

В этом руководстве вы узнаете:
- Что такое парсер LinkedIn
- Сравнение Веб-скрейпинга LinkedIn и извлечения данных через его API
- Как обойти барьер входа в LinkedIn
- Как создать скрипт для скрейпинга LinkedIn на Python
- Как получить данные LinkedIn с помощью более простого и эффективного решения
Приступим!
Что такое LinkedIn Парсер?
Парсер LinkedIn — это инструмент, который автоматически извлекает данные со страниц LinkedIn. Обычно он нацелен на популярные страницы, такие как профили, списки вакансий, страницы компаний и статьи.
Парсер собирает ключевую информацию с этих страниц и представляет ее в удобных форматах, таких как CSV или JSON. Эти данные ценны для генерации лидов, поиска работы, анализа конкурентов, выявления рыночных тенденций и других целей.
Веб-скрейпинг LinkedIn против API LinkedIn
LinkedIn предоставляет официальный API, который позволяет разработчикам интегрироваться с платформой и извлекать некоторые данные. Так зачем же вам вообще стоит рассматривать Веб-скрейпинг LinkedIn? Ответ прост и включает в себя четыре ключевых момента:
- API возвращает только поднабор данных, определенный LinkedIn, который может быть намного меньше, чем данные, доступные через Веб-скрейпинг.
- API могут меняться со временем, ограничивая ваш контроль над данными, к которым вы можете получить доступ.
- API LinkedIn в первую очередь ориентирован на интеграцию маркетинга и продаж, особенно для пользователей бесплатного тарифа.
- API LinkedIn может стоить десятки долларов в месяц, но при этом он по-прежнему имеет строгие ограничения на данные и количество профилей, из которых вы можете извлекать данные.
Сравнение двух подходов к получению данных LinkedIn приводит к следующей сводной таблице:
| Аспект | API LinkedIn | Веб-скрейпинг LinkedIn |
|---|---|---|
| Доступность данных | Ограничено подмножеством данных, определенным LinkedIn | Доступ ко всем общедоступным данным на сайте |
| Контроль над данными | LinkedIn контролирует предоставляемые данные | Полный контроль над получаемыми данными |
| Направленность | В первую очередь для интеграции маркетинга и продаж | Может нацеливаться на любую страницу LinkedIn |
| Стоимость | Может стоить десятки долларов в месяц | Без прямых затрат (за исключением инфраструктуры) |
| Ограничения | Ограниченное количество профилей и данных в месяц | Нет строгих ограничений |
Для получения дополнительной информации прочитайте наше руководство по Веб-скрейпингу и API.
Какие данные можно собирать из LinkedIn
Вот неполный список типов данных, которые можно собирать из LinkedIn:
- Профиль: личные данные, опыт работы, образование, связи и т. д.
- Компании: информация о компании, списки сотрудников, объявления о вакансиях и т. д.
- Вакансии: описание должности, заявки, критерии и т. д.
- Должности: название должности, компания, местоположение, зарплата и т. д.
- Статьи: опубликованные посты, статьи, написанные пользователями и т. д.
- LinkedIn Learning: курсы, сертификаты, учебные программы и т. д.
Как обойти барьер входа в LinkedIn
Если вы попытаетесь перейти на страницу LinkedIn Jobs сразу после поиска в Google в режиме инкогнито (или без входа в систему), вы увидите следующее:
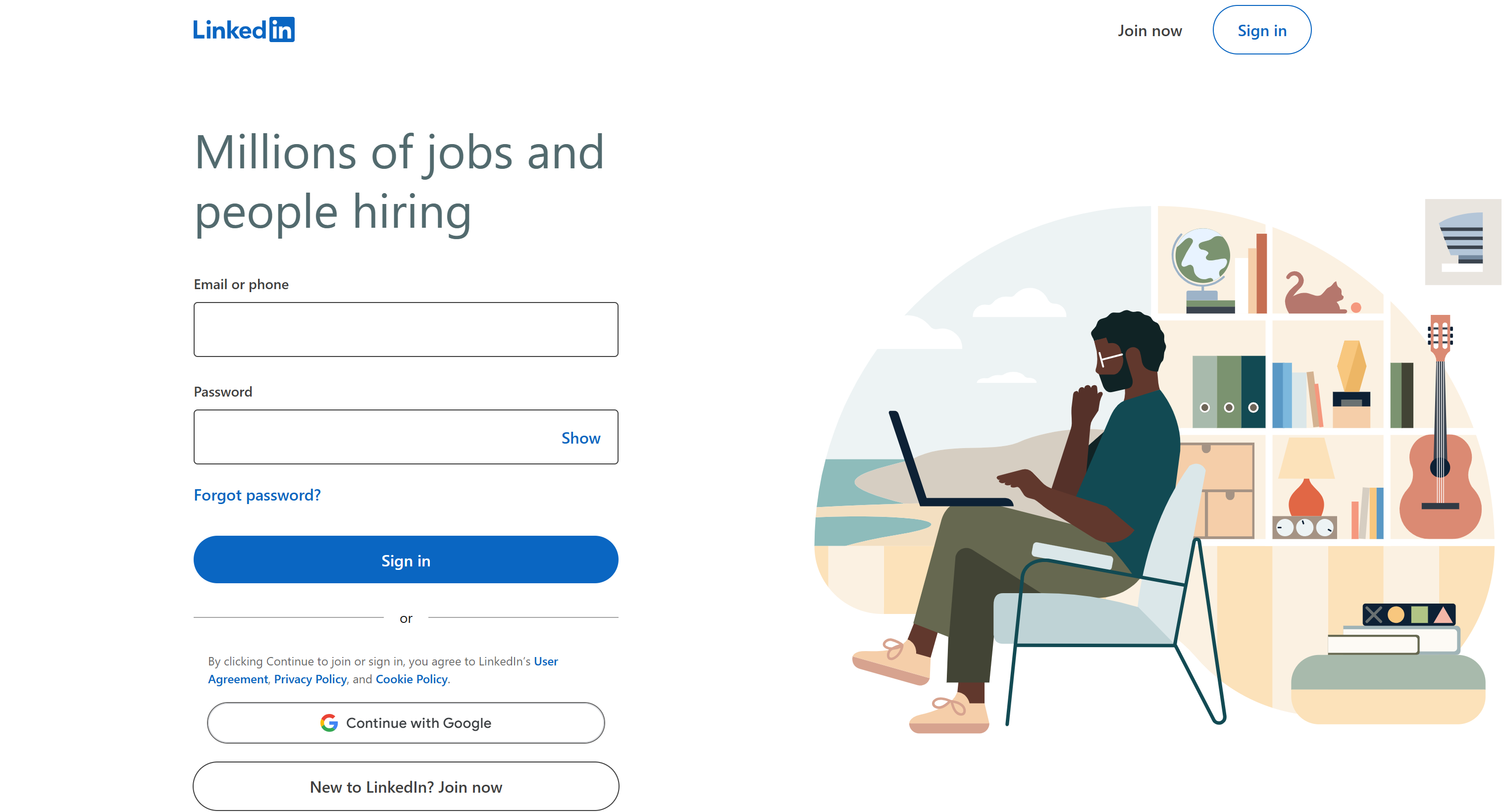
Вышеуказанная страница может создать у вас впечатление, что поиск работы на LinkedIn возможен только после входа в систему. Поскольку сбор данных за стеной входа в систему может привести к юридическим проблемам, так как это может нарушать условия предоставления услуг LinkedIn, вам следует этого избегать.
