В этом руководстве вы узнаете, почему Go – один из лучших языков для эффективного парсинга веб-страниц. Также мы расскажем, как создать парсер Go с нуля.
В этой статье мы рассмотрим:
Можно ли выполнить парсинг веб-страниц с помощью Go?
Лучшие библиотеки веб-скрапинга Go
Создание парсера в Go
Можно ли выполнить парсинг веб-страниц с помощью Go?
Go, также известный как Golang — это язык программирования со статической типизацией, созданный Google. Он разработан как эффективный, параллельный, простой в написании и сопровождении язык. Эти характеристики в последнее время сделали Go популярным выбором в ряде приложений, включая веб-скрапинг.
Go предоставляет мощные возможности, которые пригодятся при решении задач по парсингу веб-страниц. К ним относится встроенная модель параллелизма, которая поддерживает параллельную обработку нескольких веб-запросов. Это делает Go идеальным языком для эффективного сбора больших объемов данных с нескольких сайтов. Кроме того, стандартная библиотека Go включает пакеты HTTP-клиента и анализа HTML, которые можно использовать для извлечения веб-страниц, анализа HTML и получения данных с сайтов.
Если этих возможностей и пакетов по умолчанию недостаточно или они слишком сложны в использовании, есть несколько библиотек Go для парсинга. Давайте рассмотрим самые популярные из них!
Лучшие библиотеки для веб-скрапинга Go
Представляем список одних из лучших библиотек веб-скрапинга для Go:
Colly: Мощный фреймворк для парсинга и сканирования веб-страниц для Go. Он предоставляет функциональный API для выполнения HTTP-запросов, управления заголовками и анализа DOM. Colly также поддерживает параллельный парсинг, ограничение скорости и автоматическую обработку файлов cookie.
Goquery: Популярная библиотека для разбора HTML в Go, основанная на jQuery-подобном синтаксисе. Она позволяет выбирать элементы HTML с помощью селекторов CSS, манипулировать DOM и извлекать из них данные.
Selenium: Клиент Go самого популярного фреймворка для веб-тестирования. Он позволяет автоматизировать веб-браузеры для выполнения различных задач, включая веб-скрапинг. В частности, Selenium может управлять браузером и давать ему указания взаимодействовать со страницами так, как это сделал бы пользователь. Он также может выполнять парсинг веб-страниц, которые используют JavaScript для извлечения или рендеринга данных.
Требования
Прежде чем мы начнем, вам нужно установить Go на свой компьютер. Обратите внимание, что процедура установки зависит от вашей ОС.
Откройте загруженный файл и следуйте инструкциям по установке. Пакет установит Go в /usr/local/go и добавит /usr/local/go/bin в переменную окружения PATH.
Запустите загруженный файл MSI и следуйте указаниям мастера установки. Программа установит Go в C:/Program Files или C:/rogram Files (x86) и добавит папку bin в переменную среды PATH.
Закройте и снова откройте все командные подсказки.
Убедитесь, что в вашей системе нет папки /usr/local/go. Если она существует, удалите ее с помощью:
rm -rf /usr/local/go
Распакуйте загруженный архив в /usr/local:
tar -C /usr/local -xzf goX.Y.Z.linux-amd64.tar.gz
Обязательно замените XYZ на версию пакета Go, который вы загрузили
Добавьте /usr/local/go/bin в переменную окружения PATH:
export PATH=$PATH:/usr/local/go/bin
Перезагрузите компьютер.
Независимо от вашей ОС убедитесь в успешной установке Go с помощью команды:
go version
В результате получится что-то вроде:
go version go1.20.3
Готово! Теперь вы можете приступить к парсингу веб-страниц Go!
Создание парсера веб-страниц в Go
Здесь вы узнаете, как создать парсер Go. Этот автоматизированный скрипт сможет автоматически извлекать данные с главной страницы Bright Data. Цель процесса парсинга Go в данном случае – выбрать некоторые элементы HTML со страницы, извлечь из них данные и преобразовать их в удобный для изучения формат.
