
В этом руководстве вы узнаете:
- Что такое Pydantic AI и что делает его уникальным фреймворком для создания агентов ИИ.
- Почему Pydantic AI хорошо сочетается с Web MCP-сервером Bright Data для создания агентов, способных работать в Интернете.
- Как интегрировать Pydantic с Web MCP от Bright Data для создания агента искусственного интеллекта, опирающегося на реальные данные.
Давайте погрузимся!
Что такое пидантичный искусственный интеллект?
Pydantic AI – это агентный фреймворк для Python, разработанный создателями Pydantic, самой распространенной библиотеки проверки данных для Python.
По сравнению с другими фреймворками агентов ИИ, в Pydantic AI особое внимание уделяется безопасности типов, структурированным выводам и интеграции с данными и инструментами реального мира. В деталях, некоторые из его основных характеристик таковы:
- Поддержка OpenAI, Anthropic, Gemini, Cohere, Mistral, Groq, HuggingFace, Deepseek, Ollama и других провайдеров LLM.
- Проверка структурированного вывода с помощью пидантических моделей.
- Отладка и мониторинг с помощью Pydantic Logfire.
- Дополнительное внедрение зависимостей для инструментов, подсказок и валидаторов.
- Потоковые ответы LLM с проверкой данных “на лету”.
- Мультиагентная и графовая поддержка сложных рабочих процессов.
- Интеграция инструментов через MCP и включая HTTP-вызовы.
- Знакомый поток Pythonic для создания агентов ИИ как стандартных приложений на Python.
- Встроенная поддержка модульного тестирования и итеративной разработки.
Библиотека имеет открытый исходный код и уже достигла более 11 тысяч звезд на GitHub.
Зачем объединять Pydantic AI с MCP-сервером для поиска веб-данных
ИИ-агенты, созданные с помощью Pydantic AI, наследуют ограничения базового LLM. К ним относится отсутствие доступа к информации в реальном времени, что может привести к неточным ответам. К счастью, эту проблему можно легко решить, снабдив агента актуальными данными и возможностью исследовать веб-страницы в реальном времени.
Именно здесь на помощь приходит Web MCP от Bright Data. Построенный на базе Node.js, этот MCP-сервер интегрируется с набором инструментов поиска данных Bright Data с поддержкой искусственного интеллекта. Эти инструменты позволяют вашему агенту получать доступ к веб-контенту, запрашивать структурированные наборы данных, осуществлять поиск в Интернете и взаимодействовать с веб-страницами “на лету”.
На данный момент в состав сервера входят следующие инструменты MCP:
| Инструмент | Описание |
|---|---|
scrape_as_markdown |
Соскребайте содержимое с одного URL-адреса веб-страницы с помощью расширенных опций извлечения, возвращая результаты в формате Markdown. Может обходить обнаружение ботов и CAPTCHA. |
поисковая_система |
Извлекайте результаты поиска из Google, Bing или Yandex, возвращая данные SERP в формате markdown (URL, заголовок, сниппет). |
scrape_as_html |
Получение содержимого веб-страницы по URL-адресу с расширенными возможностями извлечения, возвращая полный HTML. Может обходить обнаружение ботов и CAPTCHA. |
статистика сессии |
Предоставляет статистику использования инструмента во время текущей сессии. |
scraping_browser_go_back |
Перейдите на предыдущую страницу в сеансе браузера для скраппинга. |
scraping_browser_go_forward |
Переход на следующую страницу в сеансе браузера для скраппинга. |
scraping_browser_click |
Выполните действие щелчка по определенному элементу с помощью селектора. |
соскабливание_браузерных_ссылок |
Получение всех ссылок, включая текст и селекторы, на текущей странице. |
scraping_browser_type |
Ввод текста в указанный элемент в браузере для скраппинга. |
scraping_browser_wait_for |
Подождите, пока определенный элемент станет видимым на странице, прежде чем продолжить работу. |
scraping_browser_screenshot |
Снимок экрана текущей страницы браузера. |
scraping_browser_get_html |
Получение HTML-содержимого текущей страницы в браузере. |
scraping_browser_get_text |
Извлечение видимого текстового содержимого из текущей страницы. |
Кроме того, существует более 40 специализированных инструментов для сбора структурированных данных с широкого спектра веб-сайтов (например, Amazon, Yahoo Finance, TikTok, LinkedIn и других) с помощью API Web Scraper. Например, инструмент web_data_amazon_product собирает подробную структурированную информацию о товарах с Amazon, принимая на вход действительный URL-адрес товара.
