

В этом руководстве вы увидите:
- Что представляет собой библиотека Google ADK для создания агентов искусственного интеллекта.
- Почему встроенная поддержка MCP делает его особенным.
- Как интегрировать его с сервером Bright Data MCP для создания чрезвычайно мощного агента искусственного интеллекта
Давайте погрузимся!
Что такое Google ADK?
Google ADK, сокращение от Google Agent Development Kit, – это Python-фреймворк с открытым исходным кодом для создания и развертывания агентов искусственного интеллекта. Хотя он оптимизирован для Gemini и более широкой экосистемы Google, он по-прежнему не зависит от модели и развертывания.
ADK делает упор на опыт разработчиков, предлагая инструменты и структуры данных, которые упрощают создание мощных мультиагентных систем. С помощью инструментов и интеграций вы можете определять агентов ИИ, которые могут рассуждать, сотрудничать и взаимодействовать с миром.
Конечная цель Google ADK – сделать разработку агентов более похожей на разработку традиционного программного обеспечения. Это достигается за счет упрощения процесса создания, развертывания и оркестровки агентных архитектур.
Что делает Google ADK особенным
По сравнению с другими библиотеками для создания агентов ИИ, Google ADK выделяется встроенной поддержкой MCP (Managed Connectivity Platform). Если вы не знакомы с этим понятием, MCP – это стандартизированный способ взаимодействия моделей ИИ с внешними инструментами и источниками данных, такими как API, базы данных и файловые системы.
Проще говоря, MCP позволяет агенту Google ADK использовать возможности любого MCP-совместимого сервера. Считайте, что это интеграция по принципу plug-and-play, которая расширяет возможности вашего агента ИИ за пределы ограничений базового LLM, предоставляя ему доступ к данным и действиям реального мира.
Этот вариант обеспечивает структурированный, безопасный и масштабируемый способ подключения агента к внешним возможностям, не требуя создания таких подключений с нуля. Интеграция MCP становится особенно привлекательной при интеграции с богатым MCP-сервером, таким как MCP-сервер Bright Data.
Этот MCP-сервер работает на Node.js и легко подключается ко всем мощным инструментам поиска данных ИИ компании Bright Data. Эти инструменты позволяют вашему агенту взаимодействовать с живыми веб-данными, структурированными наборами данных и возможностями соскабливания.
На данный момент поддерживаются следующие инструменты MCP:
| Инструмент | Описание |
|---|---|
поисковая_система |
Соскабливает результаты поиска из Google, Bing или Yandex. Возвращает результаты SERP в формате markdown (URL, заголовок, описание). |
scrape_as_markdown |
Соскребайте одну веб-страницу и возвращайте извлеченный контент в формате Markdown. Работает даже на защищенных от ботов или CAPTCHA страницах. |
scrape_as_html |
То же самое, что и выше, но возвращает содержимое в виде необработанного HTML. |
статистика сессии |
Предоставляет сводку об использовании инструмента в текущем сеансе. |
web_data_amazon_product |
Получение структурированных данных о товарах Amazon по URL /dp/. Более надежно, чем скраппинг, благодаря кэшированию. |
web_data_amazon_product_reviews |
Получение структурированных данных об обзорах Amazon по URL-адресу /dp/. Кэшированные и надежные. |
web_data_linkedin_person_profile |
Доступ к структурированным данным профиля LinkedIn. Кэшированные данные для обеспечения согласованности и скорости. |
веб-данные_linkedin_company_profile |
Доступ к структурированным данным компании LinkedIn. Кэшированная версия повышает надежность. |
web_data_zoominfo_company_profile |
Получение структурированных данных о компании ZoomInfo. Требуется действительный URL-адрес ZoomInfo. |
web_data_instagram_profiles |
Структурированные данные профиля Instagram. Требуется действительный URL-адрес Instagram. |
web_data_instagram_posts |
Получение структурированных данных для постов Instagram. |
web_data_instagram_reels |
Получение структурированных данных для роликов Instagram. |
web_data_instagram_comments |
Получение комментариев Instagram в виде структурированных данных. |
web_data_facebook_posts |
Доступ к структурированным данным для постов в Facebook. |
веб_данные_facebook_marketplace_listings |
Получение структурированных объявлений из Facebook Marketplace. |
веб_данные_facebook_company_reviews |
Получение отзывов о компании из Facebook. Требуется URL-адрес компании и количество отзывов. |
web_data_x_posts |
Получение структурированных данных из сообщений X (ранее Twitter). |
web_data_zillow_properties_listing |
Доступ к структурированным данным о листингах Zillow. |
web_data_booking_hotel_listings |
Получите структурированные объявления об отелях с сайта Booking.com. |
web_data_youtube_videos |
Структурированные видеоданные YouTube. Требуется действительный URL-адрес видео. |
scraping_browser_navigate |
Перейдите в браузере скрапбукинга на новый URL-адрес. |
scraping_browser_go_back |
Перейдите на предыдущую страницу. |
scraping_browser_go_forward |
Перейдите вперед в истории браузера. |
scraping_browser_click |
Щелкните определенный элемент на странице. Требуется селектор элементов. |
соскабливание_браузерных_ссылок |
Получает все ссылки на текущей странице вместе с их селекторами и текстом. |
scraping_browser_type |
Имитация ввода текста в поле ввода. |
scraping_browser_wait_for |
Дождитесь, пока определенный элемент станет видимым. |
scraping_browser_screenshot |
Сделайте снимок экрана текущей страницы. |
scraping_browser_get_html |
Получает полный HTML текущей страницы. Используйте с осторожностью, если содержимое полной страницы не нужно. |
scraping_browser_get_text |
Получение видимого текстового содержимого текущей страницы. |
О другой возможной интеграции см. нашу статью о веб-скреппинге с использованием серверов MCP.