К счастью, есть простой способ обойти блокировку и получить доступ к странице вакансий. Все, что вам нужно сделать, это посетить главную страницу LinkedIn и нажать на вкладку «Вакансии»:
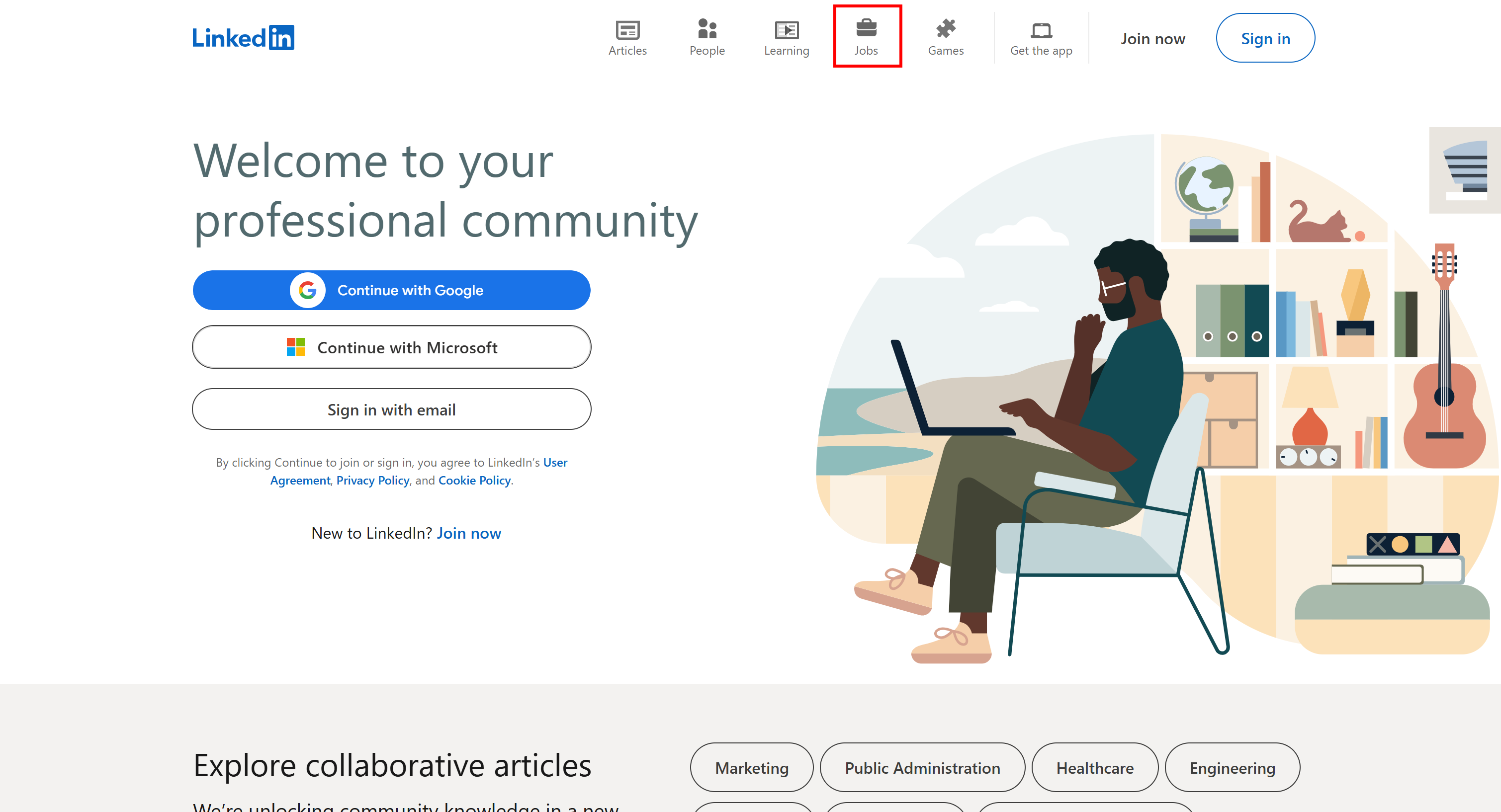
На этот раз вы получите доступ к странице поиска работы:

Как вы можете видеть в адресной строке браузера, на этот раз URL-адрес в вашем браузере содержит специальные параметры запроса:
https://www.linkedin.com/jobs/search?trk=guest_homepage-basic_guest_nav_menu_jobs&position=1&pageNum=0
В частности, аргумент trk=guest_homepage-basic_guest_nav_menu_jobs, по-видимому, является ключевым фактором, препятствующим LinkedIn ввести требование входа в систему.
Однако это не означает, что вы можете получить доступ ко всем данным LinkedIn. Некоторые разделы по-прежнему требуют входа в систему. Но, как мы сейчас увидим, это не является серьезным ограничением для Веб-скрейпинга LinkedIn.
Создание скрипта для Веб-скрейпинга LinkedIn: пошаговое руководство
В этом разделе учебника вы узнаете, как извлечь данные о вакансиях программистов в Нью-Йорке из LinkedIn:
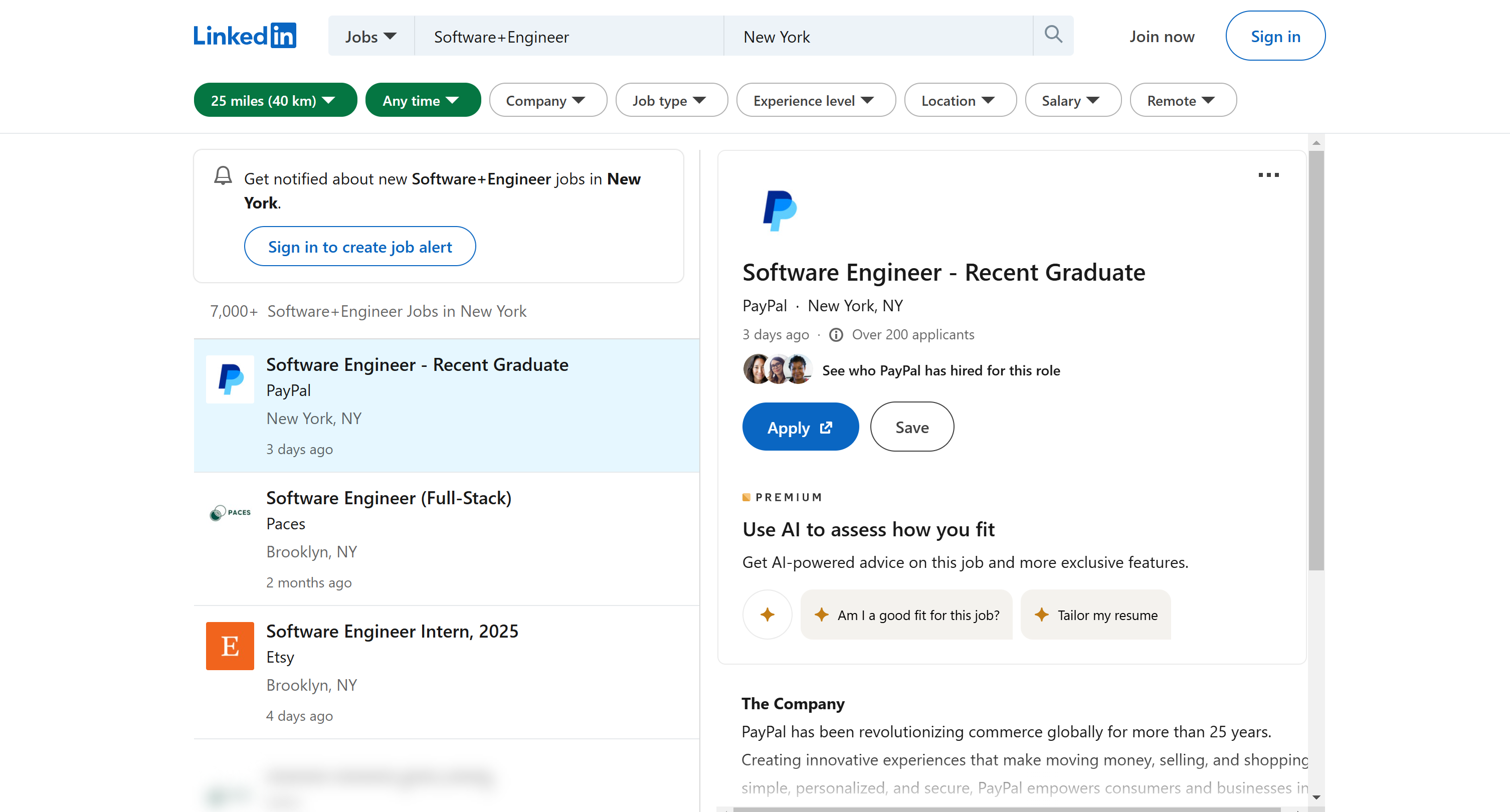
Мы начнем со страницы результатов поиска, автоматически извлечем URL-адреса объявлений о вакансиях, а затем извлечем данные из их подробных страниц. Скрейпер LinkedIn будет написан на Python, одном из лучших языков программирования для Веб-скрейпинга.
Давайте выполним веб-парсинг данных LinkedIn с помощью Python!
Шаг № 1: Настройка проекта
Прежде чем начать, убедитесь, что на вашем компьютере установлен Python 3. Если нет, загрузите его и следуйте инструкциям мастера установки.
Теперь используйте приведенную ниже команду, чтобы создать папку для вашего проекта по сбору данных:
mkdir linkedin-parser
linkedin-scraper представляет собой папку проекта вашего парсера LinkedIn на Python.
Войдите в нее и инициализируйте виртуальную среду внутри нее:
cd linkedin-parser
python -m venv venv
Загрузите папку проекта в вашей любимой IDE для Python. Подойдет Visual Studio Code с расширением Python или PyCharm Community Edition.
