

В этом руководстве вы узнаете:
- Что значит скреативить веб-сайт в Markdown и почему это полезно.
- Основные подходы к преобразованию HTML веб-страницы в Markdown для статических и динамических сайтов.
- Как использовать Python для соскабливания веб-страницы в Markdown.
- Ограничения этого решения и способы их преодоления с помощью Bright Data.
Давайте погрузимся!
Что значит “соскрести веб-сайт в Markdown”?
Скрапировать веб-сайт в Markdown – значит преобразовать его содержимое в Markdown.
Точнее, это значит взять HTML веб-страницы и преобразовать его в формат данных Markdown.
Например, подключитесь к сайту, откройте DevTools и скопируйте его HTML:
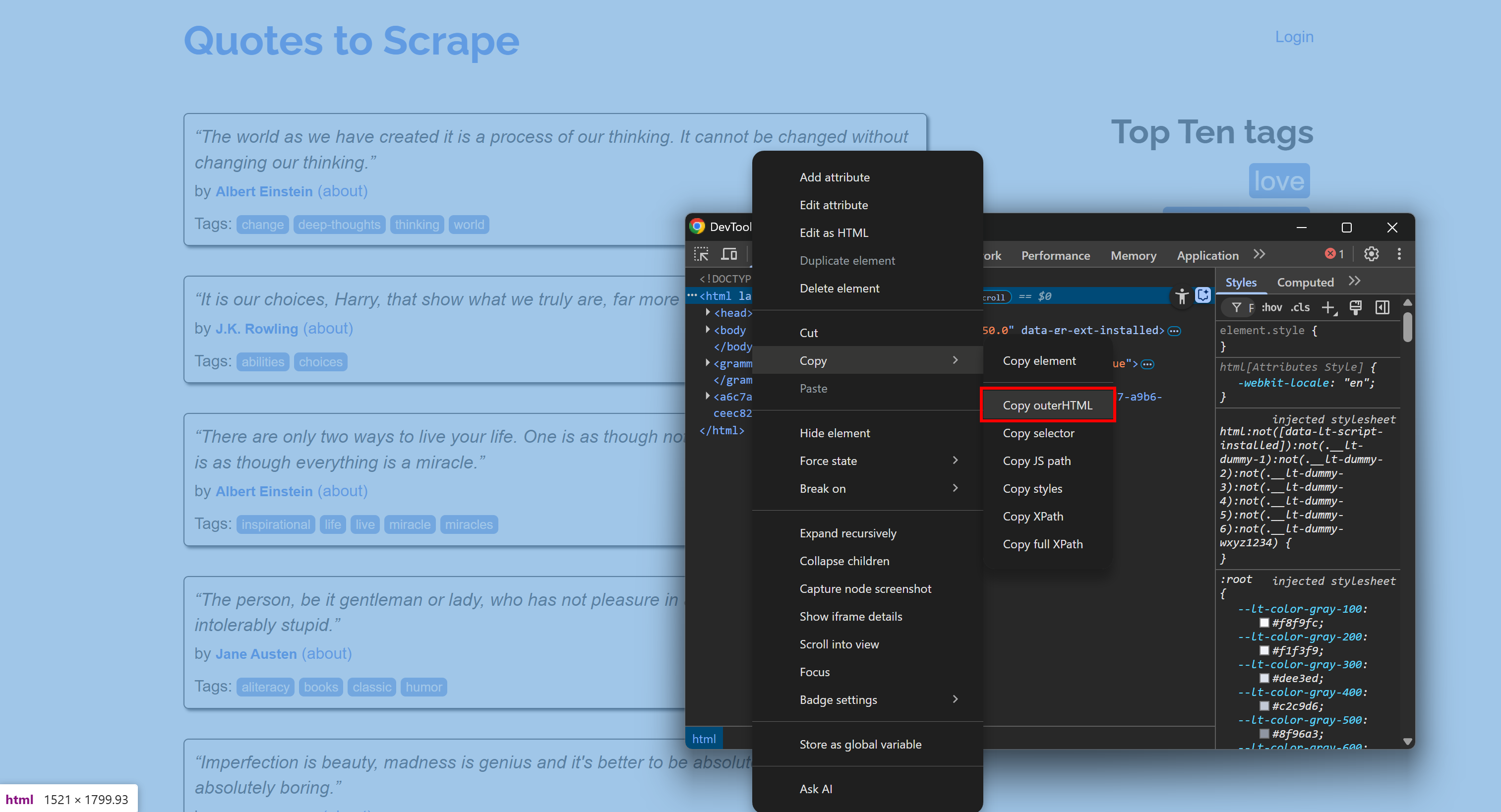
Затем вставьте его в конвертер HTML-to-Markdown:
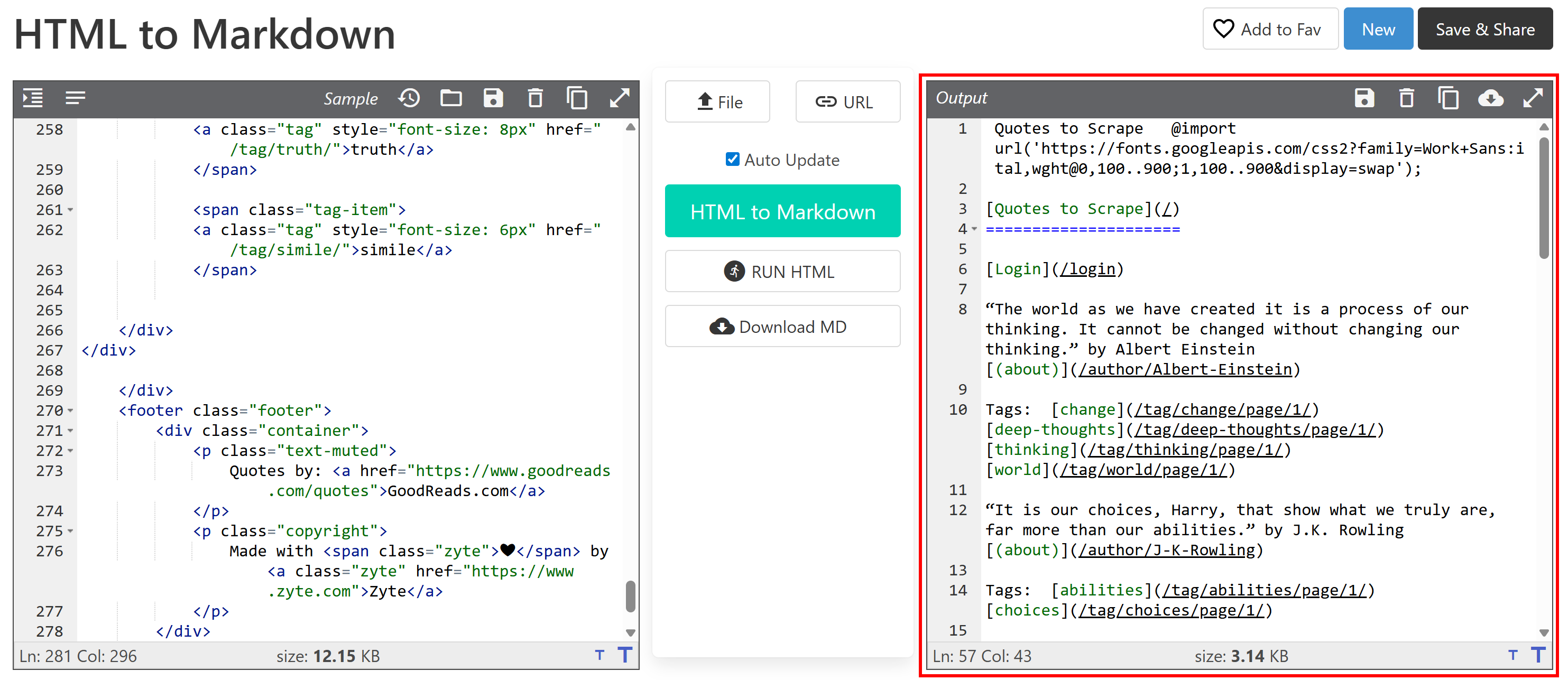
На выходе получится документ в формате Markdown, который вы хотите получить с помощью веб-скрейпинга. Теперь задача состоит в том, чтобы автоматизировать этот процесс, о чем и пойдет речь в этой статье!
