

В этом руководстве по Scrapy Splash вы узнаете:
- Что такое Scrapy Splash
- Как использовать Scrapy Splash в Python в пошаговом руководстве
- Продвинутые техники скрапбукинга с помощью Splash в Scrapy
- Ограничения при соскабливании веб-сайтов с помощью этого инструмента
Давайте погрузимся!
Что такое Scrapy Splash?
Scrapy Splash – это интеграция между этими двумя инструментами:
- Scrapy: Библиотека с открытым исходным кодом на языке Python для извлечения нужных данных с веб-сайтов.
- Splash: Легкий безголовый браузер, предназначенный для рендеринга веб-страниц, насыщенных JavaScript.
Возможно, вы зададитесь вопросом, зачем такому мощному инструменту, как Scrapy, нужен Splash. Scrapy может работать только со статическими сайтами, поскольку он полагается на возможности разбора HTML (в частности, на Parsel). Однако при работе с динамическими сайтами вам придется иметь дело с рендерингом JavaScript. Общим решением является использование автоматизированного браузера, который как раз и предоставляет Splash.
С помощью Scrapy Splash вы можете отправить специальный запрос, известный как SplashRequest, насервер Splash. Этот сервер полностью рендерит страницу, выполняя JavaScript, и возвращает обработанный HTML. Таким образом, он позволяет вашему Scrapy Spider получать данные с динамических страниц.
Короче говоря, Scrapy Splash нужен вам, если:
- Вы работаете с сайтами, насыщенными JavaScript, которые Scrapy просто не в состоянии отскрести.
- Вы предпочитаете легкие решения по сравнению с Selenium или Playwright.
- Вы хотите избежать накладных расходов на запуск полного браузера для скраппинга.
Если Scrapy Splash не удовлетворяет вашим потребностям, рассмотрите эти альтернативы:
- Selenium: Полноценный инструмент для автоматизации работы браузера с веб-сайтами, перегруженными JavaScript, который предоставляет такие интересные расширения, как Selenium Wire.
- Playwright: Инструмент автоматизации браузера с открытым исходным кодом, обеспечивающий последовательную кросс-браузерную автоматизацию и надежный API, поддерживающий множество языков программирования.
- Puppeteer: Библиотека с открытым исходным кодом для Node.js, которая предоставляет высокоуровневый API для автоматизации и управления Chrome через протокол DevTools.
Scrapy Splash в Python: Пошаговый самоучитель
В этом разделе вы узнаете, как использовать Scrapy Splash для получения данных с веб-сайта. Целевой страницей будет специальная JavaScript-рендеринговая версия популярного сайта “Quotes to Scrape“:

Это как обычный “Quotes to Scrape”, но здесь используется бесконечная прокрутка для динамической загрузки данных с помощью AJAX-запросов, запускаемых JavaScript.
Требования
Чтобы повторить этот урок, используя Scrapy Splash на Python, ваша система должна соответствовать следующим требованиям:
- Python 3.10.1 или выше.
- Docker 27.5.1 или выше.
Если на вашем компьютере не установлены эти два инструмента, перейдите по указанным выше ссылкам.
Необходимые условия, зависимости и интеграция Splash
Предположим, вы назовете главную папку своего проекта scrapy_splash/. По завершении этого шага папка будет иметь следующую структуру:
scrapy_splash/
└── venv/Где venv/ содержит виртуальную среду. Вы можете создать каталог виртуальной среды venv/ следующим образом:
python -m venv venvЧтобы активировать его, в Windows выполните команду:
venvScriptsactivateАналогично, в macOS и Linux выполните команду:
source venv/bin/activateВ активированной виртуальной среде установите зависимости с помощью:
pip install scrapy scrapy-splashВ качестве последнего условия вам нужно извлечь образ Splash через Docker:
docker pull scrapinghub/splashЗатем запустите контейнер:
docker run -it -p 8050:8050 --rm scrapinghub/splashДля получения дополнительной информации следуйте инструкциям по интеграции Docker на базе ОС.