Создайте файл scraper.py в папке проекта, который должен содержать следующую структуру файлов:
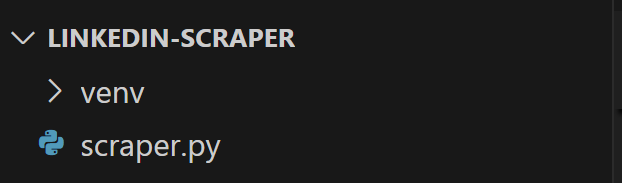
Сейчас scraper.py — это пустой скрипт Python, но вскоре он будет содержать нужную логику скрейпинга.
В терминале IDE активируйте виртуальную среду. В Linux или macOS запустите эту команду:
./env/bin/activate
Аналогично, в Windows выполните:
env/Scripts/activate
Отлично! Теперь у вас есть среда Python для Веб-скрейпинга.
Шаг 2: Выбор и установка библиотек для веб-парсинга
Прежде чем приступить к программированию, необходимо проанализировать целевой сайт, чтобы определить подходящие инструменты для скрапинга.
Начните с открытия страницы поиска вакансий LinkedIn в режиме инкогнито, как описано ранее. Использование режима инкогнито гарантирует, что вы вышли из системы и что никакие кэшированные данные не помешают процессу скрапинга.
Вот что вы должны увидеть:
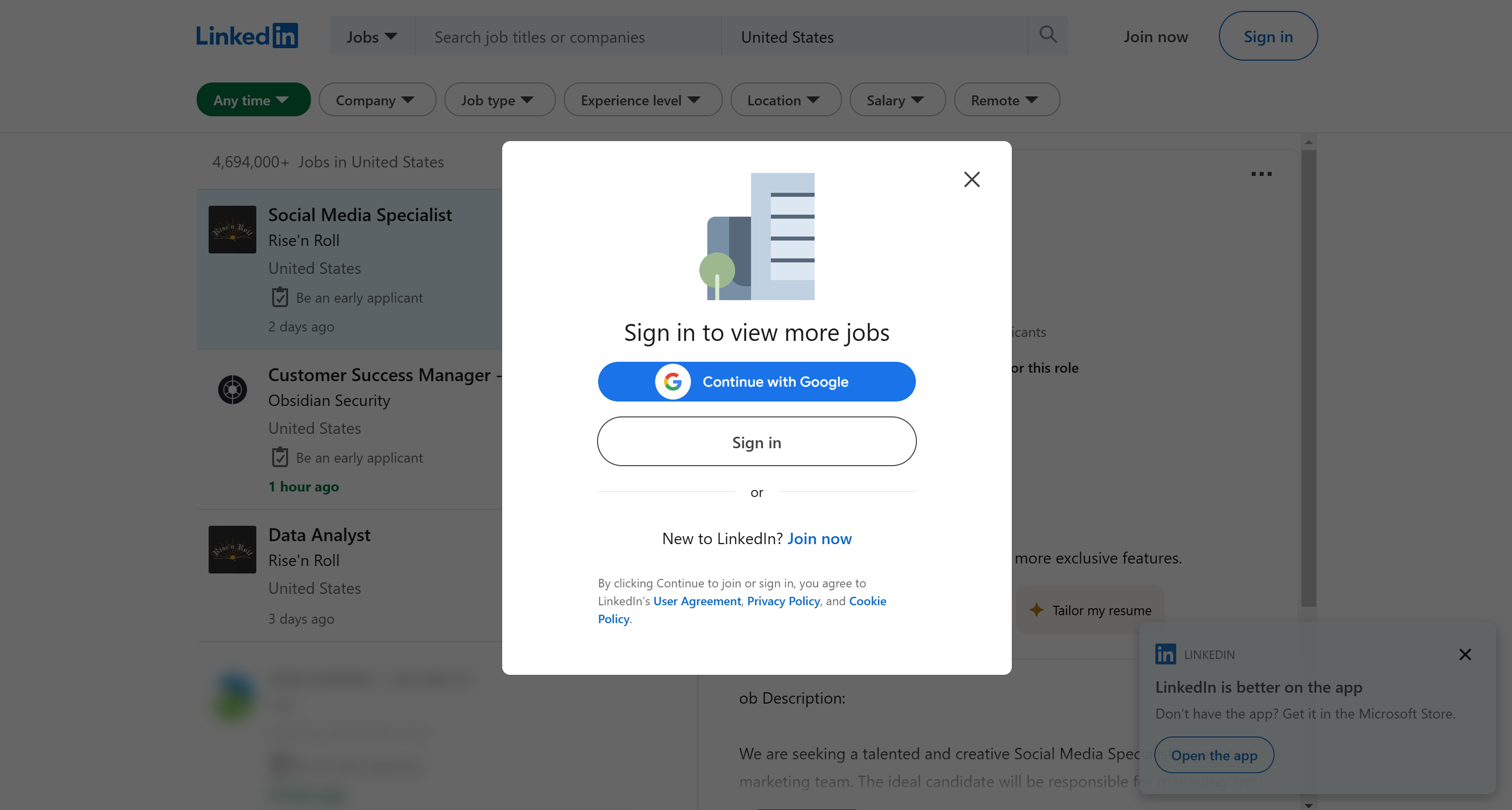
LinkedIn отображает несколько всплывающих окон в браузере. Они могут мешать при использовании инструментов автоматизации браузера, таких как Selenium или Playwright.
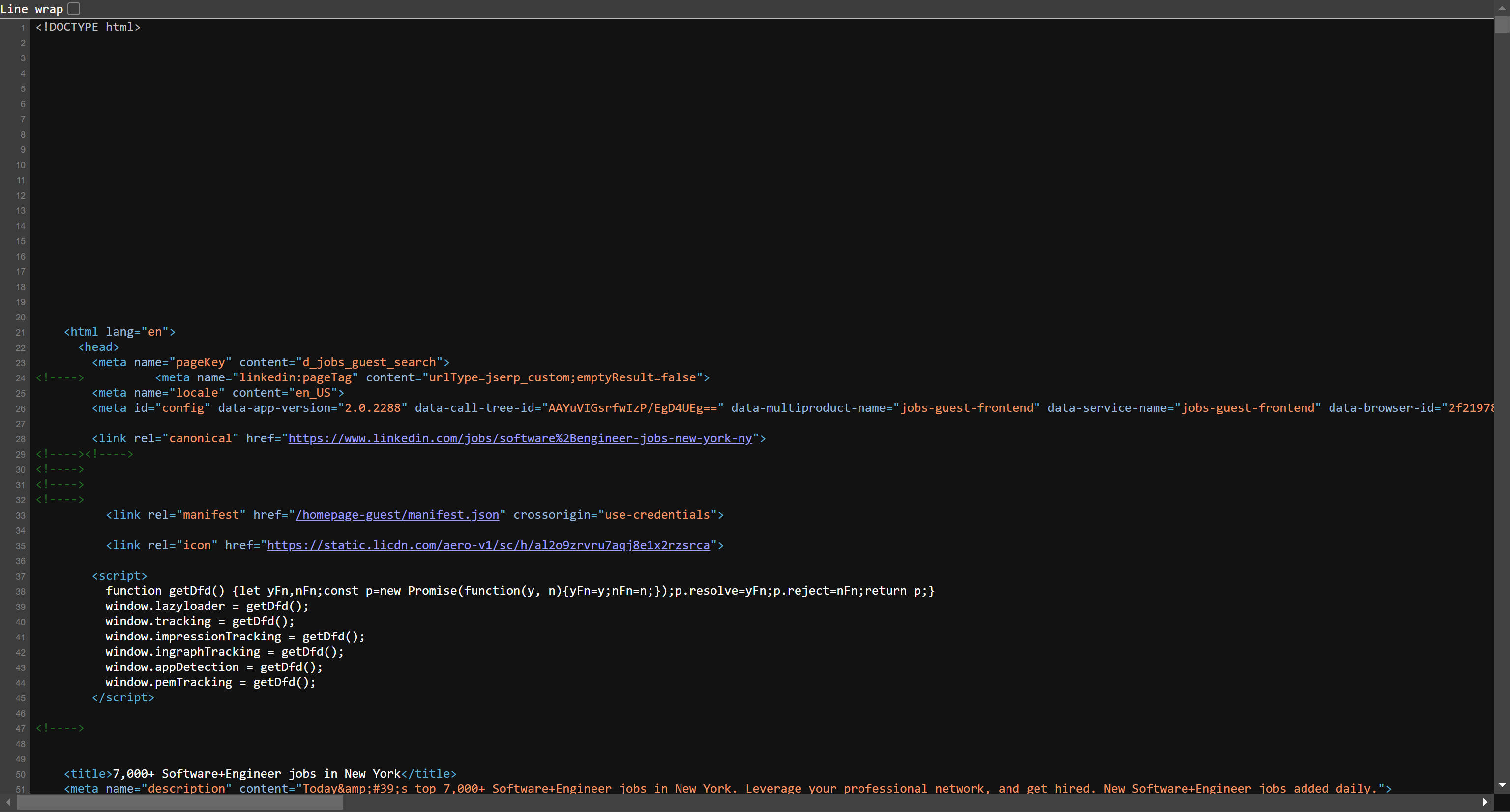
К счастью, если вы просмотрите исходный HTML-код страницы, возвращенный сервером, вы увидите, что он уже содержит большую часть данных на странице:
Аналогично, если вы проверите вкладку «Сеть» в DevTools, вы заметите, что страница не зависит от значительных динамических вызовов API:
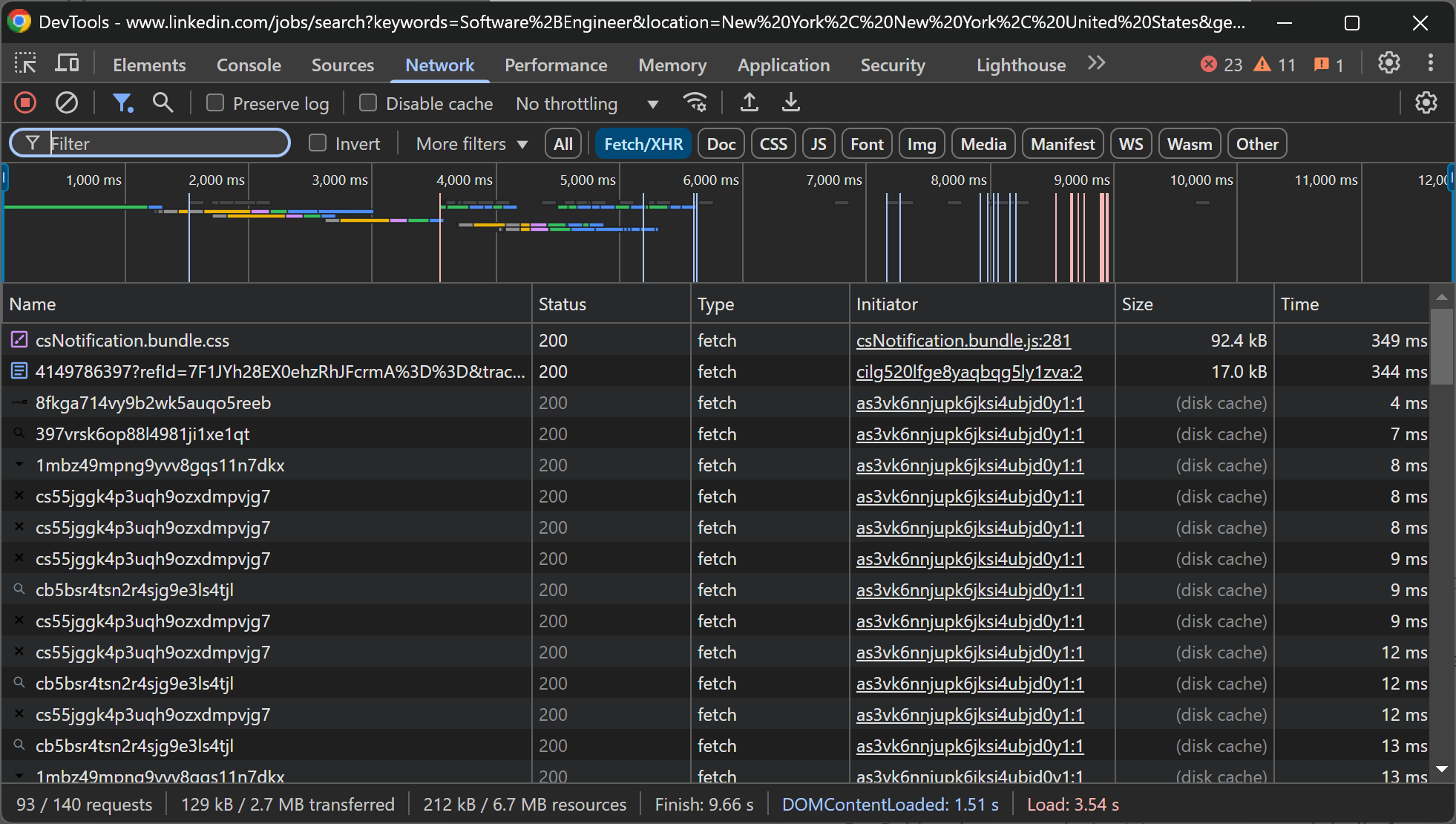
Другими словами, большая часть контента на страницах вакансий LinkedIn является статической. Это означает, что вам не нужен инструмент автоматизации браузера для сбора данных с LinkedIn. Для получения данных о вакансиях достаточно будет комбинации HTTP-клиента и HTML-парсера.
Таким образом, мы будем использовать две библиотеки Python для сбора данных о вакансиях в LinkedIn:
- Requests: простая библиотека HTTP для отправки запросов GET и извлечения содержимого веб-страниц.
- Beautiful Soup: мощный HTML-парсер, который упрощает извлечение данных из веб-страниц.
В активированной виртуальной среде установите обе библиотеки с помощью:
pip install requests beautifulsoup4
Затем импортируйте их в парсер.py с помощью:
from bs4 import BeautifulSoup
import requests
Отлично! Теперь у вас есть все необходимое, чтобы начать скрапинг LinkedIn.
Шаг № 3: Структурируйте скрипт для сбора данных
