В этой статье вы узнаете:
- Что такое AWS Cloud Development Kit (CDK) и как его можно использовать для определения и развертывания облачной инфраструктуры.
- Почему вам следует предоставить агентам AWS Bedrock AI, созданным с помощью AWS CDK, доступ к результатам веб-поиска с помощью инструмента, готового к использованию ИИ, такого как SERP API от Bright Data.
- Как создать агент AWS Bedrock, интегрированный с SERP API, с помощью AWS CDK в Python.
Приступим!
Что такое AWS Cloud Development Kit (CDK)?
AWS Cloud Development Kit, также известный как AWS CDK, — это фреймворк с открытым исходным кодом для создания облачной инфраструктуры в виде кода с использованием современных языков программирования. Он предоставляет вам все необходимое для предоставления ресурсов AWS и развертывания приложений через AWS CloudFormation с использованием языков программирования, таких как TypeScript, Python, Java, C# и Go.
Благодаря AWS CDK вы также можете программно создавать агентов ИИ для Amazon Bedrock — именно это вы и будете делать в этом учебном курсе!
Почему ИИ-агенты Amazon Bedrock, созданные с помощью AWS CDK, нуждаются в веб-поиске
Крупные языковые модели обучаются на наборах данных, представляющих знания только до определенного момента времени. В результате они склонны давать неточные или вымышленные ответы. Это особенно проблематично для ИИ-агентов, которым требуется актуальная информация.
Эту проблему можно решить, предоставив вашему ИИ-агенту возможность получать свежие и надежные данные в конфигурации RAG (Retrieval-Augmented Generation). Например, ИИ-агент может выполнять поиск в Интернете для сбора проверяемой информации, расширяя свои знания и повышая точность.
Создание настраиваемой функции AWS Lambda для сбора данных из поисковых систем возможно, но довольно сложно. Вам придется иметь дело с рендерингом JavaScript, CAPTCHA, изменением структуры сайтов и блокировкой IP-адресов.
Лучший подход — использовать многофункциональный SERP API, такой как SERP API от Bright Data. Он обрабатывает прокси, разблокировку, масштабируемость, форматирование данных и многое другое. Интегрировав его с AWS Bedrock с помощью функции Lambda, ваш ИИ-агент, созданный с помощью AWS CDK, сможет получать доступ к результатам поиска в реальном времени для получения более достоверных ответов.
Как разработать ИИ-агента с интеграцией SERP API с помощью AWS CDK в Python
В этом пошаговом разделе вы узнаете, как использовать AWS CDK с Python для создания агента AWS Bedrock ИИ. Он сможет извлекать данные из поисковых систем через Bright Data SERP API.
Интеграция будет реализована с помощью функции Lambda (которая вызывает SERP API), которую агент может вызывать в качестве инструмента. В частности, для создания агента Amazon Bedrock основными компонентами являются:
- Группа действий: определяет функции, которые агент может видеть и вызывать.
- Функция Lambda: реализует логику запроса к Bright Data SERP API.
- ИИ Agent: координирует взаимодействие между базовыми моделями, функциями и запросами пользователей.
Эта настройка будет полностью реализована с помощью AWS CDK в Python. Чтобы достичь тех же результатов с помощью визуальной консоли AWS Bedrock, см. наше руководство Amazon Bedrock + Bright Data.
Выполните следующие шаги, чтобы создать ИИ-агент AWS Bedrock с помощью AWS CDK, дополненный возможностями веб-поиска в реальном времени через SERP API!
Необходимые условия
Чтобы выполнить это руководство, вам необходимо:
- Node.js 22.x+ установлен локально для использования AWS CDK CLI.
- Python 3.11+, установленный локально для использования AWS CDK в Python.
- Активная учетная запись AWS (даже на бесплатной пробной версии).
- Установленные предварительные условия Amazon Bedrock Agents. (Amazon Bedrock Agents в настоящее время доступны только в некоторых регионах AWS.)
- Учетная запись Bright Data с готовым API-ключом.
- Базовые навыки программирования на Python.
Шаг 1: Установите и авторизуйте AWS CLI
Прежде чем приступить к работе с AWS CDK, необходимо установить AWS CLI и настроить его так, чтобы ваш терминал мог пройти аутентификацию в вашей учетной записи AWS.
Примечание: если AWS CLI уже установлен и настроен для аутентификации, пропустите этот шаг и перейдите к следующему.
Установите AWS CLI, следуя официальному руководству по установке для вашей операционной системы. После установки проверьте ее, запустив:
aws --versionВы должны увидеть результат, похожий на следующий:
aws-cli/2.31.32 Python/3.13.9 Windows/11 exe/AMD64Затем запустите команду configure, чтобы настроить свои учетные данные:
aws configureВам будет предложено ввести:
- Идентификатор ключа доступа AWS
- Секретный ключ доступа AWS
- Название региона по умолчанию (например,
us-east-1) - Формат вывода по умолчанию (необязательно, например,
json)
Заполните первые три поля, так как они необходимы для разработки и развертывания CDK. Если вы не знаете, где получить эту информацию:
- Перейдите на сайт AWS и войдите в систему.
- В правом верхнем углу нажмите на название своей учетной записи, чтобы открыть меню учетной записи, и выберите опцию «Учетные данные безопасности».
- В разделе «Ключи доступа» создайте новый ключ. Сохраните «Идентификатор ключа доступа» и «Секретный ключ доступа» в надежном месте.
Готово! Ваш компьютер может подключиться к вашей учетной записи AWS через CLI. Вы готовы приступить к разработке AWS CDK.
Шаг 2. Установите AWS CDK
Установите AWS CDK глобально в своей системе с помощью пакета npm aws-cdk:
npm install -g aws-cdkЗатем проверьте установленную версию, запустив:
cdk --versionВы должны увидеть результат, похожий на следующий:
2.1031.2 (сборка 779352d)Примечание. Для разработки и развертывания ИИ-агента с использованием AWS CDK с Python требуется версия 2.174.3 или более поздняя.
Отлично! Теперь у вас локально установлен AWS CDK CLI.
Шаг 3: Настройте свой проект AWS CDK Python
Начните с создания новой папки проекта для вашего ИИ-агента AWS CDK + Bright Data SERP API.
Например, вы можете назвать ее aws-cdk-bright-data-web-search-agent:
mkdir aws-cdk-bright-data-web-search-agentПерейдите в папку:
cd aws-cdk-bright-data-web-search-agentЗатем инициализируйте новое приложение AWS CDK на основе Python с помощью команды init:
cdk init app --language pythonЭто может занять некоторое время, поэтому будьте терпеливы, пока CDK CLI настраивает структуру вашего проекта.
После инициализации папка вашего проекта должна выглядеть следующим образом:
aws-cdk-bright-data-web-search-agent
├── .git/
├── venv/
├── aws_cdk_bright_data_web_search_agent/
│ ├── __init__.py
│ └── aws_cdk_bright_data_web_search_agent_stack.py
├── tests/
│ ├── __init__.py
│ └── unit/
│ ├── __init__.py
│ └── test_aws_cdk_bright_data_web_search_agent_stack.py
├── .gitignore
├── app.py
├── cdk.json
├── README.md
├── requirements.txt
├── requirements-dev.txt
└── source.batВам нужно сосредоточиться на этих двух файлах:
app.py: содержит определение верхнего уровня приложения AWS CDK.aws_cdk_bright_data_web_search_agent/aws_cdk_bright_data_web_search_agent_stack.py: определяет стек для веб-поискового агента (здесь вы будете реализовывать логику своего ИИ-агента).
Для получения более подробной информации обратитесь к официальному руководству AWS по работе с CDK в Python.
Теперь загрузите свой проект в любимую IDE для Python, например PyCharm или Visual Studio Code с расширением Python.
Обратите внимание, что команда cdk init автоматически создает виртуальную среду Python в проекте. В Linux или macOS активируйте ее с помощью:
source .venv/bin/activateИли, что эквивалентно, в Windows выполните:
.venvScriptsactivateЗатем, внутри активированной виртуальной среды, установите все необходимые зависимости:
python -m pip install -r requirements.txtОтлично! Теперь у вас есть среда AWS CDK Python, настроенная для разработки ИИ-агентов.
Шаг 4. Запустите AWS CDK Bootstrapping
Bootstrapping — это процесс подготовки вашей среды AWS к использованию с AWS Cloud Development Kit. Перед развертыванием стека CDK ваша среда должна быть подготовлена.
Проще говоря, этот процесс настраивает следующие ресурсы в вашей учетной записи AWS:
- Контейнер Amazon S3: хранит файлы вашего проекта CDK, такие как код функции AWS Lambda и другие ресурсы.
- Репозиторий Amazon ECR: хранит образы Docker.
- Роли AWS IAM: предоставляют необходимые разрешения для AWS CDK для выполнения развертываний. (Для получения более подробной информации см. документацию AWS по ролям IAM, созданным во время запуска).
Чтобы запустить процесс начальной настройки CDK, выполните следующую команду в папке вашего проекта:
cdk bootstrapВ службе AWS CloudFormation эта команда создает стек с именем «CDKToolkit», который содержит все ресурсы, необходимые для развертывания приложений CDK.
Убедитесь в этом, перейдя в консоль CloudFormation и проверив страницу «Стеки»:
Вы увидите стек «CDKToolkit». Перейдите по ссылке, и вы увидите примерно следующее:
Для получения дополнительной информации о том, как работает процесс начальной настройки, зачем он нужен и что происходит за кулисами, обратитесь к официальной документации AWS CDK.
Шаг 5: Подготовьтесь с помощью SERP API от Bright Data
Теперь, когда ваша среда AWS CDK настроена для разработки и развертывания, завершите предварительные шаги, подготовив свою учетную запись Bright Data и настроив службу SERP API. Вы можете следовать официальной документации Bright Data или выполнить следующие шаги.