[Дополнительно] Почему Markdown?
Почему именно Markdown, а не другой формат (например, обычный текст)? Потому что, как показал наш бенчмарк форматов данных, Markdown – один из лучших форматов для ввода в LLM. Вот три основные причины:
- Он сохраняет большую часть структуры и информации страницы (например, ссылки, изображения, заголовки и т. д.).
- Он лаконичен, что позволяет ограничить использование токенов и ускорить обработку ИИ.
- LLM, как правило, понимают Markdown гораздо лучше, чем обычный HTML.
Именно поэтому лучшие инструменты ИИ для скраппинга по умолчанию работают с Markdown.
Подходы к переходу от HTML к Markdown
Теперь вы знаете, что скраппинг сайта в Markdown означает просто преобразование HTML его страниц в Markdown. В общих чертах этот процесс выглядит следующим образом:
- Подключитесь к сайту.
- Получите HTML в виде строки.
- Используйте библиотеку HTML-to-Markdown для создания вывода в формате Markdown.
Проблема в том, что не все веб-страницы предоставляются одинаково. Первые два шага могут существенно отличаться в зависимости от того , является ли целевая страница статической или динамической. Давайте рассмотрим, как справиться с обоими сценариями, расширив необходимые шаги!
Шаг № 1: Подключение к сайту
На статической веб-странице HTML-документ, возвращаемый сервером, – это именно то, что вы видите в браузере. Другими словами, все фиксировано и встроено в HTML, созданный сервером.
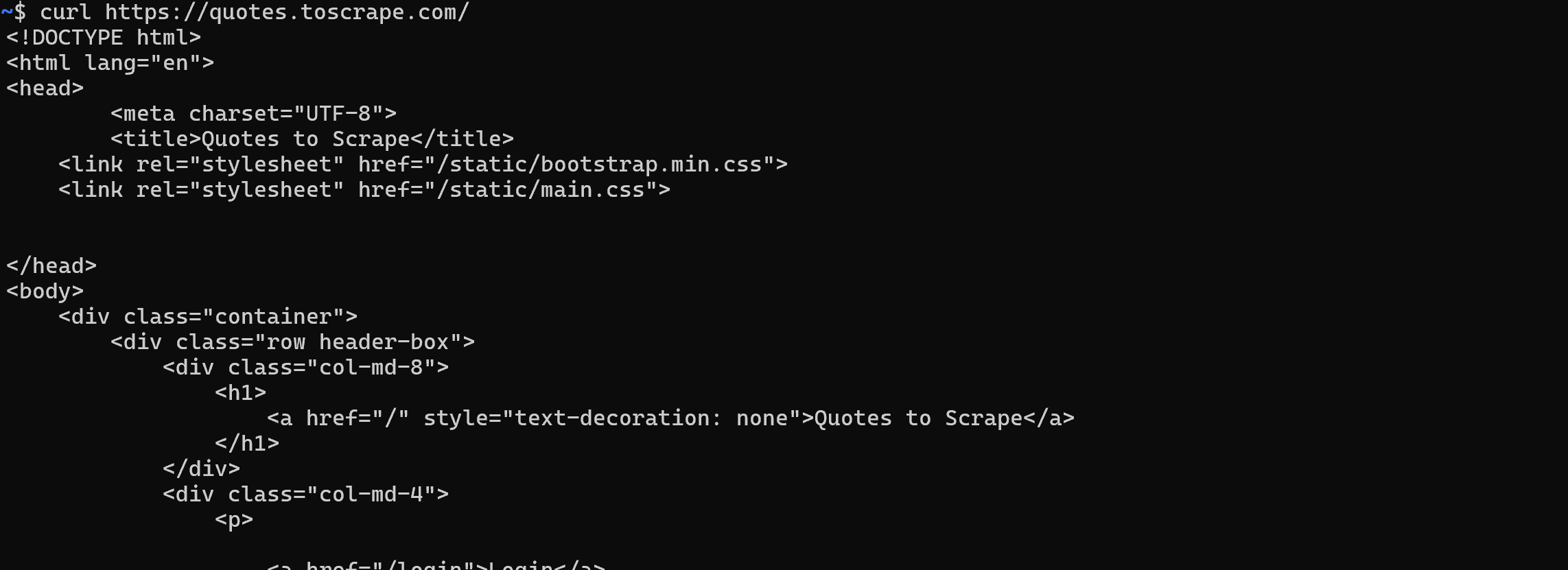
В этом случае получить HTML-документ очень просто. Достаточно выполнить HTTP-запрос GET к URL страницы с помощью любого HTTP-клиента:
Напротив, на динамическом сайте большая часть содержимого (или часть) извлекается через AJAX и отображается в браузере с помощью JavaScript. Это означает, что первоначальный HTML-документ, возвращаемый веб-сервером, содержит лишь необходимый минимум. Только после выполнения JavaScript на стороне клиента страница наполняется полным содержимым:

В таких случаях вы не можете просто получить HTML с помощью простого HTTP-клиента. Вместо этого вам нужен инструмент, который может фактически отрисовать страницу, например, средство автоматизации браузера. Такие решения, как Playwright, Puppeteer или Selenium, позволяют программно управлять браузером для загрузки целевой страницы и получения ее полного HTML.
Шаг № 2: Получение HTML в виде строки
Для статических веб-страниц этот шаг прост. Ответ веб-сервера на ваш GET-запрос уже содержит полный HTML-документ в виде строки. Большинство HTTP-клиентов, например, Python’s Requests, предоставляют метод или поле для прямого доступа к этой строке:
url = "https://quotes.toscrape.com/"
response = requests.get(url)
# Доступ к HTML-содержимому страницы в виде строки
html = response.textДля динамических сайтов все гораздо сложнее. На этот раз вас не интересует необработанный HTML-документ, возвращаемый сервером. Вместо этого вам нужно подождать, пока браузер отрендерит страницу, DOM стабилизируется, а затем получить доступ к конечному HTML.