После запуска контейнера Docker дождитесь, пока служба Splash не выдаст сообщение, приведенное ниже:
Server listening on http://0.0.0.0:8050Сообщение сообщает, что Splash теперь доступен по адресу http://0.0.0.0:8050. Перейдите по этому URL-адресу в браузере, и вы увидите следующую страницу:

В зависимости от вашей конфигурации переход по URL-адресу http://0.0.0.0:8050 может не показать, что служба Splash работает. В этом случае попробуйте использовать один из следующих вариантов:
http://localhost:8050http://127.0.0.1:8050
Примечание: Помните, что соединение с сервером Splash должно оставаться открытым во время использования Scrapy-Splash. Другими словами, если вы использовали CLI для запуска контейнера Docker, держите этот терминал открытым и используйте отдельный терминал для выполнения следующих шагов этой процедуры.
Замечательно! Теперь у вас есть все необходимое, чтобы скрести веб-страницы с помощью Scrapy Splash.
Шаг #1: Начните новый проект Scrapy
В основной папке scrapy_splash/ введите следующую команду, чтобы запустить новый проект Scrapy:
scrapy startproject quotesС помощью этой команды Scrapy создаст папку quotes/. Внутри нее она автоматически сгенерирует все необходимые файлы. Вот результирующая структура папок:
scrapy_splash/
├── quotes/
│ ├── quotes/
│ │ ├── spiders/
│ │ ├── __init__.py
│ │ ├── items.py
│ │ ├── middlewares.py
│ │ ├── pipelines.py
│ │ └── settings.py
│ │
│ └── scrapy.cfg
└── venv/ Отлично! Вы начали новый проект Scrapy.
Шаг № 2: Создайте паука
Чтобы сгенерировать нового паука для просмотра целевого сайта, перейдите в папку quotes/:
cd quotesЗатем сгенерируйте нового паука:
scrapy genspider words https://quotes.toscrape.com/scrollВы получите следующий результат:
Created spider 'words' using template 'basic' in module:
quotes.spiders.wordsКак вы можете видеть, Scrapy автоматически создал файл words.py в папке spiders/. Файл words.py содержит следующий код:
import scrapy
class WordsSpider(scrapy.Spider):
name = "words"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/scroll"]
def parse(self, response):
passВскоре в нем будет содержаться необходимая логика извлечения информации с динамической целевой страницы.
Ура! Вы сгенерировали паука, чтобы он поскреб целевой сайт.
Шаг #3: Настройте Scrapy на использование Splash
Теперь вам нужно настроить Scrapy так, чтобы он мог использовать сервис Splash. Для этого добавьте следующие конфигурации в файл settings.py:
# Set the Splash local server endpoint
SPLASH_URL = "http://localhost:8050"
# Enable the Splash downloader middleware
DOWNLOADER_MIDDLEWARES = {
"scrapy_splash.SplashCookiesMiddleware": 723,
"scrapy_splash.SplashMiddleware": 725,
"scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware": 810,
}
# Enable the Splash deduplication argument filter
SPIDER_MIDDLEWARES = {
"scrapy_splash.SplashDeduplicateArgsMiddleware": 100,
}В приведенных выше конфигурациях:
SPLASH_URLзадает конечную точку для локального сервера Splash. Сюда Scrapy будет отправлять запросы на рендеринг JavaScript.DOWNLOADER_MIDDLEWARESпозволяет определенным промежуточным программам взаимодействовать с Splash. В частности:Polylang placeholder do not modify
SPIDER_MIDDLEWARESгарантирует, что запросы с одинаковыми аргументами Splash не будут дублироваться, что полезно для снижения лишней нагрузки и повышения эффективности.
Более подробную информацию об этих конфигурациях можно найти в официальной документации по Scrapy-Splash.
Отлично! Теперь Scrapy может подключаться к Splash и программно использовать его для рендеринга JavaScript.
Шаг #4: Определите сценарий Lua для рендеринга на JavaScript
Scrapy теперь может интегрироваться с Splash для рендеринга веб-страниц, основанных на JavaScript, как, например, целевая страница этого руководства. Чтобы определить пользовательскую логику рендеринга и взаимодействия, необходимо использовать сценарии Lua. Это связано с тем, что Splash опирается на сценарии Lua для взаимодействия с веб-страницами через JavaScript и программного управления поведением браузера.