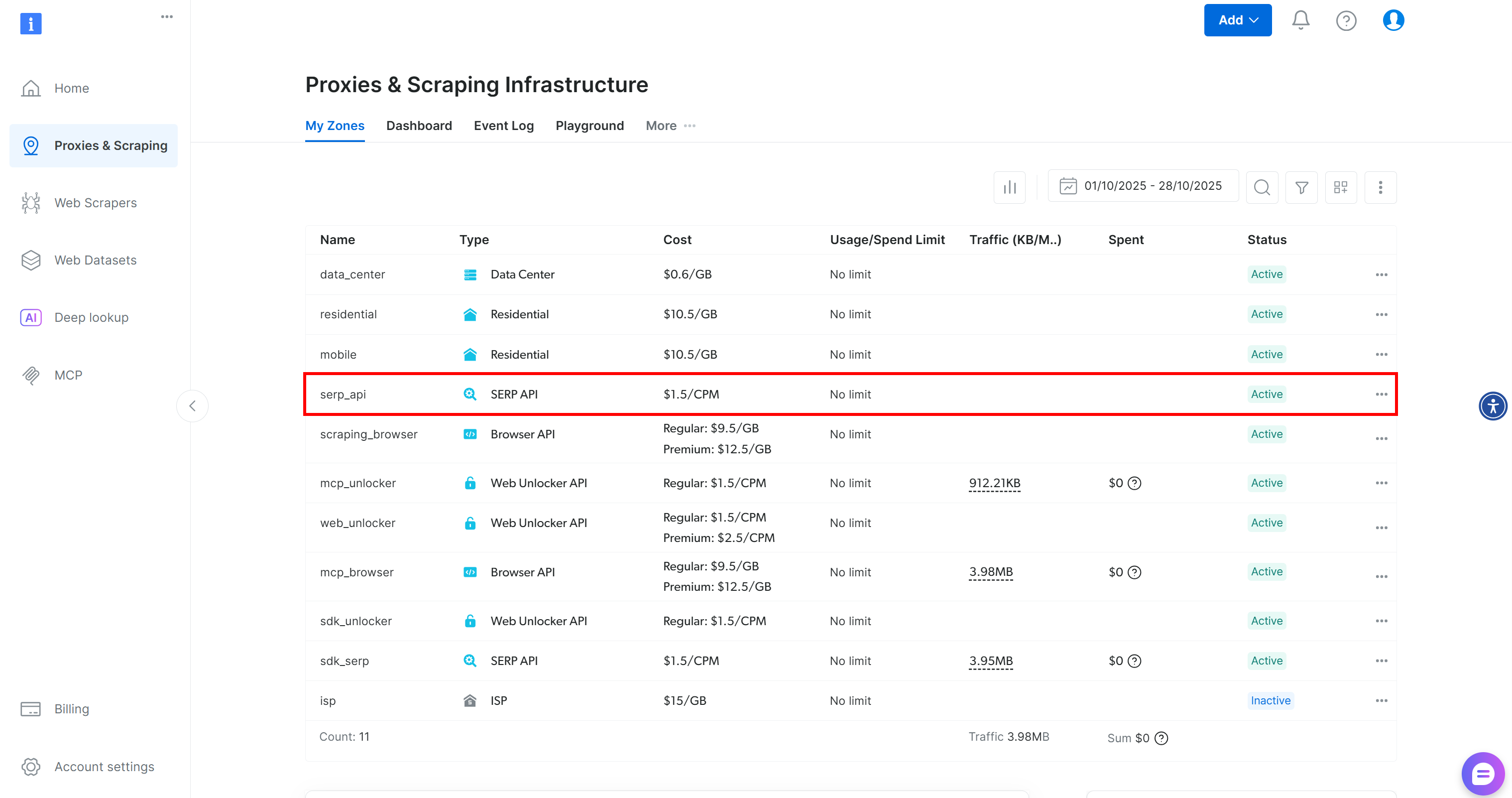
Если у вас еще нет учетной записи, создайте учетную запись Bright Data. Или просто войдите в систему. В своей учетной записи Bright Data перейдите на страницу «Прокси и скрапинг». В разделе «Мои зоны» найдите в таблице строку «SERP API»:
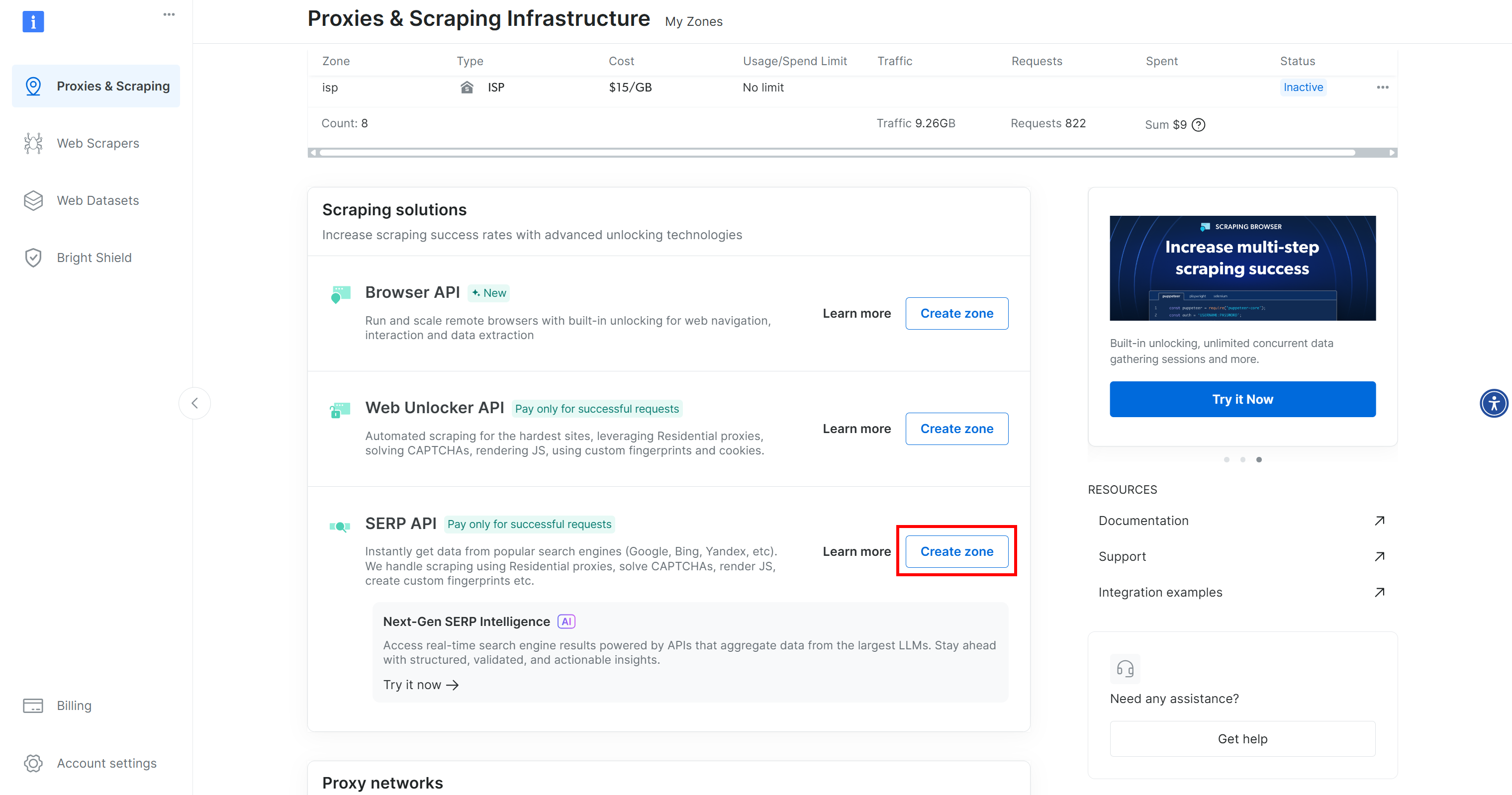
Если вы не видите строку с надписью «SERP API», это означает, что вы еще не настроили зону. Прокрутите вниз до раздела «SERP API» и нажмите «Создать зону», чтобы добавить ее:
Создайте зону SERP API и дайте ей имя, например serp_api (или любое другое имя по вашему усмотрению). Запомните выбранное вами имя зоны, так как оно понадобится вам для доступа к сервису через API.
На странице продукта SERP API переключите переключатель «Активировать», чтобы включить зону:
Наконец, следуйте официальному руководству, чтобы сгенерировать ключ API Bright Data. Храните его в надежном месте, так как он вам скоро понадобится.
Отлично! Теперь у вас есть все необходимое для использования SERP API Bright Data в вашем агенте AWS Bedrock ИИ, разработанном с помощью AWS CDK.
Шаг 6. Сохраните секретные данные приложения CDK в AWS Secrets Manager
Вы только что получили конфиденциальную информацию (например, ключ API Bright Data и имя зоны SERP API). Вместо того, чтобы жестко прописывать эти значения в коде вашей функции Lambda, вам следует безопасно считывать их из AWS Secrets Manager.
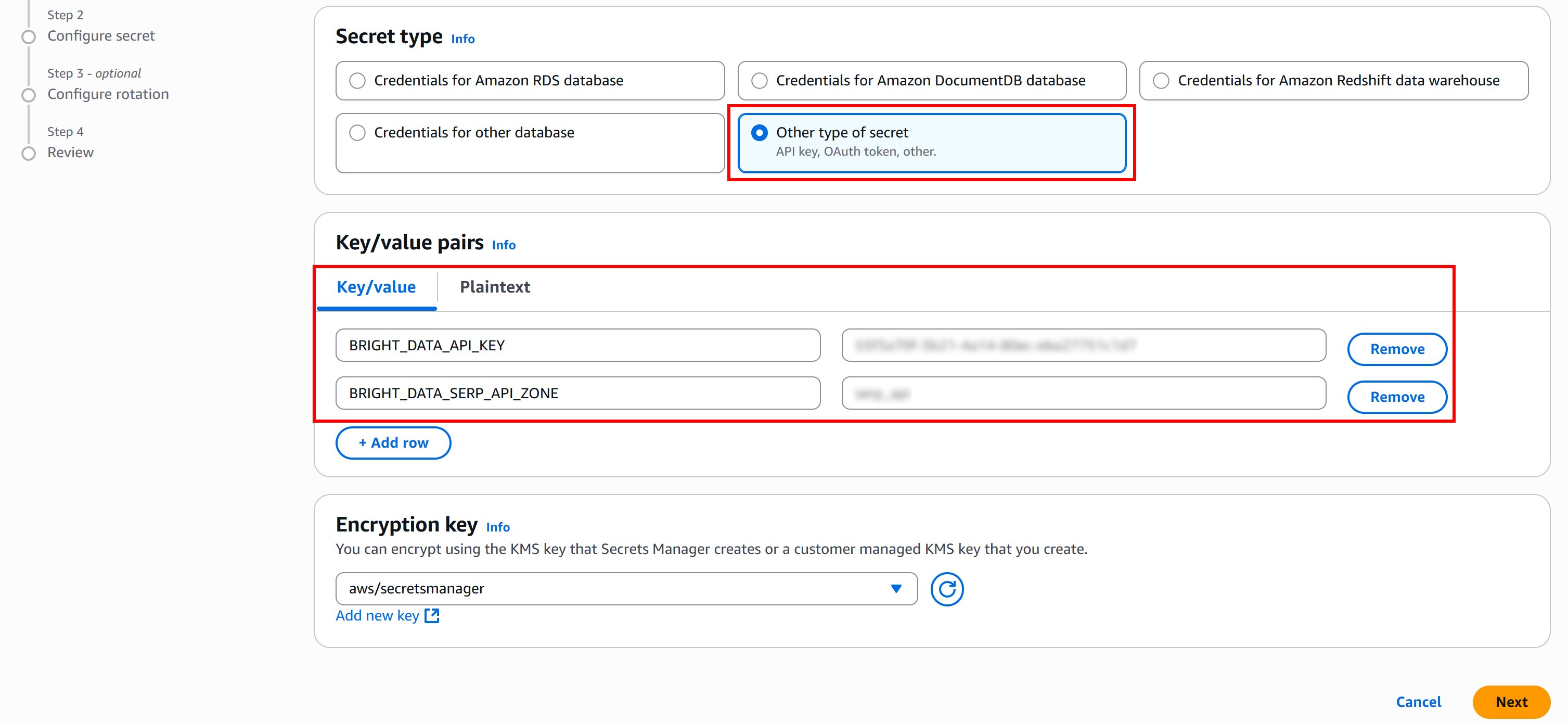
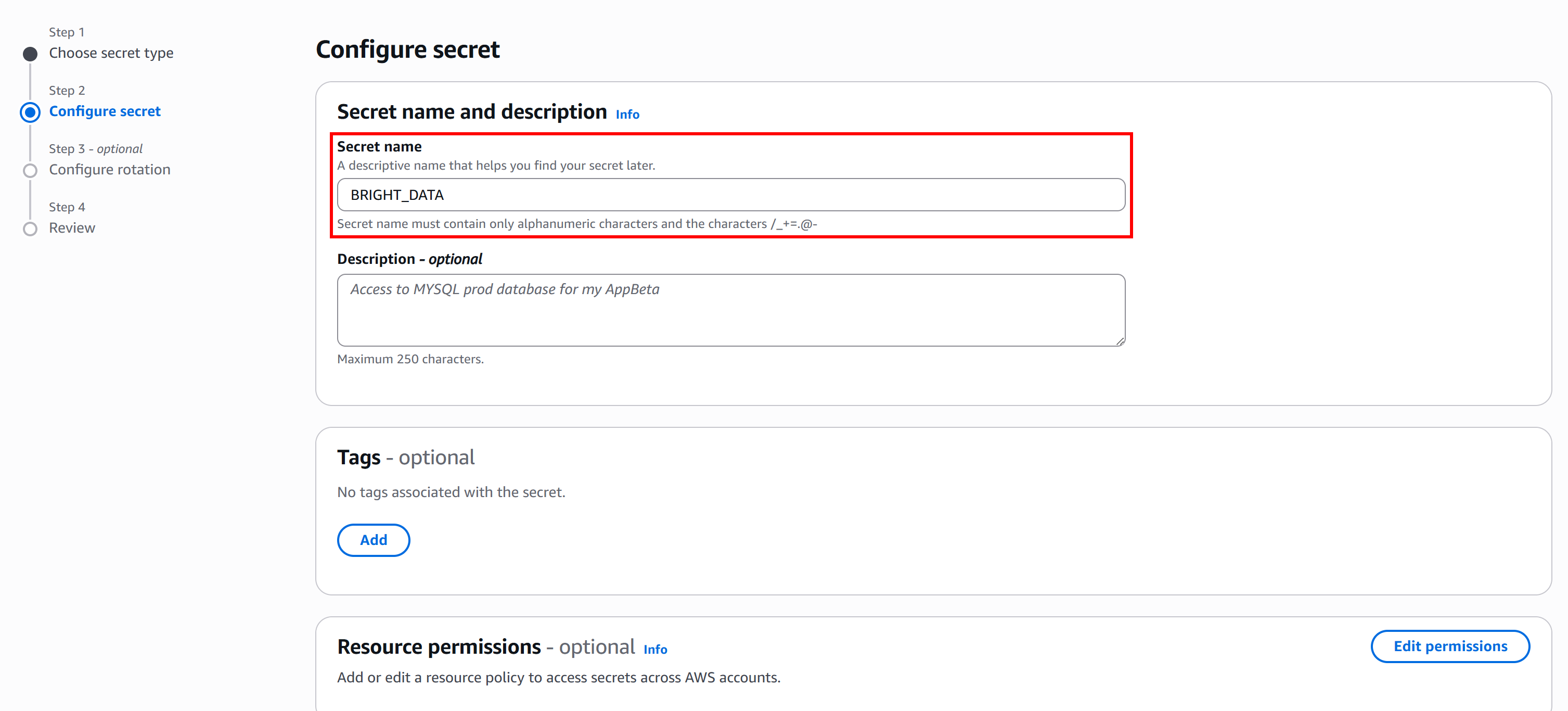
Выполните следующую команду Bash, чтобы создать секрет с именем BRIGHT_DATA, содержащий ваш ключ API Bright Data и зону API SERP API:
aws secretsmanager create-secret
--name "BRIGHT_DATA"
--description "API credentials for Bright Data SERP API integration"
--secret-string '{
"BRIGHT_DATA_API_KEY": "<YOUR_BRIGHT_DATA_API_KEY>",