Это соответствует тому, что вы обычно делаете вручную, открывая DevTools и копируя HTML из узла <html>:
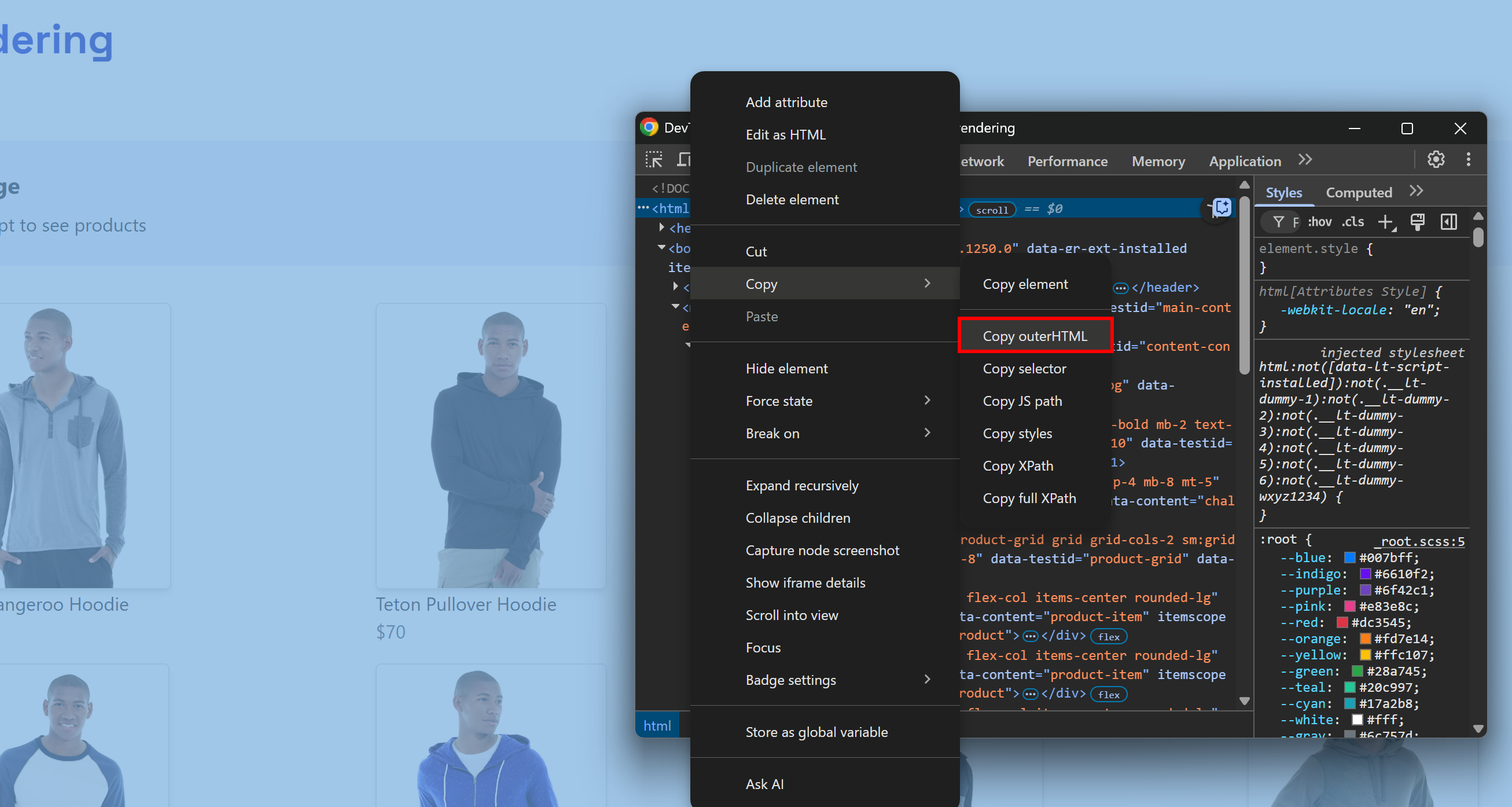
Сложность заключается в том, чтобы понять, когда страница закончила рендеринг. Распространенные стратегии включают:
- Ждать события
DOMContentLoaded: Возникает, когда исходный HTML разобран, а отложенные<script>загружены и выполнены. Ожидание этого события является поведением Playwright по умолчанию. - Ждать события
load: Возникает, когда загружается вся страница, включая таблицы стилей, скрипты, iframe и изображения (кроме лениво загружаемых). - Ждать события
networkidle: Считает рендеринг завершенным, если в течение заданного времени (например,500 мсв Playwright) нет сетевых запросов. Это ненадежно для сайтов с обновляемым контентом, так как никогда не сработает. - Ожидание определенных элементов: Используйте пользовательские API ожидания, предоставляемые фреймворками для автоматизации браузеров, чтобы дождаться появления определенных элементов в DOM.
После того как страница будет полностью отрисована, вы можете извлечь HTML с помощью специального метода/поля, предоставляемого средством автоматизации браузера. Например, в Playwright:
html = await page.content()Шаг № 3: Используйте библиотеку HTML-to-Markdown для генерации выходных данных в формате уценки
После того как вы получили HTML в виде строки, вам нужно просто отправить его в одну из множества доступных библиотек HTML-to-Markdown. Наиболее популярными являются:
| Библиотека . | Язык программирования | GitHub Stars |
|---|---|---|
markdownify |
Python | 1.8k+ |
свернуть |
JavaScript/Node.js | 10k+ |
Html2Markdown |
C# | 300+ |
commonmark-java |
Java | 2.5k+ |
html-to-markdown |
Go | 3k+ |
html-to-markdown |
PHP | 1.8k+ |
Скрапирование веб-сайта в Markdown: Практические примеры на Python
В этом разделе вы увидите готовые сниппеты Python для соскабливания веб-сайта в Markdown. Приведенные ниже скрипты реализуют шаги, описанные ранее. Обратите внимание, что вы можете легко перевести логику на JavaScript или любой другой язык программирования.
На входе будет URL веб-страницы, а на выходе – соответствующий контент в формате Markdown!
Статические сайты
В этом примере мы будем использовать следующие две библиотеки:
requests: Для выполнения GET-запроса и получения HTML-адреса страницы в виде строки.markdownify: Для преобразования HTML страницы в Markdown.
