

Финансовые рынки ежесекундно генерируют огромное количество данных. NASDAQ – одна из крупнейших в мире бирж, на которой представлены такие крупные компании, как Apple, Microsoft, Tesla и Amazon.
Если вы создаете торговые алгоритмы, исследовательские панели или финтех-приложения, сбор этих финансовых данных представляет собой как значительные возможности, так и технические проблемы. В этом руководстве рассматриваются 3 проверенных метода сбора финансовых данных с NASDAQ: прямой доступ к API через внутренние конечные точки, использование корпоративной прокси-инфраструктуры для масштабирования и использование веб-скрепинга на основе искусственного интеллекта с помощью MCP (Model Context Protocol).
Понимание ландшафта данных NASDAQ
NASDAQ предоставляет обширные рыночные данные, которые идеально подходят для исследований, бэктестинга и аналитических приложений. Вот к чему вы обычно можете получить доступ:
- Ценовые данные – цена последней сделки, дневные максимумы/минимумы, цены открытия/закрытия, объем торгов и процентные изменения для котирующихся акций.
- Исторические данные – ежедневные данные OHLC (Open, High, Low, Close), истории дивидендов, дробления акций и исторические объемы торгов.
- Информация о компании – основные сведения о компании, отраслевая классификация, ссылки на документы Комиссии по ценным бумагам и биржам США и новости компании
- Дополнительные возможности – интерактивные графики, календари прибылей и данные об институциональных холдингах.
Трейдеры и инвесторы используют бэктестирование для анализа исторических показателей стратегий перед их применением в реальной торговле. Предприятия используют эти рыночные данные для конкурентной разведки, что помогает им отслеживать деятельность конкурентов и выявлять рыночные тенденции и возможности. Для более сложных сценариев изучите наши комплексные примеры использования финансовых данных.
Теперь давайте посмотрим, как получить эти данные.
Методология извлечения данных
Современные финансовые сайты, такие как NASDAQ, yahoo finance и google finance, построены как одностраничные приложения, использующие JavaScript для отображения динамического контента. Вместо того чтобы разбирать хрупкий HTML, надежнее напрямую вызывать их внутренние конечные точки JSON API, поскольку ответы JSON чище и стабильнее.
Вот как определить конечные точки NASDAQ в формате JSON:
- Откройте любую страницу с бегущей строкой (например, https://www.nasdaq.com/market-activity/stocks/aapl) и откройте Инструменты разработчика вашего браузера.
- На вкладке Сеть выберите фильтр Fetch/XHR, чтобы изолировать трафик API.
- Перезагрузите страницу, чтобы перехватить все запросы.
После перезагрузки вы увидите такие запросы, как market-info, chart, watchlist и некоторые другие.
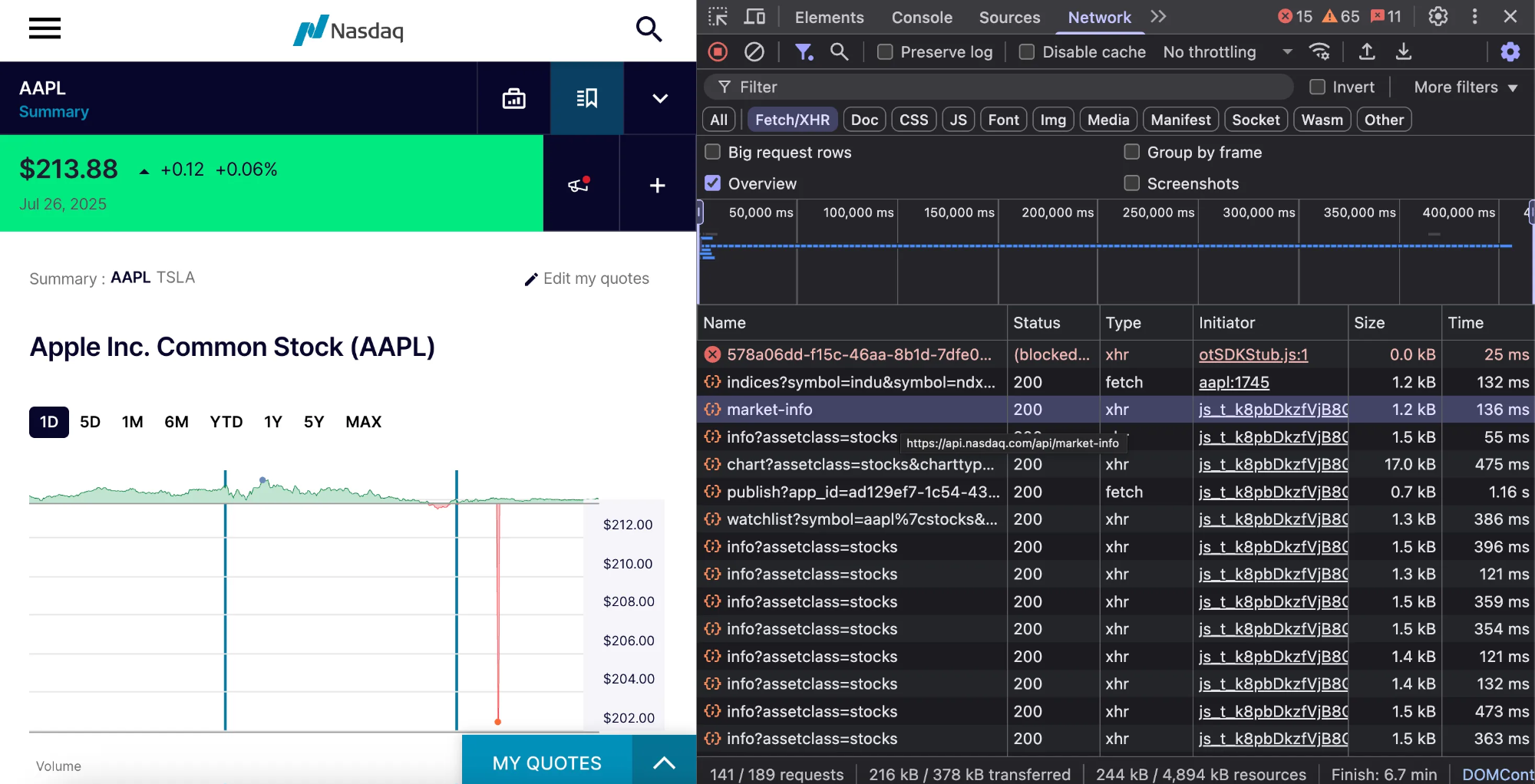