"BRIGHT_DATA_SERP_API_ZONE": "<YOUR_BRIGHT_DATA_SERP_API_ZONE>"
}'Или, что эквивалентно, в PowerShell:
aws secretsmanager create-secret `
--name "BRIGHT_DATA" `
--description "API credentials for Bright Data SERP API integration" `
--secret-string '{"BRIGHT_DATA_API_KEY":"<YOUR_BRIGHT_DATA_API_KEY>","BRIGHT_DATA_SERP_API_ZONE":"<YOUR_BRIGHT_DATA_SERP_API_ZONE>"}'Обязательно замените <YOUR_BRIGHT_DATA_API_KEY> и <YOUR_BRIGHT_DATA_SERP_API_ZONE> на фактические значения, которые вы получили ранее.
Эта команда настроит секрет BRIGHT_DATA, что можно подтвердить в консоли AWS Secrets Manager на странице «Секреты»:
Если вы нажмете кнопку «Retrieve secret value» (Получить секретное значение), вы увидите секретные ключи BRIGHT_DATA_API_KEY и BRIGHT_DATA_SERP_API_ZONE:
Отлично! Эти секреты будут использоваться для аутентификации запросов к SERP API в функции Lambda, которую вы скоро определите.
Шаг 7. Реализуйте свой стек AWS CDK
Теперь, когда вы настроили все необходимое для создания вашего ИИ-агента, следующим шагом будет реализация стека AWS CDK в Python. Во-первых, важно понять, что такое стек AWS CDK.
Стек — это наименьшая развертываемая единица в CDK. Он представляет собой набор ресурсов AWS, определенных с помощью конструкций CDK. При развертывании приложения CDK все ресурсы в стеке развертываются вместе как единый стек CloudFormation.
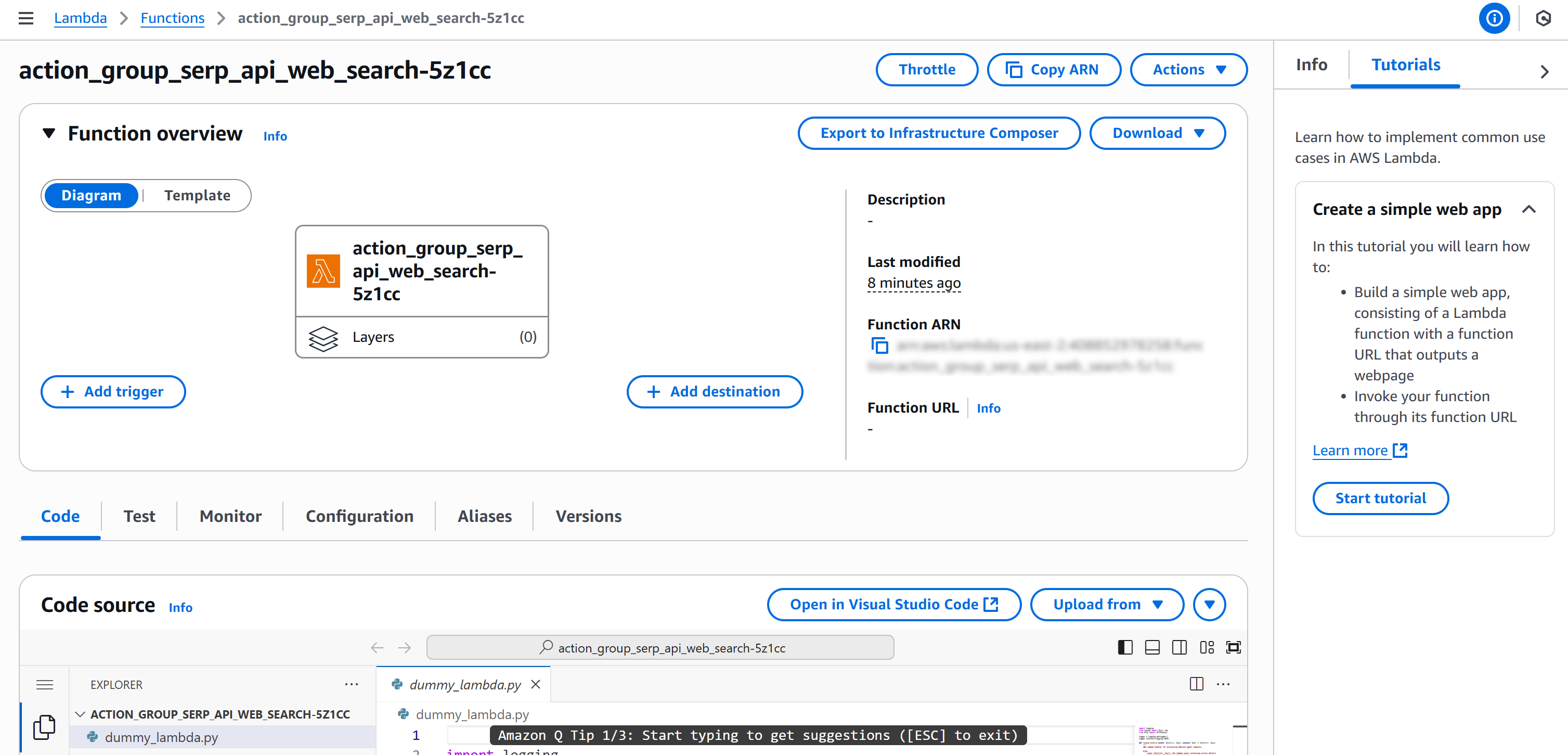
Файл стека по умолчанию находится по адресу:
aws_cdk_bright_data_web_search_agent/aws_cdk_bright_data_web_search_agent_stack.pyПросмотрите его в Visual Studio Code:
Он содержит общий шаблон стека, в котором вы будете определять свою логику. Ваша задача — реализовать полный стек AWS CDK для создания AI-агента с интеграцией Bright Data SERP API, включая функции Lambda, роли IAM, группы действий и AI-агент Bedrock.
