

В этой статье вы узнаете:
- Что такое Azure ИИ Foundry и что он предлагает.
- Почему интеграция с SERP API компании Bright Data в Azure ИИ Foundry является выигрышной стратегией.
- Как построить реальный оперативный поток ИИ в Azure, подключившись к SERP API.
Давайте погрузимся!
Что такое Azure ИИ Foundry?
Azure ИИ Foundry – это унифицированная платформа, которая предоставляет набор инструментов и услуг для создания, развертывания и управления приложениями, агентами и потоками ИИ. Другими словами, она выступает в роли “фабрики ИИ”, стандартизируя процесс создания систем ИИ.
Его главная цель – помочь вам пройти путь от концепции до производства. Это достигается путем предоставления доступа к широкому спектру моделей и возможностей от таких поставщиков ИИ, как Azure OpenAI, Meta и Mistral, а также инструментов для разработки, развертывания и непрерывного мониторинга.
Зачем интегрировать SERP API от Bright Data в Azure ИИ Foundry
В Azure ИИ Foundry представлен длинный список LLM, но независимо от того, какого из них вы выберете, их знания статичны. Например, LLM не знает о сегодняшних биржевых новостях, спортивных результатах прошлой ночи и т. д. Это может привести к “несвежим” или “галлюцинированным” ответам.
Чтобы преодолеть это ограничение, можно построить систему, которая будет “заземлять” LLM данными из Интернета в режиме реального времени. Такой подход особенно распространен в рабочих процессах RAG(Retrieval-Augmented Generation), где LLM получает внешнюю информацию перед генерацией ответа, что гарантирует, что его вывод основан на текущих фактах.
ИИ Azure поставляется со встроенным инструментом обоснования, но он ограничен Bing в качестве источника данных, что не всегда идеально. Более профессиональная и гибкая альтернатива – SERP API от Bright Data!
SERP API позволяет программно выполнять поисковые запросы в поисковых системах и получать полный контент SERP, обеспечивая вас надежным источником свежих, проверяемых данных, которые можно легко интегрировать в агентов ИИ и рабочие процессы LLM. Ознакомьтесь со всеми его возможностями в официальной документации.
В Azure ИИ Foundry интеграция API сторонних разработчиков может быть реализована как в агентах, так и в потоках. Здесь мы сосредоточимся на потоках подсказок, которые особенно хорошо подходят для сценариев RAG.
Как получить контекст веб-поиска в потоке подсказок Azure ИИ с помощью SERP API
В этом руководстве вы увидите, как интегрировать SERP API от Bright Data в поток ИИ Azure в качестве части потока подсказок для анализа новостей. Этот рабочий процесс состоит из четырех основных этапов:
- Получение входных данных: Вы сообщаете рабочему процессу интересующую вас тему, чтобы получить соответствующие новости.
- Получение новостей: специализированный узел Python получает входную тему и отправляет ее в SERP API Bright Data для получения новостных статей из Google.
- Анализ новостей: LLM обрабатывает данные, полученные от SERP API, чтобы определить, какие новости стоит прочитать.
- Формирование выходных данных: Созданный отчет в формате Markdown содержит список всех новостей, извлеченных из SERP, а также краткое описание и оценку, указывающую на их пригодность для чтения.
Примечание: Это всего лишь пример, и вы можете использовать SERP API во многих других сценариях и случаях.
Следуйте приведенным ниже инструкциям, чтобы построить рабочий процесс в стиле RAG на основе свежих данных из SERP API от Bright Data в Azure ИИ Foundry!
Предварительные условия
Чтобы следовать этому разделу руководства, убедитесь, что у вас есть:
- Учетная запись Microsoft.
- Подписка на Azure (достаточно даже бесплатной пробной версии).
- Учетная запись Bright Data с активным ключом API (с правами администратора ).
Следуйте официальному руководству Bright Data для получения ключа API. Сохраните его в надежном месте, так как он вам скоро понадобится.
Шаг № 1: Создайте концентратор ИИ в Azure
Оперативные потоки ИИ доступны только в концентраторах ИИ Azure, поэтому первым шагом будет их создание.
Для этого войдите в свою учетную запись Azure и откройте службу Azure ИИ Foundry, нажав на ее значок или найдя ее в строке поиска:
Вы должны попасть на страницу управления “ИИ Foundry”:
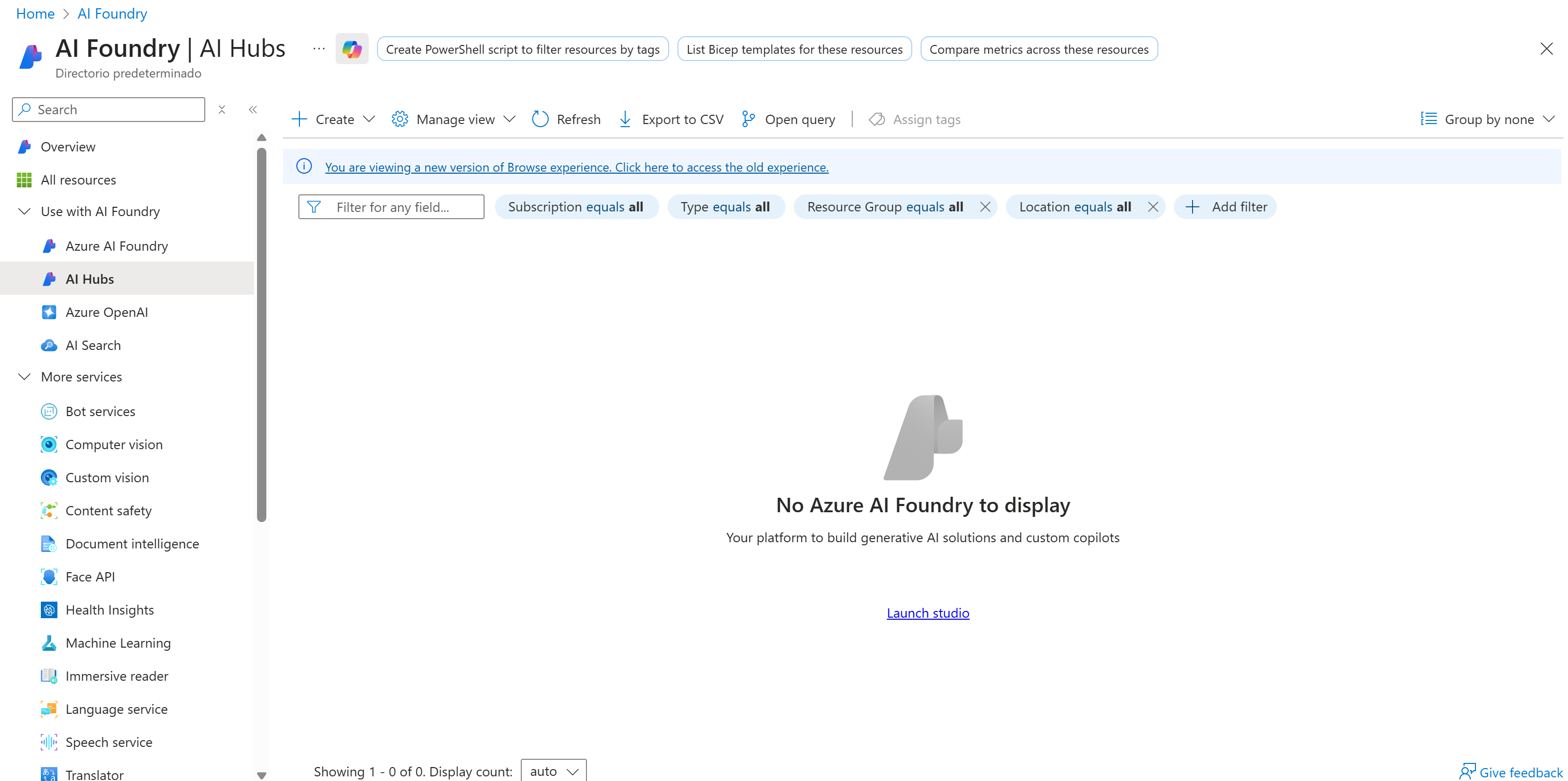
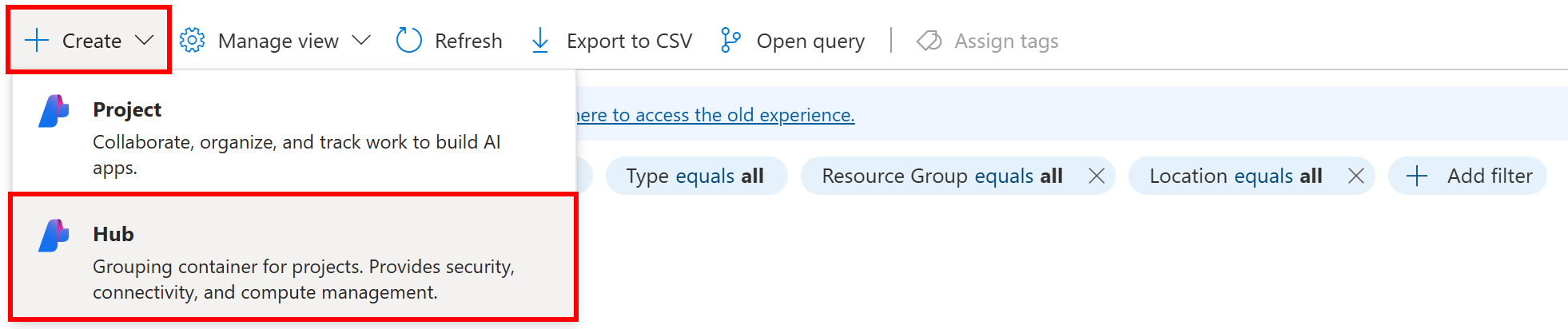
Здесь нажмите кнопку “Создать” и выберите вариант “Хаб”:
Далее заполните форму создания концентратора ИИ Azure, как показано ниже:
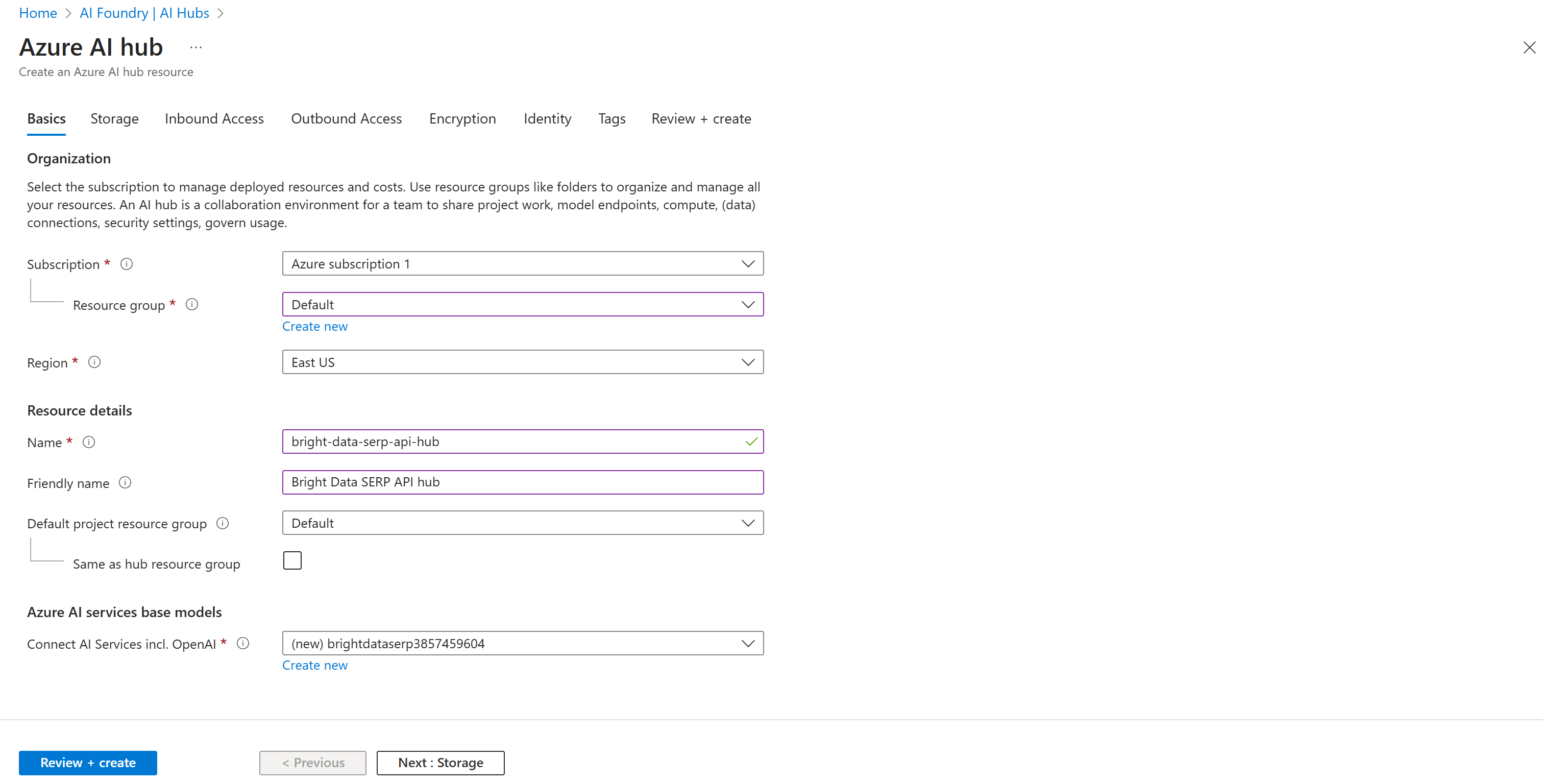
Выберите регион, выберите существующую группу ресурсов (или создайте новую, если нужно) и дайте хабу имя, например bright-data-serp-ai-hub.
