

В этом руководстве вы узнаете:
- Почему Perplexity – хороший выбор для веб-скраппинга на основе искусственного интеллекта
- Как скреативить сайт в Python с помощью пошагового руководства
- Основное ограничение этого подхода к веб-скреппингу и способы его обхода
Давайте начнем!
Почему стоит использовать Perplexity для веб-скрапинга?
Perplexity – это поисковая система на базе искусственного интеллекта, использующая большие языковые модели для создания подробных ответов на запросы пользователей. Он извлекает информацию в режиме реального времени, обобщает ее и может предоставить в ответ ссылки на источники.
Использование Perplexity для веб-скрепинга сводит процесс извлечения данных из неструктурированного HTML-контента к простой подсказке. Это устраняет необходимость в ручном разборе данных, что значительно упрощает извлечение нужной информации.
Кроме того, Perplexity создан для продвинутых сценариев веб-кроулинга, благодаря своим возможностям по обнаружению и изучению веб-страниц.
Для получения дополнительной информации см. наше руководство по использованию искусственного интеллекта для веб-скрапинга.
Примеры использования
Некоторые примеры использования скраппинга с помощью Perplexity::
- Страницы, часто меняющие структуру: Он может адаптироваться к динамическим страницам, где макеты и элементы данных часто меняются, например, к сайтам электронной коммерции, таким как Amazon.
- Создание крупных веб-сайтов: он может помочь в обнаружении и навигации по страницам или выполнить поиск на основе искусственного интеллекта, который направляет процесс создания сайтов.
- Извлечение данных из сложных страниц: Для сайтов с трудноразбираемой структурой Perplexity может автоматизировать извлечение данных, не требуя при этом обширной пользовательской логики разбора.
Сценарии
Некоторые примеры, когда скраппинг с помощью Perplexity может быть полезен:
- Retrieval-Augmented Generation (RAG): Расширение возможностей искусственного интеллекта за счет интеграции сбора данных в режиме реального времени. Для практического примера использования подобной модели ИИ ознакомьтесь с нашим руководством по созданию чатбота RAG на основе данных SERP.
- Агрегация контента: Сбор новостей, сообщений в блогах или статей из нескольких источников для составления сводок или аналитики.
- Скраппинг социальных сетей: Извлечение структурированных данных из платформ с динамичным или часто обновляемым контентом.
Как выполнить веб-скраппинг с помощью Perplexity в Python
В этом разделе мы будем использовать конкретную страницу товара из песочницы “Ecommerce Test Site to Learn Web Scraping“:

Эта страница представляет собой отличный пример, поскольку страницы товаров электронной коммерции часто имеют различную структуру и отображают разные типы данных. Именно это делает веб-скраппинг в электронной коммерции таким сложным, и именно здесь может помочь искусственный интеллект.
В частности, скрепер на базе Perplexity будет использовать искусственный интеллект для извлечения подробной информации о продукте со страницы, не прибегая к ручному парсингу:
- SKU
- Имя
- Изображения
- Цена
- Описание
- Размеры
- Цвета
- Категория
Примечание: Для простоты и из-за популярности соответствующих SDK следующий пример будет на языке Python. Тем не менее, вы можете получить тот же результат, используя JavaScript или любой другой язык программирования.
Следуйте приведенным ниже инструкциям, чтобы узнать, как собирать веб-данные с помощью Perplexity!
Шаг № 1: Создайте свой проект
Прежде чем начать, убедитесь, что на вашем компьютере установлен Python 3. Если он не установлен, загрузите его и следуйте инструкциям по установке.
Затем выполните приведенную ниже команду, чтобы инициализировать папку для вашего проекта скрапбукинга:
mkdir perplexity-scraperДиректория perplexity-scraper будет служить папкой проекта для веб-скраппинга с помощью Perplexity.
Перейдите в папку в терминале и создайте в ней виртуальную среду Python:
cd perplexity-scraper
python -m venv venvОткройте папку проекта в предпочитаемой вами IDE Python. Visual Studio Code с расширением Python или PyCharm Community Edition – отличные варианты.
Создайте файл scraper.py в папке проекта, который теперь должен выглядеть следующим образом:

На данный момент scraper.py – это просто пустой Python-скрипт, но вскоре он будет содержать логику для веб-скреппинга LLM.
Затем активируйте виртуальную среду в терминале вашей IDE. В Linux или macOS выполните команду:
source venv/bin/activateЭквивалентно, в Windows используйте:
venv/Scripts/activateОтлично! Теперь ваша среда Python настроена для веб-скраппинга с помощью Perplexity.
Шаг № 2: Получите ключ API Perplexity
Как и большинство поставщиков ИИ, Perplexity предоставляет свои модели через API. Чтобы получить к ним программный доступ, вам сначала нужно выкупить ключ API Perplexity. Вы можете обратиться к официальному руководству “Первоначальная настройка” или следовать приведенным ниже инструкциям.
Если у вас еще нет учетной записи Perplexity, создайте ее и войдите в систему. Затем перейдите на страницу “API” и нажмите “Настроить”, чтобы добавить способ оплаты, если вы этого еще не сделали:

Примечание: На этом этапе с вас не будет взиматься плата. Perplexity сохраняет ваши платежные данные только для будущего использования API. Вы можете использовать кредитную/дебетовую карту, Google Pay или любой другой поддерживаемый способ оплаты.
После настройки способа оплаты вы увидите следующий раздел:

Приобретите несколько кредитов, нажав на кнопку “+ Купить кредиты”, и дождитесь, пока они будут добавлены в ваш аккаунт. Как только кредиты станут доступны, кнопка “+ Генерировать” в разделе API-ключей станет активной. Нажмите ее, чтобы сгенерировать свой API-ключ Perplexity:

На экране появится ключ API:

Скопируйте ключ и храните его в надежном месте. Для простоты мы определим его как константу в scraper.py:
PERPLEXITY_API_KEY="<YOUR_PERPLEXITY_API_KEY>"Важно: В производственных скриптах Perplexity избегайте хранения ключей API в виде обычного текста. Вместо этого храните такие секреты в переменных окружения или в файле .env, управляемом с помощью таких библиотек, как python-dotenv.
Замечательно! Вы готовы использовать OpenAI SDK для выполнения API-запросов к моделям Perplexity на Python.
Шаг #3: Настройка Perplexity в Python
В последнем предложении предыдущего шага нет опечатки, несмотря на то, что в нем упоминается OpenAI SDK. Это потому, что Perplexity API полностью совместим с OpenAI. На самом деле, рекомендуемый способ подключения к Perplexity API с помощью Python – через OpenAI SDK.
В качестве первого шага установите OpenAI Python SDK. В активированной виртуальной среде запустите:
pip install openaiЗатем импортируйте его в сценарий scraper.py:
from openai import OpenAIЧтобы подключиться к Perplexity вместо OpenAI, настройте клиент следующим образом:
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")Отлично! Настройка Perplexity Python завершена, и вы готовы делать API-запросы к их моделям.
Шаг #4: Получите HTML целевой страницы
Теперь вам нужно получить HTML целевой страницы. Это можно сделать с помощью мощного HTTP-клиента Python, например Requests.
В активированной виртуальной среде установите Requests с помощью:
pip install requestsЗатем импортируйте библиотеку в файл scraper.py:
import requestsИспользуйте метод get(), чтобы отправить GET-запрос на URL страницы:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)В ответ целевой сервер получит исходный HTML-файл страницы.
Если вы напечатаете response.content, то увидите полный HTML-документ:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Ajax Full-Zip Sweatshirt – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Теперь у вас есть точный HTML целевой страницы на языке Python. Давайте разберем его и извлечем из него нужные нам данные!
Шаг #5: Преобразование HTML-страницы в Markdown (необязательно)
Внимание: Этот шаг не является технически обязательным, но он может сэкономить вам значительное время и деньги. Поэтому его определенно стоит рассмотреть.
Обратите внимание на то, как другие технологии веб-скреппинга, основанные на искусственном интеллекте, например Crawl4AI и ScrapeGraphAI, обрабатывают сырой HTML. Вы заметите, что обе они предлагают опции для преобразования HTML в Markdown перед передачей содержимого в настроенный LLM.
Почему они так поступают? Есть две основные причины:
- Экономическая эффективность: Преобразование в Markdown сокращает количество маркеров, отправляемых в ИИ, что помогает вам сэкономить деньги.
- Более быстрая обработка: Меньшее количество исходных данных означает меньшие вычислительные затраты и более быстрые ответы.
Подробнее об этом читайте в нашем руководстве о том , почему новые агенты ИИ выбирают Markdown, а не HTML.
Пора повторить логику преобразования HTML в Markdown, чтобы уменьшить использование токенов!
Начните с открытия целевой веб-страницы в режиме инкогнито (чтобы убедиться, что вы работаете в новой сессии). Затем щелкните правой кнопкой мыши в любом месте страницы и выберите “Осмотреть”, чтобы открыть инструменты разработчика.
Изучите структуру страницы. Вы увидите, что все необходимые данные содержатся в HTML-элементе, обозначенном CSS-селектором #main:

Технически, вы можете отправить весь необработанный HTML в Perplexity для разбора данных. Однако в этом случае вы получите много ненужной информации – например, заголовки и нижние колонтитулы. Вместо этого использование содержимого внутри #main в качестве исходных данных гарантирует, что вы будете иметь дело только с наиболее релевантными данными. Это уменьшит шум и ограничит галлюцинации ИИ.
Чтобы извлечь только элемент #main, вам понадобится библиотека Python для разбора HTML, например Beautiful Soup. В активированной виртуальной среде Python установите ее с помощью этой команды:
pip install beautifulsoup4Если вы не знакомы с его API, прочитайте наше руководство по веб-скрапингу Beautiful Soup.
Теперь импортируйте его в файл scraper.py:
from bs4 import BeautifulSoupИспользуйте “Красивый суп”, чтобы:
- Разберите необработанный HTML, полученный с помощью Requests
- Выберите элемент
#main - Получите его HTML-содержимое
Добейтесь этого с помощью данного фрагмента:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Если вы напечатаете main_html, то увидите что-то вроде этого:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-309"
class="product type-product post-309 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- omitted for brevity... -->
</div>
</main>Используйте инструмент OpenAI Tokenizer, чтобы проверить, скольким лексемам соответствует выбранный HTML:

Затем оцените стоимость отправки этих токенов в API Perplexity с помощью LLM API Pricing Calculator:

Как видите, при таком подходе получается более 20 000 токенов. Это означает от 0,21 до примерно 0,63 доллара за запрос. Для масштабного проекта с тысячами страниц это очень много!
Чтобы уменьшить потребление токенов, преобразуйте извлеченный HTML в Markdown с помощью библиотеки вроде markdownify. Установите ее в свой скрап-проект на базе Perplexity с помощью:
pip install markdownifyИмпортируйте markdownify в scraper.py:
from markdownify import markdownifyЗатем используйте его для преобразования HTML из #main в Markdown:
main_markdown = markdownify(main_html)В результате преобразования данных будет получен результат, показанный ниже:

По элементу “size” в конце двух текстовых областей видно, что версия входных данных в формате Markdown намного меньше, чем исходный HTML #main. Кроме того, при осмотре вы заметите, что она по-прежнему содержит все ключевые данные для поиска!
Снова используйте OpenAI’s Tokenizer, чтобы проверить, сколько токенов потребляет новый Markdown-ввод:
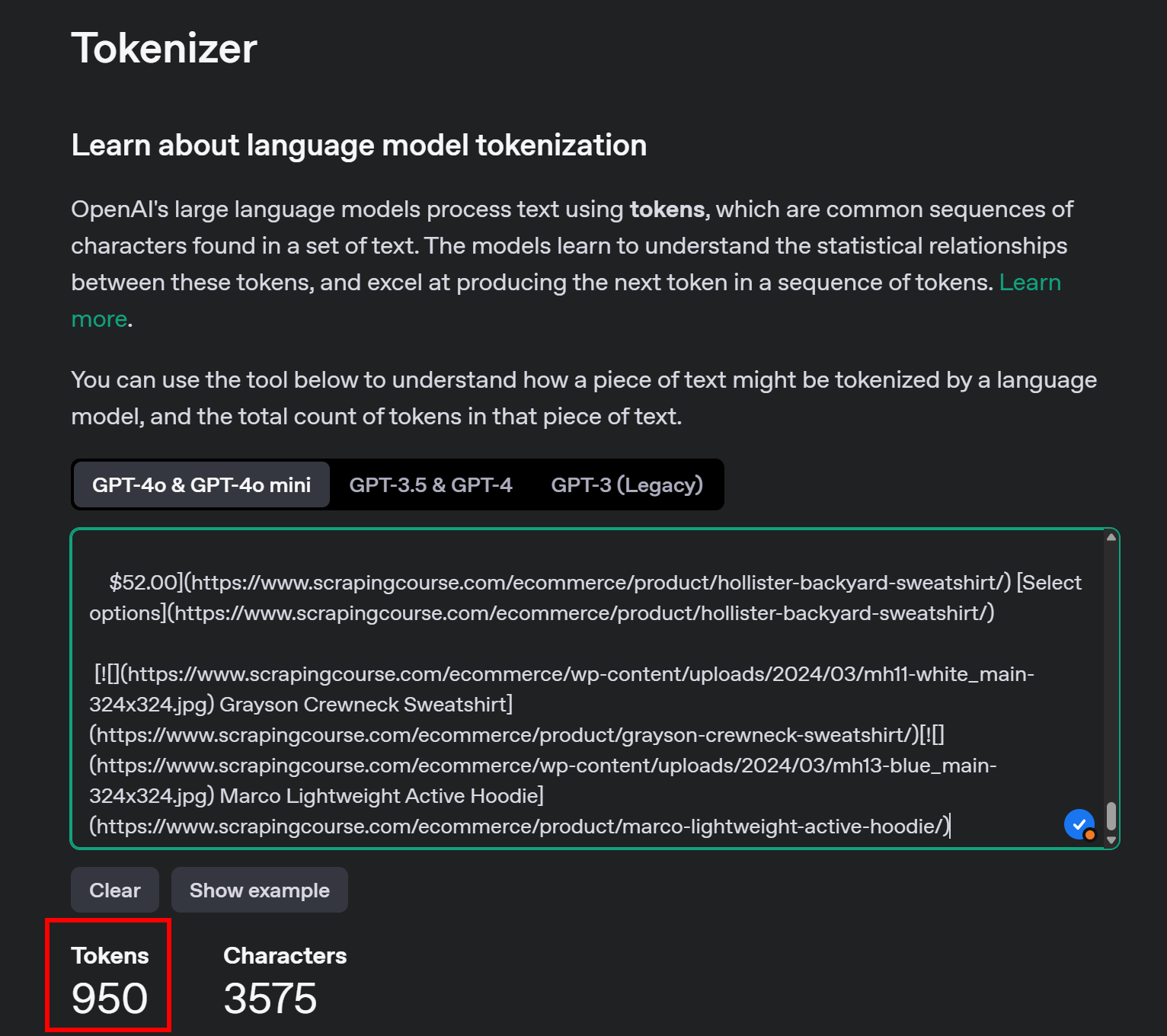
С помощью этого простого трюка вы сократили 20 658 токенов до 950 – более чем на 95 %. Это также привело к значительному снижению затрат Perplexity API на один запрос:

Стоимость снижается с 0,21-0,63 доллара за запрос до 0,014-0,04 доллара за запрос!
Шаг #6: Используйте недоумение для разбора данных
Выполните следующие шаги, чтобы получить данные с помощью Perplexity:
- Напишите хорошо структурированный запрос для извлечения JSON-данных в нужном формате из входных данных Markdown
- Отправьте запрос к LLM-модели Perplexity с помощью OpenAI Python SDK
- Разберите полученный JSON
Выполните первые два шага с помощью следующего кода:
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.contentПеременная prompt указывает Perplexity на извлечение структурированных данных из содержимого main_markdown. Для улучшения результатов рекомендуется задать системе четкую подсказку, чтобы она знала, как себя вести и что делать.
Примечание: Perplexity по-прежнему использует старый синтаксис OpenAI для создания вызовов API. Если вы попытаетесь использовать более новый синтаксис responses.create(), вы столкнетесь со следующей ошибкой:
httpx.HTTPStatusError: Client error '404 Not Found' for url 'https://api.perplexity.ai/responses'Теперь product_raw_string должен содержать JSON-данные в следующем формате:
"```json
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "$69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.nnMint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": ["XS", "S", "M", "L", "XL"],
"colors": ["Blue", "Green", "Red"],
"category": "Hoodies & Sweatshirts"
}
```"Как видите, Perplexity возвращает данные в формате Markdown.
Для реализации шага 3 алгоритма, приведенного в начале этого раздела, необходимо извлечь необработанное содержимое JSON с помощью regex. Затем можно разобрать полученные JSON-данные на Python-словарь json.loads():
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)Не забудьте импортировать json и re из стандартной библиотеки Python:
import json
import reПримечание: Если вы являетесь пользователем Perplexity Tier-3, вы можете пропустить этап регекс-парсинга, настроив API на возврат данных в структурированном формате JSON напрямую. Дополнительную информацию можно найти в руководстве Perplexity “Структурированные выходные данные”.
Разобрав словарь product_data, вы можете получить доступ к полям для дальнейшей обработки данных. Например:
price = product_data["price"]
price_eur = price * USD_EUR
# ...Фантастика! Вы успешно использовали Perplexity для веб-скрапинга. Осталось только экспортировать собранные данные по мере необходимости.
Шаг № 7: Экспорт собранных данных
В настоящее время собранные данные хранятся в словаре Python. Чтобы сохранить их в виде JSON-файла, используйте следующий код:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)В результате будет создан файл product.json, содержащий отсканированные данные в формате JSON.
Отлично! Теперь ваш веб-скрепер на базе Perplexity готов.
Шаг № 8: Соберите все вместе
Вот полный код вашего скрипта, использующего Perplexity для парсинга данных:
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import re
import json
# Your Perplexity API key
PERPLEXITY_API_KEY = "<YOUR_PERPLEXITY_API_KEY>" # replace with your API key
# Conffigure the OpenAI SDK to connect to Perplexity
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")
# Retrieve the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)
# Convert the #main HTML to Markdown
main_markdown = markdownify(main_html)
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.content
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Запустите скрипт скрапбукинга с помощью:
python scraper.pyПо окончании выполнения в папке проекта будет создан файл product.json. Откройте его, и вы найдете структурированные данные, как показано ниже:
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.n• Mint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Blue",
"Green",
"Red"
],
"category": "Hoodies & Sweatshirts"
}И вуаля! Скрипт преобразовал неструктурированные данные с HTML-страницы в аккуратно организованный JSON-файл, и все это благодаря веб-скреппингу на базе Perplexity.
Следующие шаги