Щелкните любой запрос, чтобы просмотреть полезную нагрузку в формате JSON. Например, запрос market-info отображает обширную структуру данных с информацией о рынке в реальном времени.
Определив конечные точки, давайте настроим необходимые инструменты.
Пререквизиты
- Python 3.x
- Редактор кода (VS Code, PyCharm и т. д.)
- Базовое знакомство с инструментами разработчика Chrome
- Понимание основ скрапбукинга на Python и библиотек для извлечения данных
- Библиотека
requests. Установите ее с помощью командыpip install requests
Если вы новичок в библиотеке requests, наше руководство по Python requests охватывает все техники, которые мы будем использовать в этом уроке.
Подготовив эти инструменты, давайте рассмотрим первый метод.
Метод 1 – веб-скраппинг с прямым доступом к API
Ключевые конечные точки, которые мы будем использовать, предоставляют исчерпывающие рыночные данные в виде чистых ответов в формате JSON.
Состояние рынка и график торгов
Эта конечная точка возвращает информацию о состоянии американского рынка с обратным отсчетом времени и полным расписанием торгов. Она охватывает обычные часы, предрыночные и внеурочные сессии, предоставляя предыдущие и следующие даты торгов в различных форматах временных меток для упрощения интеграции.
Конечная точка – https://api.nasdaq.com/api/market-info.
Вот простая реализация:
import requests
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
response = requests.get('https://api.nasdaq.com/api/market-info', headers=headers)
print(response.json())API возвращает данные о состоянии рынка следующим образом:
{
"data": {
"country": "U.S.",
"marketIndicator": "Market Open",
"uiMarketIndicator": "Market Open",
"marketCountDown": "Market Closes in 3H 7M",
"preMarketOpeningTime": "Jul 29, 2025 04:00 AM ET",
"preMarketClosingTime": "Jul 29, 2025 09:30 AM ET",
"marketOpeningTime": "Jul 29, 2025 09:30 AM ET",
"marketClosingTime": "Jul 29, 2025 04:00 PM ET",
"afterHoursMarketOpeningTime": "Jul 29, 2025 04:00 PM ET",
"afterHoursMarketClosingTime": "Jul 29, 2025 08:00 PM ET",
"previousTradeDate": "Jul 28, 2025",
"nextTradeDate": "Jul 30, 2025",
"isBusinessDay": true,
"mrktStatus": "Open",
"mrktCountDown": "Closes in 3H 7M",
"pmOpenRaw": "2025-07-29T04:00:00",
"ahCloseRaw": "2025-07-29T20:00:00",
"openRaw": "2025-07-29T09:30:00",
"closeRaw": "2025-07-29T16:00:00"
}
}Отлично! Это показывает API-подход для получения данных о рыночном тайминге в реальном времени.
Данные о котировках акций
Конечная точка котировок NASDAQ предоставляет подробные данные о любой публично торгуемой компании, включая последние цены, объем торгов, информацию о компании и рыночную статистику.
Конечная точка – https://api.nasdaq.com/api/quote/{symbol}/info?assetclass=stocks. Для получения данных об акциях необходимо указать символ тикера (AAPL, TSLA) и установить класс активов на stocks.