Затем нажмите кнопку “Обзор + Создать”. Вам будет показана сводная информация:
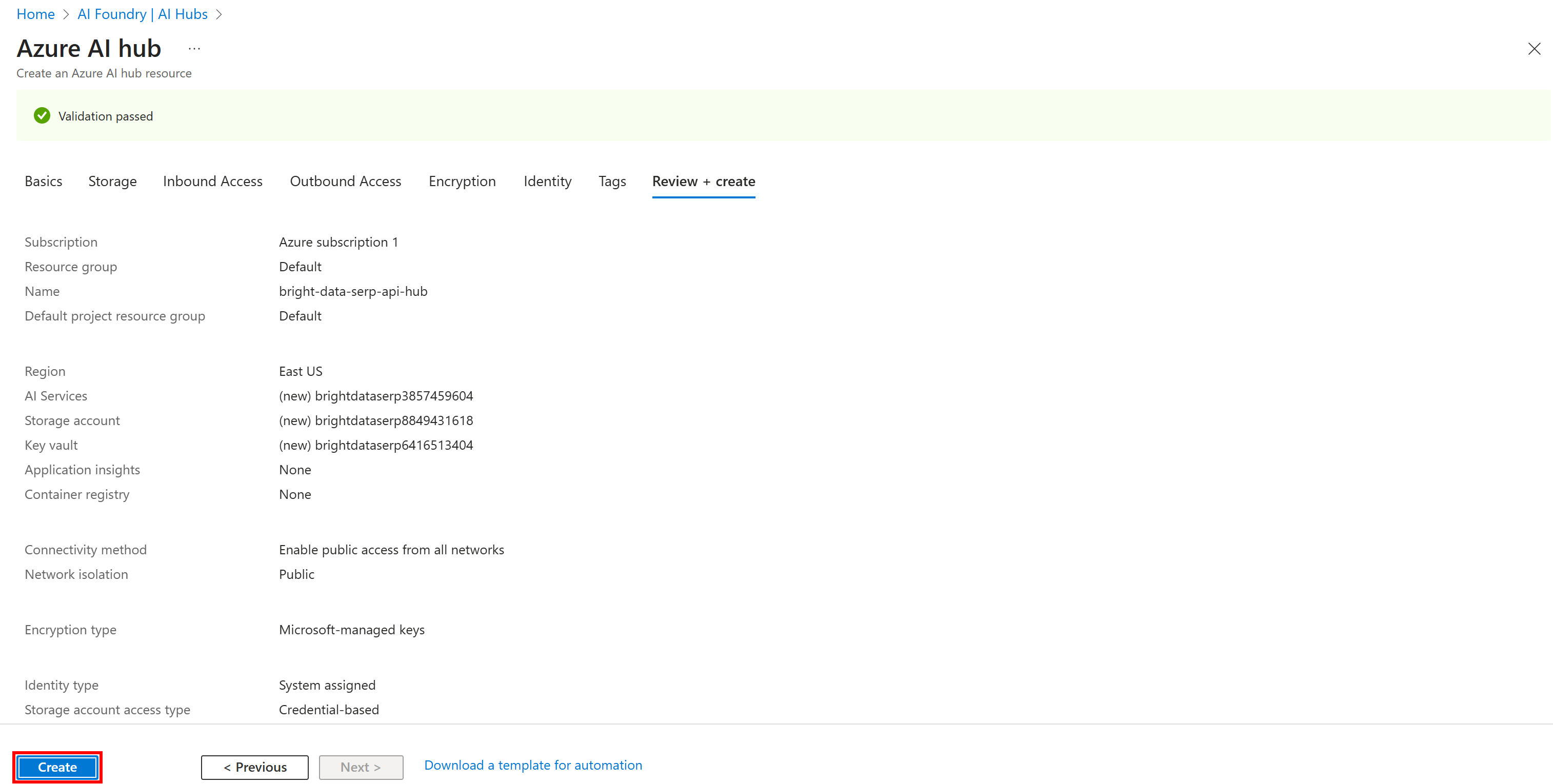
Если все выглядит хорошо, нажмите “Создать”, чтобы начать развертывание.
Процесс инициализации может занять несколько минут. По его завершении вы должны увидеть страницу подтверждения, как показано здесь:
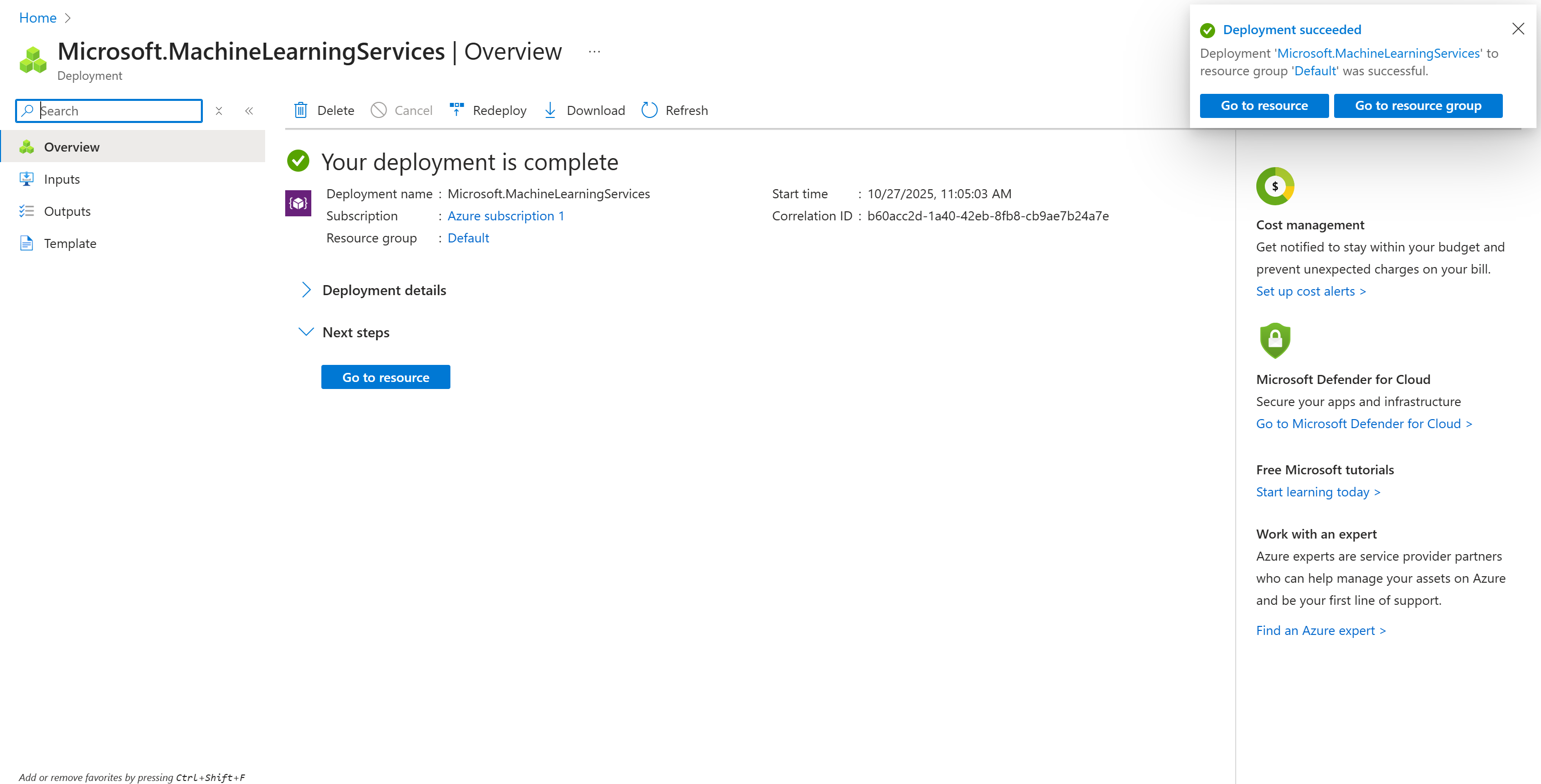
Замечательно! Теперь у вас есть Azure ИИ Hub, где вы можете создать проект и инициализировать поток подсказок.
Шаг № 2: Создание проекта в концентраторе ИИ
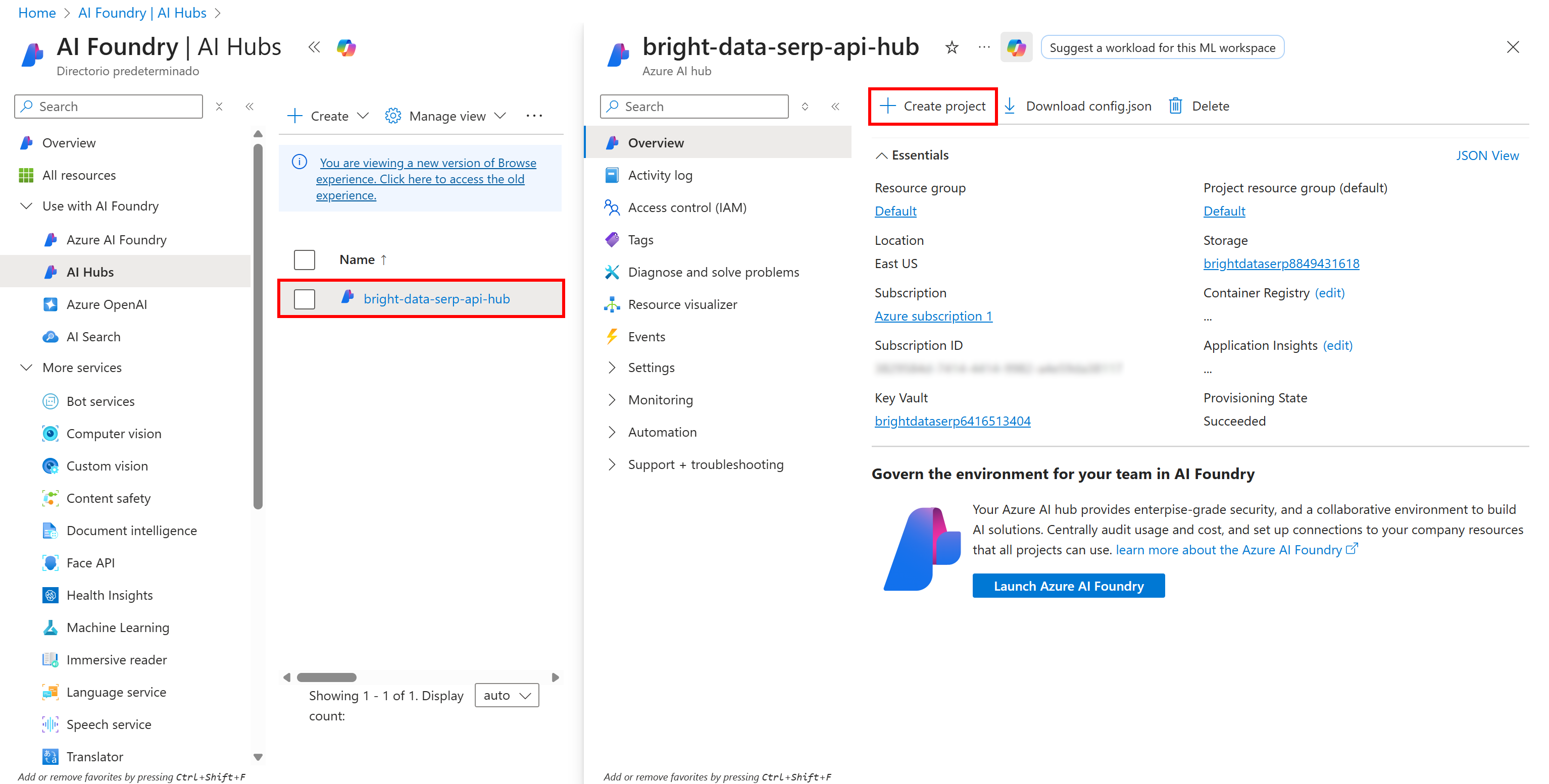
Чтобы управлять потоком подсказок, сначала нужно создать проект в ИИ-концентраторе. Начните с нажатия на опцию “Хабы ИИ” в левом меню:

Щелкните по названию вашего хаба и в появившемся разделе справа выберите “Создать проект”:
Заполните форму создания проекта. На этот раз назовите свой проект как-нибудь вроде serp-api-flow:
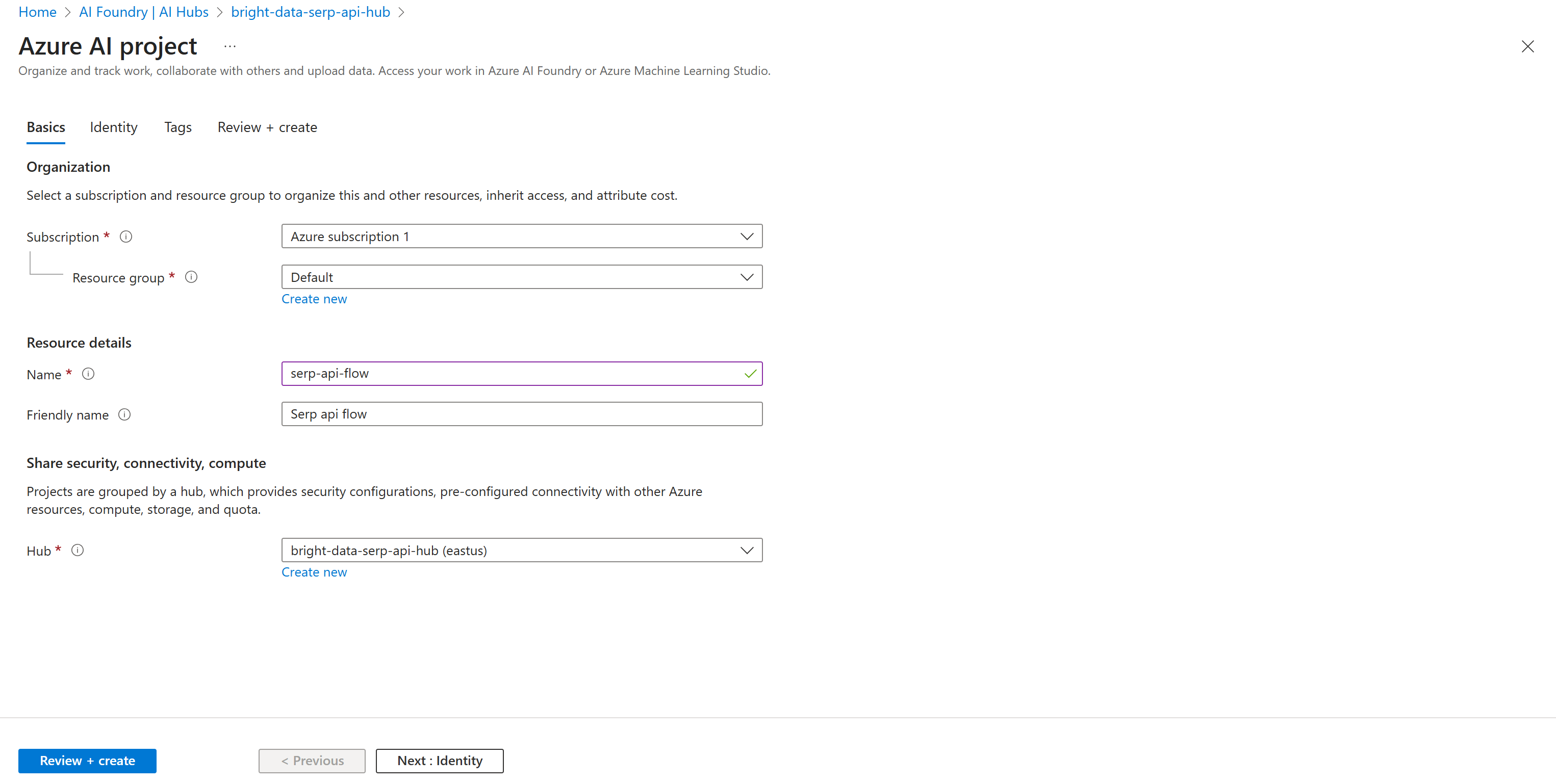
Нажмите кнопку “Review + create”, затем проверьте, все ли правильно в разделе “Summary”. Наконец, нажмите “Создать”, чтобы развернуть проект.
