
В этом учебном пособии вы узнаете:
- Что такое Flyte и что делает его особенным для рабочих процессов ИИ, данных и машинного обучения.
- Почему рабочие процессы Flyte становятся еще более мощными, когда в них включаются веб-данные.
- Как интегрировать Flyte с Bright Data SDK для создания рабочего процесса на основе ИИ для SEO-анализа.
Давайте погрузимся!
Что такое Flyte?
Flyte – это современная платформа оркестровки рабочих процессов с открытым исходным кодом, которая помогает создавать конвейеры ИИ, данных и машинного обучения производственного уровня. Ее главная сила заключается в объединении команд и технологических стеков, способствуя сотрудничеству между учеными, изучающими данные, инженерами ML и разработчиками.
Построенный на Kubernetes, Flyte обеспечивает масштабируемость, воспроизводимость и распределенную обработку. Вы можете использовать его для определения рабочих процессов с помощью Python SDK. Затем развернуть их в облачных или локальных средах, открывая возможности для эффективного использования ресурсов и упрощения управления рабочими процессами.
На момент написания статьи репозиторий Flyte на GitHub насчитывает более 6,5 тысяч звезд!
Основные возможности
Основные возможности, поддерживаемые Flyte, следующие:
- Сильно типизированные интерфейсы: Определение типов данных на каждом шаге для обеспечения корректности и соблюдения защитных барьеров данных.
- Неизменяемость: Неизменяемость выполнения гарантирует воспроизводимость, предотвращая изменения состояния рабочего процесса.
- История данных: Отслеживайте перемещение и преобразование данных на протяжении всего жизненного цикла рабочего процесса.
- Картографические задачи и параллелизм: Эффективное параллельное выполнение задач с минимальной конфигурацией.
- Гранулярное повторное выполнение и восстановление после сбоев: Повторное выполнение только неудачных задач или повторное выполнение определенных задач без изменения предыдущих состояний рабочего процесса.
- Кэширование: кэшируйте результаты задач, чтобы оптимизировать повторное выполнение.
- Динамические рабочие процессы и ветвления: создавайте адаптируемые рабочие процессы, которые развиваются в зависимости от требований, и выборочно выполняйте ветвления.
- Гибкость языка: Разрабатывайте рабочие процессы с помощью Python, Java, Scala, JavaScript SDK или необработанных контейнеров на любом языке.
- Облачное нативное развертывание: Развертывайте Flyte на AWS, GCP, Azure или у других облачных провайдеров.
- Простота перехода от разработки к производству: Переносите рабочие процессы из разработки или staging в production без особых усилий.
- Обработка внешних входных данных: Приостанавливайте выполнение до тех пор, пока не будут получены необходимые данные.
Чтобы узнать обо всех возможностях, обратитесь к официальной документации Flyte.
Почему рабочим процессам ИИ нужны свежие веб-данные
Рабочие процессы ИИ настолько мощны, насколько мощны обрабатываемые ими данные. Конечно, открытые данные очень ценны, но доступ к данным в реальном времени – это то, что имеет значение с точки зрения бизнеса. А что является самым большим и богатым источником данных? Интернет!
Включив веб-данные в реальном времени в рабочие процессы ИИ, вы сможете получить более глубокие сведения, повысить точность прогнозов и принимать более обоснованные решения. Например, такие задачи, как SEO-анализ, исследование рынка или отслеживание настроения бренда, зависят от актуальной информации, которая постоянно меняется в сети.
Проблема в том, что получить свежие веб-данные довольно сложно. Веб-сайты имеют разную структуру, требуют разных подходов к соскабливанию и часто обновляются. Именно здесь на помощь приходит такое решение, как Bright Data Python SDK!
SDK позволяет программно искать, скрести и взаимодействовать с живым веб-контентом. Более того, он предоставляет доступ к наиболее полезным продуктам инфраструктуры Bright Data с помощью всего нескольких простых вызовов методов. Это делает доступ к веб-данным надежным и масштабируемым.
Объединив веб-возможности Flyte и Bright Data, вы сможете создавать автоматизированные рабочие процессы искусственного интеллекта, которые не отстают от постоянно меняющегося Интернета. Узнайте, как это сделать в следующей главе!