Установите их обе с помощью команды:
pip install requests markdownifyЦелевой страницей будет статическая страница “Quotes to Scrape“. Достичь цели можно с помощью следующего фрагмента:
import requests
из markdownify import markdownify as md
# URL-адрес страницы, которую нужно скрапировать
url = "http://quotes.toscrape.com/"
# Получение HTML-содержимого с помощью запросов
response = requests.get(url)
# Получение HTML в виде строки
html_content = response.text
# Преобразуйте HTML-содержимое в Markdown
markdown_content = md(html_content)
# Выведите данные в формате Markdown
print(markdown_content)По желанию вы можете экспортировать содержимое в файл .md:
with open("page.md", "w", encoding="utf-8") as f:
f.write(markdown_content)Результат работы скрипта будет таким:
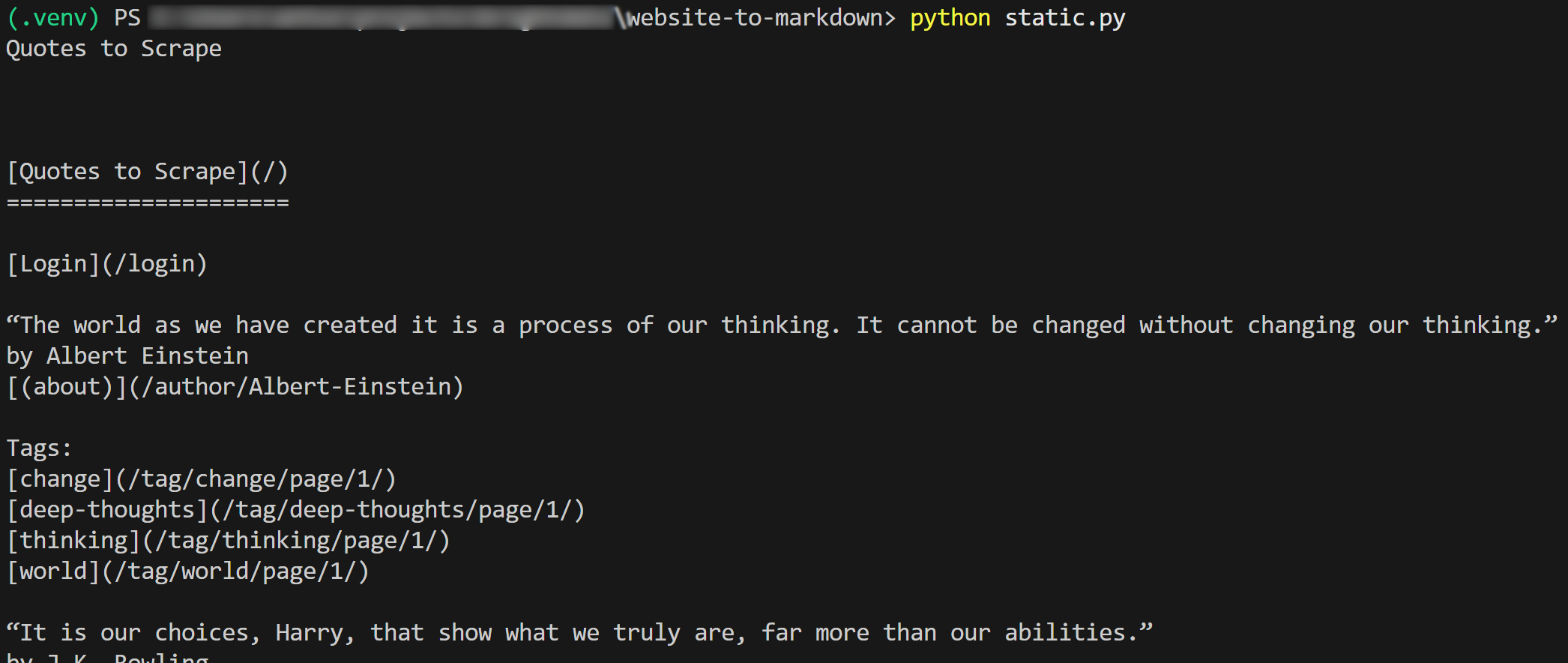
Если скопировать выходной Markdown и вставить его в рендере Markdown, вы увидите:
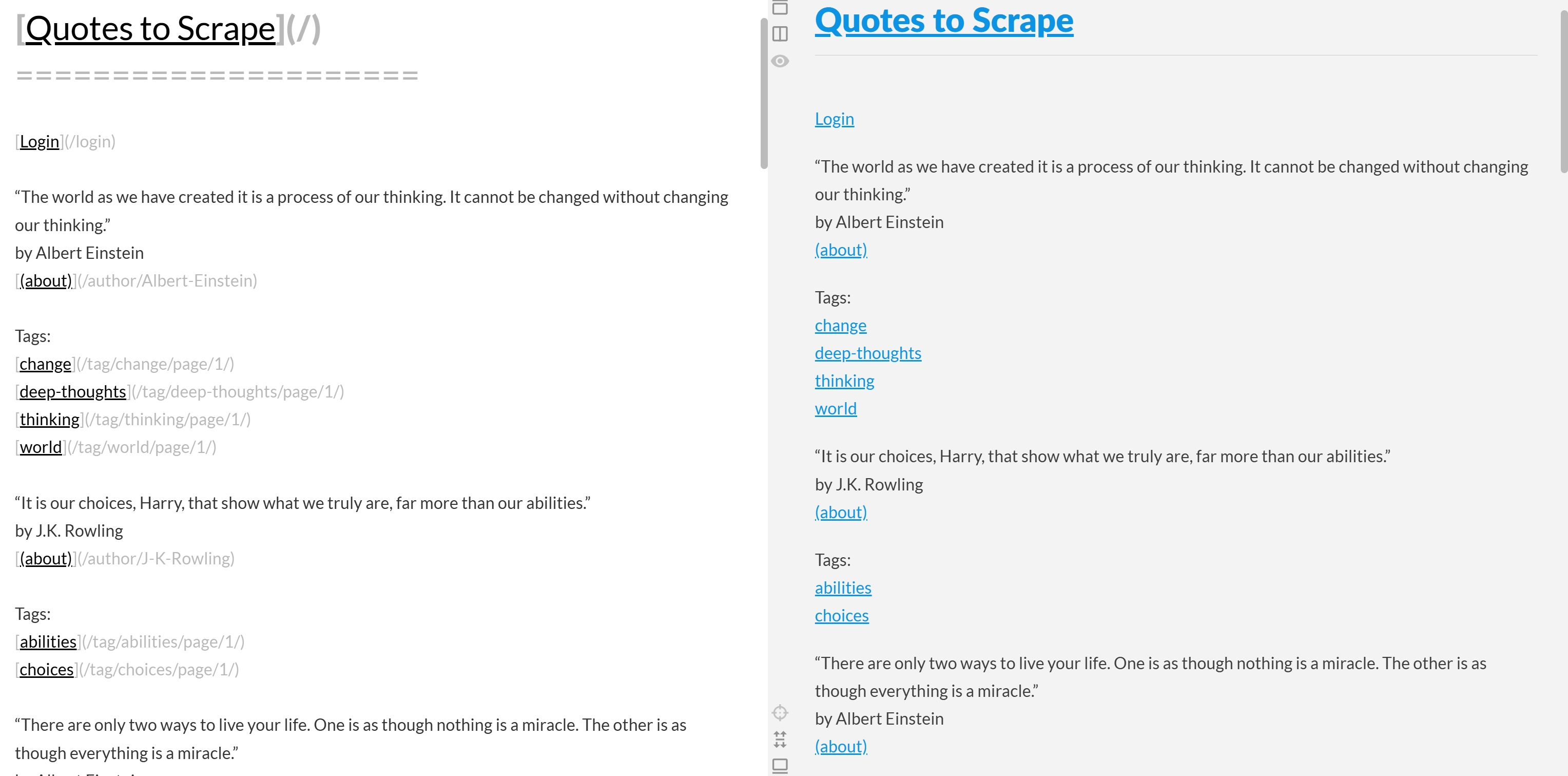
Обратите внимание, что это выглядит как упрощенная версия исходного контента со страницы “Quotes to Scrape”:
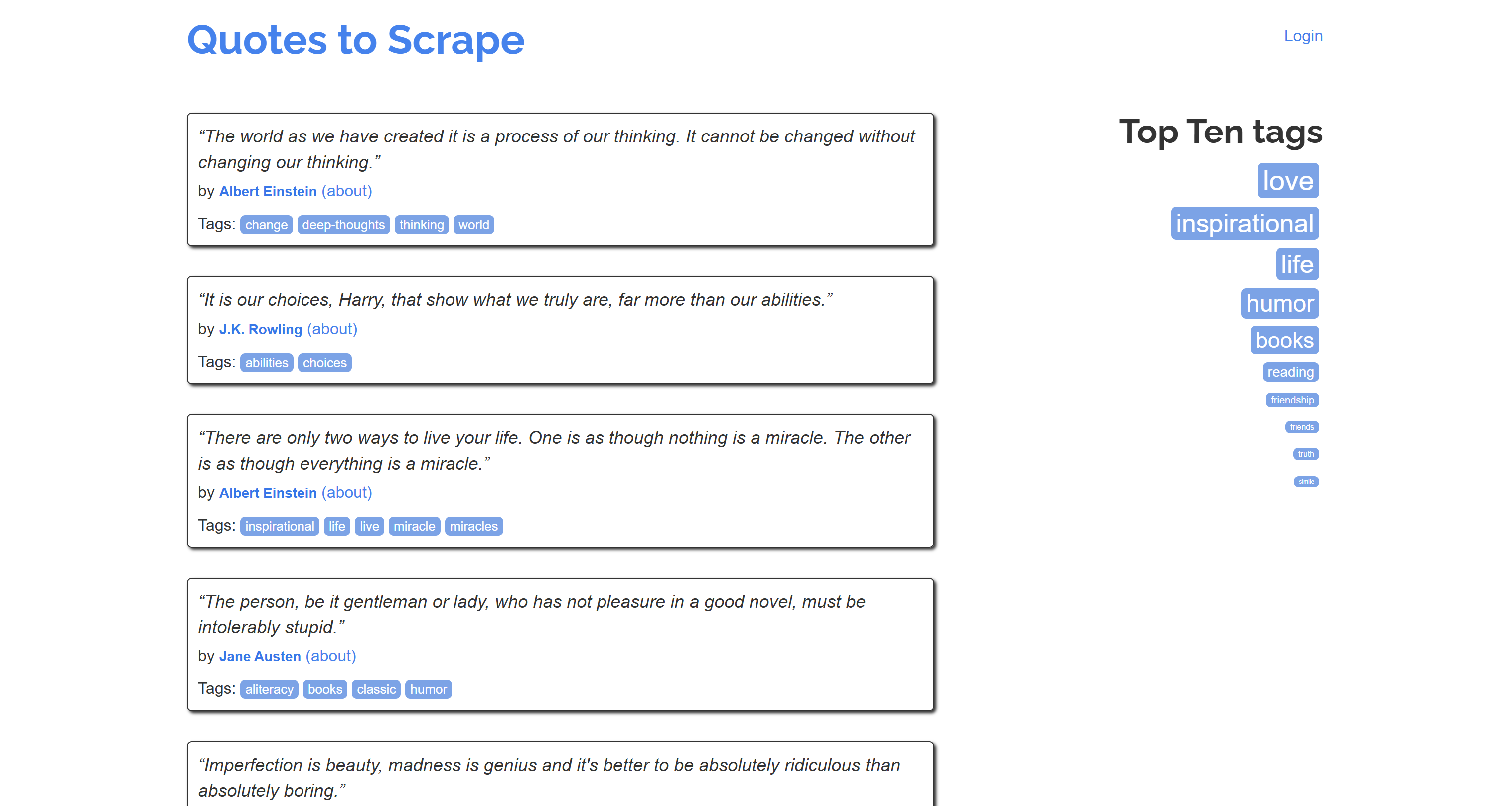
Миссия выполнена!
Динамические сайты
Здесь мы будем использовать эти две библиотеки:
playwright: Для рендеринга целевой страницы в контролируемом экземпляре браузера.markdownify: Для преобразования отрисованного DOM страницы в Markdown.
Установите две вышеуказанные зависимости с помощью:
pip install playwright markdownifyЗатем завершите установку Playwright с помощью:
python -m playwright installМестом назначения будет динамическая страница “JavaScript Rendering” на сайте ScrapingCourse.com:
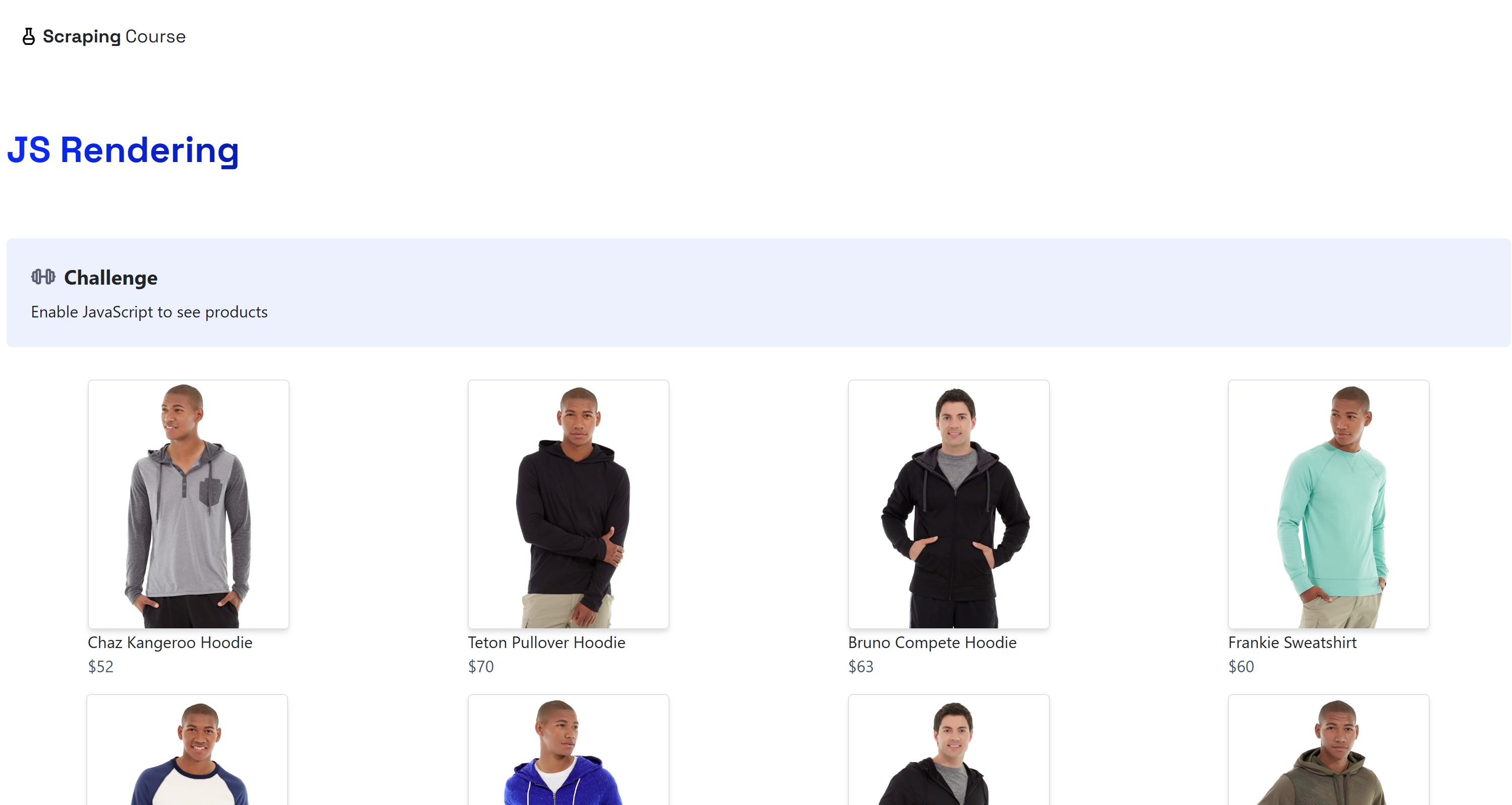
Эта страница получает данные на стороне клиента через AJAX и отображает их с помощью JavaScript:
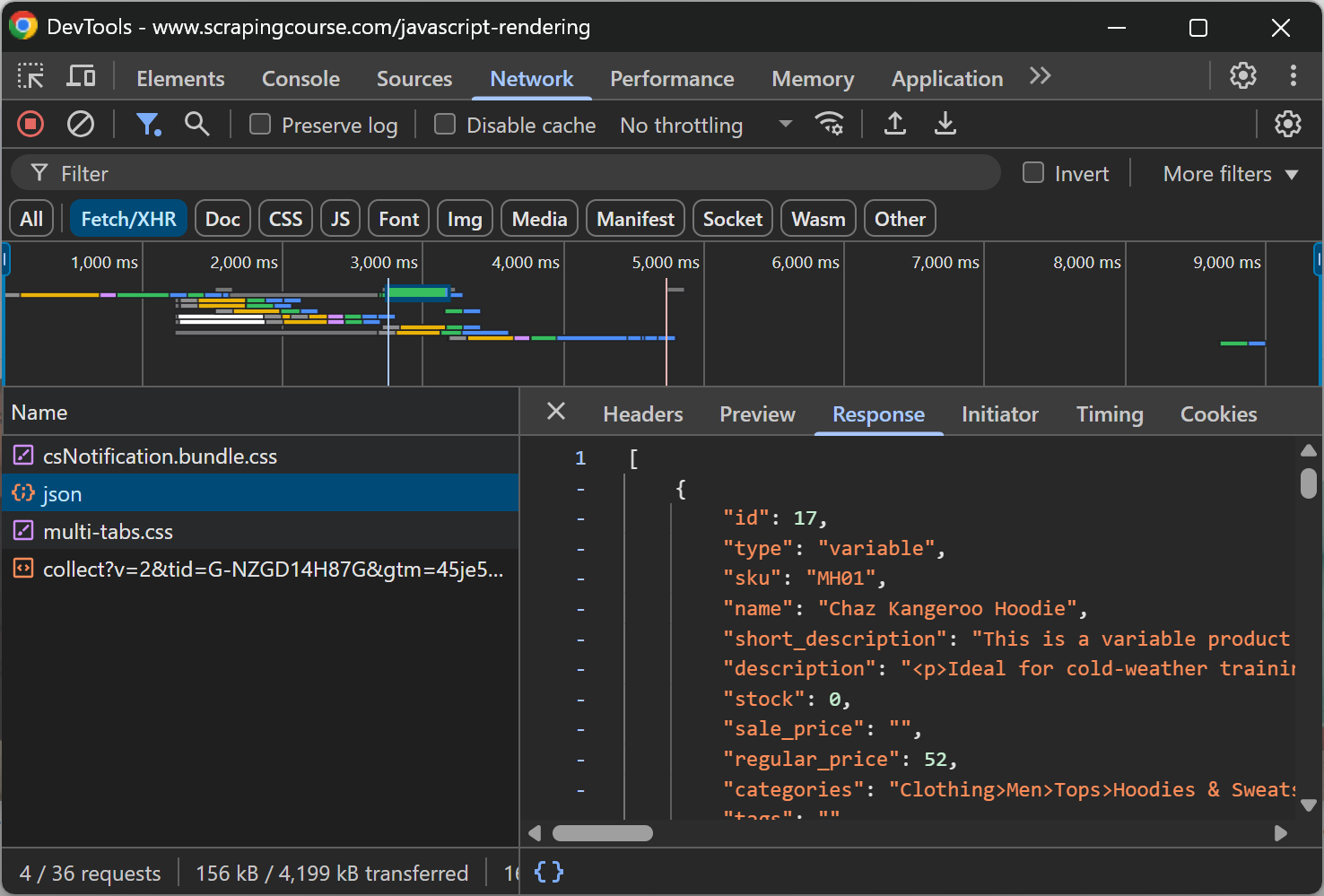
Соскребите динамический веб-сайт в Markdown, как показано ниже:
from playwright.sync_api import sync_playwright
from markdownify import markdownify as md
with sync_playwright() as p:
# Запуск безголового браузера
browser = p.chromium.launch()
page = browser.new_page()
# URL динамической страницы
url = "https://scrapingcourse.com/javascript-rendering"
# Переход на страницу
page.goto(url)
# Подождите до 5 секунд, пока первый элемент ссылки на товар не будет заполнен
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)
# Получение полностью отрендеренного HTML
rendered_html = page.content()
# Преобразование HTML в Markdown
markdown_content = md(rendered_html)
# Выведите полученный текст в формате Markdown
print(markdown_content)
# Закройте браузер и освободите его ресурсы
browser.close()В приведенном выше фрагменте мы выбрали вариант 4 (“Ждать определенных элементов”), поскольку он является наиболее надежным. Для более детального рассмотрения посмотрите на эту строку кода:
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)Это ожидание до 5000 миллисекунд (5 секунд), пока элемент .product-link (тег <a> ) не будет иметь непустой атрибут href. Этого достаточно, чтобы показать, что первый элемент продукта на странице был отрисован, то есть данные были получены и DOM теперь стабилен.