Вот простой фрагмент кода:
import requests
def get_stock_info(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/info?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
stock_info = get_stock_info('AAPL', headers)
print(stock_info)API возвращает данные о котировках акций следующим образом:
{
"data": {
"symbol": "AAPL",
"companyName": "Apple Inc. Common Stock",
"stockType": "Common Stock",
"exchange": "NASDAQ-GS",
"isNasdaqListed": true,
"isNasdaq100": true,
"isHeld": false,
"primaryData": {
"lastSalePrice": "$211.9388",
"netChange": "-2.1112",
"percentageChange": "-0.99%",
"deltaIndicator": "down",
"lastTradeTimestamp": "Jul 29, 2025 12:51 PM ET",
"isRealTime": true,
"bidPrice": "$211.93",
"askPrice": "$211.94",
"bidSize": "112",
"askSize": "235",
"volume": "23,153,569",
"currency": null
},
"secondaryData": null,
"marketStatus": "Open",
"assetClass": "STOCKS",
"keyStats": {
"fiftyTwoWeekHighLow": {
"label": "52 Week Range:",
"value": "169.21 - 260.10"
},
"dayrange": {
"label": "High/Low:",
"value": "211.51 - 214.81"
}
},
"notifications": [
{
"headline": "UPCOMING EVENTS",
"eventTypes": [
{
"message": "Earnings Date : Jul 31, 2025",
"eventName": "Earnings Date",
"url": {
"label": "AAPL Earnings Date : Jul 31, 2025",
"value": "/market-activity/stocks/AAPL/earnings"
},
"id": "upcoming_events"
}
]
}
]
}
}Основные показатели компании и ключевые метрики
Сводный API NASDAQ предоставляет основные финансовые данные, включая рыночную стоимость, объем торгов, информацию о дивидендах и отраслевую классификацию для любого символа акций.
Когда вы заходите на страницу компании NASDAQ и прокручиваете страницу до раздела “Основные данные”, ваш браузер вызывает определенную конечную точку. Эта конечная точка – https://api.nasdaq.com/api/quote/{SYMBOL}/summary?assetclass=stocks – содержит все фундаментальные данные компании.
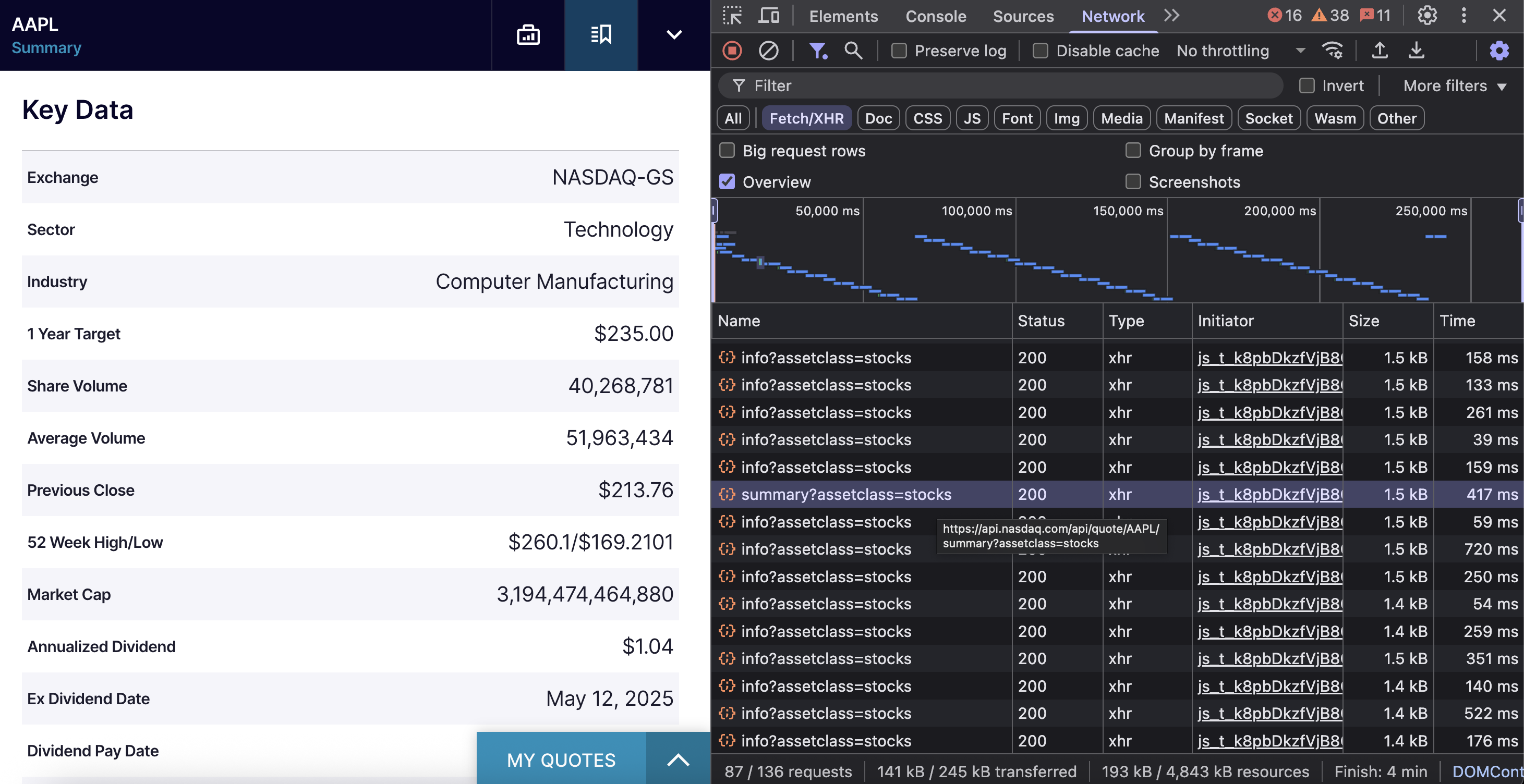
Вот фрагмент кода:
import requests
def get_company_data(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/summary?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
company_data = get_company_data('AAPL', headers)
print(company_data)API возвращает данные о ключах компании следующим образом:
{
"data": {
"symbol": "AAPL",
"summaryData": {
"Exchange": {
"label": "Exchange",
"value": "NASDAQ-GS"
},
"Sector": {
"label": "Sector",
"value": "Technology"
},
"Industry": {
"label": "Industry",
"value": "Computer Manufacturing"
},
"OneYrTarget": {
"label": "1 Year Target",
"value": "$235.00"
},
"TodayHighLow": {
"label": "Today's High/Low",
"value": "$214.81/$210.825"
},
"ShareVolume": {
"label": "Share Volume",
"value": "25,159,852"
},
"AverageVolume": {
"label": "Average Volume",
"value": "51,507,684"
},
"PreviousClose": {
"label": "Previous Close",
"value": "$214.05"
},
"FiftTwoWeekHighLow": {
"label": "52 Week High/Low",
"value": "$260.1/$169.2101"
},
