

В этой статье вы узнаете:
- Что такое Apify
- Почему использование Scraping Browser с Apify – это беспроигрышный вариант
- Как интегрировать браузер для скрапинга Bright Data в скрипт Apify Python
- Как использовать прокси-серверы Bright Data на Apify
Давайте погрузимся!
Что такое Apify?
Apify – это полнофункциональная платформа для веб-скрапинга и извлечения данных. Она позволяет создавать и запускать в облаке пользовательские инструменты для веб-скрепинга, известные как Actors. Эти Actors автоматизируют задачи, связанные со сбором, обработкой и автоматизацией данных.
На Apify вы можете монетизировать свои скрипты скраппинга, сделав их общедоступными для других пользователей. Независимо от того, планируете ли вы использовать свой Actor в частном порядке или сделать его общедоступным, решения Bright Data для скраппинга помогут сделать ваш скраппер более надежным и эффективным.
Зачем использовать браузер для скрапинга Bright Data на Apify
Чтобы оценить преимущества браузера для скрапинга Bright Data, необходимо понять, что это за инструмент и что он предлагает.
Самым большим ограничением инструментов автоматизации браузеров являются не их API, а браузеры, которыми они управляют. Scraping Browser – это веб-браузер нового поколения, специально разработанный для веб-скрапинга. В частности, он обладает следующими ключевыми особенностями:
- Надежные отпечатки пальцев TLS для предотвращения обнаружения
- Неограниченная масштабируемость для извлечения больших объемов данных
- Встроенная ротация IP-адресов с помощью 150-миллионной сети IP-прокси.
- Автоматические повторы для обработки неудачных запросов
- Возможности решения проблемы CAPTCHA
Scraping Browser совместим со всеми основными фреймворками для автоматизации браузеров, включая Playwright, Puppeteer и Selenium. Таким образом, вам не нужно изучать новый API или устанавливать сторонние зависимости. Вы можете просто интегрировать его непосредственно в существующий скрипт автоматизации браузера.
Теперь использование Scraping Browser вместе с Apify дает еще больше преимуществ, которые заключаются в следующем:
- Сокращение расходов на облачные вычисления: Браузеры потребляют значительное количество ресурсов, что приводит к повышению нагрузки на процессор и оперативную память. Scraping Browser, размещенный в облаке с гарантированной неограниченной масштабируемостью, позволяет сократить расходы на облако во время работы актера на Apify. Поскольку Apify взимает плату за использование сервера, даже с учетом платы за Scraping Browser такая настройка может привести к экономии средств.
- Универсальный инструмент для обхода ботов: Scraping Browser справляется с IP-запретами, CAPTCHA, отпечатками пальцев браузера и другими барьерами, препятствующими скрапингу. Это делает ваш процесс скрапинга более эффективным и менее подверженным сбоям.
- Встроенная интеграция с прокси-серверами: Scraping Browser включает в себя управление прокси-серверами, поэтому вам больше не нужно беспокоиться о поддержке и ручной ротации прокси-серверов.
- Преимущества Apify: Использование Scraping Browser на облачном акторе Apify (вместо общего скрипта) дает дополнительные преимущества, такие как
:Polylang placeholder не изменяется
Интеграция Bright Data + Apify не только упрощает рабочий процесс скрапинга, но и повышает его надежность. Кроме того, она сокращает время и усилия, необходимые для запуска вашего бота для сбора информации в Интернете.
Как интегрировать браузер для скрапинга Bright Data в Apify: Пошаговое руководство
Целевым сайтом в этом разделе будет Amazon – платформа, богатая информацией, но печально известная своими строгими антиботскими мерами. Без соответствующих инструментов вы, скорее всего, столкнетесь с печально известной капчей Amazon CAPTCHA, блокирующей ваши попытки скраппинга:

В этом разделе мы создадим актор скрапинга, который использует браузер скрапинга Bright Data для извлечения данных с общей страницы поиска товаров Amazon:

Примечание: Актор будет написан на Python, но помните, что Apify также поддерживает JavaScript.
Следуйте приведенным ниже инструкциям, чтобы узнать, как интегрировать инструменты для сбора информации Bright Data с Apify!
Пререквизиты
Чтобы следовать этому руководству, вам необходимо выполнить следующие предварительные условия:
- Локально установленный Python 3.8+: Для разработки и сборки локального скрипта Actor.
- Node.js, установленный локально: Для установки Apify CLI.
- Учетная запись Apify: Чтобы развернуть локальный Actor на платформе Apify.
- Учетная запись Bright Data: Чтобы получить доступ к браузеру скрапинга.
Шаг №1: Настройка проекта
Самый простой способ создать новый проект Apify Actor – это использовать Apify CLI. Сначала установите его глобально через Node.js с помощью следующей команды:
npm install -g apify-cliЗатем создайте новый проект Apify, выполнив команду:
npx apify-cli createВам будет предложено ответить на несколько вопросов. Ответьте на них следующим образом:
✔ Name of your new Actor: amazon-scraper
✔ Choose the programming language of your new Actor: Python
✔ Choose a template for your new Actor. Detailed information about the template will be shown in the next step.
Playwright + ChromeТаким образом, Apify CLI создаст новый Python Actor в папке amazon-scraper, используя шаблон “Playwright + Chrome”. Если вы не знакомы с этими инструментами, прочитайте наше руководство по веб-скрейпингу с помощью Playwright.
Примечание: Шаблон Selenium или Puppeteer также подойдет, так как Bright Data’s Scraping Browser интегрируется с любым инструментом автоматизации браузера.
Ваш проект Apify Actor будет иметь следующую структуру:
amazon-scraper
│── .dockerignore
│── .gitignore
│── README.md
│── requirements.txt
│
├── .venv/
│ └── ...
│
├── .actor/
│ │── actor.json
│ │── Dockerfile
│ └── input_schema.json
│
├── src/
│ │── main.py
│ │── __init__.py
│ │── __main__.py
│ └── py.typed
│
└── storage/
└── ...Загрузите папку amazon-scraper в предпочитаемую вами среду разработки Python, например Visual Studio Code с расширением Python или PyCharm Community Edition.
Помните, что для локального запуска Actor необходимо установить браузеры Playwright. Для этого сначала активируйте папку виртуального окружения (.venv) в каталоге проекта. В Windows выполните команду:
.venv/Scripts/activateАналогично, в Linux/macOS запустите:
source .venv/bin/activateЗатем установите необходимые зависимости Playwright, выполнив команду:
playwright install --with-depsЗамечательно! Теперь вы можете запускать Actor локально с помощью:
apify runТеперь ваш проект Apify полностью настроен и готов к интеграции с браузером для скрапинга Bright Data!
Шаг № 2: Подключение к целевой странице
Если вы посмотрите на URL-адрес страницы результатов поиска Amazon, то заметите, что он имеет такой формат:
https://www.amazon.com/search/s?k=<keyword>Например:

Целевой URL-адрес вашего скрипта должен использовать этот формат, где может быть динамически задан с помощью входного аргумента Apify. Входные параметры, которые принимает Actor, определяются в файле input_schema.json, расположенном в директории .actor.
Определение аргумента keyword делает скрипт настраиваемым, позволяя пользователям указывать предпочитаемый ими поисковый термин. Чтобы определить этот параметр, замените содержимое файла input_schema.json на следующее:
{
"title": "Amazon Scraper",
"type": "object",
"schemaVersion": 1,
"properties": {
"keyword": {
"title": "Search keyword",
"type": "string",
"description": "The keyword used to search products on Amazon",
"editor": "textfield"
}
},
"required": ["keyword"]
}Эта конфигурация определяет необходимый параметр ключевого слова типа string.
Чтобы задать аргумент ключевого слова при локальном запуске Actor, измените файл INPUT.json внутри storage/key_value_stores/default следующим образом:
{
"keyword": "laptop"
}Таким образом, Actor прочитает аргумент ввода ключевого слова, используя "laptop" в качестве поискового запроса.
После развертывания Actor на платформе Apify вы увидите поле ввода, в котором можно настроить этот параметр перед запуском Actor:

Помните, что начальным файлом Apify Actor является main.py, расположенный в папке src. Откройте этот файл и измените его на:
- Считывание параметра ключевого слова из входных аргументов
- Создайте целевой URL-адрес для страницы поиска Amazon
- Используйте Playwright для перехода на эту страницу
К концу этого шага ваш файл main.py должен содержать приведенную ниже логику Python:
from apify import Actor
from playwright.async_api import async_playwright
async def main() -> None:
# Enter the context of the Actor
async with Actor:
# Retrieve the Actor input, and use default values if not provided
actor_input = await Actor.get_input() or {}
# Reading the "keyword" argument from the input data, assigning it the
# value "laptop" as a default value
keyword = actor_input.get("keyword")
# Building the target url
target_url = f"https://www.amazon.com/search/s?k={keyword}"
# Launch Playwright and open a new browser context
async with async_playwright() as playwright:
# Configure the browser to launch in headless mode as per Actor configuration
browser = await playwright.chromium.launch(
headless=Actor.config.headless,
args=["--disable-gpu"],
)
context = await browser.new_context()
try:
# Open a new page in the browser context and navigate to the URL
page = await context.new_page()
await page.goto(target_url)
# Scraping logic...
except Exception:
Actor.log.exception(f"Cannot extract data from {target_url}")
finally:
await page.close()Приведенный выше код:
- Инициализирует Apify
Actorдля управления жизненным циклом сценария - Получает входные аргументы с помощью
Actor.get_input(). - Извлекает аргумент
ключевого словаиз входных данных - Создает целевой URL-адрес с помощью f-строки Python.
- Запускаем Playwright и запускаем безголовый браузер Chromium с отключенным GPU
- Создает новый контекст браузера, открывает страницу и переходит к целевому URL с помощью
page.goto(). - Все ошибки записываются в журнал с помощью
Actor.log.exception(). - Обеспечивает закрытие страницы Playwright после выполнения
Отлично! Ваш Apify Actor готов к использованию браузера Bright Data Scraping Browser для эффективного веб-скрепинга.
Шаг № 3: Интеграция браузера для скрапинга Bright Data
Теперь с помощью API Playwright сделайте снимок экрана после подключения к целевой странице:
await page.screenshot(path="screenshot.png")Запустите Actor локально, и он создаст файл screenshot.png в папке проекта. Откройте его, и вы, скорее всего, увидите что-то вроде этого:

Аналогичным образом вы можете получить следующую страницу ошибки Amazon:

Как видите, ваш веб-бот был заблокирован антиботами Amazon. Это лишь одна из многих проблем, с которыми вы можете столкнуться при работе с Amazon или другими популярными сайтами.
Забудьте об этих проблемах, используя Bright Data’s Scraping Browser –облачное решение для скрапинга, которое обеспечивает неограниченную масштабируемость, автоматическую ротацию IP-адресов, решение CAPTCHA и обход защиты от скрапинга.
Для начала, если вы еще не сделали этого, создайте учетную запись Bright Data. Затем войдите в платформу. В разделе “Приборная панель пользователя” нажмите кнопку “Получить прокси-продукты”:

В таблице “Мои зоны” на странице “Прокси и инфраструктура скрапинга” выберите строку “scraping_browser”:

Включите устройство, переключив переключатель вкл/выкл:

Теперь на вкладке “Конфигурация” убедитесь, что опции “Премиум-домены” и “CAPTCHA Solver” включены для максимальной эффективности:

На вкладке “Обзор” скопируйте строку подключения Playwright Scraping Browser:

Добавьте строку соединения в файл main.py в качестве константы:
SBR_WS_CDP = "<YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING>"Замените строкой подключения, которую вы скопировали ранее.
Примечание: Если вы планируете сделать свой Актор публичным на Apify, вам следует определить SBR_WS_CDP в качестве входного аргумента Apify Actor. Таким образом, пользователи, использующие ваш Актор, смогут интегрировать свои собственные строки подключения к Scraping Browser.
Теперь обновите определение браузера в файле main.py, чтобы использовать Scraping Browser с Playwright:
browser = await playwright.chromium.connect_over_cdp(SBR_WS_CDP, timeout=120000)Обратите внимание, что таймаут соединения должен быть установлен на большее значение, чем обычно, так как ротация IP-адресов через прокси-серверы и решение CAPTCHA может занять некоторое время.
Готово! Вы успешно интегрировали Scraping Browser в Playwright в рамках Apify Actor.
Шаг № 4: Подготовьте все объявления о продаже товаров
Чтобы извлечь списки товаров с Amazon, сначала нужно проинспектировать страницу, чтобы понять ее HTML-структуру. Для этого щелкните правой кнопкой мыши на одном из элементов продукта на странице и выберите опцию “Inspect”. Появится следующий раздел DevTools:

Здесь видно, что каждый элемент списка товаров может быть выбран с помощью этого CSS-селектора:
[data-component-type="s-search-result"]Нацеливание на атрибуты пользовательских данных-* идеально, поскольку эти атрибуты обычно используются для тестирования или мониторинга. Таким образом, они, как правило, остаются неизменными с течением времени.
Теперь используйте локатор Playwright, чтобы получить все элементы продукта на странице:
product_elements = page.locator("[data-component-type="s-search-result"]")Затем пройдитесь по элементам продукта и подготовьтесь к извлечению данных из них:
for product_element in await product_elements.all():
# Data extraction logic...Потрясающе! Пора реализовать логику извлечения данных Amazon.
Шаг #5: Реализация логики скрапинга
Сначала проверьте отдельный элемент списка товаров:

В этом разделе вы можете получить изображение продукта из атрибута src элемента .s-image:
image_element = product_element.locator(".s-image").nth(0)
image = await image_element.get_attribute("src")Обратите внимание, что nth(0) требуется для получения первого HTML-элемента, соответствующего локатору.
Затем изучите название продукта:

Вы можете получить URL-адрес и название продукта из и
внутри элемента [data-cy="title-recipe"] соответственно:
title_header_element = product_element.locator("[data-cy="title-recipe"]").nth(0)
link_element = title_header_element.locator("a").nth(0)
url = None if url_text == "javascript:void(0)" else "https://amazon.com" + url_text
title_element = title_header_element.locator("h2").nth(0)
title = await title_element.get_attribute("aria-label")
title_header_element = product_element.locator("[data-cy="title-recipe"]").nth(0)
link_element = title_header_element.locator("a").nth(0)
url = None if url_text == "javascript:void(0)" else "https://amazon.com" + url_text
title_element = title_header_element.locator("h2").nth(0)
title = await title_element.get_attribute("aria-label")Обратите внимание на логику, используемую для игнорирования “javascript:void(0)” URL-адреса (которые появляются на специальных рекламных продуктах) и обработку для преобразования URL-адресов продуктов в абсолютные.
Затем загляните в раздел отзывов:

Из [data-cy="reviews-block"] можно получить рейтинг рецензии из aria-label элемента элемента:
rating_element = product_element.locator("[data-cy="reviews-block"] a").nth(0)
rating_text = await rating_element.get_attribute("aria-label")
rating_match = re.search(r"(d+(.d+)?) out of 5 stars", rating_text)
if rating_match:
rating = rating_match.group(1)
else:
rating = NoneПоскольку текст рейтинга в aria-label имеет формат “X из 5 звезд”, вы можете извлечь значение рейтинга X с помощью простого regex. Смотрите, как использовать regex для веб-скрапинга.
Не забудьте импортировать re из стандартной библиотеки Python:
import reТеперь проверьте элемент подсчета отзывов:

Извлеките количество отзывов из элемента элемента [data-component-type="s-client-side-analytics"]:
review_count_element = product_element.locator("[data-component-type="s-client-side-analytics"] a").nth(0)
review_count_text = await review_count_element.text_content()
review_count = int(review_count_text.replace(",", ""))Обратите внимание на простую логику преобразования строки типа “2 539” в числовое значение в Python.
Наконец, проверьте узел цены продукта:
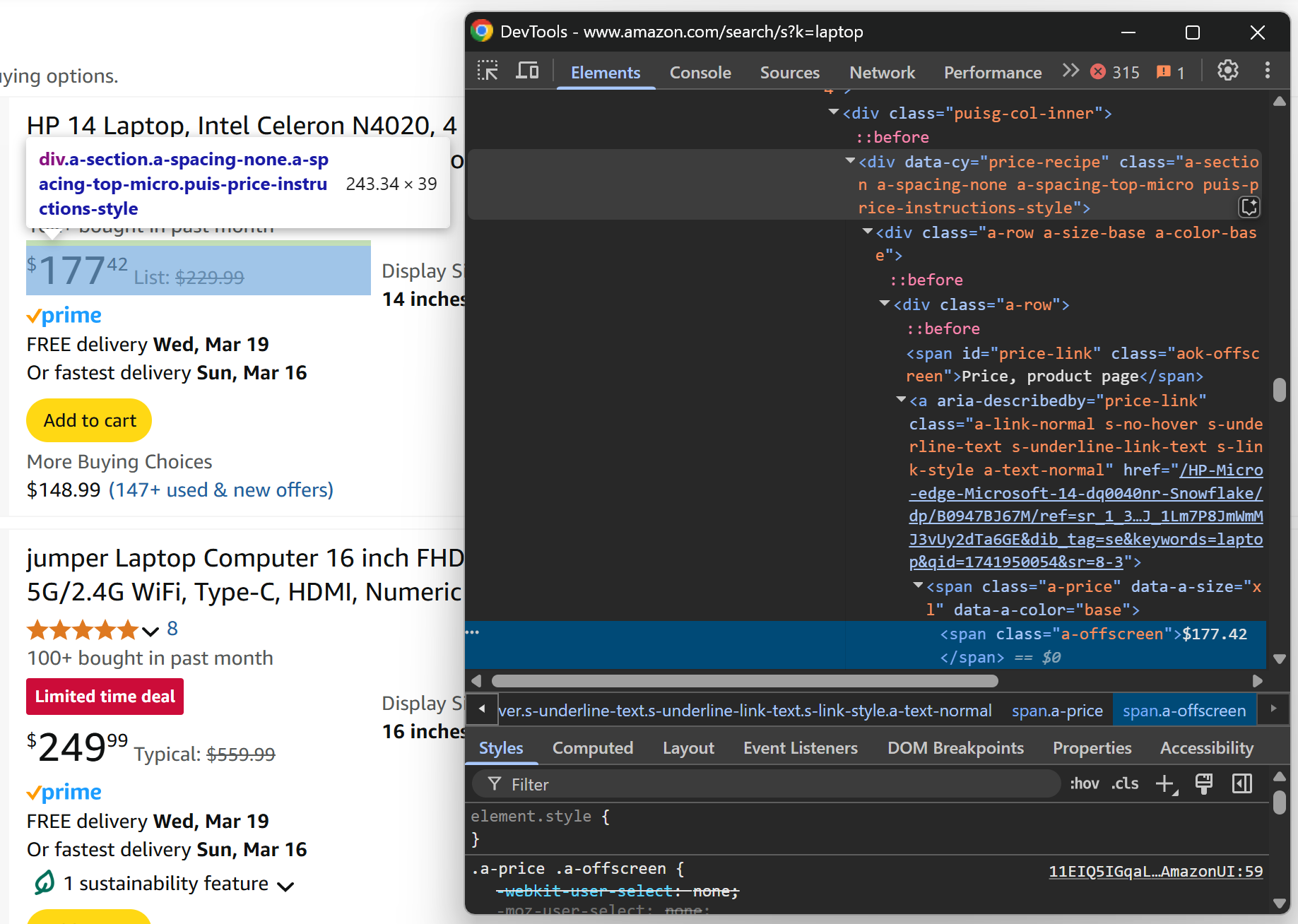
Соберите цену продукта из элемента .a-offscreen внутри [data-cy="price-recipe"]:
price_element_locator = product_element.locator("[data-cy="price-recipe"] .a-offscreen")
# If the price element is on the product element
if await price_element_locator.count() > 0:
price = await price_element_locator.nth(0).text_content()
else:
price = NoneПоскольку не все товары имеют элемент цены, для этого нужно проверить количество элементов цены, прежде чем пытаться получить их значение.
Чтобы сценарий заработал, обновите импорт Playwright:
from playwright.async_api import async_playwright, TimeoutErrorПрекрасно! Логика соскабливания данных о товарах Amazon завершена.
Обратите внимание, что целью этой статьи не является глубокое изучение логики работы с данными Amazon. Для получения более подробной информации следуйте нашему руководству по поиску данных о товарах Amazon на Python.
Шаг № 6: Сбор данных, полученных в результате сканирования
В качестве последней инструкции цикла for заполните объект продукта полученными данными:
product = {
"image": image,
"url": url,
"title": title,
"rating": rating,
"review_count": review_count,
"price": price
}Затем поместите его в набор данных Apify:
await Actor.push_data(product)push_data() гарантирует, что собранные данные будут зарегистрированы в Apify, что позволит вам получить к ним доступ через API или экспортировать их в один из множества поддерживаемых форматов (например, CSV, JSON, Excel, JSONL и т. д.).
Шаг №7: Соберите все вместе
Вот что должен содержать ваш финальный файл Apify + Bright Data Actor main.py:
from apify import Actor
from playwright.async_api import async_playwright, TimeoutError
import re
async def main() -> None:
# Enter the context of the Actor
async with Actor:
# Retrieve the Actor input, and use default values if not provided
actor_input = await Actor.get_input() or {}
# Reading the "keyword" argument from the input data, assigning it the
# value "laptop" as a default value
keyword = actor_input.get("keyword")
# Building the target url
target_url = f"https://www.amazon.com/search/s?k={keyword}"
# Launch Playwright and open a new browser context
async with async_playwright() as playwright:
# Your Bright Data Scraping API connection string
SBR_WS_CDP = "wss://brd-customer-username-zone-scraping_browser:[email protected]:9222"