Результат будет таким:
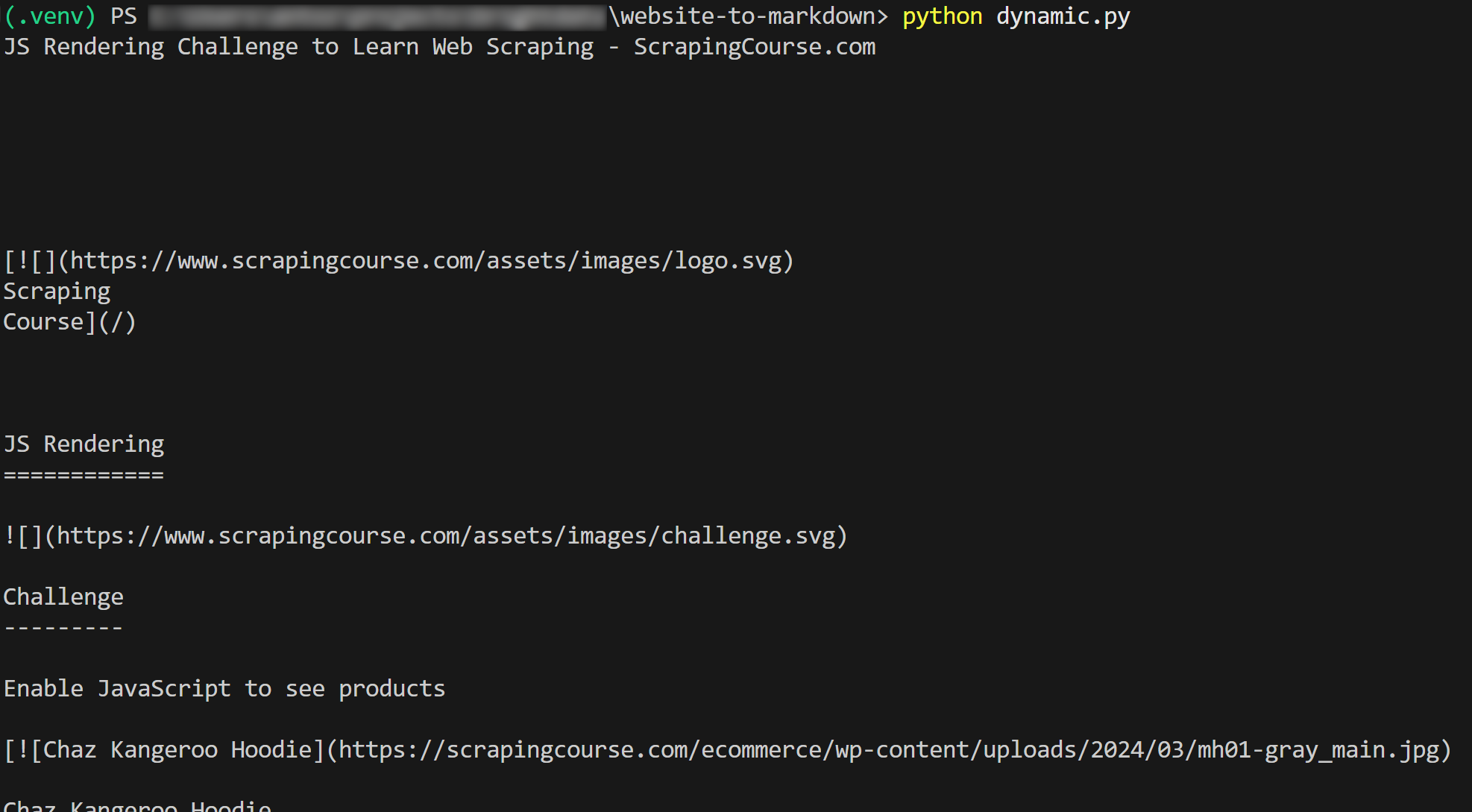
Et voilà! Вы только что узнали, как скрапировать веб-сайт в Markdown.
Ограничения этих подходов и решение
Все примеры, приведенные в этом блоге, объединяет один фундаментальный аспект: они относятся к страницам, которые были созданы для того, чтобы их было легко соскребать!
К сожалению, большинство реальных веб-страниц не так уж и открыты для ботов, занимающихся веб-скрейпингом. Напротив, многие сайты используют такие средства защиты от скрапинга, как CAPTCHA, запрет IP-адресов, отпечатки пальцев браузера и многое другое.
Другими словами, нельзя ожидать, что простой HTTP-запрос или инструкция Playwright goto() сработают так, как нужно. При работе с большинством реальных веб-сайтов вы можете столкнуться с ошибкой 403 Forbidden:

Или страницы ошибок / проверки человеком:
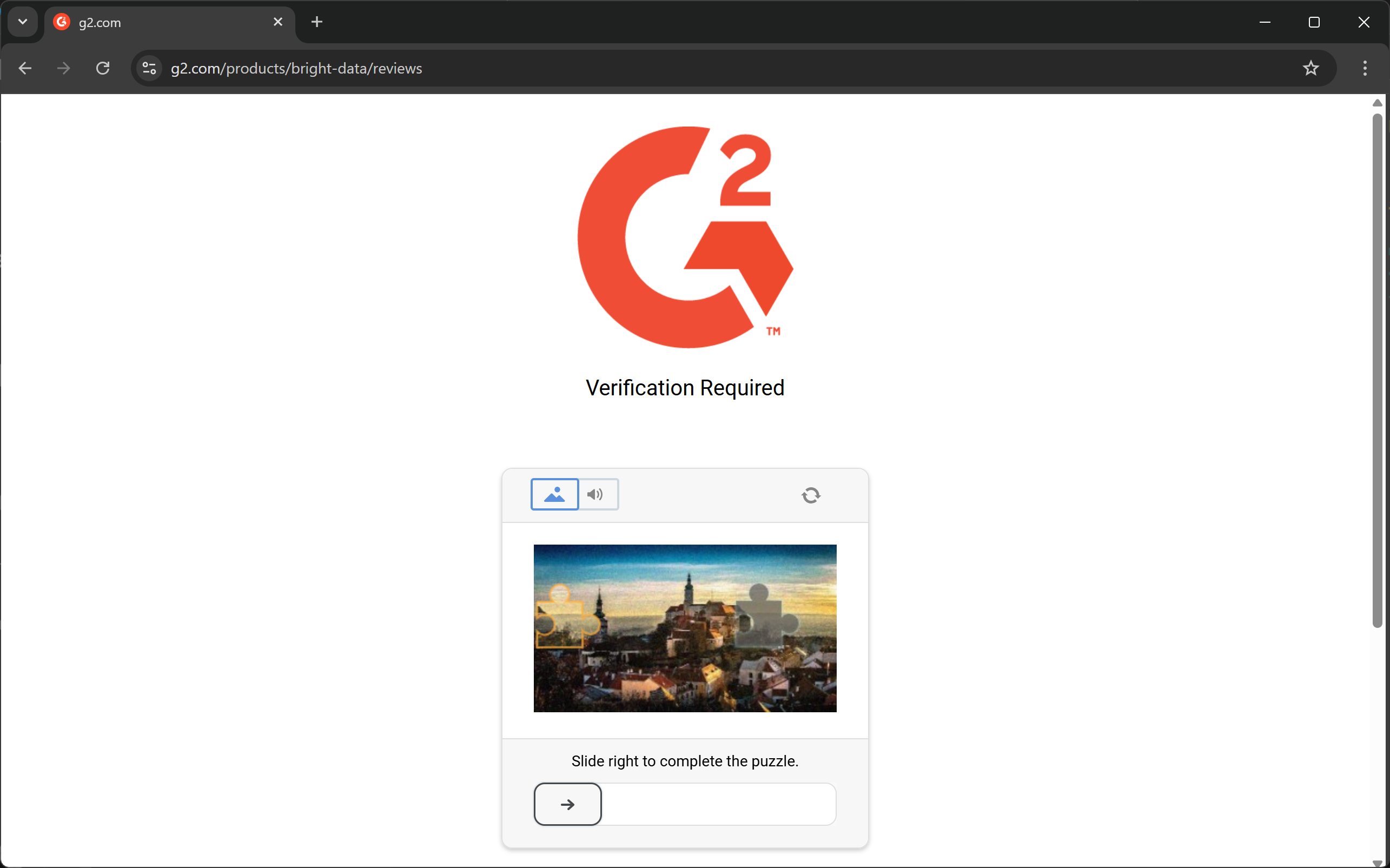
Еще один ключевой аспект, который следует учитывать, заключается в том, что большинство библиотек HTML-to-Markdown выполняют преобразование необработанных данных. Это может привести к нежелательным результатам. Например, если страница содержит элементы <style> или <script>, встроенные непосредственно в HTML, их содержимое (т. е. код CSS и JavaScript, соответственно) будет включено в вывод Markdown:
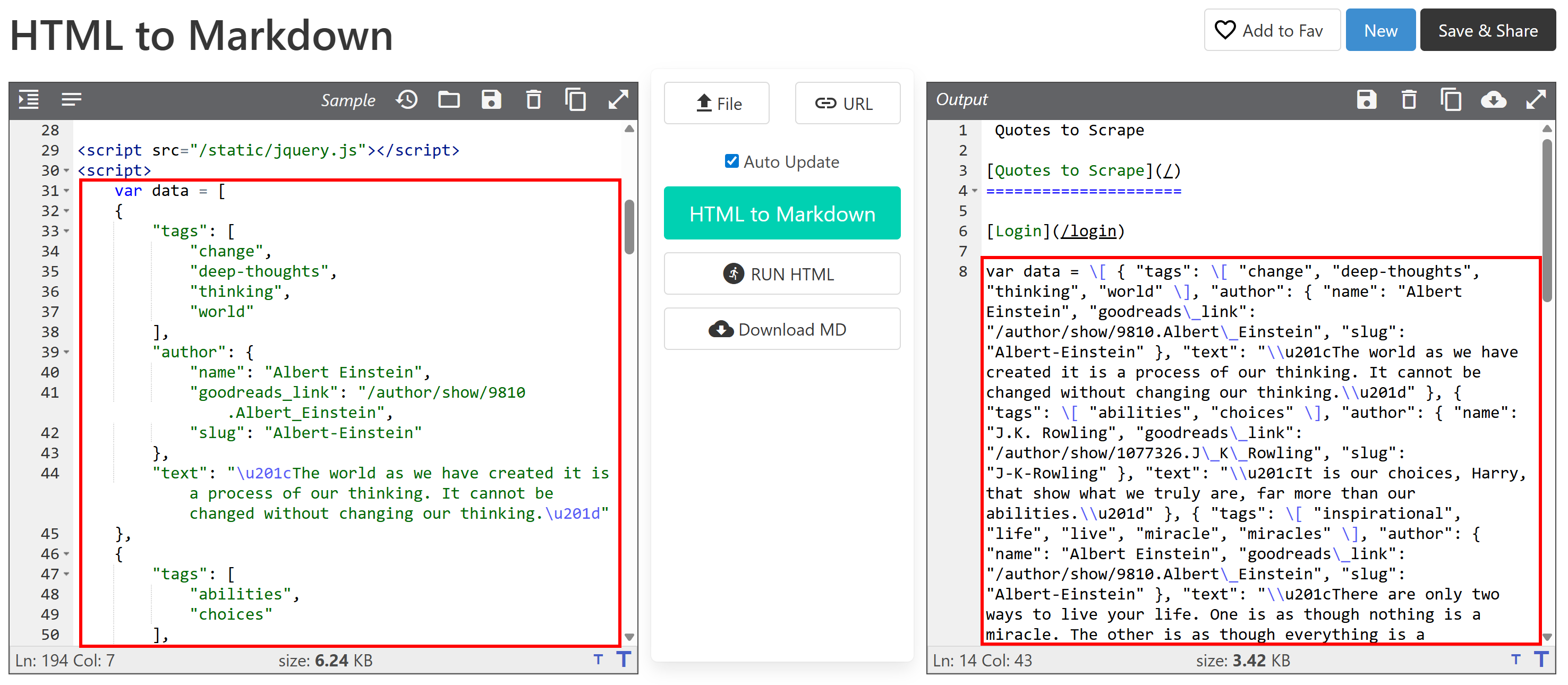
Это, как правило, нежелательно, особенно если вы планируете передавать Markdown в LLM для обработки данных. В конце концов, эти текстовые элементы просто добавляют шум.
Решение? Положитесь на специальный API Web Unlocker, который может получить доступ к любому сайту, независимо от его защиты, и выдать готовый для LLM Markdown. Это гарантирует, что извлеченный контент будет чистым, структурированным и готовым для последующих задач ИИ.
Веб-скрейпинг в формате Markdown с помощью Web Unlocker
Web Unlocker от Bright Data – это облачный API для веб-скрейпинга, который может вернуть HTML любой веб-страницы. Это справедливо независимо от наличия средств защиты от скрапинга и ботов, а также от того, является ли страница статической или динамической.
API поддерживается сетью прокси из более чем 150 миллионов IP-адресов, что позволяет вам сосредоточиться на сборе данных, в то время как Bright Data занимается всей инфраструктурой разблокировки, рендерингом JavaScript, решением CAPTCHA, масштабированием и обновлением обслуживания.
Использовать его очень просто. Выполните POST HTTP-запрос к Web Unlocker с правильными аргументами, и вы получите в ответ полностью разблокированную веб-страницу. Вы также можете настроить API на возврат контента в оптимизированном для LLM формате Markdown.