"MarketCap": {
"label": "Market Cap",
"value": "3,162,213,080,720"
},
"AnnualizedDividend": {
"label": "Annualized Dividend",
"value": "$1.04"
},
"ExDividendDate": {
"label": "Ex Dividend Date",
"value": "May 12, 2025"
},
"DividendPaymentDate": {
"label": "Dividend Pay Date",
"value": "May 15, 2025"
},
"Yield": {
"label": "Current Yield",
"value": "0.49%"
}
},
"assetClass": "STOCKS",
"additionalData": null,
"bidAsk": {
"Bid * Size": {
"label": "Bid * Size",
"value": "$211.75 * 280"
},
"Ask * Size": {
"label": "Ask * Size",
"value": "$211.79 * 225"
}
}
}
}График NASDAQ и исторические данные
NASDAQ предоставляет данные о графиках через специализированные конечные точки, предназначенные для различных временных рамок и гранулярности данных.
NASDAQ распределяет данные графика по конечным точкам в зависимости от требований к временным рамкам:
- Внутридневная конечная точка – поминутные данные для таймфреймов 1D и 5D.
- Историческая конечная точка – ежедневные данные OHLC для таймфреймов 1M, 6M, YTD, 1Y, 5Y и MAX.
Данные внутридневного графика (1D таймфрейм)
Эта конечная точка идеально подходит для анализа поминутного движения цен во время торговых сессий.
Конечная точка – https://api.nasdaq.com/api/quote/{symbol}/chart?assetclass=stocks&charttype=rs.
Конечная точка требует три параметра: символ биржевого тикера, класс активов – акции для данных по акциям и charttype=rs для регулярных торговых часов.
Вот простая реализация:
import requests
def get_chart_data(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/chart?assetclass=stocks&charttype=rs'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
chart_data = get_chart_data('AAPL', headers)
print(chart_data)API возвращает внутридневные данные компании в следующей структуре:
{
"data": {
"chart": [
{
"w": 995, // Trading volume for this minute
"x": 1753416000000, // Timestamp (milliseconds)
"y": 214.05, // Price
"z": { // Human-readable format
"time": "4:00 AM",
"shares": "995",
"price": "$214.05",
"prevCls": "213.7600" // Previous day's close
}
}
]
}
}Для 5-дневных минутных данных необходимо использовать другую конечную точку:
https://charting.nasdaq.com/data/charting/intraday?symbol=AAPL&mostRecent=5&includeLatestIntradayData=1Это возвращает данные, структурированные следующим образом (обрезано для краткости):
{
"companyName": "APPLE INC",
"marketData": [
{
"Date": "2025-07-22 09:30:00",
"Value": 212.639999,
"Volume": 2650933
},
{
"Date": "2025-07-22 09:31:00",
"Value": 212.577103,
"Volume": 232676
}
],
"latestIntradayData": {
"Date": "2025-07-28 16:00:00",
"High": 214.845001,
"Low": 213.059998,
"Open": 214.029999,
"Close": 214.050003,
"Change": 0.169998,
"PctChange": 0.079483,
"Volume": 37858016
}
}Исторические данные (1M, 6M, YTD, 1Y, 5Y, MAX)
Для более длительных временных периодов NASDAQ предоставляет ежедневные данные OHLC по исторической конечной точке.
