

В этом руководстве по тонкой настройке GPT-OSS с помощью веб-данных вы узнаете:
- Что такое Unsloth и почему он ускоряет тонкую настройку.
- Как собирать качественные учебные данные с помощью API для скраппинга Bright Data
- Как настроить среду для эффективной тонкой настройки
- Как выполнить тонкую настройку GPT-OSS с помощью полного пошагового руководства
Давайте начнем!
Что такое Unsloth и зачем его использовать для тонкой настройки?
Unsloth – это легковесная библиотека, которая значительно ускоряет тонкую настройку LLM и при этом полностью совместима с экосистемой Hugging Face (Hub, трансформаторы, PEFT, TRL). Библиотека поддерживает большинство графических процессоров NVIDIA, от GTX 1070 до H100, и легко работает со всем набором тренеров из библиотеки TRL.
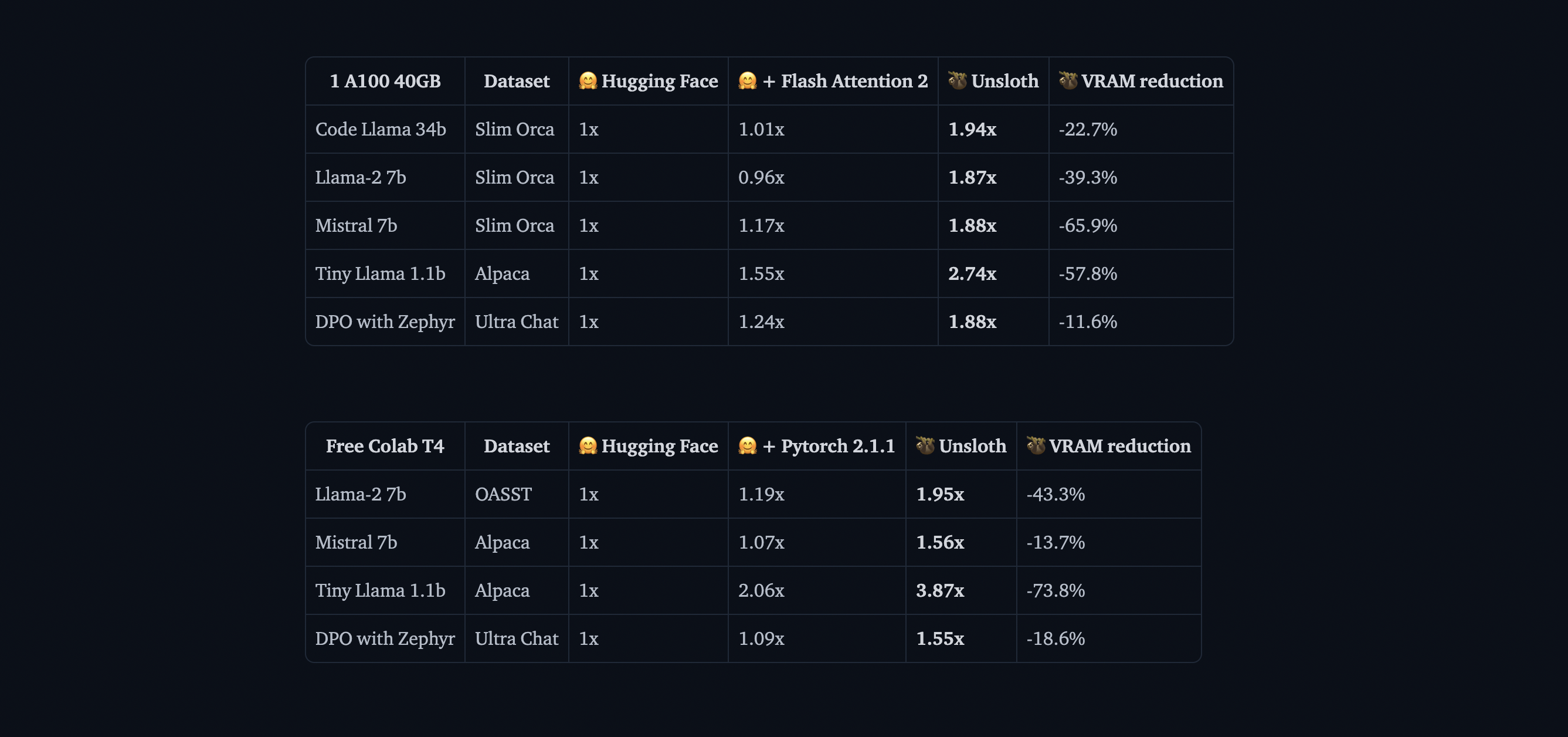
Прирост производительности Unsloth впечатляет. В бенчмарках он достигает в 2 раза более высокой скорости обучения по сравнению со стандартными реализациями трансформаторов, используя при этом на 40 % меньше памяти. Это означает, что вы можете обучать более крупные модели или использовать большие объемы партий на том же оборудовании. И, пожалуй, самое главное: точность модели снижается на 0 %, так что вы получаете все эти преимущества без ущерба для качества модели.
Понимание моделей GPT-OSS
Выпуск OpenAI GPT-OSS знаменует собой значительный сдвиг в подходе OpenAI к разработке ИИ. Впервые мы получили доступ к настоящим моделям GPT без ограничений API, тарификации на основе использования или ограничений по тарифу.
GPT-OSS поставляется в двух основных вариантах:
- GPT-OSS-120B: эта более крупная модель соответствует качеству GPT-4, но требует не менее 80 ГБ памяти GPU.
- GPT-OSS-20B: сравнимая с GPT-3.5 по производительности, эта модель эффективно работает на 16 ГБ GPU (идеально подходит для нашего учебника).
Уникальная особенность, которая отличает GPT-OSS от других открытых моделей, – это контроль усилия рассуждений. Вы можете настроить, насколько глубоко модель обдумывает проблемы, установив уровень рассуждений на “низкий”, “средний” или “высокий”. Это позволяет балансировать между скоростью и точностью в зависимости от конкретного случая использования.
Почему качественные данные важны для тонкой настройки
Тонкая настройка хороша лишь настолько, насколько хороши данные, которые вы ей предоставляете. У нас может быть самая сложная система обучения, но если наши данные шумные, непоследовательные или плохо отформатированы, ваша модель будет учиться на тех же проблемах. Именно поэтому мы будем использовать API веб-скрапера Bright Data для получения чистых, хорошо отформатированных и точных данных.
Bright Data решает сложные задачи веб-скрейпинга, которые часто ставят под сомнение пользовательские решения. Она управляет ротацией IP-адресов, чтобы избежать ограничения скорости, автоматически решает CAPTCHA, обрабатывает динамический контент с JavaScript-рендерингом и поддерживает постоянное качество данных при миллионах запросов.
В нашем учебном пособии мы будем использовать API Bright Data для сбора документации Python, которую затем превратим в обучающие данные для нашей модели.
Предварительные условия и настройка среды
Прежде чем мы начнем, давайте убедимся, что у вас есть все необходимое для успешной тонкой настройки. Мы будем использовать Google Colab, поскольку он предоставляет бесплатный доступ к GPU, но этот же процесс работает на любой машине с не менее чем 16 ГБ VRAM.
Требования к аппаратному обеспечению
Для этого урока вам понадобятся:
- Графический процессор с не менее чем 16 ГБ VRAM (T4, V100 или лучше).
