

Gerapy – это полностековое решение для развертывания Scrapy. Если вы посмотрите на историю коммитов, то увидите, что он получил несколько изменений в зависимостях, но на самом деле не обновлялся с 2022 года. Запуск Gerapy может быть сложным процессом, часто полным проб и ошибок.
Это руководство создано для того, чтобы облегчить работу с Gerapy. К концу этого руководства вы сможете ответить на следующие вопросы.
- Почему Gerapy не работает с моей стандартной установкой Python?
- Как настроить Python и pip для Gerapy?
- Как создать учетную запись администратора?
- Как написать свой первый скребок?
- Как устранить неполадки в работе скребка?
- Как протестировать и развернуть свой скребок?
Введение в Gerapy
Давайте лучше разберемся, что такое Gerapy и что делает его уникальным.
Что такое Герапи?
Gerapy предоставляет нам панель управления Django и API Scrapyd. Эти сервисы предоставляют простой, но мощный интерфейс для управления стеком. На данный момент это устаревшая программа, но она все равно улучшает рабочий процесс и ускоряет развертывание. Gerapy делает веб-скраппинг более доступным для DevOps и команд, ориентированных на управление.
- GUI-панель для создания и мониторинга скреперов.
- Разверните скребок одним нажатием кнопки.
- Получайте информацию о журналах и ошибках в режиме реального времени по мере их возникновения.
Что делает Gerapy уникальным?
Gerapy – это универсальное решение для управления скреперами. Начало работы с Gerapy – утомительный процесс из-за его устаревшего кода и зависимостей. Однако, как только вы начнете работать с ним, вы получите полный набор инструментов, предназначенных для масштабной работы со скреперами.
- Создавайте свои скрепы внутри браузера.
- Разверните их в Scrapyd, не обращаясь к командной строке.
- Централизованное управление всеми вашими краулерами и скреперами.
- Фронтенд, построенный на Django, для управления пауками.
- Бэкэнд на базе Scrapyd для простоты создания и развертывания.
- Встроенный планировщик для автоматизации задач.
Как соскребать информацию с помощью Gerapy
Процесс настройки Gerapy трудоемок. Вам придется устранять технические проблемы и заниматься сопровождением программного обеспечения. После долгих проб и ошибок мы узнали, что Gerapy даже не совместим с более современными версиями Python. Мы начали с современной установки Python 3.13. Она оказалась слишком современной для зависимостей Gerapy. Мы попробовали 3.12 – все равно не получилось – только больше проблем с зависимостями.
Как выяснилось, нам нужен был Python 3.10. Кроме того, нам нужно было изменить часть кода Gerapy, чтобы исправить устаревший класс, а затем вручную понизить почти все зависимости в Gerapy. За последние три года Python претерпел значительные изменения, и развитие Gerapy не поспевало за ним. Нам нужно воссоздать идеальные условия Gerapy трехлетней давности.
Настройка проекта
Python 3.10
Для начала нам нужно установить Python 3.10. Эта версия не вымерла, но она уже не так широко доступна. На родной Ubuntu и Windows WSL с Ubuntu его можно установить с помощью apt.
sudo apt update
sudo apt install software-properties-common
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.10 python3.10-venv python3.10-devЗатем вы можете проверить, установлен ли он, с помощью флага --version.
python3.10 --versionЕсли все прошло успешно, вы должны увидеть результат, аналогичный приведенному ниже.
Python 3.10.17Создание папки проекта
Сначала создайте новую папку.
mkdir gerapy-environmentДалее нам нужно зайти в папку нашего нового проекта и настроить виртуальную среду.
cd gerapy-environment
python3.10 -m venv venvАктивируйте окружающую среду.
source venv/bin/activateКак только среда станет активной, вы сможете проверить активную версию Python.
python --versionКак видите, теперь python по умолчанию устанавливает нашу версию 3.10 из виртуальной среды.
Python 3.10.17Установка зависимостей
Команда ниже устанавливает Gerapy и необходимые версии зависимостей. Как видите, нам нужно вручную установить множество унаследованных пакетов с помощью pip==.
pip install setuptools==80.8.0
pip install scrapy==2.7.1 gerapy==0.9.13 scrapy-splash==0.8.0 scrapy-redis==0.7.3 scrapyd==1.2.0 scrapyd-client==1.2.0 pyopenssl==23.2.0 cryptography==41.0.7 twisted==21.2.0Теперь мы создадим настоящий проект Gerapy с помощью команды init.
gerapy initДалее заходим в папку gerapy и запускаем migrate для создания базы данных.
cd gerapy
gerapy migrateТеперь пришло время создать учетную запись администратора. Эта команда по умолчанию дает вам привилегии администратора.
gerapy initadminНаконец, мы запускаем сервер Gerapy.
gerapy runserverНа выходе вы должны увидеть следующее.
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
INFO - 2025-05-24 13:49:16,241 - process: 1726 - scheduler.py - gerapy.server.core.scheduler - 105 - scheduler - successfully synced task with jobs with force
May 24, 2025 - 13:49:16
Django version 2.2.28, using settings 'gerapy.server.server.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.Использование приборной панели
Если вы посетите сайт http://127.0.0.1:8000/, вам будет предложено войти в систему. По умолчанию имя вашей учетной записи – admin, как и пароль. После входа в систему вы попадете на приборную панель Gerapy.