Подождите несколько минут, пока проект инициализируется. Когда он будет готов, вы увидите его в списке на странице “ИИ-концентраторы”. Щелкните по нему:
Нажмите кнопку “Запустить студию”, чтобы открыть его в студии Azure ИИ Foundry:
Отметьте вверху, что вы работаете в проекте “Serp api flow”. Если это не так (например, у вас несколько проектов), убедитесь, что выбрали правильный проект.
Отлично! Приготовьтесь к определению потока подсказок ИИ в Azure.
Шаг № 3: Развертывание LLM
Чтобы использовать узлы LLM в потоках подсказок, в Azure необходимо сначала развернуть одну из доступных моделей ИИ.
Для этого в левом меню выберите пункт “Каталог моделей”. На странице каталога найдите модель ИИ, которую вы хотите использовать. Например, предположим, что вы хотите использовать gpt-5-mini.
Найдите “gpt-5-mini” и выберите ее:
На странице модели нажмите “Использовать эту модель”, чтобы принять ее:
В появившемся модальном окне нажмите кнопку “Создать ресурс и развернуть”, затем дождитесь окончания развертывания модели:
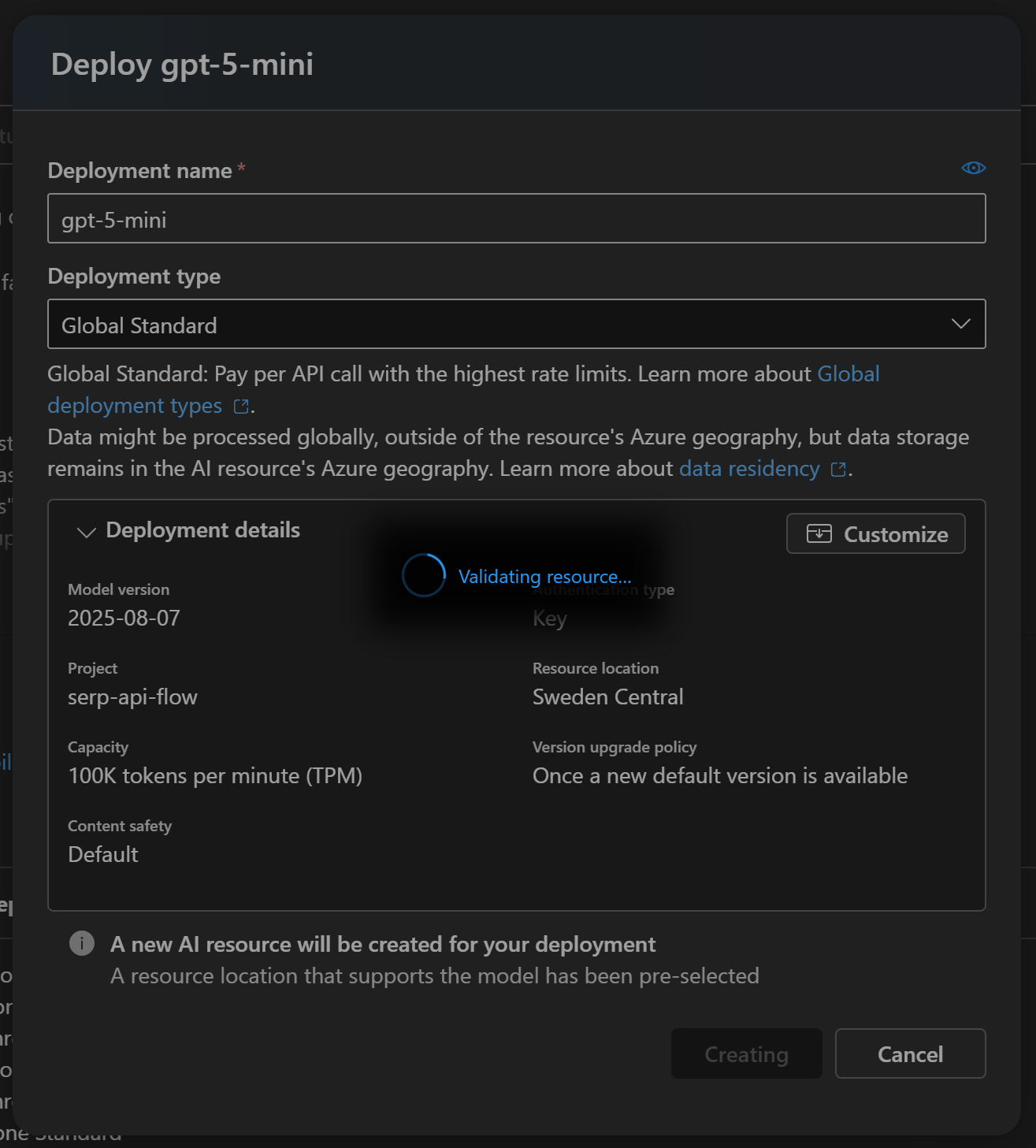
Этот процесс может занять несколько минут, поэтому наберитесь терпения. После завершения развертывания вы увидите модель, доступную в вашем проекте ИИ Azure, как показано ниже:
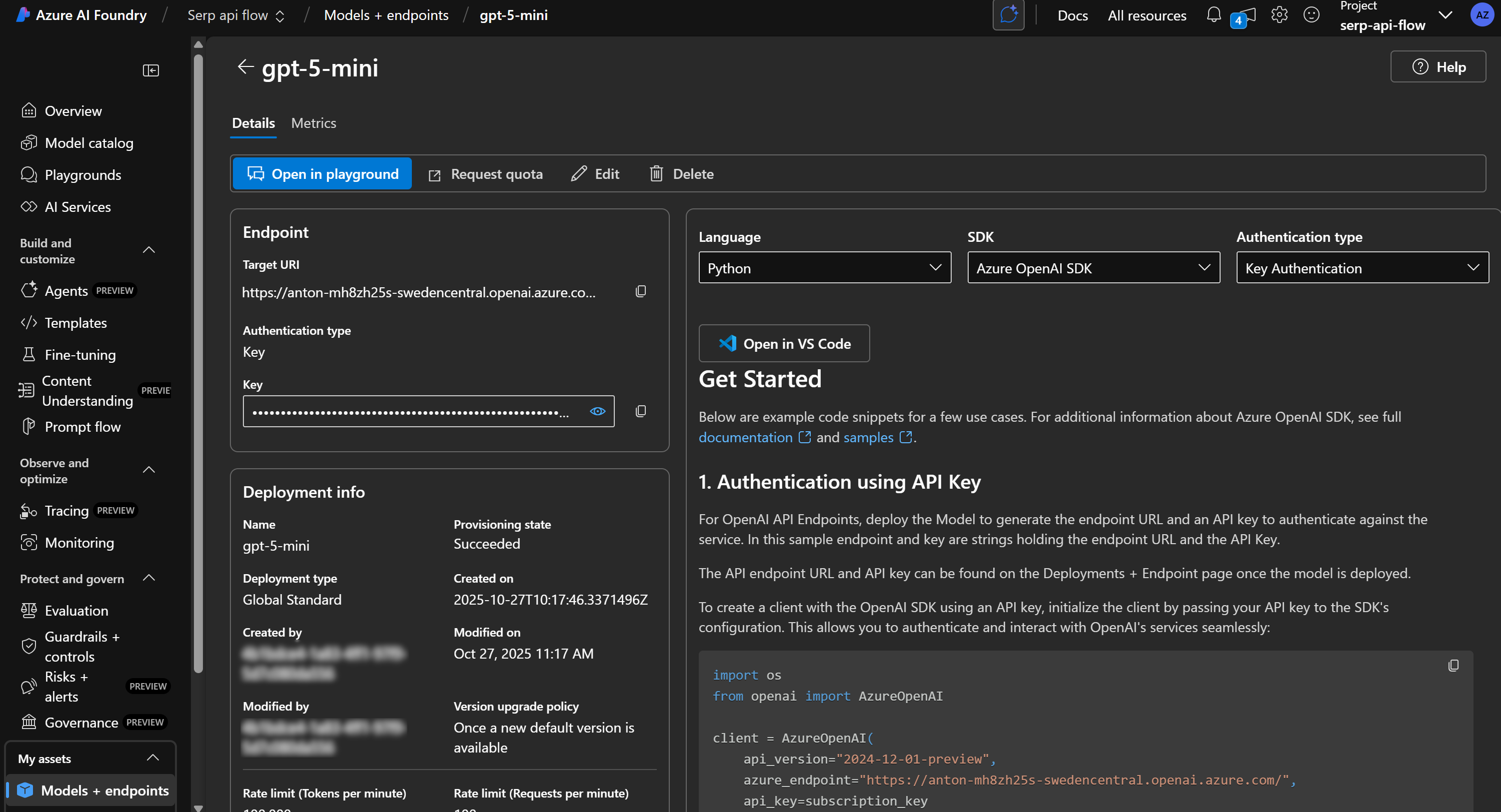
Замечательно! Теперь у вас есть движок LLM, готовый к работе с потоком подсказок.
