

TL; DR: Из этого урока вы узнаете, как извлекать данные с сайта на языке C++ и почему это один из самых эффективных языков для скрейпинга.
В данном руководстве будут рассмотрены следующие темы:
- Является ли C++ хорошим языком для веб-скрейпинга?
- Лучшие библиотеки для веб-скрейпинга на C++
- Как создать веб-скрейпер на C++
Является ли C++ хорошим языком для веб-скрейпинга?
C++ — язык программирования со статической типизацией, который широко используется для разработки высокопроизводительных приложений. Это связано с тем, что он хорошо известен своей скоростью, эффективностью и возможностями управления памятью. C++ — это универсальный язык, который удобен в широком спектре приложений, включая веб-скрейпинг.
C++ — это компилируемый язык, который по своей природе быстрее интерпретируемых языков, таких как Python. Это делает его отличным выбором для изготовления быстрых скрейперов. Однако C++ не предназначен для веб-разработки, и для веб-скрейпинга доступно не так много библиотек. Хотя существует несколько сторонних пакетов, их возможности не так обширны, как в Python, Ruby или Java.
Таким образом, веб-скрейпинг на C++ возможен и эффективен, но требует более низкоуровневого программирования по сравнению с другими языками. Давайте узнаем, какие инструменты могут облегчить этот процесс!
Лучшие библиотеки для веб-скрейпинга на C++
Вот несколько популярных библиотек для веб-скрейпинга для языка C++:
- CPR: современная клиентская библиотека HTTP для языка C++, вдохновленная проектом Python Requests. Это оболочка libcurl , которая обеспечивает простой для понимания интерфейс, встроенные возможности аутентификации и поддержку асинхронных вызовов.
- libxml2: мощная и полнофункциональная библиотека для анализа документов XML и HTML, изначально разработанная для Gnome. Она поддерживает управление DOM с помощью селекторов XPath.
- Lexbor: быстрая и легкая библиотека для скрейпинга HTML, полностью написанная на языке C с поддержкой селекторов CSS. Она доступна только для Linux.
В течение многих лет наиболее широко используемым скрейпером HTML для C++ был Gumbo. Он не поддерживается с 2016 года, и даже официальный README теперь не рекомендует его использовать.
Предварительные условия
Прежде чем погрузиться в программирование, вам необходимо:
Следуйте приведенному ниже руководству для вашей операционной системы и узнайте, как выполнить эти требования.
Настройка C++ на macOS
В macOS самым популярным компилятором C, C++ и Objective-C является Clang. Имейте в виду, что Clang предустановлен на многих компьютерах Mac. Чтобы убедиться в этом, откройте терминал и выполните следующую команду:
clang --version
Если возникает ошибка command not found: clang («команда не найдена: clang»), это означает, что Clang установлен или настроен неправильно. В этом случае вы можете установить его с помощью инструментов командной строки Xcode:
xcode-select --install
Это может занять некоторое время, поэтому наберитесь терпения.
Чтобы настроить vcpkg, сначала понадобятся инструменты разработчика macOS. Добавьте их на свой Mac с помощью:
xcode-select --install
Затем вам необходимо установить vcpkg глобально. Создайте папку /dev , введите ее в терминале и запустите:
git clone https://github.com/microsoft/vcpkg
Теперь каталог будет содержать исходный код. Создайте менеджер пакетов с помощью:
./vcpkg/bootstrap-vcpkg.sh
Для выполнения этой команды вам могут понадобиться повышенные привилегии.
Наконец, добавьте /dev/vcpkg в свой $PATH , следуя этому руководству.
Чтобы установить CMake, скачайте программу установки с официального сайта, запустите ее и следуйте указаниям мастера установки.
Настройка C++ в Windows
Загрузите программу установки MinGW-x64 из набора утилит и библиотекMSYS2, запустите ее и следуйте инструкциям. Этот пакет содержит новейшие нативные сборки GCC, Mingw-w64 и других полезных инструментов и библиотек C++.
В терминале MSYS2, открывающемся в конце процесса установки, выполните следующую команду для установки набора инструментов Mingw-w64:
pacman -S --needed base-devel mingw-w64-x86_64-toolchain
Дождитесь окончания процесса и добавьте MinGW в окружение PATH , как описано здесь.
Затем вам необходимо установить vcpkg глобально. Создайте папку C:/dev , откройте ее в PowerShell и выполните команду:
git clone https://github.com/microsoft/vcpkg
Создайте исходный код менеджера пакетов, содержащийся в подпапке vcpkg , используя:
./vcpkg/bootstrap-vcpkg.bat
Теперь добавьте C:/dev/vcpkg в свой PATH , как это было сделано ранее.
Осталось только установить CMake. Загрузите программу установки, дважды щелкните по ней и обязательно выберите опцию ниже во время установки.