Перейдите на вкладку “Проекты” и создайте новый проект. Мы назовем его "Цитаты“.
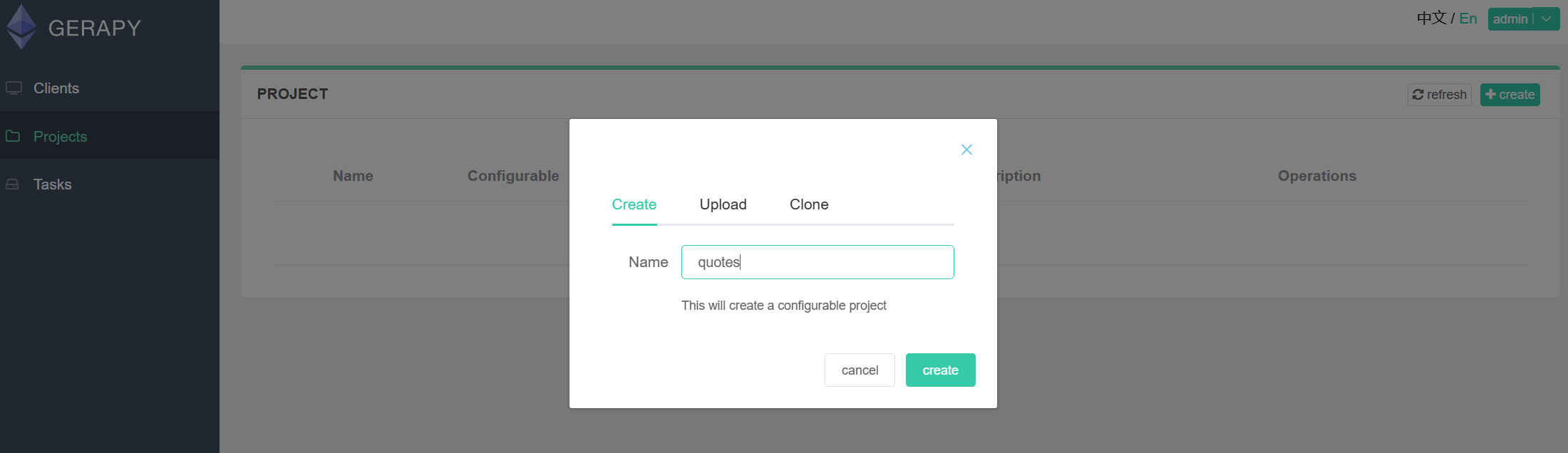
Получение целевого сайта
Теперь создадим нового паука. В новом проекте нажмите кнопку “Добавить паука”. В разделе “Стартовые урлы” добавьте https://quotes.toscrape.com. В разделе “Домены” введите quotes.toscrape.com.