Как построить рабочий процесс SEO AI на Flyte и Bright Data Python SDK
В этом разделе вы узнаете, как создать во Flyte ИИ-агент, который:
- Принимает ключевое слово (или ключевую фразу) в качестве входных данных и использует Bright Data SDK для поиска релевантных результатов в Интернете.
- Использует Bright Data SDK для поиска 3 лучших страниц по заданному ключевому слову.
- Передает содержимое полученных страниц в OpenAI для создания отчета в формате Markdown, содержащего SEO-информацию.
Другими словами, благодаря интеграции Flyte + Bright Data вы создадите реальный рабочий процесс ИИ для SEO-анализа. Это позволяет получить полезные, связанные с контентом сведения о том, что делают наиболее эффективные страницы, чтобы хорошо ранжироваться.
Давайте приступим!
Предварительные условия
Чтобы следовать этому руководству, убедитесь, что у вас есть:
- Python установлен локально
- API-ключ Bright Data (с правами администратора )
- Ключ API OpenAI
Вы получите инструкции по настройке вашей учетной записи Bright Data для использования Bright Data Python SDK, поэтому не стоит беспокоиться об этом прямо сейчас. Для получения дополнительной информации ознакомьтесь с документацией.
Официальное руководство по установке Flyte рекомендует устанавливать через uv. Итак, установите/обновите uv глобально с помощью:
pip install -U uvШаг #1: Настройка проекта
Откройте терминал и создайте новую директорию для вашего проекта SEO-анализа AI:
mkdir flyte-seo-workflowПапка flyte-seo-workflow/ будет содержать Python-код для вашего рабочего процесса Flyte.
Далее перейдите в директорию проекта:
cd flyte-seo-workflowНа данный момент Flyte поддерживает только Python версий >=3.9 и <3.13 (рекомендуется версия 3.12 ).
Настройте виртуальное окружение для Python 3.12 с помощью:
uv venv --python 3.12Активируйте виртуальную среду. В Linux или macOS выполните команду:
source .venv/bin/activateАналогично, в Windows выполните:
.venv/Scripts/activateДобавьте новый файл workflow.py. Теперь ваш проект должен содержать:
flyte-seo-workflow/
├── .venv/
└──── workflow.pyworkflow.py представляет собой ваш основной Python-файл.
Активировав виртуальную среду, установите необходимые зависимости:
uv pip install flytekit brightdata-sdk openaiВы только что установили следующие библиотеки:
flytekit: Для создания рабочих процессов и задач Flyte.brightdata-sdk: Помогает получить доступ к решениям Bright Data на Python.openai: Для взаимодействия с LLM-системами OpenAI.
Примечание: Flyte предоставляет официальный коннектор ChatGPT(ChatGPTTask), но он опирается на старую версию API OpenAI. Он также имеет некоторые ограничения, например, строгие таймауты. По этим причинам, как правило, лучше прибегнуть к собственной интеграции.
Загрузите проект в вашу любимую Python IDE. Мы рекомендуем Visual Studio Code с расширением Python или PyCharm Community Edition.
Готово! Теперь у вас есть среда Python, готовая к разработке рабочих процессов ИИ в Flyte.
Шаг № 2: Разработка рабочего процесса искусственного интеллекта
Прежде чем приступить к кодированию, полезно сделать шаг назад и подумать о том, что должен делать ваш рабочий процесс ИИ.
Во-первых, помните, что рабочий процесс Flyte состоит из:
- Задачи: Функции, помеченные аннотацией
@task. Это фундаментальные единицы вычислений во Flyte. Задачи – это независимо исполняемые, сильно типизированные и контейнированные строительные блоки, из которых состоят рабочие процессы. - Рабочие процессы: Помеченные символом
@workflow, рабочие процессы строятся путем объединения задач в цепочки, при этом выход одной задачи подается на вход следующей, образуя направленный ациклический граф (DAG).
В данном случае вы можете достичь своей цели с помощью следующих трех простых задач:
get_seo_urls: Учитывая введенное ключевое слово или ключевую фразу, используйте Bright Data SDK для получения 3 лучших URL-адресов из результирующей страницы Google SERP (Search Engine Results Page).get_content_pages: Получает URL-адреса в качестве входных данных и использует Bright Data SDK для перебора страниц, возвращая их содержимое в формате Markdown(который идеально подходит для обработки искусственным интеллектом).generate_seo_report: Получает список содержимого страниц и передает его подсказке, прося ее создать отчет в формате Markdown, содержащий SEO-инсайты, такие как общие подходы, ключевую статистику (количество слов, абзацев, H1s, H2s и т. д.) и другие важные метрики.