- 25 ГБ свободного места на диске для хранения веса моделей и контрольных точек
- Стабильное интернет-соединение для загрузки моделей и зависимостей
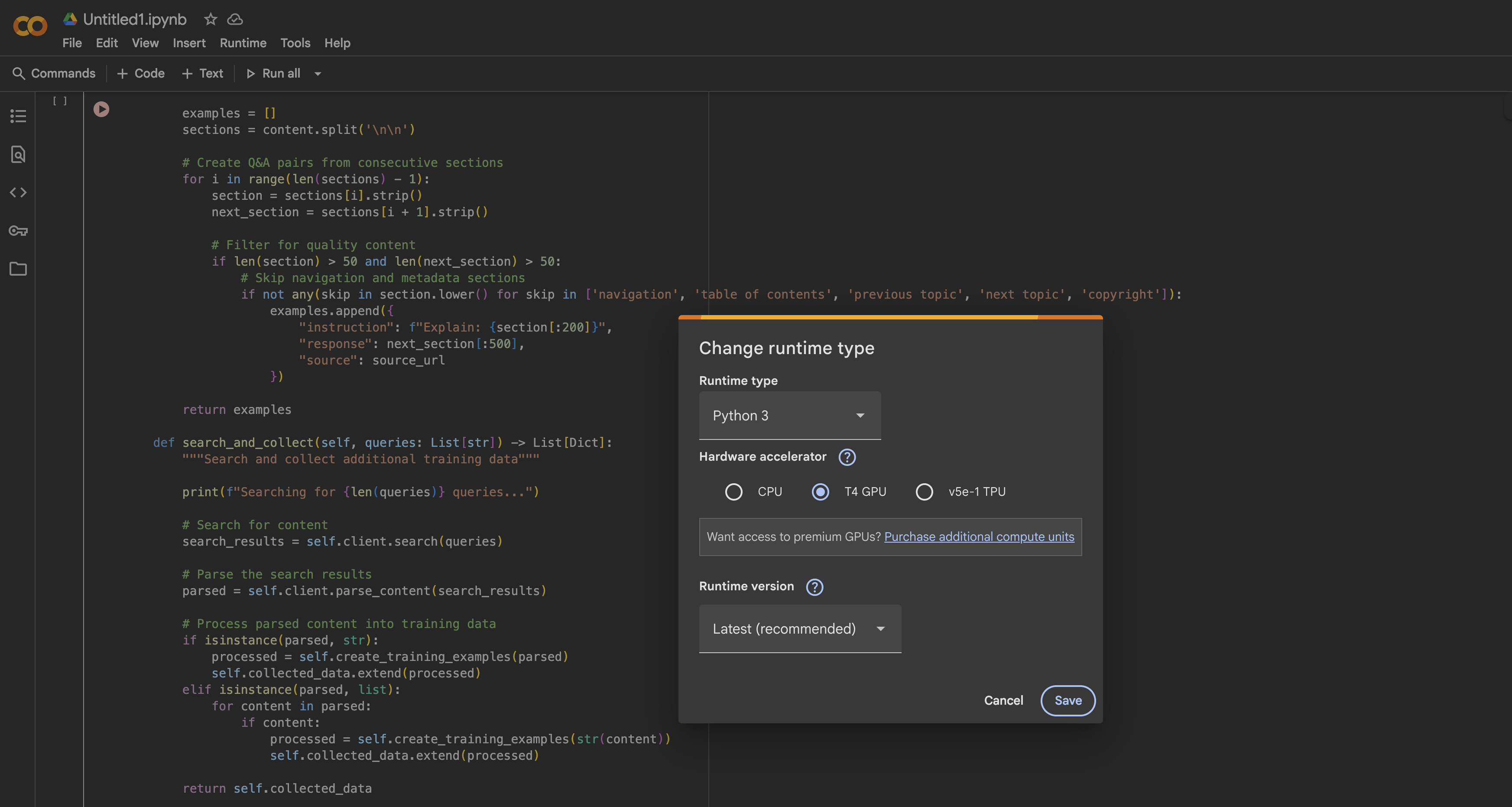
В Google Colab вы можете бесплатно получить доступ к графическому процессору T4, открыв новый ноутбук:
- Открыть новый блокнот
- Перейдите в раздел Время выполнения → Изменить тип времени выполнения
- Выбрать GPU в качестве аппаратного ускорителя
- Нажмите кнопку Сохранить, чтобы применить изменения.
Установка Unsloth и зависимостей
После того как ваша среда выполнения на GPU будет готова, мы установим Unsloth и все необходимые зависимости. Процесс установки оптимизирован, чтобы избежать конфликтов между различными версиями пакетов:
%%capture
# Установка Unsloth и основных зависимостей
!pip install --upgrade -qqq uv
try: import numpy; get_numpy = f "numpy=={numpy.__version__}"
except: get_numpy = "numpy"
!uv pip install -qqq
"torch>=2.8.0" "triton>=3.4.0" {get_numpy} torchvision bitsandbytes "transformers>=4.55.3"
"unsloth_zoo[base] @ git+https://github.com/unslothai/unsloth-zoo"
"unsloth[base] @ git+https://github.com/unslothai/unsloth"
git+https://github.com/triton-lang/triton.git@05b2c186c1b6c9a08375389d5efe9cb4c401c075#subdirectory=python/triton_kernels
!uv pip install --upgrade --no-deps transformers==4.56.2 tokenizers
!uv pip install --no-deps trl==0.22.2
!pip install -q brightdata-sdkЭтот сценарий установки решает несколько важных задач. Во-первых, он использует uv для более быстрого разрешения пакетов. Он также фиксирует определенные версии, чтобы избежать проблем с совместимостью, устанавливает пользовательские ядра Triton от Unsloth для оптимальной производительности и включает Bright Data SDK для нашего этапа сбора данных.
Проверка настройки GPU
После установки давайте проверим, правильно ли определяется ваш GPU и достаточно ли у него памяти:
import torch
# Получение информации о GPU
gpu_stats = torch.cuda.get_device_properties(0)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f "GPU = {gpu_stats.name}")
print(f "Максимальная память = {max_memory} GB")
print(f "Версия CUDA = {torch.version.cuda}")
print(f "Версия PyTorch = {torch.__version__}")
# Проверьте минимальные требования
if max_memory < 15:
print("⚠️ Warning: Your GPU might not have enough memory for GPT-OSS-20B")
else:
print("✅ Ваш GPU имеет достаточно памяти для тонкой настройки")Вы должны увидеть не менее 15 ГБ доступной памяти GPU. Графический процессор T4 в бесплатной Colab предоставляет 16 ГБ, что идеально подходит для наших нужд с оптимизацией Unsloth.
Загрузка GPT-OSS с помощью Unsloth
Теперь мы загрузим модель GPT-OSS с помощью оптимизированного загрузчика Unsloth. По сравнению со стандартными трансформаторами этот процесс удивительно прост, поскольку Unsloth обрабатывает все детали оптимизации автоматически.
Загрузка базовой модели
from unsloth import FastLanguageModel
import torch
# Конфигурация
max_seq_length = 1024 # Настраивается в зависимости от ваших данных
dtype = None # Автоматическое определение лучшего dtype для вашего GPU
# Unsloth предоставляет предварительно квантованные модели для более быстрой загрузки
fourbit_models = [
"unsloth/gpt-oss-20b-unsloth-bnb-4bit", # BitsAndBytes 4bit
"unsloth/gpt-oss-120b-unsloth-bnb-4bit",
"unsloth/gpt-oss-20b", # Формат MXFP4
"unsloth/gpt-oss-120b",
]
# Загрузите модель
модель, токенизатор = FastLanguageModel.from_pretrained(
model_name = "unsloth/gpt-oss-20b",
dtype = dtype,
max_seq_length = max_seq_length,
load_in_4bit = True, # Необходимо для подгонки под 16 ГБ
full_finetuning = False, # Использование LoRA для эффективности
)
print(f"✅ Модель загружена успешно!")
print(f "Размер модели: {model.num_parameters():,} параметров")
print(f "Использование устройства: {model.device}")Метод FastLanguageModel.from_pretrained() делает несколько вещей за кулисами. Он автоматически определяет возможности вашего GPU и соответствующим образом оптимизирует его, применяет 4-битное квантование для сокращения использования памяти на 75 %, настраивает модель для обучения LoRA вместо полной тонкой настройки, а также настраивает механизмы внимания, экономящие память.
