

Ручное изучение контента по десяткам результатов поиска Google занимает слишком много времени и часто упускает ключевые моменты, разбросанные по нескольким источникам. Традиционный веб-скраппинг предоставляет исходный HTML, но не обладает достаточным интеллектом для синтеза информации в связное повествование. В этом руководстве вы узнаете, как создать систему на базе искусственного интеллекта, которая будет автоматически просматривать результаты поисковой выдачи Google, анализировать контент с помощью вкраплений и генерировать исчерпывающие статьи или конспекты.
Вы узнаете:
- Как построить автоматизированный конвейер для преобразования исследований в статьи с помощью Bright Data и векторных вкраплений
- Как семантически анализировать отсканированный контент и выявлять повторяющиеся темы
- Как генерировать структурированные конспекты и полные статьи с помощью LLM
- Как создать интерактивный интерфейс Streamlit для генерации контента
Давайте начнем!
Трудности исследования для создания контента
Создатели контента сталкиваются с серьезными препятствиями при поиске тем для статей, постов в блогах или маркетинговых материалов. Ручное исследование предполагает открытие десятков вкладок браузера, чтение объемных статей и попытку синтезировать информацию из разрозненных источников. Этот процесс чреват человеческими ошибками, требует много времени и трудно масштабируется.
Традиционные подходы к веб-скреппингу с использованием BeautifulSoup или Scrapy предоставляют необработанный HTML-текст, но не обладают достаточным интеллектом для понимания контекста контента, выявления ключевых тем или синтеза информации из нескольких источников. В результате получается коллекция неструктурированного текста, который по-прежнему требует значительной ручной обработки.
Сочетание надежных возможностей скраппинга Bright Data с современными методами искусственного интеллекта, такими как векторные вкрапления и большие языковые модели, позволяет автоматизировать весь процесс перехода от исследования к статье. Таким образом, часы ручной работы превращаются в минуты автоматизированного анализа.
Что мы создаем: Система исследования контента на основе искусственного интеллекта
Вы создадите интеллектуальную систему генерации контента, которая будет автоматически искать результаты поиска Google по любому заданному ключевому слову. Система извлекает полный контент из целевых веб-страниц, анализирует информацию с помощью векторных вкраплений для выявления тем и идей и генерирует структурированные наброски статей или готовые проекты статей с помощью интуитивно понятного интерфейса Streamlit.
Необходимые условия
Настройте среду разработки в соответствии с этими требованиями:
- Python 3.9 или выше
- Аккаунт Bright Data: Зарегистрируйтесь и создайте API-токен (доступны бесплатные пробные кредиты).
- API-ключ OpenAI: Создайте ключ в вашей панели OpenAI для встраивания и доступа к LLM.
- Виртуальная среда Python: Обеспечивает изоляцию зависимостей
- LangChain + Vector Embeddings (FAISS): Занимается анализом и хранением контента.
- Streamlit: Обеспечивает интерактивный пользовательский интерфейс, позволяющий пользователям использовать инструмент.
Настройка среды
Создайте каталог проекта и установите зависимости. Начните с создания чистого виртуального окружения, чтобы избежать конфликтов с другими проектами Python.
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install langchain langchain-community langchain-openai streamlit "crewai-tools[mcp]" crewai mcp python-dotenvСоздайте новый файл article_generator.py и добавьте в него следующие импорты. Эти библиотеки занимаются веб-скреппингом, обработкой текста, вставками и пользовательским интерфейсом.
import streamlit as st
import os
import json
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from mcp import StdioServerParameters
from crewai_tools import MCPServerAdapter
load_dotenv()Конфигурация ярких данных
Безопасное хранение учетных данных API с помощью переменных окружения. Создайте файл .env для хранения ваших учетных данных, чтобы сохранить конфиденциальную информацию отдельно от вашего кода.
BRIGHT_DATA_API_TOKEN="ваш_bright_data_api_token_здесь"
BRIGHT_DATA_ZONE="название_вашей_серп_зоны"
OPENAI_API_KEY="ваш_openai_api_ключ_здесь"Вам потребуется:
- API-токен Bright Data: Генерируется на панели инструментов Bright Data
- Зона скрапинга SERP: Создайте новую зону Web Scraper, настроенную на Google SERP
- API-ключ OpenAI: Для генерации вкраплений и LLM-текста
Настройте API-соединения в article_generator.py. Этот класс управляет всеми коммуникациями с инфраструктурой скрапинга Bright Data.