Достигните всего этого с помощью:
import aws_cdk.aws_iam as iam
from aws_cdk import (
Aws,
CfnOutput,
Duration,
Stack)
from aws_cdk import aws_bedrock as bedrock
from aws_cdk import aws_lambda as _lambda
from constructs import Construct
# Определите необходимые константы
AI_MODEL_ID = "amazon.nova-lite-v1:0" # Название LLM, используемого для работы агента
ACTION_GROUP_NAME = "action_group_web_search"
LAMBDA_FUNCTION_NAME = "serp_api_lambda"
AGENT_NAME = "web_search_agent"
# Определение стека CDK для развертывания агента веб-поиска на базе Bright Data
class AwsCdkBrightDataWebSearchAgentStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Предоставляет Lambda разрешения на ведение журналов и чтение секретов
lambda_policy = iam.Policy(
self,
"LambdaPolicy",
statements=[
# Разрешение на создание групп журналов CloudWatch
iam.PolicyStatement(
sid="CreateLogGroup",
effect=iam.Effect.ALLOW,
actions=["logs:CreateLogGroup"],
resources=[f"arn:aws:logs:{Aws.REGION}:{Aws.ACCOUNT_ID}:*"],
),
# Разрешение на создание потоков журналов и размещение событий журналов
iam.PolicyStatement(
sid="CreateLogStreamAndPutLogEvents",
effect=iam.Effect.ALLOW,
actions=["logs:CreateLogStream", "logs:PutLogEvents"],
resources=[
f"arn:aws:logs:{Aws.REGION}:{Aws.ACCOUNT_ID}:log-group:/aws/lambda/{LAMBDA_FUNCTION_NAME}",
f"arn:aws:logs:{Aws.REGION}:{Aws.ACCOUNT_ID}:log-group:/aws/lambda/{LAMBDA_FUNCTION_NAME}:log-stream:*",
],
),
# Разрешение на чтение секретов BRIGHT_DATA из Secrets Manager
iam.PolicyStatement(
sid="GetSecretsManagerSecret",
effect=iam.Effect.ALLOW,
actions=["secretsmanager:GetSecretValue"],
resources=[
f"arn:aws:secretsmanager:{Aws.REGION}:{Aws.ACCOUNT_ID}:secret:BRIGHT_DATA*",
],
),
],
)
# Определение роли IAM для функций Lambda
lambda_role = iam.Role(
self,
"LambdaRole",
role_name=f"{LAMBDA_FUNCTION_NAME}_role",
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com"),
)
# Прикрепить политику к роли Lambda
lambda_role.attach_inline_policy(lambda_policy)
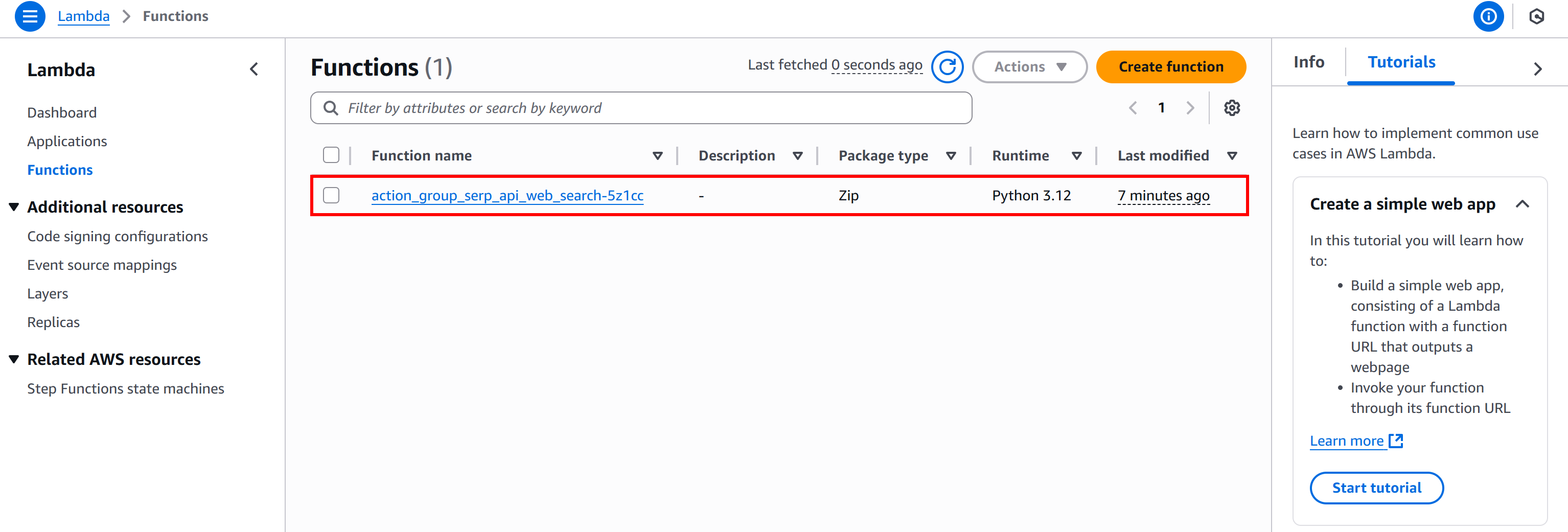
# Определение функции Lambda
lambda_function = _lambda.Function(
self,
LAMBDA_FUNCTION_NAME,
function_name=LAMBDA_FUNCTION_NAME,
runtime=_lambda.Runtime.PYTHON_3_12, # Среда выполнения Python
architecture=_lambda.Architecture.ARM_64,
code=_lambda.Code.from_asset("lambda"), # Считать код Lambda из папки «lambda/»
handler=f"{LAMBDA_FUNCTION_NAME}.lambda_handler",
timeout=Duration.seconds(120),
role=lambda_role, # Прикрепить роль IAM
environment={"LOG_LEVEL": "DEBUG", "ACTION_GROUP": f"{ACTION_GROUP_NAME}"},
)
# Разрешить службе Bedrock вызывать функции Lambda
bedrock_account_principal = iam.PrincipalWithConditions(
iam.ServicePrincipal("bedrock.amazonaws.com"),
conditions={
"StringEquals": {"aws:SourceAccount": f"{Aws.ACCOUNT_ID}"},
},
)
lambda_function.add_permission(
id="LambdaResourcePolicyAgentsInvokeFunction",
principal=bedrock_account_principal,
action="lambda:invokeFunction",
)
# Определите политику IAM для агента Bedrock
agent_policy = iam.Policy(
self,
"AgentPolicy",
statements=[
iam.PolicyStatement(
sid="AmazonBedrockAgentBedrockFoundationModelPolicy",
effect=iam.Effect.ALLOW,
actions=["bedrock:InvokeModel"], # Предоставить разрешение на вызов базовой модели
resources=[f"arn:aws:bedrock:{Aws.REGION}::foundation-model/{AI_MODEL_ID}"],
),
],
)
# Доверительные отношения для роли агента, позволяющие Bedrock принимать ее на себя
agent_role_trust = iam.PrincipalWithConditions(
iam.ServicePrincipal("bedrock.amazonaws.com"),
conditions={
"StringLike": {"aws:SourceAccount": f"{Aws.ACCOUNT_ID}"},
"ArnLike": {"aws:SourceArn": f"arn:aws:bedrock:{Aws.REGION}:{Aws.ACCOUNT_ID}:agent/*"},
},
)
# Определение роли IAM для агента Bedrock
agent_role = iam.Role(
self,
"AmazonBedrockExecutionRoleForAgents",
role_name=f"AmazonBedrockExecutionRoleForAgents_{AGENT_NAME}",
assumed_by=agent_role_trust,
)
agent_role.attach_inline_policy(agent_policy)
# Определение группы действий для агента ИИ
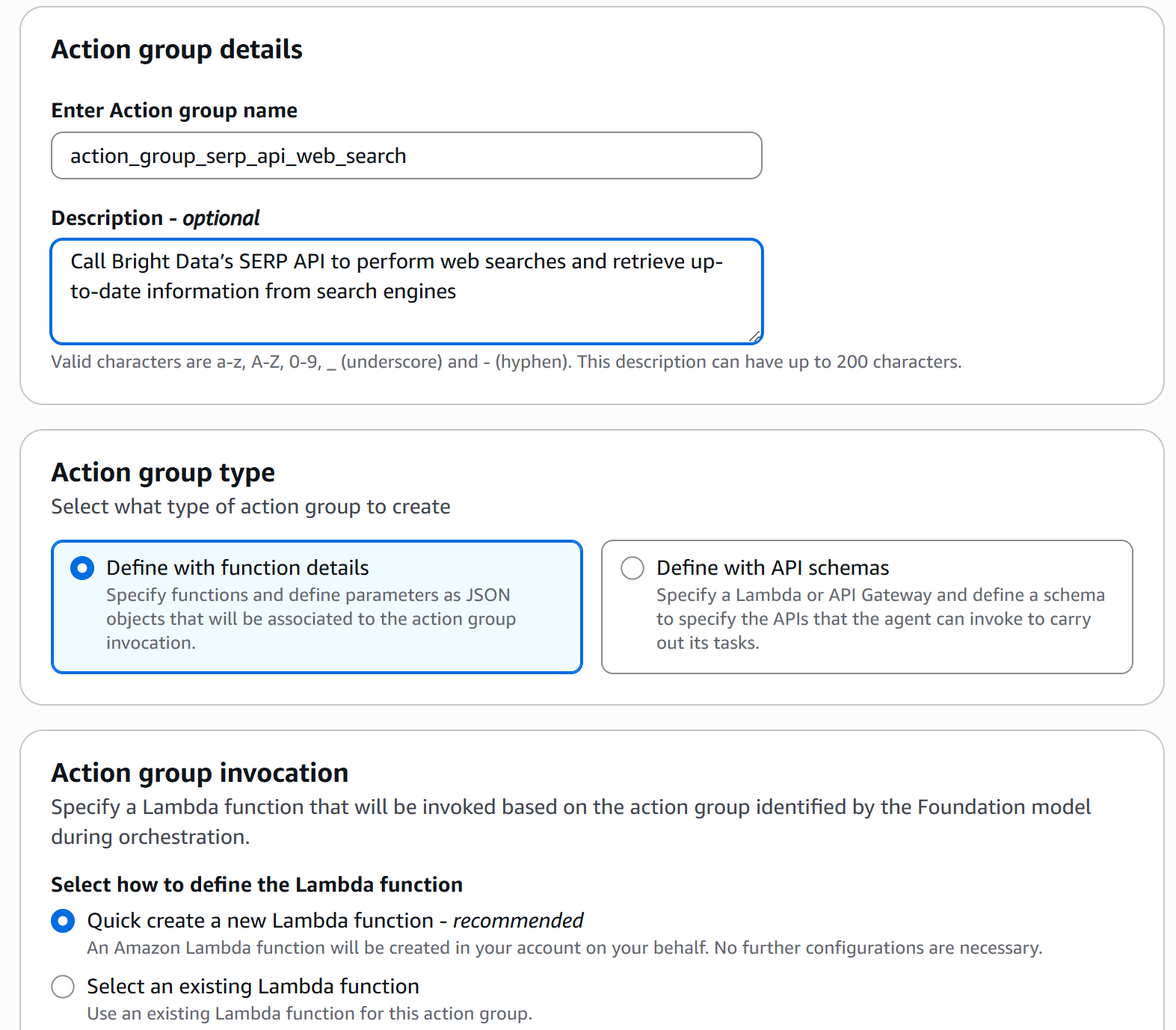
action_group = bedrock.CfnAgent.AgentActionGroupProperty(
action_group_name=ACTION_GROUP_NAME,
