

Это руководство поможет вам вручную извлечь общедоступные данные из Airbnb с помощью Python. Собранные данные могут помочь проанализировать рыночные тенденции, разработать конкурентоспособные ценовые стратегии, провести анализ настроений по отзывам гостей или создать системы рекомендаций.
Кроме того, изучите передовые решения от Bright Data. Специализированные прокси и браузеры для скрейпинга упрощают и улучшают процесс извлечения данных.
Как извлечь данные из Airbnb
Прежде чем приступить к работе, рекомендуется иметь базовые знания о Веб-скрейпинге и HTML. Кроме того, убедитесь, что на вашем компьютере установлен Python, если он еще не установлен.Официальное руководство по Pythonсодержит подробные инструкции о том, как это сделать. Если Python уже установлен, убедитесь, что он обновлен до версии Python 3.7.9 или более поздней. Мы также рекомендуем прочитать полное руководство по Веб-скрейпингу Python перед началом работы.
После установки Python запустите терминал или интерфейс командной строки и начните создание нового каталога проекта с помощью следующих команд:
mkdir airbnb-parser && cd airbnb-parser
После создания нового каталога проекта вам необходимо настроить несколько дополнительных библиотек, которые вы будете использовать для Веб-скрейпинга. В частности, вы будете использовать Requests, библиотеку, позволяющую выполнять HTTP-запросы в Python; pandas, надежную библиотеку, предназначенную для манипулирования и анализа данных; Beautiful Soup (BS4) для разбора HTML-контента; и Playwright для автоматизации задач, основанных на браузере.
Чтобы установить эти библиотеки, откройте терминал или оболочку и выполните следующие команды:
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
playwright install
Убедитесь, что процесс установки завершился без ошибок, прежде чем переходить к следующему шагу этого руководства.
Примеча ние: последняя команда (
playwright install) необходима для установки бинарных файлов браузера.
Структура Airbnb и объекты данных
Прежде чем приступить к сбору данных с Airbnb, необходимо ознакомиться с его структурой. На главной странице Airbnb есть удобная панель поиска, которая позволяет искать варианты проживания, развлечения и даже приключения.
После ввода критериев поиска результаты отображаются в виде списка, в котором указаны названия объектов, цены, местоположение, рейтинги и другие соответствующие сведения. Стоит отметить, что эти результаты поиска можно фильтровать по различным параметрам, таким как ценовой диапазон, тип объекта и даты доступности.
Если вы хотите увидеть больше результатов поиска, чем те, которые отображаются изначально, вы можете воспользоваться кнопками пагинации, расположенными внизу страницы. Каждая страница обычно содержит множество объявлений, что позволяет вам просматривать дополнительные объекты. Фильтры, расположенные в верхней части страницы, дают возможность уточнить поиск в соответствии с вашими потребностями и предпочтениями.
Чтобы понять структуру HTML веб-сайта Airbnb, выполните следующие действия:
- Перейдите на веб-сайт Airbnb.
- Введите желаемое местоположение, диапазон дат и количество гостей в строку поиска и нажмите Enter.
- Запустите инструменты разработчика браузера, щелкнув правой кнопкой мыши по карточке объекта недвижимости и выбрав «Проверить».
- Изучите HTML-макет, чтобы найти теги и атрибуты, которые содержат данные, которые вы хотите скопировать.
Сбор данных из объявления Airbnb
Теперь, когда вы знаете больше о структуре Airbnb, настройте Playwright для перехода к списку Airbnb и сбора данных. В этом примере вы соберете название списка, местоположение, информацию о ценах, данные о владельце и отзывы.
