

В этом руководстве вы узнаете:
- Зачем вообще нужно решение для мониторинга брендов.
- Как создать такое решение с помощью Bright Data SDK, OpenAI и SendGrid.
- Как реализовать рабочий процесс ИИ-мониторинга репутации бренда на Python.
Вы можете просмотреть репозиторий GitHub для всех файлов проекта. А теперь давайте погрузимся в работу!
Зачем создавать индивидуальное решение для мониторинга бренда?
Мониторинг бренда – одна из самых важных задач в маркетинге, и существует несколько онлайн-сервисов, которые могут помочь в ее решении. Проблема с этими решениями заключается в том, что они, как правило, стоят дорого и не могут быть адаптированы к вашим конкретным потребностям.
Именно поэтому имеет смысл создать индивидуальное решение для мониторинга репутации бренда. Поначалу это может показаться пугающим, так как может показаться, что это сложная задача. Однако с помощью правильных инструментов (как вы сейчас увидите) она вполне достижима.
Рабочий процесс ИИ для репутации бренда Объяснение
Прежде всего, вы не сможете создать эффективный инструмент мониторинга бренда без достоверной внешней информации о нем. Отличным источником такой информации являются новости Google. Понимая, что говорят о вашем бренде в ежедневных новостных статьях и какие настроения за ними стоят, вы сможете принимать взвешенные решения. Конечная цель – отреагировать, защитить или продвинуть свой бренд.
Проблема в том, что соскабливать новостные статьи очень сложно. Новости Google, в частности, защищены множеством мер по борьбе с ботами. Кроме того, каждый источник новостей имеет свой собственный сайт с уникальной защитой, что затрудняет программный сбор данных о новостях.
Именно здесь на помощь приходит Bright Data. Благодаря своим возможностям веб-поиска и скрапинга, она предлагает множество продуктов и интеграций для программного доступа к готовым к искусственному интеллекту публичным веб-данным с любого сайта.
В частности, с помощью нового Bright Data SDK вы можете использовать самые полезные решения Bright Data в упрощенном режиме с помощью всего нескольких строк кода на Python!
Получив данные о новостях, вы можете положиться на ИИ, который выберет наиболее релевантные статьи и проанализирует их на предмет настроения и понимания бренда. Затем вы можете воспользоваться сервисом вроде Twilio SendGrid, чтобы отправить полученный отчет всей вашей маркетинговой команде. В общих чертах это именно то, что делает пользовательский рабочий процесс ИИ для оценки репутации бренда.
Теперь давайте подробнее рассмотрим, как реализовать его с технической точки зрения!
Технические шаги
Для реализации рабочего процесса AI мониторинга репутации бренда необходимо выполнить следующие шаги:
- Загрузите переменные окружения: Загрузите ключи API Bright Data, OpenAI и SendGrid из переменных окружения. Эти ключи необходимы для подключения к сторонним сервисам, обеспечивающим работу этого рабочего процесса.
- Загрузка файла конфигурации: Считывание конфигурационного файла JSON (например,
config.json), содержащего исходные поисковые запросы, количество новостных статей для включения в отчет, а также адреса электронной почты отправителя и получателей. - Получение URL-адресов страниц Google News: Используйте Bright Data SDK для сканирования страниц результатов поисковых систем (SERP) по заданному поисковому запросу. На каждой из них получите URL-адреса страниц новостей Google.
- Соскоб страниц новостей Google: Используйте Bright Data SDK для соскабливания полных страниц Google News в формате Markdown. Каждая из этих страниц содержит несколько URL-адресов новостных статей.
- Позвольте искусственному интеллекту определить главные новости: Отправьте отсканированные страницы Google News в модель OpenAI, чтобы она выбрала наиболее релевантные новостные статьи для мониторинга бренда.
- Соскребайте отдельные новостные статьи: Используйте Bright Data SDK для получения содержимого каждой новостной статьи, возвращенной ИИ.
- Проанализируйте новостные статьи на предмет репутации бренда: Отправьте каждую новостную статью в ИИ и попросите его предоставить краткое описание, анализ настроений и основные сведения о репутации бренда.
- Создайте итоговый HTML-отчет: Передайте ИИ результаты анализа новостей и попросите его создать хорошо структурированный HTML-отчет.
- Отправьте отчет по электронной почте: Используйте SendGrid SDK, чтобы отправить сгенерированный ИИ HTML-отчет указанным получателям, обеспечивая всесторонний обзор репутации бренда.

Посмотрите, как реализовать этот рабочий процесс ИИ в Python!
Создание рабочего процесса по оценке репутации бренда с помощью ИИ с помощью Bright Data SDK
В этом учебном разделе вы узнаете, как создать рабочий процесс на основе искусственного интеллекта для мониторинга репутации вашего бренда. Необходимые данные о новостях бренда будут получены от Bright Data с помощью Bright Data Python SDK. Возможности ИИ будут предоставлены OpenAI, а доставка электронной почты будет осуществляться с помощью SendGrid.