description="Вызов SERP API Bright Data для выполнения веб-поиска и получения актуальной информации из поисковых систем.",
action_group_executor=bedrock.CfnAgent.ActionGroupExecutorProperty(lambda_=lambda_function.function_arn),
function_schema=bedrock.CfnAgent.FunctionSchemaProperty(
functions=[
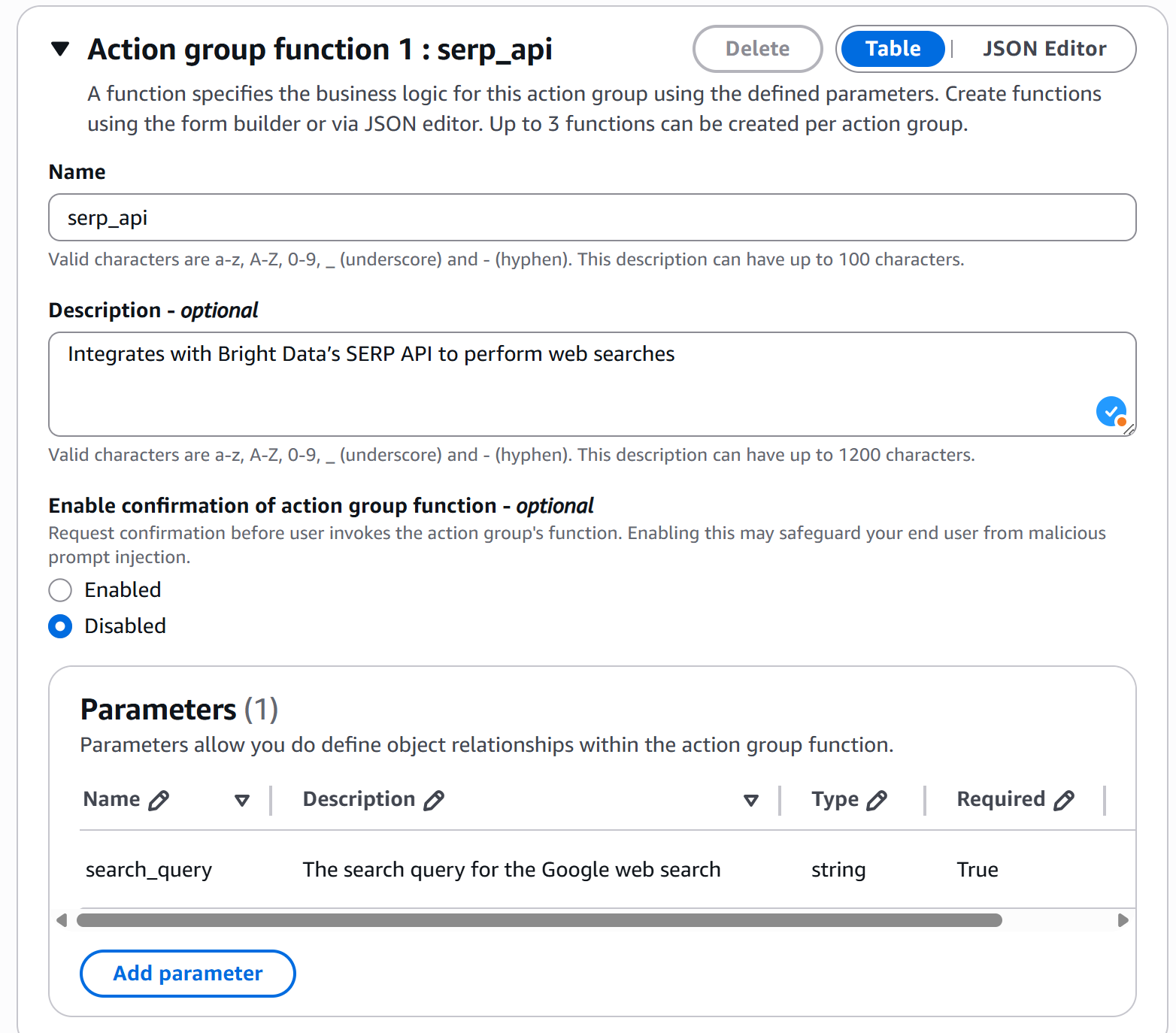
bedrock.CfnAgent.FunctionProperty(
name=LAMBDA_FUNCTION_NAME,
description="Интеграция с SERP API Bright Data для выполнения веб-поиска.",
parameters={
"search_query": bedrock.CfnAgent.ParameterDetailProperty(
type="string",
description="Поисковый запрос для веб-поиска Google.",
required=True,
)
},
),
]
),
)
# Создать и указать агента Bedrock AI
agent_description = """
Агент искусственного интеллекта, который может подключаться к SERP API Bright Data для получения свежей информации о веб-поиске из поисковых систем.
"""
agent_instruction = """
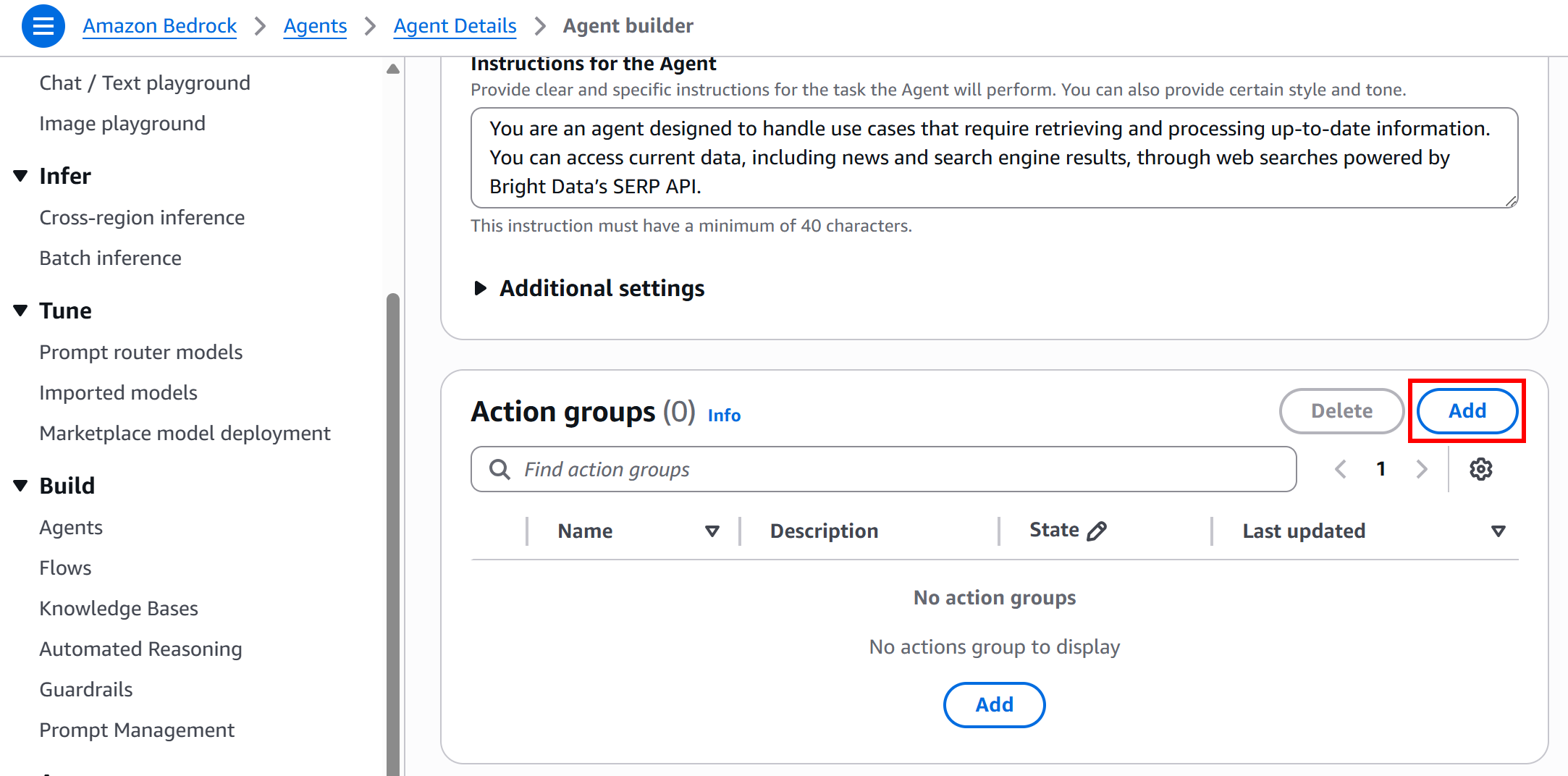
Вы являетесь агентом, предназначенным для обработки случаев использования, требующих получения и обработки актуальной информации.
Вы можете получить доступ к текущим данным, включая новости и результаты поисковых систем, с помощью веб-поиска, основанного на SERP API Bright Data.
"""
agent = bedrock.CfnAgent(
self,
AGENT_NAME,
description=agent_description,
agent_name=AGENT_NAME,
foundation_model=AI_MODEL_ID,
action_groups=[action_group],
auto_prepare=True,
instruction=agent_instruction,
agent_resource_role_arn=agent_role.role_arn,
)
# Экспорт ключевых результатов для развертывания
CfnOutput(self, "agent_id", value=agent.attr_agent_id)
CfnOutput(self, "agent_version", value=agent.attr_agent_version)Вышеприведенный код является модифицированной версией официальной реализации стека AWS CDK для веб-поискового ИИ-агента.
То, что происходит в этих более чем 150 строках кода, отражает шаги, описанные ранее в руководстве: шаг № 1, шаг № 2 и шаг № 3 нашей статьи«Как интегрировать Bright Data SERP API с AWS Bedrock AI Agents».
Чтобы лучше понять, что происходит в этом файле, разберем код на пять функциональных блоков:
- Политика и роль Lambda IAM: настраивает разрешения для функции Lambda. Lambda требует доступа к журналам CloudWatch для записи сведений об исполнении и к AWS Secrets Manager для безопасного чтения ключа API Bright Data и зоны. Для Lambda создается роль IAM и прикрепляется соответствующая политика, что обеспечивает ее безопасную работу только с необходимыми разрешениями.
- Определение функции Lambda: здесь определяется и настраивается сама функция Lambda. Она указывает среду выполнения и архитектуру Python, указывает на папку, содержащую код Lambda (который будет реализован на следующем этапе), и настраивает переменные среды, такие как уровень журнала и имя группы действий. Разрешения предоставляются, чтобы AWS Bedrock мог вызывать Lambda, позволяя агенту ИИ запускать веб-поиск через SERP API Bright Data.
- Роль IAM агента Bedrock: создает роль выполнения для агента Bedrock AI. Агенту необходимы разрешения для вызова выбранной базовой модели ИИ из поддерживаемых (в данном случае
amazon.nova-lite-v1:0). Определяется доверительная связь, чтобы только Bedrock мог принимать на себя эту роль в вашей учетной записи. Прилагается политика, предоставляющая доступ к модели. - Определение группы действий: группа действий определяет конкретные действия, которые может выполнять агент ИИ. Она связывает агента с функцией Lambda, которая позволяет ему выполнять веб-поиск через SERP API Bright Data. Группа действий также включает метаданные для входных параметров, чтобы агент понимал, как взаимодействовать с функцией и какая информация требуется для каждого поиска.
- Определение агента Bedrock AI: определяет сам агент ИИ. Он связывает агента с группой действий и ролью выполнения и предоставляет четкое описание и инструкции по его использованию.
После развертывания стека CDK в вашей консоли AWS появится ИИ-агент. Этот агент может автономно выполнять веб-поиск и извлекать актуальную информацию, используя интеграцию Bright Data SERP API в функции Lambda. Замечательно!