Как объясняется во введении к этому разделу, парсер LinkedIn будет выполнять две основные задачи:
- Получать URL-адреса страниц вакансий со страницы поиска LinkedIn Jobs
- Извлечение сведений о вакансиях с каждой конкретной страницы
Чтобы скрипт был хорошо организован, структурируйте файл scraper.py с помощью двух функций:
def retrieve_job_urls(job_search_url):
pass
# Будет реализовано...
def scrape_job(job_url):
pass
# Будет реализовано...
# Вызов функций и логика экспорта данных...
Ниже приведено описание двух функций:
retrieve_job_urls(job_search_url): Принимает URL-адрес страницы поиска вакансий и возвращает список URL-адресов страниц вакансий.scrape_job(job_url): Принимает URL-адрес страницы с вакансиями и извлекает такие данные о вакансии, как название, компания, местоположение и описание.
Затем, в конце скрипта, вызовите эти функции и реализуйте логику экспорта данных для хранения извлеченных данных о вакансиях. Пришло время реализовать эту логику!
Шаг 4: Подключитесь к странице поиска вакансий
В функции retrieve_job_urls() используйте библиотеку requests для извлечения целевой страницы с помощью URL-адреса, переданного в качестве аргумента:
response = requests.get(job_url)
В фоновом режиме выполняется HTTP-запрос GET к целевой странице и извлекается HTML-документ, возвращенный сервером.
Чтобы получить доступ к HTML-содержимому из ответа, используйте атрибут .text:
html = response.text
Отлично! Теперь вы готовы к парсингу HTML и извлечению URL-адресов вакансий.
Шаг № 5: Получение URL-адресов вакансий
Чтобы произвести парсинг ранее извлеченного HTML-кода, передайте его в конструктор Beautiful Soup:
soup = BeautifulSoup(html, "html.parser")
Второй аргумент указывает HTML-парсер, который будет использоваться. html.parser — это парсер по умолчанию, включенный в стандартную библиотеку Python.
Затем просмотрите элементы карточки вакансии на странице поиска вакансий LinkedIn. Щелкните правой кнопкой мыши по одной из них и выберите «Просмотреть» в DevTools вашего браузера:

Как видно из HTML-кода карточки вакансии, URL-адреса вакансий можно извлечь с помощью следующего CSS-селектора:
[data-tracking-control-name="public_jobs_jserp-result_search-card"]
Примечание: использование атрибутов data-* для выбора узлов при Веб-скрейпинге является идеальным вариантом, поскольку они часто используются для тестирования или внутреннего отслеживания. Это снижает вероятность их изменения со временем.