Настройка адаптеров LoRA
LoRA (Low-Rank Adaptation) – это то, что делает тонкую настройку возможной на потребительском оборудовании. Вместо того чтобы обновлять все параметры модели, мы обучаем только небольшие матрицы адаптеров, которые вставляются в ключевые слои:
model = FastLanguageModel.get_peft_model(
model,
r = 8, # Ранг LoRA - выше = больше производительность, но медленнее
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 16, # коэффициент масштабирования LoRA
lora_dropout = 0, # Отключение отсеивания для ускорения обучения
bias = "none", # Не тренировать условия смещения
use_gradient_checkpointing = "unsloth", # Критично для экономии памяти
random_state = 3407,
use_rslora = False, # Стандартный LoRA работает лучше для большинства случаев
loftq_config = None,
)
# Отображение статистики обучения
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
all_params = sum(p.numel() for p in model.parameters())
обучаемый_процент = 100 * обучаемые_параметры / все_параметры
print(f "Обучение {trainable_params:,} параметров из {all_params:,}")
print(f "Это всего лишь {trainable_percent:.2f}% всех параметров!")
print(f "Экономия памяти: ~{(1 - trainable_percent/100) * 40:.1f}GB")Эта конфигурация позволяет найти баланс между эффективностью обучения и емкостью модели. При r=8 мы обучаем менее 1 % всех параметров и при этом достигаем отличных результатов тонкой настройки. Одна только градиентная контрольная точка экономит около 30 % памяти, что может быть разницей между подгонкой модели в памяти и ошибками OOM (Out of Memory).
Тестирование GPT-OSS Reasoning Effort Control
Прежде чем приступить к тонкой настройке, давайте изучим уникальную функцию GPT-OSS “Усилие рассуждения”. Она позволяет контролировать, сколько “размышлений” модель делает перед ответом:
from transformers import TextStreamer
# Тестовая задача, требующая математических рассуждений
сообщения = [
{ "role": "user", "content": "Решите x^5 + 3x^4 - 10 = 3. Объясните свой подход."}
]
# Тест с малым количеством рассуждений
print("="*60)
print("LOW REASONING (Быстро, но менее тщательно)")
print("="*60)
inputs = tokenizer.apply_chat_template(
сообщения,
add_generation_prompt = True,
return_tensors = "pt",
return_dict = True,
reasoning_effort = "low",
).to("cuda")
text_streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, max_new_tokens = 128, streamer = text_streamer)
# Тест с высоким уровнем аргументации
print("n" + "="*60)
print("HIGH REASONING (Медленнее, но точнее)")
print("="*60)
inputs = tokenizer.apply_chat_template(
сообщения,
add_generation_prompt = True,
return_tensors = "pt",
return_dict = True,
reasoning_effort = "high",
).to("cuda")
_ = model.generate(**inputs, max_new_tokens = 512, streamer = text_streamer)Запустив этот код, мы увидим, что при “низких” рассуждениях модель выдает быстрый приблизительный ответ, а при “высоких” – более подробное решение с пошаговой работой. Эта функция неоценима для баланса между скоростью и точностью в производственных развертываниях.
Сбор обучающих данных с помощью Bright Data
Теперь мы соберем высококачественные учебные данные с помощью API веб-скрапера Bright Data. Этот подход гораздо надежнее, чем создание собственного скрапера, так как Bright Data обрабатывает всю сложную инфраструктуру, необходимую для крупномасштабного Веб-скрейпинга.
Настройка сборщика данных
from brightdata import bdclient
from typing import List, Dict
импорт re
импорт json
class DataCollector:
def __init__(self, api_token: str):
"""
Инициализация клиента Bright Data для веб-скрейпинга.
Args:
api_token: Ваш токен API Bright Data
"""
self.client = bdclient(api_token=api_token)
self.collected_data = []
print("✅ Клиент Bright Data инициализирован")
def collect_documentation(self, urls: List[str]) -> List[Dict]:
"""
Соскабливаем страницы документации и преобразуем их в обучающие данные.
Этот метод обрабатывает как пакетные, так и индивидуальные запросы к URL,
автоматически возвращаясь к индивидуальным запросам, если пакетный не работает.
"""
print(f "Starting to scrape {len(urls)} URLs...")
try:
# Попытка пакетного соскабливания для повышения эффективности
results = self.client.scrape(urls, data_format="markdown")
if isinstance(results, str):
# Возвращается один результат
print("Обработка одного результата...")
training_data = self.process_single_result(results)
elif isinstance(results, list):
# Возвращается несколько результатов
print(f "Обработка {len(results)} результатов...")
training_data = []
for i, content in enumerate(results, 1):
if content:
print(f" Обработка результата {i}/{len(results)}")
examples = self.process_single_result(content)
training_data.extend(examples)
else:
print(f "Неожиданный тип результата: {type(results)}")
training_data = []
except Exception as e:
print(f "Пакетный скрейпинг не удался: {e}")
print("Возвращаемся к индивидуальному скраппингу URL...")
# Возврат к пакетному скраппингу: скраппинг URL по одному
training_data = []
for url in urls:
try:
print(f" Scraping: {url}")
content = self.client.scrape(url, data_format="markdown")
if content:
examples = self.process_single_result(content)
training_data.extend(examples)
print(f" ✓ Извлечено {len(examples)} примеров")
except Exception as url_error:
print(f" ✗ Failed: {url_error}")
self.collected_data = training_data
print(f"n✅ Сбор завершен: {len(self.collected_data)} учебных примеров")
return self.collected_dataЧто делает этот код:
- Интеллектуальная стратегия возврата: Для повышения эффективности сборщик сначала пытается выполнить пакетный скрейпинг. Если это не удается (из-за проблем с сетью или ограничений API), он автоматически возвращается к индивидуальному скраппингу URL.
- Отслеживание прогресса: Обновления в реальном времени показывают нам, что именно происходит в процессе скраппинга, что облегчает отладку.
- Устойчивость к ошибкам: Каждый URL завернут в свой собственный блок try-catch, поэтому один неудачный URL не остановит весь процесс сбора.
- Формат Markdown: Мы запрашиваем данные в формате Markdown, потому что он чище, чем HTML, и его легче переработать в учебные данные.
Клиент Bright Data решает за нас несколько сложных задач:
- Ротация IP-адресов, чтобы избежать ограничения скорости
- Автоматическое решение CAPTCHA
- рендеринг страниц с большим количеством JavaScript
- Повторное выполнение неудачных запросов с экспоненциальным резервированием
Обработка соскобленного контента в обучающие данные
Ключом к хорошей тонкой настройке являются чистые, хорошо отформатированные данные. Вот как мы обрабатываем необработанный контент в пары “вопрос-ответ”:
def process_single_result(self, content: str) -> List[Dict]:
"""
Обработка отсканированного контента в чистые учебные пары вопросов и ответов.
Этот метод выполняет агрессивную очистку, чтобы удалить все
артефактов форматирования и создания естественно звучащих примеров.