В частности, добавьте приведенный ниже сценарий Lua в файл words.py:
script = """
function main(splash, args)
splash:go(args.url)
-- custom rendering script logic...
return splash:html()
end
"""В приведенном выше фрагменте переменная script содержит логику Lua, которую Splash будет выполнять на сервере. В частности, этот сценарий предписывает Splash:
- Перейдите на заданный URL с помощью метода
splash:go(). - Верните отрисованное HTML-содержимое с помощью метода
splash:html().
Используйте приведенный выше сценарий Lua в функции start_requests() внутри класса WordsSpider:
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)Приведенный выше метод start_requests() переопределяет стандартный start_requests() Scrapy. Таким образом, Scrapy Splash может выполнить Lua-скрипт для получения JavaScript-рендеринга HTML страницы. Выполнение Lua-скрипта происходит через аргумент "lua_source": script в методе SplashRequest(). Также обратите внимание на использование конечной точки Splash "execute" (о которой вы узнаете в ближайшее время).
Не забудьте импортировать SplashRequest из Scrapy Splash:
from scrapy_splash import SplashRequestТеперь ваш файл words.py оснащен правильным сценарием Lua для доступа к содержимому страницы, отображаемому на JavaScript!
Шаг #5: Определите логику разбора данных
Прежде чем приступить к работе, просмотрите HTML-элемент цитаты на целевой странице, чтобы понять, как его разобрать:

Здесь видно, что элементы цитаты можно выбрать с помощью .quote. Получив цитату, вы можете получить:
- Текст цитаты из
файла .text. - Автор цитаты из
.author. - Теги цитат из
.tags.
Логика скраппинга для получения всех цитат с целевой страницы может быть определена с помощью следующего метода parse():
def parse(self, response):
# Retrieve CSS selectors
quotes = response.css(".quote")
for quote in quotes:
yield {
"text": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"tags": quote.css(".tags a.tag::text").getall()
}parse() обрабатывает ответ, возвращаемый Splash. В деталях она:
- Извлекает все элементы
divс классомquoteс помощью CSS-селектора".quote". - Итерация над каждым элементом
цитатыдля извлечения имени, автора и тега для каждой цитаты.
Очень хорошо! Логика скрапирования Scrapy Splash завершена.
Шаг #6: Соберите все вместе и запустите сценарий
Вот как должен выглядеть ваш окончательный файл words.py:
import scrapy
from scrapy_splash import SplashRequest
# Lua script for JavaScript rendering
script = """
function main(splash, args)
splash:go(args.url)
return splash:html()
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
yield {
"text": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"tags": quote.css(".tags a.tag::text").getall()
}Запустите сценарий с помощью этой команды:
scrapy crawl wordsЭто ожидаемый результат:

Желаемый результат можно представить следующим образом:
2025-03-18 12:21:55 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/scroll>
{'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Albert Einstein', 'tags': ['change', 'deep-thoughts', 'thinking', 'world']}
2025-03-18 12:21:55 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/scroll>
{'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', 'author': 'J.K. Rowling', 'tags': ['abilities', 'choices']}
# omitted for brevity...
2025-03-18 12:21:55 [scrapy.core.engine] INFO: Closing spider (finished)Обратите внимание, что в выходных данных содержатся интересующие вас данные.
Обратите внимание, что если вы удалите метод start_requests() из класса Words``Spider, Scrapy не вернет никаких данных. Это связано с тем, что без Splash она не может отображать страницы, требующие JavaScript.
Очень хорошо! Вы завершили свой первый проект Scrapy Splash.
Заметка о брызгах
Splash – это сервер, который взаимодействует по протоколу HTTP. Это позволяет вам скрести веб-страницы с помощью Splash, используя любой HTTP-клиент, вызывая его конечные точки. Он предоставляет следующие конечные точки:
execute: Выполняет пользовательский скрипт рендеринга Lua и возвращает его результат.render.html: Возвращает HTML-файл страницы, отрендеренной на javascript.render.png: Возвращает изображение (в формате PNG) страницы, отрендеренной с помощью javascript.render.jpeg: Возвращает изображение (в формате JPEG) страницы, отрендеренной с помощью javascript.render.har: Возвращает информацию о взаимодействии Splash с веб-сайтом в формате HAR.render.json: Возвращает словарь в кодировке JSON с информацией о веб-странице, отрендеренной на javascript. Он может включать HTML, PNG и другую информацию, основанную на переданных аргументах.