Шаг № 4: Создание нового потока подсказок
Наконец-то пришло время начать работу над потоком подсказок. Начните с выбора “Prompt flow” в левом меню, затем нажмите кнопку “Create”:
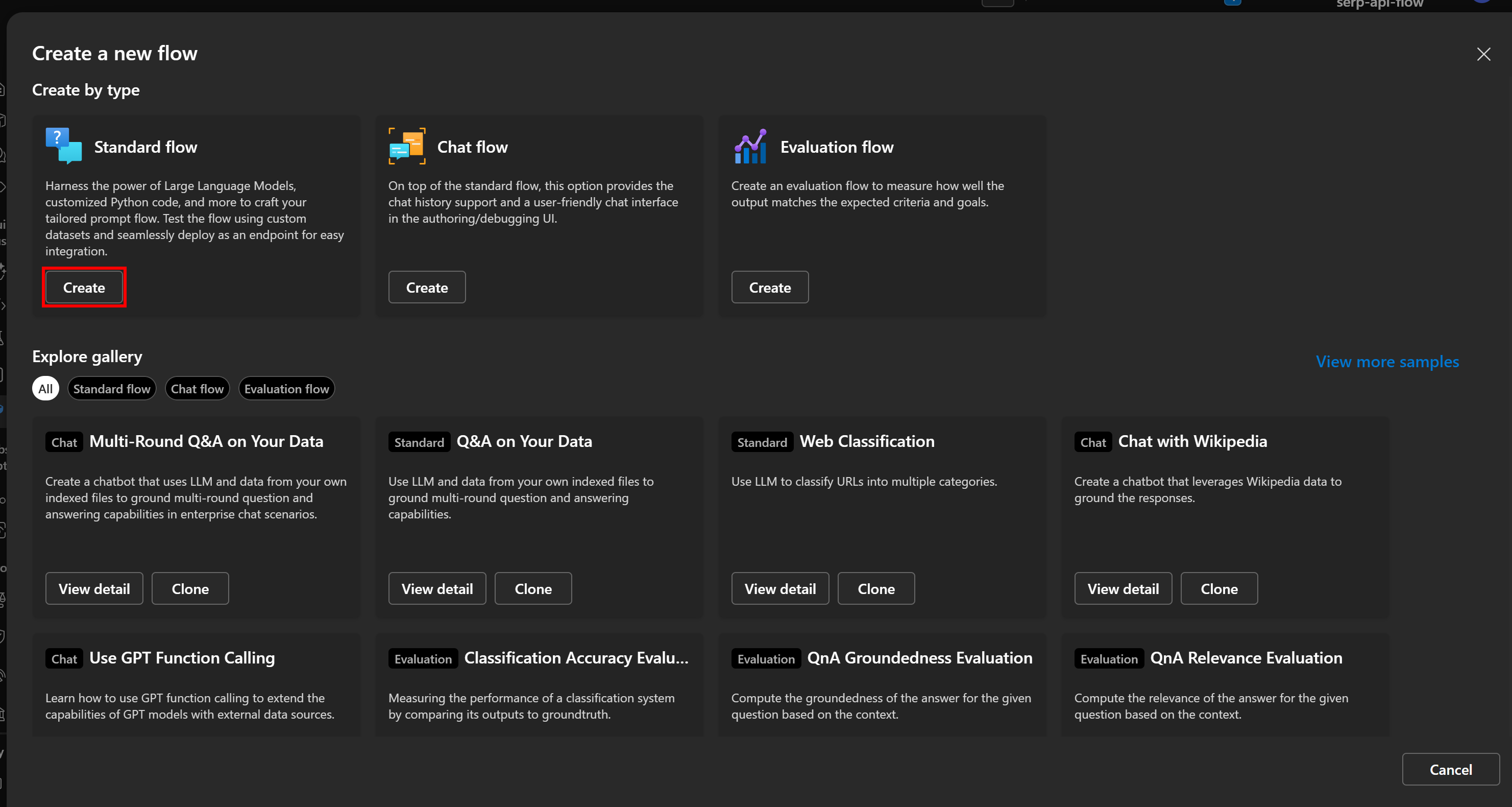
В модале “Создание нового потока” нажмите кнопку “Создать” на карточке “Стандартный поток”, чтобы запустить новый, базовый поток подсказок:
Вам будет предложено ввести имя потока. Назовите его как-нибудь вроде bright-data-serp-api-flow:
Нажмите кнопку “Создать”, дождитесь инициализации потока подсказок, и у вас должен получиться такой поток:
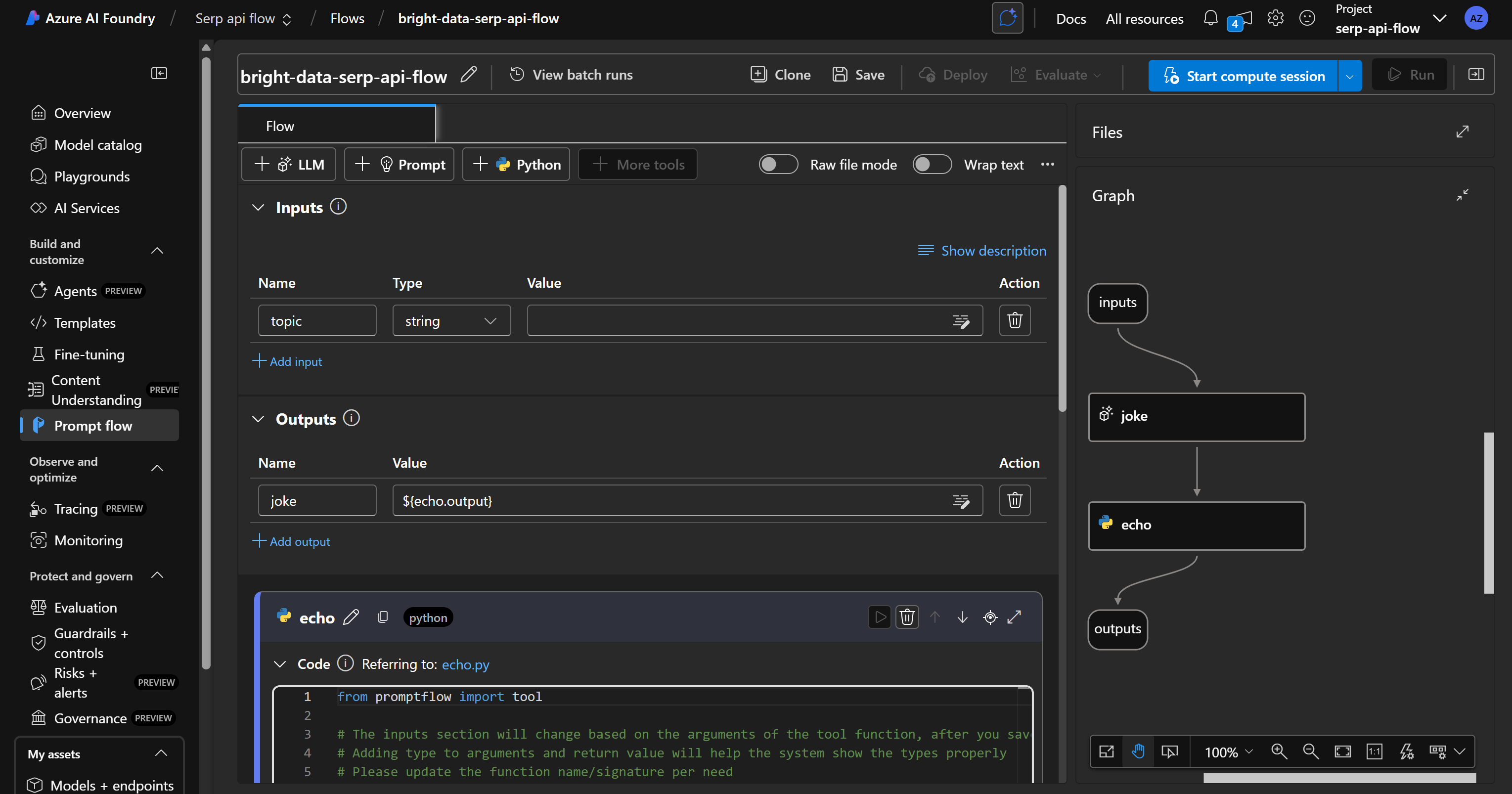
Как вы можете заметить, справа находится DAG(Directed Acyclic Graph) представление вашего потока.
Вместо этого слева находится визуальный редактор, в котором вы можете определить узлы вашего потока. Любые изменения, сделанные слева, автоматически отражаются в DAG справа.
По умолчанию стандартный поток включает простой пример, в котором ИИ предлагается рассказать анекдот.
Начните с нуля, удалив все существующие узлы и нажав “Start compute session”, чтобы ваша платформа для разработки потока заработала:
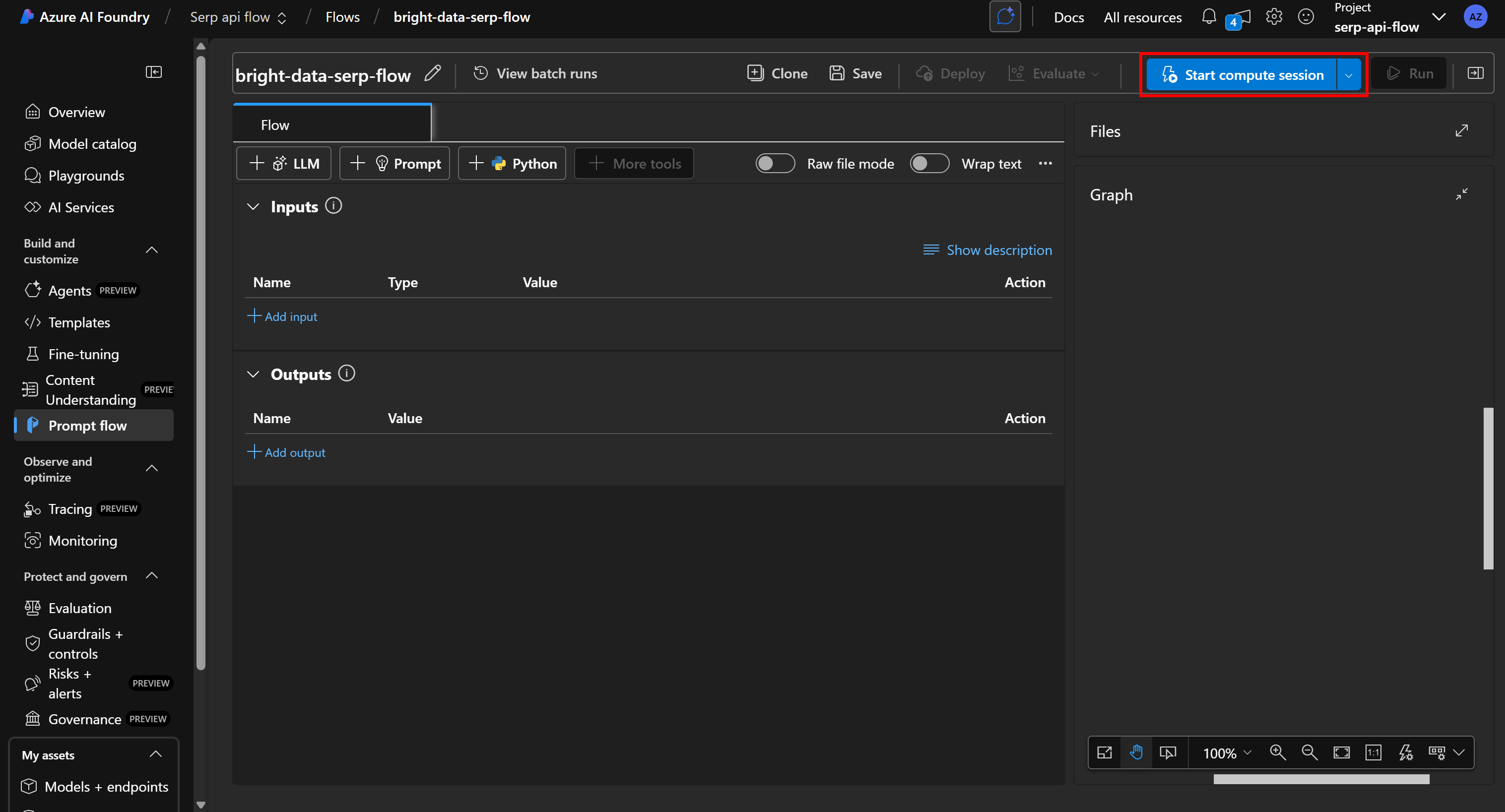
Примечание: При запуске вычислительной сессии Azure автоматически пытается запустить вычислительный экземпляр по умолчанию. Однако выделение ресурса может занять несколько минут или даже часов. Чтобы избежать длительного ожидания, запустите вычислительный сеанс вручную с помощью пользовательской конфигурации на собственном вычислительном экземпляре.
Отлично! Теперь у вас есть чистый холст, который можно превратить в поток подсказок ИИ в Azure на базе SERP API от Bright Data.
Шаг № 5: Разработка потока подсказок
Прежде чем создавать поток, необходимо четко определить узлы, которые он будет включать.
В данном случае целью является создание потока поиска и оценки новостей. При задании темы он будет опираться на Bright Data SERP API для получения связанных новостных статей из Google, а затем передавать их в LLM для оценки на предмет пригодности к прочтению. Таким образом, вы сможете быстро определить, какие статьи стоит прочитать.
Для достижения этой цели ваш поток будет состоять из четырех узлов:
- Входной узел, который принимает тему для поиска новостей в Интернете.
- Узел инструмента Python, который вызывает SERP API Bright Data, используя предоставленную тему.
- Узел LLM, который обрабатывает данные SERP, возвращаемые API, чтобы идентифицировать и оценить новостные статьи.
- Узел вывода, который отображает итоговый отчет, созданный LLM.
В следующих шагах вы узнаете, как реализовать этот поток подсказок ИИ в Azure!
Шаг № 6: Добавление входного узла
Каждый поток должен содержать как входной, так и выходной узел. Таким образом, узлы ввода и вывода не могут быть удалены и уже являются частью потока.
Чтобы настроить узел ввода, перейдите в раздел “Входы” вашего потока и нажмите кнопку “Добавить кнопку”:

Определите вход как тему и установите его тип на string:
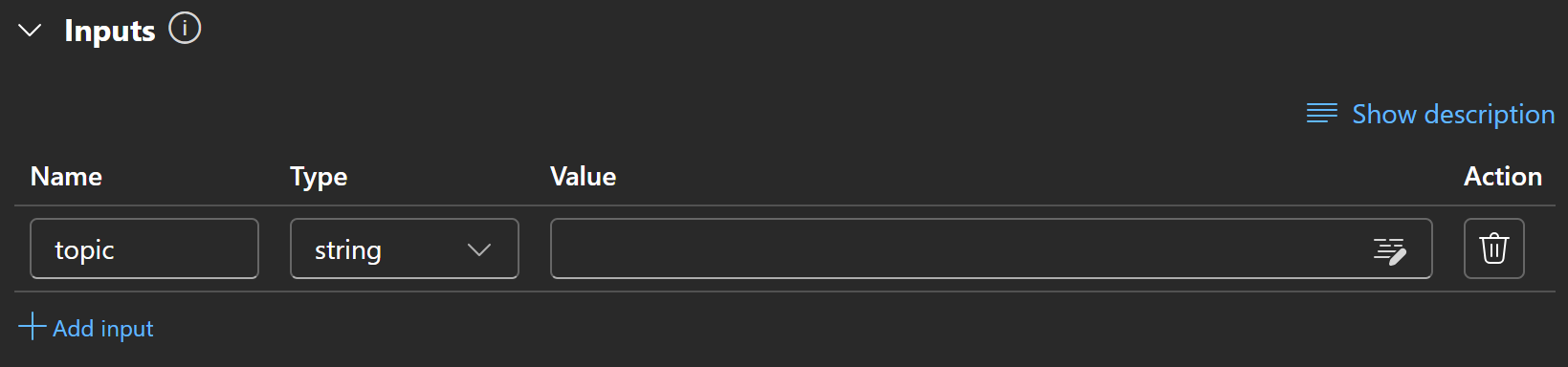
Потрясающе! Теперь узел ввода настроен.
Шаг № 7: Подготовка к вызову SERP API
Перед созданием пользовательского узла Python, вызывающего SERP API Bright Data, вам необходимо выполнить несколько подготовительных шагов. Они не являются строго обязательными, но упростят интеграцию и сделают ее более безопасной.
Во-первых, чтобы упростить вызовы API, установите Bright Data Python SDK. Этот SDK предоставляет удобные методы взаимодействия с продуктами Bright Data, включая SERP API (вместо того чтобы обращаться к ним напрямую через API с помощью HTTP-клиента). Подробнее о нем вы можете узнать из официальной документации.