"""
примеры = []
# Шаг 1: Удаление всего форматирования HTML и Markdown
content = re.sub(r'<[^>]+>', '', content) # HTML-теги
content = re.sub(r'', '', content) # Изображения
content = re.sub(r'[([^]]+)]([^)]+)', r'1', content) # Ссылки
content = re.sub(r'``[^`]*``', '', content) # Блоки кода
content = re.sub(r'`[^`]+`', '', content) # Встроенный код
content = re.sub(r'[#*_~>`|-]+', ' '', content) # Символы уценки
content = re.sub(r'\(.)', r'1', content) # Эскейп-последовательности
content = re.sub(r'https?://[^s]+', '', content) # URL-адреса
content = re.sub(r'S+.w+', '', content) # Пути к файлам
content = re.sub(r's+', ' '', content) # Нормализация пробельных символов
# Шаг 2: Разделение на предложения
предложения = re.split(r'(?<=[.!?])s+', content)
# Шаг 3: Отфильтруйте навигационный и шаблонный контент
cleanan_sentences = []
skip_patterns = ['navigation', 'copyright', 'index',
'оглавление', 'предыдущий', 'следующий',
'нажмите здесь', 'скачать', 'поделиться']
для sent в sentences:
sent = sent.strip()
# Сохраните только содержательные предложения
if (len(sent) > 30 и
not any(skip in sent.lower() for skip in skip_patterns)):
clean_sentences.append(sent)
# Шаг 4: Создайте пары вопросов и ответов из последовательных предложений
for i in range(0, len(clean_sentences) - 1):
инструкция = clean_sentences[i][:200].strip()
ответ = clean_sentences[i + 1][:300].strip()
# Убедитесь, что обе части содержательны
if len(instruction) > 20 и len(response) > 30:
examples.append({
"инструкция": инструкция,
"response": response
})
вернуть примерыКак работает обработка:
Метод process_single_result преобразует необработанный веб-контент в чистые обучающие данные с помощью четырех критических шагов:
- Шаг 1 – Агрессивная очистка: Мы удаляем все артефакты форматирования, которые могут запутать модель:
- HTML-теги, которые могли выжить после преобразования в Markdown
- Ссылки на изображения и ссылки, которые не добавляют ценности для понимания текста
- Блоки кода и встроенный код (нам нужна проза, а не примеры кода)
- Специальные символы и экранирующие последовательности, которые создают шум
- Шаг 2 – Сегментация предложений: Мы разбиваем содержимое на отдельные предложения с помощью знаков препинания. Таким образом, мы получаем логические единицы текста для работы.
- Шаг 3 – Фильтрация качества: Мы удаляем:
- Короткие предложения (менее 30 символов), в которых отсутствует суть
- Навигационные элементы типа “нажмите здесь” или “следующая страница”
- Шаблонный контент, например, уведомления об авторских правах
- Любые предложения, содержащие общие шаблоны веб-навигации
- Шаг 4 – Создание пар: Мы создаем обучающие пары, рассматривая последовательные предложения как пары “вопрос-ответ”. Это работает потому, что документация часто следует схеме изложения концепции, а затем ее объяснения.
В результате получаются чистые, контекстуальные данные для обучения, которые учат модель естественному потоку и шаблонам ответов.
Сбор и проверка данных
Теперь давайте соберем все вместе и соберем наши учебные данные:
# Инициализируйте коллектор с помощью вашего API-токена
# Получите свой токен из: /cp/api_tokens
BRIGHTDATA_API_TOKEN = "your_brightdata_api_token_here"
collector = DataCollector(api_token=BRIGHTDATA_API_TOKEN)
# URL-адреса для соскоба - документация Python является отличным учебным материалом
urls = [
"https://docs.python.org/3/tutorial/introduction.html",
"https://docs.python.org/3/tutorial/controlflow.html",
"https://docs.python.org/3/tutorial/datastructures.html",
"https://docs.python.org/3/tutorial/modules.html",
"https://docs.python.org/3/tutorial/classes.html",
]
print("="*60)
print("НАЧАЛО СБОРА ДАННЫХ")
print("="*60)
учебные_данные = collector.collect_documentation(urls)
# Проверьте, что мы получили данные
if len(training_data) == 0:
print("⚠️ ERROR: Не собраны обучающие данные!")
print("nШаги по устранению неполадок:")
print("1. Убедитесь, что ваш токен API Bright Data правильный")
print("2. Убедитесь, что на вашем счету достаточно кредитов")
print("3. Попробуйте сначала использовать один URL-адрес для проверки возможности подключения")
raise ValueError("Данные для обучения не собраны")Понимание настройки сбора данных:
- API Token: Чтобы получить API-токен, вам нужно зарегистрироваться на сайте Bright Data. Компания предлагает бесплатную пробную версию с кредитами для начала работы.
- Выбор URL: Мы используем документацию Python, потому что:
- Она хорошо структурирована и последовательна.
- Она содержит технический контент, идеально подходящий для обучения помощника по кодингу
- Объяснительный стиль хорошо переносится в формат вопросов и ответов
- Она общедоступна и основана на этических нормах.
- Обработка ошибок: Проверка достоверности гарантирует, что вы не продолжите работу с пустым набором данных, что впоследствии приведет к сбою обучения. Шаги по устранению неполадок помогают диагностировать распространенные проблемы.
Окончательная проверка и очистка данных
Прежде чем использовать данные для обучения, мы выполняем последнюю очистку:
# Окончательная валидация и очистка
def final_validation(examples: List[Dict]) -> List[Dict]:
"""
Выполняем финальную валидацию и дедупликацию обучающих примеров.
"""
cleanan_data = []
seen_instructions = set()
для ex в examples:
instruction = ex.get('instruction', '').strip()
response = ex.get('response', '').strip()
# Последний проход очистки
инструкция = re.sub(r'[^a-zA-Z0-9s.,?!]', '', инструкция)
response = re.sub(r'[^a-zA-Z0-9s.,?!]', '', response)
# Удаление дубликатов и обеспечение качества
if (len(instruction) > 10 and
len(response) > 20 и
instruction not in seen_instructions):
seen_instructions.add(instruction)
cleanan_data.append({
"инструкция": инструкция,
"response": response
})
return cleanan_data
training_data = final_validation(training_data)
print(f"n✅ Финальный набор данных: {len(training_data)} уникальных примеров")
print("nВыборка обучающих примеров:")
print("="*60)
for i, example in enumerate(training_data[:3], 1):
print(f"nПример {i}:")
print(f "Q: {example['instruction']}")
print(f "A: {example['response']}")Чего достигает валидация:
- Дедупликация: Набор
seen_instructionsгарантирует, что у нас не будет дублирующихся вопросов, которые могут привести к завышению оценки во время обучения. - Окончательная очистка символов: Мы удаляем все оставшиеся специальные символы, кроме основных знаков препинания, обеспечивая чистоту и единообразие текста.
- Проверка длины: Мы соблюдаем минимальную длину, чтобы обеспечить содержательность примеров:
- Инструкции должны быть не менее 10 символов
- Ответы должны быть не менее 20 символов.
- Гарантия качества: Распечатав примеры, вы можете визуально убедиться в качестве данных, прежде чем приступать к обучению.
На выходе должны получиться чистые, читаемые пары вопросов и ответов, которые имеют смысл использовать в качестве обучающих данных. Если примеры выглядят нелепо или плохо отформатированы, возможно, вам нужно настроить параметры обработки или выбрать другие URL-адреса источников.
Профессиональный совет: для использования в производственных целях воспользуйтесь торговой площадкой Bright Data для сбора данных. Наборы данных для различных доменов помогут вам сэкономить время и обеспечить стабильное качество.
Форматирование данных для обучения GPT-OSS
GPT-OSS ожидает данные в определенном формате чата. Мы воспользуемся утилитами Unsloth, чтобы обеспечить правильное форматирование данных для оптимальных результатов обучения:
from unsloth.chat_templates import standardize_sharegpt
from Наборы данных import Dataset
def prepare_dataset(raw_data: List[Dict]):
"""
Преобразование необработанных пар вопросов и ответов в правильно отформатированные наборы данных для обучения.
Эта функция обрабатывает:
1. Преобразование в формат сообщений
2. Применение шаблона чата GPT-OSS
3. Исправление любых проблем с форматированием
"""
print("Подготовка наборов данных для обучения...")
# Шаг 1: преобразование в формат сообщений чата
форматированные_данные = []
for item in raw_data:
formatted_data.append({
"messages": [
{"роль": "user", "content": item["instruction"]},
{ "role": "помощник", "содержимое": item["ответ"]}
]
})
# Шаг 2: Создание набора данных HuggingFace
dataset = Dataset.from_list(formatted_data)
print(f "Created dataset with {len(dataset)} examples")
# Шаг 3: Стандартизация в формат ShareGPT
dataset = standardize_sharegpt(dataset)Что происходит в этой первой части:
- Преобразование формата сообщения: Мы преобразуем наши простые пары вопросов и ответов в формат разговора, который ожидают модели GPT. Каждый тренировочный пример превращается в разговор в два оборота с вопросом пользователя и ответом ассистента.