Теперь посмотрите, как вы можете использовать эти инструменты MCP в Pydantic AI!
Как интегрировать Pydantic AI с сервером Bright MCP Server на Python
В этом разделе вы узнаете, как использовать Pydantic AI для создания агента искусственного интеллекта. Агент будет оснащен возможностями сбора, извлечения и взаимодействия с данными с сервера Web MCP.
В качестве примера мы покажем, как агент может получать данные о товарах с Amazon “на лету”. Не забывайте, что это лишь один из многих возможных вариантов использования. ИИ-агент может использовать любой из 50 с лишним инструментов, доступных через сервер MCP, для выполнения широкого спектра задач.
Следуйте этому руководству, чтобы создать своего агента ИИ на базе Gemini + Bright Data MCP с помощью Pydantic AI!
Пререквизиты
Чтобы воспроизвести пример кода, убедитесь, что у вас локально установлено следующее:
- Python 3.10 или выше.
- Node.js (мы рекомендуем последнюю версию LTS).
Вам также понадобятся:
- Учетная запись Bright Data.
- Ключ API Gemini (или ключ API другого поддерживаемого провайдера LLM, например OpenAI, Anthropic, Deepseek, Ollama, Groq, Cohere и Mistral).
Пока не беспокойтесь о настройке ключей API. Шаги, описанные ниже, помогут вам настроить учетные данные Bright Data и Gemini, когда придет время.
Хотя это и не является обязательным, эти знания помогут вам следовать учебнику:
- Общее понимание того, как работает MCP.
- Базовые знания о том , как работают агенты искусственного интеллекта.
- Некоторые знания о сервере Web MCP и его доступных инструментах.
- Базовые знания асинхронного программирования на Python.
Шаг #1: Создайте свой проект Python
Откройте терминал и создайте новую папку для вашего проекта:
mkdir pydantic-ai-mcp-agentВ папке pydantic-ai-mcp-agent будет храниться весь код для вашего агента ИИ на Python.
Перейдите в только что созданную папку и создайте в ней виртуальную среду:
cd pydantic-ai-mcp-agent
python -m venv venvТеперь откройте папку с проектом в предпочтительной среде разработки Python. Мы рекомендуем Visual Studio Code с расширением Python или PyCharm Community Edition.
Создайте файл с именем agent.py в корне вашего проекта. На данный момент структура папок должна выглядеть следующим образом:
pydantic-ai-mcp-agent/
├── venv/
└── agent.pyВ настоящее время файл agent.py пуст, но вскоре он будет содержать логику для интеграции Pydantic AI с сервером Bright Data Web MCP.
Активируйте виртуальную среду с помощью терминала в вашей IDE. В Linux или macOS выполните эту команду:
source venv/bin/activateАналогично, в Windows запустите:
venv/Scripts/activateВсе готово! Теперь у вас есть среда Python, готовая к созданию агента ИИ с веб-доступом к данным.
Шаг №2: Установите Pydantic AI
В активированной виртуальной среде установите все необходимые пакеты Pydantic AI:
pip install "pydantic-ai-slim[google,mcp]" Это устанавливает pydantic-ai-slim, облегченную версию полного пакета pydantic-ai, которая позволяет избежать установки ненужных зависимостей.
В данном случае, поскольку вы планируете интегрировать своего агента с сервером Bright Data Web MCP, вам потребуется расширение mcp. А поскольку мы будем интегрировать Gemini в качестве провайдера LLM, вам также понадобится расширение google.
Примечание: Для других моделей или провайдеров обратитесь к документации модели, чтобы узнать, какие дополнительные зависимости требуются.
Затем добавьте эти импорты в файл agent.py:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderКруто! Теперь вы можете использовать Pydantic AI для создания агентов.
Шаг #3: Настройка чтения переменных окружения
Ваш ИИ-агент будет взаимодействовать со сторонними сервисами, такими как Bright Data и Gemini, через API. Не вписывайте ключи API в код на Python. Вместо этого загружайте их из переменных окружения для повышения безопасности и удобства обслуживания.
