20 в v0.30+).
- verbose – Потоковая передача каждой подсказки, мысли и вызова инструмента в stdout (полезно для отладки).
- описание – Обучение, ориентированное на действие, вводится каждый ход.
- expected_output – Формальный контракт правильного ответа (используйте строгий JSON, без запятой в конце).
- agent – Привязывает эту задачу к конкретному экземпляру
агентадляCrew.kickoff().
Шаг 6. Сбор экипажа и выполнение
Эта часть собирает агента и задачу в экипаж и запускает рабочий процесс.
def scrape_product_data():
"""Assembles and runs the scraping crew."""
with MCPServerAdapter(server_params) as mcp_tools:
scraper_agent = build_scraper_agent(mcp_tools)
scraping_task = build_scraping_task(scraper_agent)
crew = Crew(
agents=[scraper_agent],
tasks=[scraping_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
try:
result = scrape_product_data()
print("n[SUCCESS] Scraping completed!")
print("Extracted product data:")
print(result)
except Exception as e:
print(f"n[ERROR] Scraping failed: {str(e)}")Шаг 7. Запуск скребка
Выполните сценарий в терминале. Вы увидите в консоли ход мыслей агента, как он планирует и выполняет задание.
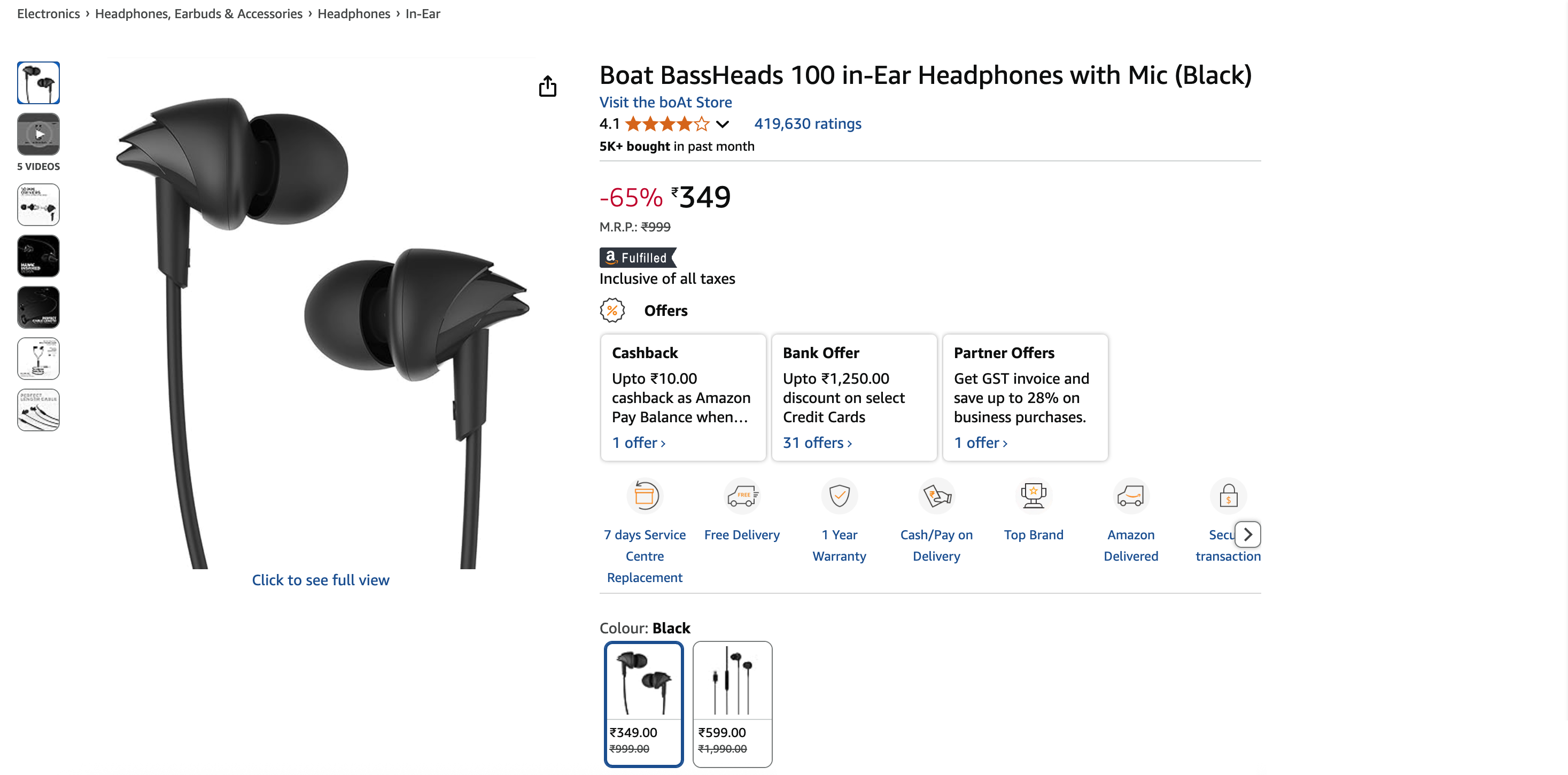
Конечным результатом будет чистый объект JSON:
{
"title": "Boat BassHeads 100 in-Ear Headphones with Mic (Black)",
"current_price": "₹349",
"original_price": "₹999",
"discount": "-65%",
"rating": 4.1,
"review_count": 419630,
"last_month_bought": 5000,
"availability": "In stock",
"product_id": "B071Z8M4KX",
"image_url": "https://m.media-amazon.com/images/I/513ugd16C6L._SL1500_.jpg",
"brand": "boAt",
"key_features": [
"10mm dynamic driver",
"HD microphone",
"1.2 m cable",
"Comfortable fit",
"1 year warranty"
]
}Адаптация к другим целям
Настоящая сила агентного дизайна заключается в его гибкости. Хотите скрести посты LinkedIn вместо товаров Amazon? Просто измените роль, цель и предысторию агента, а также описание задачи и ожидаемый_вывод. Все остальное, включая базовый код и инфраструктуру, остается неизменным.