Шаг 8: Реализация Lambda для интеграции SERP API
Взгляните на этот фрагмент из предыдущего кода:
lambda_function = _lambda.Function(
self,
LAMBDA_FUNCTION_NAME,
function_name=LAMBDA_FUNCTION_NAME,
runtime=_lambda.Runtime.PYTHON_3_12, # Python runtime
architecture=_lambda.Architecture.ARM_64,
code=_lambda.Code.from_asset("lambda"), # Считать код Lambda из папки «lambda/»
handler=f"{LAMBDA_FUNCTION_NAME}.lambda_handler",
timeout=Duration.seconds(120),
role=lambda_role, # Прикрепить роль IAM
environment={"LOG_LEVEL": "DEBUG", "ACTION_GROUP": f"{ACTION_GROUP_NAME}"},
)Строка code=_lambda.Code.from_asset("lambda") указывает, что код функции Lambda будет загружен из папки lambda/. Поэтому создайте папку lambda/ в своем проекте и добавьте в нее файл с именем serp_api_lambda.py:
Файл serp_api_lambda.py должен содержать реализацию функции Lambda, используемой ранее определенным агентом ИИ. Реализуйте эту функцию для обработки интеграции с API SERP Bright Data следующим образом:
import json
import logging
import os
import urllib.parse
import urllib.request
import boto3
# ----------------------------
# Конфигурация ведения журнала
# ----------------------------
log_level = os.environ.get("LOG_LEVEL", "INFO").strip().upper()
logging.basicConfig(
format="[%(asctime)s] p%(process)s {%(filename)s:%(lineno)d} %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)
logger.setLevel(log_level)
# ----------------------------
# Регион AWS из среды
# ----------------------------
AWS_REGION = os.environ.get("AWS_REGION")
if not AWS_REGION:
logger.warning("Переменная среды AWS_REGION не установлена; boto3 будет использовать регион по умолчанию")
# ----------------------------
# Получить секретный объект из AWS Secrets Manager
# ----------------------------
def get_secret_object(key: str) -> str:
"""
Получить секретное значение из AWS Secrets Manager.
"""
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=AWS_REGION
)
try:
get_secret_value_response = client.get_secret_value(
SecretId=key
)
except Exception as e:
logger.error(f"Не удалось получить секрет '{key}' из Secrets Manager: {e}")
raise e
secret = json.loads(get_secret_value_response["SecretString"])
return secret
# Получить учетные данные Bright Data
bright_data_secret = get_secret_object("BRIGHT_DATA")
BRIGHT_DATA_API_KEY = bright_data_secret["BRIGHT_DATA_API_KEY"]
BRIGHT_DATA_SERP_API_ZONE = bright_data_secret["BRIGHT_DATA_SERP_API_ZONE"]
# ----------------------------
# SERP API Web Search
# ----------------------------
def serp_api_web_search(search_query: str) -> str:
"""
Вызывает Bright Data SERP API для получения результатов поиска Google.
"""
logger.info(f"Выполнение поиска Bright Data SERP API для search_query='{search_query}'")
# Кодирование запроса для URL
encoded_query = urllib.parse.quote(search_query)
# Создание URL-адреса Google для сбора SERP
search_engine_url = f"https://www.google.com/search?q={encoded_query}"
# Запрос Bright Data API (документация: https://docs.brightdata.com/scraping-automation/serp-api/send-your-first-request)
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
data = {
"zone": BRIGHT_DATA_SERP_API_ZONE,
"url": search_engine_url,
"format": "raw",
"data_format": "markdown" # Чтобы получить SERP в виде документа Markdown, готового для ИИ
}
payload = json.dumps(data).encode("utf-8")
request = urllib.request.Request(url, data=payload, headers=headers)
try:
response = urllib.request.urlopen(request)
response_data: str = response.read().decode("utf-8")
logger.debug(f"Ответ от SERP API: {response_data}")
return response_data
except urllib.error.HTTPError as e:
logger.error(f"Не удалось вызвать Bright Data SERP API. Ошибка HTTP {e.code}: {e.reason}")
except urllib.error.URLError as e:
logger.error(f"Не удалось вызвать Bright Data SERP API. Ошибка URL: {e.reason}")
return ""
# ----------------------------
# Lambda handler
# ----------------------------
def lambda_handler(event, _):
"""
Обработчик AWS Lambda.
Ожидает событие с actionGroup, function и дополнительными параметрами (включая search_query).
"""
logger.debug(f"lambda_handler вызван с событием: {event}")
action_group = event.get("actionGroup")
function = event.get("function")
parameters = event.get("parameters", [])
# Извлечение search_query из параметров
search_query = next(
(param["value"] for param in parameters if param.get("name") == "search_query"),
None,
)
logger.debug(f"Ввод поискового запроса: {search_query}")
serp_page = serp_api_web_search(search_query) if search_query else ""
logger.debug(f"Результаты поискового запроса: {serp_page}")
# Подготовка ответа Lambda
function_response_body = {"TEXT": {"body": serp_page}}
action_response = {
"actionGroup": action_group,
"function": function,
"functionResponse": {"responseBody": function_response_body},
}
response = {"response": action_response, "messageVersion": event.get("messageVersion")}
logger.debug(f"lambda_handler response: {response}")
return responseЭта функция Lambda выполняет три основные задачи:
- Безопасное извлечение учетных данных API: извлекает ключ API Bright Data и зону API SERP из AWS Secrets Manager, поэтому конфиденциальная информация никогда не закрепляется в коде.
- Выполнение веб-поиска через SERP API: кодирует поисковый запрос, формирует URL-адрес поиска Google и отправляет запрос в Bright Data SERP API. API возвращает результаты поиска в формате Markdown, который является идеальным форматом данных для использования ИИ.
- Ответ AWS Bedrock: возвращает результаты в структурированном ответе, который может использовать агент ИИ.
Вот и все! Ваша функция AWS Lambda для подключения к Bright Data SERP API успешно определена.
Шаг 9: Разверните приложение AWS CDK
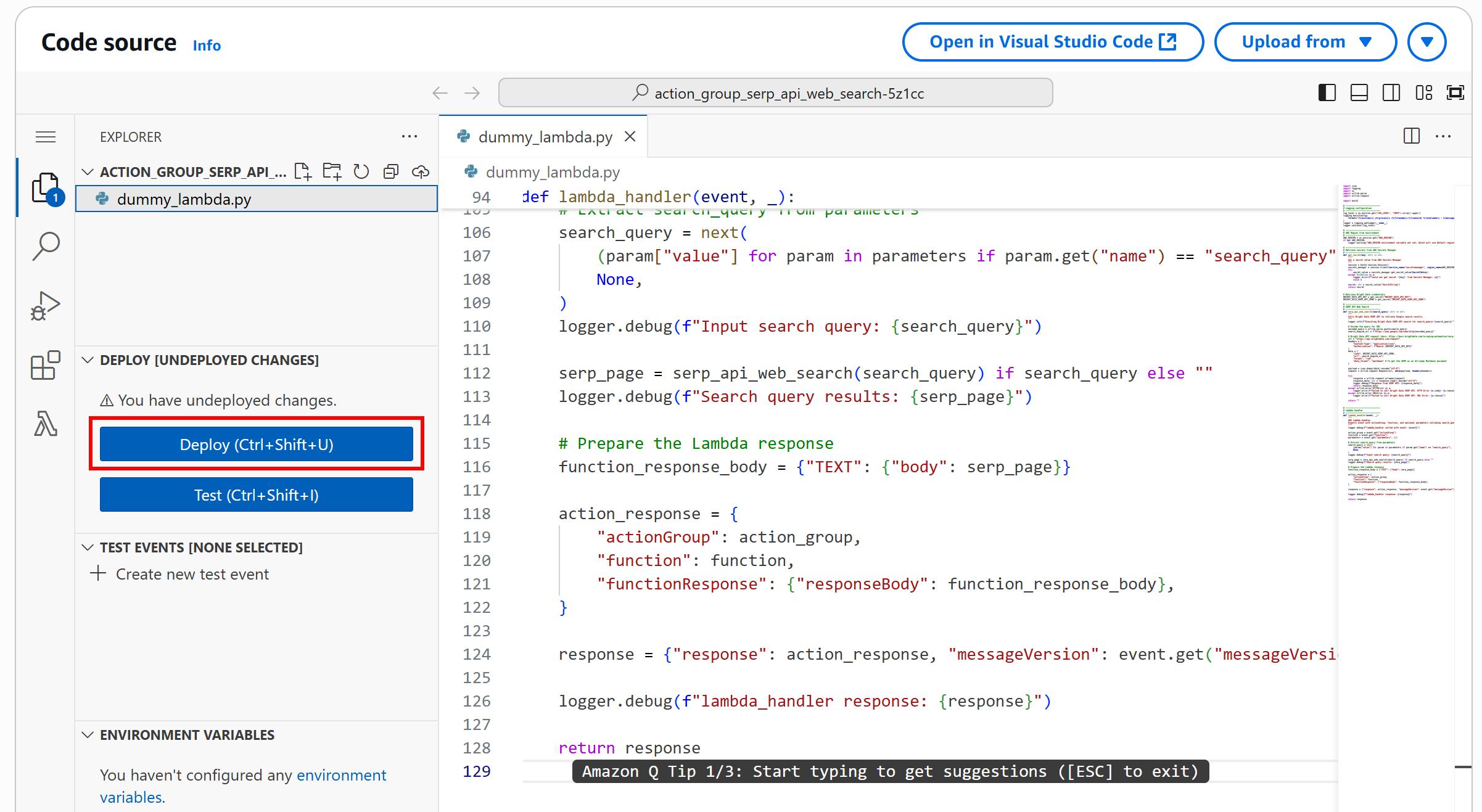
Теперь, когда ваш стек CDK и связанная с ним функция Lambda реализованы, последним шагом является развертывание вашего стека в AWS. Для этого в папке вашего проекта запустите команду развертывания:
cdk deployКогда появится запрос на предоставление разрешения на создание роли IAM, введите y для утверждения.
Через несколько секунд, если все работает как ожидалось, вы должны увидеть следующий результат:
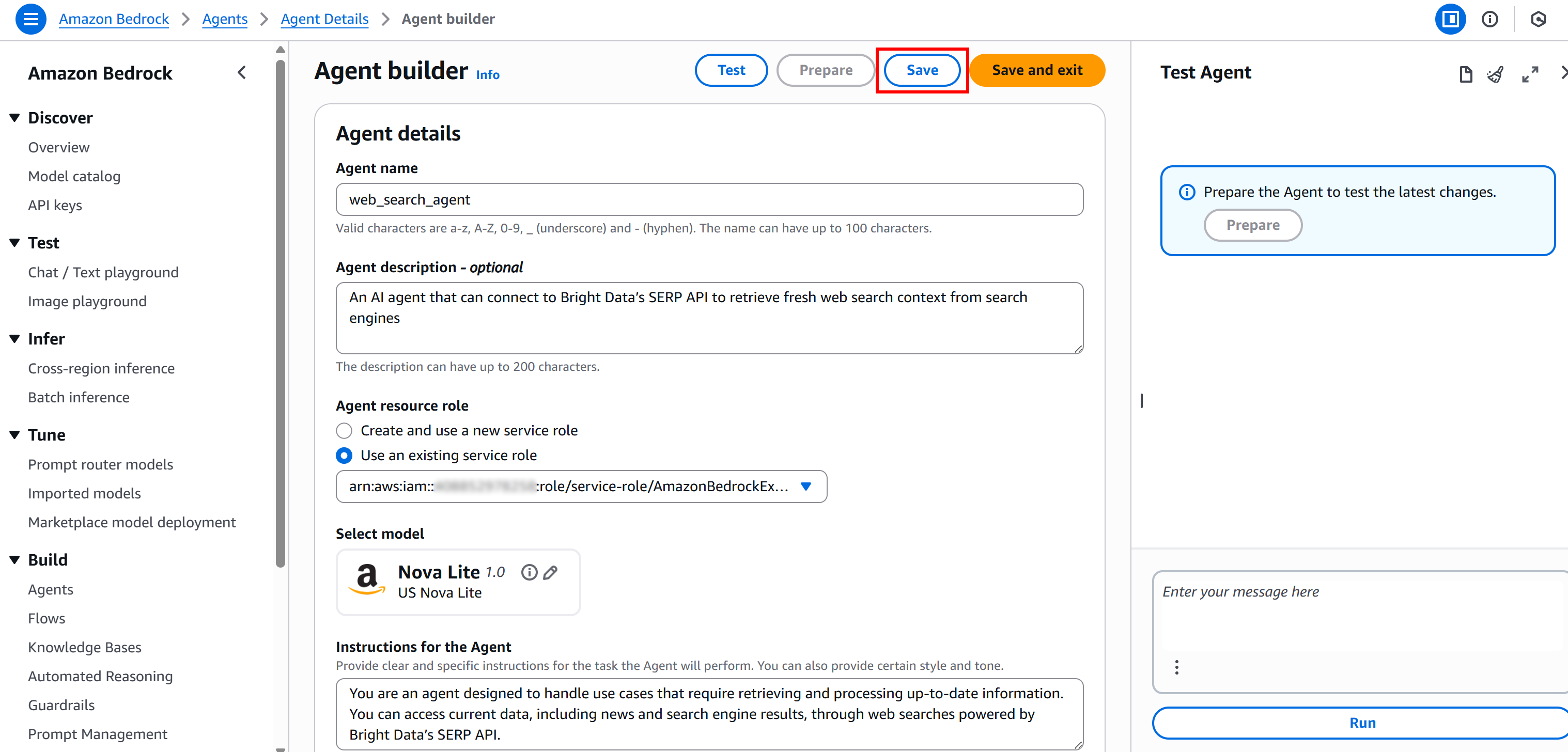
Затем перейдите в консоль Amazon Bedrock. На странице «Agents» (Агенты) вы должны увидеть запись «web_search_agent»:
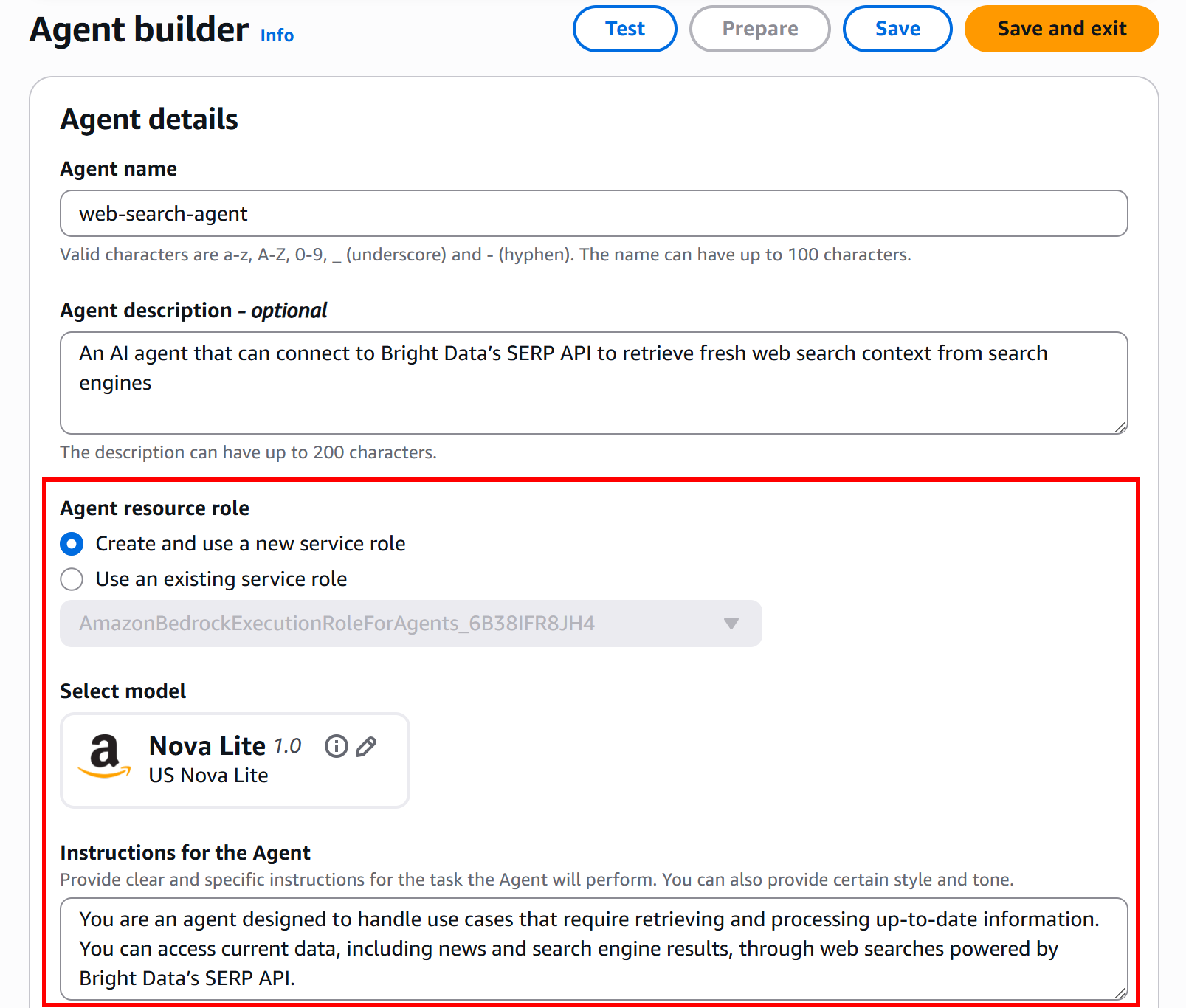
Откройте агента, и вы увидите подробную информацию о развернутом агенте:
Просмотрите его, нажав кнопку «Edit and Agent Builder» (Редактировать и создать агент), и вы увидите точно такой же агент ИИ, реализованный в«Как интегрировать Bright Data SERP API с AWS Bedrock».
Наконец, обратите внимание, что вы можете протестировать агента напрямую, используя интерфейс чата в правом углу. Это то, что вы будете делать на следующем и последнем шаге!
Шаг № 10: Тестирование ИИ-агента
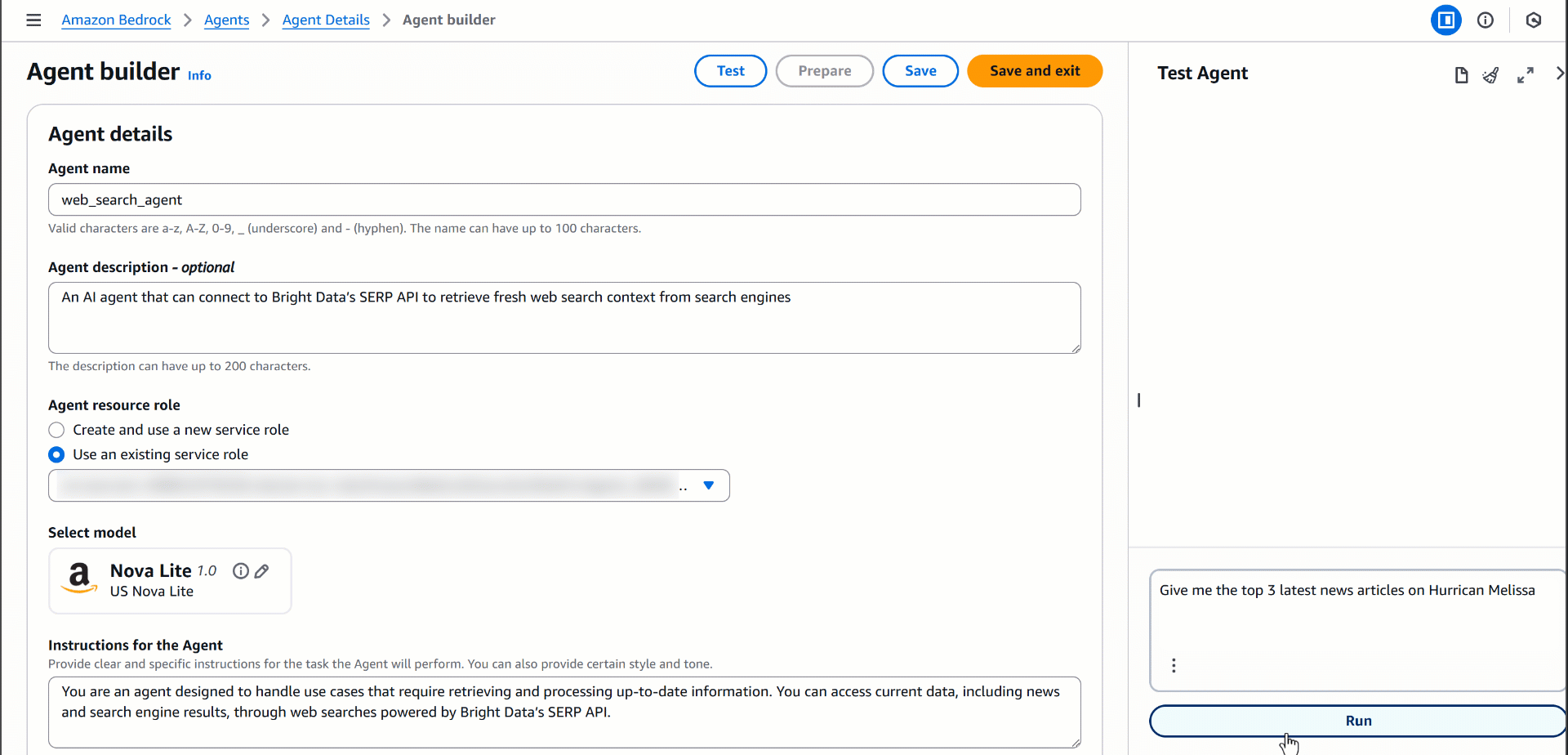
Чтобы протестировать возможности вашего ИИ-агента по веб-поиску и получению данных в реальном времени, попробуйте ввести такой запрос:
«Дайте мне 3 последние новости о закрытии правительства США»(Примечание: это всего лишь пример. Таким образом, вы можете протестировать любой запрос, который требует результатов веб-поиска).
Это идеальная команда, поскольку она запрашивает актуальную информацию, которой не располагает базовая модель. Агент вызовет функцию Lambda, интегрированную с SERP API, получит результаты и обработает данные, чтобы сгенерировать связный ответ.