- Создание наборов данных: Класс HuggingFace’s Dataset обеспечивает эффективную работу с данными, включая:
- Доступ к большим наборам данных с использованием памяти
- Встроенные пакетная обработка и перемешивание
- Совместимость со всей экосистемой HuggingFace.
- Стандартизация ShareGPT: Функция
standardize_sharegptобеспечивает соответствие наших данных формату ShareGPT, который стал стандартом де-факто для обучения моделей чата. Это позволяет решить крайние случаи и обеспечить согласованность.
Применение шаблона чата
Теперь мы применим специфические требования GPT-OSS к форматированию:
# Шаг 4: Применение специфического шаблона чата GPT-OSS
def formatting_prompts_func(examples):
"""Применим шаблон чата GPT-OSS к каждому примеру."""
convos = examples["messages"]
texts = []
for convo in convos:
# Применяем шаблон без подсказки генерации (мы тренируемся)
text = tokenizer.apply_chat_template(
convo,
tokenize = False,
add_generation_prompt = False
)
texts.append(text)
return {"text": texts}
наборы данных = dataset.map(
formatting_prompts_func,
batched = True,
desc = "Применение шаблона чата"
)Понимание применения шаблона:
- Шаблон чата Назначение: Каждое семейство моделей имеет свои собственные специальные теги и форматирование. GPT-OSS использует такие теги, как
<|start|>,<|message|>и<|channel|>, чтобы разграничить различные части разговора. - Нет подсказки поколения: Мы установили
add_generation_prompt = False, потому что мы обучаемся, а не генерируем. Во время обучения мы хотим, чтобы модель видела законченные разговоры, а не подсказки, ожидающие завершения. - Пакетная обработка: Параметр
batched = Trueобрабатывает несколько примеров одновременно, что значительно ускоряет процесс форматирования больших наборов данных. - Текстовый вывод: На этом этапе мы сохраняем вывод в виде текста (не токенизированного), поскольку тренер будет обрабатывать токенизацию с помощью собственных настроек.
Проверка и исправление проблем с форматом
GPT-OSS предъявляет особые требования к тегу канала, которые нам необходимо проверить:
# Шаг 5: Проверка и исправление тега канала, если необходимо
sample_text = dataset[0]['text']
print("nПроверка формата...")
print(f "Образец (первые 200 символов): {sample_text[:200]}")
если "<|channel|>" отсутствует в sample_text:
print("⚠️ Отсутствует тег канала, исправляем формат...")
def fix_formatting(examples):
"""Добавьте тег channel для совместимости с GPT-OSS."""
fixed_texts = []
for text in examples["text"]:
# GPT-OSS ожидает тег канала между ролью и сообщением
text = text.replace(
"<|start|>assistant<|message|>",
"<|start|>assistant<|channel|>final<|message|>"
)
fixed_texts.append(text)
return {"text": fixed_texts}
наборы данных = dataset.map(
fix_formatting,
batched = True,
desc = "Добавление тегов каналов"
)
print("✅ Формат исправлен")
print(f"n✅ Наборы данных готовы: {len(dataset)} отформатированных примеров")
вернуть набор данных
# Подготовить набор данных
dataset = prepare_dataset(training_data)Почему тег канала имеет значение:
- Функция тега канала: Тег
<|channel|>finalсообщает GPT-OSS, что это окончательный ответ, а не промежуточный шаг рассуждения. Это часть уникальной системы контроля усилий GPT-OSS по аргументации. - Проверка формата: Мы проверяем, существует ли тег, и добавляем его, если он отсутствует. Это предотвращает сбои в обучении из-за несоответствия форматов.
- Автоматическое исправление: Операция замены обеспечивает совместимость, не требуя ручного вмешательства. Это особенно важно при использовании различных версий токенизаторов, которые могут иметь разное поведение по умолчанию.
Статистика и проверка наборов данных
Наконец, давайте проверим наш подготовленный набор данных:
# Вывести статистику
print("nDataset Statistics:")
print(f "Количество примеров: {len(dataset)}")
print(f "Средняя длина текста: {sum(len(x['text']) for x in dataset) / len(dataset):.0f} chars")
# Показать пример с полным форматированием
print("nФорматированный пример:")
print("="*60)
print(dataset[0]['text'][:500])
print("="*60)
# Проверьте, что все примеры имеют правильный формат
format_checks = {
"has_user_tag": all("<|start|>user" in ex['text'] for ex in dataset),
"has_assistant_tag": all("<|start|>assistant" in ex['text'] for ex in dataset),
"has_channel_tag": all("<|channel|>" in ex['text'] for ex in dataset),
"has_message_tags": all("<|message|>" in ex['text'] for ex in dataset),
}
print("nВалидация формата:")
для check, passed в format_checks.items():
status = "✅" if passed else "❌"
print(f"{status} {check}: {passed}")На что обратить внимание при проверке:
- Статистика длины: Средняя длина текста помогает установить подходящую длину последовательности для обучения. Если текст слишком длинный, возможно, его нужно усечь или использовать большее значение max_seq_length.
- Полнота формата: Все четыре проверки должны быть пройдены:
- Метки пользователя указывают, с чего начинается пользовательский ввод
- Теги помощников отмечают ответы модели
- Теги каналов определяют тип ответа
- Теги сообщений содержат фактическое содержимое
- Визуальный контроль: Распечатанный пример позволяет увидеть, на чем именно будет тренироваться модель. Он должен выглядеть следующим образом:
<|start|>user<|message|>Ваш вопрос здесь<|end|>
<|start|>assistant<|channel|>final<|message|>The response here<|end|>Если какая-либо проверка прошла неудачно, обучение может пройти некорректно или модель выучит неправильные паттерны. Автоматическое исправление должно справиться с большинством проблем, но ручная проверка поможет выявить крайние случаи.
Настройка обучения с помощью Unsloth и TRL
Теперь мы настроим конфигурацию обучения. Unsloth легко интегрируется с библиотекой TRL от Hugging Face, предоставляя нам лучшее из двух миров: оптимизацию скорости Unsloth и проверенные алгоритмы обучения TRL.
from trl import SFTConfig, SFTTrainer
from unsloth.chat_templates import train_on_responses_only
# Создаем конфигурацию обучения
training_config = SFTConfig(
# Основные настройки
per_device_train_batch_size = 2, # Настраивается в зависимости от памяти вашего GPU
gradient_accumulation_steps = 4, # Эффективный размер партии = 2 * 4 = 8
warmup_steps = 5,
max_steps = 60, # Для быстрого тестирования; увеличьте для производства
# Настройки скорости обучения
скорость обучения = 2e-4,
lr_scheduler_type = "linear",
# Настройки оптимизации
optim = "adamw_8bit", # 8-битный оптимизатор экономит память
weight_decay = 0.01,
# Ведение журнала и сохранение
logging_steps = 1,
save_steps = 20,
output_dir = "outputs",
# Дополнительные настройки
seed = 3407, # Для воспроизводимости
fp16 = True, # Обучение со смешанной точностью
report_to = "none", # Установите значение "wandb" для отслеживания эксперимента
)
print("Конфигурация обучения:")
print(f" Эффективный размер партии: {training_config.per_device_train_batch_size * training_config.gradient_accumulation_steps}")
print(f" Общее количество шагов обучения: {training_config.max_steps}")
print(f" Скорость обучения: {training_config.learning_rate}")Настройка тренажера
SFTTrainer (Supervised Fine-Tuning Trainer) справляется со всеми сложностями обучения:
# Инициализация трейнера
trainer = SFTTrainer(
модель = модель,
tokenizer = tokenizer,
train_dataset = dataset,
args = training_config,
)
print("✅ Trainer initialized")
# Настройте обучение только на ответах ассистентов
# Это очень важно - мы не хотим, чтобы модель обучалась на вопросах пользователя
gpt_oss_kwargs = dict(
instruction_part = "<|start|>user<|message|>",
response_part = "<|start|>assistant<|channel|>final<|message|>"
)
trainer = train_on_responses_only(
trainer,
**gpt_oss_kwargs,
)
print("✅ Настроено обучение только по ответам")Понимание настройки тренера:
- Интеграция SFTTrainer: Тренажер объединяет несколько компонентов:
- Ваша сконфигурированная модель LoRA
- Токенизатор для обработки текста
- Ваш подготовленный набор данных
- Параметры конфигурации обучения
- Обучение только по ответам: Это очень важно для моделей чатов. Используя
train_on_responses_only, мы обеспечиваем:- Модель рассчитывает потери только на ответах ассистента.