Теперь, если вы посмотрите на страницу, вы увидите, что некоторые карточки вакансий могут отображаться размыто за элементом приглашения к входу:
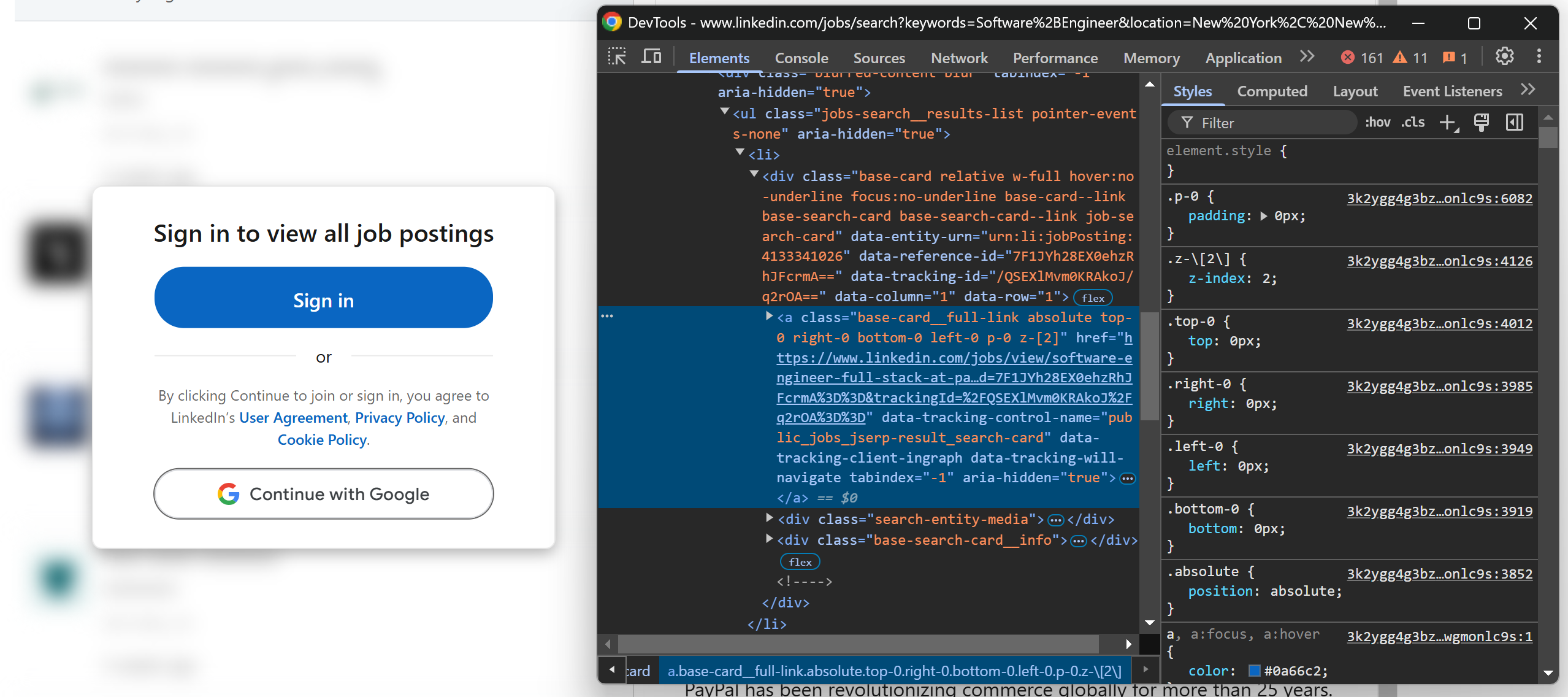
Не беспокойтесь, это всего лишь эффект интерфейса. В базовом HTML-коде по-прежнему содержатся URL-адреса страниц вакансий, поэтому вы можете получить эти URL-адреса без входа в систему.
Вот логика извлечения URL-адресов объявлений о вакансиях со страницы LinkedIn Jobs:
job_urls = []
job_url_elements = soup.select("[data-tracking-control-name="public_jobs_jserp-result_search-card"]")
for job_url_element in job_url_elements:
job_url = job_url_element["href"]
job_urls.append(job_url)
select() возвращает все элементы, соответствующие заданному CSS-селектору, которые содержат ссылки на вакансии. Затем скрипт:
- проходит по этим элементам
- Получает доступ к HTML-атрибуту
href(URL-адрес страницы вакансии) - добавляет его в список
job_urls
Если вы не знакомы с вышеуказанной логикой, прочтите наше руководство по Веб-скрейпингу Beautiful Soup.
В конце этого шага ваша функция retrieve_job_urls() будет выглядеть следующим образом:
def retrieve_job_urls(job_search_url):
# Отправляет HTTP-запрос GET для получения HTML-кода страницы
response = requests.get(job_search_url)
# Получает доступ к HTML-коду и анализирует его
html = response.text
soup = BeautifulSoup(html, "html.parser")
# Где хранить собранные данные
job_urls = []
# Логика сбора данных
job_url_elements = soup.select("[data-tracking-control-name="public_jobs_jserp-result_search-card"]")
for job_url_element in job_url_elements:
# Извлечение URL-адреса страницы вакансии и добавление его в список
job_url = job_url_element["href"]
job_urls.append(job_url)
return job_urls
Вы можете вызвать эту функцию на целевой странице, как показано ниже:
public_job_search_url = "https://www.linkedin.com/jobs/search?keywords=Software%2BEngineer&location=New%20York%2C%20New%20York%2C%20United%20States&geoId=102571732&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0"
job_urls = retrieve_job_urls(public_job_search_url)
Отлично! Вы выполнили первое задание по созданию парсера LinkedIn.
Шаг 6: Инициализация задачи по сбору данных о вакансиях
Теперь сосредоточьтесь на функции scrape_job(). Как и раньше, используйте библиотеку requests, чтобы получить HTML-код страницы с вакансиями по указанному URL-адресу и проанализировать его с помощью Beautiful Soup:
response = requests.get(job_url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
Поскольку скрейпинг данных о вакансиях в LinkedIn включает в себя извлечение различных фрагментов информации, мы разделим его на два этапа, чтобы упростить процесс.
Шаг № 7: Извлечение данных о вакансиях — Часть 1
Прежде чем приступить к сбору данных из LinkedIn, необходимо изучить страницу с подробной информацией о вакансии, чтобы понять, какие данные она содержит и как их получить.
Для этого откройте страницу с вакансиями в режиме инкогнито и используйте DevTools для просмотра страницы. Сосредоточьтесь на верхней части страницы с объявлениями о вакансиях:
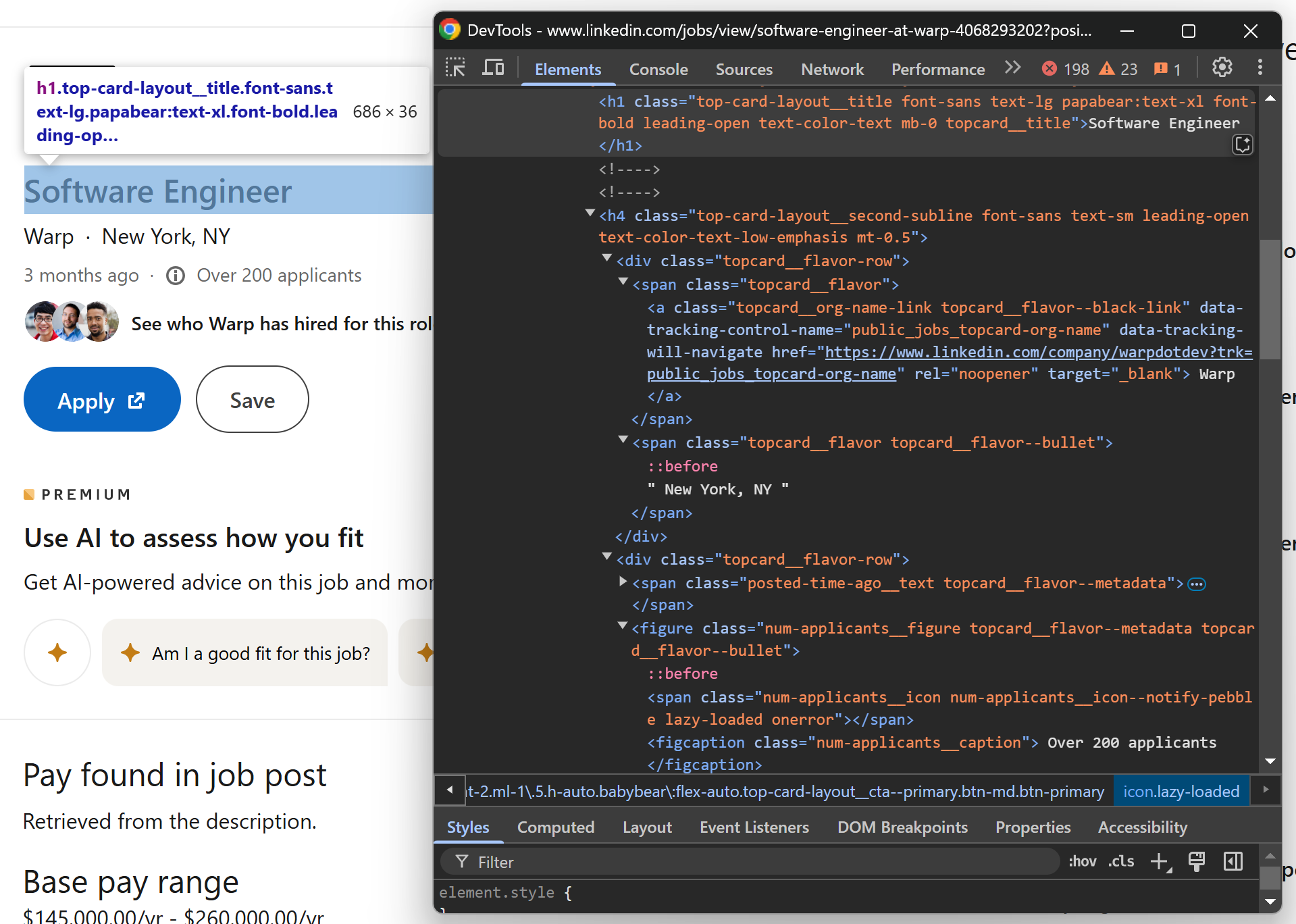
Обратите внимание, что вы можете извлечь следующие данные:
- Название вакансии из тега
<h1> - Название компании, предлагающей вакансию, из элемента
[data-tracking-control-name="public_jobs_topcard-org-name"] - Информацию о местоположении из
.topcard__flavor--bullet - Количество соискателей из узла
.num-applicants__caption
В функции scrape_job() после разбора HTML используйте следующую логику для извлечения этих полей:
title_element = soup.select_one("h1")
title = title_element.get_text().strip()
company_element = soup.select_one("[data-tracking-control-name="public_jobs_topcard-org-name"]")
company_name = company_element.get_text().strip()
company_url = company_element["href"]
location_element = soup.select_one(".topcard__flavor--bullet")
location = location_element.get_text().strip()
applicants_element = soup.select_one(".num-applicants__caption")
applicants = applicants_element.get_text().strip()
Функция strip() необходима для удаления любых пробелов в начале или в конце скопированного текста.