Подготовьтесь к реализации задач и рабочего процесса Flyte, импортировав их из flytekit:
from flytekit import task, workflowЗамечательно! Теперь осталось только реализовать сам рабочий процесс.
Шаг № 3: Управление ключами API
Перед реализацией задач необходимо позаботиться об управлении ключами API для интеграций OpenAI и Bright Data.
Flyte поставляется со специальной системой управления секретами, которая позволяет вам безопасно работать с секретами в ваших скриптах, такими как ключи API и учетные данные. В производстве использование системы управления секретами Flyte является лучшей практикой и настоятельно рекомендуется.
В этом руководстве, поскольку мы работаем с простым скриптом, мы можем упростить ситуацию, задав ключи API непосредственно в коде:
import os
os.environ["OPENAI_API_KEY"] = "< ВАШ_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<Ваш_BRIGHTDATA_API_TOKEN>"Замените заполнители на реальные значения ключей API:
<YOUR_OPENAI_API_KEY>→ Ваш ключ API OpenAI.<YOUR_BRIGHT_DATA_API_TOKEN>→ Ваш API-токен Bright Data (получите его, как описано в официальном руководстве Bright Data).
Помните, что рекомендуется использовать API-ключ Bright Data с правами администратора. Это позволит Bright Data Python SDK автоматически подключаться к вашей учетной записи и настраивать необходимые продукты при инициализации клиента.
Другими словами, Bright Data Python SDK с API-ключом администратора автоматически настроит вашу учетную запись со всем необходимым для работы.
Помните: Никогда не вводите секреты в скрипты производства! Всегда используйте менеджер секретов во Flyte.
Шаг № 4: Реализация задачи get_seo_urls
Определите функцию get_seo_urls(), которая принимает ключевое слово в виде строки, и аннотируйте ее @task, чтобы она стала действительной задачей Flyte. Внутри функции используйте методsearch() из Bright Data Python SDK для выполнения веб-поиска.
За кулисами search() вызывает Brigh Data SERP API, который возвращает результаты поиска в виде JSON-строки с таким форматом:
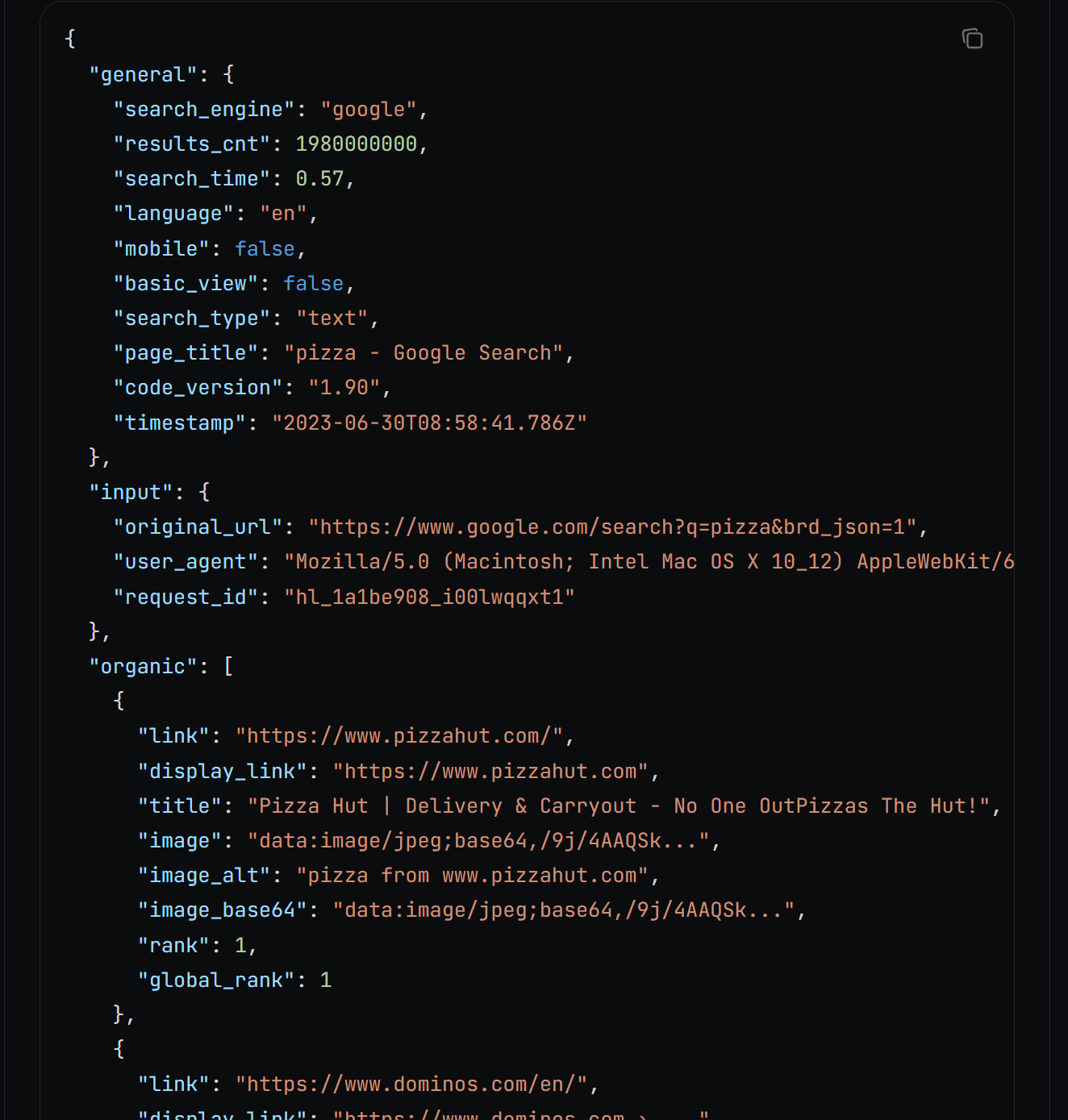
Подробнее о функции вывода JSON читайте в документации.