Примечание: На сервер Bright Data MCP регулярно добавляются новые инструменты, что со временем делает его все более мощным и многофункциональным.
Узнайте, как воспользоваться этими инструментами с помощью Google ADK!
Как интегрировать Google ADK с сервером Bright Data MCP Server
В этом учебном разделе вы узнаете, как использовать Google ADK для создания мощного агента искусственного интеллекта. Он будет оснащен возможностями живого соскабливания, получения и преобразования данных, предоставляемыми сервером Bright Data MCP.
Изначально эта настройка была реализована Меиром Кадошем, поэтому обязательно ознакомьтесь с его оригинальным репозиторием на GitHub.
В частности, агент ИИ сможет:
- Получение URL-адресов из поисковых систем.
- Соскребите текст с этих веб-страниц.
- Генерируйте ответы на основе источников, используя извлеченные данные.
Примечание: Изменив подсказки в коде, вы можете легко адаптировать ИИ-агента к любому другому сценарию или случаю использования.
Выполните следующие шаги, чтобы создать свой агент Google ADK на базе Bright Data MCP в Python!
Пререквизиты
Чтобы следовать этому руководству, вам понадобятся:
- Локально установленныйPython 3.9 или выше.
- Node.js установлен локально.
- Система на базе UNIX, например Linux или macOS, или WSL(Windows Subsystem for Linux).
Примечание: Интеграция Google ADK с сервером Bright Data MCP в настоящее время не работает на Windows. Попытка запустить ее может вызвать ошибку NotImplementedError из этого раздела кода:
transport = await self._make_subprocess_transport(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
protocol, popen_args, False, stdin, stdout, stderr,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
bufsize, **kwargs)
^^^^^^^^^^^^^^^^^^
raise NotImplementedErrorПо этой причине в руководстве предполагается, что вы используете Linux, macOS или WSL.
Вам также понадобятся:
- Учетная запись Bright Data
- Ключ API Gemini
Это руководство поможет вам настроить учетные данные Gemini и Bright Data, когда это будет необходимо. Поэтому не беспокойтесь о них сейчас.
Хотя это и не обязательно, нижеприведенные сведения помогут вам извлечь максимум пользы из этого учебника:
- Общее представление о том, как функционирует MCP.
- Базовое понимание того, как работает Google ADK.
- Знакомство с сервером Bright Data MCP и его доступными инструментами.
- Некоторый опыт работы с асинхронным программированием на Python.
Шаг №1: Настройка проекта
Откройте терминал и создайте новую папку для агента скраппинга:
mkdir google_adk_mcp_agentПапка google_adk_mcp_agent будет содержать весь код для вашего агента ИИ на Python.
Затем перейдите в папку проекта и создайте в ней виртуальную среду:
cd google_adk_mcp_agent
python3 -m venv .venvОткройте папку проекта в предпочитаемой вами среде разработки Python. Мы рекомендуем использовать Visual Studio Code с расширением Python или PyCharm Community Edition.
Внутри google_adk_mcp_agent создайте подпапку с именем web_search_agent. Эта папка будет содержать основную логику вашего агента и должна включать следующие два файла:
__init__.py: Экспортирует логику изagent.py.agent.py: Содержит определение агента Google ADK.
Это структура папок, необходимая для правильной работы библиотеки Google ADK:

Теперь инициализируйте файл __init__.py следующей строкой:
from . import agentВместо этого в файле agent.py будет определена логика агента AI.
В терминале IDE активируйте виртуальную среду. В Linux или macOS выполните эту команду:
./.venv/bin/activateАналогично, в Windows запустите:
.venv/Scripts/activateВсе готово! Теперь у вас есть среда Python для создания агента искусственного интеллекта с помощью Google ADK и сервера Bright Data MCP.
Шаг #2: Настройка чтения переменных окружения
Ваш проект будет взаимодействовать со сторонними сервисами, такими как Gemini и Bright Data. Вместо того чтобы жестко кодировать ключи API и секреты аутентификации непосредственно в коде Python, лучше всего загружать их из переменных окружения.