Следуйте руководству по начальной настройке, а затем используйте Web Unlocker для соскабливания веб-сайта в Markdown с помощью всего нескольких строк кода:
# pip install requests
импортировать requests
# Замените эти параметры на нужные значения из вашей учетной записи Bright Data
BRIGHT_DATA_API_KEY = "<ВАШ_BRIGHT_DATA_API_KEY>"
WEB_UNLOCKER_ZONE = "<ИМЯ_ВАШЕЙ_WEB_UNLOCKER_ZONE_NAME>"
# Замените на целевой URL
url_to_scrape = "https://www.g2.com/products/bright-data/reviews"
# Подготовьте необходимые заголовки
заголовки = {
"Authorization": f "Bearer {BRIGHT_DATA_API_KEY}", # Для аутентификации
"Content-Type": "application/json"
}
# Подготовьте полезную нагрузку POST для Web Unlocker
полезная нагрузка = {
"url": url_to_scrape,
"зона": WEB_UNLOCKER_ZONE,
"format": "raw",
"data_format": "markdown" # Чтобы получить ответ в виде содержимого Markdown
}
# Выполните POST-запрос к API Bright Data Web Unlocker
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
заголовки=headers
)
# Получите ответ в формате Markdown и распечатайте его
markdown_content = response.text
print(markdown_content)Выполните сценарий и получите результат:
Обратите внимание, что на этот раз вы не были заблокированы G2. Вместо этого вы получили реальный контент Mardkwon, как и хотели.
Отлично! Преобразование веб-сайта в Markdown еще никогда не было таким простым.
Примечание: Это решение доступно через 75+ интеграций с инструментами ИИ-агентов, такими как CrawlAI, Agno, LlamaIndex и LangChain. Кроме того, его можно использовать напрямую с помощью инструмента scrape_as_markdown на сервере Bright Data Web MCP.
Заключение
В этой статье вы узнали, зачем и как конвертировать веб-страницу в Markdown. Как уже говорилось, преобразование HTML в Markdown не всегда является простой задачей из-за таких проблем, как защита от скрапинга и неоптимальные результаты Markdown.
Bright Data предлагает вам Web Unlocker, облачный API для веб-скрейпинга, способный преобразовать любую веб-страницу в оптимизированный для LLM Markdown. Вы можете вызвать этот API вручную или интегрировать его непосредственно в решения по созданию агентов ИИ или с помощью интеграции Web MCP.
Помните, что Web Unlocker – это лишь один из многих инструментов для сбора веб-данных и веб-скрейпинга, доступных в инфраструктуре ИИ Bright Data.
Зарегистрируйте бесплатную учетную запись Bright Data сегодня и начните изучать наши решения для работы с веб-данными, готовыми к ИИ!