Конечная точка – https://charting.nasdaq.com/data/charting/historical?symbol={symbol}&date={start}~{end}&.
Для конечной точки требуется символ биржевого тикера и диапазон дат в формате “YYYY-MM-DD~YYY-MM-DD”.
Вот пример кода:
import requests
def get_historical_data(symbol, headers):
url = f"https://charting.nasdaq.com/data/charting/historical?symbol={symbol}&date=2024-08-24~2024-10-23&"
response = requests.get(url, headers=headers)
return response.json()
headers = {
"accept": "*/*",
"referer": "https://charting.nasdaq.com/dynamic/chart.html",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
}
historical_data = get_historical_data("AAPL", headers)
print(historical_data)В результате получаются данные, структурированные следующим образом (обрезано для краткости):
{
"companyName": "APPLE INC",
"marketData": [
{
"Date": "2024-11-18 00:00:00",
"High": 229.740000,
"Low": 225.170000,
"Open": 225.250000,
"Close": 228.020000,
"Volume": 44686020
}
],
"latestIntradayData": {
"Date": "2025-07-25 16:00:00",
"High": 215.240005,
"Low": 213.399994,
"Open": 214.699997,
"Close": 213.880005,
"Change": 0.120010,
"PctChange": 0.056143,
"Volume": 40268780
}
}Владения ETF
API NASDAQ ETF Holdings определяет биржевые фонды (ETF), которые включают определенную акцию в число 10 крупнейших держателей. Эти данные показывают структуру институционального владения и помогают выявить соответствующие инвестиционные возможности.
Конечная точка – https://api.nasdaq.com/api/company/{symbol}/holdings?assetclass=stocks.
Вот реализация:
import requests
def get_holdings_data(symbol, headers):
url = f'https://api.nasdaq.com/api/company/{symbol}/holdings?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
holdings_data = get_holdings_data('AAPL', headers)
print(holdings_data)API возвращает данные по двум категориям ETF: все ETF, которые держат акции в топ-10, и конкретные ETF, зарегистрированные на NASDAQ, с теми же критериями. Ответ включает в себя весовые коэффициенты, данные о производительности ETF и сведения о фонде.
{
"data": {
"heading": "ETFs with AAPL as a Top 10 Holding*",
"holdings": { ... }, // All ETFs with the stock as top 10 holding
"nasdaqheading": "Nasdaq Listed ETFs where AAPL is a top 10 holding*",
"nasdaqHoldings": { ... } // Specifically NASDAQ-listed ETFs
}
}Последние новости компании
Эта конечная точка получает последние новостные статьи, связанные с определенными символами акций. Она обеспечивает подробное освещение новостей, включая заголовки, детали публикации, связанные символы и метаданные статьи.
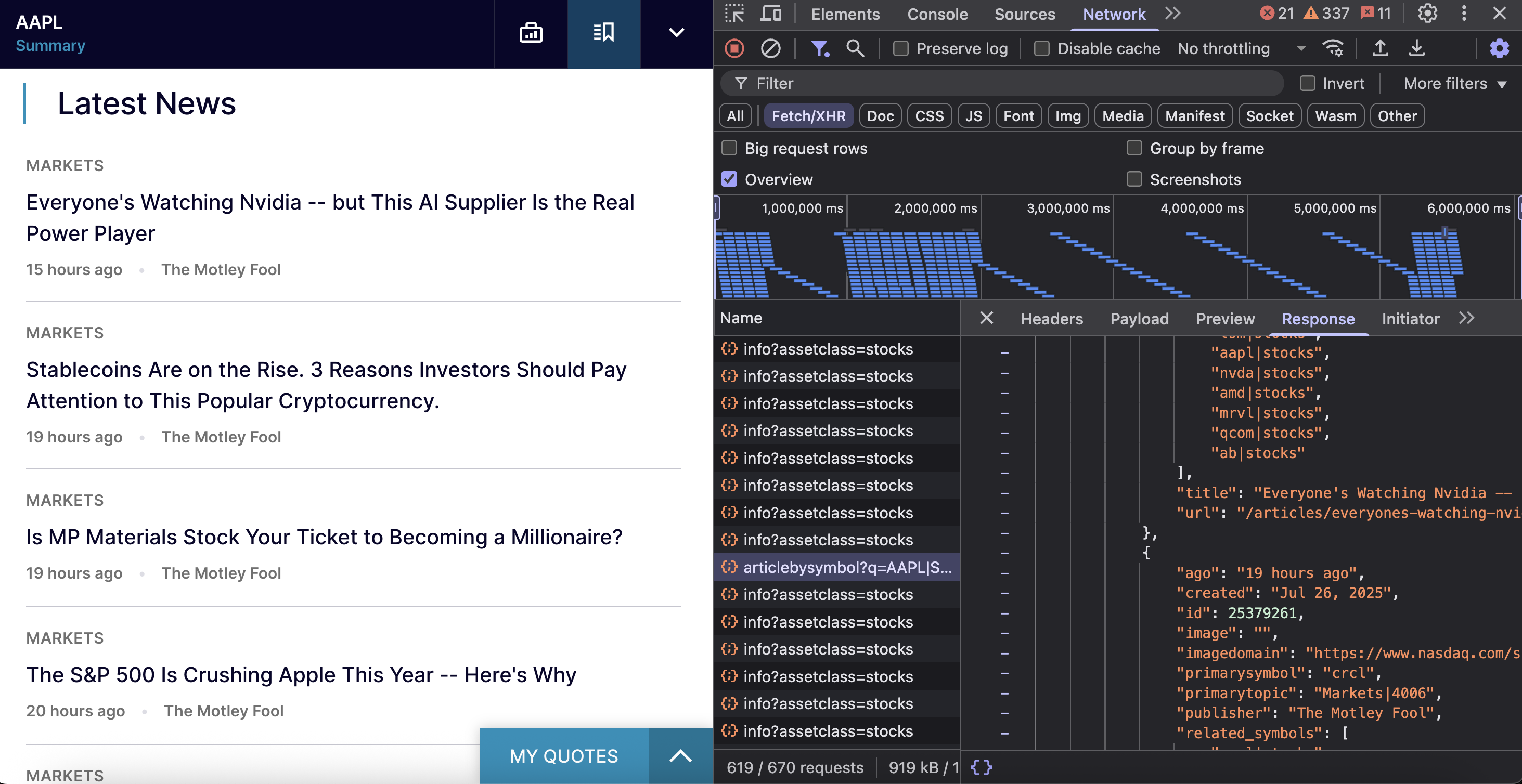
Конечная точка – https://www.nasdaq.com/api/news/topic/articlebysymbol?q={symbol}|STOCKS&offset={offset}&limit={limit}&fallback=true.