Чтобы упростить эту задачу, мы воспользуемся библиотекой python-dotenv. Активировав виртуальную среду, установите ее, выполнив команду:
pip install python-dotenvВ файле agent.py импортируйте библиотеку и загрузите переменные окружения с помощью load_dotenv():
from dotenv import load_dotenv
load_dotenv()Это позволяет считывать переменные из локального файла .env. Таким образом, добавьте файл .env в каталог вложенного агента:

Теперь вы можете читать переменные окружения в своем коде с помощью этой строки кода:
env_value = os.getenv("<ENV_NAME>")Не забудьте импортировать модуль os из стандартной библиотеки Python:
import osОтлично! Теперь вы готовы прочитать секреты от env по безопасной интеграции со сторонними сервисами.
Шаг № 3: Начните работу с Google ADK
В активированной виртуальной среде установите библиотеку Google ADK Python, выполнив команду:
pip install google-adkЗатем откройте файл agent.py и добавьте в него следующие импорты:
from google.adk.agents import Agent, SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StdioServerParametersОни будут использоваться в следующих шагах для интеграции Google ADK.
Не забывайте, что Google ADK требует интеграции с поставщиком ИИ. В данном случае мы будем использовать Gemini- поскольку эта библиотека оптимизирована для моделей ИИ Google.
Если вы еще не получили ключ API, следуйте официальной документации Google. Войдите в свой аккаунт Google и получите доступ к Google AI Studio. Затем перейдите в раздел“Получить ключ API“, и вы увидите это модальное окно:
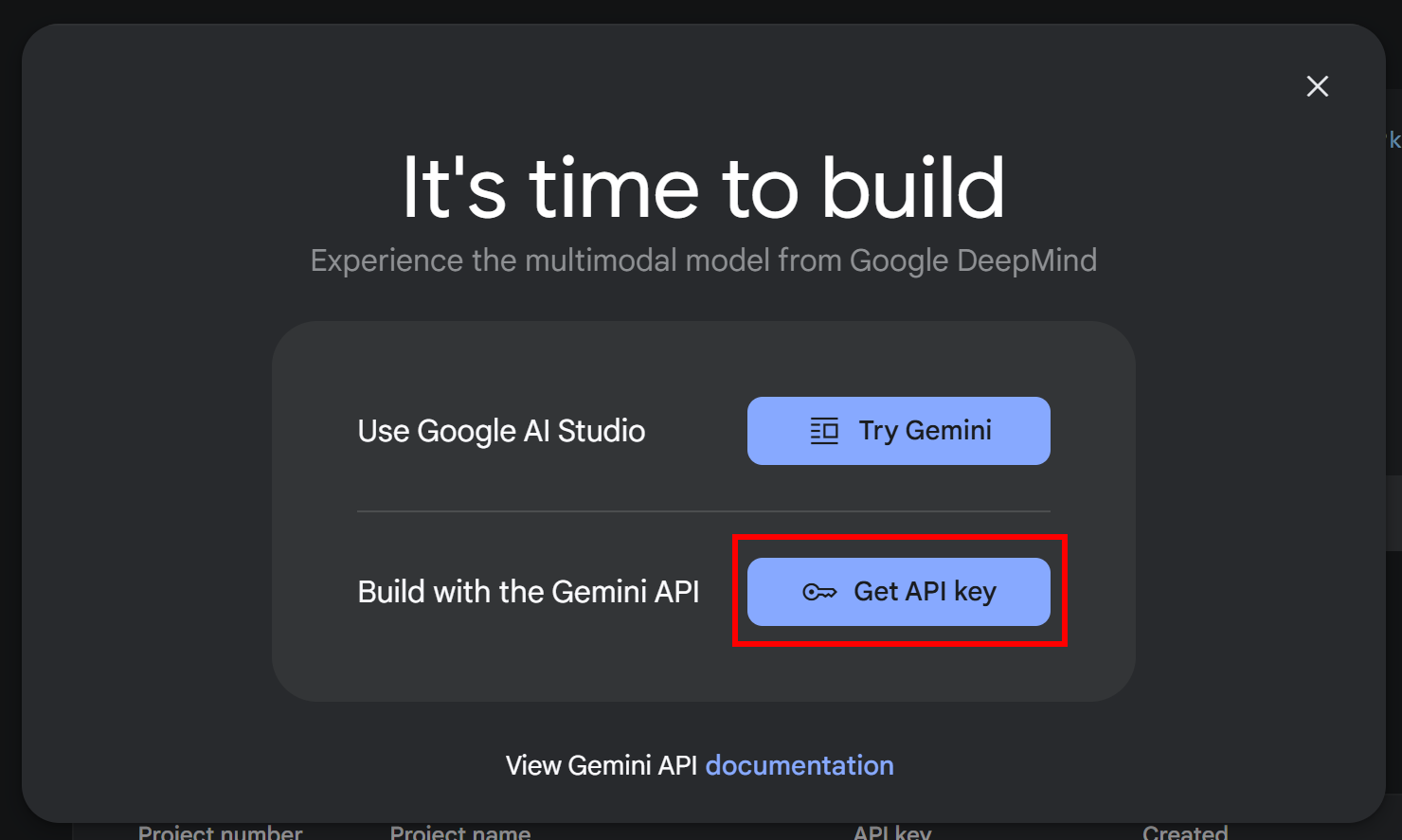
Нажмите кнопку “Получить ключ API”. В следующем окне нажмите кнопку “Создать ключ API”:
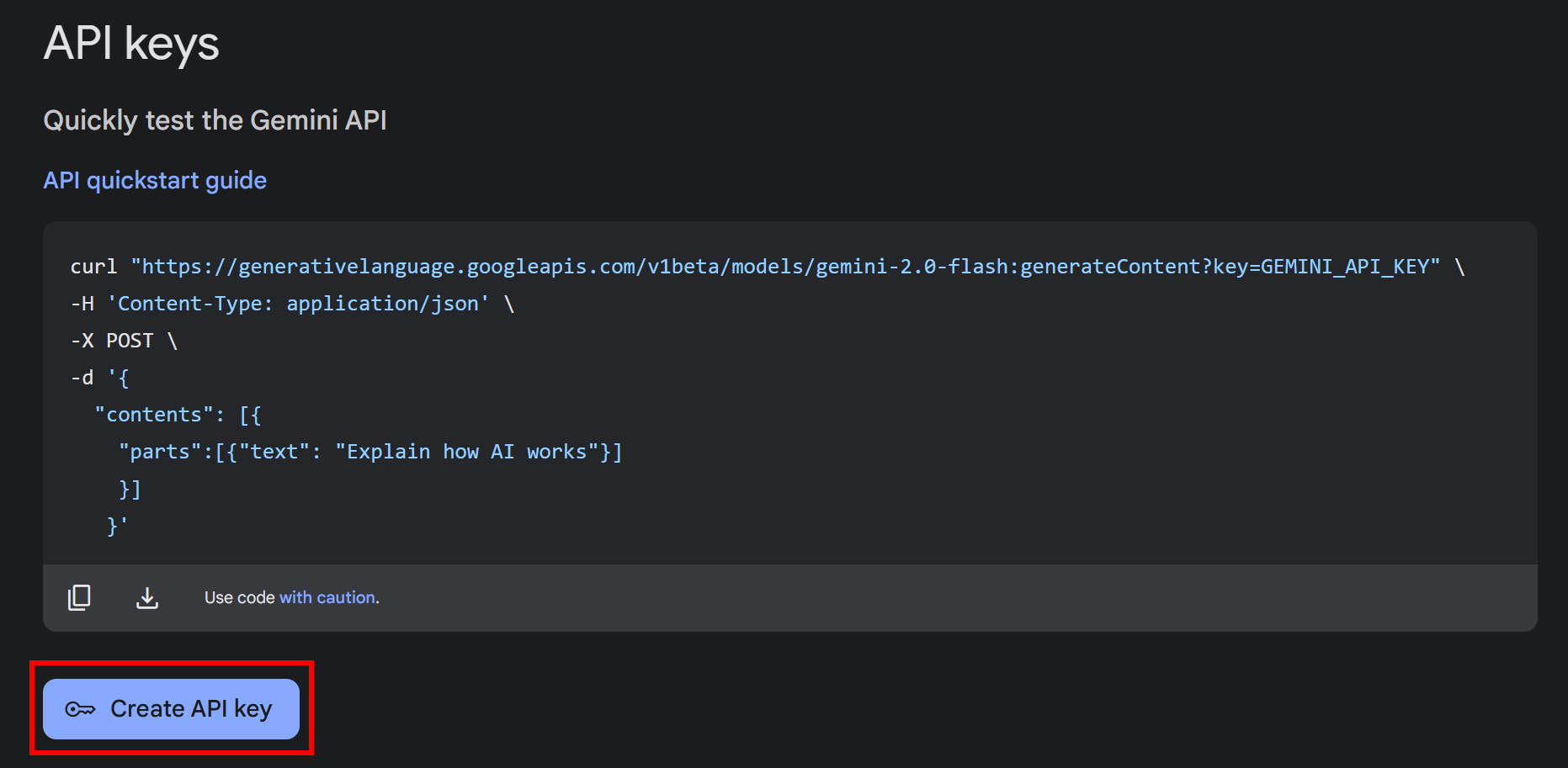
После создания вы увидите свой ключ в модальном окне:
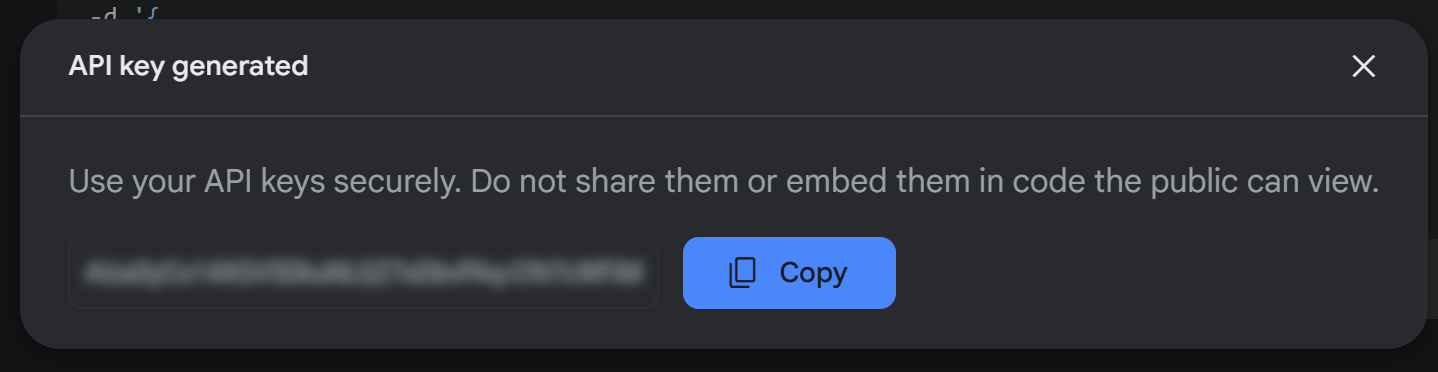
Скопируйте ключ и храните его в надежном месте. Обратите внимание, что с этим же ключом вы можете выполнять веб-скрептинг с помощью Gemini.