К концу этого урока у вас будет полный рабочий процесс ИИ на Python, который будет доставлять результаты прямо в ваш почтовый ящик. В выходном отчете будут указаны ключевые новости, о которых должен знать ваш бренд, и вы получите все необходимое для быстрого реагирования и поддержания сильного присутствия бренда.
Давайте создадим рабочий процесс ИИ для репутации бренда!
Предварительные условия
Чтобы следовать этому руководству, убедитесь, что у вас есть следующее:
- Python 3.8+, установленный локально.
- Ключ API Bright Data.
- API-ключ OpenAI.
- API-ключ Twilio SendGrid.
Если у вас еще нет API-токена Bright Data, зарегистрируйтесь на сайте Bright Data и следуйте руководству по настройке. Аналогично, следуйте официальным инструкциям OpenAI, чтобы получить ключ OpenAI API.
Что касается SendGrid, создайте учетную запись, подтвердите ее, подключите адрес электронной почты и проверьте свой домен. Создайте API-ключ и проверьте, что вы можете программно отправлять электронные письма через него.
Шаг № 1: Создание проекта на Python
Откройте терминал и создайте новую директорию для рабочего процесса ИИ мониторинга репутации бренда:
mkdir brand-reputation-monitoring-workflowПапка brand-reputation-monitoring-workflow/ будет содержать код Python для вашего рабочего процесса AI.
Далее перейдите в каталог проекта и настройте виртуальное окружение:
cd brand-reputation-monitoring-workflow
python -m venv .venvТеперь загрузите проект в вашу любимую Python IDE. Мы рекомендуем Visual Studio Code с расширением Python или PyCharm Community Edition.
Внутри папки проекта добавьте новый файл workflow.py. Теперь ваш проект должен содержать:
brand-reputation-monitoring-workflow/
├── .venv/
└──── workflow.pyworkflow.py будет вашим основным Python-файлом.
Активируйте виртуальную среду. В Linux или macOS выполните команду:
source .venv/bin/activateАналогично, в Windows выполните:
.venv/Scripts/activateКогда среда активирована, установите необходимые зависимости с помощью:
pip install python-dotenv brightdata-sdk openai sendgrid pydanticБиблиотеки, которые вы только что установили:
python-dotenv: для загрузки переменных окружения из файла.env, что упрощает безопасное управление ключами API.brightdata-sdk: Помогает получить доступ к инструментам и решениям Bright Data для скраппинга на Python.openai: Для взаимодействия с языковыми моделями OpenAI.sendgrid: Для быстрой отправки электронных писем с помощью Twilio SendGrid Web API v3.pydantic: Для определения моделей для выходов ИИ и вашей конфигурации.
Готово! Ваша среда разработки на Python готова к построению рабочего процесса ИИ для мониторинга репутации бренда с помощью OpenAI, Bright Data SDK и SendGrid.
Шаг №2: Настройте чтение переменных окружения
Настройте свой скрипт на чтение секретов из переменных окружения. В файле workflow.py импортируйте python-dotenv и вызовите load_dotenv() для автоматической загрузки переменных окружения:
from dotenv import load_dotenv
load_dotenv()Теперь ваш скрипт может считывать переменные из локального файла .env. Итак, создайте файл .env в корне каталога вашего проекта:
brand-reputation-monitoring-workflow/
├── .venv/
├── .env # <-----------
└──── workflow.pyОткройте файл .env и добавьте в него параметры OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN и SENDGRID_API_KEY:
OPENAI_API_KEY="<ВАШ_OPENAI_API_KEY>"
BRIGHT_DATA_API_TOKEN="<ВАШ_BRIGHT_DATA_API_TOKEN>"
SENDGRID_API_KEY="<ВАШ_SENDGRID_API_TOKEN>"Замените заполнители на ваши реальные учетные данные:
<YOUR_OPENAI_API_KEY>→ Ваш ключ API OpenAI.<YOUR_BRIGHT_DATA_API_TOKEN>→ Ваш API-токен Bright Data.<YOUR_SENDGRID_API_KEY>→ Ваш ключ API SendGrid.
Отлично! Теперь вы надежно настроили сторонние секреты с помощью переменных окружения.
Шаг № 3: Инициализация SDK
Начните с добавления необходимых импортов:
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClientЗатем инициализируйте SDK-клиенты:
brightdata_client = bdclient()
openai_client = OpenAI()
sendgrid_client = SendGridAPIClient()Три строки выше инициализируют следующее:
- Bright Data Python SDK
- OpenAI Python SDK
- SendGrid Python SDK
Обратите внимание, что вам не нужно вручную загружать переменные окружения API-ключа в ваш код и передавать их конструкторам. Это связано с тем, что OpenAI SDK, Bright Data SDK и SendGrid SDK автоматически ищут OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN и SENDGRID_API_KEY в вашем окружении, соответственно. Другими словами, как только эти окружения заданы в .env, SDK обрабатывают загрузку за вас.