Создайте новый скрипт Python, airbnb_scraper.py, и добавьте следующий код:
import asyncio
from playwright.async_api import async_playwright
import pandas as pd
async def scrape_airbnb():
async with async_playwright() as pw:
# Запустить новый браузер
browser = await pw.chromium.launch(headless=False)
page = await browser.new_page()
# Перейти по URL Airbnb
await page.goto('https://www.airbnb.com/s/homes', timeout=600000)
# Подождите, пока загрузятся списки
await page.wait_for_selector('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
# Извлеките информацию
results = []
listings = await page.query_selector_all('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
for listing in listings:
result = {}
# Название объекта недвижимости
name_element = await listing.query_selector('div[data-testid="listing-card-title"]')
if name_element:
result['property_name'] = await page.evaluate("(el) => el.textContent", name_element)
else:
result['property_name'] = 'N/A'
# Местоположение
location_element = await listing.query_selector('div[data-testid="listing-card-subtitle"]')
result['location'] = await location_element.inner_text() if location_element else 'N/A'
# Цена
price_element = await listing.query_selector('div._1jo4hgw')
result['price'] = await price_element.inner_text() if price_element else 'N/A'
results.append(result)
# Закрыть браузер
await browser.close()
return results
# Запустить парсер и сохранить результаты в файл CSV
results = asyncio.run(scrape_airbnb())
df = pd.DataFrame(results)
df.to_csv('airbnb_listings.csv', index=False)
Функция scrape_airbnb() асинхронно открывает браузер, переходит на страницу списка объявлений Airbnb и собирает такие данные, как название объекта, местоположение и цена из каждого объявления. Если элемент не найден, он помечается как N/A. После обработки полученные данные хранятся в DataFrame pandas и сохраняются в файле CSV с именем airbnb_listings.csv.
Чтобы запустить скрипт, выполните python3 airbnb_scraper.py в терминале или оболочке. Ваш CSV-файл должен выглядеть следующим образом:
property_name,location,price
"Brand bei Bludenz, Austria",343 kilometers away,"€ 2,047
night"
"Saint-Nabord, France",281 kilometers away,"€ 315
night"
"Kappl, Austria",362 kilometers away,"€ 1,090
night"
«Фрейзан, Франция», 394 километра, «181 евро
за ночь»
«Ланиц-Хассель-Таль, Германия», 239 километров, «185 евро
за ночь»
«Хогентаннен, Швейцария», 291 километр, «189 евро
за ночь»
…вывод опущен…
Улучшите Веб-скрейпинг с помощью прокси Bright Data
Сбор данных с веб-сайтов иногда может сопровождаться такими проблемами, как блокировка IP-адресов и геоблокировка. В этом случае проксиBright Data приходят на помощь, позволяя обойти эти препятствия и улучшить качество сбора данных.
После нескольких запусков предыдущего скрипта вы можете заметить, что перестали получать данные. Это может произойти, если Airbnb обнаружит ваш IP-адрес и заблокирует вам доступ к веб-сайту.
Чтобы смягчить связанные с этим проблемы, практичным подходом является использование прокси для сбора данных. Вот некоторые из преимуществ использования прокси для Веб-скрейпинга:
- обход IP-ограничений
- ротация IP-адресов
- Балансировка нагрузки обеспечивает распределение сетевого или прикладного трафика по многим ресурсам, предотвращая возникновение узких мест в отдельных компонентах и обеспечивая избыточность на случай сбоев.
Как интегрировать прокси Bright Data в ваш скрипт Python
Учитывая вышеупомянутые преимущества, становится понятно, почему кто-то может захотеть включить прокси Bright Data в скрипт Python. Хорошая новость заключается в том, что это легко сделать. Для этого нужно просто создать учетную запись Bright Data, настроить параметры прокси, а затем реализовать их в коде Python.
Для начала вам нужно создать учетную запись Bright Data. Для этого перейдите на веб-сайт Bright Data и выберите «Пробная версия», а затем следуйте инструкциям.
Войдите в свою учетную запись Bright Data и нажмите на значок кредитной карты в левой панели навигации, чтобы перейти в раздел «Биллинг». Здесь вам нужно ввести предпочтительный способ оплаты, чтобы активировать свою учетную запись:

Затем нажмите на значок булавки в левой панели навигации, чтобы перейти на страницу «Прокси и Скрейпинг-инфраструктура», а затем нажмите «Добавить» > «Резидентные прокси»:
Назовите свой прокси (например, residential_proxy1) и выберите опцию «Общий» в поле «Тип IP». Затем нажмите «Добавить»:
После создания резидентного прокси запишите параметры доступа, так как вам понадобятся эти данные в коде:

Чтобы использовать Резидентный прокси Bright Data, вам необходимо настроить сертификат для вашего браузера. Инструкции по установке сертификата вы найдете в этом руководстве Bright Data.