Чтобы лучше понять, как работают эти конечные точки, рассмотрим конечную точку render.html. Подключитесь к конечной точке с помощью этого кода на языке Python:
# pip install requests
import requests
import json
# URL of the Splash endpoint
url = "http://localhost:8050/render.html"
# Sending a POST request to the Splash endpoint
payload = json.dumps({
"url": "https://quotes.toscrape.com/scroll" # URL of the page to render
})
headers = {
"content-type": "application/json"
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Этот фрагмент определяет:
- Экземпляр Splash на localhost в качестве URL-адреса, выполняющего вызов конечной точки
render.html. - Целевая страница, которую нужно выскрести из
полезной нагрузки.
Выполните приведенный выше код и получите рендеринг HTML всей страницы:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Хотя Splash может самостоятельно обрабатывать HTML с JavaScript-рендерингом, использование Scrapy Splash с SplashRequest значительно упрощает процесс веб-скрапинга.
Scrapy Splash: продвинутые техники скрапинга
В предыдущем параграфе вы завершили базовый учебник по Scrapy с интеграцией Splash. Пора попробовать продвинутые техники скрапбукинга с помощью Scrapy Splash!
Управление расширенной прокруткой
Целевая страница содержит цитаты, которые загружаются динамически через AJAX благодаря бесконечной прокрутке:
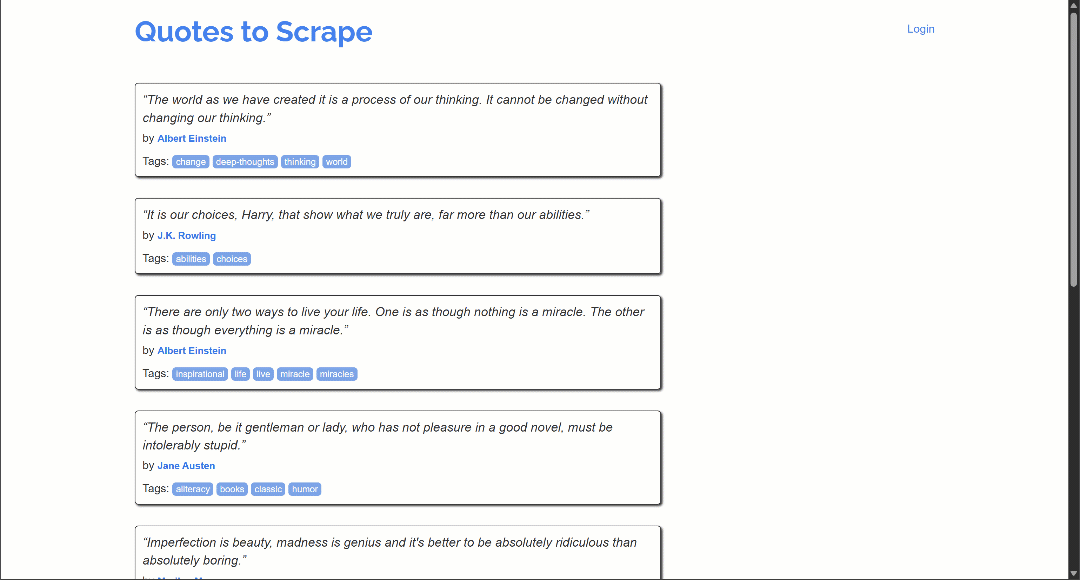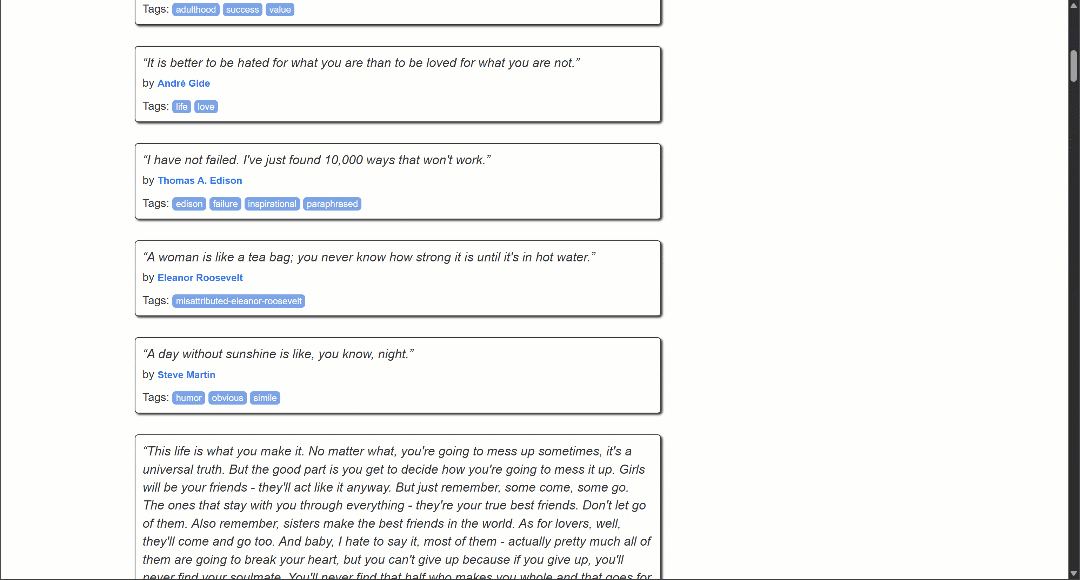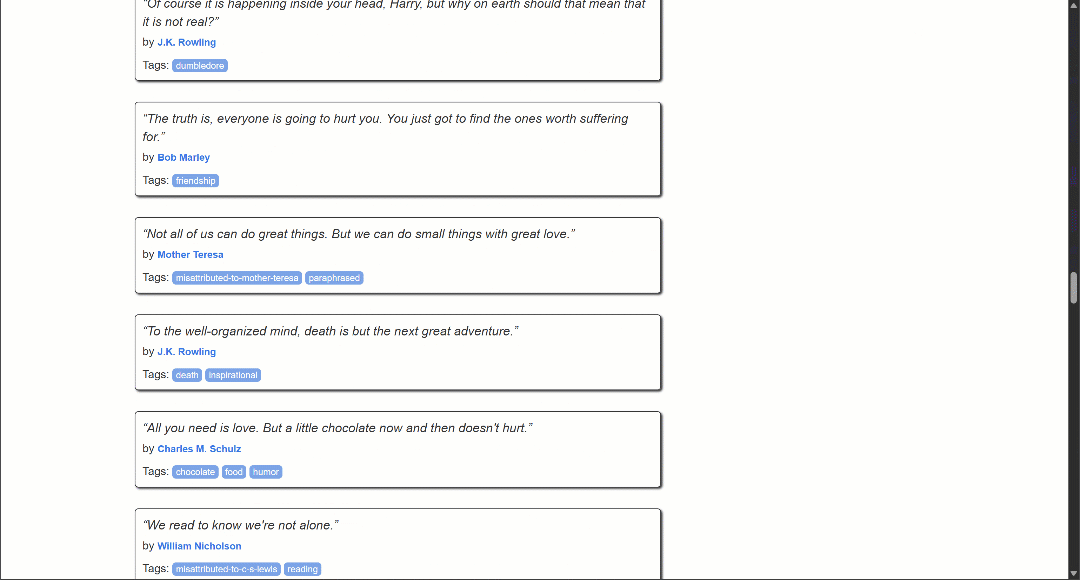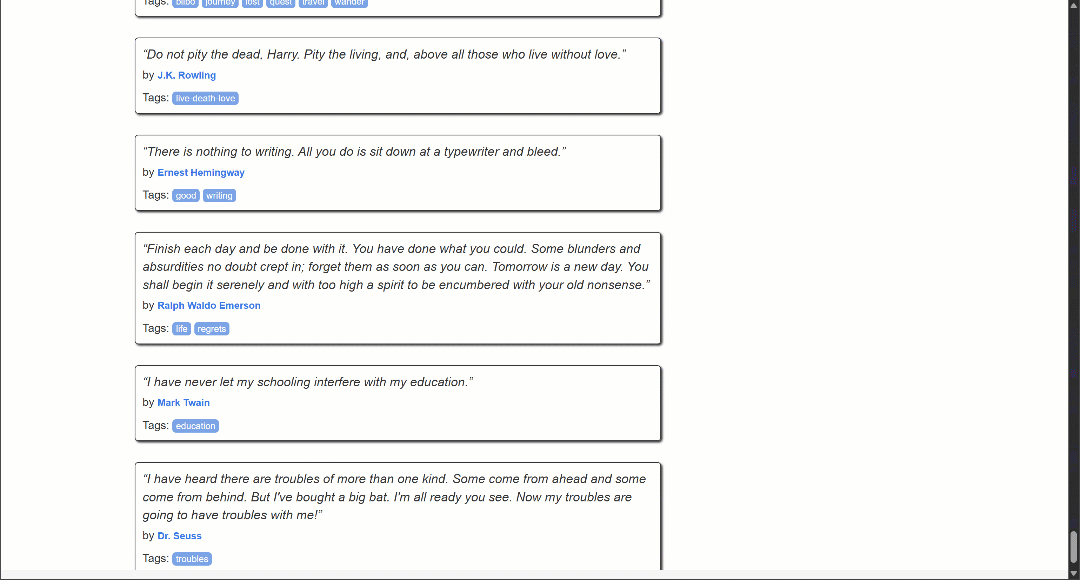
Чтобы управлять взаимодействием с бесконечной прокруткой, необходимо изменить скрипт Lua следующим образом:
script = """
function main(splash, args)
local scroll_delay = 1.0 -- Time to wait between scrolls
local max_scrolls = 10 -- Maximum number of scrolls to perform
local scroll_to = 1000 -- Pixels to scroll down each time
splash:go(args.url)
splash:wait(scroll_delay)
local scroll_count = 0
while scroll_count < max_scrolls do
scroll_count = scroll_count + 1
splash:runjs("window.scrollBy(0, " .. scroll_to .. ");")
splash:wait(scroll_delay)
end
return splash:html()
end
"""Этот модифицированный скрипт опирается на эти переменные:
max_scrollsопределяет максимальное количество прокруток. Это значение может быть изменено в зависимости от того, какой объем содержимого вы хотите соскрести со страницы.scroll_toзадает количество пикселей для прокрутки вниз каждый раз. Его значение может потребоваться скорректировать в зависимости от поведения страницы.splash:runjs()выполняет функцию JavaScriptwindow.scrollBy(), чтобы прокрутить страницу вниз на указанное количество пикселей.splash:wait()обеспечивает ожидание скрипта перед загрузкой нового содержимого. Количество времени ожидания (в секундах) определяется переменнойscroll_delay.
Проще говоря, приведенный выше Lua-скрипт имитирует определенное количество прокруток в сценарии бесконечной прокрутки веб-страницы.