В частности, SDK будут использовать настроенные API-ключи для аутентификации базовых API-вызовов на свои серверы с использованием вашей учетной записи.
Важно: Более подробную информацию о том, как работает Bright Data SDK и как подключить его к необходимым зонам в вашей учетной записи Bright Data, можно найти на официальной странице GitHub или в документации.
Отлично! Строительные блоки для создания рабочего процесса ИИ-мониторинга репутации бренда готовы.
Шаг № 4: Получение URL-адресов Google News
Первым шагом в логике рабочего процесса является сканирование SERPs для поисковых запросов, связанных с брендом, которые вы хотите отслеживать. Это можно сделать с помощью метода search() из Bright Data SDK, который вызывает SERP API за кулисами.
Затем разберите текстовый ответ JSON, полученный от search(), чтобы получить доступ к URL-адресам страниц Google News, которые будут выглядеть следующим образом:
https://www.google.com/search?sca_esv=7fb9df9863b39f3b&hl=en&q=nike&tbm=nws&source=lnms&fbs=AIIjpHxU7SXXniUZfeShr2fp4giZjSkgYzz5-5RrRWAIniWd7tzPwkE1KJWcRvaH01D-XIVr2cowAnfeRRP_dme4bG4a8V_AkFVl-SqROia4syDA2-hwysjgAT-v0BCNgzLBnrhEWcFR7F5dffabwXi9c9pDyztBxQc1yfKVagSlUz7tFb_e8cyIqHDK7O6ZomxoJkHRwfaIn-HHOcZcyM2n-MrnKKBHZg&sa=X&ved=2ahUKEwiX1vu4_KePAxVWm2oFHT6tKsAQ0pQJegQIPhABДобейтесь всего этого с помощью этой функции:
def get_google_news_page_urls(search_queries):
# Получение SERP для заданных поисковых запросов
serp_results = brightdata_client.search(
search_queries,
search_engine="google",
parse=True # Чтобы получить результат SERP в виде разобранной JSON-строки
)
news_page_urls = []
for serp_result in serp_results:
# Загрузка JSON-строки в словарь
serp_data = json.loads(serp_result)
# Извлечение URL-адреса Google News из каждого разобранного SERP
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "News":
news_url = item["href"].
news_page_urls.append(news_url)
return news_page_urlsКогда вы передаете массив запросов в search() (как в данном случае), метод возвращает массив SERPs, по одному для каждого запроса соответственно. Поскольку для параметра parse установлено значение True, каждый результат возвращается в виде строки JSON, которую затем нужно разобрать с помощью встроенного в Python модуля json.
Не забудьте импортировать json из стандартной библиотеки Python:
import jsonПотрясающе! Теперь вы можете программно получить список URL-адресов страниц Google News, связанных с вашим брендом.
Шаг № 5: Соскребите страницы новостей Google и получите URL-адреса лучших новостей
Не забывайте, что одна страница Google News содержит несколько новостных статей:
Итак, идея заключается в следующем:
- Соскрести содержимое страниц Google News и получить результаты в формате Markdown.
- Передать содержимое в формате Markdown искусственному интеллекту (в данном случае модели OpenAI), попросив его выбрать 5 лучших новостных статей для мониторинга репутации бренда.
Выполните первый микрошаг с помощью этой функции:
def scrape_news_pages(news_page_urls):
# Параллельно соскребаем каждую новостную страницу и возвращаем ее содержимое в формате Markdown
return brightdata_client.scrape(
url=news_page_urls,
data_format="markdown"
) Под капотом метод scrape() из Bright Data SDK вызывает API Web Unlocker. Когда вы передаете массив URL-адресов, scrape() выполняет задачу параллельно, получая все страницы одновременно. В данном случае API настроен на возврат данных в формате Markdown, который идеально подходит для интеграции в LLM (что было доказано в нашем бенчмарке формата данных на Kaggle).
Затем выполните второй микрошаг:
def get_best_news_urls(news_pages, num_news):
# Используем GPT для извлечения наиболее релевантных URL-адресов новостей
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system",
"content": f "Извлечение из текста {num_news} наиболее релевантных новостей для мониторинга репутации бренда и возвращение их в виде списка URL-строк."
},
{
"role": "пользователь",
"content": "nn---------------nn".join(news_pages)
},
],
text_format=URLList,
)
return response.output_parsed.urlsЭта функция просто объединяет текстовые данные в формате Markdown, полученные в предыдущей функции, и передает их модели GPT-5-mini OpenAI, прося ее извлечь наиболее релевантные URL-адреса.
