

Режим искусственного интеллекта Google представляет собой фундаментальный сдвиг в представлении результатов поиска, предлагая разговорные ответы на основе искусственного интеллекта, которые синтезируют информацию из нескольких источников. Для компаний, отслеживающих свое цифровое присутствие, команд конкурентной разведки и SEO-специалистов этот новый формат поиска создает как возможности, так и проблемы для извлечения данных.
В этом подробном руководстве рассказывается о том, что такое режим искусственного интеллекта Google, почему поиск этих данных обеспечивает стратегическую ценность для бизнеса, с какими техническими проблемами вы столкнетесь, а также о ручных и автоматизированных подходах к эффективному извлечению этой информации в масштабе.
Что такое режим искусственного интеллекта Google?
Режим искусственного интеллекта Google – это новый поисковый опыт Google, который предоставляет синтезированные, разговорные ответы в верхней части результатов, позволяя пользователям задавать последующие вопросы естественным образом. Каждый ответ содержит заметные ссылки на источник, что позволяет легко перейти к основному содержанию.
Под капотом AI Mode использует Gemini наряду с поисковыми системами Google, применяя подход “веерной обработки запросов”. Эта техника разбивает вопросы на подтемы и параллельно запускает несколько связанных между собой поисковых запросов, что позволяет получить больше релевантного материала, чем можно получить с помощью традиционных одиночных запросов.
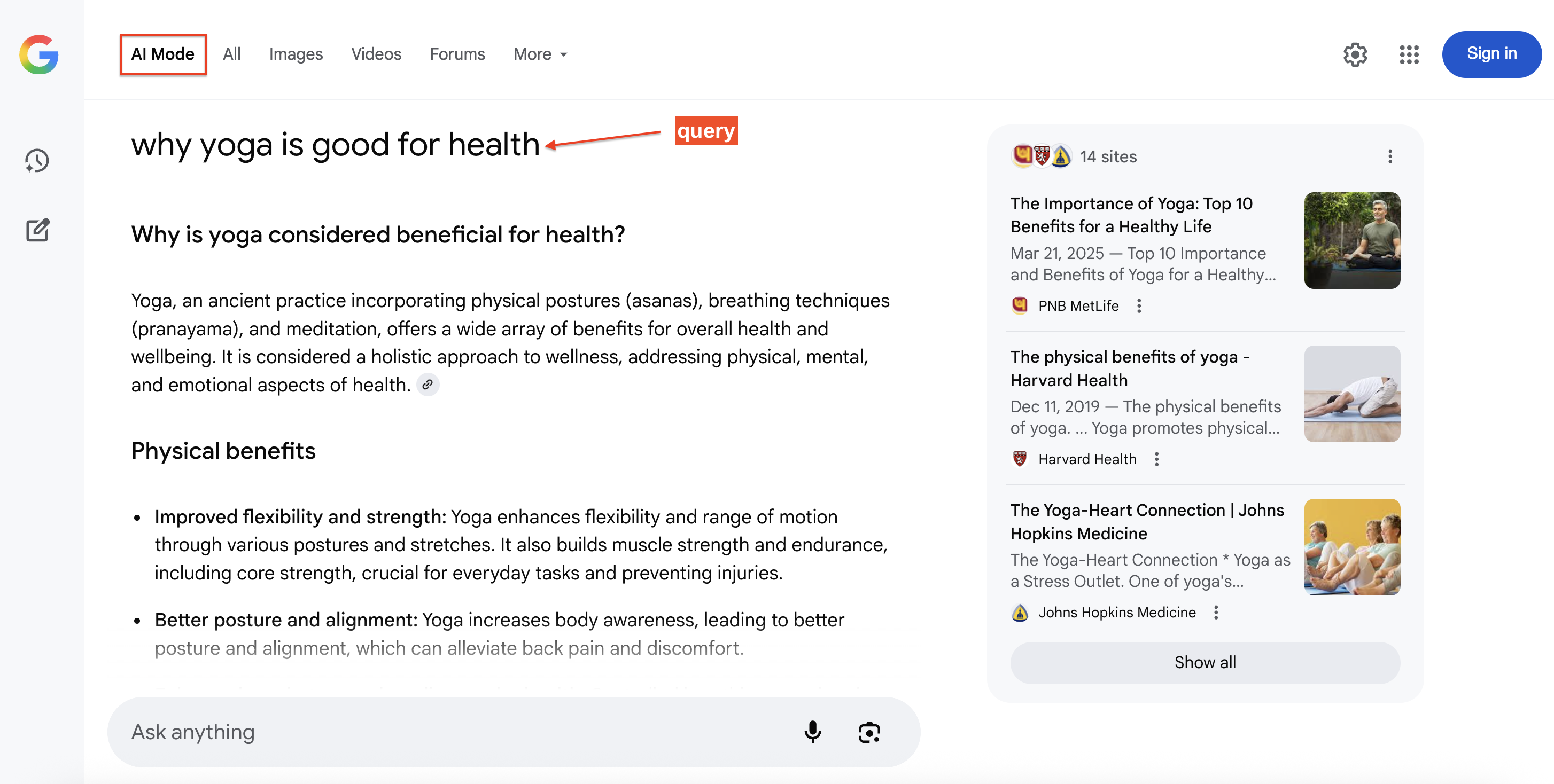
Вот пример ответа Google AI Mode на поисковый запрос со ссылками на источники (справа), на которые пользователи могут нажать для получения дополнительной информации:
Зачем соскабливать данные Google AI Mode?
Данные Google AI Mode предоставляют измеримые сведения, которые существенно влияют на SEO, разработку продуктов и исследования конкурентов.
- Отслеживание доли цитирования. Отслеживайте, на какие домены ссылается Google AI по вашим целевым запросам, включая порядок ранжирования и частоту с течением времени. Это свидетельствует об авторитетности тематики и помогает определить, приводит ли улучшение контента к увеличению количества ответов ИИ.
- Конкурентная разведка. Отслеживайте, какие бренды, продукты или местоположения появляются в рекомендательных и сравнительных запросах. Это позволяет выявить позиционирование на рынке, динамику конкуренции и атрибуты, на которых акцентируют внимание ответы ИИ.
- Анализ пробелов в контенте. Сравните ключевые факты в ответах AI Mode с существующим контентом, чтобы выявить возможности для создания структурированного контента, например часто задаваемых вопросов, руководств или таблиц данных, на которые можно ссылаться.
- Мониторинг бренда. Проанализируйте ответы ИИ о вашем бренде или отрасли, чтобы выявить устаревшую информацию и соответствующим образом обновить контент.
- Исследования и разработки. Храните ответы режима ИИ с метаданными (временные метки, местоположение, субъекты), чтобы использовать их во внутренних системах ИИ, поддерживать исследовательские команды и улучшать приложения RAG.
Метод 1 – ручной скраппинг с автоматизацией в браузере
Скраппинг Google AI Mode требует сложной автоматизации браузера из-за динамичного, насыщенного JavaScript характера контента, генерируемого искусственным интеллектом. Системы автоматизации браузера, такие как Playwright, Selenium или Puppeteer, используют реальные браузерные движки для выполнения JavaScript, ожидания загрузки контента и воспроизведения человеческого опыта просмотра веб-страниц – это важно для захвата динамически генерируемых ответов ИИ.
Вот как режим искусственного интеллекта Google отображается в результатах поиска:
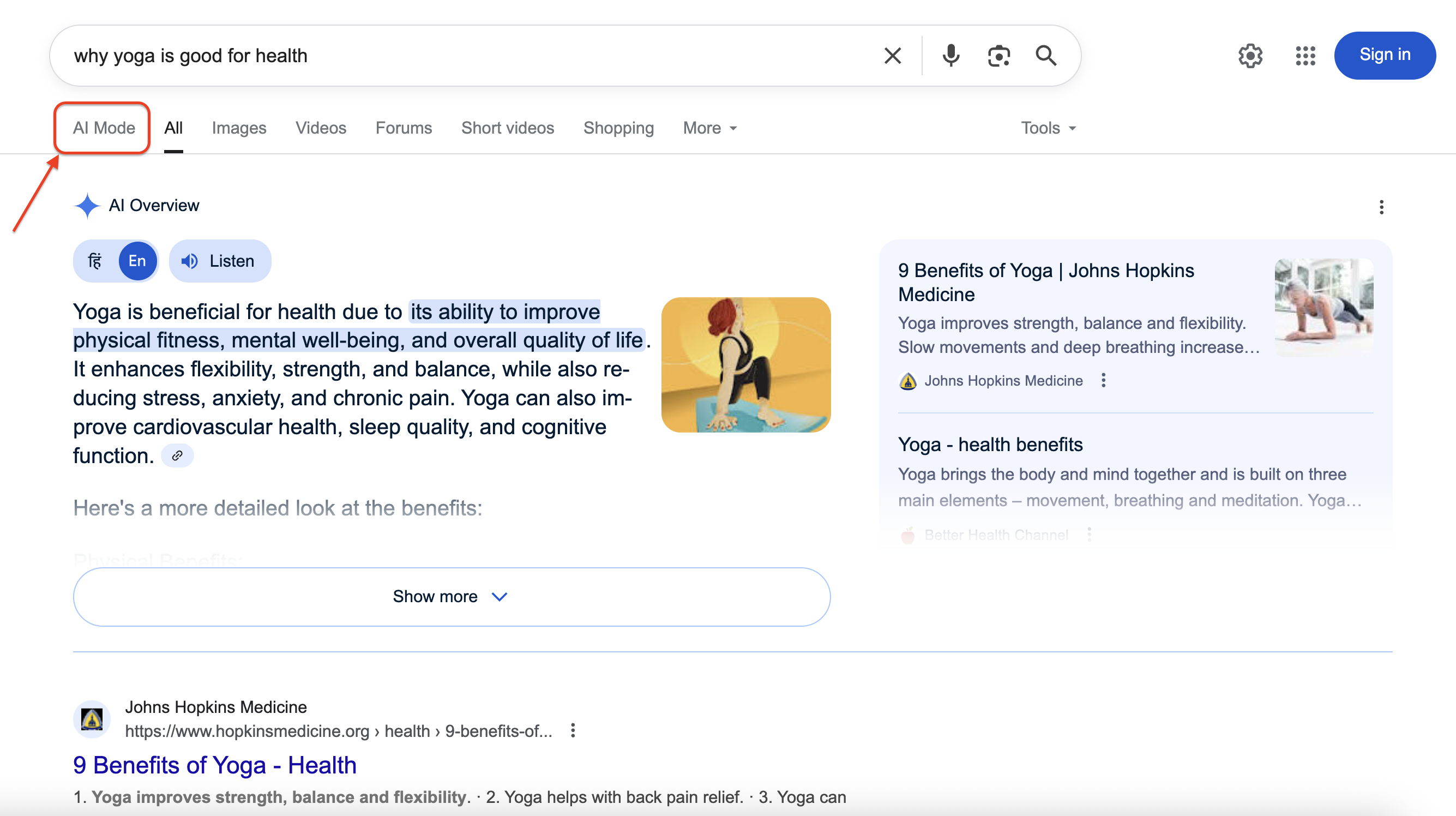
При нажатии на кнопку AI Mode открывается полный разговорный интерфейс с подробными ответами и ссылками на источники. Наша цель – программно получить доступ и извлечь эту богатую структурированную информацию.
Шаг 1 – настройка среды и предварительные условия
Установите последнюю версию Python, затем установите необходимые зависимости. Для этого урока установите Playwright, выполнив следующие команды в терминале:
pip install playwright
playwright installЭта команда установит Playwright и загрузит необходимые двоичные файлы браузера (исполняемые файлы браузера, необходимые для автоматизации).
Шаг 2 – импорт зависимостей и настройка
Импортируйте необходимые библиотеки для задачи скраппинга:
import asyncio
import urllib.parse
from playwright.async_api import async_playwrightРазбивка библиотек:
- asyncio – обеспечивает асинхронное программирование для повышения производительности и выполнения параллельных операций.
- urllib.parse – обрабатывает кодировку URL, чтобы обеспечить правильное форматирование запросов для веб-запросов.
- playwright – предоставляет возможности автоматизации браузера для взаимодействия с Google как с человеком.
Шаг 3 – архитектура функции и параметры
Определите основную функцию скрапинга с четкими параметрами и возвращаемыми значениями:
async def scrape_google_ai_mode(query: str, output_path: str = "ai_response.txt") -> bool:Параметры функции:
- query – поисковый запрос для отправки в Google AI Mode.
- output_path – место назначения файла для сохранения ответа (по умолчанию “ai_response.txt”).
- Возвращает булево значение, указывающее на успех(True) или неудачу(False) извлечения контента.
Шаг 4 – создание URL-адреса и активация режима AI
Создайте поисковый URL-адрес, который запустит интерфейс Google AI Mode:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"Ключевые компоненты:
- urllib.parse.quote_plus(query) – безопасно кодирует поисковый запрос, преобразуя пробелы в ‘+’ и экранируя специальные символы.
- udm=50 – критический параметр, активирующий интерфейс Google AI Mode.
Шаг 5 – настройка браузера и защита от обнаружения
Запустите экземпляр браузера, настроенный так, чтобы избежать обнаружения, сохраняя при этом реалистичное поведение:
async с async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, типа Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)Детали конфигурации:
- headless=False – отображает окно браузера для отладки (установите значение True для производственных сред).
- -disable-blink-features=AutomationControlled – убирает индикаторы обнаружения автоматизации.
- User agent – имитирует легитимный браузер Chrome на macOS, чтобы снизить вероятность обнаружения ботов.
Эти меры защиты от обнаружения помогают скраперу выглядеть как обычный пользователь, просматривающий Google, а не как автоматизированный скрипт.
Шаг 6 – навигация и загрузка динамического контента
Перейдите по созданному URL-адресу и дождитесь полной загрузки динамического контента:
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(2000)Объяснение стратегии загрузки:
- wait_until=”networkidle ” – ожидает, пока сетевая активность не прекратится, что указывает на полную загрузку страницы.
- wait_for_timeout – дополнительный буфер для генерации контента AI.
Шаг 7 – определение местоположения контента и извлечение DOM
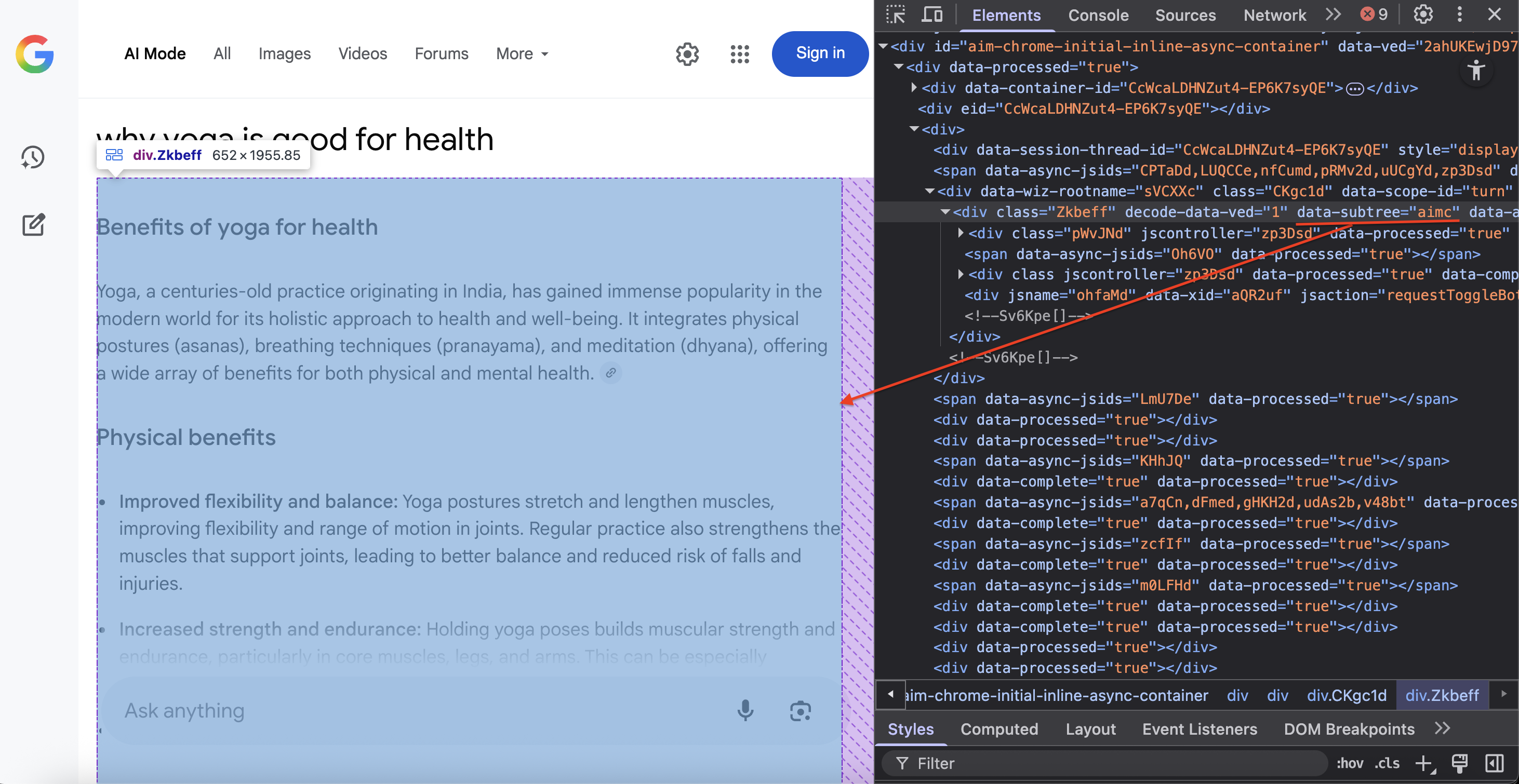
Найдите определенный DOM-контейнер, в котором находится контент Google AI Mode:
container = await page.query_selector('div[data-subtree="aimc"]')CSS-селектор div[data-subtree=”aimc”] нацелен на AIMC (контейнер режима искусственного интеллекта) Google.
Шаг 8 – извлечение и сохранение данных
Извлеките текстовое содержимое и сохраните его в указанном файле:
if container:
text = (await container.inner_text()).strip()
if text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(f "Сохранен ответ AI на '{output_path}' ({len(text):,} символов)")
await browser.close()
вернуть True
else:
print("Контейнер режима AI найден, но не содержит содержимого.")
else:
print("На странице не обнаружено содержимое AI Mode").
await browser.close()
возврат FalseХод процесса:
- Убедитесь в существовании контейнера AI на странице с помощью запроса DOM.
- Извлечение обычного текстового содержимого без HTML-разметки с помощью функции inner_text().
- Сохранение содержимого в указанный файл с кодировкой UTF-8.
- Правильно закройте ресурсы браузера, чтобы предотвратить утечку памяти.
Шаг 9 – выполнение функции скрапинга
Запустите полную операцию скрапинга, вызвав функцию с нужным вам запросом:
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("почему йога полезна для здоровья"))Полный код
Вот полный код, объединяющий все шаги:
import asyncio
import urllib.parse
from playwright.async_api import async_playwright
async def scrape_google_ai_mode(
query: str, output_path: str = "ai_response.txt"
) -> bool:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"
async с async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, типа Gecko) "
"Chrome/139.0.0.0 Safari/537.36"
)
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(1000)
container = await page.query_selector('div[data-subtree="aimc"]')
if container:
text = (await container.inner_text()).strip()
if text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(
f "Сохранен ответ AI на '{output_path}' ({len(text):,} символов)"
)
await browser.close()
вернуть True
else:
print("Контейнер AI Mode найден, но пуст.")
else:
print("Содержимое AI Mode не найдено.")
await browser.close()
вернуть False
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("почему йога полезна для здоровья"))При успешном выполнении этот скрипт создает текстовый файл, содержащий извлеченный AI-ответ:

Отличная работа! Вы успешно собрали содержимое Google AI Mode.
Проблемы и ограничения ручного скраппинга
Ручной скраппинг сопряжен с серьезными операционными проблемами, которые становятся еще более очевидными при масштабировании.
- Обнаружение ботов и проверка CAPTCHA. Google использует сложные механизмы обнаружения, которые выявляют шаблоны автоматического трафика. После ограниченного количества запросов система запускает проверку CAPTCHA, эффективно блокируя дальнейший сбор данных.
- Сложность инфраструктуры и обслуживания. Для успешного проведения крупномасштабных операций требуются различные методы, позволяющие избежать блокировки, такие как высококачественные прокси-сети по месту жительства, ротация пользовательских агентов, обход отпечатков браузеров и сложные стратегии распределения запросов. Это создает значительные технические накладные расходы и затраты на текущее обслуживание.
- Динамическое содержимое и изменения макета. Google часто обновляет структуру своего интерфейса, что может в одночасье сломать существующие парсеры, требуя немедленного внимания и обновления кода для поддержания функциональности.
- Сложность парсинга. Ответы в режиме AI содержат вложенные структуры, динамические цитаты и переменное форматирование, что требует сложной логики разбора. Сохранение точности в различных типах ответов требует тщательного тестирования и обработки ошибок.
- Ограничения масштабируемости. Ручные подходы не справляются с массовой обработкой, управлением одновременными запросами и согласованной производительностью в разных географических регионах и поисковых вертикалях.
Эти ограничения подчеркивают, почему многие организации предпочитают специализированные решения, которые профессионально справляются со всеми сложностями. Это подводит нас к изучению специально разработанного API Google AI Mode Scraper от Bright Data.
Метод 2 – Google AI Mode Scraper API
API Google AI Mode Scraper от Bright Data представляет собой готовое к производству решение, которое избавляет от необходимости поддерживать инфраструктуру скрапинга, обеспечивая при этом надежность и производительность корпоративного уровня. API извлекает всевозможные данные, включая HTML-файл ответа, текст ответа, прикрепленные ссылки, цитаты и 12 дополнительных полей.
Ключевые особенности
- Автоматизированное управление антиботами и прокси. API использует обширную сеть прокси-серверов Bright Data, насчитывающую более 150 млн IP-адресов, в сочетании с передовыми методами обхода антиботов. Эта инфраструктура позволяет избежать столкновений с CAPTCHA и проблем с блокировкой IP-адресов.
- Структурированный вывод данных. API предоставляет последовательно отформатированные данные в нескольких форматах экспорта, включая JSON, NDJSON и CSV, что обеспечивает гибкие возможности интеграции.
- Масштабируемость корпоративного уровня. Созданный для работы с большими объемами данных, API эффективно обрабатывает тысячи запросов с предсказуемым масштабированием затрат благодаря нашей модели ценообразования с оплатой за успешный результат.
- Географическая настройка. Указание целевых стран для получения результатов с учетом конкретного местоположения позволяет понять, как различаются ответы ИИ на разных рынках и демографических характеристиках пользователей.
- Отсутствие необходимости в обслуживании. Наша команда постоянно отслеживает и адаптирует скрепер к изменениям Google. Когда Google изменяет интерфейсы режима AI или вводит новые меры по борьбе с ботами, обновления устанавливаются автоматически, не требуя никаких действий со стороны вашей команды разработчиков.
Результат – комплексное извлечение данных из режима Google AI Mode с надежностью корпоративного уровня и без лишних затрат на инфраструктуру.
Начало работы с API Google AI Mode Scraper
Процесс внедрения включает в себя настройку учетной записи и генерацию ключа API для новых пользователей Bright Data, а затем выбор предпочтительного метода интеграции. Создайте бесплатную учетную запись Bright Data и сгенерируйте токен аутентификации API в 4 простых шага.
После этого перейдите в библиотеку веб-скреперов Bright Data и выполните поиск по слову “google”, чтобы найти доступные варианты скреперов. Нажмите на “google.com”.
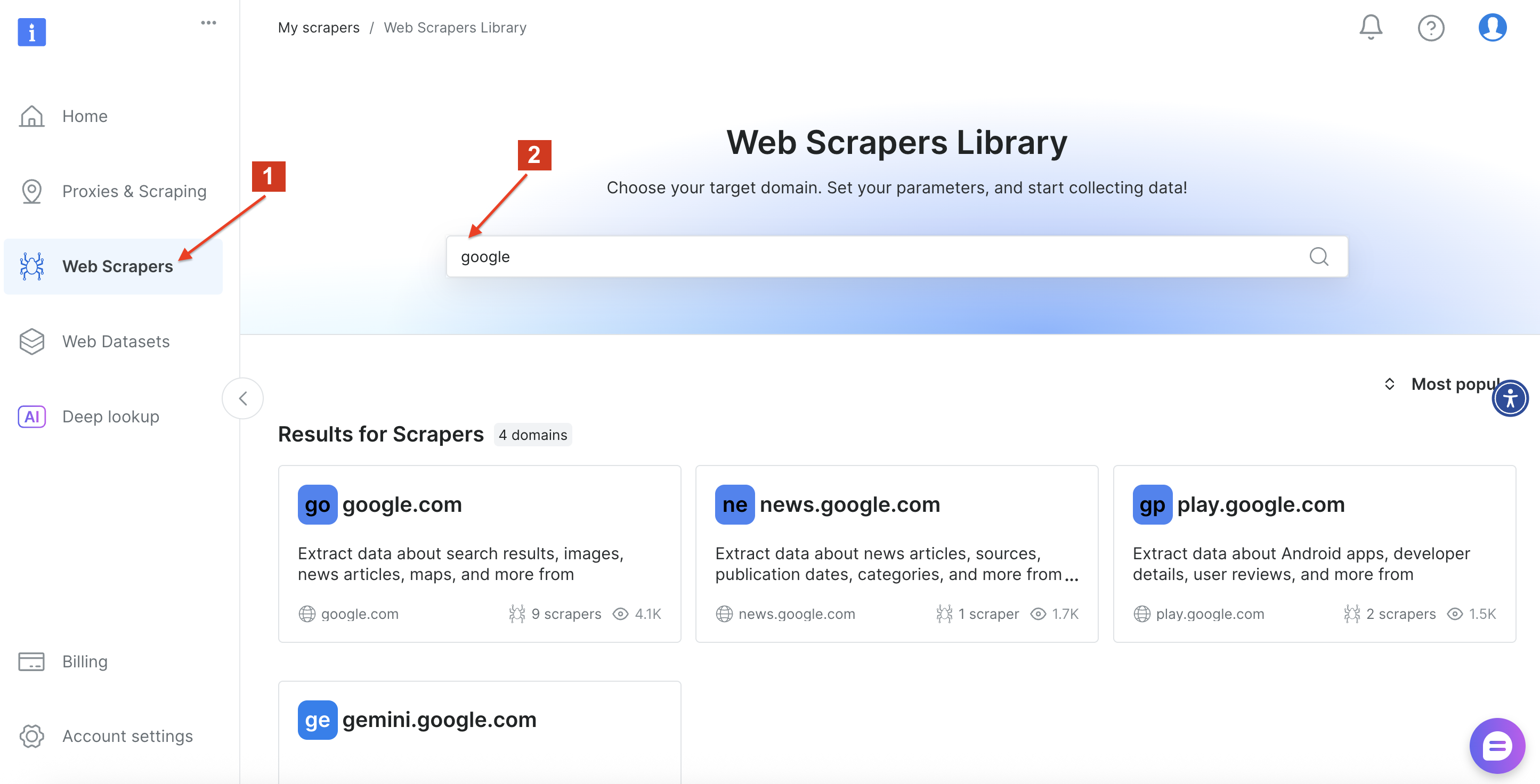
Затем выберите в интерфейсе опцию “Google AI Mode Search”.
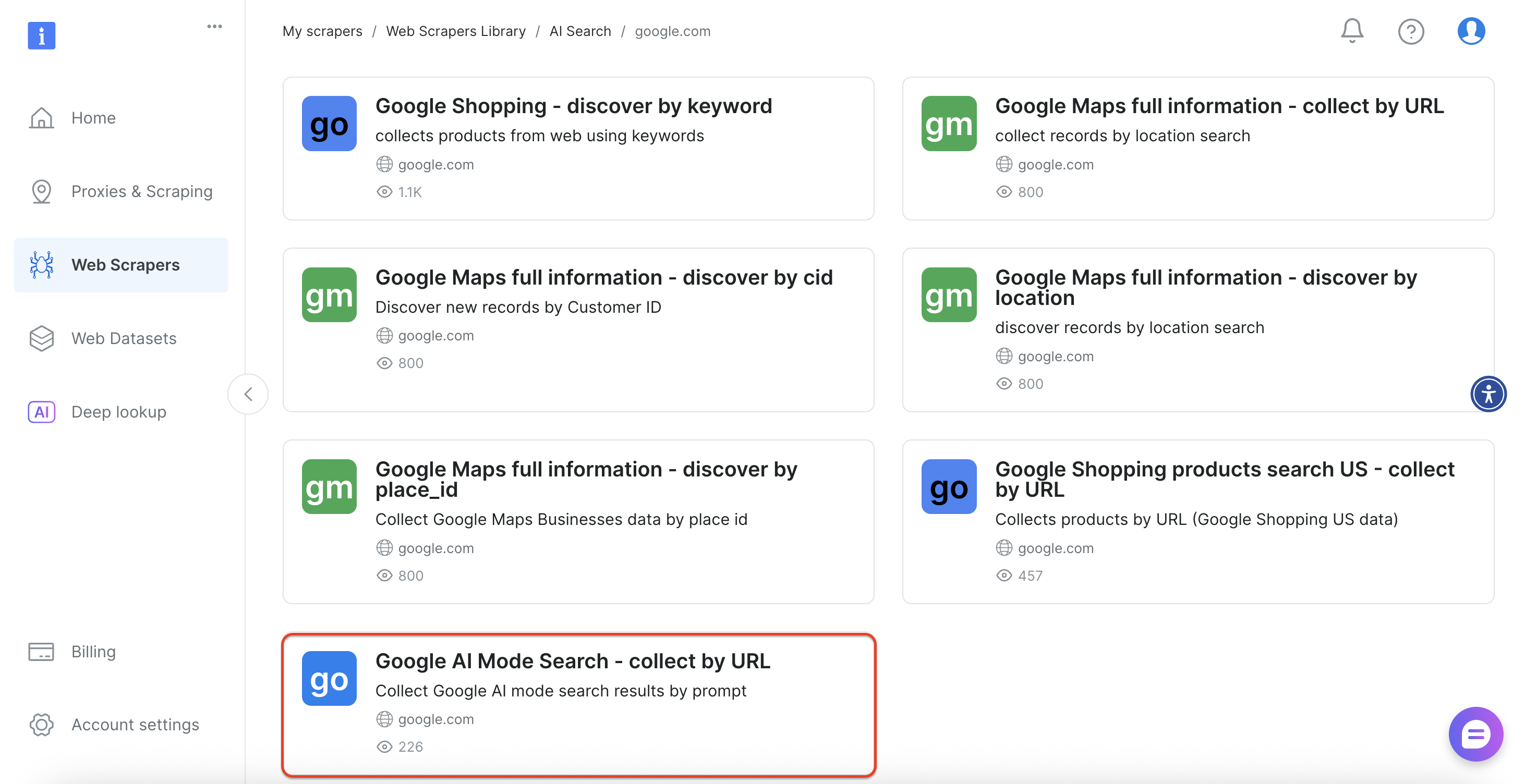
Этот скрепер предлагает как методы реализации без кода, так и на основе API, чтобы удовлетворить различные технические требования и возможности команды.
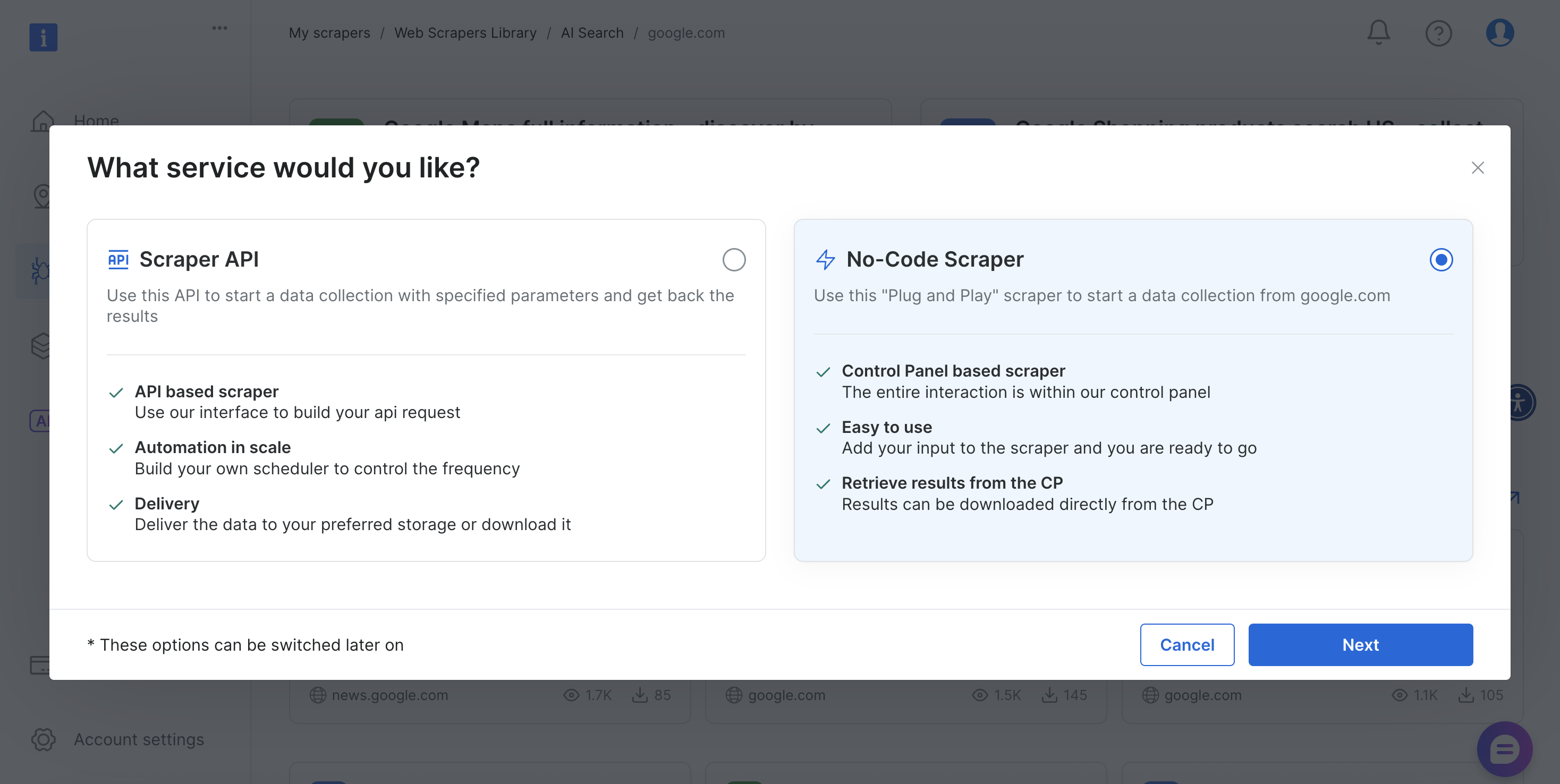
Давайте рассмотрим оба подхода.
Интерактивный скраппинг (скраппер без кода)
Веб-интерфейс предлагает удобный подход для тех, кто предпочитает не работать с кодом. Вы можете вводить поисковые запросы непосредственно через приборную панель или загружать CSV-файлы с несколькими запросами для пакетной обработки. Платформа обрабатывает все автоматически и выдает результаты в виде загружаемых файлов.
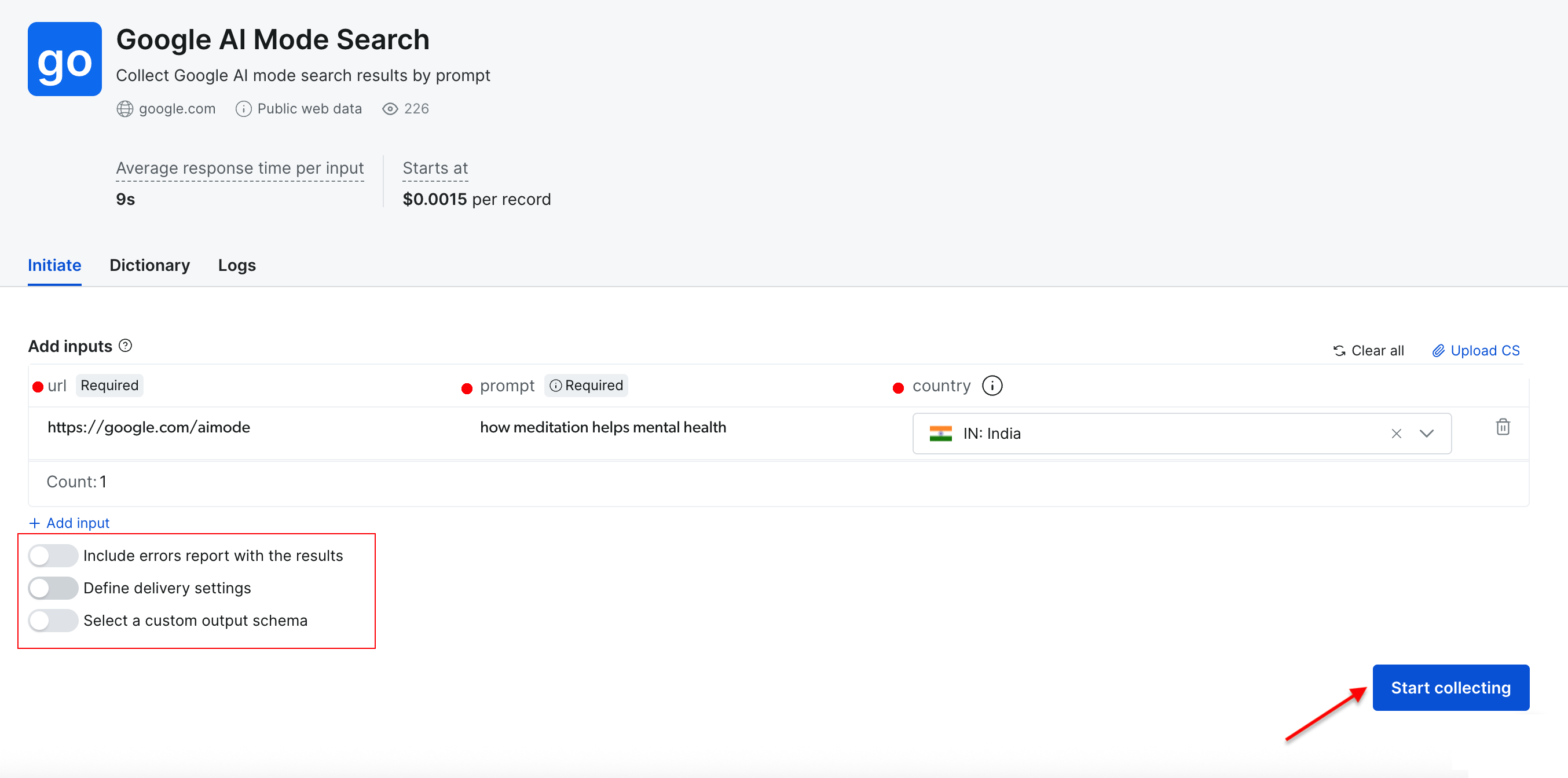
Необходимые параметры:
- URL – по умолчанию установлено значение https://google.com/aimode (оно остается неизменным).
- Prompt – ваш поисковый запрос или вопрос для анализа ИИ Google.
- Страна – географическое положение для получения результатов по конкретным регионам (необязательно).
Дополнительные настройки:
- Настройки доставки – выберите предпочтительный формат вывода и способ доставки.
- Пользовательская схема – выбор полей данных, которые следует включить в экспорт.
- Пакетная обработка – одновременная обработка нескольких запросов с помощью загрузки CSV.
Давайте выполним простой поиск по запросу “как медитация помогает психическому здоровью”, указав в качестве целевой страны “Индия”. Нажмите кнопку “Начать сбор”, чтобы начать процесс.
На приборной панели можно в режиме реального времени отслеживать ход работы(Ready, Running), а по завершении вы сможете загрузить результаты в удобном для вас формате.
Потрясающе, правда?
Скраппинг на основе API (Scraper API)
Программный подход предлагает большую гибкость и возможности автоматизации через конечные точки RESTful API. Комплексный интерфейс построения и управления API-запросами обеспечивает полный контроль над операциями скрапинга:
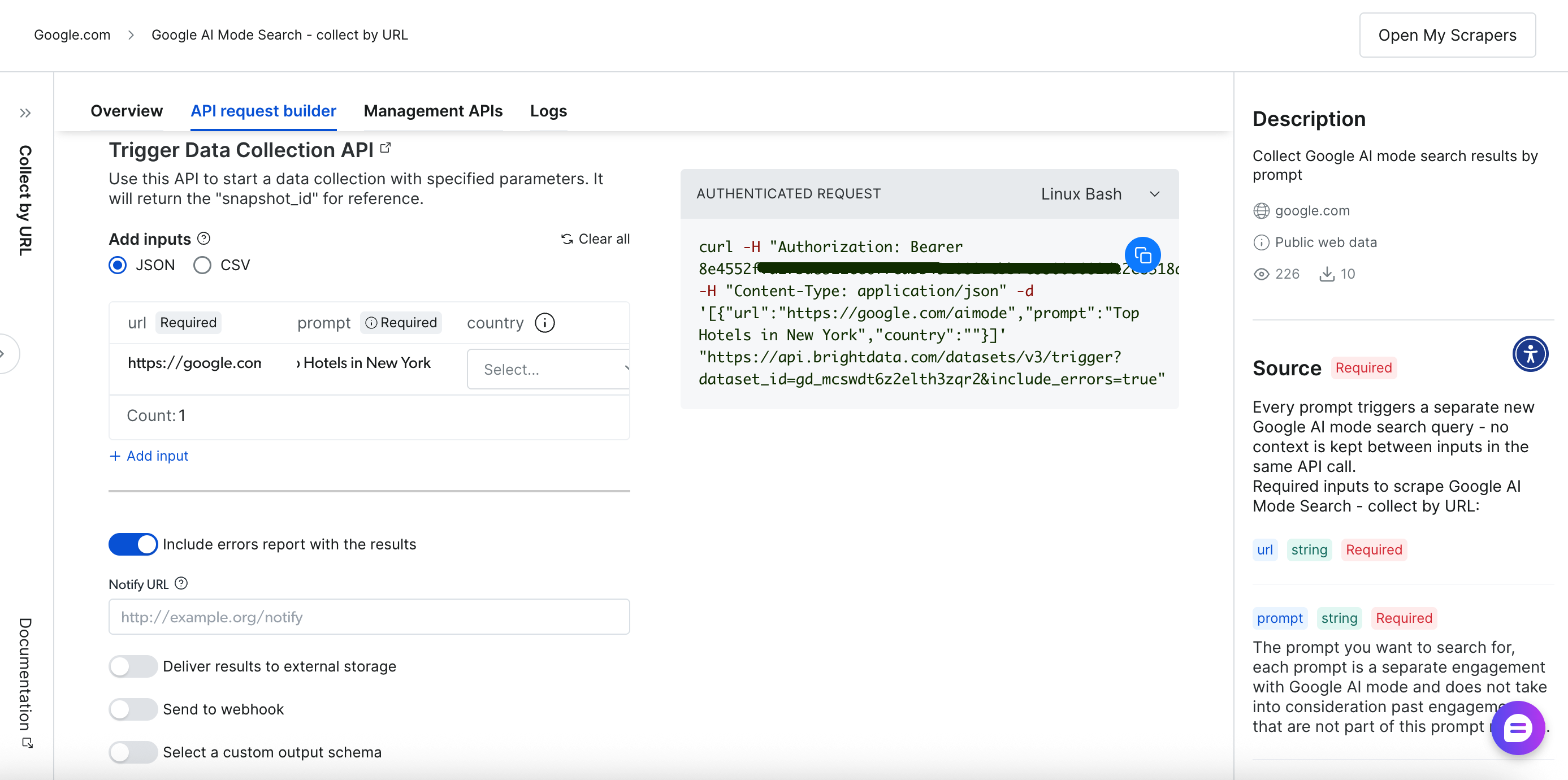
Давайте рассмотрим процесс скрапинга на основе API.
Шаг 1 – запуск сбора данных
Сначала запустите сбор данных, используя один из этих методов:
Выполнение одиночного запроса:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
-H "Content-Type: application/json"
-d '[
{
"url": "https://google.com/aimode",
"prompt": "советы по здоровью для пользователей компьютеров",
"country": "US"
}
]'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"Пакетная обработка с загрузкой CSV:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
-F 'data=@/path/to/your/queries.csv'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"Компоненты запроса:
- Аутентификация – токен на предъявителя в заголовке для безопасного доступа.
- Идентификатор набора данных – специальный идентификатор для скрепера Google AI Mode.
- Формат ввода – массив JSON или CSV-файл, содержащий параметры запроса.
- Обработка ошибок – включите параметр ошибок для получения исчерпывающей информации.
Вы также можете выбрать способ доставки через веб-хук для автоматической обработки результатов.
Шаг 2 – отслеживание выполнения задания
Используйте возвращаемый идентификатор моментального снимка для отслеживания прогресса сбора:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/progress/<snapshot_id>"В ответе будет указано “выполняется” во время сбора данных и “готово”, когда результаты будут доступны для загрузки.
Шаг 3 – загрузка результатов
Загрузите содержимое моментального снимка или доставьте его в указанное хранилище. Получите готовые результаты в удобном для вас формате:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/snapshot/<snapshot_id>?format=json"API возвращает исчерпывающие структурированные данные для каждого запроса:
{
"url": "https://www.google.co.in/search?q=health+tips+for+computer+users&hl=en&udm=50&aep=11&...",
"prompt": "советы по здоровью для пользователей компьютеров",
"answer_html": "<html>...полный ответ HTML...</html>",
"answer_text": "Советы по здоровью для пользователей компьютеровnnПродолжительное пребывание перед компьютером может привести к различным проблемам со здоровьем, включая напряжение глаз, боли в опорно-двигательном аппарате и снижение физической активности...",
"links_attached": [
{
"url": "https://www.aao.org/eye-health/tips-prevention/computer-usage",
"text": null,
"position": 1
},
{
"url": "https://uhs.princeton.edu/health-resources/ergonomics-computer-use",
"text": null,
"position": 2
}
],
"citations": [
{
"url": "https://www.ramsayhealth.co.uk/blog/lifestyle/five-healthy-tips-for-working-at-a-computer",
"title": null,
"description": "Ramsay Health Care",
"icon": "https://...icon-url...",
"domain": "https://www.ramsayhealth.co.uk",
"cited": false
},
{
"url": "https://my.clevelandclinic.org/health/diseases/24802-computer-vision-syndrome",
"title": null,
"description": "Клиника Кливленда",
"icon": "https://...icon-url...",
"domain": "https://my.clevelandclinic.org",
"cited": false
}
],
"country": "IN",
"answer_text_markdown": "Советы по здоровью для пользователей компьютеров...",
"timestamp": "2025-08-07T05:02:56.887Z",
"input": {
"url": "https://google.com/aimode",
"prompt": "советы по здоровью для пользователей компьютеров",
"country": "IN"
}
}Так просто и эффективно!
Этот простой рабочий процесс API легко интегрируется в любое приложение или проект. Конструктор запросов API от Bright Data также предоставляет примеры кода на нескольких языках программирования для упрощения реализации.
Итог
Мы рассмотрели два подхода: решение “сделай сам” с помощью Python и Playwright и готовый API Google AI Mode Scraper от Bright Data.
В условиях быстро развивающегося поискового ландшафта, когда алгоритмы и интерфейсы часто меняются, наличие надежной и хорошо поддерживаемой инфраструктуры скрапинга просто неоценимо. API избавляет вас от необходимости постоянно обновлять логику парсинга или управлять IP-ограничениями, позволяя полностью сосредоточиться на анализе богатой информации, генерируемой искусственным интеллектом, из результатов поиска Google и извлечении максимальной ценности из данных.
Сделайте следующее
- Расширьте сбор данных Google. Поскольку вы уже работаете с режимом Google AI Mode, подумайте о том, чтобы изучить дополнительные источники данных Google. У нас также есть подробное руководство по скраппингу обзоров Google AI для более широкого охвата. Вы можете получить доступ к специализированным возможностям для Google News, Maps, Search, Trends, Reviews, Hotels, Videos и Flights.
- Тестируйте без риска. Все основные продукты включают в себя бесплатные пробные версии, а также мы компенсируем первые депозиты до 500 долларов. Это дает вам возможность поэкспериментировать с расширенным функционалом, прежде чем брать на себя обязательства.
- Масштабируйте с помощью интегрированных решений. По мере роста ваших потребностей рассмотрите возможность использования сервера Web MCP, который подключает приложения искусственного интеллекта непосредственно к веб-данным, не прибегая к индивидуальной разработке для каждого сайта. Начните прямо сейчас с бесплатного плана на 5 000 ежемесячных запросов!
- Корпоративная инфраструктура по мере готовности. Многие команды, как и ваша, начинают с индивидуальных проектов, а затем нуждаются в надежной инфраструктуре для более масштабных операций. Полная платформа обеспечивает базовую инфраструктуру, когда вы будете готовы к расширению.
Не уверены в следующем шаге? Обратитесь к нашей команде – мы составим для вас карту.