Чтобы упростить процесс, воспользуйтесь библиотекой python-dotenv. Активировав виртуальную среду, установите ее, выполнив команду:
pip install python-dotenvЗатем в файле agent.py импортируйте библиотеку и загрузите переменные окружения с помощью load_dotenv():
from dotenv import load_dotenv
load_dotenv()Это позволит скрипту считывать переменные окружения из локального файла .env. Поэтому создайте файл .env в папке проекта:
pydantic-ai-mcp-agent/
├── venv/
├── agent.py
└── .env # <---------------Теперь вы можете получить доступ к переменным окружения следующим образом:
env_value = os.getenv("<ENV_NAME>")Не забудьте импортировать модуль os из стандартной библиотеки Python:
import osВот и все! Теперь вы настроены на безопасную загрузку Api ключей из файла .env.
Шаг #4: Начало работы с сервером Bright Data MCP Server
Если вы еще не сделали этого, создайте учетную запись Bright Data. Если у вас уже есть такая учетная запись, просто войдите в нее.
Затем следуйте официальным инструкциям, чтобы настроить свой API-ключ Bright Data. Для простоты мы предполагаем, что в этом разделе вы используете токен с правами администратора.
Установите Bright Data’s Web MCP глобально с помощью npm:
npm install -g @brightdata/mcpЗатем проверьте, что все работает, с помощью приведенной ниже команды Bash:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpИли, в Windows, эквивалентная команда PowerShell:
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpВ приведенной выше команде замените на реальный API Bright Data, который вы извлекли ранее. Обе команды устанавливают необходимую переменную окружения API_TOKEN и запускают MCP-сервер с помощью пакета @brightdata/mcp npm.
Если все работает правильно, на вашем терминале будут отображаться журналы, похожие на этот:

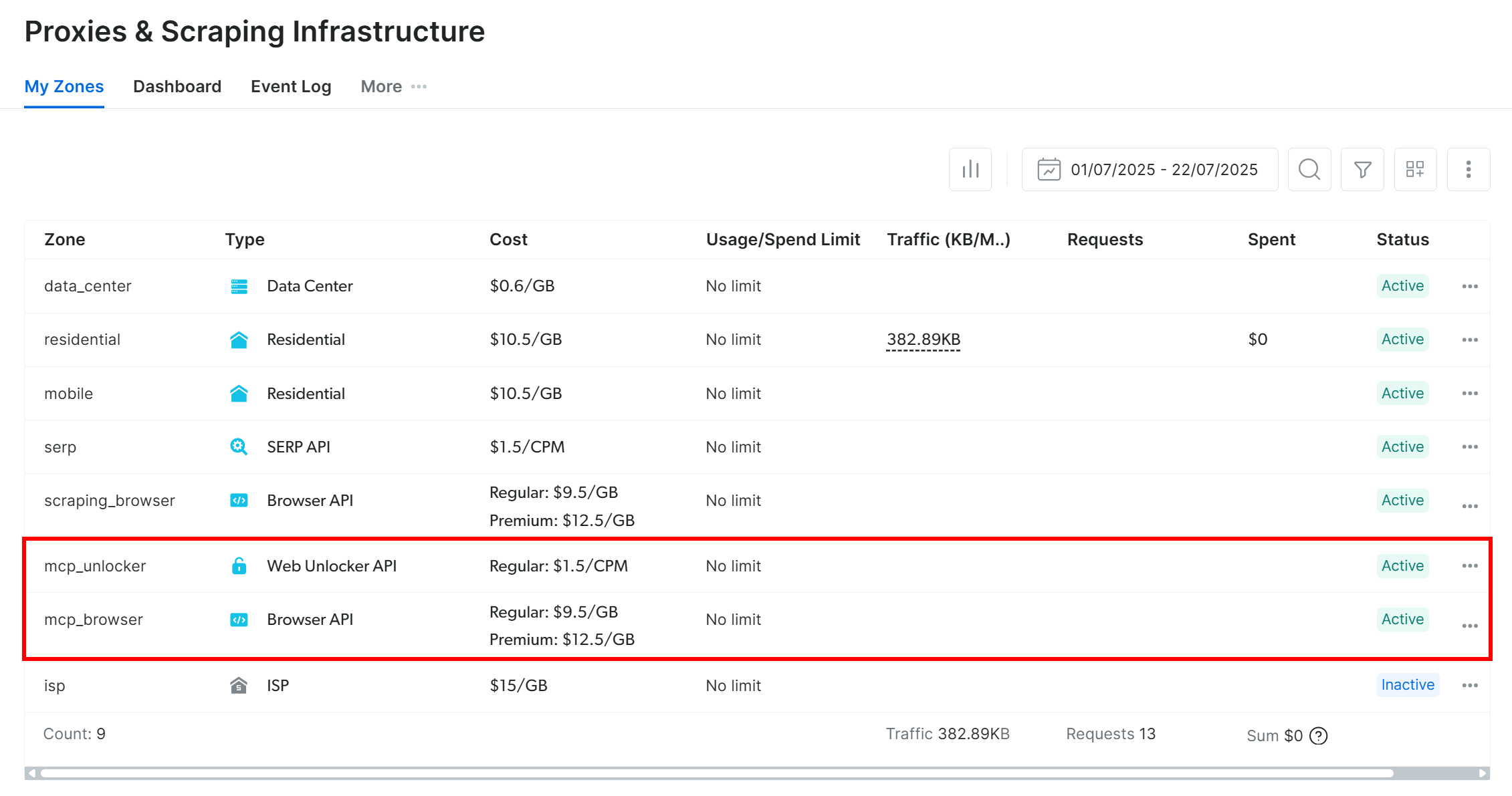
При первом запуске сервера MCP он автоматически создаст две зоны по умолчанию в вашей учетной записи Bright Data:
mcp_unlocker: Зона для Web Unlocker.mcp_browser: Зона для Browser API.
Эти две зоны позволяют серверу MCP запускать все инструменты, которые он предоставляет.
Чтобы убедиться в этом, войдите в панель управления Bright Data и перейдите на страницу“Proxies & Scraping Infrastructure“. Вы увидите автоматически созданные следующие зоны:
Примечание: Если вы не используете API-токен с правами администратора, вам придется создавать зоны вручную. В любом случае, вы всегда можете указать имена зон в envs, как описано в официальной документации.