- Она не учится генерировать вопросы пользователей
- Обучение проходит более эффективно (меньше токенов для оптимизации)
- Модель сохраняет способность понимать разнообразные пользовательские данные.
- Специфические теги GPT-OSS: Части инструкции и ответа должны точно соответствовать тому, что содержат ваши отформатированные данные. Эти теги указывают тренеру, где нужно разделить то, что игнорировать (пользовательский ввод), и то, на чем тренироваться (ответ помощника).
Проверка обучающей маски
Важно убедиться, что мы обучаемся только на ответах ассистента, а не на вопросах пользователя:
# Проверьте правильность маски обучения
print("nПроверка маски обучения...")
sample = trainer.train_dataset[0]
# Декодируем метки, чтобы понять, на чем мы обучаемся.
# -100 указывает на лексемы, на которых мы не тренируемся (маска)
visible_tokens = []
for token_id, label_id in zip(sample["input_ids"], sample["labels"]):
if label_id != -100:
visible_tokens.append(token_id)
if visible_tokens:
decoded = tokenizer.decode(visible_tokens)
print(f "Обучение по: {decoded[:200]}...")
print("✅ Маска проверена - тренировка только на ответах")
else:
print("⚠️ Warning: No visible training tokens detected")О чем говорит проверка маски:
- Метка -100: В PyTorch -100 – это специальное значение, которое указывает функции потерь игнорировать эти маркеры. Так мы реализуем обучение только по реакции:
- Входные лексемы пользователя помечаются как -100 (игнорируются).
- Токены ответов помощников сохраняют свои фактические идентификаторы токенов (обучение)
- Проверка видимых токенов: Извлекая только немаскируемые лексемы, мы можем увидеть, на чем именно будет обучаться модель. Вы должны видеть только текст ответа ассистента, а не вопрос пользователя.
- Почему это важно: Без надлежащего маскирования:
- Модель может научиться генерировать вопросы пользователя вместо ответов.
- Обучение будет менее эффективным (оптимизация ненужных лексем)
- Модель может выработать нежелательное поведение, например, эхо, повторяющее ввод пользователя
- Советы по отладке: Если вы видите пользовательский ввод в декодированном тексте, проверьте:
- Строки
instruction_partиresponse_partточно совпадают. - Форматирование наборов данных включает все необходимые теги
- Токенизатор правильно применяет шаблон чата
- Строки
Начало процесса обучения
Когда все настроено, мы готовы приступить к обучению. Давайте проконтролируем использование памяти GPU и отследим прогресс обучения:
import time
import torch
# Очистите кэш GPU перед обучением
torch.cuda.empty_cache()
# Запись начального состояния GPU
start_gpu_memory = torch.cuda.max_memory_reserved() / 1024**3
start_time = time.time()
print("="*60)
print("STARTING TRAINING")
print("="*60)
print(f "Начальная память GPU зарезервирована: {start_gpu_memory:.2f} GB")
print(f "Обучение в течение {training_config.max_steps} шагов...")
print("nПрогресс обучения:")
# Начать обучение
trainer_stats = trainer.train()
# Вычислить статистику тренировки
время_обучения = time.time() - start_time
final_gpu_memory = torch.cuda.max_memory_reserved() / 1024**3
использованная_память = конечная_gpu_память - начальная_gpu_память
print("n" + "="*60)
print("ОБУЧЕНИЕ ЗАВЕРШЕНО")
print("="*60)
print(f "Затраченное время: {training_time/60:.1f} минут")
print(f "Итоговый проигрыш: {trainer_stats.metrics['train_loss']:.4f}")
print(f "Память GPU, использованная для обучения: {memory_used:.2f} GB")
print(f "Пиковая память GPU: {final_gpu_memory:.2f} GB")
print(f "Скорость обучения: {trainer_stats.metrics.get('train_steps_per_second', 0):.2f} шагов/секунду")Понимание метрик обучения:
- Управление памятью GPU:
- Очистка кэша перед обучением освобождает неиспользуемую память
- Мониторинг использования памяти помогает оптимизировать размер партии для будущих запусков.
- Разница между началом и концом показывает фактические накладные расходы на обучение
- Пиковая память показывает, насколько близки ошибки OOM.
- Индикаторы прогресса в обучении:
- Потери: должны уменьшаться со временем. Если она достигает максимума рано, возможно, скорость обучения слишком низкая.
- Шаги/секунды: помогает оценить время обучения для больших наборов данных
- Затраченное время: На графическом процессоре T4 для 60 шагов потребуется около 10-15 минут.
- За чем нужно следить во время обучения:
- Потери стабильно уменьшаются (хорошо)
- Потери скачут неравномерно (слишком высокая скорость обучения)
- Потери не меняются (слишком низкая скорость обучения или проблемы с данными)
- Ошибки памяти (уменьшите размер партии или длину последовательности)
- Ожидания производительности:
- T4 GPU: 0,5-1,0 шагов/секунду
- V100: 1,5-2,5 шага/секунду
- A100: 3-5 шагов/секунду
Обучение должно завершиться без ошибок, и вы увидите, что потери уменьшились с примерно 2-3 в начале до менее 1,0 к концу.
Тестирование отлаженной модели
Теперь наступает самое интересное – проверка того, действительно ли наша тонкая настройка сработала! Мы создадим комплексную функцию тестирования и оценим модель по различным вопросам, связанным с Python:
from transformers import TextStreamer
def test_model(prompt: str, reasoning_effort: str = "medium", max_length: int = 256):
"""
Тестируем точно настроенную модель с заданной подсказкой.