Ожидается, что выходные данные будут соответствовать модели URLList, которая представляет собой Pydantic-модель, определенную следующим образом:
class URLList(BaseModel):
urls: List[str].Благодаря опцииtext_format в методе parse() вы указываете OpenAI API вернуть результат в виде экземпляра URLList. По сути, вы получаете список строк, где каждая строка представляет собой URL.
Импортируйте необходимые классы из pydantic:
from pydantic import BaseModel
from typing import ListПотрясающе! Теперь у вас есть структурированный список новостных URL, готовый к соскабливанию и анализу на предмет репутации бренда.
Шаг № 6: Соскребаем новостные страницы и анализируем их для мониторинга репутации бренда
Теперь, когда у вас есть список лучших новостных URL, снова используйте scrape(), чтобы получить их содержимое в формате Markdown:
def scrape_news_articles(news_urls):
# Соскребаем каждый новостной URL и возвращаем список dicts с URL и содержимым
news_content_list = brightdata_client.scrape(
url=news_urls,
data_format="markdown"
)
news_list = []
for url, content in zip(news_urls, news_content_list):
news_list.append({
"url": url,
"content": content
})
return news_listНезависимо от того, на каком домене размещены эти новостные статьи и какие меры защиты от скраппинга приняты, API Web Unlocker позаботится об этом и вернет содержимое каждой статьи в формате Markdown. Более подробно, новостные статьи будут отсканированы параллельно. Чтобы отслеживать, какой URL-адрес новости соответствует какому выходу Markdown, используйте zip().
Далее отправьте каждую новость в формате Markdown в OpenAI, чтобы проанализировать ее на предмет репутации бренда. Для каждой статьи извлекаем:
- Заголовок
- URL-адрес
- краткое резюме
- Быстрая оценка настроения (например, “положительное”, “отрицательное” или “нейтральное”)
- 3-5 действенных, коротких и простых для понимания выводов.
Достичь этого можно с помощью следующей функции:
def process_news_list(news_list):
# Где хранить проанализированные новостные статьи
news_analysis_list = []
# Анализируем каждую новостную статью с помощью GPT для получения информации о мониторинге репутации бренда
for news in news_list:
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"роль": "system",
"content": f""
Учитывая содержание новости:
1. Извлеките заголовок.
2. Извлеките URL.
3. Напишите резюме не более чем из 30 слов.
4. Определите настроение новости как одно из следующих: "положительный", "отрицательный" или "нейтральный".
5. Извлеките из новости 3-5 наиболее действенных, коротких выводов (не более 10/12 слов) о репутации бренда, изложив их четким, лаконичным, понятным языком.
"""
},
{
"роль": "пользователь",
"content": f "NEWS URL: {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NewsAnalysis,
)
# Получите объект новостей, проанализированный на выходе, и добавьте его в список
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_listНа этот раз используется модель Pydantic, заданная в формате text_format:
class NewsAnalysis(BaseModel):
title: str
url: str
резюме: str
sentiment_analysis: str
проницательность: List[str]Итак, результатом работы функции process_news_list() будет список объектов NewsAnalysis.
Круто! Обработка новостей с помощью ИИ для мониторинга репутации бренда завершена.
Шаг № 7: Формирование отчета по электронной почте и его отправка
Вы когда-нибудь задумывались, как структурируются электронные письма и красиво отображаются в почтовом ящике вашего клиента? Это происходит потому, что большинство электронных писем на самом деле представляют собой структурированные HTML-страницы. В конце концов, протокол электронной почты поддерживает отправку HTML-документов.
Сформированный ранее список объектов анализа новостей преобразуйте в JSON, передайте его AI и попросите его создать HTML-документ, готовый к отправке по электронной почте:
def create_html_email_body(news_analysis_list):
# Генерируем структурированное HTML-тело письма из проанализированных новостей
response = openai_client.responses.create(
model="gpt-5-mini",
input=f"""
Учитывая приведенное ниже содержание, сгенерируйте структурированное HTML-тело письма, хорошо отформатированное, отзывчивое и готовое к отправке.
Убедитесь в правильном использовании заголовков, абзацев, цветных меток и ссылок, где это необходимо.
Не включайте верхний и нижний колонтитулы, а также только эту информацию и ничего больше.
СОДЕРЖАНИЕ:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]}
"""
)
return response.output_textНаконец, используйте Twilio SendGrid SDK, чтобы программно отправить письмо:
def send_email(sender, recipients, html_body):
# Отправляем HTML-письмо с помощью SendGrid
message = Mail(
from_email=sender,
to_emails=recipients,
subject="Еженедельный отчет о мониторинге бренда",
html_content=html_body
)
sendgrid_client.send(message)Для этого требуется следующий импорт:
from sendgrid.helpers.mail import MailВот и все! Все функции для реализации этого рабочего процесса AI мониторинга репутации бренда теперь реализованы.
Шаг № 8: Загрузка настроек и конфигураций
Некоторые функции, определенные на предыдущих шагах, принимают определенные аргументы (например, search_queries, num_news, sender, recipients). Эти значения могут меняться от запуска к запуску, поэтому не стоит жестко кодировать их в сценарии Python.