По умолчанию в Web MCP доступны только инструменты search_engine и scrape_as_markdown. Чтобы открыть расширенные возможности, такие как автоматизация браузера и извлечение структурированных данных, необходимо включить режим Pro Mode, установив переменную окружения PRO_MODE=true.
Потрясающе! Web MCP работает как шарм.
Шаг #5: Подключение к Web MCP
Теперь, когда вы убедились, что ваша машина может работать с Web MCP, подключитесь к ней!
Начните с добавления ключа API Bright Data в файл .env:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Замените на реальный ключ API Bright Data, который вы получили ранее.
Затем прочитайте его в файле agent.py с помощью:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Помните, что Pydantic AI поддерживает три способа подключения к MCP-серверу:
- Использование транспорта Streamable HTTP.
- Использование транспорта HTTP SSE.
- Запуск сервера в качестве подпроцесса и подключение через
stdio.
Если вы не знакомы с первыми двумя методами, прочтите наше руководство по SSE vs Streamable HTTP для более подробного объяснения.
В этом случае вы хотите запустить сервер как подпроцесс (третий метод). Для этого инициализируйте экземпляр MCPServerStdio, как показано ниже:
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)Эти строки кода, по сути, запускают Web MCP с помощью той же команды npx, которую вы выполняли ранее. Она устанавливает переменную окружения API_TOKEN, используя ваш ключ API Bright Data для аутентификации. Кроме того, он включает PRO_MODE, чтобы у вас был доступ ко всем доступным инструментам, включая расширенные.
Отлично! Теперь вы успешно настроили подключение к локальному Web MCP в коде.
Шаг #6: Настройте LLM
Примечание: Этот раздел относится к Gemini, выбранному LLM для данного учебника. Однако вы можете легко адаптировать его к OpenAI или любому другому поддерживаемому LLM, следуя официальной документации.
Начните с получения ключа API Gemini и добавьте его в файл .env следующим образом:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Замените на ваш реальный ключ API.
Затем импортируйте необходимые библиотеки Pydantic AI для интеграции с Gemini:
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderЭти импорты позволяют подключаться к API Google и настраивать модель Gemini. Обратите внимание, что вам не нужно вручную считывать GOOGLE_API_KEY из файла .env. Причина в том, что GoogleProvider использует google-genai под капотом, который автоматически считывает API-ключ из энв GOOGLE_API_KEY.