Настройка C++ в Linux
В дистрибутивах на основе Debian установите GCC (коллекция компиляторов GNU), CMake и другие полезные пакеты для разработки, используя:
sudo apt install build-essential cmake
Это может занять некоторое время, поэтому наберитесь терпения.
Затем вам необходимо глобально установить vcpkg. Создайте каталог /dev , откройте его в терминале и введите:
git clone https://github.com/microsoft/vcpkg
Подкаталог vcpkg теперь будет содержать исходный код менеджера пакетов. Создайте инструмент с помощью:
./vcpkg/bootstrap-vcpkg.sh
Обратите внимание, что для выполнения этой команды могут потребоваться права администратора.
Затем добавьте /dev/vcpkg в переменную окружения $PATH , следуя этому руководству.
Великолепно! Теперь у вас есть все необходимое для начала работы с веб-скрейпингом на C++!
Как создать веб-скрейпер на C++
В этой главе вы узнаете, как написать код веб-паука на языке C++. Целевым сайтом будет домашняя страница Bright Data, а скрипт позаботится о следующем:
- Подключение к веб-странице
- Выбор интересующих HTML-элементов из DOM
- Получение данных из них
- Экспорт данных, полученных в результате скрейпинга, в CSV
Прямо сейчас, просматривая целевую страницу, посетители видят следующее:
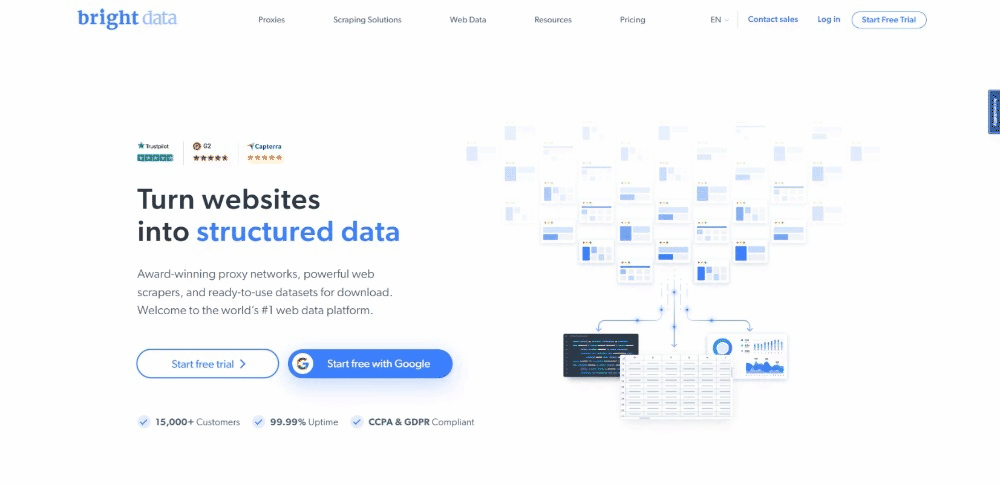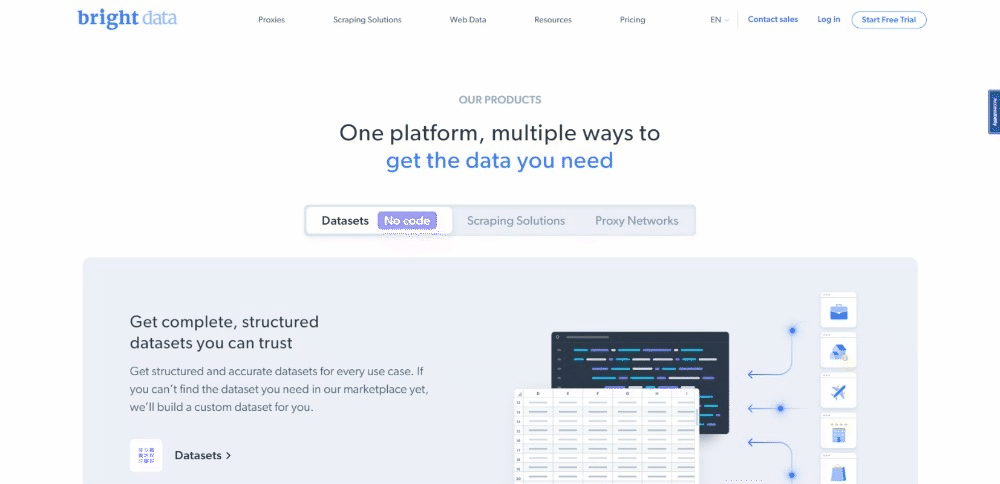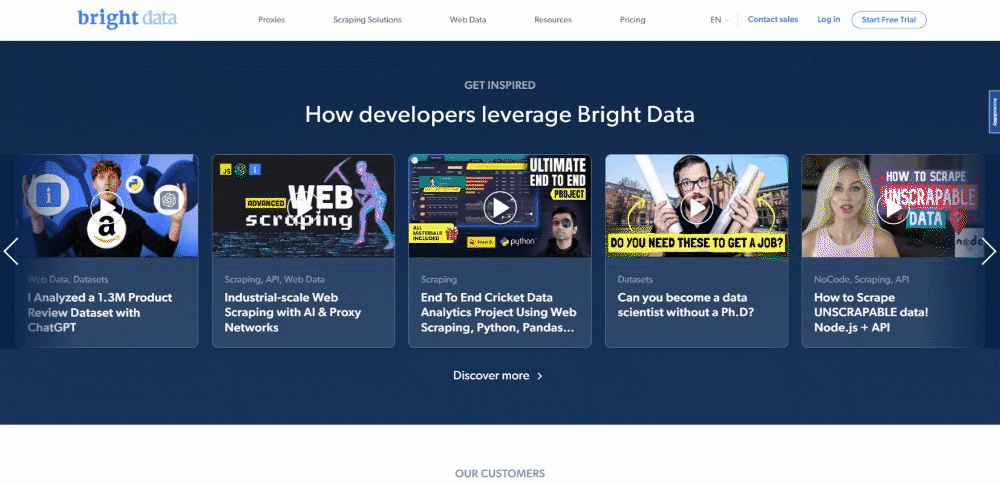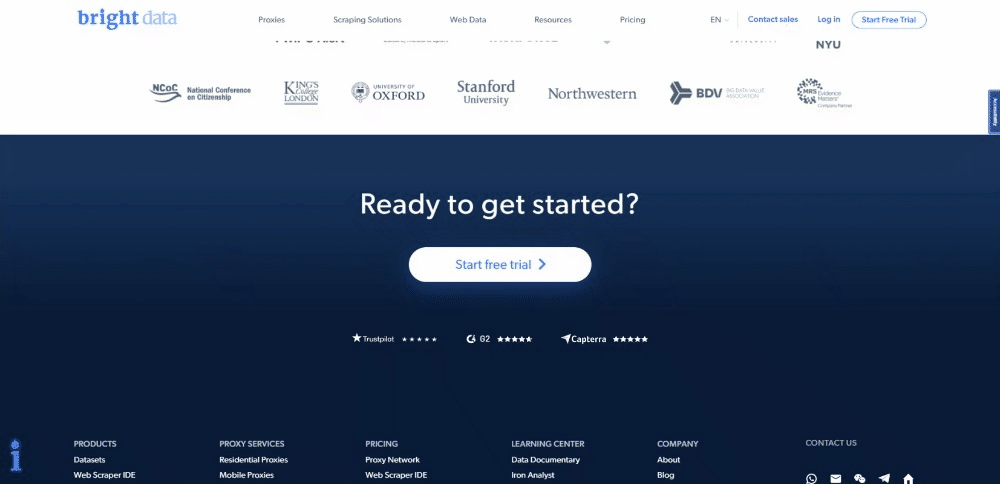
Помните, что домашняя страница Bright Data часто меняется. Так что, возможно, к тому времени, как вы прочтете эту статью, все может измениться.
Интересной информацией, которую можно почерпнуть на этой странице, является отраслевая информация, содержащаяся в этих карточках:

Цель скрейпинга для этого пошагового руководства определена. Давайте посмотрим, как выполнять веб-скрейпинг с помощью C++!
Шаг 1. Инициализация проекта скрейпинга на C++
Во-первых, вам нужна папка для размещения проекта на C++. Откройте терминал и создайте директорию проекта с помощью:
mkdir c++-web-scraper
Здесь будет ваш сценарий скрейпинга.
При создании программного обеспечения на языке C++ следует выбрать Visual Studio IDE. В частности, вы узнаете, как настроить Visual Studio Code (VS Code) для разработки на C++, используя vcpkg в качестве менеджера пакетов. Обратите внимание, что аналогичные процедуры можно применять к другим IDE для C++.
VS Code не предлагает встроенной поддержки C++, поэтому сначала нужно добавить плагин C/C++ . Запустите Visual Studio Code, нажмите значок «Расширения» на левой панели и введите «C++» в поле поиска вверху.

Нажмите кнопку «Установить» в первом элементе, чтобы добавить функциональность разработки на C++ в VS Code. Дождитесь установки расширения, после чего откройте папку c++-web-scraper помощью команды «``File``» > «``Open Folder...``».
Щелкните правой кнопкой мыши в разделе «EXPLORER», выберите «Новый файл…» и инициализируйте файл scraper.cpp следующим образом:
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}

Теперь у вас есть проект на C++!
Шаг 2. Установите библиотеки скрейпинга
Громоздкий синтаксис C++ и его ограниченные веб-возможности могут стать препятствием при создании веб-скрейпера. Чтобы упростить задачу, вам следует использовать некоторые библиотеки C++ для веб-скрейпинга. Как упоминалось ранее, выбор довольно ограничен. Таким образом, вам следует выбрать самые популярные из них: cpr и libxml2.
Вы можете установить их в Windows через vcpkg с помощью:
vcpkg install cpr libxml2 --triplet=x64-windows
В macOS замените опцию триплета на x64-osx . В Linux используйте x64-linux.
В терминале Visual Studio Code вам также необходимо выполнить следующую команду в корневом каталоге вашего проекта:
vcpkg integrate install
Это позволит связать пакеты vcpkg с проектом.
Перезапустите VS Code, и теперь вы можете импортировать любую установленную библиотеку с помощью #include. Итак, добавьте следующие три строки поверх файла scraper.cpp :
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
Убедитесь, что IDE не сообщает об ошибках.
Шаг 3. Завершите инициализацию проекта C++
Чтобы создать сценарий скрейпинга на C++ и завершить процесс инициализации проекта, вам необходимо добавить расширение CMake Tools в VS Code:

Если в вашем проекте нет папки .vscode , создайте ее. В ней VS Code ищет конфигурации, связанные с текущим проектом.
Настройте инструменты CMake для использования vcpkg в качестве набора инструментов, создав файл settings.json в папке .vscode следующим образом:
{
"cmake.configureSettings": {
"CMAKE_TOOLCHAIN_FILE": "c:/dev/vcpkg/scripts/buildsystems/vcpkg.cmake"
}
}
В macOS и Linux исправьте поле CMAKE_TOOLCHAIN_FILE в соответствии с путем, по которому вы установили vcpkg . Если вы следовали приведенному выше руководству по установке, этот путь должен выглядеть как /dev/vcpkg/scripts/buildsystems/vcpkg.cmake.
В главной строке поиска VS Code введите «>cmake» и выберите опцию «CMake: Configure»:

Это позволит вам выбрать целевую платформу компиляции. В Windows выберите «Visual Studio Build Tools 2019 Release (Средства сборки Visual Studio 2019 года выпуска) — x86_amd64»:

Добавьте файл CMakeLists.txt в корневую папку проекта для настройки CMake:
cmake_minimum_required(VERSION 3.0.0)
project(main VERSION 0.1.0)
INCLUDE_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/include
)
LINK_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/lib
)
add_executable(main scraper.cpp)
target_compile_features(main PRIVATE cxx_std_20)
find_package(cpr CONFIG REQUIRED)
target_link_libraries(main PRIVATE cpr::cpr)
find_package(LibXml2 REQUIRED)
target_link_libraries(main PRIVATE LibXml2::LibXml2)
Обратите внимание, что речь идет о двух пакетах, установленных ранее. Обязательно обновите INCLUDE_DIRECTORIES и LINK_DIRECTORIES в соответствии с вашей установочной папкой vcpkg .
Чтобы Visual Studio Code мог запускать программу на языке C++, вам нужен файл конфигурации запуска. В папке .vscode инициализируйте launch.json , как показано ниже:
{
"configurations": [
{
"name": "C++ Launch (Windows)",
"type": "cppvsdbg",
"request": "launch",
"program": "${workspaceFolder}/build/Debug/main.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": []
}
]
}
Теперь при запуске команды запуска или отладки VS Code запустит файл по пути программы , созданному CMake. Обратите внимание, что в macOS и Linux это не будет файл .exe .
Конфигурация готова!
Каждый раз, когда вы хотите отладить или создать приложение, введите «>cmake: Build» в верхнем поле ввода и выберите опцию «CMake: Build».

Дождитесь окончания процесса сборки и запустите скомпилированную программу из раздела «Run & Debug» или нажав клавишу F5. Результат работы приложения вы увидите в консоли отладки VSC.

Прекрасно! Пришло время приступить к скрейпингу некоторых данных на языке C++!
Шаг 4. Загрузите целевую страницу с помощью CPR
Если вы хотите извлечь данные со страницы, сначала необходимо получить ее HTML-документ с помощью HTTP-запроса GET .
Используйте CPR для загрузки целевой страницы с помощью:
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"});
За кулисами метод Get () выполняет запрос GET на URL-адрес, переданный в качестве параметра. response.text будет содержать строковое представление HTML-кода, возвращенного сервером.
Обратите внимание, что выполнение автоматических HTTP-запросов может запустить технологии защиты от ботов. Они могут перехватывать ваши запросы и препятствовать доступу вашего сценария к целевому сайту. В частности, самые простые решения для защиты от скрейпинга блокируют входящие запросы без действительного HTTP-заголовка User-Agent . Узнайте больше в нашем руководстве по применению User-Agentдля скрейпинга веб-страниц.
Как и любой другой HTTP-клиент, CPR использует значение-заполнитель для User-Agent. Поскольку эти агенты сильно отличаются от агентов, используемых в популярных браузерах, системы защиты от ботов могут легко вас обнаружить. Чтобы избежать блокировки по этой причине, вы можете установить действительный User-Agent в CPR с помощью:
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/121.21.21.da/31/3das/32/1"}, headers);
HTTP-запрос, отправленный с помощью Get () , теперь будет отображаться как исходящий из Google Chrome 113.
Это то, что в настоящее время содержит scraper.cpp :
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make the HTTP request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// scraping logic...
}
Шаг 5: анализ содержимого HTML с помощью libxml2
Чтобы HTML-документ, возвращаемый сервером, можно было легко изучить, сначала его следует проанализировать.
Передайте строковое представление на языке C в функцию libxml2 htmlReadMemory () , чтобы получить следующее:
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
Переменная doc теперь предоставляет API исследования DOM, предлагаемый libxml2. В частности, вы можете извлекать HTML-элементы на странице с помощью селекторов XPath. На момент написания статьи libxml2 не поддерживает селекторы CSS.
Шаг 6. Определите селекторы XPath для получения нужных HTML-элементов
Чтобы определить эффективную стратегию выбора XPath для интересующих HTML-узлов, необходимо проанализировать DOM целевой страницы. Откройте домашнюю страницу Bright Data в браузере, щелкните правой кнопкой мыши на одной из отраслевых карт и выберите «Проверить». Откроется раздел DevTools:

Изучите HTML-код, и вы заметите, что каждая отраслевая карта представляет собой элемент <div> , содержащий:
- Элемент
<figure>с<img>, представляющим изображение отрасли, и<a>, содержащим URL-адрес отраслевой страницы. - HTML-элемент
<div>, хранящий название отрасли в формате<a>.
Для каждой карты цель скрейпера C++ состоит в том, чтобы извлечь:
- URL-адрес используемого в отрасли изображения
- URL-адрес отраслевой страницы
- Название отрасли
Чтобы правильно определить селекторы XPath, обратите внимание на структуру DOM интересующих элементов. Вы заметите, что можете получить все отраслевые карты с помощью селектора XPath ниже:
//div[contains(@class, 'section_cases_row_col_item')]
Если у вас есть сомнения, протестируйте инструкции XPath в консоли браузера с помощью $x ():