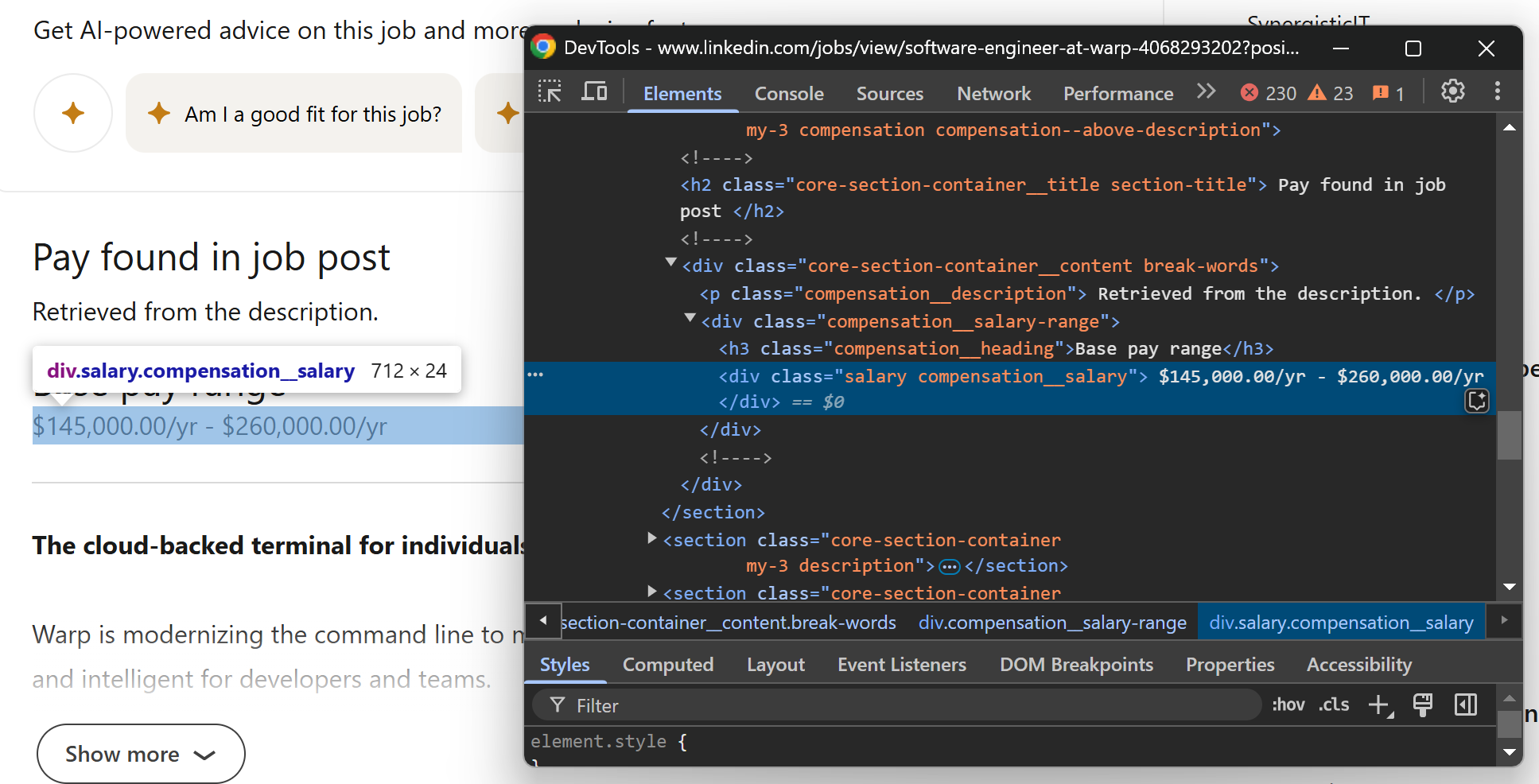
Далее сосредоточьтесь на разделе «Заработная плата» на странице:
Вы можете получить эту информацию с помощью CSS-селектора .salary. Поскольку не все вакансии имеют этот раздел, вам понадобится дополнительная логика, чтобы проверить, присутствует ли HTML-элемент на странице:
salary_element = soup.select_one(".salary")
if salary_element is not None:
salary = salary_element.get_text().strip()
else:
salary = None
Если .salary отсутствует на странице, select_one() вернет None, и переменная salary будет установлена в None.
Отлично! Вы только что извлекли часть данных со страницы вакансии в LinkedIn.