class BrightDataScraper:
def __init__(self):
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def scrape_serp(self, keyword, num_results=10):
with MCPServerAdapter(self.server_params) as mcp_tools:
try:
if not mcp_tools:
st.warning("Нет доступных инструментов MCP")
return {'results': []}
for tool in mcp_tools:
try:
имя_инструмента = getattr(tool, 'name', str(tool))
если 'search_engine' в имени_инструмента и 'batch' не в имени_инструмента:
try:
if hasattr(tool, '_run'):
result = tool._run(query=keyword)
elif hasattr(tool, 'run'):
result = tool.run(query=keyword)
elif hasattr(tool, '__call__'):
result = tool(query=keyword)
else:
result = tool.search_engine(query=keyword)
if result:
return self._parse_serp_results(result)
except Exception as method_error:
st.warning(f "Method failed for {tool_name}: {str(method_error)}")
продолжить
except Exception as tool_error:
st.warning(f "Инструмент {имя_инструмента} не сработал: {str(tool_error)}")
продолжить
st.warning(f "Ни один инструмент поисковой_системы не смог обработать: {ключевое слово}")
return {'results': []}
except Exception as e:
st.error(f "MCP scraping failed: {str(e)}")
return {'results': []}
def _parse_serp_results(self, mcp_result):
"""Разбираем результаты работы инструмента MCP в ожидаемый формат."""
if isinstance(mcp_result, dict) and 'results' in mcp_result:
return mcp_result
elif isinstance(mcp_result, list):
return {'results': mcp_result}
elif isinstance(mcp_result, str):
return self._parse_html_search_results(mcp_result)
else:
try:
parsed = json.loads(str(mcp_result))
return parsed if isinstance(parsed, dict) else {'results': parsed}
except:
return {'results': []}
def _parse_html_search_results(self, html_content):
"""Разбор HTML-страницы результатов поиска для извлечения результатов поиска."""
import re
результаты = []
link_pattern = r'<a[^>]*href="([^"]*)"[^>]*>(.*?)</a>'
title_pattern = r'<h3[^>]*>(.*?)</h3>'
ссылки = re.findall(link_pattern, html_content, re.DOTALL)
для link_url, link_text в links:
if (link_url.startswith('http') and
not any(skip in link_url for skip in [
'google.com', 'accounts.google', 'support.google',
'/search?', 'javascript:', '#', 'mailto:'
])):
cleanan_title = re.sub(r'<[^>]+>', '', link_text).strip()
if clean_title and len(clean_title) > 10:
results.append({
'url': link_url,
'title': clean_title[:200],
'snippet': '',
'position': len(results) + 1
})
if len(results) >= 10:
break
if not results:
specific_pattern = r'[(.*?)]((https?://[^)]+))'
matches = re.findall(specific_pattern, html_content)
для title, url в matches:
if not any(skip in url for skip in ['google.com', '/search?']]):
results.append({
'url': url,
'title': title.strip(),
'snippet': '',
'position': len(results) + 1
})
if len(results) >= 10:
break
return {'results': results}Создание генератора статей
Шаг 1: Соскоб SERP и целевых страниц
Основой нашей системы является всесторонний сбор данных. Вам нужно создать скрепер, который сначала извлекает результаты SERP Google, а затем переходит по ссылкам, чтобы собрать полный контент страницы из наиболее релевантных источников.
class ContentScraper:
def __init__(self):
self.bright_data = BrightDataScraper()
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def extract_serp_urls(self, keyword, max_results=10):
"""Извлечение URL-адресов из результатов SERP Google."""
serp_data = self.bright_data.scrape_serp(keyword, max_results)
urls = []
results_list = serp_data.get('results', [])
for result in results_list:
if 'url' in result and self.is_valid_url(result['url']):
urls.append({
'url': result['url'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
elif 'link' in result and self.is_valid_url(result['link']):
urls.append({
'url': result['link'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
return urls
def is_valid_url(self, url):
"""Отфильтруйте URL, не относящиеся к статьям, например, изображения, PDF или социальные сети."""
excluded_domains = ['youtube.com', 'facebook.com', 'twitter.com', 'instagram.com']
excluded_extensions = ['.pdf', '.jpg', '.png', '.gif', '.mp4']
return (not any(domain in url for domain in excluded_domains) and
not any(ext в url.lower() for ext в excluded_extensions))
def scrape_page_content(self, url, max_length=10000):
"""Извлечение чистого текстового содержимого с веб-страницы с помощью инструментов Bright Data MCP."""