SDK доступен в виде пакета brightdata-sdk. Чтобы установить его в свой поток, нажмите кнопку “Compute session running” слева, затем выберите опцию “Install packages from requirements.txt”:
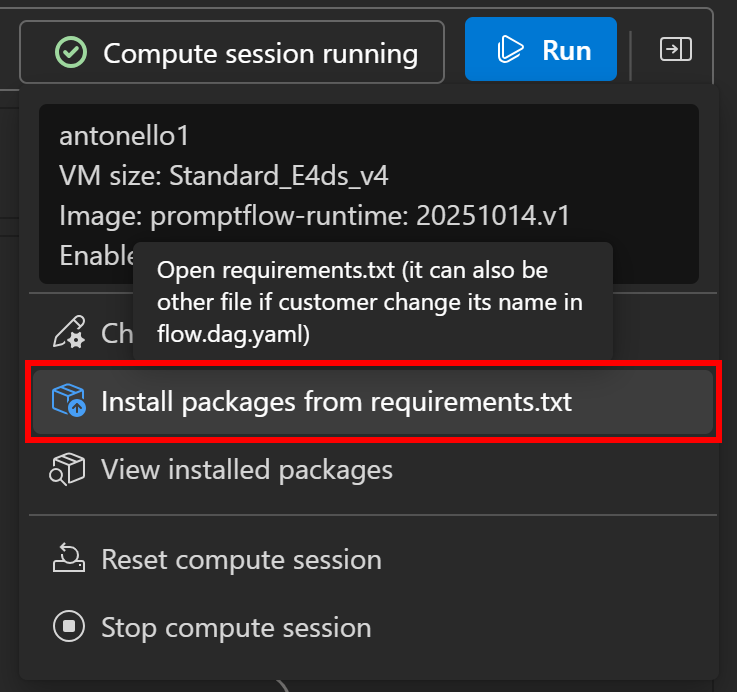
В панели определения потока откроется файл requirements.txt. Добавьте в него следующую строку, а затем нажмите кнопку “Сохранить и установить”:

После установки вы сможете использовать Bright Data Python SDK в пользовательских узлах инструментов Python.
Далее, поскольку SERP API требует аутентификации с помощью ключа API, а вы не хотите жестко кодировать его в своем потоке, вам следует надежно сохранить его как секрет в Azure. Для этого откройте “Центр управления” в левом меню (обычно это последний пункт):
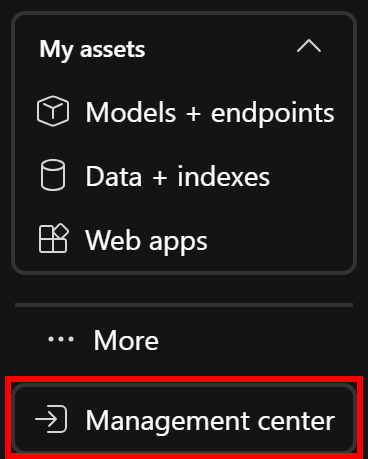
В обзоре управления проектом нажмите “Новое соединение” в разделе “Подключенные ресурсы”:
В появившемся модале выберите опцию “Пользовательские ключи”:
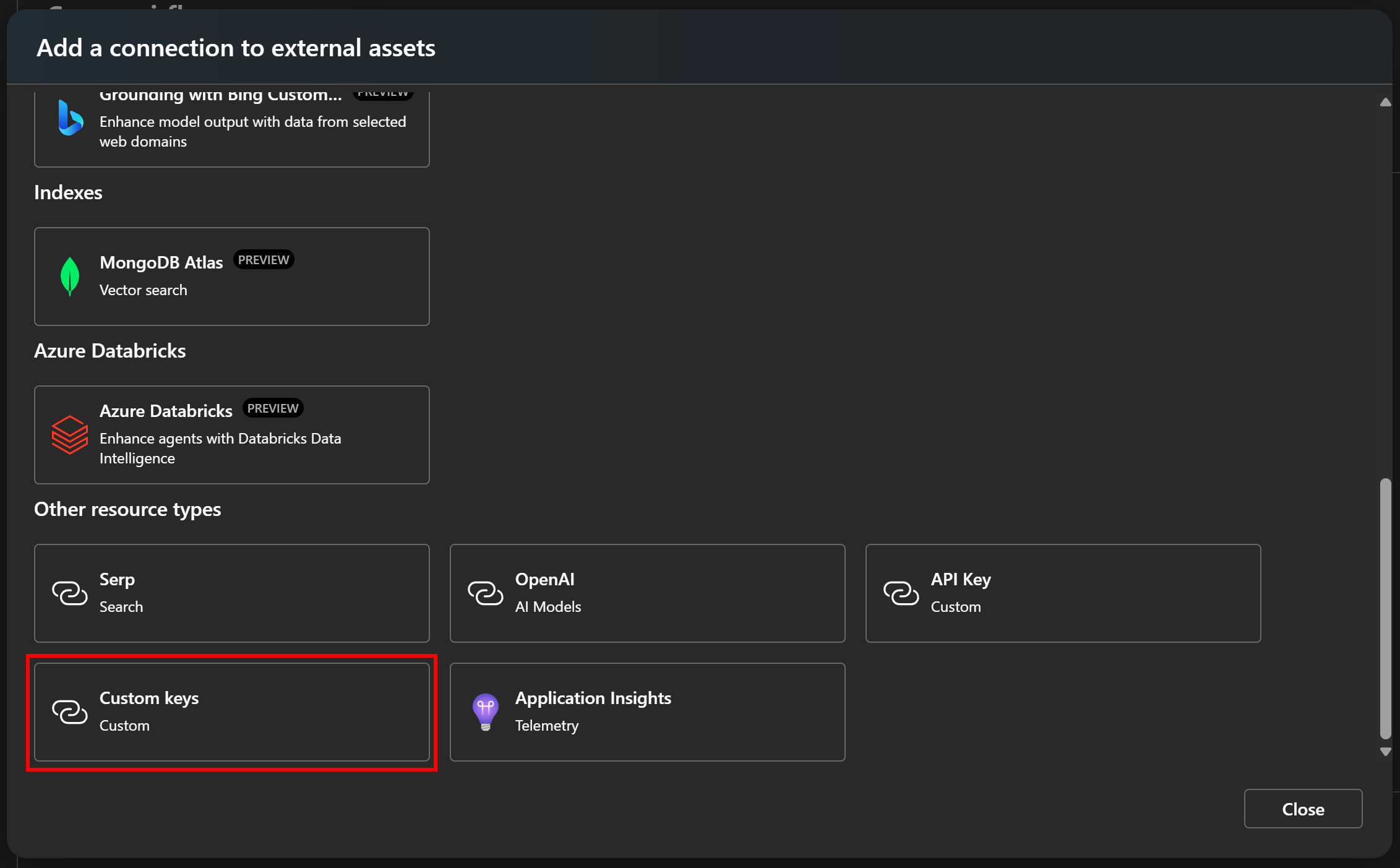
Так можно хранить пользовательские ключи API в Azure ИИ Foundry.
Теперь создайте новый секретный ключ с именем что-то вроде BRIGHT_DATA_API_KEY и вставьте свой ключ API Bright Data в поле “Значение”. Обязательно отметьте опцию “является секретным”. Затем дайте своему подключению узнаваемое имя, например bright-data:
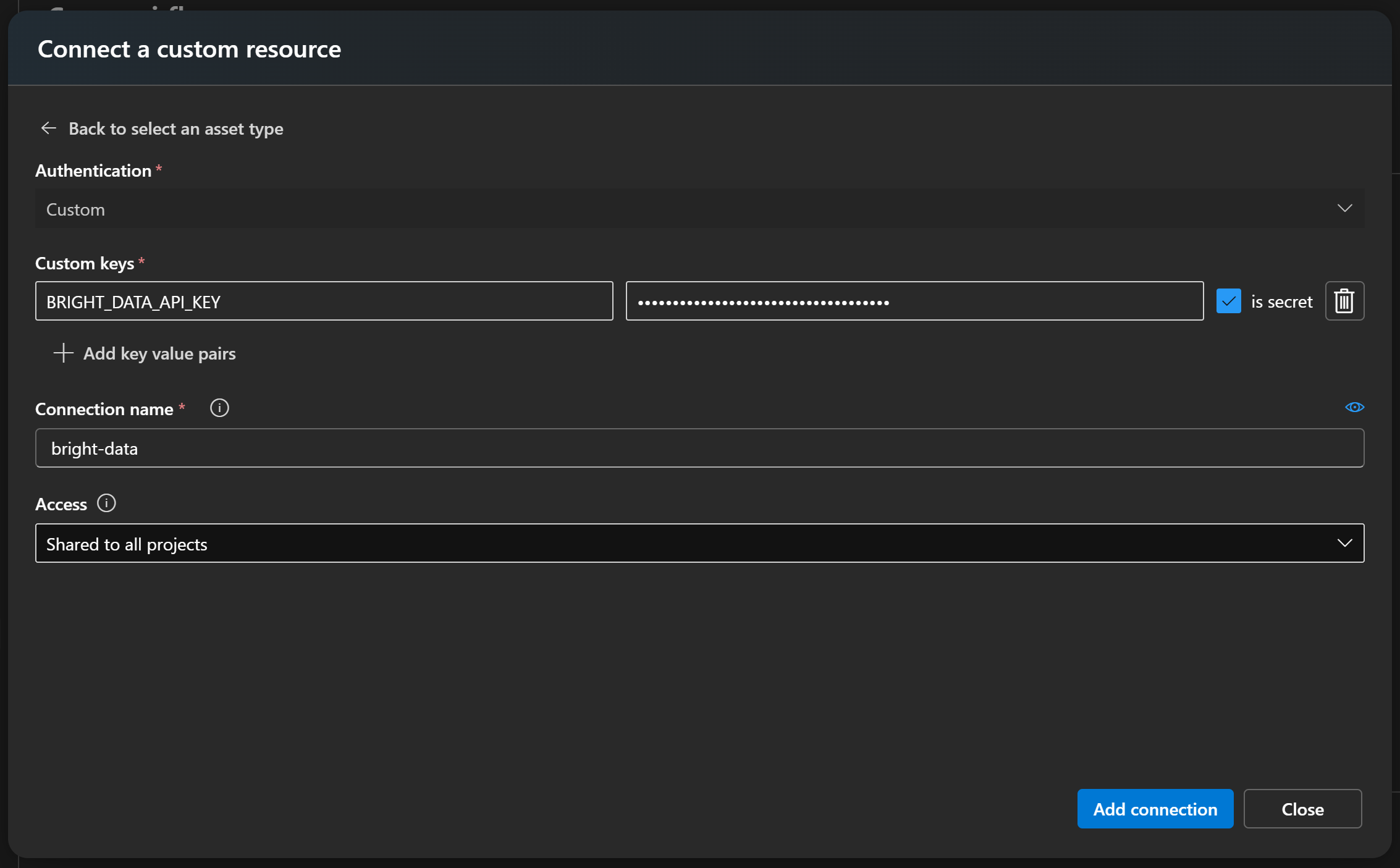
Наконец, нажмите “Добавить соединение”, чтобы сохранить.
Отлично! Возвращайтесь к своему потоку. Вы готовы увидеть, как использовать Bright Data Python SDK и сохраненный ключ API для вызова SERP API всего в нескольких строках кода.
Шаг № 8: Определение пользовательского узла Python для вызова SERP API Bright Data
На канве потока нажмите кнопку “Python”, чтобы создать новый узел инструмента Python:

Дайте узлу имя, например serp_api, и нажмите кнопку “Добавить”:

В текстовой области кода добавьте следующий Python-код:
from promptflow import tool
from promptflow.connections import CustomConnection
from brightdata import bdclient
@tool
def serp_api(search_input: str, bd_conn: CustomConnection) -> str:
# Инициализация клиента Bright Data SDK
client = bdclient(api_token=bd_conn.BRIGHT_DATA_API_KEY)
# Получение SERP из Google в формате Markdown
serp_page = client.search(
search_input,
data_format="markdown",
страна="мы"
)
return serp_pageВ Azure ИИ Foundry узлы Python должны определять инструменты как функции, аннотированные с помощью @tool. В данном случае функция serp_api() принимает в качестве входных данных строку поиска и пользовательское соединение.
Из пользовательского соединения функция считывает ключ BRIGHT_DATA_API_KEY, который вы определили ранее, и использует его для инициализации экземпляра клиента Bright Data API Python SDK. Затем этот клиент используется для вызова SERP API через метод search() с параметрами data_format="markdown" и country="US", чтобы вернуть соскобленную страницу SERP из американской версии Google в формате Markdown. (что идеально подходит для обработки ИИ).
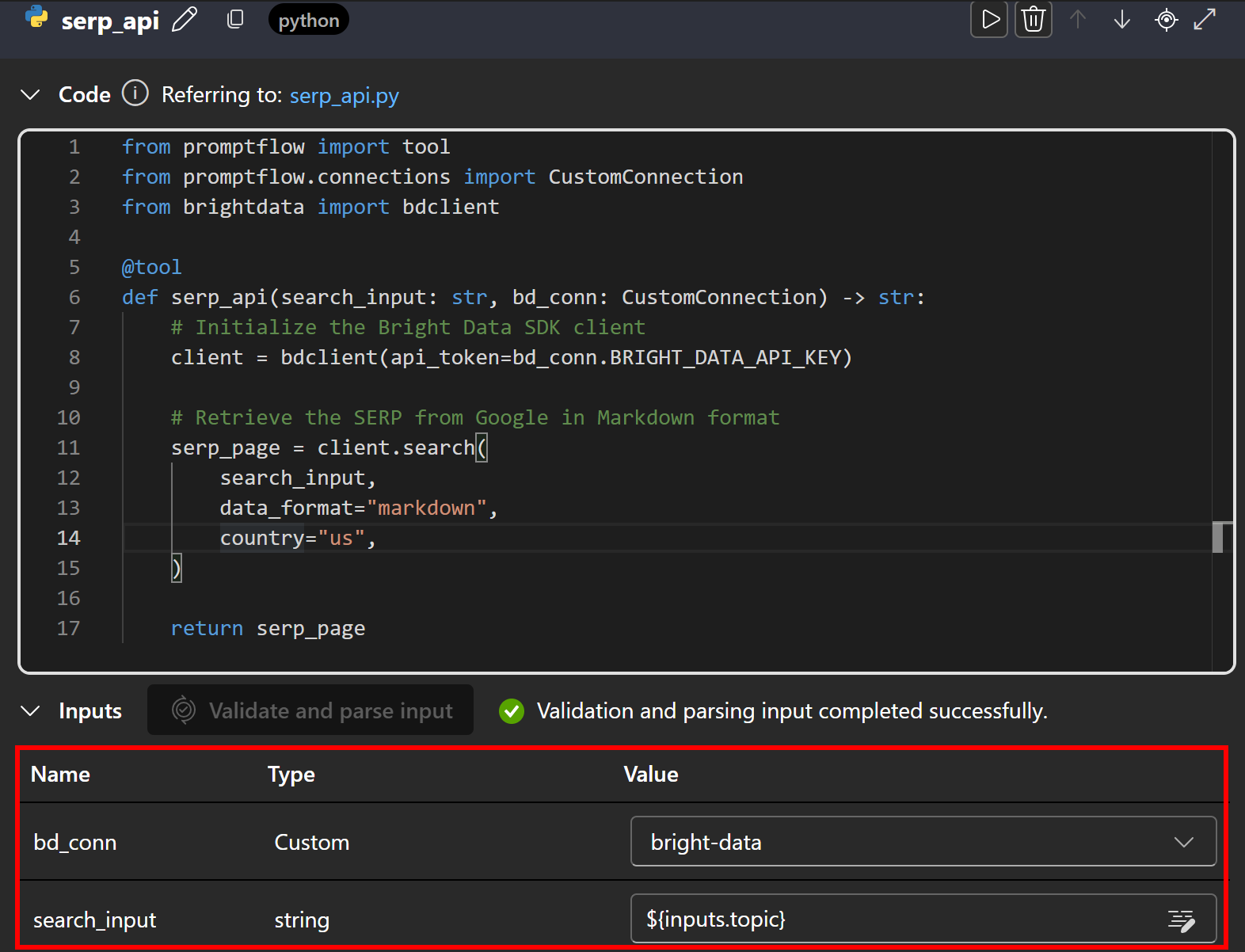
Далее прокрутите страницу вниз и определите элементы ввода для узла. Сначала нажмите “Validate and parse input”, чтобы узел мог распознать корректные входные данные. Настройте идентифицированные входы путем сопоставления:
bd_connнаbright-data(ваше пользовательское соединение, определенное ранее).search_inputна${input.topic}, чтобы поисковые данные из узла ввода передавались в SERP API.