На момент написания статьи целевой сайт выглядел так:
Следуйте нашему пошаговому руководству и узнайте, как выполнять парсинг веб-страниц в Go!
Шаг 1. Настройте проект Go
Пришло время инициализировать ваш проект парсера Go. Откройте терминал и создайте папку go-web-scraper:
Это инициализирует модуль веб-скрапера в корне проекта.
Каталог go-web-scraper теперь будет содержать следующий файл go.mod:
module web-scraper
go 1.20
Обратите внимание, что последняя строка меняется в зависимости от вашей версии Go.
Теперь вы готовы начать писать логику Go в своей IDE! В этом руководстве мы будем использовать Visual Studio Code. Поскольку изначально он не поддерживает Go, сначала необходимо установить расширение Go.
Запустите VS Code, нажмите «Расширения» на левой панели и введите «Перейти».
Нажмите кнопку «Установить» на первой карточке, чтобы добавить расширение Go для Visual Studio Code.
Нажмите «Файл», выберите «Открыть папку…» и откройте каталог go-web-scraper.
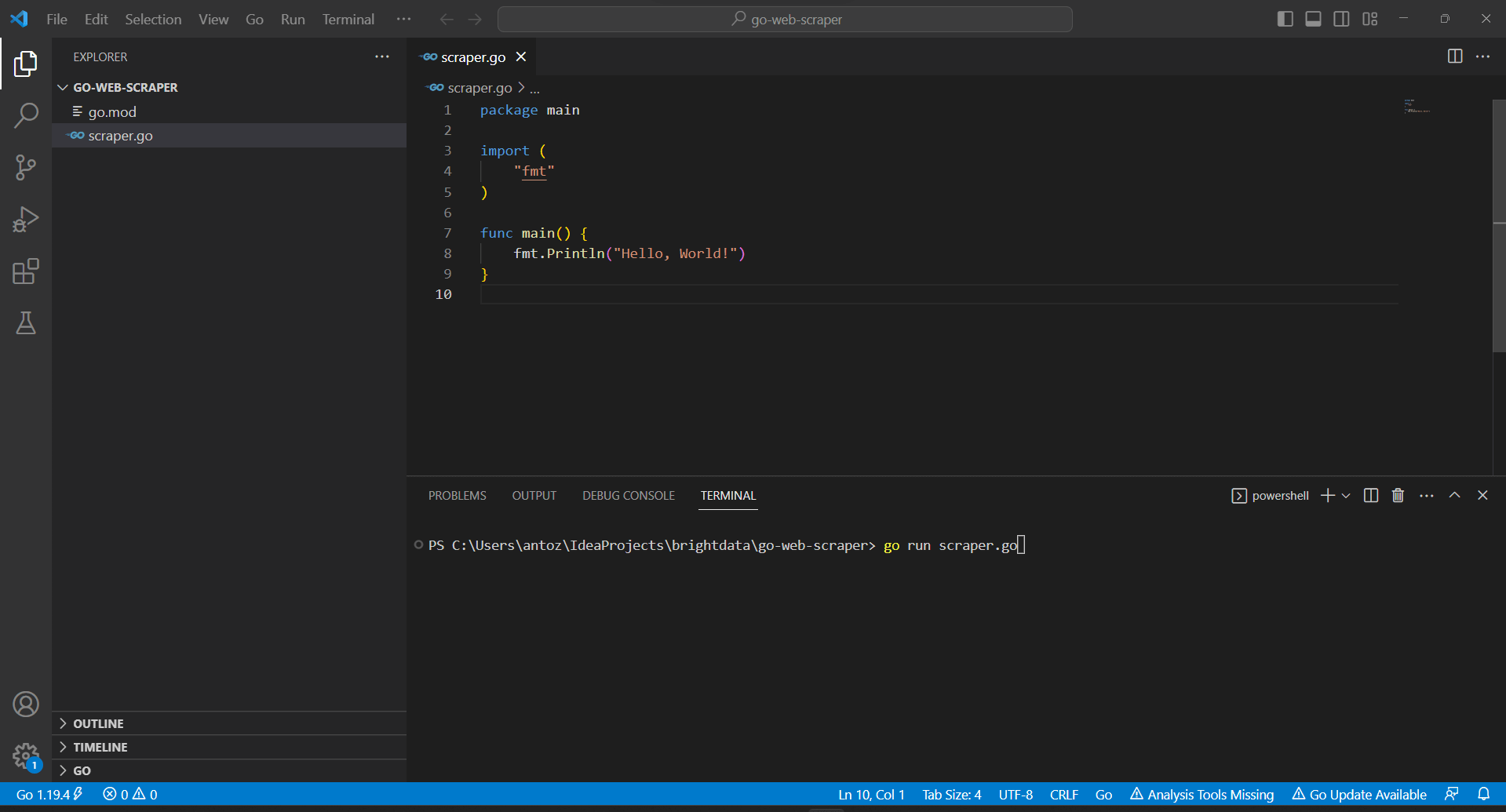
Щелкните правой кнопкой мыши на разделе «Обозреватель», выберите «Новый файл…» и создайте файл scraper.go следующим образом
Учитывайте, что функция main() – это точка входа любого приложения Go. Здесь нужно разместить логику веб-скрапинга Golang.
Visual Studio Code попросит вас установить несколько пакетов для завершения интеграции с Go. Установите их все. Затем запустите скрипт Go, запустив приведенную ниже команду в VS Terminal:
go run scraper.go
Что вы увидите:
Hello, World!
Шаг 2. Начните работу с Colly.
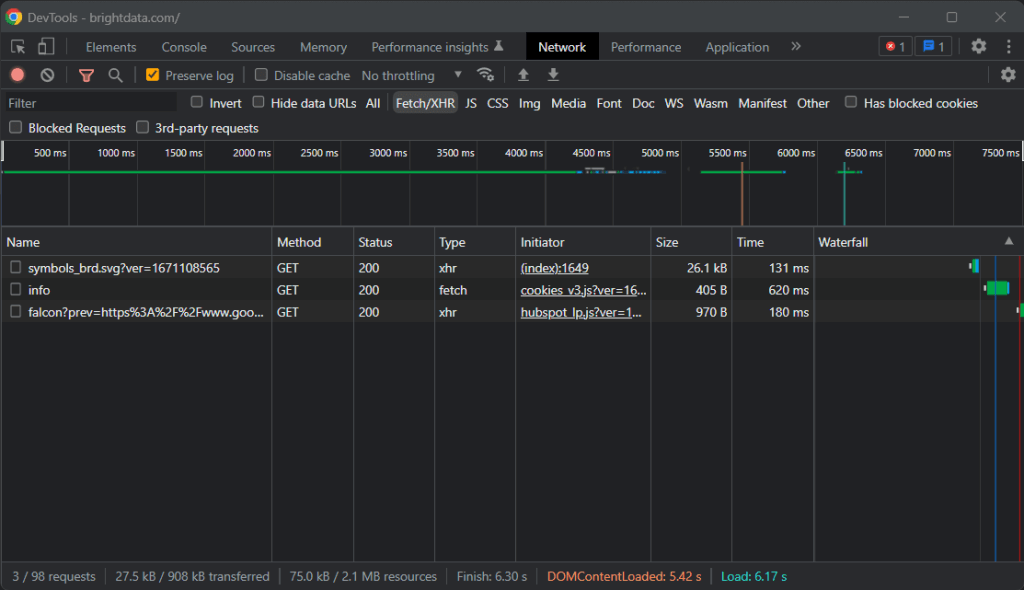
Чтобы упростить создание парсера для Go, вы должны использовать один из пакетов, представленных ранее. Но сначала вам нужно определить, какая библиотека веб-скрапинга Golang больше соответствует вашим целям. Зайдите на целевой сайт, щелкните правой кнопкой мыши на фоне и выберите параметр «Посмотреть». Откроется DevTools вашего браузера. Во вкладке «Сеть» вам нужен раздел «Fetch/XHR».
