

В этом руководстве мы рассмотрим:
- Начало работы с веб-скрапингом в R
Начало работы с веб-скрапингом в R
Первым шагом станет обзор инструментов, которые мы будем использовать в этом учебнике по R.
Понимание инструментов: R и rvest
R — богатая и простая в использовании библиотека для статистического анализа и визуализации данных, которая предоставляет полезные инструменты для работы с данными и динамической типизацией.
rvest 一 от «harvest»一 один из самых популярных пакетов R, предоставляющий функции веб-скрапинга, в том числе и благодаря чрезвычайно удобному интерфейсу. Ванильный rvest позволяет извлекать данные только с одной веб-страницы, что идеально подходит для первоначального исследования. Впоследствии вы можете расширить его с помощью библиотеки polite для скрапинга большего количества веб-страниц.
Настройка среды разработки
Если вы еще не используете R в RStudio, следуйте приведенным здесь инструкциям по его установке.
После этого откройте консоль и установите rvest:
install.packages("rvest")
Официальная рекомендация заключается в расширении встроенных функций rvest за счет дополнительных пакетов из коллекции tidyverse — например, magrittr, который улучшает читабельность кода, или xml2, позволяющего работать с HTML и XML. Вы можете сделать это, установив tidyverse:
install.packages("tidyverse")Понимание веб-страницы
Веб-скрапинг — это технология получения данных с веб-сайтов в рамках соответствующих автоматизированных процессов.
Из этого определения вытекают три важных момента:
- Данные поступают в различных форматах.
- Сайты отображают информацию совершенно разными способами.
- Получаемые с помощью веб-скрапинга данные должны находиться в открытом доступе.
Чтобы понять, как выполнить веб-скрапинг целевого URL, сначала необходимо разобраться, как отображается содержимое веб-страницы с помощью языка разметки HTML и CSS.
HTML отвечает за содержание и структуру веб-страницы 一 язык разметки загружается в веб-браузер для создания древовидной объектной модели документа (DOM) 一 путем организации ее содержимого с помощью специальных тегов, которые имеют иерархическую структуру. Каждый из них обладает определенной функциональностью, применяемой ко всему содержимому, находящему внутри его открывающих (<>) и закрывающих угловых скобок (</>):
<!DOCTYPE html>
<html lang="en-gb" class="a-ws a-js a-audio a-video a-canvas a-svg a-drag-drop a-geolocation a-history a-webworker a-autofocus a-input-placeholder a-textarea-placeholder a-local-storage a-gradients a-transform3d -scrolling a-text-shadow a-text-stroke a-box-shadow a-border-radius a-border-image a-opacity a-transform a-transition a-ember" data-19ax5a9jf="dingo" data-aui-build-date="3.22.2-2022-12-01">
▶<head>..</head>
▶<body class="a-aui_72554-c a-aui_accordion_a11y_role_354025-c a-aui_killswitch_csa_logger_372963-c a-aui_launch_2021_ally_fixes_392482-t1 a-aui_pci_risk_banner_210084-c a-aui_preload_261698-c a-aui_rel_noreferrer_noopener_309527-c a-aui_template_weblab_cache_333406-c a-aui_tnr_v2_180836-c a-meter-animate" style="padding-bottom: 0px;">..</body>
</html>Тег <html> является обязательным элементом любой веб-страницы, внутри которого вложены еще два — <head> и <body>. Последние также являются родительскими для множества других тегов, среди которых самые популярные — это <div> (для секции документа) и <p> (для параграфа).
В приведенном выше фрагменте вы можете увидеть атрибуты, связанные с каждым HTML-элементом: lang, class и style создаются по умолчанию, тогда как атрибуты, которые начинаются с «data-» — являются на Amazon пользовательскими.
класс и атрибут id представляют особый интерес для веб-скрапинга, поскольку позволяют точно нацелиться на один или несколько элементов. Изначально они были внедрены для упрощения стилизации веб-страницы с помощью CSS.