try:
with MCPServerAdapter(self.server_params) as mcp_tools:
if not mcp_tools:
st.warning("Нет инструментов MCP, доступных для скраппинга контента")
return ""
for tool in mcp_tools:
try:
имя_инструмента = getattr(tool, 'name', str(tool))
if 'scrape_as_markdown' in tool_name:
try:
if hasattr(tool, '_run'):
result = tool._run(url=url)
elif hasattr(tool, 'run'):
result = tool.run(url=url)
elif hasattr(tool, '__call__'):
result = tool(url=url)
else:
result = tool.scrape_as_markdown(url=url)
if result:
content = self._extract_content_from_result(result)
if content:
return self._clean_content(content, max_length)
except Exception as method_error:
st.warning(f "Method failed for {tool_name}: {str(method_error)}")
продолжить
except Exception as tool_error:
st.warning(f "Инструмент {имя_инструмента} не сработал для {url}: {str(tool_error)}")
продолжить
st.warning(f "Ни один инструмент scrape_as_markdown не смог скрапировать: {url}")
return ""
except Exception as e:
st.warning(f "Failed to scrape {url}: {str(e)}")
return ""
def _extract_content_from_result(self, result):
"""Извлечение содержимого из результата работы инструмента MCP."""
if isinstance(result, str):
return result
elif isinstance(result, dict):
for key in ['content', 'text', 'body', 'html']:
if key in result and result[key]:
return result[key].
elif isinstance(result, list) and len(result) > 0:
return str(result[0])
return str(result) if result else ""
def _clean_content(self, content, max_length):
"""Очищаем и форматируем вырезанный контент."""
if isinstance(content, dict):
content = content.get('text', content.get('content', str(content)))
если '<' в содержимом и '>' в содержимом:
import re
content = re.sub(r'<script[^>]*>.*?</script>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<style[^>]*>.*?</style>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<[^>]+>', '', content)
строки = (line.strip() for line in content.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = ' '.join(chunk for chunk in chunks if chunk)
return text[:max_length]Этот скрепер интеллектуально фильтрует URL-адреса, чтобы сосредоточиться на содержании статей, избегая мультимедийных файлов и ссылок на социальные сети, которые не предоставят ценный текстовый контент для анализа.
Шаг 2: Векторные вкрапления и анализ контента
Преобразуйте отсканированный контент в векторные вкрапления, которые передают семантический смысл и позволяют проводить интеллектуальный анализ контента. Процесс встраивания преобразует текст в числовые представления, которые машины понимают и сравнивают.
class ContentAnalyzer:
def __init__(self):
self.embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["nn", "n", ".", "!", "?", ",", " ", ""]
)
def process_content(self, scraped_data):
"""Преобразуем соскобленный контент во вкрапления и анализируем темы."""
all_texts = []
метаданные = []
for item in scraped_data:
if item['content']:
chunks = self.text_splitter.split_text(item['content'])
for chunk in chunks:
all_texts.append(chunk)
metadata.append({
'url': item['url'],
'title': item['title'],
'position': item['position']
})
if not all_texts:
raise ValueError("Нет содержимого, доступного для анализа")
vectorstore = FAISS.from_texts(all_texts, self.embeddings, metadatas=metadata)
return vectorstore, all_texts, metadata
def identify_themes(self, vectorstore, query_terms, k=5):
"""Используйте семантический поиск для выявления ключевых тем и сюжетов."""
theme_analysis = {}
для term в query_terms:
similar_docs = vectorstore.similarity_search(term, k=k)
theme_analysis[term] = {
'relevant_chunks': len(similar_docs),
'key_passages': [doc.page_content[:200] + "..." for doc in similar_docs[:3]],
'sources': list(set([doc.metadata['url'] for doc in similar_docs]))
}
return theme_analysis
def generate_content_summary(self, all_texts, metadata):
"""Генерируем статистическую сводку по отсканированному контенту."""
total_words = sum(len(text.split()) for text in all_texts)
total_chunks = len(all_texts)
avg_chunk_length = total_words / total_chunks if total_chunks > 0 else 0
return {
'total_sources': len(set(meta['url'] for meta in metadata)),
'total_chunks': total_chunks,
'total_words': total_words,
'avg_chunk_length': round(avg_chunk_length, 1)
}Анализатор разбивает контент на семантические блоки и создает векторную базу данных с возможностью поиска, которая позволяет интеллектуально определять темы и синтезировать контент.