Args:
prompt: Вопрос или инструкция
reasoning_effort: "низкая", "средняя" или "высокая"
max_length: Максимальное количество генерируемых лексем
Возвращает:
Сгенерированный ответ
"""
# Создайте формат сообщения
сообщения = [
{ "роль": "system", "content": "Вы - помощник эксперта по Python."}
{ "роль": "пользователь", "содержимое": prompt}
]
# Применить шаблон чата
inputs = tokenizer.apply_chat_template(
сообщения,
add_generation_prompt = True,
return_tensors = "pt",
return_dict = True,
reasoning_effort = reasoning_effort,
).to("cuda")
# Настройка потоковой передачи данных для вывода в реальном времени
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
# Сгенерировать ответ
outputs = model.generate(
**входы,
max_new_tokens = max_length,
streamer = streamer,
температура = 0.7,
top_p = 0.9,
do_sample = True,
)
# Декодируем и возвращаем ответ
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
вернуть ответ
# Тесты по различным темам Python
test_questions = [
"Что такое генератор Python и когда его следует использовать?",
"Как прочитать CSV-файл в Python?",
"Объясните async/await в Python на простом примере",
"В чем разница между списком и кортежем в Python?",
"Как правильно обрабатывать исключения в Python?",
]
print("="*60)
print("TESTING FINE-TUNED MODEL")
print("="*60)
for i, question in enumerate(test_questions, 1):
print(f"n{'='*60}")
print(f "Вопрос {i}: {вопрос}")
print(f"{'='*60}")
print("Ответ:")
_ = test_model(question, reasoning_effort="medium")
print()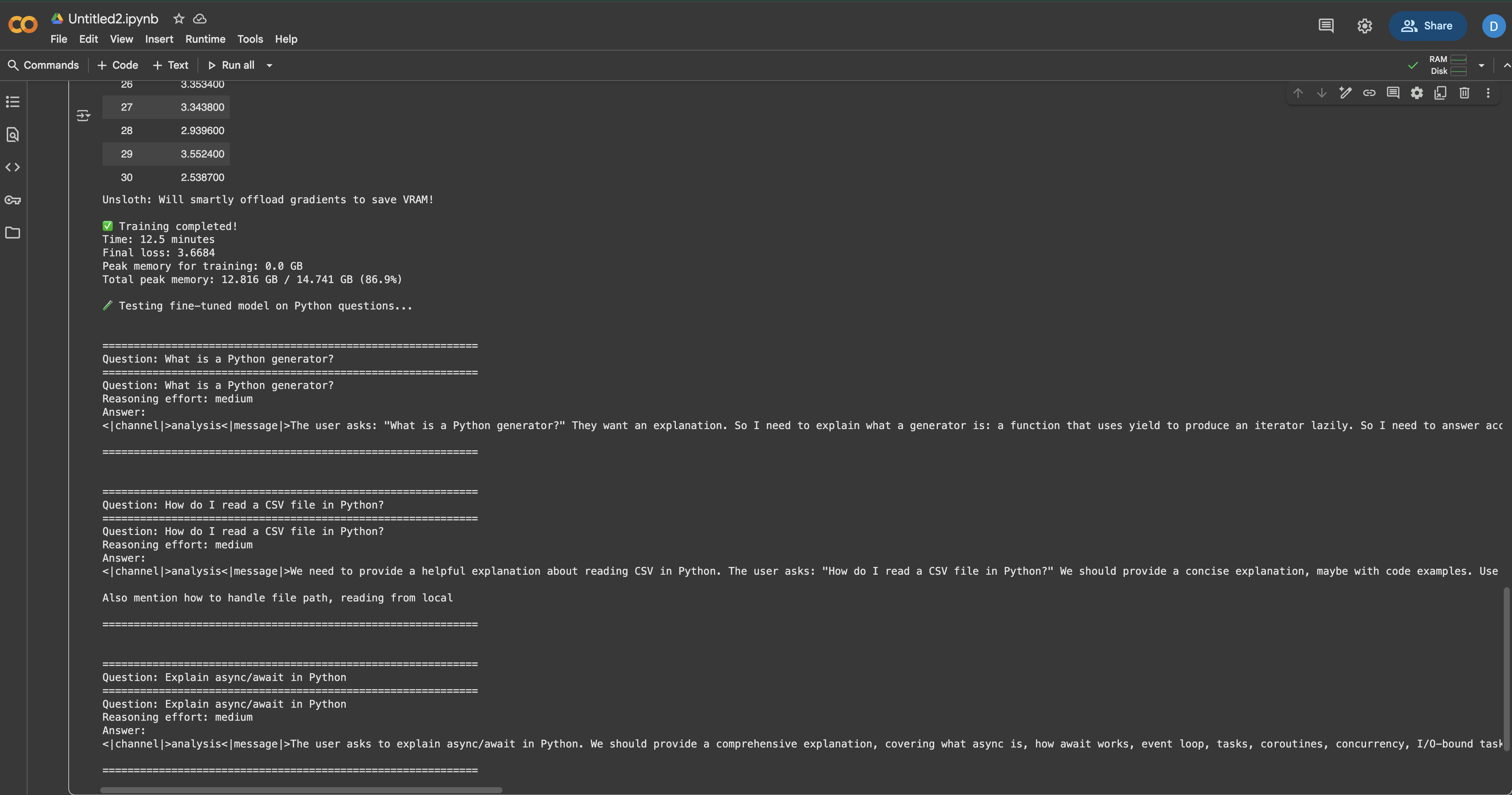
Вы должны заметить, что модель теперь предоставляет более подробные, специфичные для Python ответы, чем до тонкой настройки. Ответы должны отражать стиль документации и техническую глубину ваших обучающих данных.
Тестирование различных уровней рассуждений
Давайте также проверим, как уровень аргументации влияет на ответы:
complex_question = "Напишите функцию Python, которая находит все простые числа до n, используя сито Эратосфена".
print("="*60)
print("TESTING REASONING EFFORT LEVELS")
print("="*60)
для усилий в ["низкие", "средние", "высокие"]:
print(f"n{'='*40}")
print(f "Разумные усилия: {effort.upper()}")
print(f"{'='*40}")
_ = test_model(complex_question, reasoning_effort=effort, max_length=300)
print()Запустив код, вы увидите, что “низкий” уровень дает базовую реализацию, “средний” обеспечивает хороший баланс объяснений и кода, а “высокий” включает подробные объяснения и оптимизацию.
Сохранение и развертывание модели
После успешной доработки вы захотите сохранить модель для дальнейшего использования. У нас есть несколько вариантов в зависимости от ваших потребностей в развертывании:
Сохранение локально
импорт os
# Создаем каталог для сохранения
save_dir = "gpt-oss-python-expert"
os.makedirs(save_dir, exist_ok=True)
print("Сохранение модели локально...")
# Вариант 1: сохраняем только адаптеры LoRA (небольшой размер, ~200 МБ)
lora_save_dir = f"{save_dir}-lora"
model.save_pretrained(lora_save_dir)
tokenizer.save_pretrained(lora_save_dir)
print(f"✅ LoRA-адаптеры сохранены в {lora_save_dir}")
# Проверьте размер
lora_size = sum(
os.path.getsize(os.path.join(lora_save_dir, f))
for f in os.listdir(lora_save_dir)
) / (1024**2)
print(f" Размер: {lora_size:.1f} MB")
# Вариант 2: Сохранить объединенную модель (полный размер, ~20 ГБ)
merged_save_dir = f"{save_dir}-merged"
model.save_pretrained_merged(
merged_save_dir,
токенизатор,
save_method = "merged_16bit" # Опции: "merged_16bit", "mxfp4"
)
print(f"✅ Объединенная модель сохранена в {merged_save_dir}")Передача в Hugging Face Hub
Для удобства обмена и развертывания разместите свою модель на Hugging Face:
from huggingface_hub import login
# Войдите в Hugging Face (вам понадобится ваш токен)
# Получите токен из: https://huggingface.co/settings/tokens
login(token="hf_...") # Замените на свой токен
# Подключаем адаптеры LoRA (рекомендуется для совместного использования)
model_name = "your-username/gpt-oss-python-expert-lora"
print(f "Pushing LoRA adapters to {model_name}...")
model.push_to_hub(
имя_модели,
use_auth_token=True,
commit_message="Уточненная настройка GPT-OSS в документации Python"
)
tokenizer.push_to_hub(
имя_модели,
use_auth_token=True
)
print(f"✅ Модель доступна по адресу: https://huggingface.co/{имя_модели}")
# По желанию вытолкните объединенную модель (это займет больше времени)
if False: # Установите значение True, если хотите выложить полную модель
merged_model_name = "your-username/gpt-oss-python-expert"
model.push_to_hub_merged(
merged_model_name,
токенизатор,
save_method = "mxfp4", # 4 бита для меньшего размера
use_auth_token=True
)Загрузка уточненной модели
Вот как загрузить вашу модель для последующего вывода:
from unsloth import FastLanguageModel
# Загрузка из локального каталога
model, tokenizer = FastLanguageModel.from_pretrained(
имя_модели = "gpt-oss-python-expert-lora",
max_seq_length = 1024,
dtype = None,
load_in_4bit = True,
)
# Или загрузите из Hugging Face Hub
модель, токенизатор = FastLanguageModel.from_pretrained(
model_name = "your-username/gpt-oss-python-expert-lora",
max_seq_length = 1024,
dtype = None,
load_in_4bit = True,
)
print("✅ Модель загружена и готова к выводу!")Стратегии оптимизации для получения лучших результатов
Вот некоторые из стратегий, которые я нашел полезными для оптимизации тонкой настройки модели:
Методы оптимизации памяти
При работе с ограниченным объемом памяти GPU эти техники могут сделать разницу между успехом и ошибками OOM:
# 1. Градиентная контрольная точка - обмен вычислений на память
model.gradient_checkpointing_enable()
# 2. Уменьшите длину последовательности, если ваши данные позволяют
max_seq_length = 512 # Вместо 1024
# 3. Используйте меньшие размеры партий с большим количеством накоплений
per_device_train_batch_size = 1
gradient_accumulation_steps = 16 # По-прежнему эффективный размер партии 16
# 4. Включите эффективное для памяти внимание (если поддерживается)
model.config.use_flash_attention_2 = True
# 5. Регулярно очищайте кэш во время обучения
импортировать gc
gc.collect()
torch.cuda.empty_cache()Лучшие практики обучения
По опыту, эти практики приводят к лучшим результатам тонкой настройки:
- Начните с малого: сначала протестируйте 100 примеров. Если это сработает, постепенно увеличивайте масштаб.
