

Из этого руководства вы узнаете:
- Определение парсера Google Maps
- Какие данные можно извлечь с его помощью
- Как создать скрипт парсинга Google Maps с помощью Python
Давайте рассмотрим эти вопросы подробнее!
Что такое Парсер Google Maps?
Парсер Google Maps — это специализированный инструмент для извлечения данных из Google Maps. Он автоматизирует процесс сбора данных Maps, например, с помощью скрипта парсинга на Python. Данные, полученные с помощью такого парсера, обычно используются для исследования рынка, анализа конкурентов и многого другого.
Какие данные можно получить из Google Maps
Информация, которую вы можете извлечь из Google Maps, включает:
- Название компании: название компании или местоположения, указанное на Google Maps.
- Адрес: физический почтовый адрес предприятия или места.
- Номер телефона: контактный телефон компании.
- Веб-сайт: URL-адрес веб-сайта компании.
- Часы работы: время открытия и закрытия бизнеса.
- Отзывы: отзывы покупателей, включая оценки и подробные отзывы.
- Оценки: средняя оценка в звездах, основанная на отзывах пользователей.
- Фотографии: изображения, загруженные компанией или клиентами.
Пошаговые инструкции по парсингу Google Maps с помощью Python
В этом пошаговом разделе вы узнаете, как создать скрипт Python для парсинга Google Maps.
Конечная цель — получить данные, содержащиеся в объектах Google Maps на странице «Итальянские рестораны»:
Выполните следующие действия!
Шаг 1: настройка проекта
Прежде чем начать, вам необходимо убедиться, что на вашем компьютере установлен Python 3. Если это не так, скачайте, установите и следуйте указаниям мастера установки.
Затем с помощью следующих команд создайте папку для проекта, войдите в нее и создайте в ней виртуальную среду:
mkdir google-maps-scraper
cd google-maps-scraper
python -m venv env
Папка google-maps-scraper представляет собой папку проекта Python -парсера Google Maps.
Загрузите папку проекта в свою предпочтительную Python IDE. Подойдет PyCharm Community Edition или Visual Studio Code с расширением Python.
Внутри папки проекта создайте файл scraper.py. Вот какая файловая структура должна быть в вашем проекте прямо сейчас:
scraper.py теперь пустой скрипт Python, но вскоре он будет содержать логику парсинга.
В терминале IDE активируйте виртуальную среду. Для этого в Linux или macOS выполните следующую команду:
./env/bin/activate
Или же в Windows запустите:
env/Scripts/activate
Чудесно, теперь у вас есть среда Python для вашего парсера!
Шаг №2: выберите библиотеку парсинга
Google Maps — это очень интерактивная платформа, и нет смысла тратить время на определение того, является ли сайт статическим или динамическим. В таких случаях лучше всего использовать инструмент автоматизации браузера.
Если вы не знакомы с этой технологией, инструменты автоматизации браузера позволяют отображать веб-страницы и взаимодействовать с ними в среде управляемого браузера. Кроме того, создать действительный URL-адрес для поиска в Google Maps непросто. Самый простой способ решить эту проблему — выполнить поиск непосредственно в браузере.
Одним из лучших инструментов автоматизации браузеров на Python является Selenium, что делает его идеальным выбором для парсинга Google Maps. Подготовьтесь к установке, так как это будет основная библиотека, используемая для этой задачи!
Шаг №3: установка и настройка библиотеки парсинга
Установите Selenium через pip-пакет selenium с помощью этой команды в активированной виртуальной среде Python:
pip install selenium
Подробнее об использовании этого инструмента читайте в нашем руководстве «Веб-парсинг с помощью Selenium».
Импортируйте Selenium в scraper.py и создайте объект WebDriver для управления экземпляром Chrome в режиме без заголовка:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to launch Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# create a Chrome web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
Приведенный выше фрагмент кода инициализирует экземпляр Chrome WebDriver для программного управления окном браузера Chrome. Флаг --headless предназначен для запуска Chrome в режиме без заголовка, при котором приложение запускается в фоновом режиме без загрузки окна. Для отладки вы можете закомментировать эту строку, чтобы наблюдать за действиями скрипта в реальном времени.
В качестве последней строки скрипта очистки Google Maps не забудьте закрыть веб-драйвер:
driver.quit()
Потрясающе! Теперь у вас все готово к парсингу страниц Google Maps.
Шаг №4. подключитесь к целевой странице.