Шаг № 8: Получение данных о вакансии — часть 2
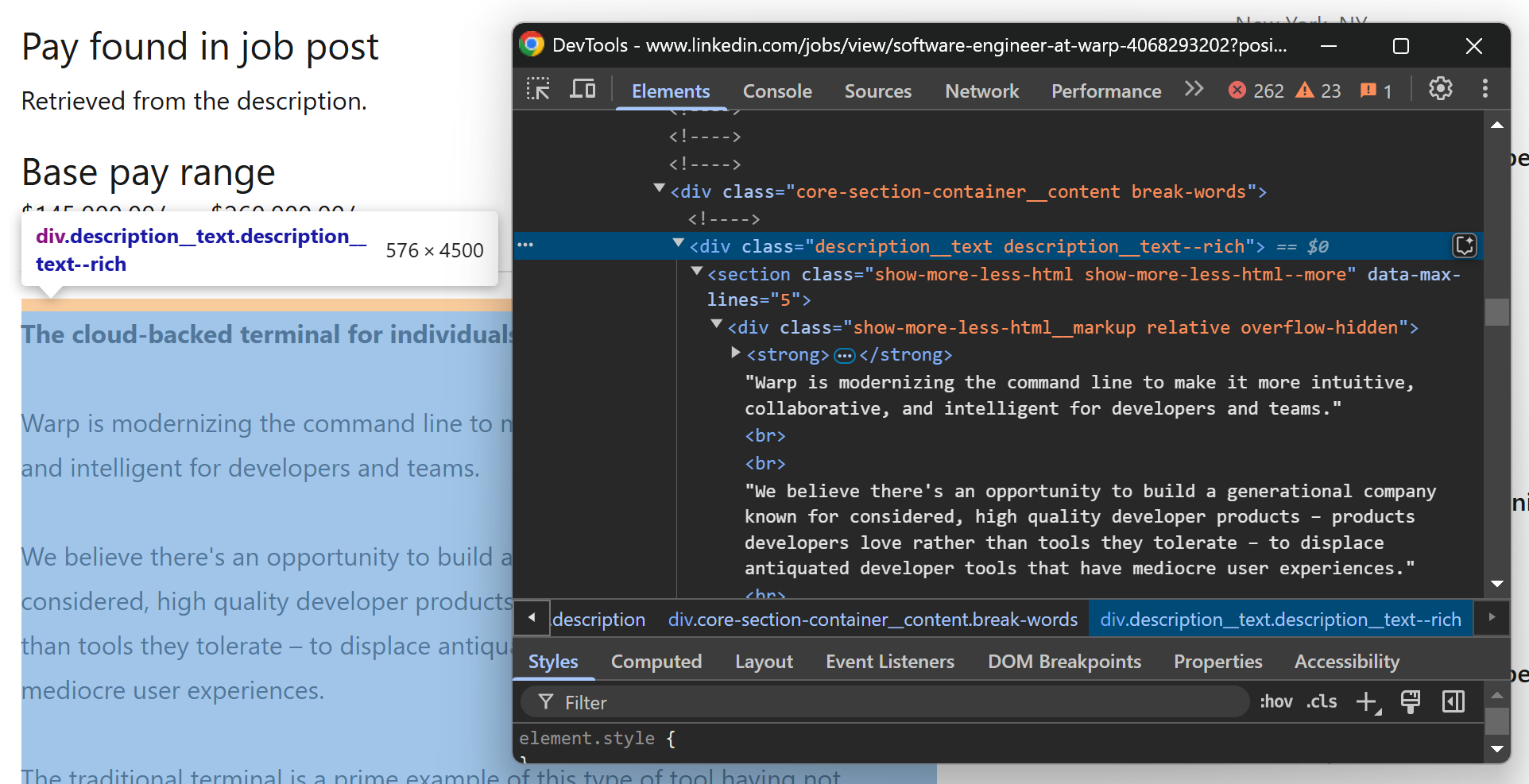
Теперь сосредоточьтесь на нижней части страницы вакансий LinkedIn, начиная с описания вакансии:
Вы можете получить доступ к тексту описания вакансии из элемента .description__text .show-more-less-html, используя следующий код:
description_element = soup.select_one(".description__text .show-more-less-html")
description = description_element.get_text().strip()
Наконец, самой сложной частью Веб-скрейпинга LinkedIn является работа с разделом критериев:
В этом случае вы не можете точно предсказать, какие данные будут представлены на странице. Таким образом, вам необходимо обрабатывать каждую запись критериев как пару <имя, значение>. Чтобы извлечь данные критериев:
- Выберите элемент
<ul>с помощью CSS-селектора.description__job-criteria-list li - Пройдите по выбранным элементам и для каждого из них:
- Скрепите название элемента из
.description__job-criteria-subheader - Извлеките значение элемента из
.description__job-criteria-text - Добавьте извлеченные данные в виде словаря в массив
- Скрепите название элемента из
Реализуйте логику извлечения данных из LinkedIn для раздела критериев с помощью следующих строк кода:
criteria = []
criteria_elements = soup.select(".description__job-criteria-list li")
for criteria_element in criteria_elements:
name_element = criteria_element.select_one(".description__job-criteria-subheader")
name = name_element.get_text().strip()
value_element = criteria_element.select_one(".description__job-criteria-text")
value = value_element.get_text().strip()
criteria.append({
"name": name,
"value": value
})
Отлично! Вы успешно собрали данные о вакансии. Следующий шаг — собрать все собранные данные LinkedIn в объект и вернуть его.
Шаг 9: Сбор собранных данных
Используйте данные, извлеченные в предыдущих двух шагах, для заполнения объекта вакансии и возвращения его из функции:
job = {
"url": job_url,
"title": title,
"company": {
"name": company_name,
"url": company_url
},
"location": location,
"applications": applicants,
"salary": salary,
"description": description,
"criteria": criteria
}
return job
После выполнения предыдущих трех шагов scrape_job() должен выглядеть следующим образом:
def scrape_job(job_url):
# Отправить HTTP GET-запрос для получения HTML-кода страницы
response = requests.get(job_url)
# Получить доступ к HTML-тексту из ответа и проанализировать его
html = response.text
soup = BeautifulSoup(html, "html.parser")
# Логика сбора данных
title_element = soup.select_one("h1")
title = title_element.get_text().strip()
company_element = soup.select_one("[data-tracking-control-name="public_jobs_topcard-org-name"]")
company_name = company_element.get_text().strip()
company_url = company_element["href"]
location_element = soup.select_one(".topcard__flavor--bullet")
location = location_element.get_text().strip()
applicants_element = soup.select_one(".num-applicants__caption")
applicants = applicants_element.get_text().strip()
salary_element = soup.select_one(".salary")
if salary_element is not None:
salary = salary_element.get_text().strip()
else:
salary = None
description_element = soup.select_one(".description__text .show-more-less-html")
description = description_element.get_text().strip()
criteria = []
criteria_elements = soup.select(".description__job-criteria-list li")
for criteria_element in criteria_elements:
name_element = criteria_element.select_one(".description__job-criteria-subheader")
name = name_element.get_text().strip()
value_element = criteria_element.select_one(".description__job-criteria-text")
value = value_element.get_text().strip()
criteria.append({
"name": name,
"value": value
})
# Сбор и возврат собранных данных
job = {
"url": job_url,
"title": title,
"company": {
"name": company_name,
"url": company_url
},
"location": location,
"applications": applicants,
"salary": salary,
"description": description,
"criteria": criteria
}
return job
Чтобы собрать данные о вакансиях, вызовите эту функцию, проходя по URL-адресам вакансий, возвращенным функцией retrieve_job_urls(). Затем добавьте собранные данные в массив jobs:
jobs = []
for job_url in job_urls:
job = scrape_job(job_url)
jobs.append(job)
Отлично! Логика сбора данных LinkedIn теперь готова.
Шаг № 10: Экспорт в JSON
Данные о вакансиях, извлеченные из LinkedIn, теперь хранятся в массиве объектов. Поскольку эти объекты не являются плоскими, имеет смысл экспортировать эти данные в структурированном формате, таком как JSON.
Python позволяет экспортировать данные в JSON без дополнительных зависимостей. Для этого можно использовать следующую логику:
file_name = "jobs.json"
with open(file_name, "w", encoding="utf-8") as file:
json.dump(jobs, file, indent=4, ensure_ascii=False)
Функция open() создает выходной файл jobs.json, который затем заполняется с помощью json.dump(). Параметр indent=4 обеспечивает форматирование JSON для удобства чтения, а ensure_ascii=False гарантирует правильное кодирование не-ASCII символов.
Чтобы код работал, не забудьте импортировать json из стандартной библиотеки Python:
import json
Шаг № 11: Завершите логику скрапинга
Теперь скрипт для скрапинга LinkedIn в основном готов. Тем не менее, есть несколько улучшений, которые можно внести:
- Ограничьте количество скрапируемых заданий
- Добавьте логгирование для отслеживания прогресса скрипта
Первый пункт важен, потому что:
- Вы не хотите перегружать целевой сервер слишком большим количеством запросов от вашего парсера LinkedIn
- Вы не знаете, сколько заданий находится на одной странице
Поэтому имеет смысл ограничить количество скрапируемых заданий следующим образом:
scraping_limit = 10
jobs_to_scrape = job_urls[:scraping_limit]
jobs = []
for job_url in jobs_to_scrape:
# ...
Это ограничит количество сканируемых страниц до 10.
Затем добавьте несколько операторов print(), чтобы отслеживать, что делает скрипт во время работы:
public_job_search_url = "https://www.linkedin.com/jobs/search?keywords=Software%2BEngineer&location=New%20York%2C%20New%20York%2C%20United%20States&geoId=102571732&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0"
print("Начало извлечения вакансий из URL-адреса поиска LinkedIn...")
job_urls = retrieve_job_urls(public_job_search_url)
print(f"Получено {len(job_urls)} URL-адресов вакансийn")
scraping_limit = 10
jobs_to_scrape = job_urls[:scraping_limit]
print(f"Сбор данных {len(jobs_to_scrape)} вакансий...n")
jobs = []
for job_url in jobs_to_scrape:
print(f"Начало извлечения данных из "{job_url}"")
job = scrape_job(job_url)
jobs.append(job)
print(f"Работа извлечена")
print(f"nЭкспорт {len(jobs)} извлеченных работ в JSON")
file_name = "jobs.json"
with open(file_name, "w", encoding="utf-8") as file:
json.dump(jobs, file, indent=4, ensure_ascii=False)
print(f"Вакансии успешно сохранены в "{file_name}"n")
Логика ведения журнала поможет вам отслеживать прогресс парсера, что очень важно, учитывая, что он проходит несколько этапов.