Что нужно для прохождения:
- q – символ биржевого тикера с суффиксом |STOCKS (например, AAPL|STOCKS или MSFT|STOCKS)
- смещение – количество записей, которые необходимо пропустить для пагинации (начинается с 0)
- limit – максимальное количество возвращаемых статей (по умолчанию 10)
- fallback – булевский флаг, определяющий поведение fallback (рекомендуется: true).
Вот краткая реализация:
import requests
def get_news_data(symbol, headers):
url = f'https://www.nasdaq.com/api/news/topic/articlebysymbol?q={symbol}|STOCKS&offset=0&limit=10&fallback=true'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
news_data = get_news_data('AAPL', headers)
print(news_data)API возвращает структурированный ответ в формате JSON, который выглядит следующим образом:
{
"data": {
"message": null,
"rows": [...], // Array of news articles
"totalrecords": 8905 // Total number of available articles
}
}Каждая новостная статья содержит подробную информацию:
{
"ago": "15 hours ago",
"created": "Jul 26, 2025",
"id": 25379586,
"image": "",
"imagedomain": "https://www.nasdaq.com/sites/acquia.prod/files",
"primarysymbol": "tsm",
"primarytopic": "Markets|4006",
"publisher": "The Motley Fool",
"related_symbols": [
"tsm|stocks",
"aapl|stocks",
"nvda|stocks"
],
"title": "Everyone's Watching Nvidia -- but This AI Supplier Is the Real Power Player",
"url": "/articles/everyones-watching-nvidia-ai-supplier-real-power-player"
}API использует простую пагинацию на основе смещения, чтобы помочь вам эффективно перемещаться по тысячам статей. Вот как работает пагинация:
- Первая партия –
offset=0&limit=10извлекает статьи 1-10 - Вторая партия –
offset=10&limit=10извлекает статьи 11-20 - Третья партия –
offset=20&limit=10извлекает статьи 21-30
Чтобы получить следующий набор статей, увеличьте смещение на ваше предельное значение.
Метод 2 – масштабирование данных NASDAQ с помощью прокси-серверов жилых помещений
Хотя прямой доступ к API хорошо подходит для большинства случаев использования, масштабирование сбора данных на уровне предприятия приводит к возникновению серьезных проблем с веб-скреппингом. При больших объемах операций возникают ограничения по скорости, системы обнаружения ботов и блокировки IP-адресов, которые могут полностью остановить сбор данных.
Основным узким местом в крупномасштабном скраппинге является управление репутацией IP-адресов. На финансовых сайтах, таких как NASDAQ, установлены передовые системы защиты от ботов, которые активно отслеживают шаблоны и частоту запросов с отдельных IP-адресов. Когда эти системы обнаруживают автоматизированные схемы трафика с одного IP-адреса, они применяют блокировки – от ограничения скорости до полного запрета IP-адресов.