CSS отвечает за внешнюю стилизацию веб-страницы. С его помощью можно выбрать конкретный элемент HTML и изменить его цвет, размер, позиционирование и любое другое свойство. Вы можете применить CSS-стиль непосредственно внутри целевого HTML-элемента, используя для этого специальный атрибут style, как показано в приведенном выше фрагменте:
<body .. style="padding-bottom: 0px;">На чистом CSS это будет выглядеть следующим образом:
body {padding-bottom: 0px;}
Здесь body — это выбранный селектор, padding-bottom — свойство, а 0px — его значение. Любой тег, класс или id может быть использован в качестве селектора CSS.
Интернет-пользователи могут динамически взаимодействовать с содержимым веб-страницы с помощью функций JavaScript благодаря внедрению в HTML-разметку специального тега script. После взаимодействия с пользователем отображаемое содержимое может измениться, а вместо него появится новое; продвинутые веб-скраперы могут имитировать действия реальных пользователей, о чем мы поговорим позже.
Понимание DevTools
Основные браузеры предоставляют встроенные инструменты разработчика, которые позволяют собирать и обновлять техническую информацию на веб-странице в режиме реального времени для ведения журнала, отладки, тестирования и анализа производительности. В этом учебнике мы будем использовать DevTools в Chrome.
