

Из этой статьи вы узнаете, как вручную собирать финансовые данные и как использовать API парсера финансовых данных от Bright Data для автоматизации этого процесса.
Знайте, что вы хотите парсить и как это организовано
Финансовые данные включают широкий и часто сложный спектр информации. Прежде чем приступить к парсингу, необходимо четко определить, какой тип данных вам нужен.
Например, вы можете захотеть выполнить парсинг цен акций, отражающих последнюю цену акции, цену открытия и закрытия за день, максимумы и минимумы, достигнутые в течение дня, а также любые изменения цены, произошедшие с течением времени. Финансовые данные, такие как отчеты о прибылях и убытках компании, балансы (с описанием активов и обязательств) и отчеты о движении денежных средств (отслеживание поступления и вывода денег), также необходимы для оценки эффективности. Финансовые коэффициенты, оценки аналитиков и отчеты помогают принимать решения о покупке и продаже, а новые обновления и анализ настроений в социальных сетях позволяют глубже понять рыночные тенденции.
Понимание того, как организованы данные на веб-странице, может упростить поиск и парсинг нужной информации.
Проанализируйте правовые и этические аспекты
Прежде чем парсить веб-сайт, обязательно ознакомьтесь с условиями обслуживания этого сайта. Многие веб-сайты запрещают парсинг без предварительного согласия или разрешения.
Вам также необходимо соблюдать правила файла robots.txt , в котором указано, к каким частям сайта вы можете получить доступ. Кроме того, убедитесь, что вы не перегружаете сервер запросами и не допускаете задержек между запросами. Это помогает защитить ресурсы веб-сайта и избежать проблем.
Используйте инструменты для разработчиков браузеров
Для просмотра HTML-элементов веб-страницы вы можете использовать инструменты разработчика вашего браузера. Эти инструменты встроены в большинство современных браузеров, включая Chrome, Safari и Edge. Чтобы открыть инструменты разработчика, нажмите Ctrl + Shift + I в Windows, Cmd + Option + I на Mac или щелкните страницу правой кнопкой мыши и выберите Inspect.
После открытия вы можете проверить HTML-структуру страницы и определить конкретные элементы данных. На вкладке Elements отображается дерево объектной модели документа (DOM), позволяющее находить и выделять элементы на странице. На вкладке Network отображаются все сетевые запросы, что полезно для поиска конечных точек API или динамически загружаемых данных. Вкладка Console позволяет запускать команды JavaScript и работать со скриптами страницы.
В этом уроке вы выполните парсинг акций APPL из Yahoo Finance. Чтобы найти соответствующие HTML-теги, перейдите на страницу APPL stock , щелкните правой кнопкой мыши цену, показанную на странице, и выберите Inspect. На вкладке Elements выделен элемент HTML, содержащий цену:
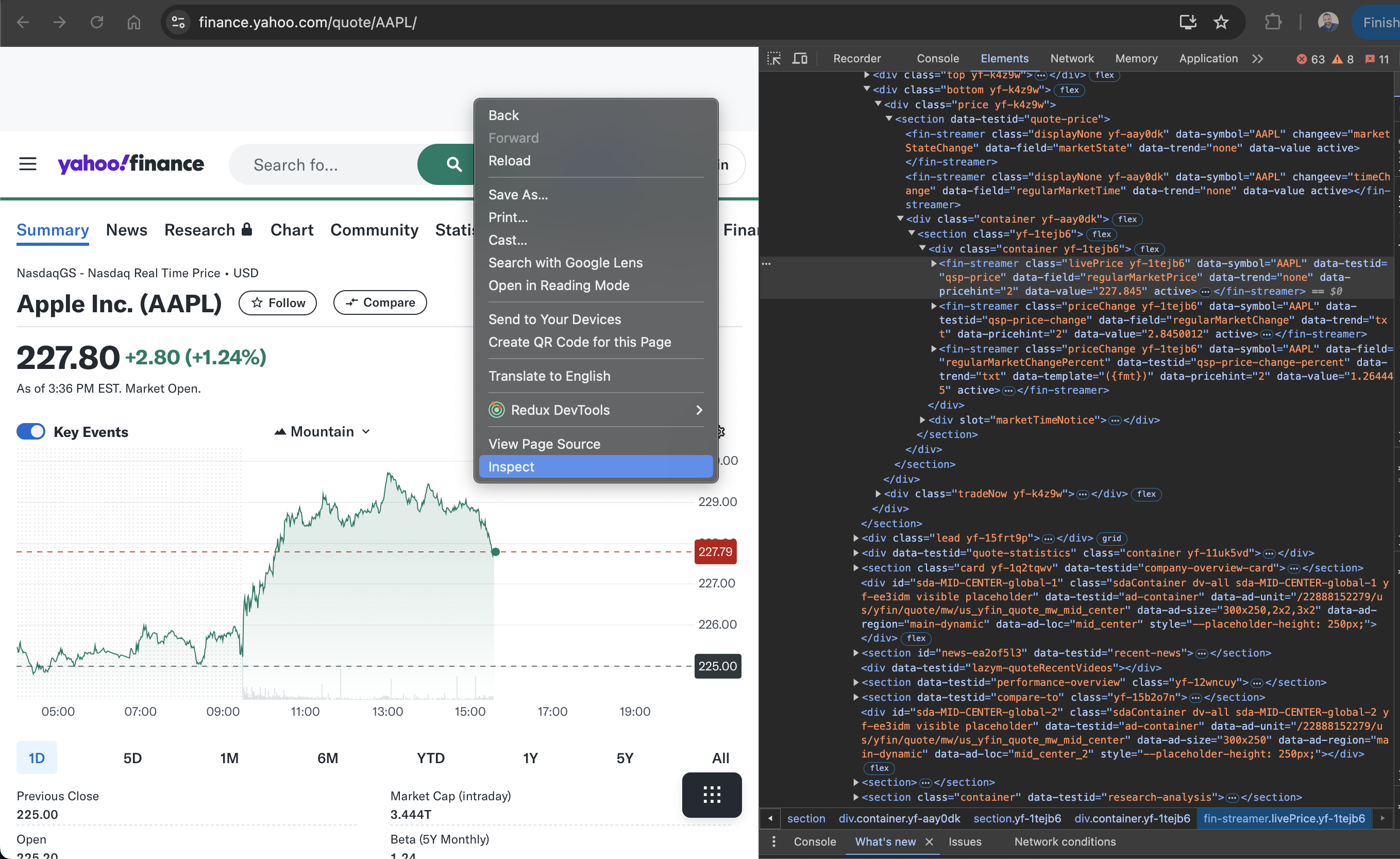
Обратите внимание на имя тега и любые уникальные атрибуты, такие как class или id, чтобы помочь вам найти этот элемент в парсере.
Как настроить среду и проект