Используйте метод get() для подключения к главной странице Google Maps:
driver.get("https://www.google.com/maps")
Прямо сейчас scraper.py будет содержать следующие строки:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to launch Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# create a Chrome web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google Maps home page
driver.get("https://www.google.com/maps")
# scraping logic...
# close the web browser
driver.quit()
Отлично, пора начать парсить динамический веб-сайт , например Maps!
Шаг №5: разберитесь с диалоговым окном GDPR по использованию файлов cookie
Примечание: если вы не находитесь в ЕС (Европейском союзе), вы можете пропустить этот шаг.
Запустите скрипт scraper.py в режиме с заголовком, добавив точку останова перед последней строкой, если возможно. При этом окно браузера останется открытым, и вы сможете наблюдать за ним, не закрывая его сразу. Если вы находитесь в ЕС, вы должны увидеть что-то вроде этого:

Примечание: сообщение «Chrome контролируется программным обеспечением для автоматического тестирования» подтверждает, что Selenium успешно управляет Chrome.
Google должен показать пользователям из ЕС некоторые варианты политики использования файлов cookie из-за требований GDPR. Если это относится к вам, вам нужно будет сделать этот выбор, если вы хотите взаимодействовать со страницей. Если это не так, вы можете перейти к шагу 6.
Посмотрите на URL-адрес в адресной строке браузера, и вы заметите, что он не соответствует странице, указанной в get(). Причина в том, что Google перенаправил вас. После нажатия кнопки «Принять все» вы вернетесь на целевую страницу — главную страницу Google Maps.
Чтобы работать с опциями GDPR, откройте главную страницу Google Maps в режиме инкогнито в браузере и дождитесь перенаправления. Нажмите правой кнопкой мыши кнопку «Принять все» и выберите опцию «Просмотреть код»:

Как вы могли заметить, классы CSS HTML-элементов на странице, похоже, генерируются случайным образом. Это означает, что они плохо подходят для веб-парсинга, поскольку они, вероятно, обновляются при каждом развертывании. Поэтому вам нужно сосредоточиться на более стабильных атрибутах, таких как aria-label:
accept_button = driver.find_element(By.CSS_SELECTOR, "[aria-label="Accept all"]")
find_element() — это метод в Selenium, используемый для поиска HTML-элементов на странице с использованием различных стратегий. В данном случае мы использовали селектор CSS. Если вы хотите узнать больше о различных типах селекторов, ознакомьтесь с нашим руководством «Селекторы XPath по сравнению с селекторами CSS».
Не забудьте импортировать By, добавив этот импорт в scraper.py:
from selenium.webdriver.common.by import By
Следующая инструкция — нажать кнопку:
accept_button.click()
Вот как все сочетается для обработки опциональной страницы cookie Google:
try:
# select the "Accept all" button from the GDPR cookie option page
accept_button = driver.find_element(By.CSS_SELECTOR, "[aria-label="Accept all"]")
# click it
accept_button.click()
except NoSuchElementException:
print("No GDPR requirenments")
Команда click() нажимает кнопку «Принять все», позволяя Google перенаправить вас на домашнюю страницу Maps. Если вы находитесь за пределами ЕС, этой кнопки не будет на странице, что приведет к возникновению исключения NoSuchElementException. Скрипт обнаружит исключение и продолжит работу, так как это не критическая ошибка, а потенциальный сценарий.
Обязательно импортируйте NoSuchelementException:
from selenium.common import NoSuchElementException
Отлично! Теперь вы готовы сосредоточиться на парсинге Google Maps.
Шаг №6: отправьте форму поиска
Прямо сейчас ваш парсер Google Maps должен попасть на страницу, подобную приведенной ниже:

Обратите внимание, что местоположение на картах зависит от местоположения вашего IP-адреса. В этом примере мы находимся в Нью-Йорке.
Далее вам нужно заполнить поле «Поиск в Google Maps» и отправить форму поиска. Чтобы найти этот элемент, откройте главную страницу Google Maps в режиме инкогнито в своем браузере. Нажмите правой кнопкой мыши поле ввода поиска и выберите опцию «Просмотреть код»:
search_input = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#searchboxinput"))
)
WebDriverWait — это специализированный класс Selenium, который приостанавливает выполнение скрипта до тех пор, пока на странице не будет выполнено указанное условие. В приведенном выше примере он ожидает появления входного HTML-элемента до 5 секунд. Это ожидание гарантирует полную загрузку страницы, что необходимо, если вы выполнили шаг 5 (из-за перенаправления).