Инструменты разработчика можно найти в настройках, которые открываются при нажатии на три вертикальные точки в верхнем правом углу браузера, в разделе «Дополнительные инструменты»:
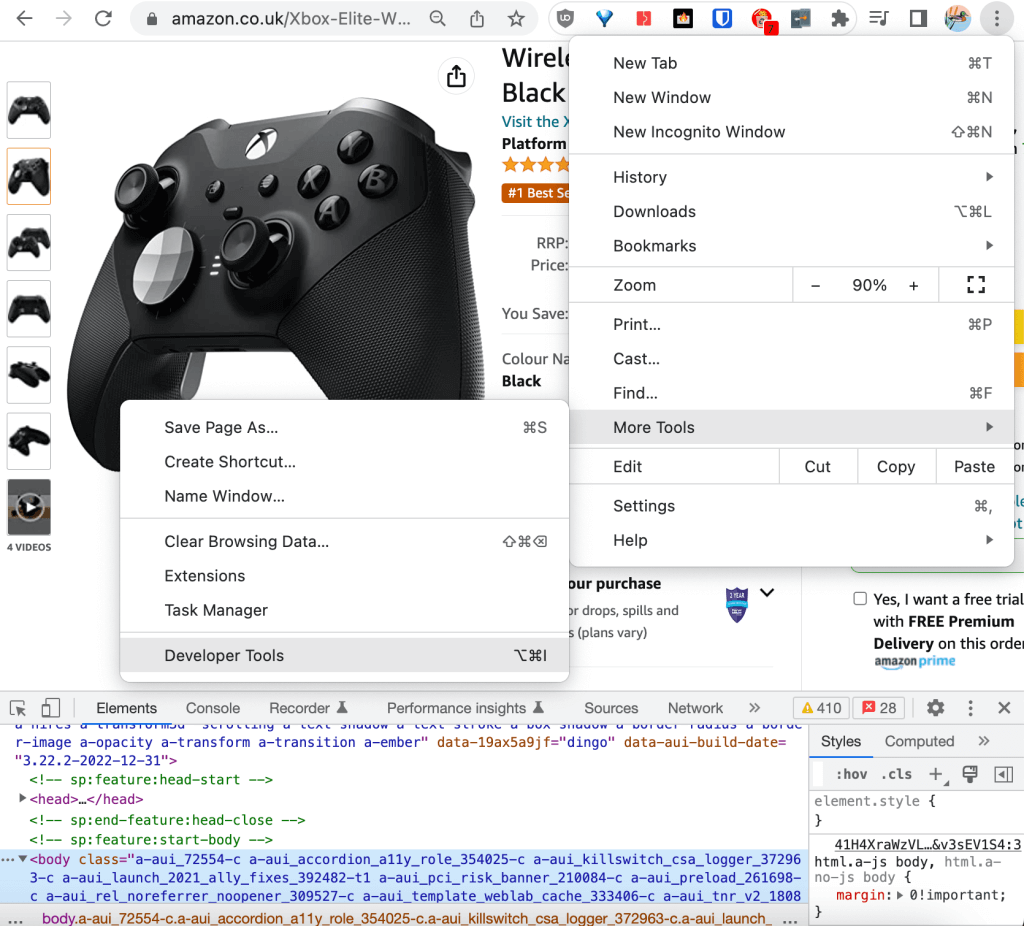
С помощью инструментов разработчика вы сможете увидеть во вкладке «Элементы» HTML-код веб-страницы. При наведении на любую из строк HTML-кода соответствующий ей элемент на веб-странице выделяется синим цветом:
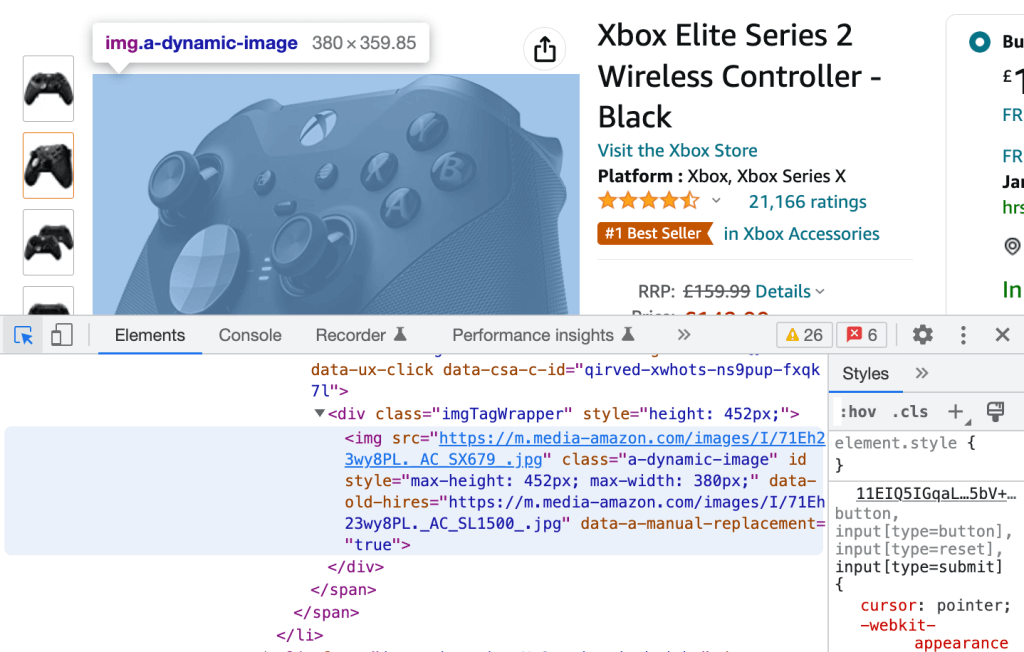
И наоборот, вы можете нажать на иконку в левом верхнем углу и выбрать любой визуализированный элемент веб-страницы, чтобы выделить отвечающий за него HTML-код, который также для удобства выделяется синим цветом.
Эти два процесса — все, что нужно, чтобы извлечь дескрипторы CSS для нашего практического руководства.
Глубокое погружение в веб-скрапинг в R: Учебник
В этом разделе мы рассмотрим, как выполнять веб-скрапинг URL-адресов Amazon для извлечения отзывов о товарах.
Предустановки
Убедитесь, что в среде Rstudio установлено следующее:
- R = 4.2.2
- rvest = 1.0.3
- tidyverse = 1.3.2
Интерактивное изучение веб-страницы
Вы можете использовать DevTools в Chrome для изучения HTML вашего URL и создания списка всех классов и идентификаторов HTML-элементов, которые содержат интересующую вас информацию, т.е. обзоры продуктов:

Каждый отзыв клиента располагается в div с id в следующем формате:
customer_review_$INTERNAL_ID.