- Следите за метриками: Если потери при обучении снижаются, а потери при проверке растут, остановитесь раньше.
- Смешивайте данные: Комбинируйте данные, специфичные для конкретной области, с общими данными об инструкциях, чтобы предотвратить катастрофическое забывание.
- График скорости обучения: Начните со стандартного значения 2e-4, но не бойтесь экспериментировать. Я видел хорошие результаты с 5e-5 для небольших наборов данных.
- Стратегия создания контрольных точек: Сохраняйте каждые N шагов, чтобы можно было восстановиться с лучшей контрольной точки:
training_config = SFTConfig(
save_steps = 50,
save_total_limit = 3, # Сохранять только 3 лучшие контрольные точки
load_best_model_at_end = True,
metric_for_best_model = "loss",
)Оптимизация скорости
Чтобы максимизировать скорость обучения:
# Используйте компиляцию PyTorch 2.0 для ускорения обучения
if hasattr(torch, 'compile'):
model = torch.compile(model)
print("✅ Модель скомпилирована для ускорения обучения")
# Включите TF32 на графических процессорах Ampere (A100, RTX 30xx)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
# Используйте большие размеры партий, если позволяет память
# Большие партии обычно быстрее обучаются
optimal_batch_size = find_optimal_batch_size(model, max_memory=0.9)Варианты развертывания для производства
После того, как модель отлажена, у вас есть несколько вариантов развертывания:
Быстрый локальный API с FastAPI
Для быстрого создания прототипов создайте простой API:
# сохранить как: api.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
from unsloth import FastLanguageModel
app = FastAPI()
# Загружаем модель один раз при запуске
модель, токенизатор = Нет, Нет
@app.on_event("startup")
async def load_model():
global model, tokenizer
model, tokenizer = FastLanguageModel.from_pretrained(
"gpt-oss-python-expert-lora",
max_seq_length = 1024,
load_in_4bit = True,
)
class GenerateRequest(BaseModel):
prompt: str
reasoning_effort: str = "medium"
max_tokens: int = 256
@app.post("/generate")
async def generate(request: GenerateRequest):
if not model:
raise HTTPException(status_code=503, detail="Модель не загружена")
messages = [{"role": "user", "content": request.prompt}]
inputs = tokenizer.apply_chat_template(
сообщения,
add_generation_prompt = True,
return_tensors = "pt",
reasoning_effort = request.reasoning_effort,
).to("cuda")
outputs = model.generate(
**входы,
max_new_tokens = request.max_tokens,
температура = 0.7,
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return { "response": response}
# Запуск с помощью: uvicorn api:app --host 0.0.0.0 --port 8000Развертывание на производстве с помощью vLLM
Для высокопроизводительной работы vLLM обеспечивает отличную производительность:
# Установите vLLM
pip install vllm
# Подача вашей модели
python -m vllm.entrypoints.openai.api_server
-модель gpt-oss-python-expert-merged
--tensor-parallel-size 1
--max-model-len 1024
--dtype float16Варианты развертывания облака
Каждая облачная платформа имеет свои преимущества:
Конечные точки вывода обнимающихся лиц
- Самая простая настройка – просто нажать и развернуть
- Отлично подходит для тестирования и мелкосерийного производства
- Доступно автоматическое масштабирование
- Идеально подходит для бессерверного развертывания
- Платите только за фактическое использование
- Отличный вариант для быстро меняющихся рабочих нагрузок
- Наиболее экономичный вариант для круглосуточного обслуживания
- Полный контроль над средой
- Хорошо подходит для приложений с высокой пропускной способностью
- Корпоративный уровень с полной интеграцией с AWS
- Расширенный мониторинг и ведение журналов
- Лучше всего подходит для крупномасштабных производственных развертываний
Устранение общих проблем
Даже благодаря оптимизации Unsloth вы можете столкнуться с некоторыми проблемами. Вот как решить наиболее распространенные из них:
Ошибки CUDA Out of Memory Errors
Это наиболее распространенная проблема при тонкой настройке больших моделей:
# Решение 1: Уменьшить размер партии
training_config = SFTConfig(
per_device_train_batch_size = 1, # Минимальный размер партии
gradient_accumulation_steps = 8, # Компенсация накопления
)
# Решение 2: уменьшить длину последовательности
max_seq_length = 512 # Вместо 1024
# Решение 3: Использовать более агрессивное квантование
модель = FastLanguageModel.from_pretrained(
имя_модели = "unsloth/gpt-oss-20b",
load_in_4bit = True,
use_double_quant = True, # Еще большая экономия памяти
)
# Решение 4: Включить все оптимизации памяти
use_gradient_checkpointing = "unsloth"
use_flash_attention = TrueЗамедление скорости обучения
Если обучение занимает слишком много времени:
# Используйте полный набор оптимизаций Unsloth
модель = FastLanguageModel.get_peft_model(
model,
use_gradient_checkpointing = "unsloth", # Критично
lora_dropout = 0, # 0 быстрее, чем отсев
bias = "none", # "none" быстрее, чем тренировочные biases
use_rslora = False, # Стандартный LoRA работает быстрее
)
# Проверьте, что вы используете правильный dtype
torch.set_float32_matmul_precision('medium') # Или 'high'Модель не обучается
Если потери не уменьшаются:
- Проверьте формат данных: Убедитесь, что ваши данные точно соответствуют формату GPT-OSS.
- Проверьте маскировку ответов: Убедитесь, что вы обучаетесь только на ответах
- Отрегулируйте скорость обучения: Попробуйте 5e-4 или 1e-4 вместо 2e-4.
- Повысьте качество данных: Удалите некачественные примеры
- Добавьте больше данных: 500+ примеров обычно работают лучше, чем 100
Непоследовательные результаты
Если модель генерирует противоречивые или некачественные результаты:
# Используйте более низкую температуру для получения более согласованных результатов
outputs = model.generate(
temperature = 0.3, # Ниже = более согласованные результаты
top_p = 0.9,
repetition_penalty = 1.1, # Уменьшить количество повторений
)
# Тонкая настройка для большего количества шагов
max_steps = 200 # Вместо 60
# Используйте более качественную фильтрацию данных
min_response_length = 50 # Вместо 30Заключение
Заключение
Тонкая настройка GPT-OSS становится быстрее и проще, если объединить скорость Unsloth с высококачественными структурированными данными для обучения, предоставляемыми одной из ведущих компаний, специализирующихся на данных для обучения ИИ. Использование решений Bright Data для ИИ обеспечивает доступ к надежным данным, необходимым для эффективной тонкой настройки, что позволяет создавать специализированные модели ИИ для любых задач.
Для дальнейшего изучения стратегий извлечения данных с помощью ИИ ознакомьтесь с этими дополнительными ресурсами:





