

В этом руководстве вы узнаете:
- Что такое Gospider и как он работает
- Какие функции он предлагает
- Как использовать его для веб-ползания
- Как интегрировать его с Colly для веб-скреппинга
- Его основные ограничения и способы их обхода
Давайте погрузимся!
Что такое Gospider?
Gospider – это быстрый и эффективный CLI-инструмент для сканирования веб-сайтов, написанный на языке Go. Он создан для параллельного сканирования веб-сайтов и извлечения URL-адресов, обрабатывая несколько запросов и доменов одновременно. Кроме того, он уважает robots.txt и может обнаруживать ссылки даже в файлах JavaScript.
Gospider предлагает несколько флагов настройки, позволяющих контролировать глубину охвата, задержки запросов и многое другое. Он также поддерживает интеграцию с прокси-серверами, а также различные другие опции для большего контроля над процессом переползания.
Что делает Gospider уникальным средством для веб-ползания?
Чтобы лучше понять, почему Gospider особенно подходит для веб-краулинга, давайте подробно рассмотрим его возможности и изучим поддерживаемые флаги.
Характеристики
Ниже перечислены основные возможности Gospider в области веб-ползания:
- Быстрый просмотр веб-сайтов: Эффективный просмотр отдельных веб-сайтов на высокой скорости.
- Параллельное ползание: Одновременный просмотр нескольких сайтов для ускорения сбора данных.
- Парсинг
sitemap.xml: Автоматически обрабатывает файлы sitemap для более эффективного наполнения. - Парсинг
robots.txt: Соблюдает директивыrobots.txtдля этичного ползания. - Разбор ссылок JavaScript: Извлекает ссылки из файлов JavaScript.
- Настраиваемые параметры ползания: Настройте глубину просмотра, параллельность, задержку, тайм-аут и многое другое с помощью гибких флагов.
- Рандомизация
пользовательских агентов: Рандомизация между мобильными и веб-агентами для более реалистичных запросов. Определите лучшийUser-Agentдля просмотра веб-страниц. - Настройка файлов cookie и заголовков: Позволяет настраивать куки и HTTP-заголовки.
- Поиск ссылок: Определяет URL-адреса и другие ресурсы на сайте.
- Поиск ведер AWS S3: Обнаружение ведер AWS S3 из источников ответа.
- Найти поддомены: Обнаружение поддоменов из источников ответа.
- Сторонние источники: Извлекает URL-адреса из таких сервисов, как Wayback Machine, Common Crawl, VirusTotal и Alien Vault.
- Удобное форматирование результатов: Выводит результаты в форматах, удобных для
поискаи анализа. - Поддержка Burp Suite: Интеграция с Burp Suite для более удобного тестирования и наполнения.
- Расширенная фильтрация: Черные и белые списки URL-адресов, включая фильтрацию на уровне домена.
- Поддержка поддоменов: Включает поддомены в обходы как целевого сайта, так и сторонних источников.
- Режимы отладки и подробной информации: Включает отладку и подробное протоколирование для облегчения поиска и устранения неисправностей.
Параметры командной строки
Вот как выглядит типовая команда Gospider:
gospider [flags]В частности, поддерживаются следующие флаги:
-s, --site: Сайт для просмотра.-S, --sites: Список сайтов, которые нужно просмотреть.-p, --proxy: URL-адрес прокси-сервера.-o, --output: Папка для вывода.-u, --user-agent: Используемый агент пользователя (например,web,mobiили пользовательский агент).--cookie: Куки для использования (например,testA=a; testB=b).-H, --header: Использовать заголовок (заголовки) (вы можете повторить флаг несколько раз для нескольких заголовков).строка --burp: Загрузка заголовков и файлов cookie из необработанного HTTP-запроса Burp Suite.-Черный список: Черный список URL Regex.--whitelist: Белый список URL Regex.--whitelist-domain: Домен белого списка.-t, --threads: Количество потоков для параллельной работы (по умолчанию:1).-c, --concurrent: Максимальное количество одновременных запросов для совпадающих доменов (по умолчанию:5).-d, --depth: Максимальная глубина рекурсии для URL-адресов (для бесконечной рекурсии установлено значение0, по умолчанию:1).-k, --delay int: Задержка между запросами (в секундах).-K, --random-delay int: Дополнительная рандомизированная задержка перед выполнением запросов (в секундах).-m, --timeout int: Таймаут запроса (в секундах, по умолчанию:10).-B, --base: Отключить все и использовать только HTML-контент.--js: Включить поиск ссылок в файлах JavaScript (по умолчанию:true).--subs: Включить поддомены.--sitemap: Ползать поsitemap.xml.--robots: Ползать по файлуrobots.txt(по умолчанию:true).-a, --other-source: Поиск URL-адресов из сторонних источников, таких как Archive.org, CommonCrawl, VirusTotal, AlienVault.-w, --include-subs: Включить поддомены, полученные из сторонних источников (по умолчанию: только основной домен).-r, --include-other-source: Включить URL-адреса из сторонних источников и продолжать их просматривать.--debug: Включить режим отладки.--json: Включить вывод JSON.-v, --verbose: Включить вывод подробной информации.-l, --length: Показать длину URL-адреса.-L, --filter-length: Фильтровать URL по длине.-R, --raw: показать необработанный вывод.-q, --quiet: Подавляет весь вывод и показывает только URL.--no-redirect: отключить перенаправления.--version: Проверьте версию.-h, --help: Показать справку.
Веб-ползание с помощью Gospider: Пошаговое руководство
В этом разделе вы узнаете, как использовать Gospider для перебора ссылок с многостраничного сайта. В частности, целевым сайтом будет Books to Scrape:

На сайте представлен список товаров на 50 страницах. У каждой записи о продукте на этих страницах есть своя собственная страница продукта. Ниже описаны шаги, которые помогут вам с помощью Gospider получить все эти URL-адреса страниц товаров!
Необходимые условия и настройка проекта
Прежде чем приступить к работе, убедитесь, что у вас есть все необходимое:
- На вашем компьютере установлена программа Go: Если вы еще не установили Go, загрузите ее с официального сайта и следуйте инструкциям по установке.
- IDE для работы с Go: Рекомендуется использовать Visual Studio Code с расширением Go.
Чтобы убедиться, что Go установлен, выполните команду:
go versionЕсли Go установлен правильно, вы должны увидеть вывод, похожий на этот (в Windows):
go version go1.24.1 windows/amd64Отлично! Go настроен и готов к работе.
Создайте новую папку проекта и перейдите к ней в терминале:
mkdir gospider-project
cd gospider-project Теперь вы готовы установить Gospider и использовать его для просмотра веб-страниц!
Шаг #1: Установите Gospider
Выполните следующую команду go install, чтобы скомпилировать и установить Gospider глобально:
go install github.com/jaeles-project/gospider@latestПосле установки убедитесь, что Gospider установлен, запустив программу:
gospider -hПри этом должны быть выведены инструкции по использованию Gospider, как показано ниже:
Fast web spider written in Go - v1.1.6 by @thebl4ckturtle & @j3ssiejjj
Usage:
gospider [flags]
Flags:
-s, --site string Site to crawl
-S, --sites string Site list to crawl
-p, --proxy string Proxy (Ex: http://127.0.0.1:8080)
-o, --output string Output folder
-u, --user-agent string User Agent to use
web: random web user-agent
mobi: random mobile user-agent
or you can set your special user-agent (default "web")
--cookie string Cookie to use (testA=a; testB=b)
-H, --header stringArray Header to use (Use multiple flag to set multiple header)
--burp string Load headers and cookie from burp raw http request
--blacklist string Blacklist URL Regex
--whitelist string Whitelist URL Regex
--whitelist-domain string Whitelist Domain
-L, --filter-length string Turn on length filter
-t, --threads int Number of threads (Run sites in parallel) (default 1)
-c, --concurrent int The number of the maximum allowed concurrent requests of the matching domains (default 5)
-d, --depth int MaxDepth limits the recursion depth of visited URLs. (Set it to 0 for infinite recursion) (default 1)
-k, --delay int Delay is the duration to wait before creating a new request to the matching domains (second)
-K, --random-delay int RandomDelay is the extra randomized duration to wait added to Delay before creating a new request (second)
-m, --timeout int Request timeout (second) (default 10)
-B, --base Disable all and only use HTML content
--js Enable linkfinder in javascript file (default true)
--sitemap Try to crawl sitemap.xml
--robots Try to crawl robots.txt (default true)
-a, --other-source Find URLs from 3rd party (Archive.org, CommonCrawl.org, VirusTotal.com, AlienVault.com)
-w, --include-subs Include subdomains crawled from 3rd party. Default is main domain
-r, --include-other-source Also include other-source's urls (still crawl and request)
--subs Include subdomains
--debug Turn on debug mode
--json Enable JSON output
-v, --verbose Turn on verbose
-q, --quiet Suppress all the output and only show URL
--no-redirect Disable redirect
--version Check version
-l, --length Turn on length
-R, --raw Enable raw output
-h, --help help for gospiderПотрясающе! Gospider был установлен, и теперь вы можете использовать его для сканирования одного или нескольких сайтов.
Шаг № 2: Перейдите по URL-адресам на целевой странице
Чтобы просмотреть все ссылки на целевой странице, выполните следующую команду:
gospider -s "https://books.toscrape.com/" -o output -d 1Здесь приведена разбивка используемых флагов Gospider:
-s "https://books.toscrape.com/": Указывает целевой URL-адрес.-o output: Сохраняет результаты расследования в папкеoutput.-d 1: Устанавливает глубину поиска1, что означает, что Gospider будет находить только URL-адреса на текущей странице. Другими словами, он не будет переходить по найденным URL для более глубокого обнаружения ссылок.
В результате выполнения приведенной выше команды будет получена следующая структура:
gospider-project/
└── output/
└── books_toscrape_comОткройте файл books_toscrape_com в папке output, и вы увидите результат, похожий на этот:
[url] - [code-200] - https://books.toscrape.com/
[href] - https://books.toscrape.com/static/oscar/favicon.ico
# omitted for brevity...
[href] - https://books.toscrape.com/catalogue/page-2.html
[javascript] - http://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js
# omitted for brevity...
[javascript] - https://books.toscrape.com/static/oscar/js/bootstrap-datetimepicker/locales/bootstrap-datetimepicker.all.js
[url] - [code-200] - http://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js
# omitted for brevity...
[linkfinder] - [from: https://books.toscrape.com/static/oscar/js/bootstrap-datetimepicker/locales/bootstrap-datetimepicker.all.js] - dd/mm/yyyy
# omitted for brevity...
[url] - [code-200] - https://books.toscrape.com/static/oscar/js/bootstrap-datetimepicker/bootstrap-datetimepicker.jsСгенерированный файл содержит различные типы обнаруженных ссылок:
[url]: Просмотренные страницы/ресурсы.[href]: Все ссылки<a href>, найденные на странице.[javascript]: URL-адреса файлов JavaScript.[linkfinder]: Извлекает ссылки, встроенные в код JavaScript.
Шаг № 3: Пройдитесь по всему сайту
Из приведенного выше результата видно, что Gospider остановился на первой странице пагинации. Он обнаружил ссылку на вторую страницу, но не перешел на нее.
Вы можете убедиться в этом, поскольку файл books_toscrape_com содержит:
[href] - https://books.toscrape.com/catalogue/page-2.htmlТег [href] указывает на то, что ссылка была обнаружена. Однако, поскольку нет соответствующей записи [url] с тем же URL, ссылка была найдена, но не посещена.
Если вы посмотрите на целевую страницу, то увидите, что указанный выше URL соответствует второй странице пагинации:

Чтобы просмотреть весь сайт, необходимо перейти по всем ссылкам пагинации. Как показано на изображении выше, целевой сайт содержит 50 страниц с товарами (обратите внимание на текст “Страница 1 из 50”). Установите глубину Gospider на 50, чтобы обеспечить доступ к каждой странице.
Поскольку в процессе работы будет просмотрено большое количество страниц, нелишним будет увеличить уровень параллелизма (т. е. количество одновременных запросов). По умолчанию Gospider использует уровень параллелизма 5, но увеличение его до 10 ускорит выполнение.
Последняя команда для просмотра всех страниц с товарами:
gospider -s "https://books.toscrape.com/" -o output -d 50 -c 10На этот раз Gospider будет выполняться дольше и выдаст тысячи URL-адресов. Теперь в результатах будут такие записи, как:
[url] - [code-200] - https://books.toscrape.com/
[href] - https://books.toscrape.com/static/oscar/favicon.ico
[href] - https://books.toscrape.com/static/oscar/css/styles.css
# omitted for brevity...
[href] - https://books.toscrape.com/catalogue/page-50.html
[url] - [code-200] - https://books.toscrape.com/catalogue/page-50.htmlКлючевой деталью, которую необходимо проверить в выводе, является наличие URL последней страницы пагинации:
[url] - [code-200] - https://books.toscrape.com/catalogue/page-50.htmlЗамечательно! Это подтверждает, что Gospider успешно выполнил все ссылки пагинации и просмотрел весь каталог товаров, как и предполагалось.
Шаг № 4: Получите только страницу продукта
Всего за несколько секунд Gospider собрал все URL-адреса со всего сайта. На этом можно было бы закончить это руководство, но давайте сделаем еще один шаг вперед.
А если вам нужно извлечь только URL-адреса страниц товаров? Чтобы понять, как структурированы эти URL-адреса, изучите элемент продукта на целевой странице:

Из этого обзора вы можете заметить, что URL-адреса страниц товаров следуют этому формату:
https://books.toscrape.com/catalogue/<product_slug>/index.htmlЧтобы отфильтровать только страницы товаров из необработанных URL-адресов, можно использовать пользовательский скрипт Go.
Сначала создайте модуль Go в каталоге проекта Gospider:
go mod init crawlerЗатем создайте папку crawler в каталоге проекта и добавьте в нее файл crawler.go. Затем откройте папку проекта в вашей IDE. Теперь структура папок должна выглядеть следующим образом:
gospider-project/
├── crawler/
│ └── crawler.go
└── output/
└── books_toscrape_comСценарий crawler.go должен:
- Запустите команду Gospider из чистого состояния.
- Считывание всех URL из выходного файла.
- Фильтруйте только URL-адреса страниц товаров, используя шаблон regex.
- Экспортируйте отфильтрованные URL-адреса продуктов в файл .txt.
Ниже приведен код Go для достижения этой цели:
package main
import (
"bufio"
"fmt"
"os"
"os/exec"
"regexp"
"slices"
"path/filepath"
)
func main() {
// Delete the output folder if it exists to start with a clean run
outputDir := "output"
os.RemoveAll(outputDir)
// Create the Gospider CLI command to crawl the "books.toscrape.com" site
fmt.Println("Running Gospider...")
cmd := exec.Command("gospider", "-s", "https://books.toscrape.com/", "-o", outputDir, "-d", "50", "-c", "10")
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// Run the Gospider command and wait for it to finish
cmd.Run()
fmt.Println("Gospider finished")
// Open the generated output file that contains the crawled URLs
fmt.Println("nReading the Gospider output file...")
inputFile := filepath.Join(outputDir, "books_toscrape_com")
file, _ := os.Open(inputFile)
defer file.Close()
// Extract product page URLs from the file using a regular expression
// to filter out the URLs that point to individual product pages
urlRegex := regexp.MustCompile(`(https://books.toscrape.com/catalogue/[^/]+/index.html)`)
var productURLs []string
// Read each line of the file and check for matching URLs
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := scanner.Text()
// Extract all URLs from the line
matches := urlRegex.FindAllString(line, -1)
for _, url := range matches {
// Ensure that the URL has not been added already to avoid duplicates
if !slices.Contains(productURLs, url) {
productURLs = append(productURLs, url)
}
}
}
fmt.Printf("%d product page URLs foundn", len(productURLs))
// Export the product page URLs to a new file
fmt.Println("nExporting filtered product page URLs...")
outputFile := "product_urls.txt"
out, _ := os.Create(outputFile)
defer out.Close()
writer := bufio.NewWriter(out)
for _, url := range productURLs {
_, _ = writer.WriteString(url + "n")
}
writer.Flush()
fmt.Printf("Product page URLs saved to %sn", outputFile)
}Программа Go автоматизирует поиск информации в Интернете с помощью:
os.RemoveAll()для удаления выходного каталога(output/), если он уже существует, чтобы гарантировать чистый старт.exec.Command()иcmd.Run()для создания и выполнения процесса командной строки Gospider, который будет ползать по целевому веб-сайту.os.Open()иbufio.NewScanner(), чтобы открыть выходной файл, сгенерированный Gospider(books_toscrape_com), и прочитать его построчно.regexp.MustCompile()иFindAllString(), чтобы использовать regex для извлечения URL-адресов страниц товаров из каждой строки, используяslices.Contains()для предотвращения дубликатов.os.Create()иbufio.NewWriter()для записи отфильтрованных URL-адресов страниц товаров в файлproduct_urls.txt. Шаг № 5: Выполнение сценария ползания Запустите сценарийcrawler.goс помощью следующей команды:
go run crawler/crawler.goСценарий выведет в терминал следующее сообщение:
Running Gospider...
# Gospider output omitted for brevity...
Gospider finished
Reading the Gospider output file...
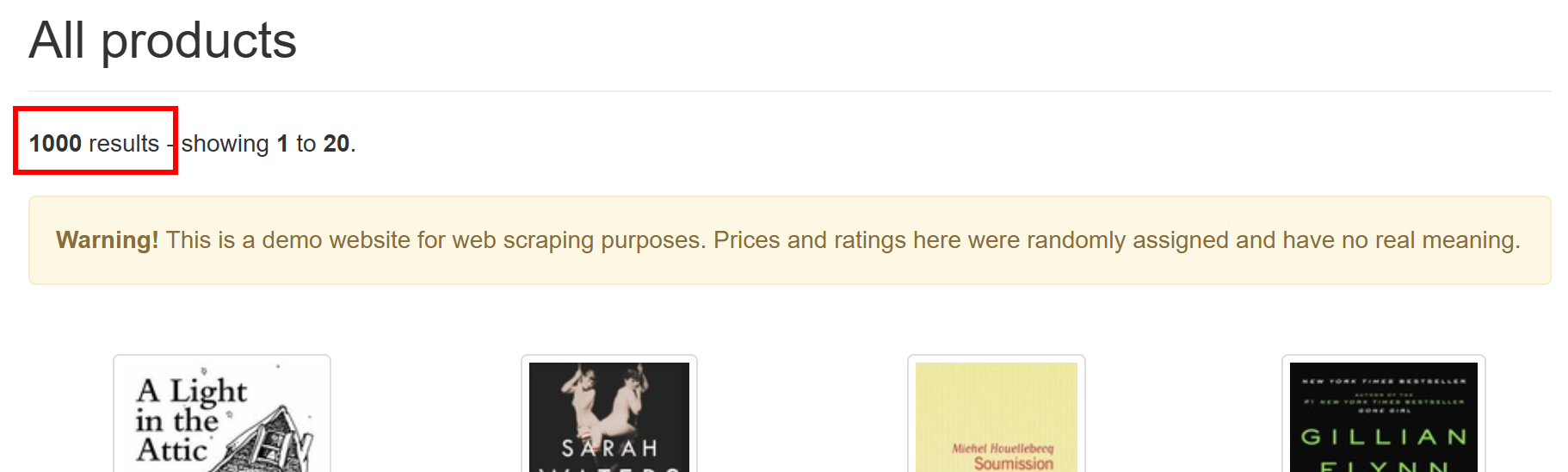
1000 product page URLs found
Exporting filtered product page URLs...
Product page URLs saved to product_urls.txtСкрипт Gospider успешно нашел 1 000 URL-адресов страниц товаров. Как вы можете легко убедиться на целевом сайте, именно столько страниц товаров имеется в наличии:
Эти URL будут храниться в файле product_urls.txt, созданном в папке проекта. Откройте этот файл и вы увидите:
https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
# omitted for brevity...
https://books.toscrape.com/catalogue/frankenstein_20/index.htmlПоздравляем! Вы только что создали скрипт Gospider для выполнения веб-ползания в Go.
[Дополнительно] Добавьте логику скрапинга в Gospider Crawler
Веб-скраппинг – это, как правило, лишь один из этапов более крупного проекта по веб-скраппингу. Узнайте больше о разнице между этими двумя методами, прочитав наше руководство по веб-скреппингу и веб-скреппингу.
Чтобы сделать это руководство более полным, мы также продемонстрируем, как использовать найденные ссылки для веб-скрапинга. Скрипт Go для скраппинга, который мы собираемся создать, будет:
- Считайте URL-адреса страниц товаров из файла
product_urls.txt, который был создан ранее с помощью Gospider и пользовательской логики. - Посетите страницу каждого продукта и соберите данные о нем.
- Экспортируйте полученные данные о продуктах в файл CSV.
Пора добавить логику веб-скреппинга в вашу систему Gospider!
Шаг #1: Установите Colly
В качестве библиотеки для веб-скрапинга используется Colly, элегантный фреймворк для скраперов и краулеров на Golang. Если вы не знакомы с его API, ознакомьтесь с нашим руководством по веб-скрейпингу с помощью Go.
Выполните следующую команду, чтобы установить Colly:
go get -u github.com/gocolly/colly/...Затем создайте файл scraper.go в папке scraper в каталоге проекта. Теперь структура вашего проекта должна выглядеть следующим образом:
gospider-project/
├── crawler/
│ └── crawler.go
├── output/
│ └── books_toscrape_com
└── scraper/
└── scraper.goОткройте файл scraper.go и импортируйте Colly:
import (
"bufio"
"encoding/csv"
"os"
"strings"
"github.com/gocolly/colly"
)Фантастика! Выполните следующие действия, чтобы использовать Colly для извлечения данных со страниц товаров.
Шаг № 2: Прочитайте URL-адреса для соскоба
Используйте следующий код, чтобы получить URL-адреса страниц товаров для сканирования из файла filtered_urls.txt, который был сгенерирован crawler.go:
// Open the input file with the crawled URLs
file, _ := os.Open("product_urls.txt")
defer file.Close()
// Read page URLs from the input file
var urls []string
scanner := bufio.NewScanner(file)
for scanner.Scan() {
urls = append(urls, scanner.Text())
}Чтобы приведенный выше фрагмент работал, включите эти импорты в начало вашего файла:
import (
"bufio"
"os"
)Отлично! В фрагменте urls будут содержаться все URL-адреса страниц товаров, готовые к соскабливанию.
Шаг № 3: Реализация логики извлечения данных
Прежде чем реализовывать логику извлечения данных, необходимо понять структуру HTML страницы продукта.
Для этого зайдите на страницу товара в браузере в режиме инкогнито, чтобы обеспечить новую сессию. Откройте DevTools и просмотрите элементы страницы, начиная с HTML-узла изображения товара:

Затем изучите раздел с информацией о продукте:

Из проверенных элементов можно извлечь:
- Заголовок продукта из тега
<h1>. - Цена продукта из первого узла
.price_colorна странице. - Рейтинг продукта (звезды) из класса
.star-rating. - URL-адрес изображения продукта из элемента
#product_gallery img.
Учитывая эти атрибуты, определите следующую структуру Go struct для представления отсканированных данных:
type Product struct {
Title string
Price string
Stars string
ImageURL string
}Поскольку будет соскоблено несколько страниц с товарами, определите фрагмент для хранения извлеченных продуктов:
var products []ProductЧтобы получить данные, начните с инициализации коллектора Colly:
c := colly.NewCollector()Используйте обратный вызов OnHTML() в Colly, чтобы определить логику скраппинга:
c.OnHTML("html", func(e *colly.HTMLElement) {
// Scraping logic
title := e.ChildText("h1")
price := e.DOM.Find(".price_color").First().Text()
stars := ""
e.ForEach(".star-rating", func(_ int, el *colly.HTMLElement) {
class := el.Attr("class")
if strings.Contains(class, "One") {
stars = "1"
} else if strings.Contains(class, "Two") {
stars = "2"
} else if strings.Contains(class, "Three") {
stars = "3"
} else if strings.Contains(class, "Four") {
stars = "4"
} else if strings.Contains(class, "Five") {
stars = "5"
}
})
imageURL := e.ChildAttr("#product_gallery img", "src")
// Adjust the relative image path
imageURL = strings.Replace(imageURL, "../../", "https://books.toscrape.com/", 1)
// Create a new product object with the scraped data
product := Product{
Title: title,
Price: price,
Stars: stars,
ImageURL: imageURL,
}
// Append the product to the products slice
products = append(products, product)
})Обратите внимание на структуру else if, используемую для получения звездного рейтинга на основе атрибута class в .star-rating. Также посмотрите, как относительный URL-адрес изображения преобразуется в абсолютный с помощью strings.Replace().
Добавьте следующий необходимый импорт:
import (
"strings"
)Теперь ваш скребок Go настроен на извлечение данных о продукте!
Шаг № 4: Подключение к целевым страницам
Colly – это основанный на обратных вызовах фреймворк для веб-скрапинга с определенным жизненным циклом обратных вызовов. Это означает, что вы можете определить логику скраппинга до получения HTML, что является необычным, но мощным подходом.
Теперь, когда логика извлечения данных создана, поручите Колли посетить страницу каждого продукта:
pageLimit := 50
for _, url := range urls[:pageLimit] {
c.Visit(url)
}Примечание: Количество URL-адресов было ограничено 50, чтобы не перегружать целевой сайт большим количеством запросов. В производственном сценарии вы можете снять или скорректировать это ограничение в зависимости от ваших потребностей.
Теперь Колли будет:
- Посетите каждый URL-адрес из списка.
- Примените обратный вызов
OnHTML()для извлечения данных о продукте. - Сохраните извлеченные данные в фрагменте
продуктов.
Потрясающе! Осталось только экспортировать собранные данные в человекочитаемый формат, например CSV.
Шаг № 5: Экспорт собранных данных
Экспортируйте срез продуктов в CSV-файл, используя следующую логику:
outputFile := "products.csv"
csvFile, _ := os.Create(outputFile)
defer csvFile.Close()
// Initialize a new CSV writer
writer := csv.NewWriter(csvFile)
defer writer.Flush()
// Write CSV header
writer.Write([]string{"Title", "Price", "Stars", "Image URL"})
// Write each product's data to the CSV
for _, product := range products {
writer.Write([]string{product.Title, product.Price, product.Stars, product.ImageURL})
}В приведенном выше фрагменте создается файл products.csv и заполняется полученными данными.
Не забудьте импортировать пакет CSV из стандартной библиотеки Go:
import (
"encoding/csv"
)Вот и все! Теперь ваш проект Gospider по ползанию и скраппингу полностью реализован.
Шаг №6: Соберите все вместе
scraper.go теперь должен содержать:
package main
import (
"bufio"
"encoding/csv"
"os"
"strings"
"github.com/gocolly/colly"
)
// Define a data type for the data to scrape
type Product struct {
Title string
Price string
Stars string
ImageURL string
}
func main() {
// Open the input file with the crawled URLs
file, _ := os.Open("product_urls.txt")
defer file.Close()
// Read page URLs from the input file
var urls []string
scanner := bufio.NewScanner(file)
for scanner.Scan() {
urls = append(urls, scanner.Text())
}
// Create an array where to store the scraped data
var products []Product
// Set up Colly collector
c := colly.NewCollector()
c.OnHTML("html", func(e *colly.HTMLElement) {
// Scraping logic
title := e.ChildText("h1")
price := e.DOM.Find(".price_color").First().Text()
stars := ""
e.ForEach(".star-rating", func(_ int, el *colly.HTMLElement) {
class := el.Attr("class")
if strings.Contains(class, "One") {
stars = "1"
} else if strings.Contains(class, "Two") {
stars = "2"
} else if strings.Contains(class, "Three") {
stars = "3"
} else if strings.Contains(class, "Four") {
stars = "4"
} else if strings.Contains(class, "Five") {
stars = "5"
}
})
imageURL := e.ChildAttr("#product_gallery img", "src")
// Adjust the relative image path
imageURL = strings.Replace(imageURL, "../../", "https://books.toscrape.com/", 1)
// Create a new product object with the scraped data
product := Product{
Title: title,
Price: price,
Stars: stars,
ImageURL: imageURL,
}
// Append the product to the products slice
products = append(products, product)
})
// Iterate over the first 50 URLs to scrape them all
pageLimit := 50 // To avoid overwhelming the target server with too many requests
for _, url := range urls[:pageLimit] {
c.Visit(url)
}
// Export the scraped products to CSV
outputFile := "products.csv"
csvFile, _ := os.Create(outputFile)
defer csvFile.Close()
// Initialize a new CSV writer
writer := csv.NewWriter(csvFile)
defer writer.Flush()
// Write CSV header
writer.Write([]string{"Title", "Price", "Stars", "Image URL"})
// Write each product's data to the CSV
for _, product := range products {
writer.Write([]string{product.Title, product.Price, product.Stars, product.ImageURL})
}
}Запустите скребок с помощью следующей команды:
go run scraper/scraper.goВыполнение может занять некоторое время, поэтому наберитесь терпения. После завершения в папке проекта появится файл products.csv. Откройте его, и вы увидите собранные данные, аккуратно структурированные в табличном формате:

И вуаля! Госпайдер для ползания + Колли для скребка – выигрышный дуэт.