Логика извлечения
Далее мы добавим логику извлечения. Функция parse(), представленная ниже, использует CSS-селекторы для извлечения цитат со страницы. Подробнее о селекторах вы можете узнать здесь.
Прокрутите вниз до раздела “Внутренний код” и добавьте свою функцию парсинга.
def parse(self, response):
quotes = response.css('div.quote')
print(f"Found {len(quotes)} quotes")
for quote in quotes:
text = quote.css('span.text::text').get()
author = quote.css('small.author::text').get()
print(f"Text: {text}, Author: {author}")
yield {
'text': text,
'author': author,
}Теперь нажмите кнопку “Сохранить”, расположенную в правом нижнем углу экрана. Если вы запустите паука сейчас, то столкнетесь с критической ошибкой. Gerapy пытается использовать BaseItem из Scrapy. Однако BaseItem был удален из Scrapy несколько лет назад.

Исправление ошибки BaseItem
Чтобы решить эту ошибку, нам нужно отредактировать внутренний код Scrapy. Вы можете сделать это из командной строки. Однако гораздо проще это сделать в текстовом редакторе с графическим интерфейсом и функциями поиска.
Перейдите по cd к исходным файлам вашей виртуальной среды.
cd venv/lib/python3.10/site-packages/gerapy/server/coreЧтобы открыть папку в VSCode, можно воспользоваться следующей командой.
code .Откройте файл parser.py и найдите нашего виновника.

Нам нужно заменить эту строку на следующую.
from scrapy import Item
Теперь, когда мы удалили импорт BaseItem, нам нужно удалить все экземпляры BaseItem с Item. Наш единственный экземпляр находится в функции run_callback(). Когда вы закончите сохранять изменения, закройте редактор.

Если вы запустите паука, то получите новую ошибку.

Устранение устаревания REQUEST_FINGERPRINTER_IMPLEMENTATION
Это не заметно, но Gerapy на самом деле внедряет наши настройки прямо в нашего паука. cd из нашей текущей папки, а затем в папку projects.
cd
cd gerapy-environment/gerapy/projects/quotesСнова откройте текстовый редактор.
code .Теперь откройте своего паука. Он должен называться quotes.py и находиться в папке spiders. Вы должны увидеть функцию parse() внутри класса паука. В нижней части файла вы должны увидеть массив под названием custom_settings. Наши настройки были буквально внедрены в паука с помощью Gerapy.

Нам нужно добавить одну новую настройку. Вам нужно использовать 2.7. 2.6 будет продолжать выдавать ошибку. Мы обнаружили это после многочисленных проб и ошибок.
"REQUEST_FINGERPRINTER_IMPLEMENTATION": "2.7",Теперь, когда вы запускаете паука с помощью кнопки воспроизведения Gerapy, все ошибки устраняются. Как вы можете видеть ниже, вместо сообщения об ошибке мы видим просто “Follow Request”.

Собираем все вместе
Создание скребка
Если вы вернетесь на вкладку “Проекты” в Gerapy, вы увидите “X” в колонке “Built” для проекта. Это означает, что наш скрепер не был собран в исполняемый файл для развертывания.

Нажмите кнопку “развернуть”. Теперь нажмите кнопку “Сборка”.

Использование планировщика
Чтобы запланировать запуск скребка на определенное время или интервал, нажмите “Задачи”, а затем создайте новую задачу. Затем выберите нужные настройки для расписания.