Вместо этого считайте их из файла config.json, содержащего следующие поля:
search_queries: Список запросов репутации бренда для получения новостей.num_news: Количество новостных статей, которые необходимо включить в итоговый отчет.отправитель: Утвержденный SendGrid адрес электронной почты, с которого будет отправлен отчет.получатели: Список адресов электронной почты, на которые будет отправлен HTML-отчет.
Смоделируйте объект конфигурации с помощью следующего класса Pydantic:
class Config(BaseModel):
search_queries: List[str] = Field(..., min_items=1)
num_news: int = Field(..., gt=0)
отправитель: str = Field(..., min_length=1)
получатели: List[str] = Field(..., min_items=1)Определения полей задают правила проверки, чтобы убедиться, что конфигурации соответствуют ожидаемому формату. Импортируйте их с помощью:
from pydantic import FieldДалее прочитайте конфигурации рабочего процесса из локального файла config.json и разберите его на объекты Config:
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config) Добавьте файл config.json в каталог вашего проекта:
brand-reputation-monitoring-workflow/
├── .venv/
├──── .env
├──── config.json # <-----------
└──── workflow.pyИ заполните его чем-то вроде этого:
{
"search_queries": ["apple", "iphone", "ipad"],
"sender": "[email protected]",
"recipients": ["[email protected]", "[email protected]", "[email protected]"],
"num_news": 5
}Адаптируйте значения под свои конкретные задачи. Также помните, что поле отправителя должно быть адресом электронной почты, проверенным в вашем аккаунте SendGrid. В противном случае функция send_email() завершится с ошибкой 403 Forbidden.
Так держать! Еще один шаг – и рабочий процесс завершен.
Шаг № 9: Определите главную функцию
Пришло время все скомпоновать. Вызовите каждую предопределенную функцию в правильном порядке, предоставив нужные данные из конфига:
search_queries = config.search_queries
print(f "Получение URL-адресов страниц Google News для следующих поисковых запросов: {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} URL(ы) страниц Google News получены!n")
print("Скрапирование содержимого каждой страницы Google News...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Страницы Google News выскоблены!n")
print("Извлечение наиболее релевантных URL-адресов новостей...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)} найденных новостных статей:n" + "n".join(f"- {news}" for news in news_urls) + "n")
print("Скрапирование выбранных новостных статей...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} новостных статей соскоблено!")
print("Анализируем каждую новость для мониторинга репутации бренда...")
news_analysis_list = process_news_list(news_list)
print("Анализ новостей завершен!n")
print("Генерирование HTML-тела письма...")
html = create_html_email_body(news_analysis_list)
print("HTML-тело письма сгенерировано!n")
print("Отправка письма с HTML-отчетом о мониторинге репутации бренда...")
send_email(config.sender, config.recipients, html)
print("Письмо отправлено!")Примечание: выполнение этого процесса может занять некоторое время, поэтому полезно добавить журналы, чтобы отслеживать прогресс в терминале. Миссия завершена!
Шаг № 10: Соберите все вместе
Окончательный код файла workflow.py выглядит следующим образом:
from dotenv import load_dotenv
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClient
from pydantic import BaseModel, Field
from typing import List
импортировать json
из sendgrid.helpers.mail import Mail
# Загрузите переменные окружения из файла .env
load_dotenv()
# Инициализация клиента Bright Data SDK
brightdata_client = bdclient()
# Инициализация клиента OpenAI SDK
openai_client = OpenAI()
# Инициализация SDK-клиента SendGrid
sendgrid_client = SendGridAPIClient()
# Модели Pydantic
class Config(BaseModel):
search_queries: List[str] = Field(..., min_items=1)
num_news: int = Field(..., gt=0)
отправитель: str = Field(..., min_length=1)
получатели: List[str] = Field(..., min_items=1)
class URLList(BaseModel):
urls: List[str]
class NewsAnalysis(BaseModel):
заголовок: str
url: str
резюме: str
sentiment_analysis: str
проницательность: Список[str]
def get_google_news_page_urls(search_queries):
# Получение SERP для заданных поисковых запросов
serp_results = brightdata_client.search(
search_queries,
search_engine="google",
parse=True # Чтобы получить результат SERP в виде разобранной JSON-строки
)
news_page_urls = []
for serp_result in serp_results:
# Загрузка JSON-строки в словарь
serp_data = json.loads(serp_result)
# Извлечение URL-адреса Google News из каждого разобранного SERP
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "News":
news_url = item["href"].
news_page_urls.append(news_url)
return news_page_urls
def scrape_news_pages(news_page_urls):
# Параллельно соскребаем каждую новостную страницу и возвращаем ее содержимое в формате Markdown
return brightdata_client.scrape(
url=news_page_urls,
data_format="markdown"
)
def get_best_news_urls(news_pages, num_news):
# Используем GPT для извлечения наиболее релевантных URL-адресов новостей
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system",
"content": f "Извлеките из текста {num_news} наиболее релевантные новости для мониторинга репутации бренда и верните их в виде списка URL-строк."