Примечание: Для этого урока достаточно бесплатного уровня Gemini. Платный уровень нужен только в том случае, если вам требуются более высокие тарифные лимиты или вы не хотите, чтобы ваши подсказки и ответы использовались для улучшения продуктов Google. Обратитесь к странице тарификации Gemini.
Теперь инициализируйте файл .env следующими переменными окружения:
GOOGLE_GENAI_USE_VERTEXAI="False"
GOOGLE_API_KEY="<YOUR_GEMINI_API_KEY>"Замените на фактический ключ, который вы только что сгенерировали. Никакого дополнительного кода в agent.py не требуется, так как библиотека google-adk автоматически ищет переменную окружения GOOGLE_API_KEY.
Аналогично, параметр GOOGLE_GENAI_USE_VERTEXAI определяет, должен ли Google ADK интегрироваться с Vertex AI. Установите значение "False", чтобы использовать Gemini API напрямую.
Потрясающе! Теперь вы можете использовать Gemini в Google ADK. Давайте продолжим начальную настройку трехстороннего решения, необходимого для интеграции.
Шаг #4: Настройка сервера Bright Data MCP Server
Если вы еще не сделали этого, [создайте учетную запись Bright Data](). Если у вас уже есть такая учетная запись, просто войдите в нее.
Далее следуйте официальным инструкциям:
- Получите свой API-токен Bright Data.
- Настройте Web Unlocker и Scraping Browser для интеграции с MCP.
В итоге вы получите:
- Токен API Bright Data.
- Зона Web Unlocker (здесь мы будем считать, что она имеет имя по умолчанию –
mcp_unlocker). - Скрапирование учетных данных аутентификации браузера в формате:
<BRIGHT_DATA_SB_USERNAME>:<BRIGHT_DATA_SB_PASSWORD>.
Теперь вы готовы к глобальной установке сервера Bright Data MCP в среде Node.js:
npm install -g @brightdata/mcpЗатем запустите сервер MCP с помощью пакета npm @brightdata/mcp:
API_TOKEN="<YOUR_BRIGHT_DATA_API_TOKEN>"
BROWSER_AUTH="<BRIGHT_DATA_SB_USERNAME>:<BRIGHT_DATA_SB_PASSWORD>"
npx -y @brightdata/mcpПриведенная выше команда устанавливает необходимые переменные окружения(API_TOKEN и BROWSER_AUTH) и запускает MCP-сервер локально. Если все настроено правильно, вы должны увидеть сообщение об успешном запуске сервера:
Checking for required zones...
Required zone "mcp_unlocker" already exists
Starting server...Потрясающе! Сервер Bright Data MCP работает как шарм.
Добавьте эти переменные окружения в файл .env в корне проекта Google ADK:
BRIGHT_DATA_API_TOKEN="<YOUR_BRIGHT_DATA_API_TOKEN>"
BRIGHT_DATA_BROWSER_AUTH="<BRIGHT_DATA_SB_USERNAME>:<BRIGHT_DATA_SB_PASSWORD>"Замените заполнители реальными значениями.
Затем прочитайте эти envs в своем коде с помощью:
BRIGHT_DATA_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
BRIGHT_DATA_BROWSER_AUTH = os.getenv("BRIGHT_DATA_BROWSER_AUTH")Отлично! Теперь у вас все готово для интеграции сервера Bright Data MCP с Google ADK. Но сначала нужно определить агентов ИИ.
Шаг #5: Определите агентов
Как уже говорилось во введении, агент Google ADK на базе MCP будет работать как агент по обобщению контента. Его основная задача – принимать данные от пользователя и выдавать высококачественное резюме с хорошими исходными данными.