Теперь инициализируйте экземпляры провайдера и модели:
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)Потрясающе! Это позволит агенту ИИ Pydantic подключиться к модели gemini-2.5-flash через Google API, который является бесплатным.
Шаг #7: Определите агента искусственного интеллекта Pydantic
Определите агент Pydantic AI Agent, который использует ранее настроенный LLM и подключается к серверу Web MCP:
agent = Agent(model, toolsets=[server])Отлично! Всего одной строкой кода вы создали объект Agent. Он представляет собой агент искусственного интеллекта, который может решать ваши задачи с помощью инструментов, предоставляемых сервером Web MCP.
Шаг #8: Запустите своего агента
Чтобы протестировать своего агента ИИ, необходимо написать запрос, включающий задачу извлечения веб-данных (при взаимодействии). Это поможет вам проверить, использует ли агент инструменты Bright Data так, как ожидалось.
Хорошей отправной точкой будет запрос на получение данных о продукте со страницы Amazon, например, так:
“Предоставьте мне данные о продукте с сайта https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/”.
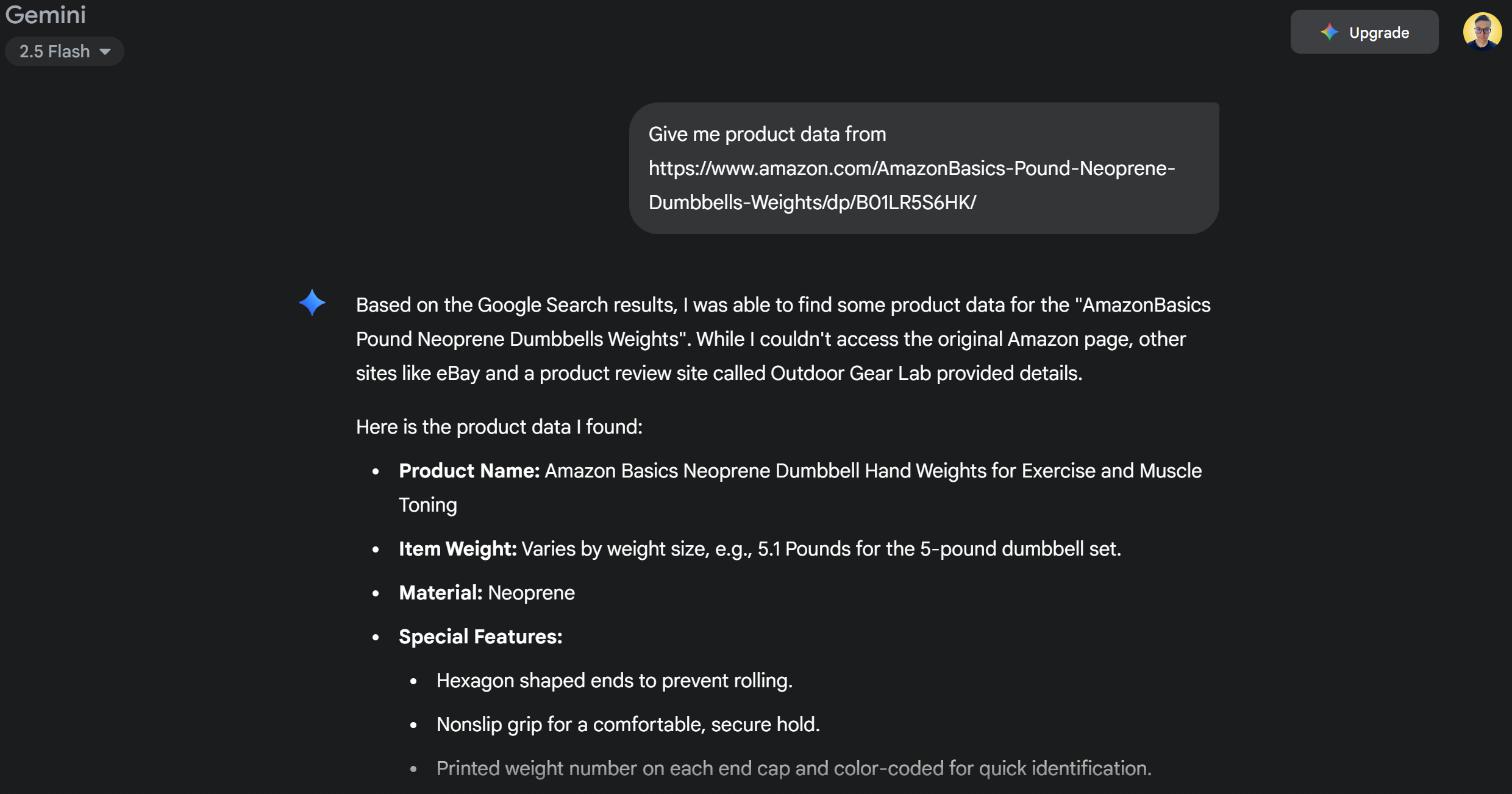
Обычно, если вы отправляете подобный запрос непосредственно в Gemini, происходит одно из двух:
- Запрос не будет выполнен из-за систем защиты Amazon от ботов (например, Amazon CAPTCHA), которые не позволяют Gemini получить доступ к содержимому страницы.