Содержимое HTML-элемента div, соответствующее отзыву покупателя на скриншоте выше, выглядит следующим образом:
<div id="customer_review-R2U9LWUSIPY0GS" class="a-section celwidget" data-csa-c-id="kj23dv-axnw47-69iej3-apdvzi" data-cel-widget="customer_review-R2U9LWUSIPY0GS">
<div data-hook="genome-widget" class="a-row a-spacing-mini">..</div>
<div class="a-row">
<a class="a-link-normal" title="4.0 out of 5 stars" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<i data-hook="review-star-rating" class="a-icon a-icon-star a-star-4 review-rating">
<span class="a-icon-alt">4.0 out of 5 stars</span>
</i>
</a>
<span class="a-letter-space"></span>
<a data-hook="review-title" class="a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<span>Very good controller if a little overpriced</span>
</a>
</div>
<span data-hook="review-date" class="a-size-base a-color-secondary review-date">..</span>
<div class="a-row a-spacing-mini review-data review-format-strip">..</div>
<div class="a-row a-spacing-small review-data">
<span data-hook="review-body" class="a-size-base review-text">
<div data-a-expander-name="review_text_read_more" data-a-expander-collapsed-height="300" class="a-expander-collapsed-height a-row a-expander-container a-expander-partial-collapse-container" style="max-height:300px">
<div data-hook="review-collapsed" aria-expanded="false" class="a-expander-content reviewText review-text-content a-expander-partial-collapse-content">
<span>In all honesty I'm not sure why the price is quite as high ….</span>
</div>
…</div>
…</span>
…</div>
…</div>
Каждый интересующий вас фрагмент отзыва покупателя имеет свой уникальный класс: review-title-content для заголовка, review-text-content для основного текста и review-rating для рейтинга.
Можно проверить, является ли класс на веб-странице уникальным и, если да, то воспользоваться им в качестве «простого селектора». Однако более надежным способом является все же использование дескриптора CSS, который останется уникальным, даже если в будущем тот же класс будет присвоен и некоторым другим элементам веб-страницы.
Просто извлеките CSS-дескриптор, щелкнув правой кнопкой мыши по элементу в DevTools и выбрав Copy Selector:
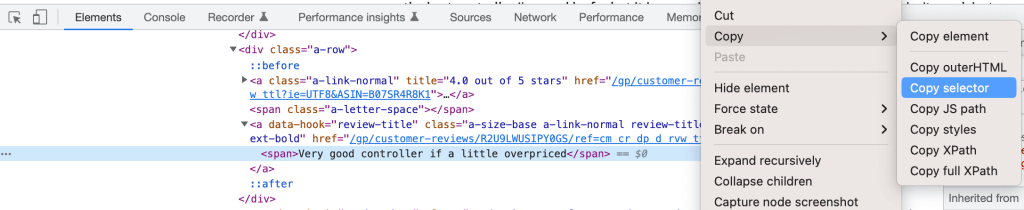
Вы можете определить свои три селектора следующим образом:
customer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold > spanдля titlecustomer_review-R2U9LWUSIPY0GS > div.a-row.a-spacing-small.review-data > span > div > div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content > spanдля bodycustomer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a:nth-child(1) > i.review-rating > spanдля rating *.review-ratingбыл добавлен вручную для лучшей согласованности.
CSS Selector vs XPath для веб-скрапинга
В этом учебнике мы решили использовать селектор CSS для идентификации элементов при веб-скрапинге. Другой популярный метод — использовать XPath, т.е. XML Path, который идентифицирует элемент через его полный путь в DOM.