Создайте новый скрипт Python airbnb_scraping_proxy.py и добавьте следующий код:
from playwright.sync_api import sync_playwright
import pandas as pd
def run(playwright):
browser = playwright.chromium.launch()
context = browser.new_context()
# Настройка прокси
proxy_username='YOUR_BRIGHTDATA_PROXY_USERNAME'
proxy_password='YOUR_BRIGHTDATA_PROXY_PASSWORD'
proxy_host = 'YOUR_BRIGHTDATA_PROXY_HOST'
proxy_auth=f'{proxy_username}:{proxy_password}'
proxy_server = f'http://{proxy_auth}@{proxy_host}'
context = browser.new_context(proxy={
'server': proxy_server,
'username': proxy_username,
'password': proxy_password
})
page = context.new_page()
page.goto('https://www.airbnb.com/s/homes')
# Подождите, пока страница загрузится
page.wait_for_load_state("networkidle")
# Извлеките данные
results = page.eval_on_selector_all('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr', '''(listings) => {
return listings.map(listing => {
return {
property_name: listing.querySelector('div[data-testid="listing-card-title"]')?.innerText || 'N/A',
location: listing.querySelector('div[data-testid="listing-card-subtitle"]')?.innerText || 'N/A',
price: listing.querySelector('div._1jo4hgw')?.innerText || 'N/A'
}
})
}''')
df = pd.DataFrame(results)
df.to_csv('airbnb_listings_scraping_proxy.csv', index=False)
# Закрыть браузер
browser.close()
with sync_playwright() as playwright:
run(playwright)
Этот код использует библиотеку Playwright для запуска браузера Chromium с определенным прокси-сервером. Он переходит на главную страницу Airbnb, извлекает из списка объявлений такие данные, как названия объектов недвижимости, их местоположение и цены, а затем сохраняет эти данные в файл CSV с помощью pandas. После извлечения данных браузер закрывается.
Примечание: замените
proxy_username,proxy_passwordиproxy_hostна свои параметры доступа Bright Data.
Чтобы запустить скрипт, выполните python3 airbnb_scraping_proxy.py в терминале или оболочке. Извлеченные данные сохраняются в файле CSV с именем airbnb_listings_scraping_proxy.csv. Ваш файл CSV должен выглядеть следующим образом:
property_name,location,price
"Sithonia, Greece",Lagomandra,"$3,305
night"
"Apraos, Greece","1,080 kilometers away","$237
night"
«Магнисия, Греция», Милопотамос Паралимпик, «200 долларов
за ночь»
«Вурвуру, Греция», 861 километр, «357 долларов
за ночь»
«Ровис, Греция», «1019 километров», «1077 долларов
за ночь»
…вывод опущен…
Сбор данных с Airbnb с помощью Браузера для скрейпинга Bright Data