- Он будет возвращать галлюцинации или выдуманную информацию о продукте, поскольку не может получить доступ к реальной странице.
Попробуйте выполнить запрос непосредственно в Gemini. Скорее всего, вы получите сообщение о том, что не удалось получить доступ к странице Amazon, а затем подробную информацию о товаре, как показано ниже:
Благодаря интеграции с сервером Web MCP в вашей системе этого не должно произойти. Вместо того чтобы терпеть неудачу или гадать, ваш агент должен использовать инструмент web_data_amazon_product для получения структурированных данных о продукте со страницы Amazon в режиме реального времени, а затем возвращать их в чистом, читаемом формате.
Поскольку метод опроса агента ИИ Pydantic является асинхронным, оберните логику выполнения в асинхронную функцию следующим образом:
async def main():
async with agent:
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())Не забудьте импортировать asyncio из стандартной библиотеки Python:
import asyncioМиссия выполнена! Осталось только запустить полный код и посмотреть, оправдает ли агент ожидания.
Шаг № 9: Соберите все вместе
Это финальный код в файле agent.py:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProvider
from dotenv import load_dotenv
import os
import asyncio
# Load the environment variables from the .env file
load_dotenv()
# Read the API key from the envs for integration with the Bright Data Web MCP server
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Connect to the Bright Data Web MCP server
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)
# Configure the Google LLM model
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)
# Initialize the AI agent with Gemini and Bright Data's Web MCP server integration
agent = Agent(model, toolsets=[server])
async def main():
async with agent:
# Ask the AI Agent to perform a scraping task
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