В этом руководстве используется [Python] (https://www.python.or) для парсинга веб-страниц из-за его простоты и доступности библиотек. Прежде чем начать, убедитесь, что в вашей системе установлен Python 3.10 или более новая версия.
Если у вас есть Python, откройте терминал или оболочку и выполните следующие команды для создания каталога и виртуальной среды:
mkdir scrape-financial-data
cd scrape-financial-data
python3 -m venv myenv
После создания виртуальной среды ее все равно нужно активировать. Команды активации различаются в зависимости от операционной системы.
Если вы используете Windows, выполните следующую команду:
.myenvScriptsactivate
Если вы используете macOS/Linux, выполните следующую команду:
source myenv/bin/activate
После активации виртуальной среды установите необходимые библиотеки с помощью pip:
pip3 install requests beautifulsoup4 lxml
Эта команда устанавливает библиотеку Requests для обработки HTTP-запросов, Beautiful Soup для анализа содержимого HTML и lxml для эффективного анализа XML и HTML.
Как вручную парсить финансовые данные
Чтобы вручную парсить финансовые данные, создайте файл с именем manual_scraping.py и добавьте следующий код для импорта необходимых библиотек:
import requests
from bs4 import BeautifulSoup
Задайте URL-адрес финансовых данных, которые вы хотите парсить. Как упоминалось ранее, в этом руководстве используется страница Yahoo Finance , посвященная акциям Apple (AAPL):
url = 'https://finance.yahoo.com/quote/AAPL?p=AAPL&.tsrc=fin-srch'
После установки URL-адреса отправьте запрос GET на URL-адрес:
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
Этот код содержит заголовок User-Agent , имитирующий запрос браузера, что позволяет избежать блокировки целевым веб-сайтом.
Убедитесь, что запрос выполнен успешно:
if response.status_code == 200:
print('Successfully retrieved the webpage')
else:
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')
exit()
Затем проанализируйте содержимое веб-страницы с помощью парсера lxml :
soup = BeautifulSoup(response.content, 'lxml')
Найдите элементы на основе их уникальных атрибутов, извлеките текстовое содержимое и распечатайте извлеченные данные:
# Extract specific company details
try:
# Extract specific company details
previous_close = soup.find('fin-streamer', {'data-field': 'regularMarketPreviousClose'}).text.strip()
open_price = soup.find('fin-streamer', {'data-field': 'regularMarketOpen'}).text.strip()
day_range = soup.find('fin-streamer', {'data-field': 'regularMarketDayRange'}).text.strip()
week_52_range = soup.find('fin-streamer', {'data-field': 'fiftyTwoWeekRange'}).text.strip()
market_cap = soup.find('fin-streamer', {'data-field': 'marketCap'}).text.strip()
# Extract PE Ratio (TTM)
pe_label = soup.find('span', class_='label', title='PE Ratio (TTM)')
pe_value = pe_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Extract EPS (TTM)
eps_label = soup.find('span', class_='label', title='EPS (TTM)')
eps_value = eps_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Print the scraped details
