

В этом руководстве вы узнаете:
- Почему Gemini – отличное решение для веб-скрапинга на основе искусственного интеллекта
- Как использовать его для сканирования сайта на Python с помощью руководства
- Самое большое ограничение этого способа соскабливания веб-страниц и способы его преодоления
Давайте погрузимся!
Почему стоит использовать Gemini для веб-скрапинга?
Gemini – это семейство мультимодальных моделей ИИ, разработанных Google, которые могут анализировать и интерпретировать текст, изображения, аудио, видео и код. Использование Gemini для веб-скрапинга упрощает извлечение данных, автоматизируя интерпретацию и структурирование неструктурированного контента. Это устраняет необходимость в ручном труде, особенно когда речь идет о разборе данных.
Вот некоторые из наиболее распространенных вариантов использования Gemini для веб-скрапинга:
- Страницы, часто меняющие структуру: Gemini может работать с динамическими страницами, где макет или элементы данных часто меняются, как, например, на сайтах электронной коммерции, таких как Amazon.
- Страницы с большим количеством неструктурированных данных: Он отлично справляется с извлечением полезной информации из больших объемов неорганизованного текста.
- Страницы, для которых написание собственной логики парсинга затруднительно: Для страниц со сложной или непредсказуемой структурой Gemini может автоматизировать процесс, не требуя сложных правил парсинга.
Обычные сценарии использования Gemini для веб-скреппинга включают:
- RAG (Retrieval-Augmented Generation): Сочетание сбора данных в режиме реального времени для повышения эффективности ИИ. Для полного примера использования подобной технологии ИИ следуйте нашему руководству по созданию чатбота RAG на основе данных SERP.
- Скраппинг социальных сетей: Сбор структурированных данных с платформ с динамическим контентом.
- Агрегация контента: Сбор новостей, статей или сообщений в блогах из нескольких источников для создания сводок или аналитики.
Для получения дополнительной информации см. наше руководство по использованию искусственного интеллекта для веб-скрапинга.
Веб-скрапинг с Gemini на Python: Пошаговое руководство
В качестве целевого сайта в этом разделе мы будем использовать конкретную страницу товара из песочницы “Ecommerce Test Site to Learn Web Scraping“:
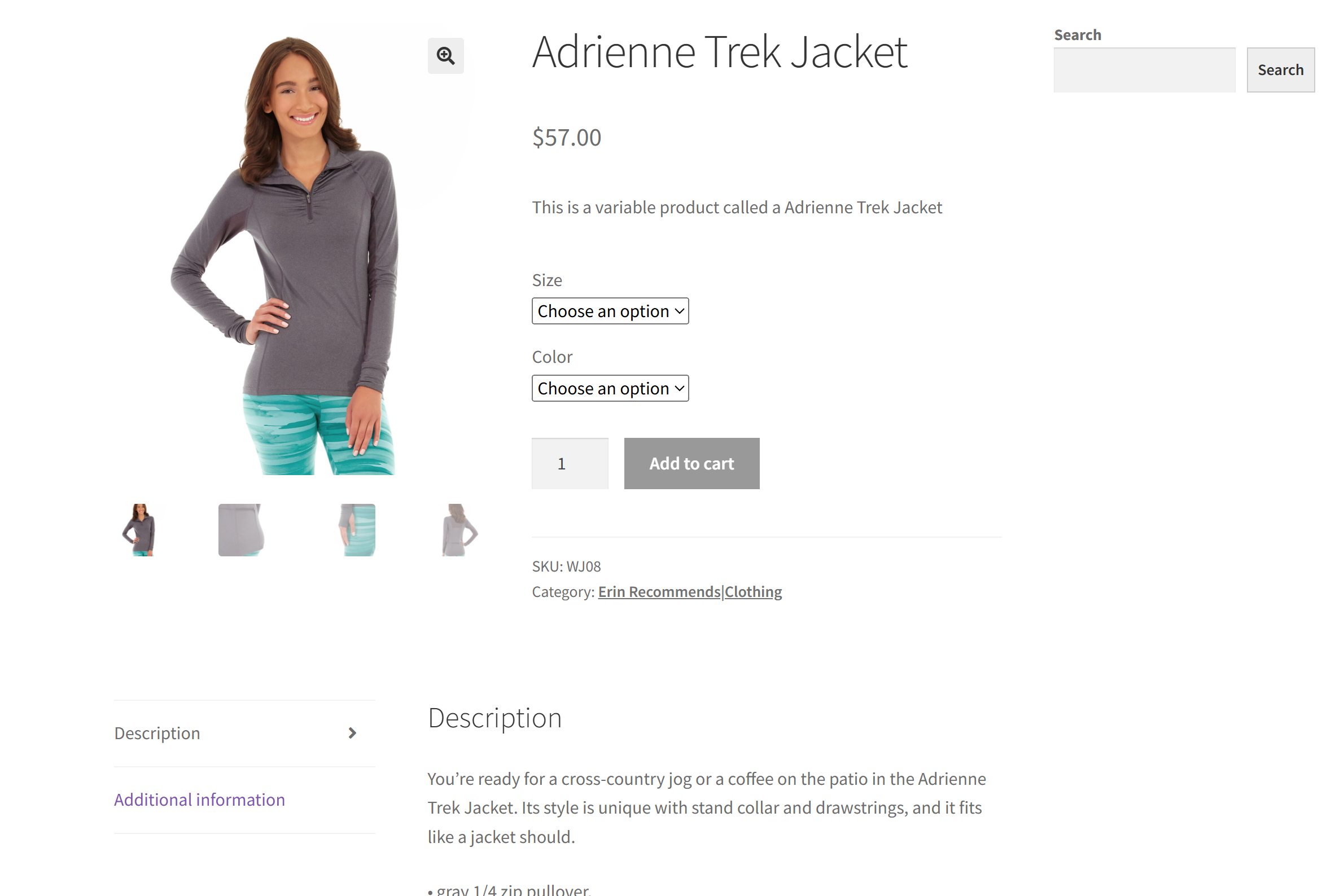
Это отличный пример, потому что большинство страниц товаров электронной коммерции отображают различные типы данных или имеют различную структуру. Именно это делает веб-скраппинг в электронной коммерции таким сложным, и именно здесь может помочь искусственный интеллект.
Цель нашего скрепера на базе Gemini – использовать искусственный интеллект для извлечения информации о продукте со страницы без написания логики ручного парсинга. Данные о товарах, полученные с помощью искусственного интеллекта, будут включать в себя:
- SKU
- Имя
- Изображения
- Цена
- Описание
- Размеры
- Цвета
- Категория
Следуйте приведенным ниже инструкциям, чтобы узнать, как выполнять веб-скраппинг с помощью Gemini!
Шаг №1: Настройка проекта
Прежде чем приступить к работе, убедитесь, что на вашем компьютере установлен Python 3. В противном случае загрузите его и следуйте указаниям мастера установки.
Теперь выполните следующую команду, чтобы создать папку для проекта скрапбукинга:
mkdir gemini-scrapergemini-scraper представляет собой папку проекта вашего веб-скрапера на базе Python Gemini-powered.
Перейдите к нему в терминале и инициализируйте виртуальную среду внутри него:
cd gemini-scraper
python -m venv venvЗагрузите папку с проектом в вашу любимую Python IDE. Visual Studio Code с расширением Python или PyCharm Community Edition – два отличных варианта.
Создайте файл scraper.py в папке проекта, который теперь должен содержать такую структуру файлов:

В настоящее время scraper.py – это пустой Python-скрипт, но вскоре он будет содержать необходимую логику скрапинга LLM.
В терминале IDE активируйте виртуальную среду. В Linux или macOS выполните эту команду:
./venv/bin/activateАналогично, в Windows выполните команду:
venv/Scripts/activateЗамечательно! Теперь у вас есть среда Python для веб-скрапинга с помощью Gemini.
Шаг №2: Настройка Gemini
Gemini предоставляет API, который можно вызвать с помощью любого HTTP-клиента, включая запросы. Тем не менее, лучше всего подключаться через официальный Google AI Python SDK для API Gemini. Чтобы установить его, выполните следующую команду в активированной виртуальной среде:
pip install google-generativeaiЗатем импортируйте его в файл scraper.py:
import google.generativeai as genaiЧтобы SDK работал, вам нужен ключ API Gemini. Если вы еще не получили свой API-ключ
следуйте официальной документации Google. В частности, войдите в свой аккаунт Google и присоединитесь к Google AI Studio. Перейдите на страницу“Получить ключ API“, и вы увидите следующее модальное окно:

Нажмите кнопку “Получить ключ API”, после чего появится следующий раздел:

Теперь нажмите “Создать ключ API”, чтобы сгенерировать ключ API Gemini:

Скопируйте ключ и храните его в надежном месте.
Примечание: для данного примера достаточно бесплатного уровня Gemini. Платный уровень необходим только в том случае, если вам нужны более высокие ограничения по скорости или вы хотите убедиться, что ваши подсказки и ответы не будут использованы для улучшения продуктов Google. Дополнительные сведения см. на странице биллинга Gemini.
Чтобы использовать ключ API Gemini в Python, вы можете задать его в качестве переменной окружения:
export GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>Или, как вариант, сохраните его непосредственно в вашем Python-скрипте в виде константы:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"И передайте его в genai в виде конфигурации, как показано ниже:
genai.configure(api_key=GEMINI_API_KEY)В данном случае мы воспользуемся вторым способом. Однако имейте в виду, что оба метода работают, поскольку google-generativeai автоматически пытается считать API-ключ из GEMINI_API_KEY, если вы не передали его вручную.
Потрясающе! Теперь вы можете использовать Gemini SDK для выполнения API-запросов к LLM на языке Python.
Шаг № 3: Получите HTML целевой страницы
Чтобы подключиться к целевому серверу и получить HTML-файлы его веб-страниц, мы будем использовать Requests – самый популярный HTTP-клиент на Python. В активированной виртуальной среде установите его с помощью:
pip install requestsЗатем импортируйте его в файл scraper.py:
import requestsС его помощью можно отправить GET-запрос на целевую страницу и получить ее HTML-документ:
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)В response.content теперь будет содержаться исходный HTML страницы. Пора разобрать его и подготовиться к извлечению данных из него!
Шаг #4: Преобразование HTML в Markdown
Если вы сравните другие технологии AI-скреппинга, например Crawl4AI, то заметите, что они позволяют использовать CSS-селекторы для выделения HTML-элементов. Затем эти библиотеки преобразуют HTML выбранных элементов в текст в формате Markdown. И наконец, они обрабатывают этот текст с помощью LLM.
Вы когда-нибудь задумывались почему? Ну, на то есть две ключевые причины такого поведения:
- Чтобы уменьшить количество токенов, отправляемых ИИ, что поможет вам сэкономить деньги (ведь не все провайдеры LLM бесплатны, как Gemini).
- Чтобы ускорить обработку данных ИИ, поскольку меньшее количество исходных данных означает меньшие вычислительные затраты и более быстрые ответы.
Полное описание смотрите в нашем руководстве по веб-скраппингу с помощью CrawlAI и DeepSeek.
Давайте попробуем воспроизвести эту логику и посмотрим, имеет ли она смысл. Начните с осмотра целевой страницы, открыв ее в окне инкогнито (чтобы открыть новую сессию). Затем щелкните правой кнопкой мыши в любом месте страницы и выберите опцию “Осмотреть”.
Изучите структуру страницы. Вы увидите, что все необходимые данные содержатся в HTML-элементе, обозначенном CSS-селектором #main:

Вы можете передать Gemini весь необработанный HTML, но это приведет к появлению большого количества ненужной информации (например, заголовков и нижних колонтитулов). Вместо этого, передавая только содержимое #main, вы уменьшаете шум и предотвращаете галлюцинации ИИ.
Чтобы выбрать только #main, вам понадобится инструмент для разбора HTML на Python, например Beautiful Soup. Поэтому установите его с помощью:
pip install beautifulsoup4Если вы не знакомы с его синтаксисом, ознакомьтесь с нашим руководством по веб-скрапингу Beautiful Soup.
Теперь импортируйте его в файл scraper.py:
from bs4 import BeautifulSoupИспользуйте Beautiful Soup, чтобы разобрать необработанный HTML, полученный через Requests, выбрать элемент #main и извлечь его HTML:
# Parse the HTML with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Если вы напечатаете main_html, то увидите что-то вроде этого:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
</main>Теперь проверьте, сколько токенов сгенерировал бы этот HTML, и оцените стоимость, если бы вы использовали платный уровень Gemini. Для этого воспользуйтесь таким инструментом, как Token Calculator:
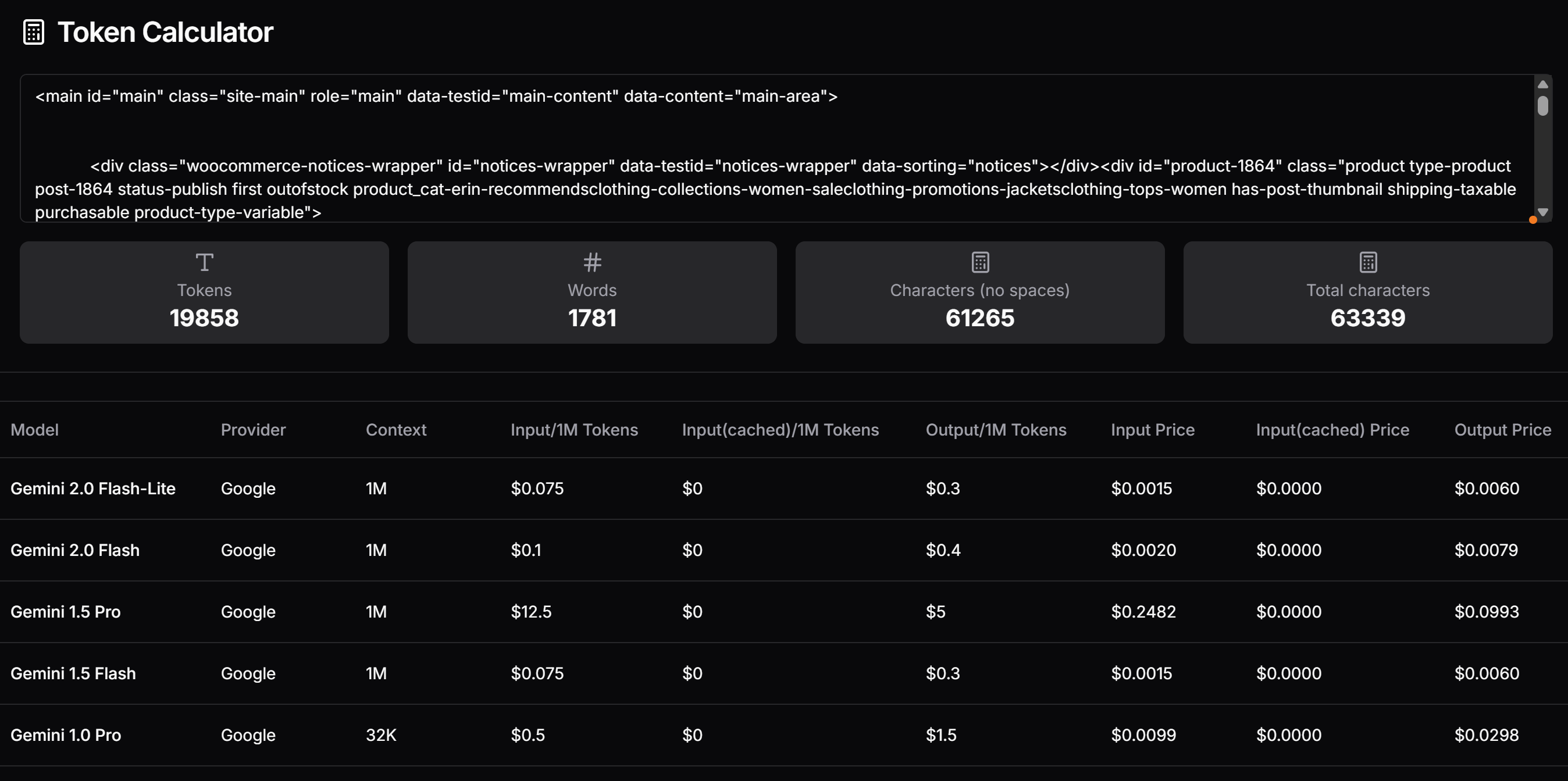
Как вы можете видеть, такой подход означает около 20 000 токенов, что обходится примерно в $0,25 за запрос для Gemini 1.5 Pro. Для крупномасштабного проекта по скраппингу это может стать проблемой!
Попробуйте преобразовать извлеченный HTML в Markdown – аналогично тому, как это делает Crawl4AI. Сначала установите библиотеку преобразования HTML в Markdown, например markdownify:
pip install markdownifyИмпортируйте markdownify в scraper.py:
from markdownify import markdownifyЗатем используйте markdownify, чтобы преобразовать извлеченный HTML в Markdown:
main_markdown = markdownify(main_html)Полученная строка main_markdown содержит что-то вроде этого:
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back.jpg)
Adrienne Trek Jacket
====================
$57.00
This is a variable product called a Adrienne Trek Jacket
| | |
| --- | --- |
| Size | Choose an optionXSSMLXL |
| Color | Choose an optionGrayOrangePurple[Clear](#) |
Adrienne Trek Jacket quantity
Add to cart
SKU: WJ08
Category: [Erin Recommends|Clothing](https://www.scrapingcourse.com/ecommerce/product-category/clothing/women/tops-women/jacketsclothing-tops-women/promotions-jacketsclothing-tops-women/women-saleclothing-promotions-jacketsclothing-tops-women/collections-women-saleclothing-promotions-jacketsclothing-tops-women/erin-recommendsclothing-collections-women-saleclothing-promotions-jacketsclothing-tops-women/)
* [Description](#tab-description)
* [Additional information](#tab-additional_information)
Description
-----------
You’re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.
* gray 1/4 zip pullover.
* Comfortable, relaxed fit.
* Front zip for venting.
* Spacious, kangaroo pockets.
* 27″ body length.
* 95% Organic Cotton / 5% Spandex.
Additional information
----------------------
| | |
| --- | --- |
| Size | XS, S, M, L, XL |
| Color | Gray, Orange, Purple |Эта версия исходных данных в формате Markdown намного меньше, чем оригинальный HTML #main, но при этом содержит все ключевые данные, необходимые для скраппинга.
Снова используйте Token Calculator, чтобы проверить, сколько токенов будет потреблять новый вход:
Мы сократили 19 858 жетонов до 765 – на 95 %!
Шаг #5: Используйте LLM для извлечения данных
Чтобы выполнить веб-скраппинг с помощью Gemini, выполните следующие действия:
- Напишите хорошо структурированный запрос для извлечения нужных данных из исходного текста в формате Markdown. Обязательно определите атрибуты, которыми должен обладать результат.
- Отправьте запрос к модели Gemini LLM с помощью
genai, настроив его так, чтобы запрос возвращал данные в формате JSON. - Разберите полученный JSON.
Реализуйте описанную выше логику с помощью следующих строк кода:
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)Переменная prompt указывает Gemini на извлечение структурированных данных из содержимого main_markdown. Затем genai.GenerativeModel() устанавливает модель "gemini-2.0-flash-lite" для выполнения LLM-запроса. Наконец, необработанная строка ответа в формате JSON преобразуется в пригодный для использования словарь Python с помощью json.loads().
Обратите внимание на конфигурацию "application/json", чтобы указать Gemini возвращать данные в формате JSON.
Не забудьте импортировать json из стандартной библиотеки Python:
import jsonТеперь, когда у вас есть отсканированные данные в словаре product_data, вы можете получить доступ к их полям для дальнейшей обработки данных, как показано в примере ниже:
price = product_data["price"]
price_eur = price * USD_EUR
# ...Фантастика! Вы только что использовали Gemini для веб-скрапинга. Осталось только экспортировать собранные данные.
Шаг № 6: Экспорт собранных данных
В настоящее время отсканированные данные хранятся в словаре Python. Чтобы экспортировать их в JSON-файл, используйте следующий код:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)В результате будет создан файл product.json, содержащий отсканированные данные в формате JSON.
Поздравляем! Работа над веб-скребком на базе Gemini завершена.
Шаг №7: Соберите все вместе
Ниже приведен полный код вашего скрипта скрапинга Gemini:
import google.generativeai as genai
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
# Your Gemini API key
GEMINI_API_KEY = "<YOUR_GEMINI_API_KEY>"
# Set up the Google Gemini API
genai.configure(api_key=GEMINI_API_KEY)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Запустите скрипт с помощью кнопки :
python scraper.pyПосле выполнения в папке проекта появится файл product.json. Откройте его, и вы увидите структурированные данные, как показано ниже:
{
"sku": "WJ08",
"name": "Adrienne Trek Jacket",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back-416x516.jpg"
],
"price": "$57.00",
"description": "Youu2019re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.nnu2022 gray 1/4 zip pullover. nu2022 Comfortable, relaxed fit. nu2022 Front zip for venting. nu2022 Spacious, kangaroo pockets. nu2022 27u2033 body length. nu2022 95% Organic Cotton / 5% Spandex.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Gray",
"Orange",
"Purple"
],
"category": "Erin Recommends|Clothing"
}И вуаля! Вы начали с неструктурированных данных на HTML-странице, а теперь получили их в структурированном JSON-файле благодаря веб-скреппингу на базе Gemini.