# Get the result produced by the agent and print it
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())Вот это да! Благодаря Pydantic AI и Bright Data, всего за 50 строк кода вы только что создали мощный ИИ-агент на базе MCP.
Выполните агент ИИ с помощью:
python agent.pyВ терминале вы должны увидеть следующий вывод:
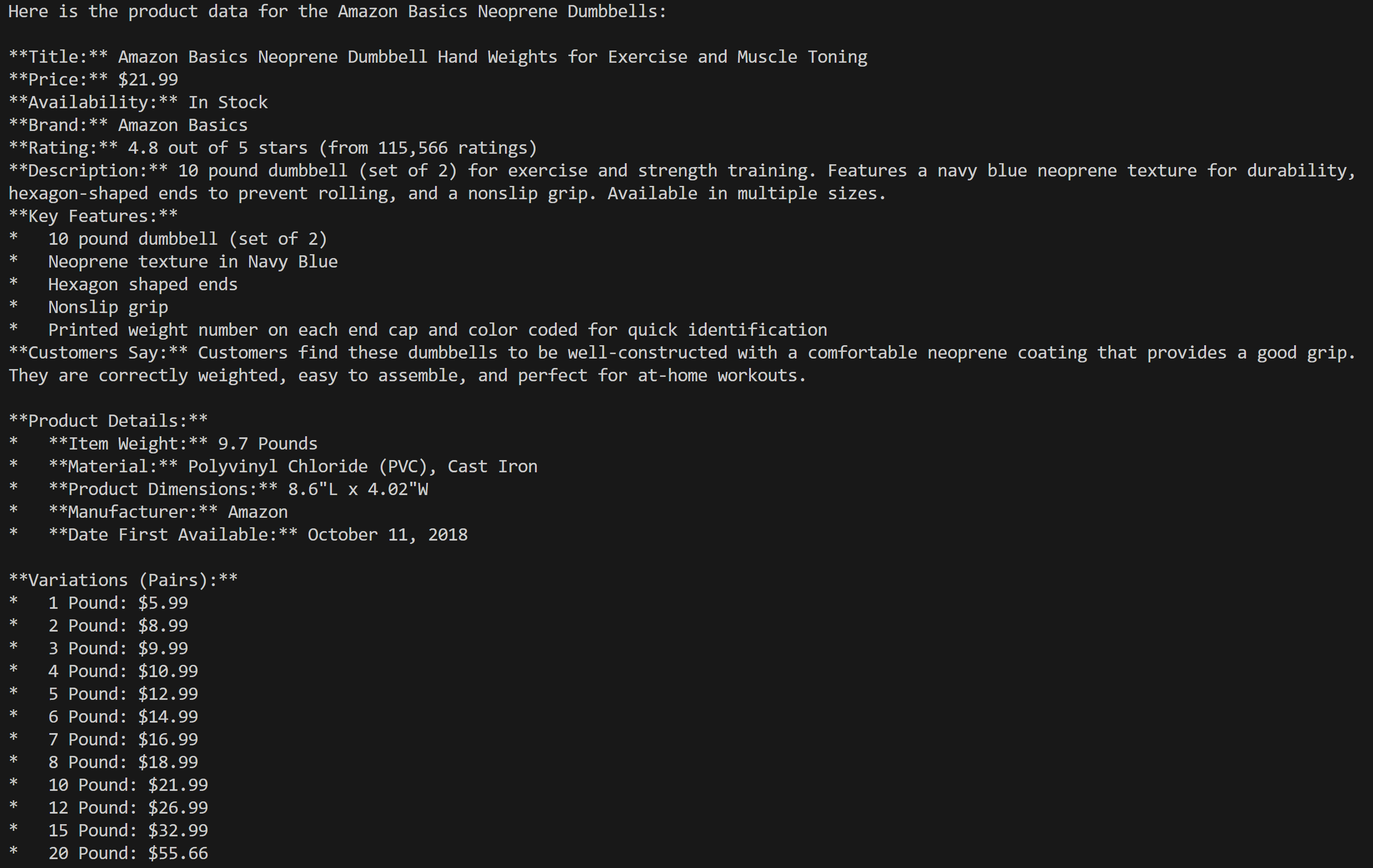
Как вы можете убедиться, проверив страницу товара Amazon, указанную в подсказке, информация, возвращенная агентом искусственного интеллекта, является точной:
Это потому, что агент использовал инструмент web_data_amazon_product, предоставленный сервером Web MCP, для получения свежих структурированных данных о товарах с Amazon в формате JSON.
И вуаля! Ожидания оправдались, и интеграция Pydantic AI + MCP сработала именно так, как было задумано.
Следующие шаги
Созданный здесь ИИ-агент функционален, но он служит лишь отправной точкой. Подумайте о том, чтобы поднять его на следующий уровень:
- Реализация цикла REPL для общения с агентом в CLI или интеграция его с инструментами чата с графическим интерфейсом, такими как Gradio.
- Расширение инструментов Bright Data MCP за счет определения собственных инструментов.
- Добавление отладки и мониторинга с помощью Pydantic Logfire.
- Преобразование вашего агента в автономного агента RAG в рамках мультиагентного рабочего процесса.
- Определение валидаторов пользовательских функций для обеспечения целостности выходных данных.
Заключение
В этой статье вы узнали, как интегрировать Pydantic AI с Web MCP-сервером Bright Data для создания агента искусственного интеллекта, способного работать в Интернете. Эта интеграция стала возможной благодаря встроенной в Pydantic AI поддержке MCP.
Чтобы создать более сложные агенты, изучите весь спектр услуг, доступных в инфраструктуре ИИ Bright Data. Эти решения способны обеспечить работу самых разных агентских сценариев.
Создайте бесплатную учетную запись Bright Data и начните экспериментировать с нашими инструментами для работы с веб-данными, поддерживающими искусственный интеллект!