print("n### Stock Price ###")
print(f"Open Price: {open_price}")
print(f"Previous Close: {previous_close}")
print(f"Day's Range: {day_range}")
print(f"52 Week Range: {week_52_range}")
print("n### Company Details ###")
print(f"Market Cap: {market_cap}")
print(f"PE Ratio (TTM): {pe_value}")
print(f"EPS (TTM): {eps_value}")
except AttributeError as e:
print("Error while scraping data. Some fields may not be found.")
print(e)
Запустите и протестируйте код
Чтобы протестировать код, откройте терминал или оболочку и выполните следующую команду:
python3 manual_scraping.py
Ваш результат должен выглядеть следующим образом:
Successfully retrieved the webpage
### Stock Price ###
Open Price: 225.20
Previous Close: 225.00
Day's Range: 225.18 - 229.74
52 Week Range: 164.08 - 237.49
### Company Details ###
Market Cap: 3.447T
PE Ratio (TTM): 37.50
EPS (TTM): 37.50
Решайте проблемы с помощью ручного парсинга
Ручной парсинг данных может быть сложной задачей по разным причинам, в том числе из-за необходимости решения капч или блокировками IP-адресов, для обхода которых требуются стратегии. Неструктурированные или запутанные данные могут привести к ошибкам парсинга, а очистка без соответствующих разрешений может привести к юридическим проблемам. Частые обновления веб-сайта также могут привести к поломке вашего парсера, поэтому для обеспечения постоянной функциональности требуется регулярное обслуживание кода.
Чтобы создать и автоматизировать парсер, вам придется потратить много времени на написание кода и его исправление, а не на анализ данных. Если вы работаете с большими объемами данных, это может быть еще сложнее, так как вы должны убедиться, что данные чисты и организованы. Если вы управляете разными структурами веб-сайтов, вы также должны разбираться в различных веб-технологиях.
То есть, если вам нужно часто и быстро парсить данные, ручной парсинг веб-страниц — не лучший вариант.
Как парсить данные с помощью API для парсинга финансовых данных Bright Data
Bright Data решает проблемы ручного парсинга с помощью API парсера финансовых данных, который автоматизирует извлечение данных. Он оснащен встроенным управлением прокси-серверами с ротацией прокси для предотвращения блокировок IP-адресов. API возвращает структурированные данные в таких форматах, как JSON и CSV. Он также обладает высокой масштабируемостью, что позволяет легко обрабатывать большие объемы данных.
Чтобы использовать API парсера финансовых данных, зарегистрируйте бесплатную учетную запись на веб-сайте Bright Data. Подтвердите свой адрес электронной почты и выполните все необходимые шаги для подтверждения личности.
После настройки учетной записи войдите в систему, чтобы получить доступ к панели управления и ключи API.
Настройка API парсинга финансовых данных
На панели управления перейдите к API веб-парсера на левой вкладке навигации. Выберите
Финансовые данные в категориях , а затем нажмите, чтобы открыть раздел Yahoo Finance Business Information — Collect по URL-адресу:

Нажмите Начать настройку вызова API:

Чтобы использовать API, вам необходимо создать токен, который аутентифицирует ваши вызовы API в парсере Bright Data. Чтобы создать новый токен, нажмите Создать токен:

Откроется диалоговое окно. Установите для Разрешения значение «Администратор» и сделайте срок действия «Неограниченным»:

После сохранения этой информации будет создан токен, и вам будет предложено ввести новый токен. Обязательно сохраните его в безопасном месте, так как оно вам скоро понадобится:

Если вы уже создали токен, вы можете получить его в пользовательских настройкахв разделе токенов API. Выберите вкладку Подробнее своего пользователя и нажмите Скопировать токен.
Запустите парсер для получения финансовых данных
На странице Yahoo Finance Business Information добавьте свой токен API в поле API-токен , а затем добавьте стандартный URL-адрес целевого веб-сайта: https://finance.yahoo.com/quote/AAPL/. Скопируйте запрос в разделе АУТЕНТИФИЦИРОВАННЫЙ ЗАПРОС справа:

Откройте терминал или оболочку и запустите вызов API, используя curl. Оно должно выглядеть следующим образом:
curl -H "Authorization: Bearer YOUR_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://finance.yahoo.com/quote/AAPL/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=YOUR_DATA_SET_ID&include_errors=true"
После выполнения команды вы получите snapshot_id в качестве ответа:
{"snapshot_id":"s_m3n8ohui15f8v3mdgu"}
Скопируйте snapshot_id и запустите следующий вызов API из терминала или оболочки:
curl -H "Authorization: Bearer YOUR_TOKEN" "https://api.brightdata.com/datasets/v3/snapshot/YOUR_SNAP_SHOT_ID?format=jsonl"
Обязательно замените
YOUR_TOKENиYOUR_SNAP_SHOT_IDсвоими учетными данными.
После запуска этого кода вы должны получить данные парсинга в качестве выходных данных. Данные должны быть похожи на следующий файл JSON.
Если вы получите ответ о том, что снимок не готов, подождите десять секунд и повторите попытку.
API парсера финансовых данных от Bright Data извлек все необходимые данные без необходимости анализировать структуру HTML или находить определенные теги. Она получила данные всей страницы, включая дополнительные поля, такие как earning_estimate, история заработкови growth_estinates.
Весь код для этого руководства доступен в этом репозитории GitHub..
Преимущества использования API Bright Data
API для парсинга финансовых данных от Bright Data упрощает процесс парсинга, устраняя необходимость писать код парсинга или управлять им. API также помогает обеспечить соответствие требованиям, управляя ротацией прокси-серверов и соблюдая условия обслуживания веб-сайта, что позволяет собирать данные, не опасаясь блокировки или нарушения правил.
API парсера финансовых данных от Bright Data предоставляет структурированные и надежные данные с минимальным количеством кода. Он выполняет навигацию по страницам и парсинг HTML за вас, упрощая процесс. Масштабируемость API позволяет собирать данные о многочисленных акциях и других финансовых показателях без внесения больших изменений в код. Техническое обслуживание также минимально, потому что Bright Data обновляет парсер, когда веб-сайты меняют свою структуру, поэтому сбор данных продолжается без дополнительных усилий.
Заключение
Сбор финансовых данных — важнейшая задача для разработчиков и групп данных, занимающихся финансовым анализом, алгоритмической торговлей и исследованиями рынка. Из этой статьи вы узнали, как вручную парсить финансовые данные с помощью Python и API парсера финансовых данных от Bright Data. Хотя парсинг данных вручную обеспечивает контроль, обход мер по защите от парсинга и несение расходов на техническое обслуживание может быть сопряжено с трудностями, а масштабирование сопряжено с трудностями.
API парсера финансовых данных от Bright Data упрощает сбор данных за счет решения сложных задач, таких как ротация прокси и решение капч. Помимо API, Bright Data также предлагает наборы данных, резидентные прокси-серверыи Scraping Browser для улучшения ваших проектов по веб-парсингу. Подпишитесь на бесплатную пробную версию , чтобы изучить все, что предлагает Bright Data.