Процесс сбора данных можно сделать еще более эффективным с помощью Браузера для скрейпинга Bright Data Scraping Browser. Этот инструмент специально разработан для Веб-скрейпинга и предоставляет ряд преимуществ, включая автоматическую разблокировку, простое масштабирование и обход программного обеспечения для обнаружения ботов.
Перейдите на панель управления Bright Data и нажмите на значок булавки, чтобы перейти на страницу «Прокси и скрейпинг-инфраструктура»; затем нажмите «Добавить» > «Браузер для скрейпинга»:
Назовите его (например, scraping_browser) и нажмите «Добавить»:
Затем выберите «Параметры доступа » и запишите свое имя пользователя, хост и пароль — эти данные понадобятся позже в этом руководстве:
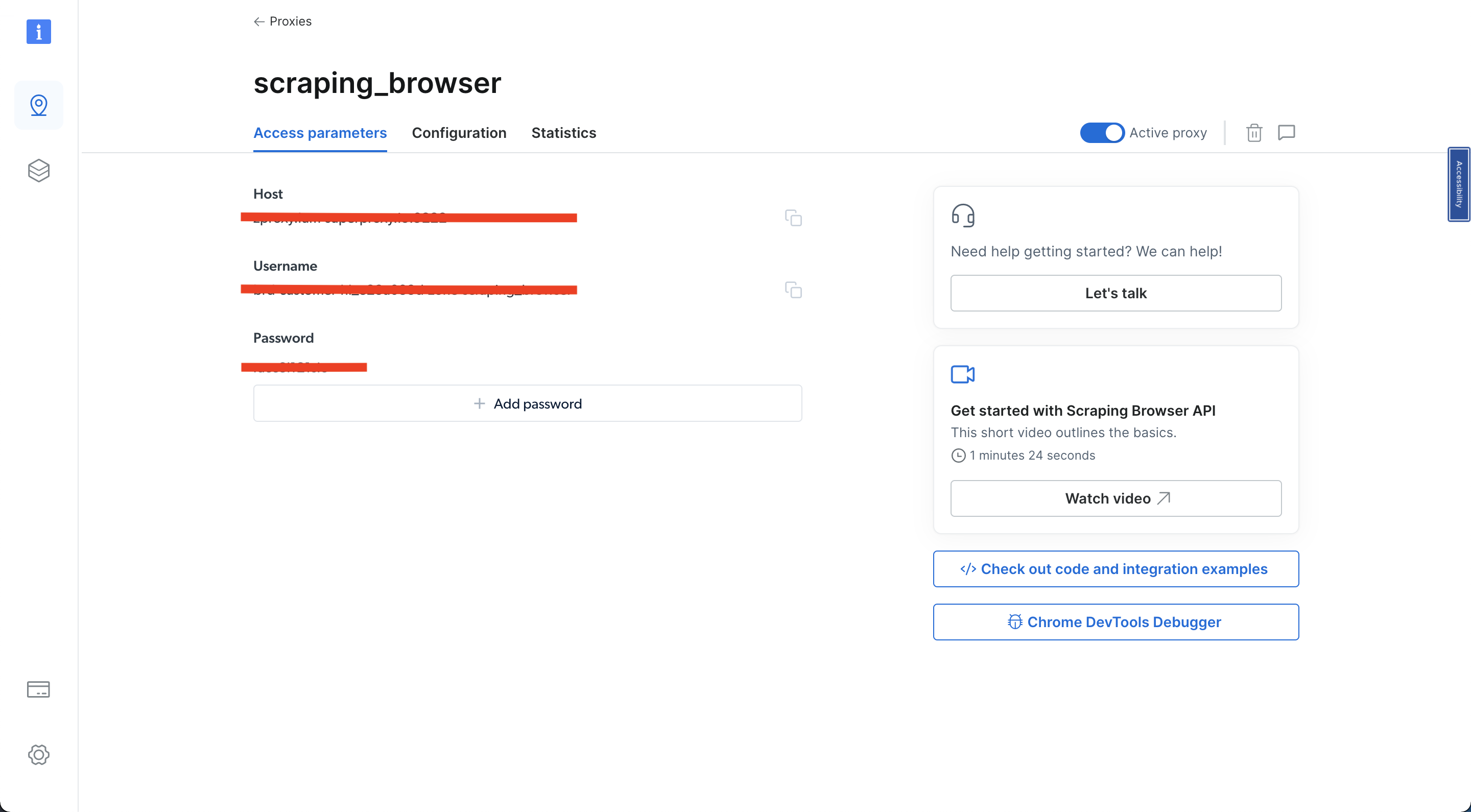
После выполнения этих шагов создайте новый скрипт Python с именем airbnb_scraping_brower.py и добавьте следующий код:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def scrape_airbnb():
async with async_playwright() as pw:
# Запустить новый браузер
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('подключено')
page = await browser.new_page()
# Перейти к URL Airbnb
await page.goto('https://www.airbnb.com/s/homes', timeout=120000)
print('готово, оценка')
# Получить весь HTML-контент
html_content = await page.evaluate('()=>document.documentElement.outerHTML')
# Разбор HTML с помощью Beautiful Soup
soup = BeautifulSoup(html_content, 'html.parser')
# Извлечение информации
results = []
listings = soup.select('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
for listing in listings:
result = {}
# Название объекта недвижимости
name_element = listing.select_one('div[data-testid="listing-card-title"]')
result['property_name'] = name_element.text if name_element else 'N/A'
# Местоположение
location_element = listing.select_one('div[data-testid="listing-card-subtitle"]')
result['location'] = location_element.text if location_element else 'N/A'
# Цена
price_element = listing.select_one('div._1jo4hgw')
result['price'] = price_element.text if price_element else 'N/A'
results.append(result)
# Закрыть браузер
await browser.close()
return results
# Запустить скрейпер и сохранить результаты в файл CSV
results = asyncio.run(scrape_airbnb())
df = pd.DataFrame(results)
df.to_csv('airbnb_listings_scraping_browser.csv', index=False)
Этот код использует прокси Bright Data для подключения к браузеру Chromium и сбора сведений о недвижимости (т. е. название, местоположение и цена) с сайта Airbnb. Полученные данные хранятся в списке, затем сохраняются в DataFrame и экспортируются в файл CSV с именем airbnb_listings_scraping_browser.csv.
Примечание: не забудьте заменить
имя пользователя,парольихостна свои параметры доступа Bright Data.
Запустите код из терминала или оболочки:
python3 airbnb_scraping_browser.py
Вы должны увидеть новый CSV-файл с именем airbnb_listings_scraping_browser.csv, созданный в вашем проекте. Файл должен выглядеть следующим образом:
property_name,location,price
"Benton Harbor, Michigan",Round Lake,"$514
night"
"Pleasant Prairie, Wisconsin",Lake Michigan,"$366
night"
"New Buffalo, Michigan",Lake Michigan,"$2,486
night"
"Фокс-Лейк, Иллинойс", Нипперсинк-Лейк, "199
долларов за ночь"
"Сейлем, Висконсин", Хукер-Лейк, "880
долларов за ночь"
...вывод опущен...
Теперь соберите некоторые данные, относящиеся к одному объявлению. Создайте новый скрипт Python, airbnb_scraping_single_listing.py, и добавьте следующий код:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def scrape_airbnb_listing():
async with async_playwright() as pw:
# Запустить новый браузер
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('подключено')
page = await browser.new_page()
# Перейти по URL-адресу Airbnb
await page.goto('https://www.airbnb.com/rooms/26300485', timeout=120000)
print('done, evaluating')
# Подождите, пока загрузится контент
await page.wait_for_selector('div.tq51prx.dir.dir-ltr h2')
# Получите весь HTML-контент
html_content = await page.evaluate('()=>document.documentElement.outerHTML')
# Разбор HTML с помощью Beautiful Soup
soup = BeautifulSoup(html_content, 'html.parser')
# Извлечение имени хоста
host_div = soup.select_one('div.tq51prx.dir.dir-ltr h2')
host_name = host_div.text.split("hosted by ")[-1] if host_div else 'N/A'
print(f'Имя хоста: {host_name}')
# Извлечение отзывов
reviews_span = soup.select_one('span._s65ijh7 button')
reviews = reviews_span.text.split(" ")[0] if reviews_span else 'N/A'
print(f'Отзывы: {reviews}')
# Закрыть браузер
await browser.close()
return {
'host_name': host_name,
'reviews': reviews,
}
# Запустить парсер и сохранить результаты в файл CSV
results = asyncio.run(scrape_airbnb_listing())
df = pd.DataFrame([results]) # results теперь является словарем
df.to_csv('scrape_airbnb_listing.csv', index=False)
В этом коде вы переходите к URL-адресу нужного объявления, извлекаете HTML-содержимое, выполняете парсинг с помощью Beautiful Soup, чтобы получить имя хозяина и количество отзывов, и, наконец, сохраняете извлеченные данные в файл CSV с помощью pandas.
Запустите код из терминала или оболочки:
python3 airbnb_scraping_single_listing.py
В вашем проекте должен появиться новый CSV-файл с именем scrape_airbnb_listing.csv. Содержимое этого файла должно выглядеть следующим образом:
host_name,reviews
Amelia,88
Весь код для этого урока доступен в этом репозитории GitHub.
Преимущества использования браузера для скрейпинга Bright Data
Есть несколько причин, по которым вам стоит выбрать Браузер для скрейпинга Bright Data вместо локальной версии Chromium. Вот некоторые из них:
- Автоматическое разблокирование: Браузер для скрейпинга Bright Data Scraping Browser автоматически обрабатывает CAPTCHA, заблокированные страницы и другие препятствия, которые веб-сайты используют для сдерживания скрейперов. Это значительно снижает вероятность блокировки вашего скрейпера.
- Простое масштабирование: решения Bright Data разработаны для простого масштабирования, что позволяет вам собирать данные с большого количества веб-страниц одновременно.
- Перехитрите программное обеспечение для обнаружения ботов: современные веб-сайты используют сложные системы обнаружения ботов. Браузер Bright Data Scraping Browser может успешно имитировать поведение человека, чтобы перехитрить эти алгоритмы обнаружения.
Кроме того, если ручной сбор данных или настройка скриптов кажется слишком трудоемким или сложным, отличным альтернативным решением станут настраиваемые наборы данных Bright Data. Они предлагают набор данных Airbnb, который включает информацию о недвижимости Airbnb, к которой вы можете получить доступ и проанализировать, не занимаясь сбором данных самостоятельно.