Разберите строку JSON в словарь и извлеките заданное количество SEO URL. Эти URL соответствуют X верхним результатам, которые вы обычно получаете от Google при поиске по введенному ключевому слову.
Реализуйте задачу с помощью:
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
import json
# Инициализация клиента Bright Data SDK
from brightdata import bdclient
bright_data_client = bdclient()
# Получение поисковой выдачи Google по заданному ключевому слову в виде разобранной строки JSON
res = bright_data_client.search(kw, response_format="json", parse=True)
json_response = res["body"]
data = json.loads(json_response)
# Извлечение URL-адресов SEO-страниц с наибольшим "num_links" из SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urlsПомните о необходимом импорте для типизации:
from typing import ListПримечание: Вам может быть интересно, почему клиент Bright Data Python SDK импортируется внутри задачи, а не глобально. Это сделано намеренно, поскольку задачи Flyte должны быть независимо исполняемыми. Другими словами, каждая задача должна включать в себя все необходимое для самостоятельного запуска, не полагаясь на глобальные зависимости.
Шаг № 5: Реализация задачи get_content_pages
Теперь, когда вы получили URL-адреса SEO, вы можете передать их методуscrape() из Bright Data Python SDK. Этот метод параллельно перебирает все страницы и возвращает их содержимое. Чтобы получить результат в формате Markdown, просто задайте аргумент data_format="markdown":
@task()
def get_content_pages(page_urls:List[str]) -> List[str]:
# Инициализация клиента Bright Data SDK
from brightdata import bdclient
bright_data_client = bdclient()
# Получение содержимого в формате Markdown с каждой страницы
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_listpage_content_list будет представлять собой список строк, где каждая строка – это Markdown-представление соответствующей входной страницы.
Под капотом функция scrape() вызывает API Bright Data Web Unlocker. Это универсальный API для скрапинга, способный получить доступ к любой веб-странице, независимо от ее защиты от ботов.
Независимо от того, какие URL-адреса вы получили в предыдущей задаче, функция get_content_pages() успешно получит их содержимое и преобразует его из сырого HTML в оптимизированный, пригодный для ИИ Markdown.