Резидентные прокси-серверы решают эти проблемы, направляя запросы через реальные домашние интернет-соединения. Таким образом, ваши запросы выглядят как легитимный пользовательский трафик, распределенный по разным географическим точкам, что значительно снижает вероятность срабатывания систем защиты от ботов.
Наша инфраструктура прокси-серверов для жилых домов предоставляет 150 млн IP-адресов в 195 с лишним местах, специально разработанных для сбора данных в масштабах предприятия. Новые пользователи могут начать с нашего руководства по быстрому запуску для базового внедрения, а корпоративные клиенты, которым требуются расширенные конфигурации, могут обратиться к нашей подробной документации по настройке.
Настройка жилых прокси с запросами Python требует минимальной конфигурации. Настройте учетные данные прокси следующим образом:
proxies = {
'http': 'http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}',
'https': 'http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}'
}Вот полная реализация:
import requests
import urllib3
# Disable SSL warnings
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
proxies = {
"http": "http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}",
"https": "http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}",
}
headers = {
"accept": "application/json, text/plain, */*",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
}
response = requests.get(
"https://www.nasdaq.com/api/news/topic/articlebysymbol?q=AAPL|STOCKS&offset=0&limit=10&fallback=true",
headers=headers,
proxies=proxies,
verify=False,
timeout=30,
)
print(f"Status Code: {response.status_code}")
print(response.json())Благодаря такой настройке прокси-сервера вы можете выполнять сотни или тысячи одновременных запросов с разных IP-адресов без ограничения скорости.
Мы также предлагаем бесплатный инструмент управления прокси с открытым исходным кодом, который обеспечивает расширенный контроль над работой прокси, например централизованное управление прокси, мониторинг запросов в реальном времени, расширенные настройки ротации и многое другое. Наше руководство по настройке поможет вам в процессе настройки.
Метод 3 – поиск данных о NASDAQ с помощью MCP на основе искусственного интеллекта
Протокол Model Context Protocol стандартизирует интеграцию ИИ с данными, обеспечивая взаимодействие на естественном языке с инфраструктурой веб-скрепинга. Реализация Bright Data MCP объединяет решения по сбору данных и их извлечению с помощью искусственного интеллекта, оптимизируя операции по сбору данных с помощью разговорных интерфейсов.
Этот MCP-сервер для извлечения финансовых данных упрощает обнаружение конечных точек, управление заголовками и защиту от ботов за счет использования инфраструктуры веб-данных. Система осуществляет интеллектуальную навигацию и извлечение данных с современных веб-сайтов, таких как NASDAQ, обрабатывая рендеринг JavaScript, динамический контент и системы безопасности, обеспечивая при этом вывод структурированных данных.
Теперь давайте посмотрим на это в действии, интегрировав Bright Data MCP с настольным приложением Claude. Перейдите в настольное приложение Claude, затем перейдите в Настройки > Разработчик > Редактировать конфигурацию. Вы увидите файл claude_desktop_config.json, в который нужно добавить следующую конфигурацию:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<your-brightdata-api-token>",
"WEB_UNLOCKER_ZONE": "<optional – override default zone name 'mcp_unlocker'>",
"BROWSER_AUTH": "<optional – enable full browser control via Scraping Browser>"
}
}
}
}Требования к конфигурации:
- API-токен – настройте свою учетную запись Bright Data и сгенерируйте API-токен на своей приборной панели.
- Зона Web Unlocker – укажите имя зоны Web Unlocker или используйте стандартное
mcp_unlocker. - Настройка браузера для скрапинга (Browser API) – для сценариев динамического контента настройте Browser API для страниц с JavaScript-рендерингом. Используйте учетные данные
Username:Passwordна вкладке Overview в зоне Browser API.
После завершения настройки выйдите из настольного приложения Claude и откройте его снова. Вы увидите доступную опцию Bright Data, указывающую на то, что инструменты MCP теперь интегрированы в вашу среду Claude.
Благодаря интеграции Claude и Bright Data MCP вы можете извлекать данные с помощью разговорных подсказок без написания кода.
Пример запроса: “Извлеките ключевые данные из URL NASDAQ в формате JSON: https://www.nasdaq.com/market-activity/stocks/aapl. Выполните динамическую загрузку, поскольку NASDAQ использует JavaScript-рендеринг”.
Разрешите разрешения инструментов, когда появится запрос. Система автоматически вызывает инструменты Bright Data MCP, используя Browser API для обработки рендеринга JavaScript и обхода защиты от ботов. Затем она возвращает структурированные JSON-данные с исчерпывающей информацией по акциям.