Чтобы просмотреть наборы данных, нажмите «Веб-данные» в левом меню навигации, затем выберите «Рынок наборов данных » и найдите Airbnb. Нажмите «Просмотреть набор данных». На этой странице вы можете применить фильтры и приобрести любые данные, которые вам нужны. Вы платите в зависимости от количества записей, которые хотите:
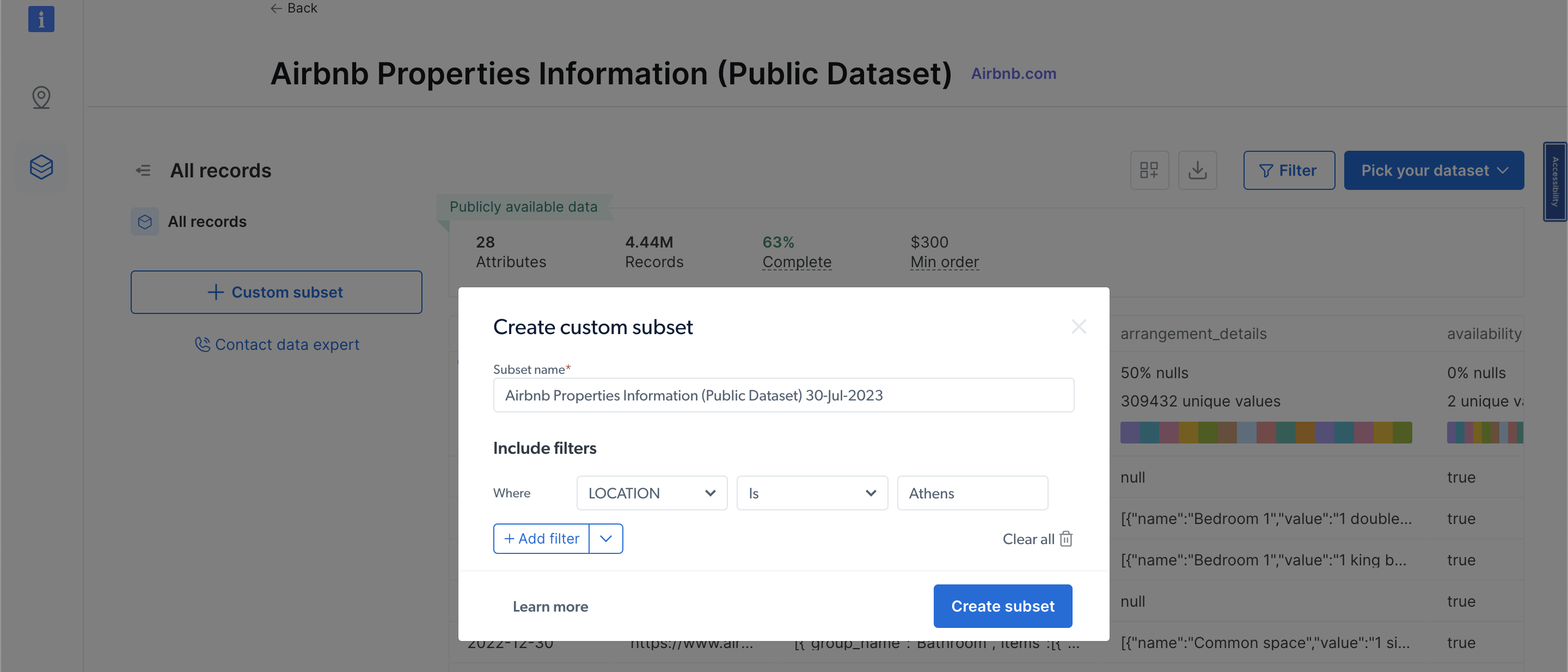
Заключение
В этом уроке вы узнали, как извлекать данные из списков Airbnb с помощью Python, и увидели, как инструменты Bright Data, такие как прокси и Браузер для скрейпинга, могут еще больше упростить эту работу.
Bright Data предлагает набор инструментов, которые помогут вам быстро и легко собирать данные с любого веб-сайта, а не только с Airbnb. Эти инструменты превращают сложные задачи Веб-скрейпинга в простые, экономя ваше время и усилия. Не уверены, какой продукт вам нужен? Поговорите с экспертами Bright Data по веб-данным, чтобы найти правильное решение для ваших потребностей в данных.
Хотите скрапировать другие веб-сайты? Продолжите чтение статей ниже:
Примечание: это руководство было тщательно протестировано нашей командой на момент написания, но поскольку веб-сайты часто обновляют свой код и структуру, некоторые шаги могут больше не работать как ожидалось.