В деталях агент будет следовать этому процессу:
- Интерпретируйте запрос пользователя и разбейте его на поисковые запросы в стиле Google.
- Обрабатывайте поисковые запросы с помощью субагента, который
:Polylang placeholder do not modify
- Создайте отчет в формате Markdown в ответ на исходный запрос пользователя. Процесс будет использовать только что собранный контент в качестве источника и включать ссылки для дальнейшего чтения.
Поскольку процесс естественным образом разбивается на три отдельных этапа, имеет смысл разделить агента ИИ верхнего уровня на три субагента:
- Планировщик: Преобразует сложные темы в правильно сформированные поисковые запросы.
- Исследователь: Выполняет поиск и извлекает значимую информацию из полученных веб-страниц.
- Издатель: Синтезирует результаты исследования в хорошо написанный и структурированный документ.
Реализуйте эти три агента в Google ADK с помощью следующего кода на Python:
- Планировщик:
def create_planner_agent():
return Agent(
name="planner",
model="gemini-2.0-flash",
description="Breaks down user input into focused search queries for research purposes.",
instruction="""
You are a research planning assistant. Your task is to:
1. Analyze the user's input topic or question.
2. Break it down into 3 to 5 focused and diverse search engine-like queries that collectively cover the topic.
3. Return your output as a JSON object in the following format:
{
"queries": ["query1", "query2", "query3"]
}
IMPORTANT:
- The queries should be phrased as if typed into a search engine.
""",
output_key="search_queries"
)- Исследователь:
def create_researcher_agent(mcp_tools):
return Agent(
name="researcher",
model="gemini-2.0-flash",
description="Performs web searches and extracts key insights from web pages using the configured tools.",
instruction="""
You are a web research agent. Your task is to:
1. Receive a list of search queries from the planner agent.
2. For each search query, apply the `search_engine` tool to get Google search results.
3. From the global results, select the top 3 most relevant URLs.
4. Pass each URL to the `scraping_browser_navigate` tool.
5. From each page, use the `scraping_browser_get_text` tool to extract the main page content.
6. Analyze the extracted text and summarize the key insights in the following JSON format:
[
{
"url": "https://example.com",
"insights": [
"Main insight one",
"Main insight two"
]
},
...
]
IMPORTANT:
- You are only allowed to use the following tools: `search_engine`, `scraping_browser_navigate`, and `scraping_browser_get_text`.
""",
tools=mcp_tools
)Примечание: Входной аргумент mcp_tools – это список, определяющий, с какими инструментами MCP может взаимодействовать агент. В следующем шаге вы увидите, как заполнить этот список, используя инструменты, предоставляемые сервером Bright Data MCP.
- Издатель:
“python
def create_publisher_agent():
return Agent(
name=”publisher”,
model=”gemini-2.0-flash”,
description=”Синтезирует результаты исследований во всеобъемлющий, хорошо структурированный итоговый документ.”,
instruction=”””
Вы – опытный писатель. Ваша задача – взять структурированные результаты исследований, полученные от агента-скрепера, и составить четкий, глубокий и хорошо организованный отчет.РУКОВОДСТВО: - Используйте правильную структуру, подобную структуре Markdown: заголовок (#), подзаголовок, введение, главы (##), подглавы (###) и заключение (##). - Включайте контекстные ссылки (где это необходимо), используя URL-адреса из результатов работы агента-исследователя. - Поддерживайте профессиональный, объективный и информативный тон. - Не ограничивайтесь пересказом выводов - синтезируйте информацию, связывайте идеи и представляйте их в виде связного повествования. """)
Note that each AI agent prompt corresponds to one specific step in the overall 3-step workflow. In other words, each sub-agent is responsible for a distinct task within the process.
### Step #6: Add the MCP Integration
As mentioned in the previous step, the `reasearch` agent depends on the tools exported by the Bright Data Web MCP server. Retrieve them with this function:python
async def initialize_mcp_tools():
print(“Подключение к Bright Data MCP…”)
tools, exit_stack = await MCPToolset.from_server(
connection_params=StdioServerParameters(
command=’npx’,
args=[“-y”, “@brightdata/mcp”],
env={
“API_TOKEN”: BRIGHT_DATA_API_TOKEN,
“BROWSER_AUTH”: BRIGHT_DATA_BROWSER_AUTH,
}
)
)
print(f “Набор инструментов MCP успешно создан с помощью {len(tools)} инструментов”)
tool_names = [tool.name for tool in tools]
print(f “Доступные инструменты включают: {‘, ‘.join(tool_names)}”)
print("MCP initialization complete!")
return tools, exit_stackДля загрузки инструментов MCP Google ADK предоставляет функцию MCPToolset.from_server(). Этот метод принимает команду, используемую для запуска сервера MCP, а также все необходимые переменные окружения. В данном случае команда, настроенная в коде, соответствует команде, которую вы использовали в шаге № 4 для локального тестирования сервера MCP.