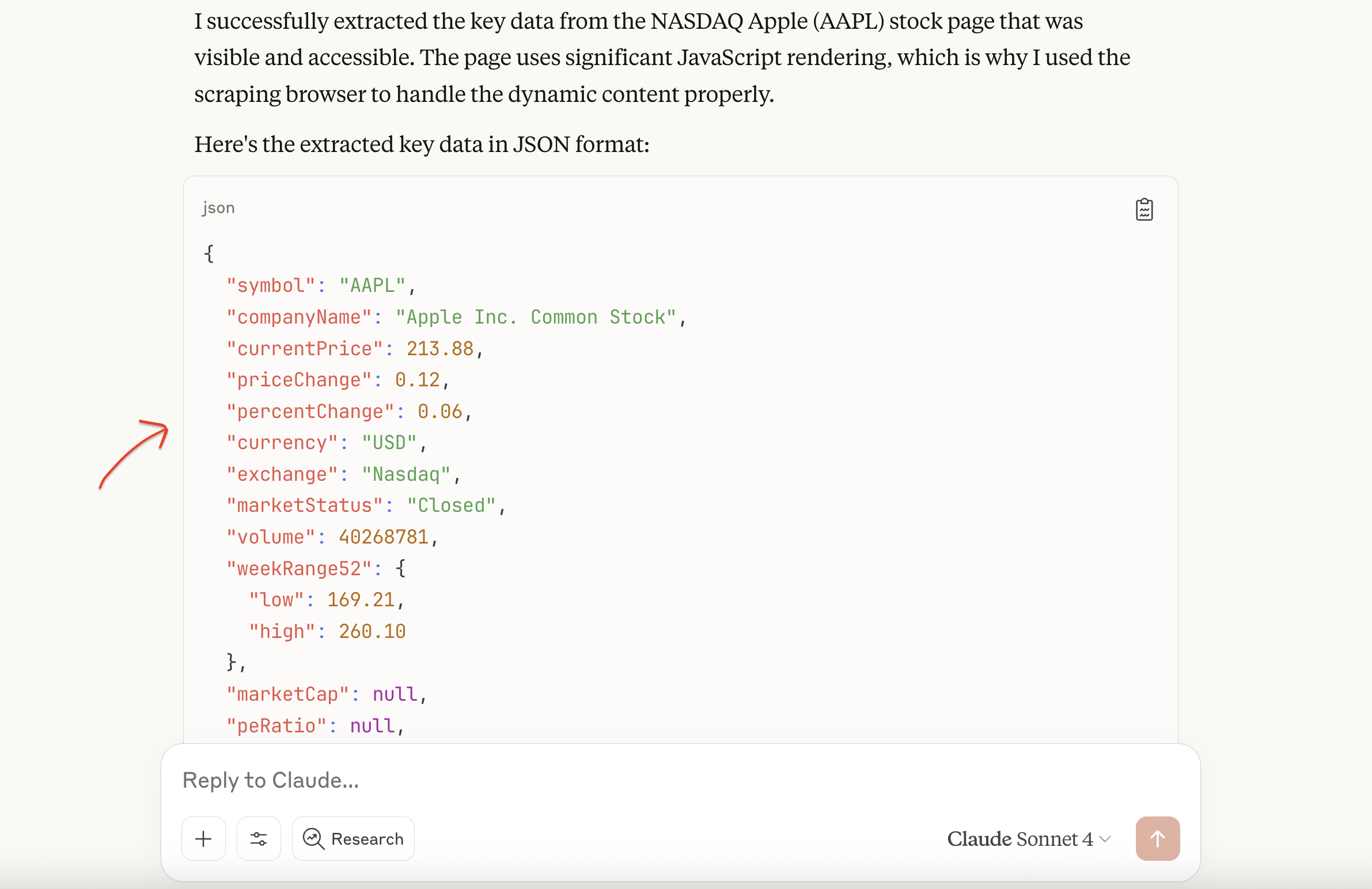
Здесь показано одно из применений MCP для извлечения финансовых данных. Универсальность протокола выходит далеко за рамки финансового скраппинга, так как команды, создающие рабочие процессы ИИ, регулярно объединяют несколько серверов MCP для различных возможностей.
В нашем обзоре ведущих MCP-серверов сравниваются и подчеркиваются уникальные возможности каждого поставщика, охватывающие все аспекты: от извлечения веб-данных и автоматизации работы браузера до интеграции кода и управления базами данных.
Заключение
Для эффективного соскабливания данных NASDAQ необходимо выбрать правильный подход, соответствующий вашим конкретным потребностям. В то время как базовый скрапинг подходит для извлечения данных в небольших объемах, производственные приложения получают значительную выгоду от надежной прокси-инфраструктуры и корпоративных решений.
Организациям, которым требуются решения для работы с финансовыми данными корпоративного уровня, стоит оценить различные варианты. Наш анализ ведущих поставщиков финансовых данных поможет вам сделать выбор между созданием собственных скреперов и покупкой наборов данных у специализированных поставщиков.
Помимо финансовых наборов данных, на обширном рынке Bright Data представлены наборы данных для бизнеса, социальных сетей, недвижимости, электронной коммерции и многие другие.
Поскольку существует так много вариантов наборов данных и подходов к их сбору, поговорите с одним из наших экспертов по данным, чтобы узнать, какие продукты и услуги Bright Data лучше всего соответствуют вашим конкретным требованиям.