# Configure Playwright to connect to Scraping Browser and open a new context
browser = await playwright.chromium.connect_over_cdp(SBR_WS_CDP, timeout=120000)
context = await browser.new_context()
try:
# Open a new page in the browser context and navigate to the URL
page = await context.new_page()
await page.goto(target_url)
# Use a locator to select all product elements
product_elements = page.locator("[data-component-type="s-search-result"]")
# Iterate over all product elements and scrape data from them
for product_element in await product_elements.all():
# Product scraping logic
image_element = product_element.locator(".s-image").nth(0)
image = await image_element.get_attribute("src")
title_header_element = product_element.locator("[data-cy="title-recipe"]").nth(0)
link_element = title_header_element.locator("a").nth(0)
url_text = await link_element.get_attribute("href")
url = None if url_text == "javascript:void(0)" else "https://amazon.com" + url_text
title_element = title_header_element.locator("h2").nth(0)
title = await title_element.get_attribute("aria-label")
rating_element = product_element.locator("[data-cy="reviews-block"] a").nth(0)
rating_text = await rating_element.get_attribute("aria-label")
rating_match = re.search(r"(d+(.d+)?) out of 5 stars", rating_text)
if rating_match:
rating = rating_match.group(1)
else:
rating = None
review_count_element = product_element.locator("[data-component-type="s-client-side-analytics"] a").nth(0)
review_count_text = await review_count_element.text_content()
review_count = int(review_count_text.replace(",", ""))
price_element_locator = product_element.locator("[data-cy="price-recipe"] .a-offscreen")
# If the price element is on the product element
if await price_element_locator.count() > 0:
price = await price_element_locator.nth(0).text_content()
else:
price = None
# Populate a new dictionary with the scraped data
product = {
"image": image,
"url": url,
"title": title,
"rating": rating,
"review_count": review_count,
"price": price
}
# Add it to the Actor dataset
await Actor.push_data(product)
except Exception:
Actor.log.exception(f"Cannot extract data from {target_url}")
finally:
await page.close()Как видите, интеграция браузера для скрапинга Bright Data с шаблоном Apify “Playwright + Chrome” проста и требует всего нескольких строк кода.
Шаг #8: Развертывание на Apify и запуск исполнителя
Чтобы развернуть локальный Actor в Apify, выполните следующую команду в папке проекта:
apify pushЕсли вы еще не вошли в систему, вам будет предложено пройти аутентификацию через Apify CLI.
После завершения развертывания вам будет задан следующий вопрос:
✔ Do you want to open the Actor detail in your browser?Ответьте “Y” или “yes”, чтобы перенаправить вас на страницу Actor в консоли Apify Console:

При желании вы можете вручную перейти на эту же страницу:
- Вход в Apify в браузере
- Переход к консоли
- Посещение страницы “Актер”
Нажмите кнопку “Start Actor”, чтобы запустить Amazon Scraper Actor. Как и ожидалось, вам будет предложено ввести ключевое слово. Попробуйте ввести что-то вроде “игровое кресло”:

После этого нажмите кнопку “Сохранить и начать”, чтобы запустить программу Actor и вычистить объявления о продаже “игровых кресел” с Amazon.
По окончании работы вы увидите полученные данные в разделе Output:

Чтобы экспортировать данные, перейдите на вкладку “Хранилище”, выберите опцию “CSV” и нажмите кнопку “Загрузить”:

Загруженный файл CSV будет содержать следующие данные:

И вуаля! Браузер для скрапинга Bright Data + интеграция с Apify работают как одно целое. Больше никаких CAPTCHA или блоков при работе с Amazon или любым другим сайтом.
[Дополнительно] Интеграция Bright Data Proxy в Apify
Использование таких продуктов для скрапинга, как Scraping Browser или Web Unlocker, непосредственно в Apify очень удобно и просто.
В то же время, предположим, что у вас уже есть актор на Apify и вам просто нужно усовершенствовать его с помощью прокси (например, чтобы избежать запрета IP-адресов). Помните, что вы можете интегрировать прокси Bright Data непосредственно в ваш Apify Actor, как описано в нашей документации или руководстве по интеграции.
Заключение
В этом уроке вы узнали, как создать Apify Actor, который интегрируется со Scraping Browser в Playwright для программного сбора данных с Amazon. Мы начали с нуля, выполнив все шаги по созданию локального скрипта для сбора данных и его развертыванию в Apify.
Теперь вы понимаете преимущества использования профессионального инструмента для скраппинга, такого как Scraping Browser, для облачного скраппинга в Apify. Следуя тем же или аналогичным процедурам, Apify поддерживает все другие продукты Bright Data:
- Услуги прокси: 4 различных типа прокси-серверов для обхода ограничений по местоположению, включая 150 миллионов IP-адресов жителей.
- API для веб-скреперов: Специальные конечные точки для извлечения свежих структурированных веб-данных из более чем 100 популярных доменов.
- SERP API: API для обработки всех текущих операций по разблокировке SERP и извлечению одной страницы
Зарегистрируйтесь на сайте Bright Data и протестируйте наши совместимые прокси-сервисы и продукты для скраппинга бесплатно!