Чтобы вывести свой скребок на базе Perplexity на новый уровень, рассмотрите эти улучшения:
- Сделайте его многоразовым: Измените скрипт так, чтобы он принимал запрос и целевой URL в качестве аргументов командной строки. Это сделает скрепер более гибким и адаптируемым для различных случаев использования и проектов.
- Защитите учетные данные API: Храните ключ API Perplexity в файле .env и используйте python-dotenv для его безопасной загрузки. Такой подход позволяет избежать жесткого кодирования конфиденциальных учетных данных в скрипте, повышая безопасность за счет сохранения секретов в тайне и отделения от кодовой базы.
- Реализуйте веб-ползание: Используйте возможности Perplexity по поиску и скретчингу на основе искусственного интеллекта для интеллектуального и оптимизированного скретчинга. Настройте скрепер для навигации по связанным страницам, извлекая структурированные данные из различных источников.
Разбираемся в самых больших ограничениях этого метода веб-скрепинга
В чем самое большое ограничение этого подхода к веб-скраппингу, основанного на искусственном интеллекте? HTTP-запросы, выполняемые запросами!
Хотя приведенный выше пример сработал идеально, это потому, что целевой сайт, по сути, является площадкой для веб-скреппинга. На самом деле компании и владельцы сайтов понимают ценность своих данных, даже если они находятся в открытом доступе. Чтобы защитить их, они применяют меры по борьбе со скрапингом, которые могут легко заблокировать ваши автоматические HTTP-запросы.
В таких случаях скрипт выдаст ошибку 403 Forbidden, например:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>
Кроме того, этот подход не работает на динамических веб-страницах, которые полагаются на JavaScript для рендеринга или асинхронного получения данных. Таким образом, веб-сайтам даже не нужны продвинутые средства защиты от ботов, чтобы заблокировать ваш скрепер, работающий на LLM.
Так как же решить все эти проблемы? Web Unlocking API!
API Web Unlocker от Bright Data – это конечная точка для скраппинга, которую можно вызвать из любого HTTP-клиента. Он возвращает полностью разблокированный HTML любого URL-адреса, который вы ему передаете, минуя блоки, препятствующие скрапингу. Неважно, сколько защит имеет целевой сайт, простой запрос к Web Unlocker позволит вам получить HTML страницы.
Чтобы начать, следуйте официальной документации Web Unlocker для получения ключа API. Затем замените существующий код запроса из “Шага № 4” на следующие строки:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
И вот так – больше никаких блоков, никаких ограничений! Теперь вы можете скрести веб с помощью Perplexity, не беспокоясь о том, что вас остановят.
Заключение
В этом уроке вы узнали, как использовать Perplexity в сочетании с Requests и другими инструментами для создания скрепера, работающего на основе искусственного интеллекта. Одной из самых больших проблем при веб-скреппинге является риск быть заблокированным, но эта проблема была решена с помощью API Web Unlocker от Bright Data.
Как уже говорилось, интегрировав Perplexity с API Web Unlocker, вы можете извлекать данные с любого сайта без необходимости использования собственной логики парсинга. Это лишь один из многих примеров использования продуктов и услуг Bright Data, позволяющих реализовать эффективный веб-скрепинг на основе искусственного интеллекта.
Ознакомьтесь с другими нашими инструментами для веб-скреппинга:
- Услуги прокси: Четыре типа прокси-серверов для обхода ограничений по местоположению, включая доступ к 150 million+м с лишним IP-адресов жителей.
- API для веб-скреперов: Специальные конечные точки для извлечения свежих структурированных веб-данных из более чем 100 популярных доменов.
- SERP API: API для управления текущей разблокировкой SERP и извлечения отдельных страниц.
- Браузер для скрапинга: Облачный браузер, совместимый с Puppeteer, Selenium и Playwright, со встроенными возможностями разблокировки.
Зарегистрируйтесь на сайте Bright Data и протестируйте наши прокси-сервисы и продукты для скрапбукинга бесплатно!