Обратите внимание, что целевой сайт не выполняет никаких значительных вызовов AJAX
Как видите, целевая веб-страница выполняет всего несколько запросов AJAX. Если вы изучите каждый запрос XHR, то заметите, что они не возвращают значимых данных. Другими словами, HTML-документ, возвращаемый сервером, уже содержит все данные. Это то, что обычно происходит с сайтами со статическим контентом.
Это показывает, что целевой сайт не использует JavaScript для динамического извлечения данных или рендеринга. То есть вам не нужна библиотека с возможностями автономного браузера для извлечения данных с целевой страницы. Вы можете использовать Selenium, но это приведет к перегрузке производительности. Поэтому вам лучше выбрать просто парсер HTML, как Colly.
Добавьте Colly к зависимостям вашего проекта с помощью:
go get github.com/gocolly/colly
Эта команда создает файл go.sum и соответствующим образом обновляет файл go.mod.
Прежде чем начать его использовать, вам нужно изучить некоторые ключевые концепции Colly.
Основной объект Колли – Collector. Он позволяет выполнять HTTP-запросы и парсинг веб-страниц с помощью следующих обратных вызовов:
OnRequest(): Вызывается перед любым HTTP-запросом с помощью Visit().
OnError(): Вызывается при возникновении ошибки в HTTP-запросе.
OnResponse(): Вызывается после получения ответа от сервера.
OnHTML(): Вызывается после OnResponse(), если сервер вернул действительный HTML-документ.
OnScraped(): Вызывается после завершения всех вызовов OnHTML().
Каждая из этих функций принимает обратный вызов в качестве параметра. Когда возникает событие, связанное с функцией, Colly выполняет обратный вызов ввода. То есть, чтобы создать парсер данных в Colly, вам нужно следовать функциональному подходу, основанному на обратных вызовах.
Вы можете инициализировать объект Collector с помощью функции NewCollector():
c := colly.NewCollector()
Импортируйте Colly и создайте Collector, обновив scraper.go следующим образом:
Используйте Colly для подключения к целевой странице с помощью:
c.Visit("https://brightdata.com/")
В фоновом режиме функция Visit() выполняет HTTP-запрос GET и извлекает целевой HTML-документ с сервера. То есть вызывает событие onRequest и запускает функциональный жизненный цикл Colly. Имейте в виду, что Visit() необходимо вызывать после регистрации других обратных вызовов Colly.
Обратите внимание, что HTTP-запрос, сделанный Visit(), может завершиться ошибкой. Если это происходит, Colly вызывает событие OnError. Причины сбоя могут быть любыми: от временно недоступного сервера до недопустимого URL. Парсеры же обычно терпят неудачу, когда целевой сайт принимает меры против ботов. Например, эти технологии обычно отфильтровывают запросы, которые не имеют действительного HTTP-заголовка User-Agent. Ознакомьтесь с нашим руководством, чтобы узнать больше о пользовательских агентах для парсинга веб-страниц.
По умолчанию Colly устанавливает User-Agent, который не соответствует агентам, используемым популярными браузерами. Это делает запросы Colly легко идентифицируемыми с помощью технологий защиты от парсинга. Чтобы избежать блокировки, укажите допустимый заголовок User-Agent в Colly, как показано ниже:
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
Любой вызов Visit() теперь будет выполнять запрос с этим HTTP-заголовком.
Теперь ваш файл scraper.go должен выглядеть следующим образом:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// connect to the target site
c.Visit("https://brightdata.com/")
// scraping logic...