Шаг 3: Создание статьи или конспекта с помощью LLM
Преобразуйте проанализированный контент в структурированные результаты с помощью тщательно продуманных подсказок, которые используют семантические знания, полученные в результате анализа вкраплений. LLM берет данные вашего исследования и создает связный, хорошо структурированный контент.
class ArticleGenerator:
def __init__(self):
self.llm = OpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY"),
температура=0.7,
max_tokens=2000
)
def generate_outline(self, keyword, theme_analysis, content_summary):
"""Генерируем структурированный конспект статьи на основе данных исследования."""
themes_text = self._format_themes_for_prompt(theme_analysis)
outline_prompt = f"""
На основе всестороннего исследования темы "{ключевое слово}" создайте подробный конспект статьи.
Резюме исследования:
- Проанализировано {content_summary['total_sources']} источников
- Обработано {content_summary['total_words']} слов контента
- Определите ключевые темы и идеи
Найдены ключевые темы:
{themes_text}
Создайте структурированный конспект, включающий:
1. Привлекательный заголовок
2. Вводный крючок и обзор
3. 4-6 основных разделов с подразделами
4. Заключение с основными выводами
5. Предлагаемый призыв к действию
Оформите в формате markdown с четкой иерархией.
"""
return self.llm(outline_prompt)
def generate_full_article(self, keyword, theme_analysis, content_summary, target_length=1500):
"""Генерируем полный черновик статьи."""
themes_text = self._format_themes_for_prompt(theme_analysis)
article_prompt = f"""
Напишите исчерпывающую статью объемом {целевая_длина} слов о "{ключевом слове}", основываясь на обширном исследовании.
Фонд исследований:
{themes_text}
Требования к содержанию:
- Увлекательное вступление, которое зацепит читателя
- Хорошо структурированная часть с четкими разделами
- Включение конкретных выводов и данных, полученных в результате исследований
- Профессиональный, информативный тон
- Сильное заключение с полезными выводами
- SEO-дружественная структура с подзаголовками
Напишите полную статью в формате markdown.
"""
return self.llm(article_prompt)
def _format_themes_for_prompt(self, theme_analysis):
"""Форматируем анализ тем для потребления LLM."""