Потрясающе! Интеграция SERP API Bright Data в Azure ИИ Foundry завершена.
Шаг № 9: Укажите узел LLM
Теперь, когда у вас есть страница SERP, соответствующая начальной теме поиска, передайте ее в узел LLM для извлечения и оценки новостей. Добавьте узел LLM, нажав кнопку “LLM” прямо под вкладкой “Поток”:

Дайте узлу LLM имя, например llm, и подтвердите его нажатием кнопки “Добавить”:

В этом узле вы определяете основную логику вашего потока подсказок. Для достижения цели извлечения и оценки новостей вы можете написать подсказку следующим образом:
# система:
Вы - помощник по анализу новостей, которому поручено определить наиболее релевантные новостные статьи по заданной теме.
# пользователь:
Учитывая приведенную ниже страницу SERP, извлеките наиболее важные новости и оцените каждую из них по шкале от 1 до 5, исходя из того, насколько она достойна прочтения.
Верните отчет в формате Markdown, содержащий:
* Заголовок новости
* URL-адрес новости
* Краткое описание (не более 20 слов)
* Читабельность (1-5)
SERP PAGE:
{{serp_page}}Раздел # system определяет роль и общее поведение помощника, а раздел # user содержит конкретную задачу и инструкции по обработке вводимых данных.
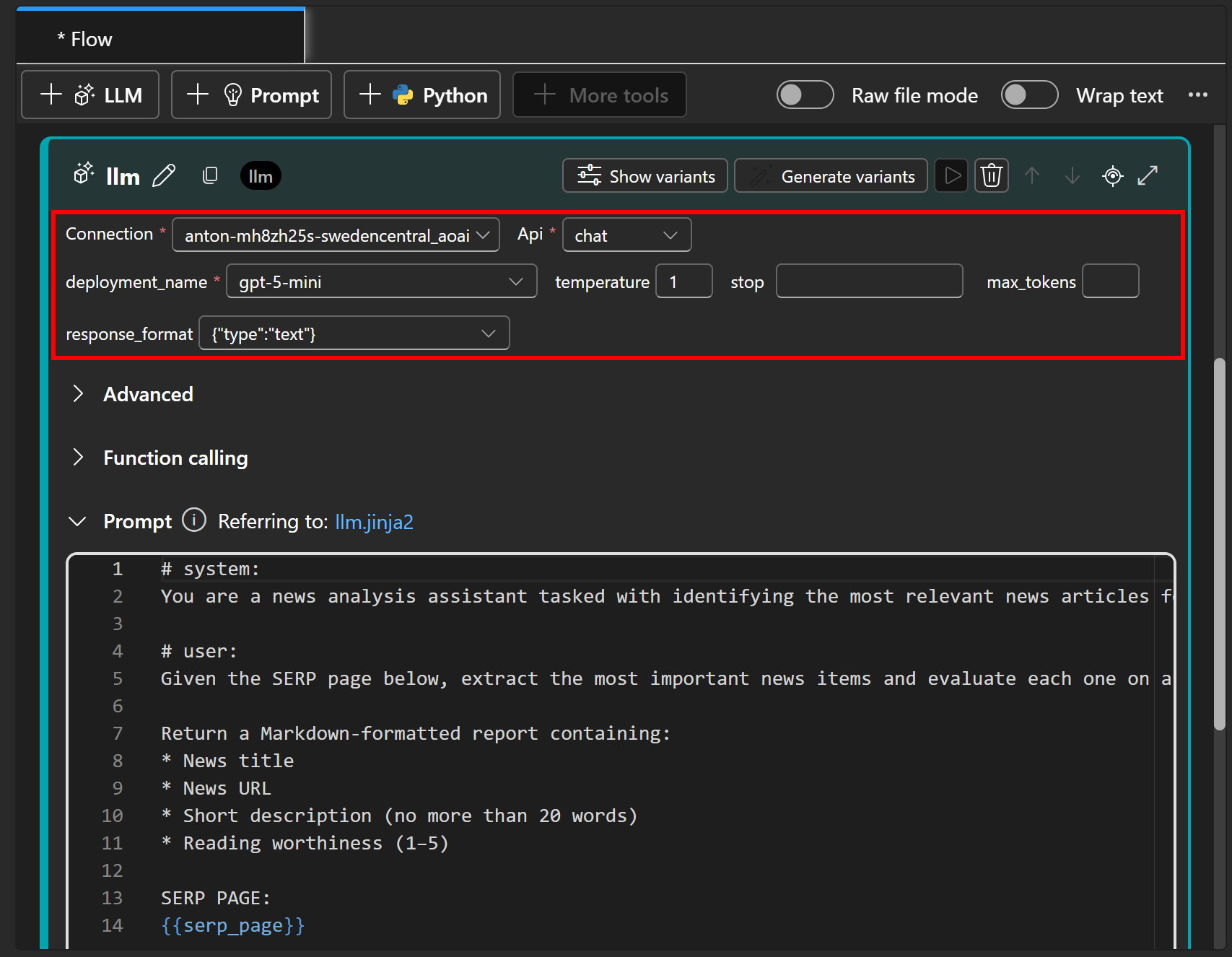
Далее настройте узел LLM на подключение к модели ИИ, развернутой ранее (в шаге #3):
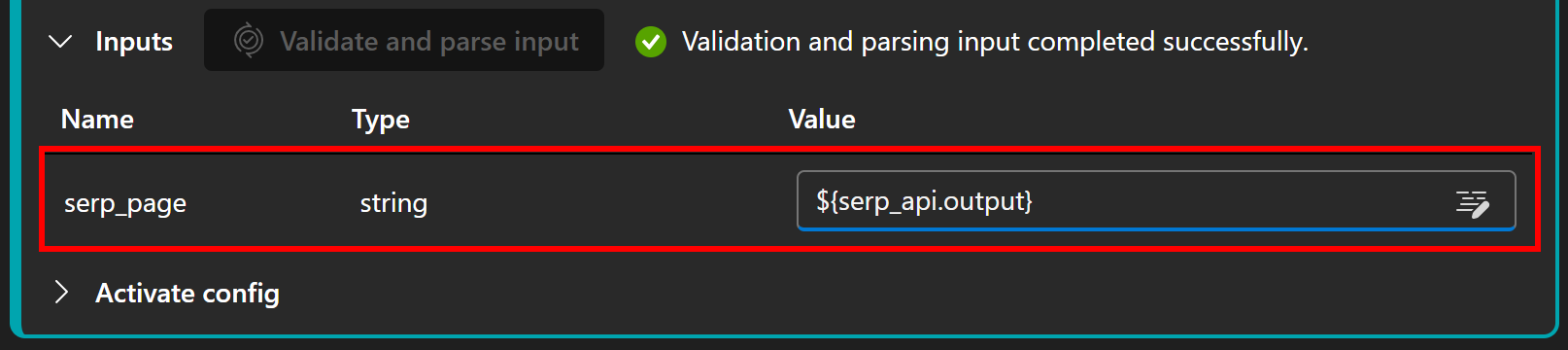
Обратите внимание, что приглашение содержит параметр serp_page, который должен быть установлен на выход узла serp_api, определенного ранее. Настройте его в разделе “Inputs”, нажав “Validate and parse input” и присвоив serp_page значение ${serp_api.output}:
Отлично! Теперь у вашего потока ИИ в Azure есть функционирующий “мозг” LLM, способный обрабатывать результаты SERP и генерировать оцененные новостные отчеты.
Шаг № 10: Определите выходной узел
Последний шаг – настройка выходного узла. В разделе “Выходы” нажмите “Добавить выход”:

Задайте для вывода имя report и назначьте его выходом узла LLM с помощью переменной ${llm.output}:

После этого нажмите “Сохранить”, чтобы сохранить поток подсказок:

Поздравляем! Теперь ваш поток ИИ в Azure полностью реализован.
Шаг #11: Соберите все вместе
Если вы посмотрите на раздел “График” в среде разработки потока, вы должны увидеть группу DAG, как показано ниже:
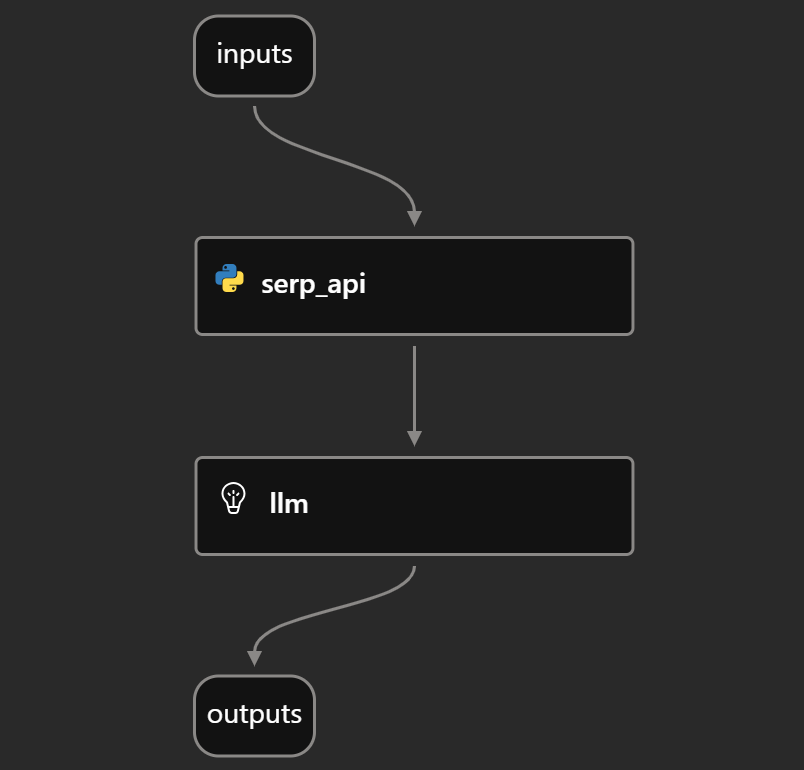
Она наглядно представляет поток анализа новостей, описанный в шаге № 5, и показывает, как связаны входные данные, вызов SERP API, оценка LLM и выход.
Шаг № 12: Запуск потока подсказок
Чтобы протестировать поток подсказок ИИ Azure, давайте воспользуемся примером темы “Новости фондового рынка”. В узле “Inputs” заполните “Value” для темы строкой “stock market news”:

Затем нажмите кнопку “Выполнить” в правом верхнем углу, чтобы запустить поток:

Вы должны увидеть, как каждый узел постепенно становится зеленым по мере прохождения данных через поток, пока они не достигнут узла “Выходы”:
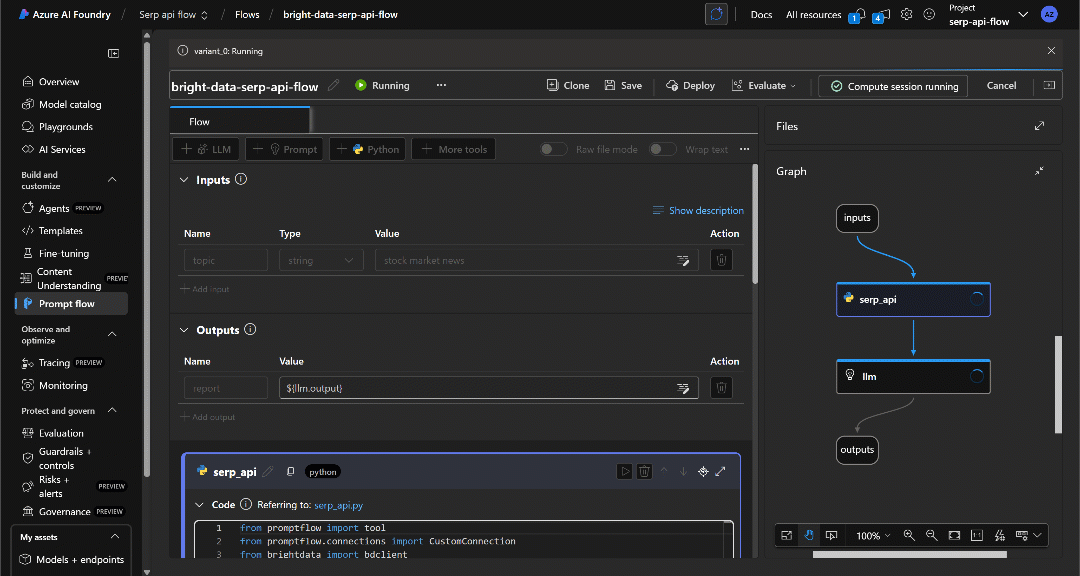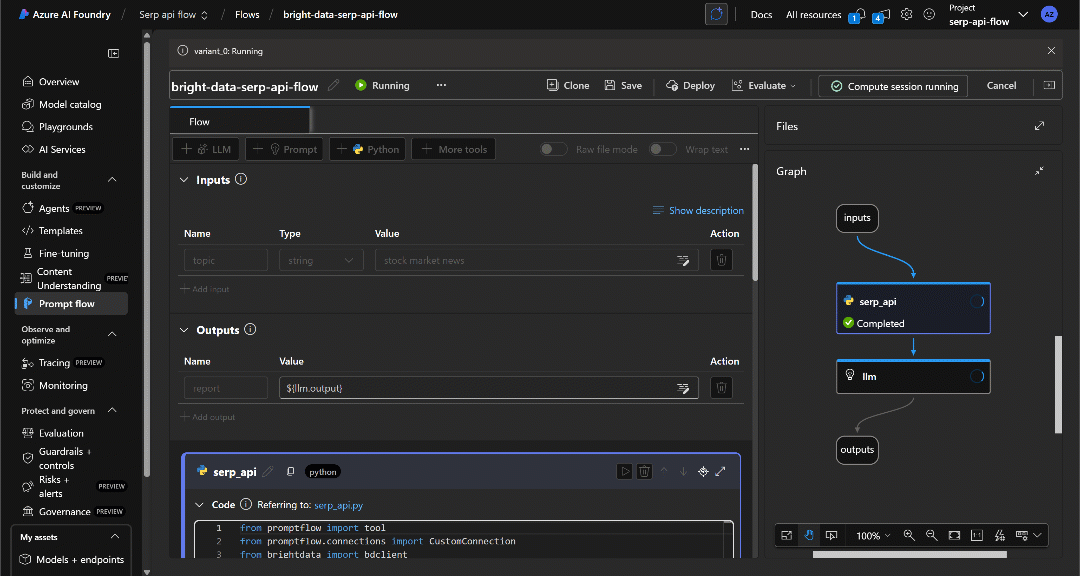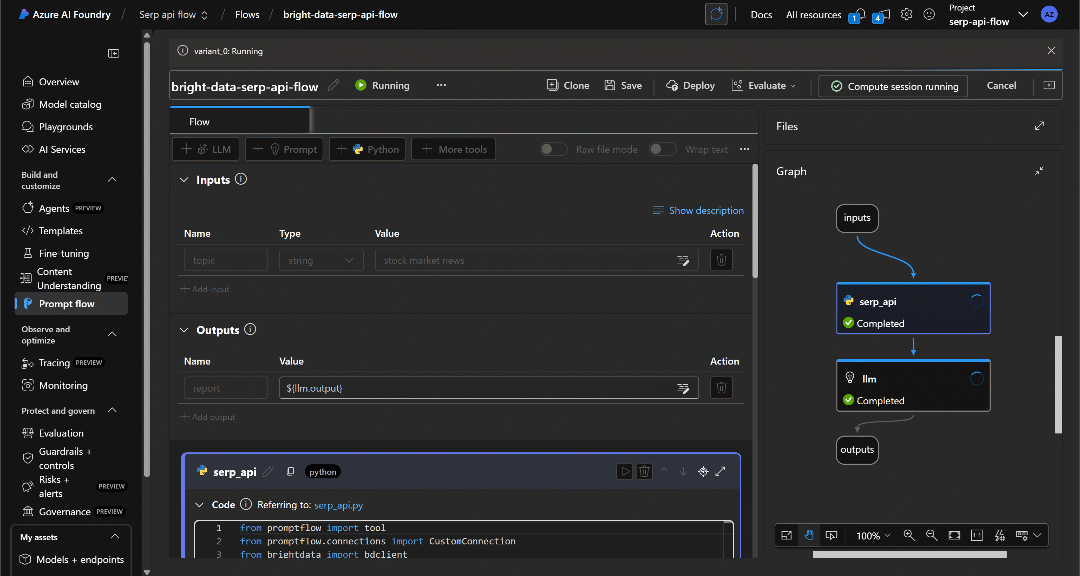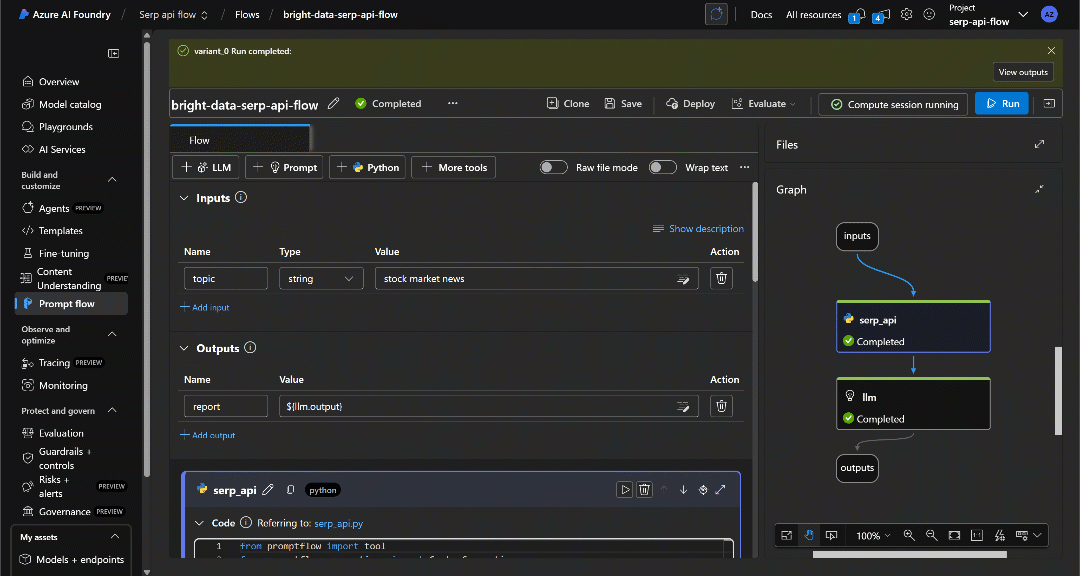
Когда выполнение завершится, вы получите уведомление, как показано на рисунке:

Нажмите кнопку “View outputs”, чтобы просмотреть результат работы потока:
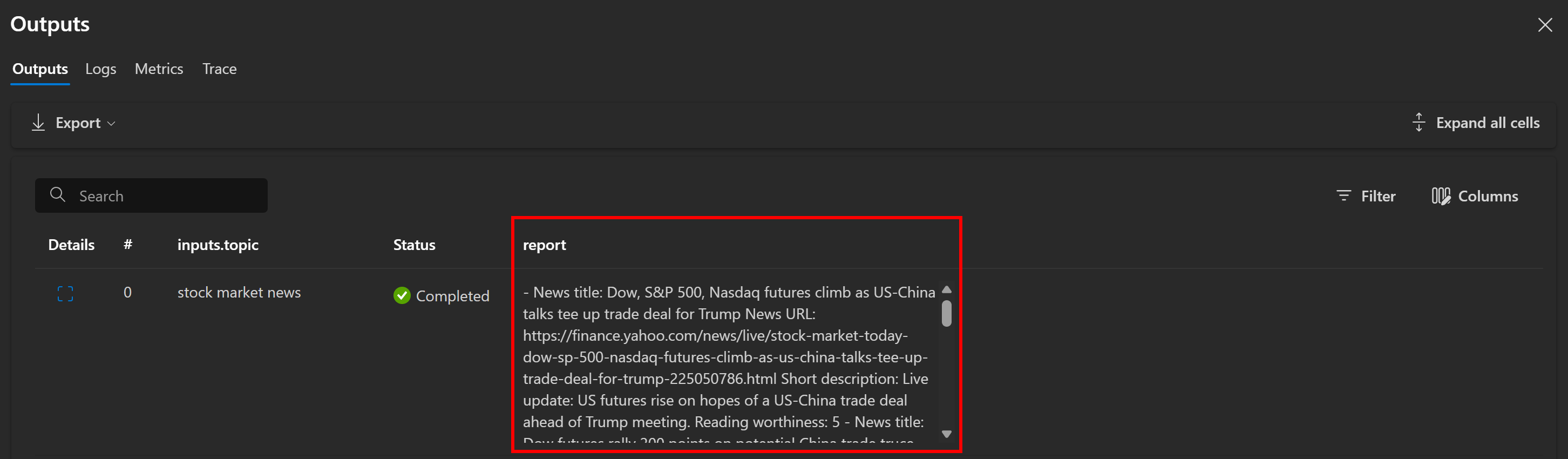
Как и ожидалось, поток создает отчет в формате Markdown, содержащий новостные статьи. В данном случае он включает:
- ** Заголовок новости:** Фьючерсы на Dow, S&P 500, Nasdaq растут на фоне переговоров между США и Китаем, которые подготавливают торговую сделку для Трампа
** URL-адрес новости:** [Yahoo Finance](https://finance.yahoo.com/news/live/stock-market-today-dow-sp-500-nasdaq-futures-climb-as-us-china-talks-tee-up-trade-deal-for-trump-225050786.html)
**Краткое описание:** Обновление в прямом эфире: американские фьючерсы растут на надеждах на заключение торговой сделки между США и Китаем в преддверии встречи с Трампом.
**Читабельность:** 5
- Заголовок новости:** Фондовый рынок сегодня: Фьючерсы на Dow, S&P 500, Nasdaq растут на фоне переговоров между США и Китаем, которые предваряют торговую сделку с Трампом
** URL-адрес новости:** [Yahoo Finance](https://finance.yahoo.com/news/live/stock-market-today-dow-sp-500-nasdaq-futures-climb-as-us-china-talks-tee-up-trade-deal-for-trump-225050786.html)
**Краткое описание:** Рынки растут на фоне возобновления оптимизма в отношении торговли между США и Китаем во время переговоров с Трампом.
**Читабельность:** 5
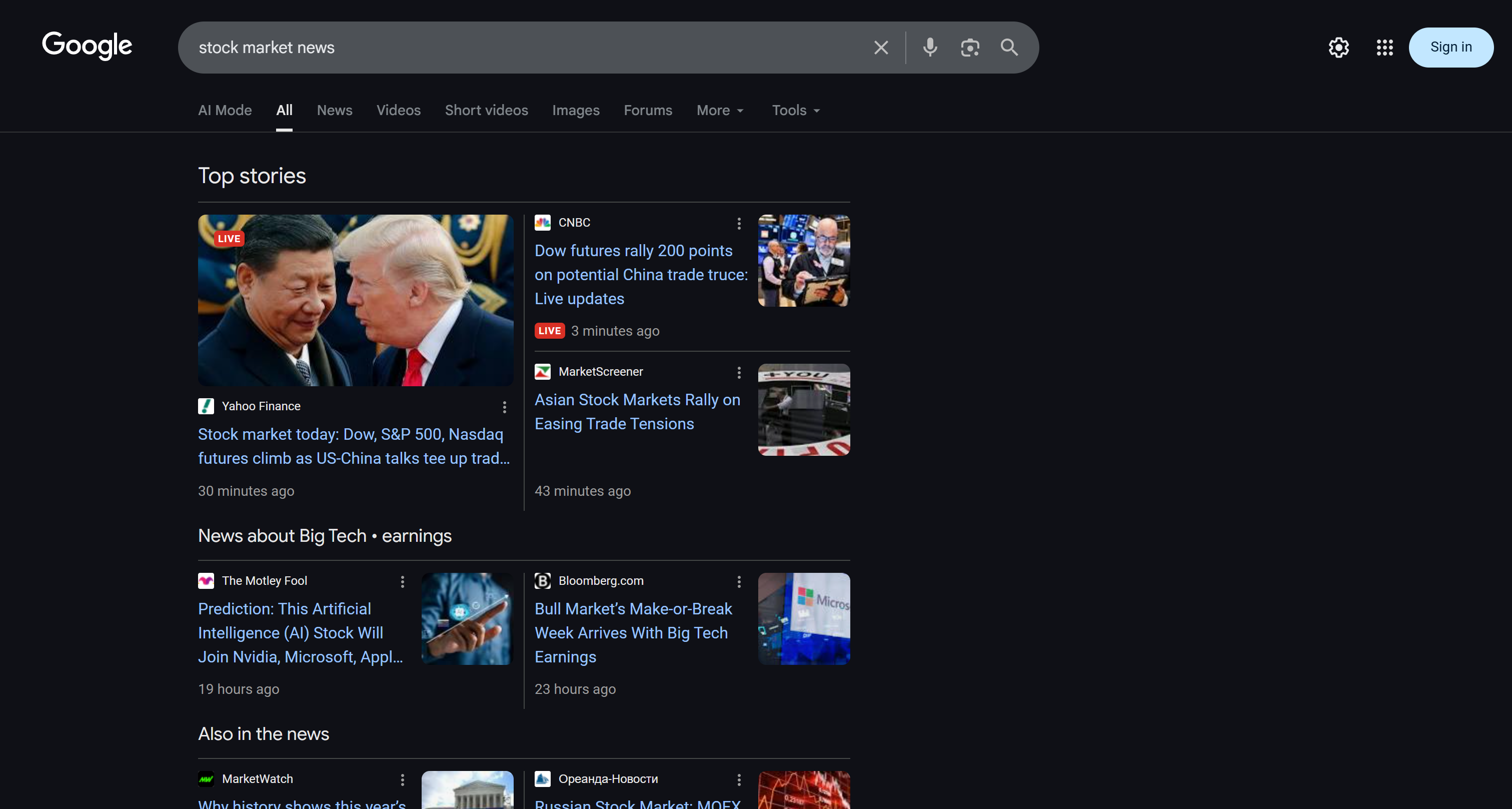
* Опущено для краткости...Эти результаты отражают SERP-страницу “Новости фондового рынка” на момент запуска потока:
Чтобы убедиться в том, что страница SERP была получена правильно, посмотрите вкладку “output” в разделе “Outputs” узла serp_api:
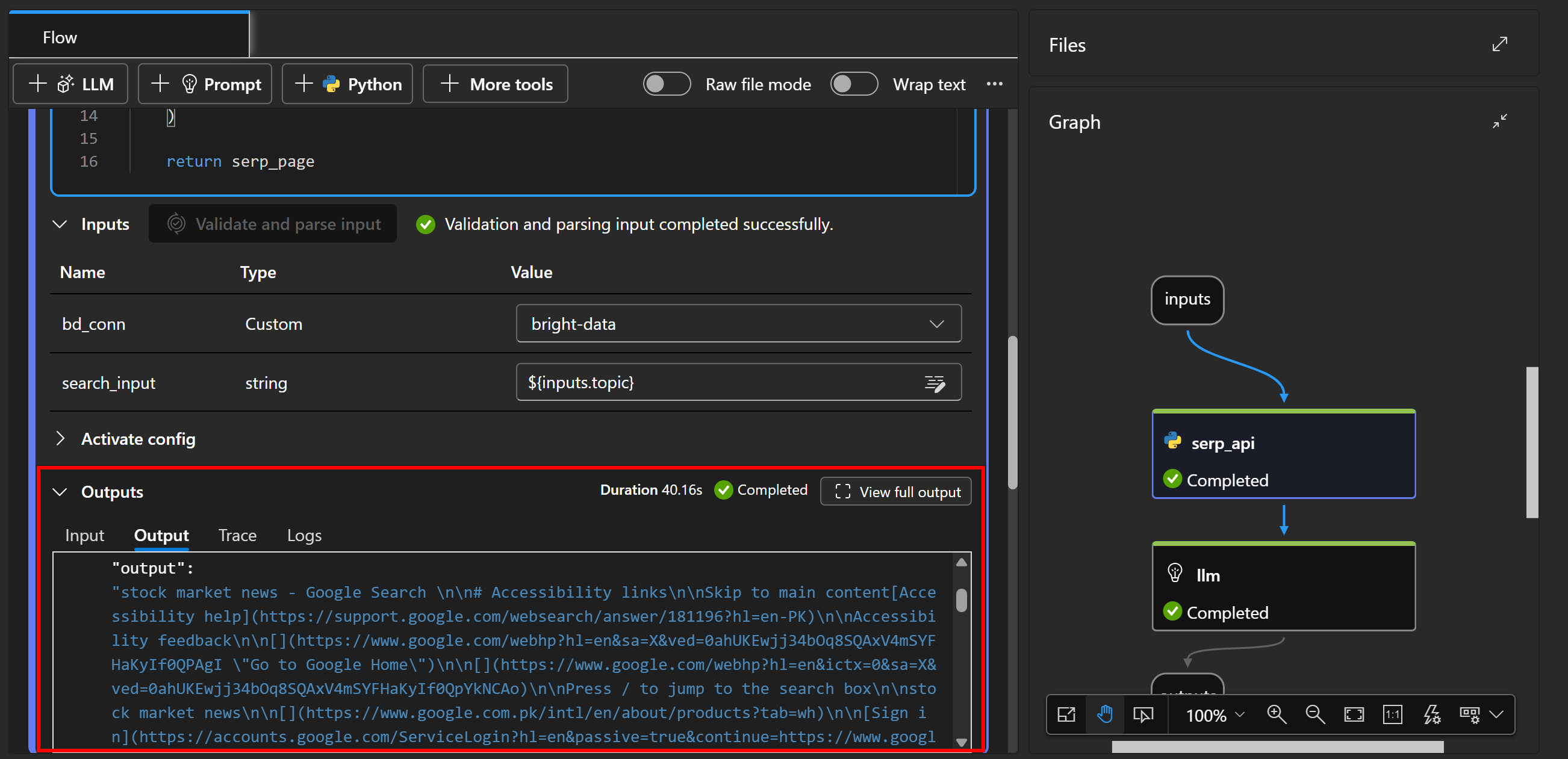
Там вы увидите версию исходного SERP в формате Markdown. SERP API от Bright Data сделал свое волшебство!