После завершения нажмите кнопку “Создать”.
Ограничения при скрапировании с помощью Gerapy
Зависимости
Его устаревший код влечет за собой множество ограничений, которые мы рассмотрим в этой статье. Чтобы запустить Gerapy, нам нужно было зайти в систему и отредактировать ее внутренний исходный код. Если вам некомфортно прикасаться к внутренностям системы, Gerapy не для вас. Помните ошибку BaseItem?
В то время как зависимости Gerapy продолжают развиваться, Gerapy остается застывшим во времени. Чтобы продолжать использовать его, вам придется лично поддерживать свою установку. Это увеличивает технический долг в виде обслуживания и вполне реального процесса проб и ошибок.
Вспомните этот фрагмент ниже. Каждый из этих номеров версий был найден в результате тщательного процесса проб и ошибок. Когда зависимости ломаются, нужно постоянно пробовать разные номера версий, пока не найдется рабочая. Только в этом учебнике нам пришлось методом проб и ошибок найти рабочие версии 10 зависимостей. Со временем ситуация будет только ухудшаться.
pip install setuptools==80.8.0
pip install scrapy==2.7.1 gerapy==0.9.13 scrapy-splash==0.8.0 scrapy-redis==0.7.3 scrapyd==1.2.0 scrapyd-client==1.2.0 pyopenssl==23.2.0 cryptography==41.0.7 twisted==21.2.0Ограничения операционной системы
Когда мы пытались создать этот учебник, мы попробовали использовать родную Windows. Так мы обнаружили первоначальные ограничения, связанные с версиями Python. Текущие стабильные версии Python ограничены 3.9, 3.11 и 3.13. Управлять несколькими версиями Python сложно независимо от ОС. Однако Ubuntu предоставляет нам PPA-репозиторий deadsnakes.
Без deadsnakes можно найти совместимую версию Python, но даже в этом случае вам придется решать проблемы PATH и различать python (установленный по умолчанию) и python3.10. Вероятно, это можно сделать и в Windows и macOS, но вам придется найти другое обходное решение. В Ubuntu и других дистрибутивах Linux на базе apt вы, по крайней мере, получите воспроизводимую среду с быстрым доступом к старым версиям Python, установленным непосредственно в PATH.
Интеграция прокси с Gerapy