Чтобы вышеуказанные строки работали, добавьте эти импорты в scraper.py:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Next, fill out the input with the `[send_keys()](https://www.selenium.dev/documentation/webdriver/actions_api/keyboard/#send-keys)` method:
search_query = "italian restaurants"
search_input.send_keys(search_query)
В данном случае поисковым запросом является «итальянские рестораны», но вы можете искать любой другой термин.
Осталось только отправить форму. Просмотрите код кнопки «отправить», которая выглядит как увеличительное стекло:

Выберите его, выбрав атрибут aria-label, и нажмите на нее:
search_button = driver.find_element(By.CSS_SELECTOR, "button[aria-label="Search"]")
search_button.click()
Невероятно! Теперь управляемый браузер загрузит данные для парсинга.
Шаг№7: выберите объекты Google Maps
Вот где сейчас должен находиться ваш скрипт:
Данные для парсинга содержатся в объектах Google Maps слева. Поскольку это список, лучшая структура для данных парсинга, — это массив. Инициализируйте один из них:
items = []
Теперь цель состоит в том, чтобы выбрать объект Google Maps слева. Осмотрите один из них:

Опять же, классы CSS, похоже, генерируются случайным образом, поэтому их нельзя подвергать очистке. Вместо этого вы можете настроить таргетинг на атрибут jsaction. Поскольку часть содержимого этого атрибута также генерируется случайным образом, сосредоточьтесь на содержащейся в нем последовательной строке, а именно на «mouseover:pane».
Селектор XPath ниже поможет вам выбрать все <div> элементы внутри родительского элемента, <div>где role="feed", чей атрибут jsaction содержит строку "mouseover:pane":
maps_items = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@role="feed"]//div[contains(@jsaction, "mouseover:pane")]'))
)
Опять же, требуется WebDriverWait, так как содержимое слева динамически загружается на страницу.
Просмотрите каждый элемент и подготовьте свой парсер Google Maps к парсингу данных:
for maps_item in maps_items:
# scraping logic...
Великолепно! Следующий шаг — извлечение данных из этих элементов.
Шаг №8: выполните парсинг объектов Google Maps
Проанализируйте код одного объекта Google Maps и сосредоточьтесь на элементах внутри него:

Здесь вы можете увидеть, парсинг чего вы можете выполнить:
- Ссылка на объект Maps из элемента
a[jsaction][jslog] - Заголовок из элемента
div.fontHeadlineSmall - Количество звезд и количество отзывов от
span [role="img"]
Вы можете добиться этого с помощью следующей логики:
link_element = maps_item.find_element(By.CSS_SELECTOR, "a[jsaction][jslog]")
url = link_element.get_attribute("href")
title_element = maps_item.find_element(By.CSS_SELECTOR, "div.fontHeadlineSmall")
title = title_element.text
reviews_element = maps_item.find_element(By.CSS_SELECTOR, "span[role="img"]")
reviews_string = reviews_element.get_attribute("aria-label")
# define a regular expression pattern to extract the stars and reviews count
reviews_string_pattern = r"(d+.d+) stars (d+[,]*d+) Reviews"
# use re.match to find the matching groups
reviews_string_match = re.match(reviews_string_pattern, reviews_string)
reviews_stars = None
reviews_count = None
# if a match is found, extract the data
if reviews_string_match:
# convert stars to float
reviews_stars = float(reviews_string_match.group(1))
# convert reviews count to integer
reviews_count = int(reviews_string_match.group(2).replace(",", ""))
Функция get_attribute() возвращает содержимое указанного атрибута HTML, а .text возвращает содержимое строки внутри узла.
Обратите внимание на использование регулярного выражения для извлечения определенных полей данных из строки «X.Y stars in Z reviews». Узнайте больше из нашей статьи об использовании регулярных выражений для веб-парсинга.
Не забудьте импортировать пакет re из стандартной библиотеки Python:
import re
Продолжайте просматривать код объекта Google Maps:
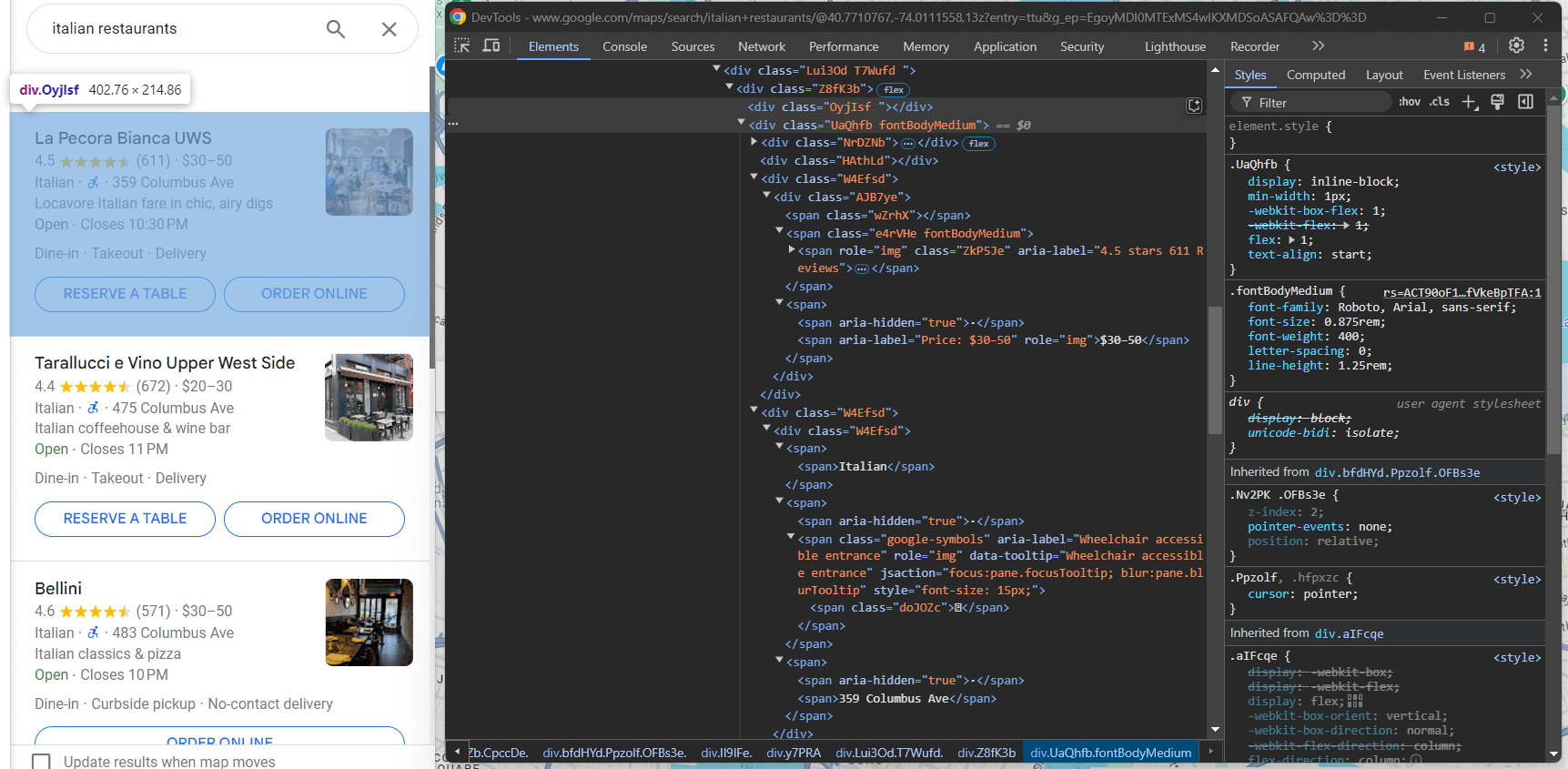
В <div> с классом fondBodyMedium большую часть информации вы можете получить из узлов <span>без атрибутов или только с атрибутом style. Что касается дополнительного элемента ценообразования, вы можете выбрать его, выбрав узел, который содержит слово Priсe («Цена») в атрибуте aria-label:
info_div = maps_item.find_element(By.CSS_SELECTOR, ".fontBodyMedium")
# scrape the price, if present
try:
price_element = info_div.find_element(By.XPATH, ".//*[@aria-label[contains(., 'Price')]]")
price = price_element.text
except NoSuchElementException:
price = None
info = []
# select all <span> elements with no attributes or the @style attribute
# and descendant of a <span>
span_elements = info_div.find_elements(By.XPATH, ".//span[not(@*) or @style][not(descendant::span)]")
for span_element in span_elements:
info.append(span_element.text.replace("⋅", "").strip())
# to remove any duplicate info and empty strings
info = list(filter(None, list(set(info))))
Поскольку элемент цены является необязательным, вы должны заключить эту логическую схему в блок try ... except. Таким образом, если ценового узла нет на странице, скрипт продолжит работу без сбоев. Если вы пропустите шаг 5, добавьте импорт для NoSuchElementException:
from selenium.common import NoSuchElementException
Чтобы избежать пустых строк и дублированных информационных элементов, обратите внимание на использование filter() и set().
Теперь сфокусируйтесь на изображении:

Вы можете выполнить его парсинг с помощью:
img_element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "img[decoding="async"][aria-hidden="true"]"))
)
image = img_element.get_attribute("src")
Имейте в виду, что требуется WebDriverWait, так как изображения загружаются асинхронно и могут появиться через некоторое время.
Последний шаг — очистить теги в элементе внизу:

Вы можете получить их все из узлов <span> с атрибутом style в последнем элемента .fontBodyMedium:
tags_div = maps_item.find_elements(By.CSS_SELECTOR, ".fontBodyMedium")[-1]
tags = []
tag_elements = tags_div.find_elements(By.CSS_SELECTOR, "span[style]")
for tag_element in tag_elements:
tags.append(tag_element.text)
Великолепно! Логическая схема парсинга Google Maps на Python создана.
Шаг №9: сбор данных после парсинга
Теперь у вас есть данные в нескольких переменных, полученные по итогам парсинга. Создайте новый объект item и заполните его этими данными:
item = {
"url": url,
"image": image,
"title": title,
"reviews": {
"stars": reviews_stars,
"count": reviews_count
},
"price": price,
"info": info,
"tags": tags
}
Затем добавьте его в массив items :
items.append(item)
В конце цикла for в узлах объектов Google Maps, items будут содержать все ваши данные парсинга. Вам нужно только экспортировать эту информацию в удобочитаемый файл, например CSV.
Шаг №10: экспорт в CSV
Импортируйте пакет csv из стандартной библиотеки Python:
import csv
Затем используйте его для заполнения пустого CSV-файла данными Google Maps:
# output CSV file path
output_file = "items.csv"
# flatten and export to CSV
with open(output_file, mode="w", newline="", encoding="utf-8") as csv_file:
# define the CSV field names
fieldnames = ["url", "image", "title", "reviews_stars", "reviews_count", "price", "info", "tags"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# write the header
writer.writeheader()
# write each item, flattening info and tags
for item in items:
writer.writerow({
"url": item["url"],
"image": item["image"],
"title": item["title"],
"reviews_stars": item["reviews"]["stars"],
"reviews_count": item["reviews"]["count"],
"price": item["price"],
"info": "; ".join(item["info"]),
"tags": "; ".join(item["tags"])
})
Приведенный выше фрагмент экспортирует items в CSV-файл с именем items.csv. Используются следующие ключевые функции:
open(): открывает указанный файл в режиме записи в кодировке UTF-8 для обработки вывода текста.csv.DictWriter(): создает объект записи CSV с использованием указанных имен полей, что позволит записывать строки в виде словарей.writeheader(): записывает строку заголовка в CSV-файл на основе имен полей.writer.writerow(): записывает каждый объект в виде строки в CSV-файле.
Обратите внимание на использование строковой функции join() для преобразования массивов в плоские строки. Это гарантирует, что выходной CSV-файл будет чистым одноуровневым файлом.
Шаг 11: заключительная сборка
Вот окончательный код Python-парсера Google Maps:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import csv
# to launch Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# create a Chrome web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google Maps home page
driver.get("https://www.google.com/maps")
# to deal with the option GDPR options
try:
# select the "Accept all" button from the GDPR cookie option page
accept_button = driver.find_element(By.CSS_SELECTOR, "[aria-label="Accept all"]")
# click it
accept_button.click()
except NoSuchElementException:
print("No GDPR requirenments")
# select the search input and fill it in
search_input = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#searchboxinput"))
)
search_query = "italian restaurants"
search_input.send_keys(search_query)
# submit the search form
search_button = driver.find_element(By.CSS_SELECTOR, "button[aria-label="Search"]")
search_button.click()
# where to store the scraped data
items = []
# select the Google Maps items
maps_items = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@role="feed"]//div[contains(@jsaction, "mouseover:pane")]'))
)
# iterate over the Google Maps items and
# perform the scraping logic
for maps_item in maps_items:
link_element = maps_item.find_element(By.CSS_SELECTOR, "a[jsaction][jslog]")
url = link_element.get_attribute("href")
title_element = maps_item.find_element(By.CSS_SELECTOR, "div.fontHeadlineSmall")
title = title_element.text
reviews_element = maps_item.find_element(By.CSS_SELECTOR, "span[role="img"]")
reviews_string = reviews_element.get_attribute("aria-label")