Шаг № 6: Реализация задачи generate_seo_report
Вызовите OpenAI API с соответствующим запросом, чтобы сгенерировать SEO-отчет на основе содержимого отсканированных страниц:
def generate_seo_report(page_content_list: List[str]) -> str:
# Инициализируем клиент OpenAI для вызова API OpenAI
from openai import OpenAI
openai_client = OpenAI()
# Запрос для создания желаемого SEO-отчета
prompt = f"""
# Учитывая приведенное ниже содержание нескольких веб-страниц,
# создайте структурированный отчет в формате Markdown, содержащий SEO-инсайты, полученные при анализе содержимого каждой страницы.
# Отчет должен включать:
# - Общие темы и элементы для всех страниц.
# - Ключевые различия между страницами
# - Сводная таблица, включающая статистику, такую как количество слов, количество абзацев, количество заголовков H2 и H3 и т. д.
# КОНТЕНТ:
# {"nnPAGE:".join(page_content_list)}
# """
# Выполнение запроса на выбранной модели ИИ
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_textРезультатом выполнения этой задачи будет желаемый отчет в формате SEO Markdown.
Примечание: В качестве модели OpenAI выше использовалась GPT-5-mini, но вы можете заменить ее на любую другую модель OpenAI. Аналогично, вы можете полностью отказаться от интеграции с OpenAI и использовать любой другой LLM-провайдер.
Фантастика! Задачи готовы, и теперь пришло время объединить их в рабочий процесс Flyte AI.
Шаг № 7: Определите рабочий процесс ИИ
Создайте функцию @workflow, которая организует последовательное выполнение задач:
@workflow
def seo_ai_workflow() -> str:
input_kw = "best llms"
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
вернуть отчётВ этом рабочем процессе:
- Задача
get_seo_urlsизвлекает 3 лучших SEO URL-адреса для ключевой фразы “best llms”. - Задача
get_content_pagesсобирает и преобразует содержимое этих URL в Markdown. - Задача
generate_seo_reportберет это содержимое в формате Markdown и создает итоговый отчет о SEO-инсайтах в формате Markdown.
Миссия выполнена!
Шаг № 8: Соберите все вместе
Ваш финальный файл workflow.py должен содержать:
from flytekit import task, workflow
import os
from typing import List
# Установите необходимые секреты (замените их своими ключами API)
os.environ["OPENAI_API_KEY"] = "< ВАШ_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<Ваш_BRIGHTDATA_API_TOKEN>"
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
import json
# Инициализация клиента Bright Data SDK
from brightdata import bdclient
bright_data_client = bdclient()
# Получение поисковой выдачи Google по заданному ключевому слову в виде разобранной строки JSON
res = bright_data_client.search(kw, response_format="json", parse=True)
# Разбор JSON-строки для преобразования ее в словарь
json_response = res["body"]
data = json.loads(json_response)
# Извлечение URL-адресов SEO-страниц с наибольшим "num_links" из SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urls
@task()
def get_content_pages(page_urls: List[str]) -> List[str]:
# Инициализация клиента Bright Data SDK
from brightdata import bdclient
bright_data_client = bdclient()
# Получение содержимого в формате Markdown с каждой страницы
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_list
@task
def generate_seo_report(page_content_list: List[str]) -> str:
# Инициализируем клиент OpenAI для вызова API OpenAI
from openai import OpenAI
openai_client = OpenAI()
# Запрос для создания желаемого SEO-отчета
prompt = f"""
# Учитывая приведенное ниже содержание нескольких веб-страниц,
# создайте структурированный отчет в формате Markdown, содержащий SEO-инсайты, полученные при анализе содержимого каждой страницы.
# Отчет должен включать:
# - Общие темы и элементы для всех страниц.
# - Ключевые различия между страницами
# - Сводная таблица, включающая статистику, такую как количество слов, количество абзацев, количество заголовков H2 и H3 и т. д.
# КОНТЕНТ:
# {"nnPAGE:".join(page_content_list)}
# """
# Выполнение запроса на выбранной модели ИИ
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_text
@workflow
def seo_ai_workflow() -> str:
input_kw = "best llms" # Измените его в соответствии с вашими целями SEO-анализа
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
вернуть отчёт
if __name__ == "__main__":
seo_ai_workflow()Вот это да! Менее чем за 80 строк кода на Python вы только что построили полноценный рабочий процесс SEO AI. Это было бы невозможно без Flyte и Bright Data SDK.
Вы можете запустить рабочий процесс из CLI с помощью команды:
pyflyte run workflow.py seo_ai_workflowЭта команда запустит функцию seo_ai_workflow @workflow из файла workflow.py.