formatted_themes = []
for theme, data in theme_analysis.items():
theme_info = f "**{тема}**: Найдено в {data['relevant_chunks']} секциях содержимогоn"
theme_info += f "Ключевые сведения: {data['key_passages'][0][:150]}...n"
theme_info += f "Источники: {len(data['sources'])} уникальные ссылкиn"
formatted_themes.append(theme_info)
return "n".join(formatted_themes)Генератор создает два различных выходных формата: структурированные наброски для планирования содержания и полные статьи для немедленной публикации. Оба результата основаны на семантическом анализе отсканированного контента.

Шаг 4: Создание пользовательского интерфейса Streamlit
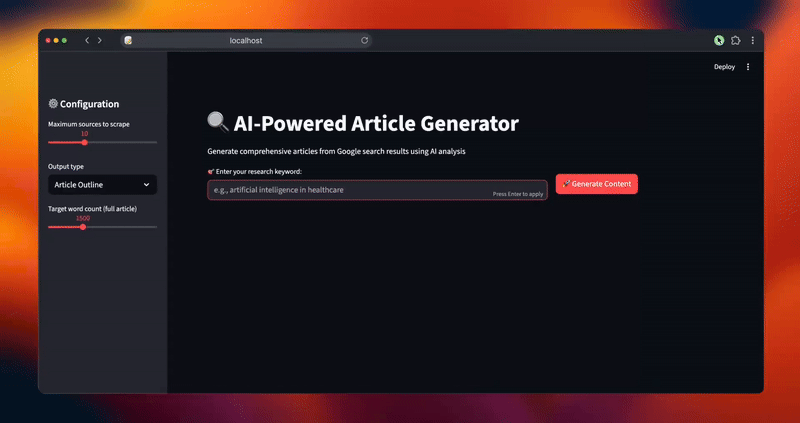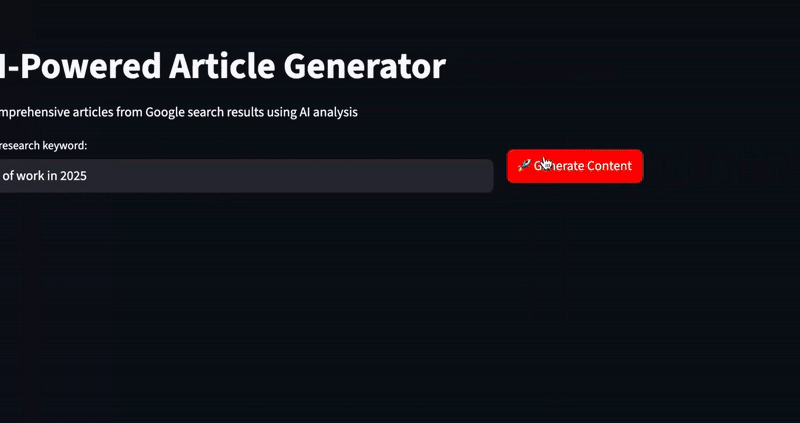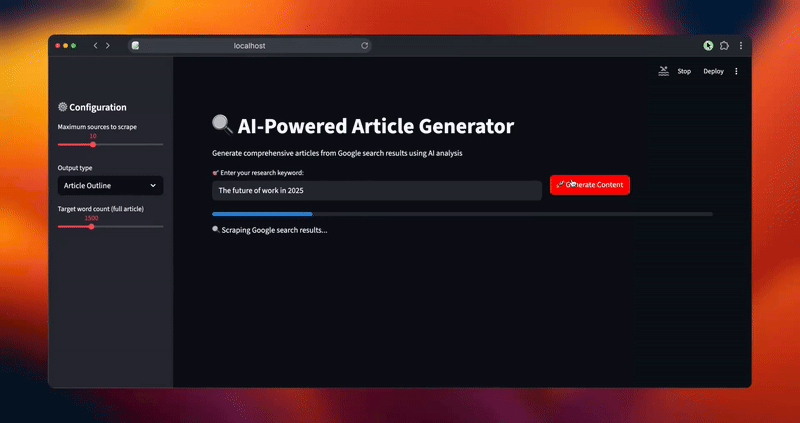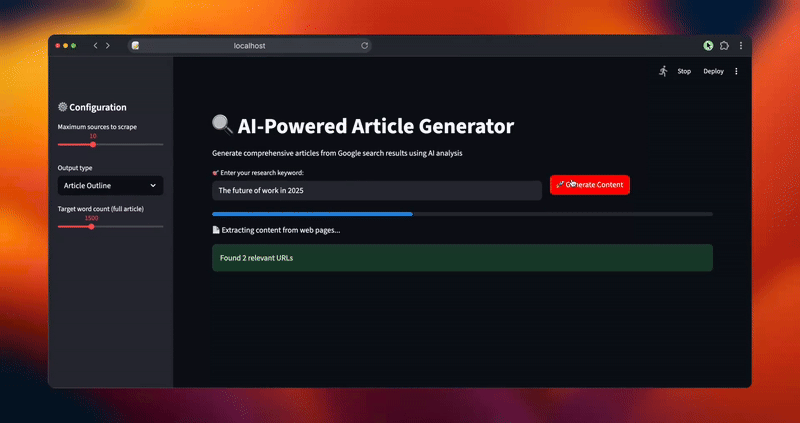
Создайте интуитивно понятный интерфейс, который проведет пользователей через весь рабочий процесс создания контента с обратной связью в режиме реального времени и возможностями настройки. Интерфейс делает сложные операции искусственного интеллекта доступными для нетехнических пользователей.
def main():
st.set_page_config(page_title="AI Article Generator", page_icon="📝", layout="wide")
st.title("🔍 AI-Powered Article Generator")
st.markdown("Генерируйте исчерпывающие статьи из результатов поиска Google, используя анализ искусственного интеллекта")
scraper = ContentScraper()
analyzer = ContentAnalyzer()
генератор = ArticleGenerator()
st.sidebar.header("⚙️ Configuration")
max_sources = st.sidebar.slider("Максимальное количество источников для скраппинга", 5, 20, 10)
output_type = st.sidebar.selectbox("Тип вывода", ["Конспект статьи", "Полная статья"])
target_length = st.sidebar.slider("Целевое количество слов (полная статья)", 800, 3000, 1500)
col1, col2 = st.columns([2, 1])
с col1:
keyword = st.text_input("🎯 Введите ключевое слово вашего исследования:", placeholder="например, искусственный интеллект в здравоохранении")
с col2:
st.write("")
generate_button = st.button("🚀 Generate Content", type="primary")
if generate_button и ключевое слово:
try:
progress_bar = st.progress(0)
status_text = st.empty()
status_text.text("🔍 Скрапирование результатов поиска Google...")