}
Шаг 4. Проверьте HTML-страницу
Давайте проанализируем DOM целевой веб-страницы, чтобы определить эффективную стратегию извлечения данных.
Откройте главную страницу Bright Data в браузере. Если вы посмотрите на нее, то заметите список карточек с отраслями, в которых услуги Bright Data могут обеспечить конкурентное преимущество. Это интересная информация для соскабливания.
Щелкните правой кнопкой мыши на одну из этих карточек HTML и выберите «Посмотреть»:
Теперь сосредоточьтесь на классах CSS, используемых интересующими вас элементами HTML, и их родителях. Благодаря им вы сможете определить стратегию селектора CSS, которая нужна для получения желаемых элементов DOM.
Каждая карточка характеризуется классом section_cases__item и содержится в <div> .elementor-element-6b05593c. Таким образом, вы можете получить все отраслевые карты с помощью следующего CSS-селектора:
.elementor-element-6b05593c .section_cases__item
Получив карту, вы можете затем выбрать соответствующие дочерние элементы <figure> и <div> с помощью:
Цель парсера Go — извлечь URL-адрес, изображение и название отрасли из каждой карточки.
Шаг 5: Выберите HTML-элементы с Colly
You can apply a CSS or XPath selector in Colly as follows:
c.OnHTML(".your-css-selector", func(e *colly.HTMLElement) {
// data extraction logic...
})
Colly вызовет функцию, переданную в качестве параметра для каждого элемента HTML, который соответствует селектору CSS. Другими словами, он автоматически перебирает все выбранные элементы.
Не забывайте, что коллектор может иметь несколько обратных вызовов OnHTML(). Они будут выполняться в том порядке, в котором появляются в коде инструкции onHTML().
Шаг 6. Соберите данные с веб-страницы с помощью Colly
Узнайте, как использовать Cooly для извлечения нужных данных с веб-страницы в формате HTML.
Перед написанием логики скраппинга вам понадобятся некоторые структуры данных, в которых будут храниться извлеченные данные. Например, вы можете использовать Struct, чтобы определить тип данных Industry следующим образом:
type Industry struct {
Url, Image, Name string
}
В Go Struct определяет набор типизированных полей, которые могут быть созданы как объект. Если вы знакомы с объектно-ориентированным программированием, то можете думать о Struct как о своего рода классе.
Теперь вы можете использовать функцию OnHTML() для реализации логики парсинга, как видите ниже:
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url!= "" || image != "" || name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
Представленный выше фрагмент веб-скрапинга Go выбирает все отраслевые карточки с домашней страницы Bright Data и выполняет итерацию по ним. Затем заполняется путем парсинга URL, изображения и названия отрасли, связанного с каждой карточкой. И наконец создает новый объект Industry и добавляет его в срез отраслей.
Как видите, выполнить парсинг в Colly очень просто. Благодаря методу Attr() вы можете извлечь атрибут HTML из текущего элемента. Вместо этого ChildAttr() и ChildText() позволяют получить значение атрибута и текст дочернего элемента HTML, выбранного с помощью селектора CSS.
Учитывайте, что вы также можете собирать данные со страниц сведений об отрасли. Для этого вам нужно перейти по ссылкам на текущей странице и соответствующим образом внедрить новую логику скрапинга. Именно в этом и заключается суть веб-краулинга и веб-скрапинга!
Готово! Вы только что узнали, как достичь поставленных целей в веб-скрапинге с помощью Go!
Шаг 7: Экспортируйте извлеченные данные
После выполнения инструкции OnHTML() отрасли будут содержать полученные данные в объектах Go. Чтобы сделать их более доступными, необходимо преобразовать их в другой формат. Узнайте, как экспортировать полученные данные в CSV и JSON.
Обратите внимание, что стандартная библиотека Go поставляется с расширенными возможностями экспорта данных. Вам не нужен внешний пакет для преобразования данных в CSV и JSON. Просто убедитесь, что ваш скрипт Go содержит следующие импорты:
Для экспорта в CSV:
import (
"encoding/csv"
"log"
"os"
)
Для экспорта в JSON:
import (
"encoding/json"
"log"
"os"
)
Вы можете экспортировать срез отраслей в файл industry.csv в Go следующим образом:
// open the output CSV file
file, err := os.Create("industries.csv")
// if the file creation fails
if err != nil {
log.Fatalln("Failed to create the output CSV file", err)
}
// release the resource allocated to handle
// the file before ending the execution
defer file.Close()
// create a CSV file writer
writer := csv.NewWriter(file)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
Приведенный выше фрагмент кода создает файл CSV и инициализирует его строкой заголовка. Затем он перебирает срез объектов Industry, преобразует каждый элемент в срез строк и добавляет в выходной файл. Go CSV Writer автоматически преобразует список строк в новую запись в формате CSV.
Запустите скрипт с помощью:
go run scraper.go
После его выполнения вы заметите файл industry.csv в корневой папке вашего проекта Go. Откройте его, и вы увидите следующие данные:
Таким же образом вы можете экспортировать отрасли в Industry.json, как показано ниже:
file, err:= os.Create("industries.json")
if err != nil {
log.Fatalln("Failed to create the output JSON file", err)
}
defer file.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
file.Write(jsonString)
This will produce the JSON file below:
[
{
"Url": "https://brightdata.com/use-cases/ecommerce",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"Name": "E-commerce"
},
// ...
{
"Url": "https://brightdata.com/use-cases/real-estate",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/real_estate-1.svg",
"Name": "Real Estate"
},
{
"Url": "https://brightdata.com/use-cases/data-for-good",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"Name": "Data for Good"
}
]
Готово! Теперь вы знаете, как перевести собранные данные в более удобный формат!
Шаг 8: Соберите все вместе
Вот как выглядит полный код парсера на языке Golang:
// scraper.go
package main
import (
"encoding/csv"
"encoding/json"
"log"
"os"
// import Colly
"github.com/gocolly/colly"
)
// definr some data structures
// to store the scraped data
type Industry struct {
Url, Image, Name string
}
func main() {
// initialize the struct slices
var industries []Industry
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url != "" && image != "" && name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
// connect to the target site
c.Visit("https://brightdata.com/")
// --- export to CSV ---
// open the output CSV file
csvFile, csvErr := os.Create("industries.csv")
// if the file creation fails
if csvErr != nil {
log.Fatalln("Failed to create the output CSV file", csvErr)
}
// release the resource allocated to handle
// the file before ending the execution
defer csvFile.Close()
// create a CSV file writer
writer := csv.NewWriter(csvFile)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
// --- export to JSON ---
// open the output JSON file
jsonFile, jsonErr := os.Create("industries.json")
if jsonErr != nil {
log.Fatalln("Failed to create the output JSON file", jsonErr)
}
defer jsonFile.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
jsonFile.Write(jsonString)
}
Менее чем за 100 строк кода вы можете легко создать парсер в Go!
Подведем итог
В этом руководстве вы узнали, почему Go — это хороший язык для парсинга веб-страниц. А также, какие лучшие библиотеки парсинга Go и что они предлагают. Также мы рассказали, как использовать стандартную библиотеку Colly and Go, чтобы создать приложение для парсинга, который может собирать данные с реальных объектов. Как вы увидели, парсинг веб-страниц с помощью Go занимает всего несколько строк кода.
Однако имейте в виду, что при извлечении данных из Интернета важно учитывать множество проблем. Многие сайты используют антискрапинговые и антибот-решения, которые могут обнаруживать и блокировать ваш скрипт парсинга Go. К счастью, вы можете создать парсер, который может обходить любые блокировки с помощью IDE Bright Data для парсеров нового поколения.