role = "Senior LinkedIn Post Extractor"
goal = (
"Return a JSON object containing: author_name, author_title, "
"author_profile_url, post_content, post_date, likes_count, "
"and comments_count"
)
backstory = (
"Seasoned social-data engineer specializing in LinkedIn data "
"extraction using Bright Data MCP. Produces clean, structured "
"JSON output."
)
description = (
"Extract post data from LinkedIn post (ID: orlenchner_agents-"
"brightdata-activity-7336402761892122625-h5Oa) and return "
"structured JSON."
)
expected_output = """{
"author_name": "Post author's full display name",
"author_title": "Author's job title/headline",
"author_profile_url": "Author's profile URL",
"post_content": "Complete post text with formatting",
"post_date": "ISO 8601 UTC timestamp",
"likes_count": "Number of post likes",
"comments_count": "Number of post comments",
}"""На выходе вы получите чистый объект JSON:
{
"author_name": "Or Lenchner",
"author_title": "CEO at Bright Data - Keeping public web data, public.",
"author_profile_url": "https://il.linkedin.com/in/orlenchner",
"post_content": "NEW PRODUCT! There’s a consensus that the future internet will be run by automated #Agents , automating the activity on behalf of “their” humans. AI solved the automation part (or at least shows strong indications), but the number one problem is ensuring smooth access to every website at scale without being blocked. browser.ai is the solution → Your Agent always gains access to any website with a simple prompt. Agents using Bright Data are already executing hundreds of millions of web actions daily on our browser infrastructure. #BrightData has long been the go-to for major LLM companies, providing the tools and scale they need to train and deploy such technologies. With browser.ai , we’re taking that foundation and tailoring it specifically for AI agents, optimizing our APIs, proxy networks, and serverless browsers to handle their unique demands. The web isn’t fully prepared for this shift yet, but we are. browser.ai immediate focus is to ensure *smooth* access to any website (DONE!), while phase two will be all about *fast* access (wip). https://browser.ai/",
"post_date": "2025-06-05T14:45:22.155Z",
"likes_count": 119,
"comments_count": 7
}Оптимизация затрат
MCP от Bright Data основан на использовании, поэтому каждый дополнительный запрос увеличивает ваш счет. Несколько вариантов дизайна позволяют сдерживать расходы:
- Целевое соскабливание. Запрашивайте только нужные вам поля вместо того, чтобы просматривать целые страницы или наборы данных.
- Кэширование. Включите кэш CrewAI на уровне инструментов
(cache_function), чтобы пропускать вызовы, когда контент не изменился, экономя время и кредиты. - Эффективный выбор инструмента. По умолчанию используется зона Web Unlocker и переключается на зону Browser API только в тех случаях, когда необходим рендеринг JavaScript.
- Установите
max_iter. Дайте каждому агенту разумную верхнюю границу, чтобы он не мог вечно циклиться на неработающей странице. (Вы также можете дросселировать запросы с помощьюmax_rpm).
Следуйте этим рекомендациям, и ваши агенты CrewAI останутся безопасными, надежными и экономичными, готовыми к производственным рабочим нагрузкам на Bright Data MCP.
Что дальше
Экосистема MCP продолжает расширяться: API Responses от OpenAI и SDK Gemini от Google DeepMind теперь говорят на родном языке MCP, гарантируя долгосрочную совместимость и постоянные инвестиции.
CrewAI внедряет мультимодальные агенты, более богатую отладку и корпоративный RBAC, а MCP-сервер Bright Data предлагает 60 с лишним готовых инструментов и продолжает расти.
Вместе агентские фреймворки и стандартизированный доступ к данным открывают новую волну веб-интеллекта для приложений, работающих на основе искусственного интеллекта. Руководство по подключению MCP к OpenAI Agents SDK подчеркивает, насколько важными стали надежные каналы передачи данных.
В конечном итоге вы не просто создаете скребок – вы организуете адаптивный рабочий процесс обработки данных, созданный для будущего Интернета.
Нужен больший масштаб? Откажитесь от обслуживания скребков и борьбы с блоками – просто запрашивайте структурированные данные:
- Crawl API – полномасштабное извлечение информации из сайта.
- Web Scraper APIs – 120 с лишним конечных точек для конкретных доменов.
- SERP API – удобный поиск информации в поисковых системах.
- Dataset Marketplace – свежие, проверенные данные по запросу.
Готовы к созданию приложений ИИ нового поколения? Ознакомьтесь с полным набором продуктов Bright Data для искусственного интеллекта и узнайте, что дает бесшовный веб-доступ для ваших агентов. Для более глубокого погружения ознакомьтесь с нашими руководствами MCP по Qwen-Agent и Google ADK.