Вы можете извлечь Xpath (полный путь к элементу в DOM), следуя той же процедуре, которая используется и для селекторов CSS. Например, название обзора является следующим:
/html/body/div[2]/div[3]/div[6]/div[32]/div/div/div[2]/div/div[2]/span[2]/div/div/div[3]/div[3]/div/div[1]/div/div/div[2]/a[2]/span
Селектор CSS чуть быстрее, а XPath имеет немного лучшую обратную совместимость. За исключением этих небольших различий, выбор одного из них зависит больше от личных предпочтений, чем от их технических преимуществ.
Программное извлечение информации с веб-страницы
Хотя мы могли бы использовать для изучения веб-скрапинга консоль напрямую, вместо этого создадим сценарий для отслеживания и воспроизведения, и запустим его через консоль с помощью команды source().
После создания скрипта первым шагом будет загрузка установленных библиотек:
library(”rvest”)
library(”tidyverse”)После этого вы можете программно извлечь интересующий вас контент следующим образом. Сначала создайте переменную, в которой будет храниться URL для поиска:
HtmlLink <- "https://www.amazon.co.uk/Xbox-Elite-Wireless-Controller-2/dp/B07SR4R8K1/ref=sr_1_1_sspa?crid=3F4M36E0LDQF3"
Затем извлеките стандартный идентификационный номер Amazon (ASIN) из URL-адреса, чтобы использовать его в качестве уникального идентификатора продукта:
ASIN <- str_match(HtmlLink, "/dp/([A-Za-z0-9]+)/")[,2]
Использование RegEx для очистки извлеченного с помощью веб-скрапинга текста является рекомендуемой мерой, способной обеспечить надлежащее качество извлекаемых данных.
Теперь загрузите HTML-контент веб-страницы:
HTMLContent <- read_html(HtmlLink)
Функция read_html() является частью пакета xml2.
Если вы выведете контент с помощью функции print(), мы увидим, что он соответствует проанализированной нами ранее структуре HTML:
{html_document}
<html lang="en-gb" class="a-no-js" data-19ax5a9jf="dingo">
[1] <head>n<meta http-equiv="Content-Type" content="text/ht ...
[2] <body class="a-aui_72554-c a-aui_accordion_a11y_role_354 ...
Теперь вы можете извлечь три интересующих вас узла для всех отзывов о товаре на странице. Используйте дескрипторы CSS, предоставленные инструментами разработчика в Chrome и модифицированные для удаления идентификатора отзыва покупателя #customer_review-R2U9LWUSIPY0GS и соединителя «>» из строки; вы также можете воспользоваться функциями html_nodes() и html_text() в rvest для сохранения HTML-контента в отдельных объектах.
Следующие команды извлекут заголовки обзоров:
review_title <- HTMLContent %>%
html_nodes("div:nth-child(2) a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold span") %>%
html_text()
Пример записи в review_title: «Очень хороший контроллер, хотя цена немного завышена».
Приведенный ниже код извлечет «тело» обзора:
review_body <- HTMLContent %>%
html_nodes("div.a-row.a-spacing-small.review-data span div div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content span") %>%
html_text()
Пример записи в review_body начинается со слов “Честно говоря, я не уверен, почему цена…”.
И вы можете использовать следующие команды для извлечения рейтинга обзора:
review_rating <- HTMLContent %>%
html_nodes("div:nth-child(2) a:nth-child(1) i.review-rating span") %>%
html_text()
Примером записи в review_rating является «4,0 из 5 звезд».
Чтобы улучшить качество этой переменной, извлеките только оценку «4.0» и преобразуйте ее в int:
review_rating <- substr(review_rating, 1, 3) %>% as.integer()
Функция %>% обеспечивается за счет использования magrittr.
Настало время для экспорта полученного с помощью веб-скапинга контента в tibble для анализа данных. tibble представляет собой пакет R, который также входит в коллекцию tidyverse и используется для манипулирования и печати фреймов данных.
df <- tibble(review_title, review_body, review_rating)
Итоговый фрейм данных выглядит следующим образом:

Наконец, отличной идеей будет рефакторинг кода в функцию scrape_amazon <- function(HtmlLink), что позволит привести его в соответствие к лучшим современным практикам и оптимизировать для масштабирования сразу на несколько целевых URL.