Ограничения подхода Gospider к веб-кроулингу
Самыми большими ограничениями подхода Gospider к поиску являются:
- Запрет IP-адресов из-за слишком большого количества запросов.
- Технологии защиты от краулинга, используемые веб-сайтами для блокировки краулинговых ботов.
Давайте посмотрим, как справиться с обеими проблемами!
Избегайте запретов на использование IP-адресов
Следствием слишком большого количества запросов с одной и той же машины является то, что ваш IP-адрес может быть заблокирован целевым сервером. Это распространенная проблема при веб-кроулинге, особенно если он плохо настроен или не соответствует этическим нормам.
По умолчанию Gospider соблюдает robots.txt, чтобы свести этот риск к минимуму. Однако не все сайты имеют файл robots.txt. Кроме того, даже если он есть, в нем могут быть не указаны корректные правила ограничения скорости для краулеров.
Чтобы ограничить запреты IP-адресов, можно попробовать использовать встроенные в Gospider флаги --delay, --random-delay, --timeout для замедления запросов. Тем не менее, поиск правильной комбинации может занять много времени и не всегда будет эффективным.
Более эффективным решением является использование вращающегося прокси, который гарантирует, что каждый запрос от Gospider будет исходить с другого IP-адреса. Это не позволит целевому сайту обнаружить и заблокировать ваши попытки краулинга.
Чтобы использовать вращающийся прокси с Gospider, передайте URL прокси с флагом -p (или --proxy):
gospider -s "https://example.com" -o output -p "<PROXY_URL>"Если у вас нет URL-адреса вращающегося прокси, получите его бесплатно!
Обход технологии защиты от краулинга
Даже при использовании вращающегося прокси некоторые сайты применяют строгие меры по борьбе с крабингом и краулингом. Например, выполните эту команду Gospider на защищенном сайте Cloudflare:
gospider -s "https://community.cloudflare.com/" -o outputРезультат будет таким:
[url] - [code-403] - https://community.cloudflare.com/Как видите, целевой сервер ответил сообщением 403 Forbidden. Это означает, что сервер успешно обнаружил и заблокировал запрос Gospider, не позволив ему просмотреть ни один URL-адрес на странице.
Чтобы избежать таких блокировок, вам нужен универсальный API для разблокировки веб-страниц. Этот сервис способен обойти анти-боты и анти-скреппинговые системы, предоставляя вам доступ к незаблокированному HTML любой веб-страницы.
Примечание: Web Unlocker от Bright Data не только справляется с этими задачами, но и может работать в качестве прокси. Поэтому, настроив его, вы можете использовать его как обычный прокси с Gospider, используя синтаксис, показанный ранее.
Заключение
В этой статье вы узнали, что такое Gospider, что он предлагает и как использовать его для веб-скраппинга в Go. Вы также узнали, как объединить его с Colly, чтобы получить полный учебник по краулингу и скраппингу.
Одной из самых больших проблем при веб-скреппинге является риск быть заблокированным – из-за запрета IP-адресов или решений по борьбе со скрейпингом. Лучшие способы преодоления этих проблем – использование веб-прокси или API для скраппинга, например Web Unlocker.
Интеграция с Gospider – лишь один из многих сценариев, которые поддерживают продукты и услуги Bright Data. Ознакомьтесь с другими нашими инструментами для веб-скрепинга:
- API для веб-скреперов: Специальные конечные точки для извлечения свежих структурированных веб-данных из более чем 100 популярных доменов.
- SERP API: API для обработки всех текущих операций по разблокировке SERP и извлечению одной страницы.
- Функции скрапинга: Полноценный интерфейс для скрапинга, позволяющий запускать скраперы как бессерверные функции.
- Браузер для скраппинга: Браузер, совместимый с Puppeteer, Selenium и Playwright, со встроенными функциями разблокировки
Зарегистрируйтесь на сайте Bright Data и протестируйте наши прокси-сервисы и продукты для скрапбукинга бесплатно!