},
{
"role": "пользователь",
"content": "nn---------------nn".join(news_pages)
},
],
text_format=URLList,
)
return response.output_parsed.urls
def scrape_news_articles(news_urls):
# Соскребаем URL каждой новости и возвращаем список dicts с URL и содержимым
news_content_list = brightdata_client.scrape(
url=news_urls,
data_format="markdown"
)
news_list = []
for url, content in zip(news_urls, news_content_list):
news_list.append({
"url": url,
"content": content
})
return news_list
def process_news_list(news_list):
# Где хранить проанализированные новостные статьи
news_analysis_list = []
# Анализируем каждую новостную статью с помощью GPT для получения информации о мониторинге репутации бренда
for news in news_list:
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"роль": "system",
"content": f""
Учитывая содержание новости:
1. Извлеките заголовок.
2. Извлеките URL.
3. Напишите резюме не более чем из 30 слов.
4. Определите настроение новости как одно из следующих: "положительный", "отрицательный" или "нейтральный".
5. Извлеките из новости 3-5 наиболее действенных, коротких выводов (не более 10/12 слов) о репутации бренда, изложив их четким, лаконичным, понятным языком.
"""
},
{
"роль": "пользователь",
"content": f "NEWS URL: {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NewsAnalysis,
)
# Получите объект новостей, проанализированный на выходе, и добавьте его в список
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_list
def create_html_email_body(news_analysis_list):
# Генерируем структурированное HTML-тело письма из проанализированных новостей
response = openai_client.responses.create(
model="gpt-5-mini",
input=f"""
Учитывая приведенное ниже содержание, сгенерируйте структурированное HTML-тело письма, хорошо отформатированное, отзывчивое и готовое к отправке.
Убедитесь в правильном использовании заголовков, абзацев, цветных меток и ссылок, где это необходимо.
Не включайте верхний и нижний колонтитулы, а также только эту информацию и ничего больше.
СОДЕРЖАНИЕ:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]}
"""
)
return response.output_text
def send_email(sender, recipients, html_body):
# Отправляем HTML-письмо с помощью SendGrid
message = Mail(
from_email=sender,
to_emails=recipients,
subject="Еженедельный отчет о мониторинге бренда",
html_content=html_body
)
sendgrid_client.send(message)
def main():
# Считываем файл конфигурации и проверяем его
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config)
search_queries = config.search_queries
print(f "Извлечение URL страниц Google News для следующих поисковых запросов: {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} URL(ы) страниц Google News получены!n")
print("Скрапирование содержимого каждой страницы Google News...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Страницы Google News выскоблены!n")
print("Извлечение наиболее релевантных URL-адресов новостей...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)} найденных новостных статей:n" + "n".join(f"- {news}" for news in news_urls) + "n")
print("Скрапирование выбранных новостных статей...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} новостных статей соскоблено!")
print("Анализируем каждую новость для мониторинга репутации бренда...")
news_analysis_list = process_news_list(news_list)
print("Анализ новостей завершен!n")
print("Генерирование HTML-тела письма...")
html = create_html_email_body(news_analysis_list)
print("HTML-тело письма сгенерировано!n")
print("Отправка письма с HTML-отчетом о мониторинге репутации бренда...")
send_email(config.sender, config.recipients, html)
print("Письмо отправлено!")
# Запуск главной функции
if __name__ == "__main__":
main()И вуаля! Благодаря Bright Data SDK, OpenAI API и Twilio SendGrid SDK вы смогли создать рабочий процесс мониторинга репутации бренда на основе ИИ менее чем за 200 строк кода.
Шаг № 11: Протестируйте рабочий процесс
Предположим, что ваши поисковые запросы – "nike" и "nike shoes". num_news установлено на 5, а отчет настроен на отправку на вашу личную электронную почту (обратите внимание, что вы можете использовать один и тот же адрес электронной почты и для отправителя, и для первого пункта в получателях).
В активированной виртуальной среде запустите рабочий процесс с помощью команды:
python workflow.pyРезультат в терминале будет выглядеть примерно так:
Получение URL-адресов страниц новостей Google для следующих поисковых запросов: nike, nike shoes
Получено 2 URL-адреса страниц новостей Google!
Скраппинг контента с каждой страницы Google News...
Страницы Google News отсканированы!
Извлечение наиболее релевантных URL-адресов новостей...