# define a regular expression pattern to extract the stars and reviews count
reviews_string_pattern = r"(d+.d+) stars (d+[,]*d+) Reviews"
# use re.match to find the matching groups
reviews_string_match = re.match(reviews_string_pattern, reviews_string)
reviews_stars = None
reviews_count = None
# if a match is found, extract the data
if reviews_string_match:
# convert stars to float
reviews_stars = float(reviews_string_match.group(1))
# convert reviews count to integer
reviews_count = int(reviews_string_match.group(2).replace(",", ""))
# select the Google Maps item <div> with most info
# and extract data from it
info_div = maps_item.find_element(By.CSS_SELECTOR, ".fontBodyMedium")
# scrape the price, if present
try:
price_element = info_div.find_element(By.XPATH, ".//*[@aria-label[contains(., 'Price')]]")
price = price_element.text
except NoSuchElementException:
price = None
info = []
# select all <span> elements with no attributes or the @style attribute
# and descendant of a <span>
span_elements = info_div.find_elements(By.XPATH, ".//span[not(@*) or @style][not(descendant::span)]")
for span_element in span_elements:
info.append(span_element.text.replace("⋅", "").strip())
# to remove any duplicate info and empty strings
info = list(filter(None, list(set(info))))
img_element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "img[decoding="async"][aria-hidden="true"]"))
)
image = img_element.get_attribute("src")
# select the tag <div> element and extract data from it
tags_div = maps_item.find_elements(By.CSS_SELECTOR, ".fontBodyMedium")[-1]
tags = []
tag_elements = tags_div.find_elements(By.CSS_SELECTOR, "span[style]")
for tag_element in tag_elements:
tags.append(tag_element.text)
# populate a new item with the scraped data
item = {
"url": url,
"image": image,
"title": title,
"reviews": {
"stars": reviews_stars,
"count": reviews_count
},
"price": price,
"info": info,
"tags": tags
}
# add it to the list of scraped data
items.append(item)
# output CSV file path
output_file = "items.csv"
# flatten and export to CSV
with open(output_file, mode="w", newline="", encoding="utf-8") as csv_file:
# define the CSV field names
fieldnames = ["url", "image", "title", "reviews_stars", "reviews_count", "price", "info", "tags"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# write the header
writer.writeheader()
# write each item, flattening info and tags
for item in items:
writer.writerow({
"url": item["url"],
"image": item["image"],
"title": item["title"],
"reviews_stars": item["reviews"]["stars"],
"reviews_count": item["reviews"]["count"],
"price": item["price"],
"info": "; ".join(item["info"]),
"tags": "; ".join(item["tags"])
})
# close the web browser
driver.quit()
Примерно за 150 строк кода вы только что создали скрипт для парсинга Google Maps!
Убедитесь, что он работает, запустив файл scraper.py. В Windows запустите парсер с помощью:
python scraper.py
Аналогично, в Linux или macOS запустите:
python3 scraper.py
Дождитесь завершения работы парсера, и в корневом каталоге вашего проекта появится файл items.csv. Откройте файл, чтобы просмотреть извлеченные данные, которые должны содержать следующие данные:

Поздравляем, миссия выполнена!
Заключение
Из этого урока вы узнали, что такое парсер Google Maps и как его создать на Python. Как вы уже видели, создание простого скрипта для автоматического извлечения данных из Google Maps занимает всего несколько строк кода Python.
Хотя решение подходит для небольших проектов, оно нецелесообразно для крупномасштабного парсинга. Google ввел расширенные меры по борьбе с ботами, такие как капчи и запреты на использование IP-адресов, которые могут заблокировать вас. Масштабирование процесса на нескольких страницах также увеличит затраты на инфраструктуру. Более того, этот простой пример не учитывает все сложные взаимодействия, необходимые на страницах Google Maps.
Означает ли это, что эффективный и надежный парсинг Google Maps невозможен? Вовсе нет! Вам просто нужно продвинутое решение, такое как API парсера Google Mapsот Bright Data.
API парсера Google Maps предоставляет конечные точки для извлечения данных из Google Maps и позволяет забыть обо всех основных проблемах. С помощью простых вызовов API вы можете получить необходимые данные в формате JSON или HTML. Если вы не привыкли работать с вызовами API, вы также можете ознакомиться с нашими готовыми к использованию наборами данных Google Maps.
Создайте бесплатный аккаунт учетную запись Bright Data сегодня, чтобы попробовать наши API парсеров или изучить наши наборы данных!