Шаг № 12: Соберите все воедино
Вот окончательный код вашего скрипта для скрапинга LinkedIn:
from bs4 import BeautifulSoup
import requests
import json
def retrieve_job_urls(job_search_url):
# Создайте HTTP GET-запрос, чтобы получить HTML-код страницы.
response = requests.get(job_search_url)
# Получите доступ к HTML-коду и проанализируйте его.
html = response.text
soup = BeautifulSoup(html, "html.parser")
# Где хранить собранные данные
job_urls = []
# Логика сбора данных
job_url_elements = soup.select("[data-tracking-control-name="public_jobs_jserp-result_search-card"]")
for job_url_element in job_url_elements:
# Извлечь URL-адрес страницы с вакансиями и добавить его в список
job_url = job_url_element["href"]
job_urls.append(job_url)
return job_urls
def scrape_job(job_url):
# Отправить HTTP-запрос GET для получения HTML-кода страницы
response = requests.get(job_url)
# Получить доступ к тексту HTML из ответа и проанализировать его
html = response.text
soup = BeautifulSoup(html, "html.parser")
# Логика скрапинга
title_element = soup.select_one("h1")
title = title_element.get_text().strip()
company_element = soup.select_one("[data-tracking-control-name="public_jobs_topcard-org-name"]")
company_name = company_element.get_text().strip()
company_url = company_element["href"]
location_element = soup.select_one(".topcard__flavor--bullet")
location = location_element.get_text().strip()
applicants_element = soup.select_one(".num-applicants__caption")
applicants = applicants_element.get_text().strip()
salary_element = soup.select_one(".salary")
if salary_element is not None:
salary = salary_element.get_text().strip()
else:
salary = None
description_element = soup.select_one(".description__text .show-more-less-html")
description = description_element.get_text().strip()
criteria = []
criteria_elements = soup.select(".description__job-criteria-list li")
for criteria_element in criteria_elements:
name_element = criteria_element.select_one(".description__job-criteria-subheader")
name = name_element.get_text().strip()
value_element = criteria_element.select_one(".description__job-criteria-text")
value = value_element.get_text().strip()
criteria.append({
"name": name,
"value": value
})
# Сбор и возврат собранных данных
job = {
"url": job_url,
"title": title,
"company": {
"name": company_name,
"url": company_url
},
"location": location,
"applications": applicants,
"salary": salary,
"description": description,
"criteria": criteria
}
return job
# Публичный URL страницы поиска вакансий LinkedIn
public_job_search_url = "https://www.linkedin.com/jobs/search?keywords=Software%2BEngineer&location=New%20York%2C%20New%20York%2C%20United%20States&geoId=102571732&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0"
print("Начало извлечения вакансий из URL-адреса поиска LinkedIn...")
# Извлечение отдельных URL-адресов для каждой вакансии на странице
job_urls = retrieve_job_urls(public_job_search_url)
print(f"Извлечено {len(job_urls)} URL-адресов вакансийn")
# Извлечение только 10 вакансий со страницы
scraping_limit = 10
jobs_to_scrape = job_urls[:scraping_limit]
print(f"Извлечение {len(jobs_to_scrape)} вакансий...n")
# Сбор данных со страницы каждой вакансии
jobs = []
for job_url in jobs_to_scrape:
print(f"Начало извлечения данных с "{job_url}"")
job = scrape_job(job_url)
jobs.append(job)
print(f"Вакансия собрана")
# Экспорт собранных данных в CSV
print(f"nЭкспорт {len(jobs)} собранных вакансий в JSON")
file_name = "jobs.json"
with open(file_name, "w", encoding="utf-8") as file:
json.dump(jobs, file, indent=4, ensure_ascii=False)
print(f"Вакансии успешно сохранены в "{file_name}"n")
Запустите его с помощью следующей команды:
python parser.py
Парсер LinkedIn должен зарегистрировать следующую информацию:
Начало извлечения вакансий из URL-адреса поиска LinkedIn...
Извлечено 60 URL-адресов вакансий
Извлечение 10 вакансий...
Начало извлечения данных по "https://www.linkedin.com/jobs/view/software-engineer-recent-graduate-at-paypal-4149786397?position=1&pageNum=0&refId=nz9sNo7HULREru1eS2L9nA%3D%3D&trackingId=uswFC6EjKkfCPcv0ykaojw%3D%3D"
Работа скрапирована
# опущено для краткости...
Начало извлечения данных по «https://www.linkedin.com/jobs/view/software-engineer-full-stack-at-paces-4090771382?position=2&pageNum=0&refId=UKcPcvFZMOsZrn0WhZYqtg%3D%3D&trackingId=p6UUa6cgbpYS1gDkRlHV2g%3D%3D"
Вакансия скопирована
Экспорт 10 скопированных вакансий в JSON
Вакансии успешно сохранены в "jobs.json"
Из 60 найденных страниц с вакансиями скрипт скреб только 10 вакансий. Поэтому выходной файл jobs.json, сгенерированный скриптом, будет содержать ровно 10 вакансий:
[
{
"url": "https://www.linkedin.com/jobs/view/software-engineer-recent-graduate-at-paypal-4149786397?position=1&pageNum=0&refId=UKcPcvFZMOsZrn0WhZYqtg%3D%3D&trackingId=UzOyWl8Jipb1TFAGlLJxqw%3D%3D",
"title": "Инженер-программист — недавний выпускник",
"company": {
"name": "PayPal",
"url": "https://www.linkedin.com/company/paypal?trk=public_jobs_topcard-org-name"
},
"location": "Нью-Йорк, штат Нью-Йорк",
"applications": "Более 200 соискателей",
"salary": null,
"description": "Опущено для краткости...",
"criteria": [
{
"name": "Уровень старшинства",
"value": "Неприменимо"
},
{
"name": "Тип занятости",
"value": "Полная занятость"
},
{
"name": "Должностные обязанности",
"value": "Инженерия"
},
{
"name": "Отрасли",
"value": "Разработка программного обеспечения, финансовые услуги, технологии, информация и Интернет"
}
]
},
// другие 8 должностей...
{
"url": "https://www.linkedin.com/jobs/view/software-engineer-full-stack-at-paces-4090771382?position=2&pageNum=0&refId=UKcPcvFZMOsZrn0WhZYqtg%3D%3D&trackingId=p6UUa6cgbpYS1gDkRlHV2g%3D%3D",
"title": "Инженер-программист (Full-Stack)",
"company": {
"name": "Paces",
"url": "https://www.linkedin.com/company/pacesai?trk=public_jobs_topcard-org-name"
},
"location": "Бруклин, Нью-Йорк",
"applications": "Более 200 соискателей",
"salary": "$150,000.00/год - $200,000.00/год",
"description": "Опущено для краткости...",
"criteria": [
{
"name": "Уровень старшинства",
"value": "Начальный уровень"
},
{
"name": "Тип занятости",
"value": "Полная занятость"
},
{
"name": "Должностные обязанности",
"value": "Инженерия и информационные технологии"
},
{
"name": "Отрасли",
"value": "Разработка программного обеспечения"
}
]
},
]
Et voilà! Веб-скрейпинг LinkedIn на Python не так уж и сложен.
Оптимизация сбора данных из LinkedIn
Скрипт, который мы создали, может создать впечатление, что сбор данных из LinkedIn — простая задача, но это не так. Блокировка входа в систему и методы запутывания данных могут быстро стать проблемой, особенно при масштабировании операций по сбору данных.
Кроме того, LinkedIn имеет механизмы ограничения скорости, которые блокируют автоматические скрипты, делающие слишком много запросов. Обычным обходным путем является ротация IP-адреса в Python, но это требует дополнительных усилий.
Кроме того, имейте в виду, что LinkedIn постоянно развивается, поэтому затраты на обслуживание и поддержку вашего парсера не являются незначительными. LinkedIn хранит сокровищницу данных в различных форматах, от объявлений о вакансиях до статей. Чтобы получить всю эту информацию, вам нужно будет создать несколько парсеров и управлять ими всеми.
Забудьте о хлопотах с API LinkedIn Parser от Bright Data. Этот специальный инструмент может собирать все необходимые вам данные LinkedIn и доставлять их через интеграции без кода или через простые конечные точки, которые вы можете вызвать с помощью любого HTTP-клиента.
Используйте его, чтобы за считанные секунды собирать профили, посты, компании, вакансии и многое другое в LinkedIn — без необходимости управлять всей архитектурой сбора данных.
Заключение
В этом пошаговом руководстве вы узнали, что такое скрейпер LinkedIn и какие типы данных он может извлекать. Вы также создали скрипт на Python для скрейпинга объявлений о вакансиях из LinkedIn.
Проблема заключается в том, что LinkedIn использует IP-баны и стены входа для блокировки автоматических скриптов. Избегайте этих проблем с помощью нашего LinkedIn Парсера.
Если Веб-скрейпинг не для вас, но вы все еще заинтересованы в данных, ознакомьтесь с нашими готовыми к использованию наборами данных LinkedIn!
Создайте бесплатную учетную запись Bright Data сегодня, чтобы попробовать наши API-интерфейсы для скрейпинга или изучить наши наборы данных.