Запустите эту команду в разделе «Test Agent» (Тестирование агента) вашего агента, и вы должны увидеть результат, похожий на этот:
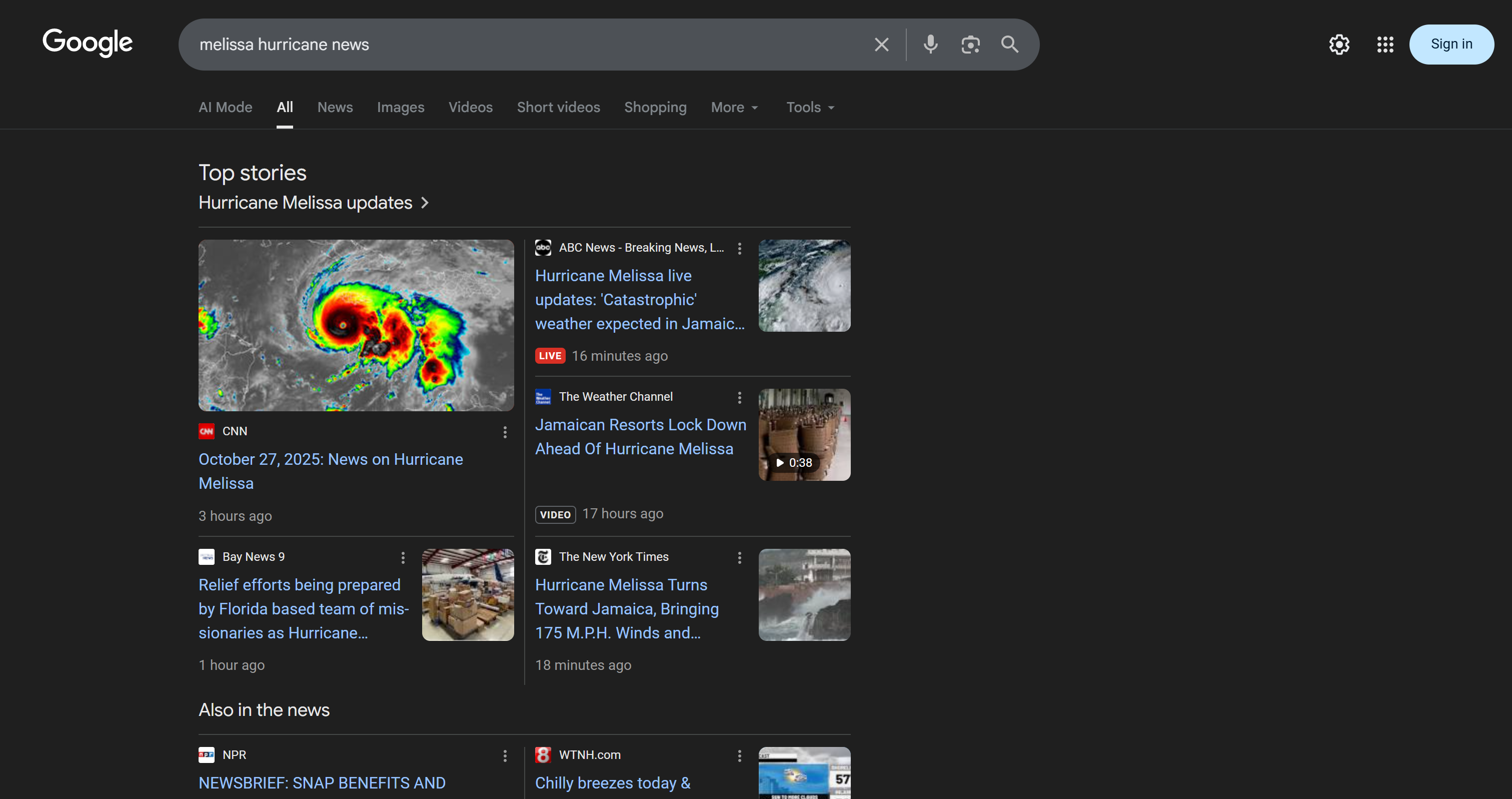
За кулисами агент вызывает функцию Lambda SERP API, извлекает последние результаты поиска Google по запросу «закрытие правительства США» и извлекает наиболее релевантные статьи (вместе с их URL-адресами). Это то, что стандартный LLM, такой как настроенный Nova Lite, не может сделать самостоятельно.
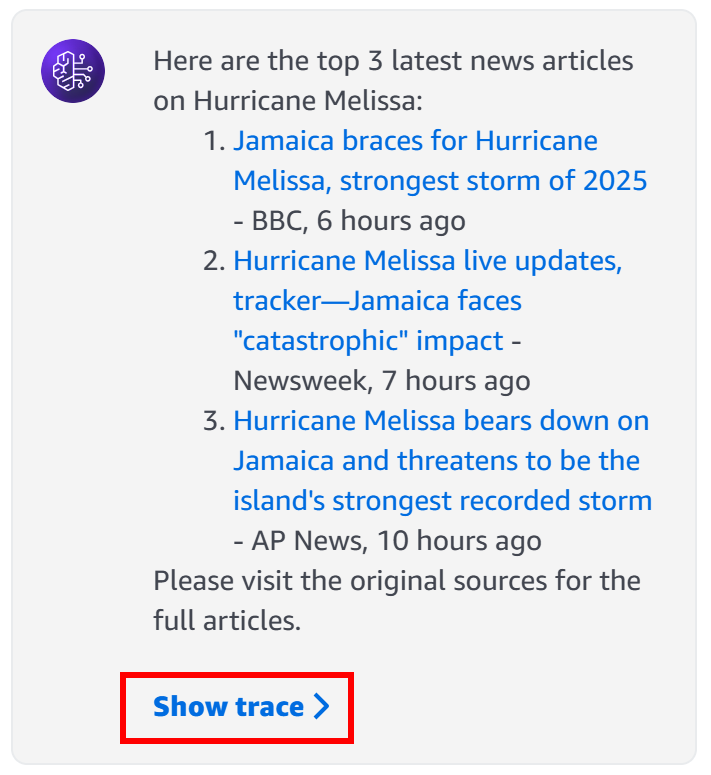
В деталях, это ответ, сгенерированный агентом:

Выбранные новостные статьи (и их URL-адреса) соответствуют тому, что вы бы нашли вручную в Google по запросу «US government shutdown» (по крайней мере, на дату тестирования агента):
Теперь любой, кто пробовал собирать результаты поиска Google, знает, насколько это может быть сложно из-за обнаружения ботов, запретов IP-адресов, рендеринга JavaScript и других проблем. API Bright Data SERP решает все эти проблемы за вас, возвращая собранные SERP в формате Markdown (или HTML, JSON и т. д.), оптимизированном для ИИ.
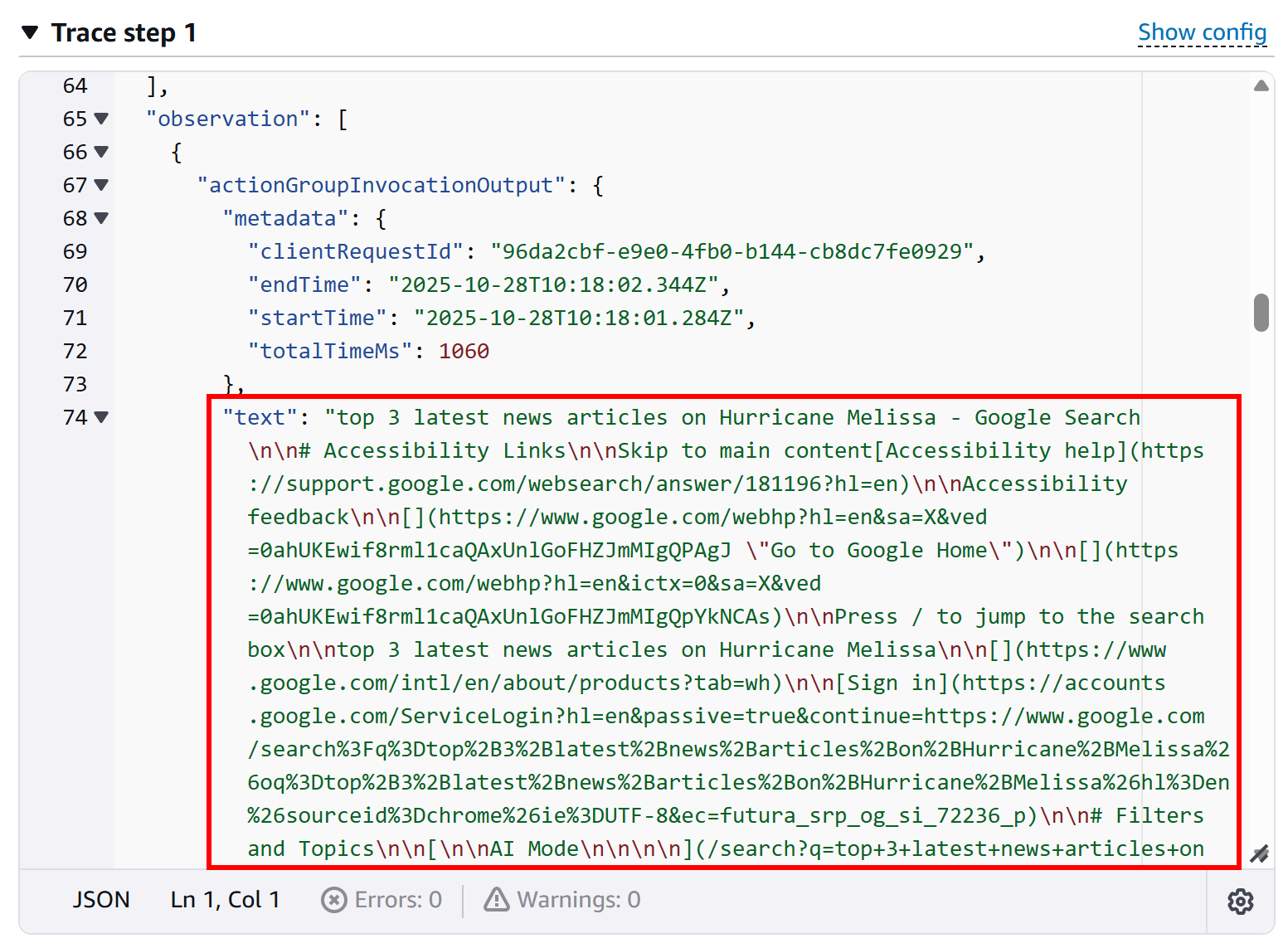
Чтобы убедиться, что ваш агент действительно вызвал функцию Lambda SERP API, нажмите кнопку «Показать трассировку» в поле ответа. В разделе «Трассировка шаг 1» прокрутите вниз до журнала вызова группы, чтобы проверить вывод из вызова Lambda:
Это подтверждает, что функция Lambda была успешно выполнена и агент взаимодействовал с SERP API, как и предполагалось. Вы также можете проверить журналы AWS CloudWatch для вашей функции Lambda, чтобы подтвердить выполнение.
Пришло время продвинуть вашего агента дальше! Протестируйте подсказки, связанные с проверкой фактов, мониторингом бренда, анализом рыночных тенденций или другими сценариями, чтобы увидеть, как он работает в различных случаях использования агентов и RAG.
Et voilà! Вы успешно создали агента AWS Bedrock, интегрированного с SERP API Bright Data, используя Python и библиотеку AWS CDK. Этот ИИ-агент способен по запросу извлекать актуальные, надежные и контекстные данные веб-поиска.
Заключение
В этом блоге вы узнали, как интегрировать SERP API Bright Data в AI-агент AWS Bedrock с помощью проекта AWS CDK Python. Этот рабочий процесс идеально подходит для разработчиков, стремящихся создать более контекстно-зависимые ИИ-агенты на AWS.
Чтобы создавать еще более сложные агенты ИИ, изучите инфраструктуру Bright Data для ИИ. Она предлагает набор инструментов для извлечения, проверки и преобразования веб-данных в режиме реального времени.
Создайте бесплатную учетную запись Bright Data сегодня и начните экспериментировать с нашими решениями для веб-данных, готовыми к использованию с ИИ!