progress_bar.progress(0.2)
urls = scraper.extract_serp_urls(keyword, max_sources)
st.success(f "Найдено {len(urls)} релевантных URL")
status_text.text("📄 Извлечение контента из веб-страниц...")
progress_bar.progress(0.4)
scraped_data = []
for i, url_data in enumerate(urls):
content = scraper.scrape_page_content(url_data['url'])
scraped_data.append({
'url': url_data['url'],
'title': url_data['title'],
'content': content,
'position': url_data['position']
})
progress_bar.progress(0.4 + (0.3 * (i + 1) / len(urls)))
status_text.text("🧠 Анализ контента с помощью AI-встроек...")
progress_bar.progress(0.75)
vectorstore, all_texts, metadata = analyzer.process_content(scraped_data)
query_terms = [keyword] + keyword.split()[:3]
theme_analysis = analyzer.identify_themes(vectorstore, query_terms)
content_summary = analyzer.generate_content_summary(all_texts, metadata)
status_text.text("✍️ Генерирование контента на основе искусственного интеллекта...")
progress_bar.progress(0.9)
if output_type == "Article Outline":
result = generator.generate_outline(keyword, theme_analysis, content_summary)
else:
result = generator.generate_full_article(keyword, theme_analysis, content_summary, target_length)
progress_bar.progress(1.0)
status_text.text("✅ Генерация контента завершена!")
st.markdown("---")
st.subheader(f"📊 Анализ исследований для '{ключевого слова}'")
col1, col2, col3, col4 = st.columns(4)
с col1:
st.metric("Проанализированные источники", content_summary['total_sources'])
с col2:
st.metric("Content Chunks", content_summary['total_chunks'])
с col3:
st.metric("Total Words", content_summary['total_words'])
с col4:
st.metric("Avg Chunk Size", f"{content_summary['avg_chunk_length']} words")
с st.expander("🎯 Выявленные ключевые темы"):
for theme, data in theme_analysis.items():
st.write(f "**{тема}**: найдены {data['relevant_chunks']} релевантные разделы")
st.write(f "Образец понимания: {data['key_passages'][0][:200]}...")
st.write(f "Источники: {len(data['sources'])} уникальные ссылки")
st.write("---")
st.markdown("---")
st.subheader(f"📝 Сгенерировано {output_type}")
st.markdown(result)
st.download_button(
label="💾 Загрузить содержимое",
data=result,
имя_файла=f"{keyword.replace(' ', '_')}_{output_type.lower().replace(' ', '_')}.md",
mime="text/markdown"
)
except Exception as e:
st.error(f"❌ Generation failed: {str(e)}")
st.write("Пожалуйста, проверьте свои учетные данные API и повторите попытку").
if __name__ == "__main__":
main()Интерфейс Streamlit обеспечивает интуитивно понятный рабочий процесс с отслеживанием прогресса в реальном времени, настраиваемыми параметрами и немедленным предварительным просмотром как анализа исследования, так и созданного контента. Пользователи загружают свои результаты в формате markdown для дальнейшего редактирования или публикации.
Запуск генератора статей
Запустите приложение, чтобы начать генерировать контент на основе веб-исследований. Откройте терминал и перейдите в каталог вашего проекта.
streamlit run article_generator.pyВы увидите, как интеллектуальный рабочий процесс системы обрабатывает ваши запросы:
- Извлекает всесторонние результаты поиска из Google SERP с фильтрацией релевантности
- Извлекает полный контент с целевых веб-страниц с защитой от ботов
- Семантическая обработка контента с использованием векторных вкраплений и идентификации тем.
- Анализирует повторяющиеся паттерны и ключевые идеи из нескольких источников
- Генерирует структурированный контент с правильной подачей и профессиональным форматированием
Заключительные мысли
Теперь у вас есть полноценная система генерации статей, которая автоматически собирает данные исследований из разных источников и преобразует их в полноценный контент. Система выполняет семантический анализ контента, выявляет повторяющиеся темы в источниках и генерирует структурированные статьи или конспекты.
Вы можете адаптировать эту систему для различных отраслей, изменяя цели поиска и критерии анализа. Модульная конструкция позволяет добавлять новые контент-платформы, модели встраивания или шаблоны генерации по мере развития ваших потребностей.
Чтобы создать более сложные рабочие процессы, изучите весь спектр решений в инфраструктуре Bright Data AI для получения, проверки и преобразования живых веб-данных.
Создайте бесплатную учетную запись Bright Data и начните экспериментировать с нашими решениями для обработки веб-данных с помощью искусственного интеллекта!