Примечание: Появление результатов может занять некоторое время, поскольку веб-поиск, скраппинг и обработка ИИ занимают определенное время.
Когда рабочий процесс завершится, вы должны получить вывод в формате Markdown, похожий на этот:
Вставьте этот вывод в любую программу просмотра Markdown, чтобы прокрутить и изучить его. Он должен выглядеть примерно так, как показано ниже:
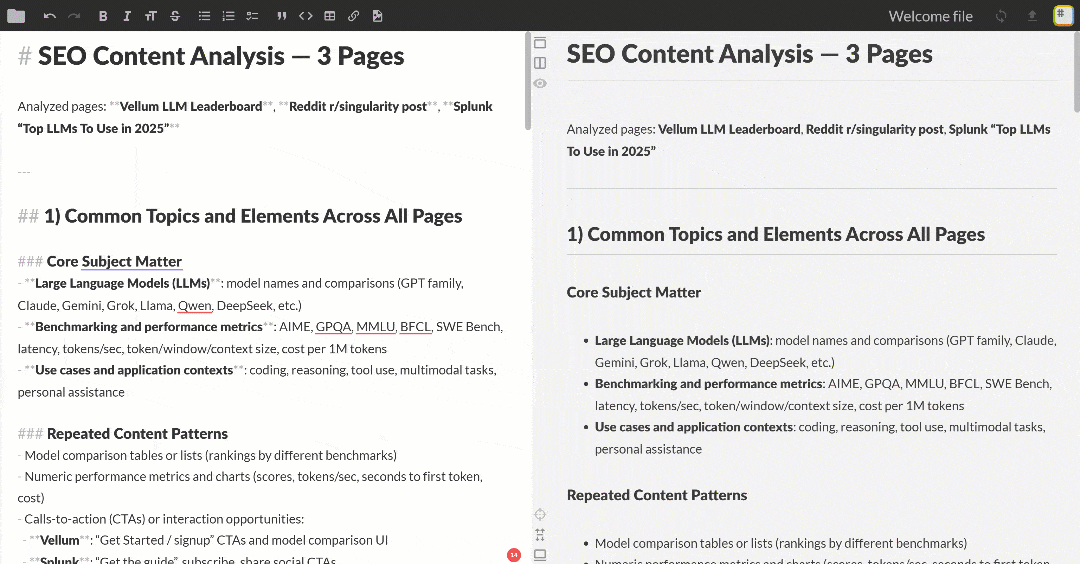
Результат содержит несколько SEO-инсайтов и сводную таблицу, в точности соответствующую запросу OpenAI. Это был всего лишь простой пример возможностей интеграции Flyte + Bright Data!
И вуаля! Не стесняйтесь определять другие задачи и пробовать различные LLM, чтобы реализовать другие полезные сценарии использования агентов и ИИ в рабочем процессе.
Следующие шаги
Представленная здесь реализация рабочего процесса Flyte AI является лишь примером. Чтобы сделать его готовым к производству или приступить к полноценной реализации, необходимо выполнить следующие шаги:
- Интегрировать систему управления секретами, поддерживаемую Flyte: Избегайте жесткого кодирования API-ключей в коде. Используйте секреты задач Flyte или другие поддерживаемые системы для безопасной и элегантной работы с учетными данными.
- Работа с подсказками: Генерировать подсказки внутри задачи вполне допустимо, но для воспроизводимости рассмотрите возможность версионирования подсказок или хранения их во внешнем хранилище.
- Разверните рабочий процесс: Следуйте официальным инструкциям по докеризации рабочего процесса и подготовьте его к развертыванию, используя возможности Flyte.
Заключение
В этой статье вы узнали, как использовать возможности веб-поиска и скрапинга Bright Data в Flyte для создания рабочего процесса SEO-анализа с поддержкой искусственного интеллекта. Процесс реализации был упрощен благодаря Bright Data SDK, который обеспечивает легкий доступ к продуктам Bright Data через простые вызовы методов.
Чтобы создать более сложные рабочие процессы, изучите полный набор решений в инфраструктуре Bright Data AI для получения, проверки и преобразования живых веб-данных.
Зарегистрируйте бесплатную учетную запись Bright Data и начните экспериментировать с нашими решениями для работы с веб-данными, готовыми к искусственному интеллекту!