Масштабирование на несколько URL-адресов
После составления скрапинг-шаблона вы можете создать с помощью веб-краулинга и веб-скрапинга список URL-адресов всех продуктов главных конкурентов на Amazon.
При масштабировании на несколько URL-адресов необходимо описать технические требования приложения.
Наличие четко сформулированных технических требований обеспечит вам правильную поддержку бизнес-требований и беспрепятственную интеграцию с существующими системами.
В зависимости от конкретных технических требований, функция скрапбукинга должна быть обновлена для поддержки следующего функционала:
- Пакетно или в режиме реального времени
- Формат(ы) вывода, например, JSON, NDJSON, CSV или XLSX
- Цель(и) вывода, например, электронная почта, API, webhook или облачное хранилище
Мы уже упоминали, что вы можете расширить возможности rvest с помощью polite для веб-скрапинга сразу нескольких интернет-страниц. polite создает и управляет сеансом сбора данных с веб-страниц при помощи трех основных функций, в полном соответствии с файлом robots.txt веб хоста, с использованием встроенного ограничителя скорости и кэшированием ответов:
bow()создает сессию по сбору данных для определенного URL, т.е. представляет вас веб-хосту и запрашивает разрешение на веб-скрапинг.scrape()получает доступ к HTML-коду URL-адреса; вы можете передать эту функцию из rvest вhtml_nodes()иhtml_text(), чтобы получить необходимый контент.nod()обновляет URL сессии до следующей страницы без необходимости заново создавать сессию.
Цитирую непосредственно с их сайта: «Три главных правила вежливого сеанса — спрашивать разрешение, не спешить и никогда не просить дважды».
Следующий шаг: Pre-Built vs. Self-Built?
Чтобы разработать современный веб-скрапер, способный извлекать полезные для бизнеса данные, необходимо иметь следующие возможности:
- Команда специалистов с большим опытом извлечения данных
- Команда инженеров DevOps с большим опытом управления прокси и обхода антиботов, позволяющим преодолевать любую CAPTCHA-защиту и работать с сайтами с ограниченным доступом.
- Команда инженеров с опытом создания инфраструктуры по извлечению данных — пакетному или в режиме реального времени
- Команда экспертов в области права в сфере законодательных требований по защите конфиденциальной информации (таких как GDPR и CCPA)
Интернет-контент имеет разные форматы, из-за чего трудно найти даже всего два сайта с абсолютно одинаковой структурой. Чем он сложнее и чем больше данных необходимо из него извлечь, тем более глубокие необходимы познания в программировании, не говоря уже о дополнительном времени и ресурсах, которые потребуются для решения проблемы.
Как правило, пользователи прибегают к использованию следующего продвинутого функционала:
- Минимизируйте вероятность CAPTCHA и обнаружения ботов: Самый простой подход здесь — добавление случайного sleep(), чтобы избежать перегрузки веб-серверов и стандартных шаблонов запросов. Наиболее же эффективным подходом считается использование user_agent или прокси-сервера для распределения запросов между различными IP.
- Веб-скрапинг сайтов с использованием Javascript: В нашем примере с Amazon URL-адрес не меняется при выборе конкретного варианта товара. Это приемлемо для отзывов, поскольку они являются общими, но не для характеристик продукта. Чтобы имитировать взаимодействие пользователей на динамических веб-страницах, можно использовать такой инструмент, как RSelenium, который позволяет автоматизировать навигацию по веб-браузеру.
Если необходимо получить данные из ресурсов с ограниченным доступом, обеспечить их надлежащее качество или воспользоваться более сложными сценариями, оптимальным вариантом станет созданный профессиональным программистом готовый веб-скрапер.
Web Scraper от Bright Data предоставляет шаблоны для множества веб-сайтов, оснащенных самыми современными функциями, включая продвинутый Amazon Scraper!