⚠️ Предупреждение: Настройка инструментов MCP и упоминание их в подсказках агента не гарантирует, что библиотека действительно будет их использовать. В конечном итоге LLM сам решает, нужны ли эти инструменты для выполнения задачи. Помните, что интеграция MCP в Google ADK все еще находится на ранних стадиях и может не всегда вести себя так, как ожидается.
Отличная работа! Осталось только вызвать эту функцию и интегрировать полученные инструменты в агент, который последовательно запускает ваши субагенты.
Шаг #7: Создание корневого агента
Google ADK поддерживает несколько типов агентов. В данном случае ваш рабочий процесс следует четкой последовательности шагов, поэтому корневой последовательный агент будет правильным выбором. Вы можете определить его следующим образом:
async def create_root_agent():
# Load the MCP tools
mcp_tools, exit_stack = await initialize_mcp_tools()
# Define an agent that applies the configured sub-agents sequentially
root_agent = SequentialAgent(
name="web_research_agent",
description="An agent that researches topics on the web and creates comprehensive reports.",
sub_agents=[
create_planner_agent(),
create_researcher_agent(mcp_tools),
create_publisher_agent(),
]
)
return root_agent, exit_stackЧтобы это работало, Google ADK ожидает, что вы определите переменную root_agent в вашем файле agent.py. Добейтесь этого с помощью:
root_agent = create_root_agent()Примечание: Не беспокойтесь о вызове async-функции без await. Именно такой подход рекомендуется в официальной документации Google ADK. Таким образом, фреймворк выполнит асинхронное выполнение за вас.
Отличная работа! Интеграция между сервером Bright Data MCP и Google ADK завершена.
Шаг № 8: Соберите все вместе
Теперь ваш файл agent.py должен содержать:
from dotenv import load_dotenv
import os
from google.adk.agents import Agent, SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StdioServerParameters
# Load the environment variables from the .env file
load_dotenv()
# Read the envs for integration with the Bright Data Web MCP server
BRIGHT_DATA_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
BRIGHT_DATA_BROWSER_AUTH = os.getenv("BRIGHT_DATA_BROWSER_AUTH")
# Define the functions for the creation of the required sub-agents
def create_planner_agent():
return Agent(
name="planner",
model="gemini-2.0-flash",
description="Breaks down user input into focused search queries for research purposes.",
instruction="""
You are a research planning assistant. Your task is to:
1. Analyze the user"s input topic or question.
2. Break it down into 3 to 5 focused and diverse search engine-like queries that collectively cover the topic.
3. Return your output as a JSON object in the following format:
{
"queries": ["query1", "query2", "query3"]
}
IMPORTANT:
- The queries should be phrased as if typed into a search engine.
""",
output_key="search_queries"
)
def create_researcher_agent(mcp_tools):
return Agent(
name="researcher",
model="gemini-2.0-flash",
description="Performs web searches and extracts key insights from web pages using the configured tools.",
instruction="""
You are a web research agent. Your task is to:
1. Receive a list of search queries from the planner agent.
2. For each search query, apply the `search_engine` tool to get Google search results.
3. From the global results, select the top 3 most relevant URLs.
4. Pass each URL to the `scraping_browser_navigate` tool.
5. From each page, use the `scraping_browser_get_text` tool to extract the main page content.
6. Analyze the extracted text and summarize the key insights in the following JSON format:
[
{
"url": "https://example.com",
"insights": [
"Main insight one",
"Main insight two"
]
},
...
]
IMPORTANT:
- You are only allowed to use the following tools: `search_engine`, `scraping_browser_navigate`, and `scraping_browser_get_text`.
""",
tools=mcp_tools
)
def create_publisher_agent():
return Agent(
name="publisher",
model="gemini-2.0-flash",
description="Synthesizes research findings into a comprehensive, well-structured final document.",
instruction="""
You are an expert writer. Your task is to take the structured research output from the scraper agent and craft a clear, insightful, and well-organized report.
GUIDELINES:
- Use proper Markdown-like structure: title (#), subtitle, introduction, chapters (##), subchapters (###), and conclusion (##).
- Integrate contextual links (where needed) using the URLs from the output of the researcher agent.
- Maintain a professional, objective, and informative tone.
- Go beyond restating findings—synthesize the information, connect ideas, and present them as a coherent narrative.