При наличии карты вы можете получить нужные узлы с помощью:
.//figure/a/img.//figure/a.//div[contains(@class, 'elementor-image-box-title')]/a
Шаг 7. Выполните скрейпинг данных с веб-страницы с помощью libxml2
Теперь вы можете использовать libxml2 для применения ранее определенных селекторов XPath и получения нужных данных с целевой веб-страницы HTML.
Во-первых, вам нужна структура данных, в инстансах которой будут храниться данные, полученные в результате скрейпинга:
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
В языке C++ структура позволяет объединить несколько атрибутов данных под одним именем в блок памяти.
Затем инициализируйте массив IndustryCard в функции main () :
std::vector<IndustryCard> industry_cards;
Здесь будут сохранены все объекты данных, полученные в результате скрейпинга.
Заполните этот вектор следующей логикой веб-скрейпинга на C++:
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
В приведенном выше фрагменте отраслевые карты выбираются с помощью селектора XPath, определенного ранее с помощью xMLXPathevalExpression (). Затем выполняется их итерация и применяется аналогичный подход для извлечения из каждой карты интересующих дочерних элементов. Затем из них удаляется URL-адрес используемого в отрасли изображения, URL-адрес страницы и название. Наконец, высвобождаются ресурсы, выделенные libxml2.
Как вы можете видеть, веб-скрейпинг с помощью C++ с libxml2 не так уж сложен. Благодаря функциям xmlGetProp () и xmlNodeGetContent () вы можете получить значение атрибута HTML и, соответственно, содержимое узла.
Теперь, когда вы знаете, как работает скрейпинг данных в C++, у вас есть инструменты, позволяющие сделать следующий шаг и приступить к скрейпингу отраслевых страниц. Вам нужно только перейти по ссылкам, найденным здесь, и создать новую логику скрейпинга. В этом и заключается суть сканирования и скрейпинга веб-страниц!
Потрясающе! Вы только что достигли своих целей. Однако урок еще не закончен.
Шаг 7. Экспорт данных, полученных в результате скрейпинга, в CSV
В конце цикла for() массив industry_cards сохранит данные, полученные в результате скрейпинга, в инстансах структуры . Как вы понимаете, это не лучший формат для предоставления данных другим командам. Вот почему вы должны преобразовать полученные данные в CSV.
Вы можете экспортировать вектор в CSV-файл с помощью встроенных функций C++ следующим образом:
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
Приведенный выше код создает файл output.csv и инициализирует его записью заголовка. Затем выполняется итерация по массиву industry_cards , преобразует каждый элемент в строку в формате CSV и добавляет ее в выходной файл.
Создайте сценарий для скрейпинга с помощью C++, запустите его, и вы увидите следующий файл output.csv в корневом каталоге проекта:

Отлично! Теперь вы знаете, как экспортировать в CSV данные, полученные в результате скрейпинга, на C++!
Шаг 8. Соберите все воедино
Вот весь скрейпер на C++:
// scraper.cpp
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
#include <vector>
// define a struct where to store the scraped data
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make an HTTP GET request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// parse the HTML document returned by the server
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
return 0;
}
Все готово! Используя примерно 80 строк кода, вы можете создать сценарий скрейпинга данных на языке C++!
Заключение
Из этого урока мы узнали, почему C++ является эффективным языком для скрейпинга веб-страниц. Хотя библиотек для скрейпинга не так много, как на других языках, они все же есть. И здесь у вас была возможность увидеть, какие из них самые популярные. Затем вы рассмотрели, как использовать CPR и libxml2 для создания паука на языке C++, который может собирать данные от реальной цели.
Однако при веб-скрейпингевозникает множество проблем. На самом деле, все больше сайтов внедряют технологии защиты от ботов и скрейпинга для защиты своих данных. Эти инструменты могут обнаруживать автоматические запросы, выполняемые вашим сценарием скрейпинга на C++, и блокировать их. К счастью, существует множество автоматизированных решений для сбора данных. Свяжитесь с нами, чтобы узнать, какое решение лучше всего подходит для вашего варианта использования.
Совсем не хотите заниматься веб-скрейпингом, но интересуетесь веб-данными? Ознакомьтесь с нашими готовыми к использованию наборами данных.