Код в файле words.py будет выглядеть следующим образом:
import scrapy
from scrapy_splash import SplashRequest
# Lua script for infinite scrolling
script = """
function main(splash, args)
local scroll_delay = 1.0 -- Time to wait between scrolls
local max_scrolls = 10 -- Maximum number of scrolls to perform
local scroll_to = 1000 -- Pixels to scroll down each time
splash:go(args.url)
splash:wait(scroll_delay)
local scroll_count = 0
while scroll_count < max_scrolls do
scroll_count = scroll_count + 1
splash:runjs("window.scrollBy(0, " .. scroll_to .. ");")
splash:wait(scroll_delay)
end
return splash:html()
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)
def parse(self, response):
# Retrieve CSS selectors
quotes = response.css("div.quote")
for quote in quotes:
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("span small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall()
}Запустите сценарий с помощью команды, приведенной ниже:
scrapy crawl wordsКраулер выведет все отсканированные цитаты в соответствии с переменной max_scrolls. Это и есть ожидаемый результат:

Обратите внимание, что теперь вывод содержит значительно больше цитат, чем раньше. Это подтверждает, что страницы были успешно прокручены вниз, и новые данные были загружены и соскоблены.
Отлично! Теперь вы узнали, как управлять бесконечной прокруткой с помощью Scrapy Splash.