Теперь, чтобы полностью изучить вывод потока, скопируйте вывод отчета в файл, например, report.md. Просмотрите его в программе просмотра Markdown, например в Visual Studio Code:
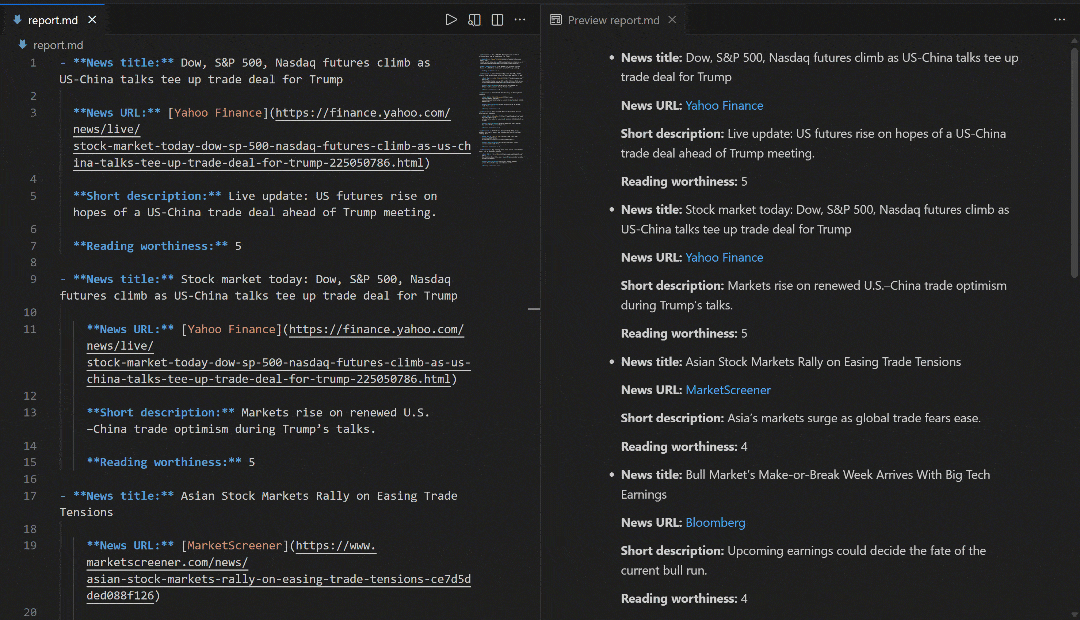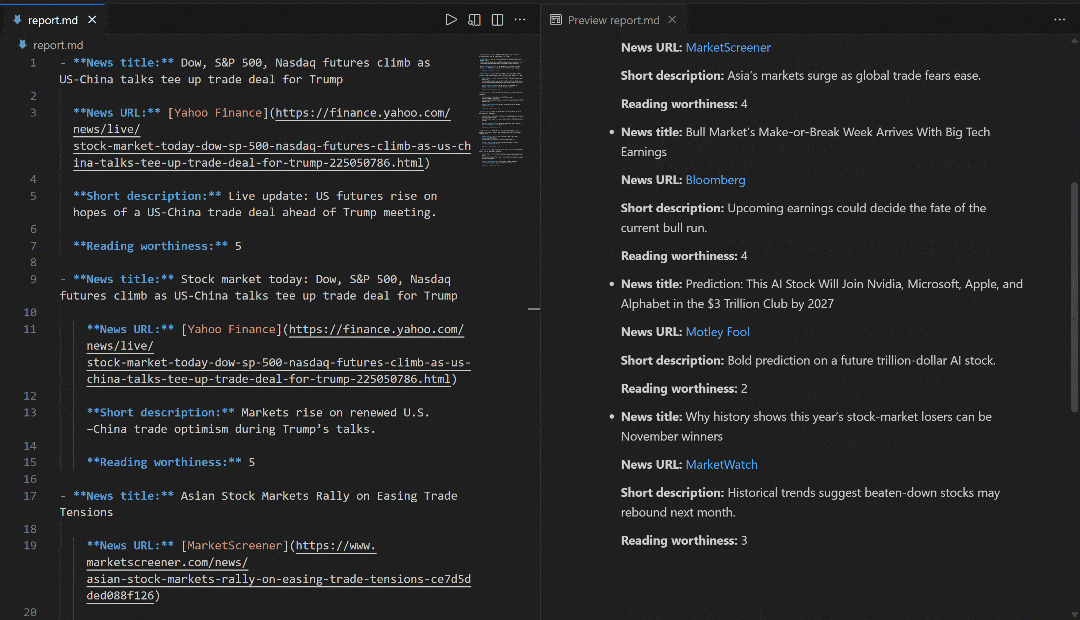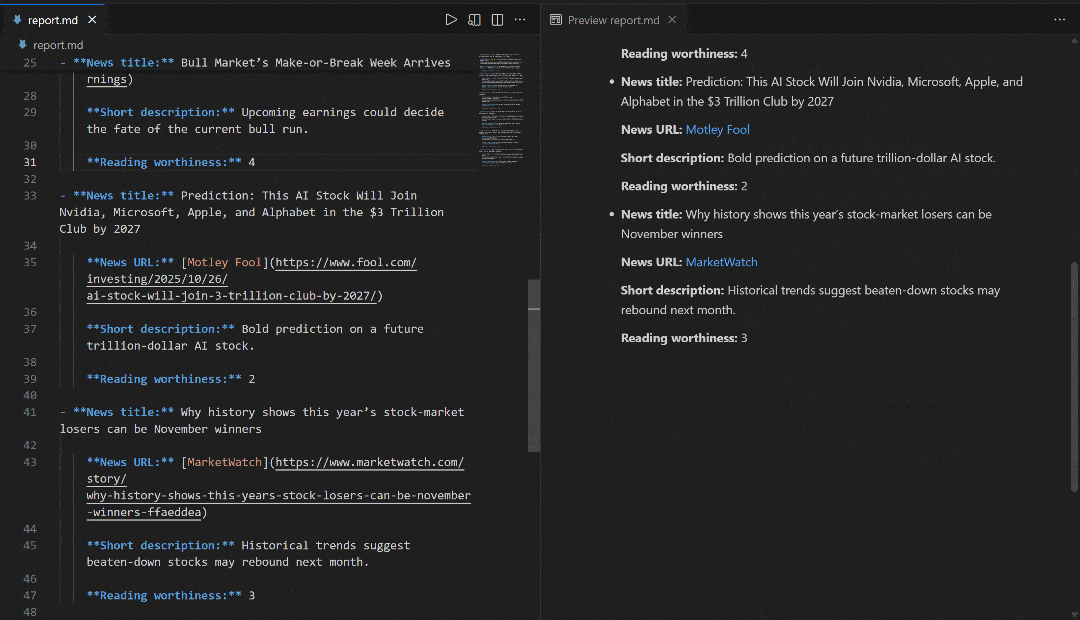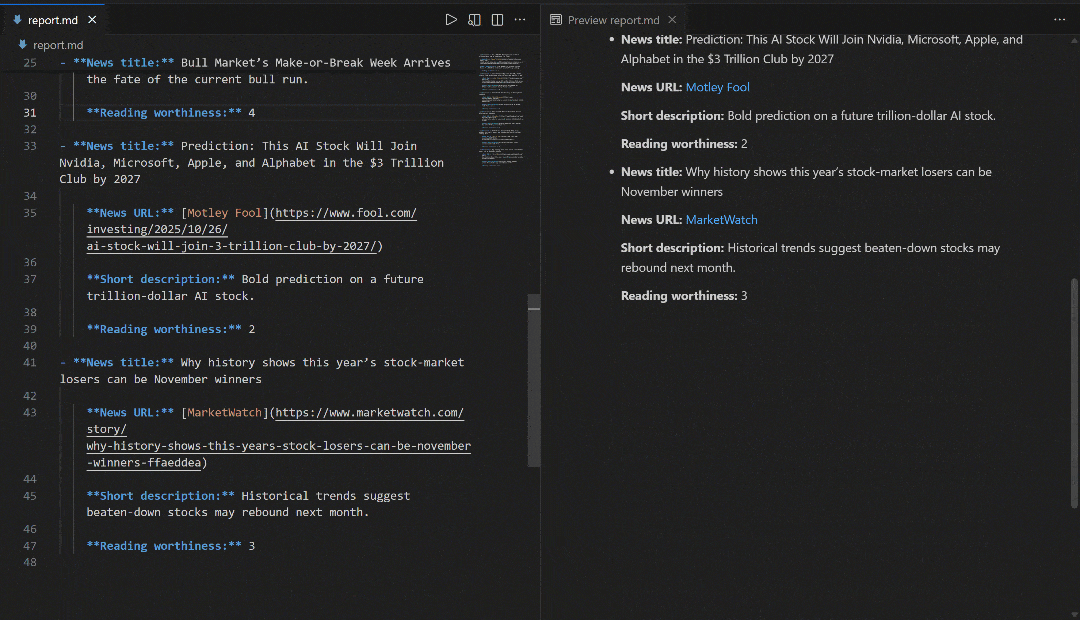
Обратите внимание, как отчет, созданный потоком, совпадает с новостями, показанными в поисковой выдаче Google по запросу “новости фондового рынка”. Скрапинг результатов поиска Google, как известно, затруднен из-за мер по борьбе с ботами и ограничителей скорости. Используя SERP API, вы можете легко и надежно получать результаты Google (или любой другой поддерживаемой поисковой системы) из разных регионов в формате Markdown, готовом для ИИ, без ограничений по масштабируемости.
Этот пример демонстрирует простой вариант использования, но вы можете экспериментировать с более сложными потоками, интегрировать другие продукты Bright Data или настроить подсказку LLM для решения различных задач. Поддерживаются и многие другие сценарии использования!
И вуаля! Теперь у вас есть поток Azure ИИ Foundry, который извлекает данные веб-поиска и использует их в качестве контекста в рабочем процессе в стиле RAG.
Заключение
В этой статье вы узнали, как использовать SERP API от Bright Data для получения свежих новостных статей из Google и интеграции их в рабочий процесс RAG в Azure ИИ.
Продемонстрированный здесь рабочий процесс ИИ идеально подходит для тех, кто хочет создать новостной помощник, фильтрующий контент, чтобы вы читали только те новости, которые имеют отношение к интересующим вас темам. Чтобы создать более сложные рабочие процессы ИИ, изучите полный набор инструментов Bright Data для получения, проверки и преобразования живых веб-данных.
Зарегистрируйте бесплатную учетную запись Bright Data сегодня и начните экспериментировать с нашими решениями для работы с веб-данными, готовыми к ИИ!