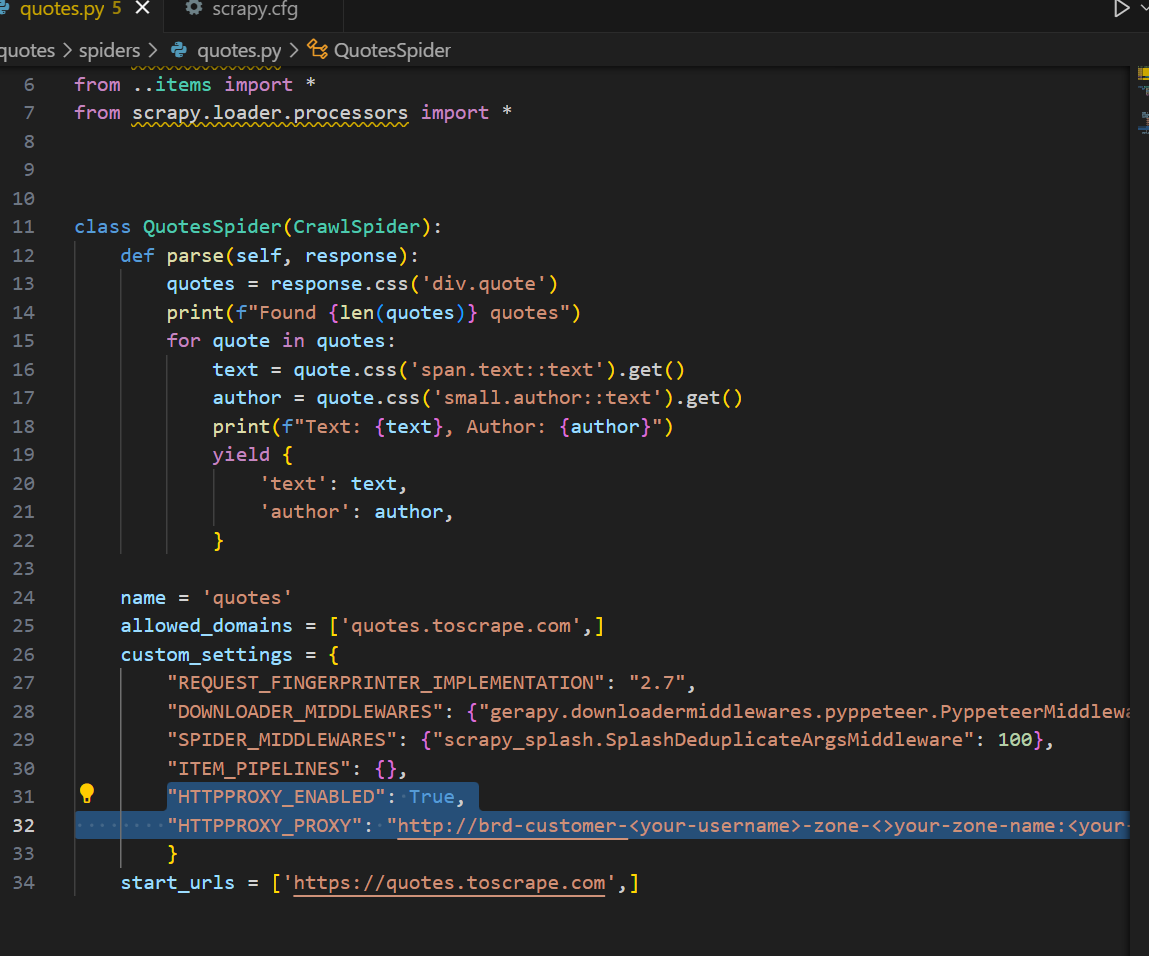
Как и в случае с ванильным Scrapy, интеграция прокси легко осуществима. В духе инъекции настроек Gerapy мы можем внедрить прокси прямо в паука. В примере ниже мы добавляем настройки HTTPPROXY_ENABLED и HTTPPROXY_PROXY для подключения с помощью Web Unlocker.
"HTTPPROXY_ENABLED": True,
"HTTPPROXY_PROXY": "http://brd-customer-<your-username>-zone-<your-zone-name>:<your-password>@brd.superproxy.io:33335"Вот полный паук после интеграции прокси. Не забудьте поменять имя пользователя, зону и пароль на свои.
Жизнеспособные альтернативы Gerapy
- Scrapyd: Это фактическая основа Gerapy и практически любого другого стека Scrapy. С помощью Scrapyd вы можете управлять всем через обычные HTTP-запросы и создавать приборную панель по своему усмотрению.
- Функции скрапинга: Наши функции скрапинга позволяют развертывать скраперы непосредственно в облаке и редактировать их из онлайн IDE – с приборной панелью, как у Gerapy, но более гибкой и современной.
Заключение
Gerapy – это устаревший продукт в нашем быстро меняющемся мире. Он требует реального обслуживания, и вам придется испачкать руки. Такие инструменты, как Gerapy, позволяют централизовать среду скраппинга и контролировать все с единой приборной панели. В кругах DevOps Gerapy действительно полезен и ценен.
Если Scrapy вам не подходит, мы предлагаем множество альтернатив, которые удовлетворят ваши потребности в сборе данных. Ниже представлены лишь некоторые из них.
- Пользовательский скребок: Создавайте скреперы без необходимости написания кода и развертывайте их в нашей облачной инфраструктуре.
- Наборы данных: Ежедневно обновляемые наборы исторических данных со всего интернета. Библиотека истории интернета прямо у вас под рукой.
- Прокси для жилых домов: Независимо от того, предпочитаете ли вы писать код самостоятельно или скрести с помощью искусственного интеллекта, наши прокси предоставляют вам доступ к интернету с геотаргетингом на реальном жилом интернет-подключении.
Запишитесь на бесплатную пробную версию сегодня и поднимите сбор данных на новый уровень!