Дождаться элемента
Веб-страницы могут получать данные динамически или рендерить узлы в браузере. Это означает, что на отрисовку конечного DOM может потребоваться время. Чтобы избежать ошибок при получении данных с веб-сайта, всегда дожидайтесь загрузки элемента на странице, прежде чем взаимодействовать с ним.
В этом примере элементом ожидания будет текст из первой цитаты:

Чтобы реализовать логику ожидания, напишите Lua-скрипт следующим образом:
script = """
function main(splash, args)
splash:go(args.url)
while not splash:select(".text") do
splash:wait(0.2)
print("waiting...")
end
return { html=splash:html() }
end
"""Этот скрипт создает цикл while, который ждет 0,2 секунды, если текстовый элемент находится на странице. Чтобы проверить, находится ли элемент .text на странице, можно использовать метод splash:select().
Ждите времени
Поскольку веб-страницы с динамическим содержимым требуют времени для загрузки и рендеринга, вы можете подождать несколько секунд, прежде чем получить доступ к HTML-содержимому. Этого можно добиться с помощью метода splash:wait(), как показано ниже:
script = """
function main(splash, args)
splash:wait(args.wait)
splash:go(args.url)
return { html=splash:html() }
end
"""В этом случае секунды, которые скрипт должен подождать, выражаются в методе SplashRequest() с помощью аргумента Lua script.
Например, установите значение"wait" : 2.0, чтобы сообщить скрипту Lua о необходимости подождать 2 секунды:
import scrapy
from scrapy_splash import SplashRequest
script = """
function main(splash, args)
splash:wait(args.wait)
splash:go(args.url)
return { html=splash:html() }
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script, "wait": 2.0} # Waiting for 2 seconds
)
# ...Примечание: Жесткое ожидание(splash:wait()) полезно для локального тестирования, поскольку оно гарантирует, что страница загрузится до начала работы. Такой подход не идеален для производства, поскольку добавляет ненужные задержки, снижая производительность и масштабируемость. Кроме того, вы не можете заранее знать, сколько времени нужно ждать.
Молодцы! Вы научились ждать определенное время в Scrapy Splash.
Ограничения использования Scrapy Splash
В этом уроке вы узнали, как использовать Scrapy Splash для извлечения данных из Сети в различных сценариях. Несмотря на простоту этой интеграции, у нее есть некоторые недостатки.
Например, для настройки Splash требуется запустить отдельный сервер Splash с Docker, что усложняет инфраструктуру скраппинга. Кроме того, API сценариев Lua в Splash несколько ограничен по сравнению с более современными инструментами, такими как Puppeteer и Playwright.
Однако, как и во всех безголовых браузерах, наибольшее ограничение исходит от самого браузера. Технологии защиты от скраппинга могут обнаружить, что браузер не используется в обычном режиме, а автоматизируется, что приводит к блокировке сценариев.
Забудьте об этих проблемах с помощью Scraping Browser –специализированного облачного браузера для скрапинга, разработанного для бесконечного масштабирования. Он включает в себя решение CAPTCHA, управление отпечатками пальцев браузера и обход анти-ботов, так что вам не придется беспокоиться о том, что вас заблокируют.
Заключение
В этой статье вы узнали, что такое Scrapy Splash и как он работает. Вы начали с основ, а затем изучили более сложные сценарии скрапинга.
Вы также обнаружили ограничения этого инструмента, в частности его уязвимость перед антиботами и системами защиты от скрапинга. Для преодоления этих проблем отлично подходит Scraping Browser. Это лишь одно из множества решений для сбора данных Bright Data, которые вы можете попробовать:
- Услуги прокси: Четыре различных типа прокси-серверов для обхода ограничений по местоположению, включая 150 миллионов IP-адресов жителей.
- API для веб-скреперов: Специальные конечные точки для извлечения свежих структурированных веб-данных из более чем 100 популярных доменов.
- SERP API: API для обработки всех текущих операций по разблокировке SERP и извлечению одной страницы
Зарегистрируйтесь на сайте Bright Data прямо сейчас и начните бесплатную пробную версию, чтобы протестировать наши решения для сбора информации.