Следующие шаги
Чтобы поднять ваш скребок Gemini-мотор на новый уровень, рассмотрите следующие усовершенствования:
- Сделайте его многоразовым: Измените сценарий так, чтобы он принимал приглашение и целевой URL в качестве аргументов командной строки. Это сделает его универсальным и адаптируемым к различным сценариям использования.
- Реализуйте веб-скраппинг: Расширьте скрепер для работы с многостраничными веб-сайтами, добавив логику для сползания и пагинации.
- Защитите учетные данные API: Храните свой ключ API Gemini в файле
.envи используйтеpython-dotenvдля его загрузки. Это предотвратит раскрытие вашего API-ключа в коде.
Преодоление основных ограничений этого подхода к веб-скрапингу
В чем заключается самое большое ограничение этого подхода к веб-скреппингу? HTTP-запрос, выполняемый запросами!
Конечно, в приведенном выше примере все сработало идеально, но это потому, что целевой сайт – всего лишь площадка для веб-скреппинга. На самом деле компании и владельцы сайтов знают, насколько ценными являются их данные, даже если они находятся в открытом доступе. Чтобы защитить их, они применяют меры по борьбе со скрапингом, которые могут легко заблокировать ваши автоматические HTTP-запросы.
Кроме того, описанный выше подход не сработает на динамических сайтах, которые полагаются на JavaScript для рендеринга или асинхронного получения данных. Таким образом, сайтам даже не нужны продвинутые антискрейперские фреймворки, чтобы остановить ваш скрепер. Достаточно использовать загрузку контента на основе JavaScript.
Решение всех этих проблем? Веб-интерфейс для разблокировки!
Web Unlocker API – это конечная точка HTTP, которую можно вызвать из любого HTTP-клиента. Ключевое отличие? Он возвращает полностью разблокированный HTML любого URL-адреса, который вы ему передаете, минуя все блоки защиты от скаппинга. Неважно, сколько защит имеет целевой сайт, простой запрос к Web Unlocker позволит вам получить HTML страницы.
Чтобы начать работу с этим инструментом и получить свой API-ключ, следуйте официальной документации Web Unlocker. Затем замените существующий код запроса из “Шага № 3” на следующие строки:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)И вот так – больше никаких блоков, никаких ограничений! Теперь вы можете скрести веб с помощью Gemini, не беспокоясь о том, что вас остановят.
Заключение
В этой статье вы узнали, как использовать Gemini в сочетании с Requests и другими инструментами для создания скрепера на основе искусственного интеллекта. Одной из основных проблем при веб-скреппинге является риск быть заблокированным, но эта проблема была решена с помощью API Web Unlocker от Bright Data.
Как объясняется здесь, комбинируя Gemini и Web Unlocker API, вы можете извлекать данные с любого сайта без необходимости использования собственной логики парсинга. Это лишь один из многих сценариев, которые поддерживают продукты и услуги Bright Data, помогая вам реализовать эффективный веб-скрепинг на основе искусственного интеллекта.
Ознакомьтесь с другими нашими инструментами для веб-скреппинга:
- Услуги прокси: Четыре различных типа прокси-серверов для обхода ограничений по местоположению, включая 150 миллионов IP-адресов жителей.
- API для веб-скреперов: Специальные конечные точки для извлечения свежих структурированных веб-данных из более чем 100 популярных доменов.
- SERP API: API для обработки всех текущих операций по разблокировке SERP и извлечению одной страницы
- Браузер для скраппинга: Браузер, совместимый с Puppeteer, Selenium и Playwright, со встроенными функциями разблокировки
Зарегистрируйтесь на сайте Bright Data и протестируйте наши прокси-сервисы и продукты для скрапбукинга бесплатно!