Найдено 5 новостных статей:
- https://www.espn.com/wnba/story/_/id/46075454/caitlin-clark-becomes-nike-newest-signature-athlete
- https://wwd.com/footwear-news/sneaker-news/nike-acg-radical-airflow-ultrafly-release-dates-1238068936/
- https://www.runnersworld.com/news/a65881486/cooper-lutkenhaus-professional-contract-nike/
- https://hypebeast.com/2025/8/nike-kobe-3-protro-low-reveal-info
- https://wwd.com/footwear-news/sneaker-news/nike-air-diamond-turf-must-be-the-money-release-date-1238075256/
Скрапирование выбранных новостных статей...
Выбрано 5 статей!
Анализ каждой новостной статьи для мониторинга репутации бренда...
Анализ новостей завершен!
Генерирование HTML-тела письма...
HTML-тело письма создано!
Отправка письма с HTML-отчетом о мониторинге репутации бренда...
Письмо отправлено!Примечание: Результаты будут меняться в зависимости от имеющихся новостей. Поэтому они никогда не будут такими же, как приведенные выше, к тому времени, когда вы прочитаете это руководство.
После сообщения “Email отправлен!” в вашем почтовом ящике должно появиться письмо “Еженедельный отчет по мониторингу бренда”:

Откройте его, и в нем будет что-то вроде:
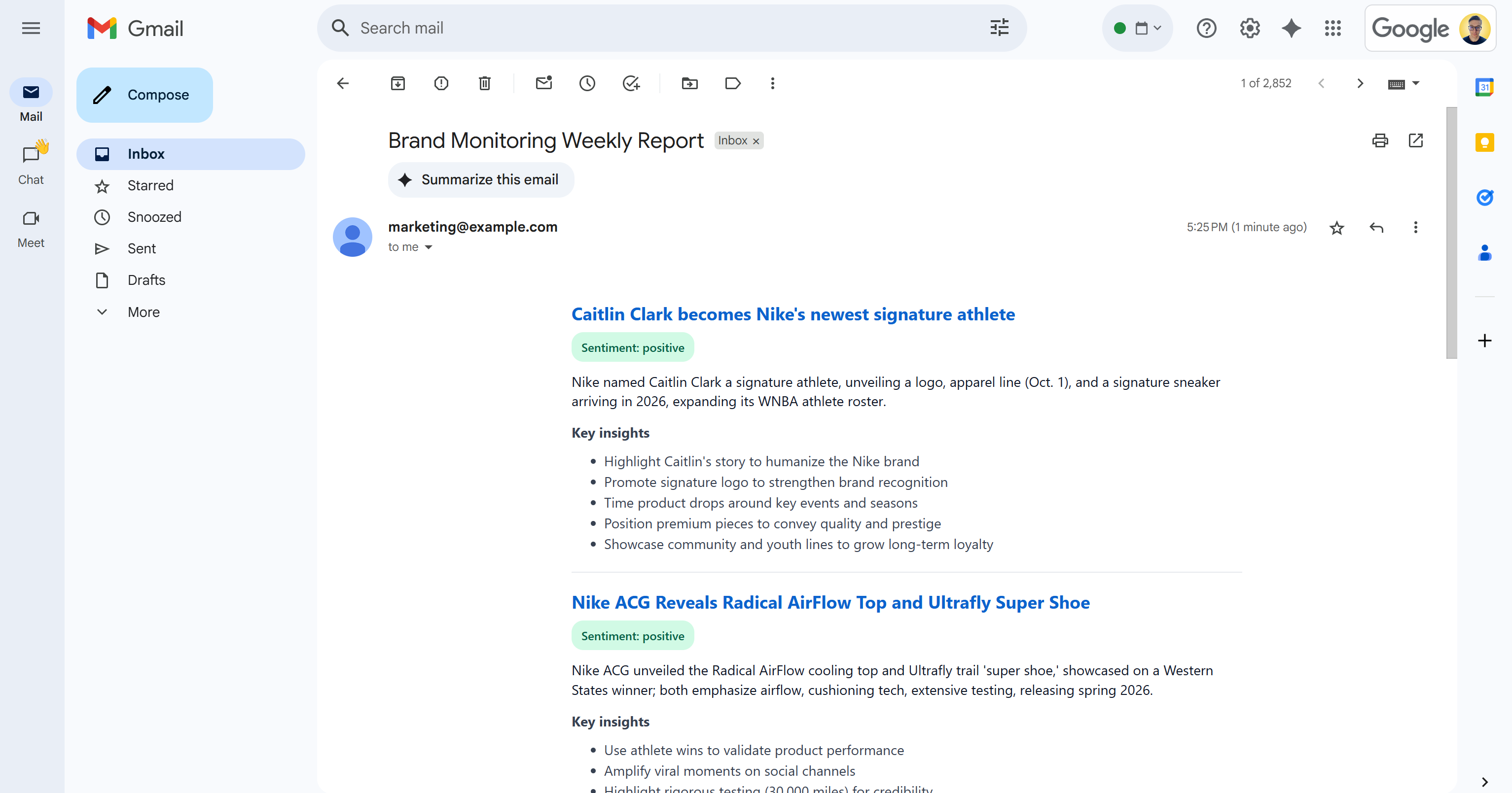
Как видите, ИИ смог создать визуально привлекательный отчет о мониторинге бренда со всеми запрошенными данными.
Прокрутите отчет, и вы увидите:
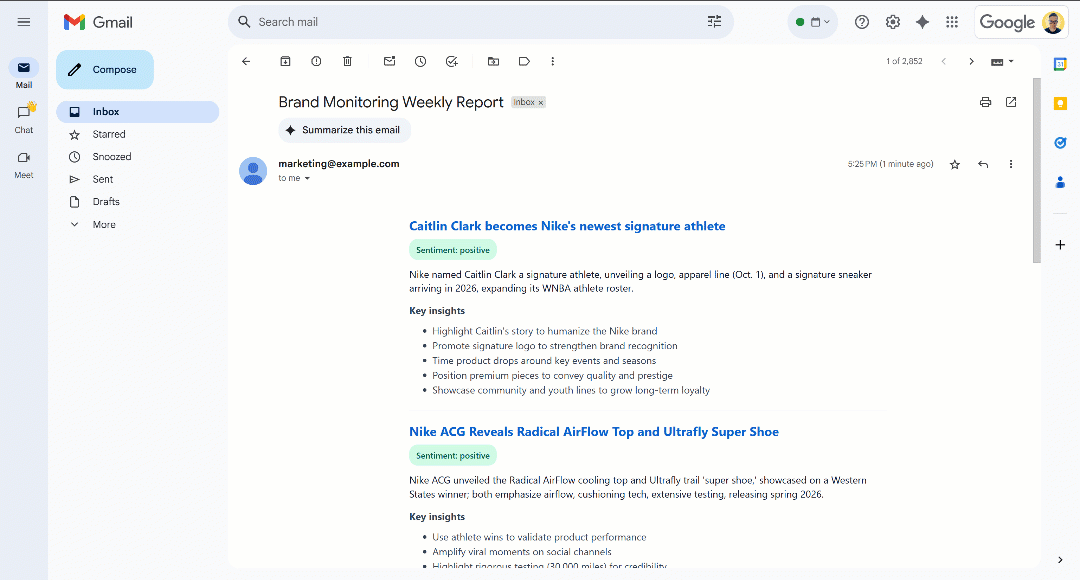
Обратите внимание, что метки настроений выделены цветом, чтобы помочь вам быстро разобраться в настроениях. Кроме того, заголовки новостей выделены синим цветом, так как это ссылки на оригинальные статьи.
И вуаля! Вы начали с нескольких поисковых запросов, а в итоге получили письмо с хорошо структурированным отчетом о мониторинге бренда.
Все это стало возможным благодаря возможностям решений для соскабливания веб-данных, доступных в Bright Data SDK. Помните, что отсканированные страницы возвращаются в оптимизированном для LLM формате Markdown, чтобы любая модель искусственного интеллекта могла проанализировать их для ваших нужд. Изучите другие поддерживаемые агентурные и ИИ сценарии использования рабочих процессов!
Следующие шаги
Текущий рабочий процесс ИИ для мониторинга репутации бренда уже достаточно сложен, но вы можете улучшить его еще больше с помощью этих идей:
- Добавить слой памяти для ранее освещенных новостей: Чтобы не анализировать одни и те же статьи несколько раз, повышая точность отчетов и сокращая дублирование.
- Внедрить шаблонизацию SendGrid для стандартизации: При каждом запуске ИИ может создавать немного разные HTML-отчеты с различной структурой. Чтобы сделать макет единообразным, определите шаблон SendGrid, заполните его сгенерированными данными анализа новостей и отправьте его через SendGrid SDK. Подробнее об этом можно узнать из официальной документации.
- Сохраните сгенерированный HTML-отчет в облаке: Сохраните отчет в S3, чтобы он был заархивирован и доступен для исторического анализа мониторинга бренда.
Заключение
В этой статье вы узнали, как использовать возможности веб-поиска и скрапинга Bright Data для создания рабочего процесса по оценке репутации бренда с помощью искусственного интеллекта. Этот процесс стал еще проще благодаря новому Bright Data SDK, который позволяет получить доступ к продуктам Bright Data с помощью простых вызовов методов.
Представленный здесь рабочий процесс с использованием искусственного интеллекта идеально подходит для маркетинговых команд, заинтересованных в мониторинге своего бренда и получении действенных выводов при небольших затратах. Он помогает сэкономить время и усилия, предоставляя контекстные инструкции для поддержки защиты бренда и принятия решений.
Чтобы создать более сложные рабочие процессы, изучите весь спектр решений в инфраструктуре Bright Data AI для получения, проверки и преобразования живых веб-данных.
Создайте бесплатную учетную запись Bright Data и начните экспериментировать с нашими решениями для работы с веб-данными, готовыми к искусственному интеллекту!