"""
)
# To load the MCP tools exposed by the Bright Data Web MCP server
async def initialize_mcp_tools():
print("Connecting to Bright Data MCP...")
tools, exit_stack = await MCPToolset.from_server(
connection_params=StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_TOKEN,
"BROWSER_AUTH": BRIGHT_DATA_BROWSER_AUTH,
}
)
)
print(f"MCP Toolset created successfully with {len(tools)} tools")
tool_names = [tool.name for tool in tools]
print(f"Available tools include: {", ".join(tool_names)}")
print("MCP initialization complete!")
return tools, exit_stack
# Define the root agent required by Google ADK to start
async def create_root_agent():
# Load the MCP tools
mcp_tools, exit_stack = await initialize_mcp_tools()
# Define an agent that applies the configured sub-agents sequentially
root_agent = SequentialAgent(
name="web_research_agent",
description="An agent that researches topics on the web and creates comprehensive reports.",
sub_agents=[
create_planner_agent(),
create_researcher_agent(mcp_tools),
create_publisher_agent(),
]
)
return root_agent, exit_stack
# Google ADK will load the root agent in the web UI or CLI
root_agent = create_root_agent()В корневой папке проекта и с включенной виртуальной средой запустите агента ИИ в веб-интерфейсе:
adk webСледующее приложение будет запущено на сайте http://localhost:8000:

После выполнения первого запроса библиотека Google ADK попытается получить доступ к переменной root_agent. Это вызовет функцию create_root_agent(), которая, в свою очередь, вызовет initialize_mcp_tools().
В результате в терминале вы увидите:
Connecting to Bright Data MCP...
Checking for required zones...
Required zone "mcp_unlocker" already exists
Starting server...
MCP Toolset created successfully with 30 tools
Available tools include: search_engine, scrape_as_markdown, scrape_as_html, session_stats, web_data_amazon_product, web_data_amazon_product_reviews, web_data_linkedin_person_profile, web_data_linkedin_company_profile, web_data_zoominfo_company_profile, web_data_instagram_profiles, web_data_instagram_posts, web_data_instagram_reels, web_data_instagram_comments, web_data_facebook_posts, web_data_facebook_marketplace_listings, web_data_facebook_company_reviews, web_data_x_posts, web_data_zillow_properties_listing, web_data_booking_hotel_listings, web_data_youtube_videos, scraping_browser_navigate, scraping_browser_go_back, scraping_browser_go_forward, scraping_browser_links, scraping_browser_click, scraping_browser_type, scraping_browser_wait_for, scraping_browser_screenshot, scraping_browser_get_text, scraping_browser_get_html
MCP initialization complete!Как видите, Google ADK корректно загрузил 30 инструментов Bright Data MCP.
Теперь после ввода запроса в чате агент ИИ будет:
- Преобразуйте ваш запрос в ключевые фразы для поисковых систем.
- Отправьте эти ключевые фразы в инструмент
Search_engineMCP, чтобы:Polylang placeholder do not modify
- Сгенерируйте контекстно-значимую статью или отчет на основе этих данных, чтобы ответить на ваш запрос.
Обратите внимание, что, как упоминалось в шаге № 6, Gemini (или любой другой LLM) иногда может полностью пропустить инструменты MCP. Это верно, даже если они настроены в коде и явно упомянуты в подсказках субагентов. Более того, он может вернуть прямой ответ или запустить субагенты без использования рекомендуемых инструментов MCP.
Чтобы избежать этого побочного эффекта, тщательно настраивайте подсказки субагентов. Также помните, что интеграция MCP в Google ADK все еще развивается и не всегда может вести себя так, как ожидается. Поэтому убедитесь, что библиотека обновлена.
Предположим, вы хотите узнать биографию недавно избранного Папы Римского. Обычно LLM затрудняются с запросами, связанными с текущими событиями. Но благодаря API SERP и возможностям веб-скрапинга Bright Data ваш ИИ-агент сможет без труда получать и обобщать информацию в режиме реального времени:

И вуаля! Миссия выполнена.
Заключение
В этой статье вы узнали, как использовать фреймворк Google ADK в сочетании с Bright Data MCP для создания мощного агента искусственного интеллекта на Python.
Как было показано, сочетание многофункционального сервера MCP с Google ADK позволяет создавать агентов искусственного интеллекта, способных получать данные из Интернета в режиме реального времени и многое другое. Это лишь один из примеров того, как инструменты и услуги Bright Data позволяют расширить возможности автоматизации, основанной на искусственном интеллекте.
Ознакомьтесь с нашими решениями для разработки агентов искусственного интеллекта:
- Автономные агенты искусственного интеллекта: Поиск, доступ и взаимодействие с любыми веб-сайтами в режиме реального времени с помощью мощного набора API.
- Вертикальные приложения искусственного интеллекта: создавайте надежные пользовательские конвейеры данных для извлечения веб-данных из отраслевых источников.
- Базовые модели: Доступ к совместимым наборам данных веб-масштаба для предварительного обучения, оценки и тонкой настройки.
- Мультимодальный ИИ: воспользуйтесь крупнейшим в мире хранилищем изображений, видео и аудио, оптимизированных для ИИ.
- Поставщики данных: Подключайтесь к надежным поставщикам, чтобы получать высококачественные, готовые к искусственному интеллекту наборы данных в масштабе.
- Пакеты данных: Получайте курируемые, готовые к использованию, структурированные, обогащенные и аннотированные наборы данных.
Для получения дополнительной информации изучите наш центр искусственного интеллекта.
Создайте учетную запись Bright Data и попробуйте все наши продукты и услуги для разработки агентов искусственного интеллекта!




