

В этом руководстве вы узнаете следующее:
- Что такое Dify и зачем его использовать.
- Причина, по которой вы должны интегрировать его с универсальным плагином для скраппинга.
- Преимущества интеграции Dify с плагином для сбора данных Bright Data.
- Пошаговое руководство по созданию рабочего процесса скрапинга в Dify.
Давайте погрузимся!
Dify: Сила низкокодовой разработки искусственного интеллекта
Dify – это платформа для разработки LLM-приложений с открытым исходным кодом. Она работает как LLM-операционное решение, упрощающее создание приложений на основе искусственного интеллекта.
В частности, она помогает разработчикам создавать и запускать готовые к использованию приложения агентского ИИ, предоставляя:
- Визуальный конструктор рабочих процессов: Создавайте многоэтапные процессы искусственного интеллекта с помощью интерфейса drag-and-drop. Вы можете объединять различные модели, инструменты и логику, не увязая в шаблонном коде.
- Агностичность моделей: Интеграция с широким спектром LLM, от проприетарных моделей, таких как серия GPT от OpenAI, до различных альтернатив с открытым исходным кодом. Это дает вам возможность выбрать наилучшую модель для вашего случая использования.
- Backend-as-a-service (BaaS): Возьмите на себя все сложности, связанные с хостингом, масштабированием и управлением внутренней инфраструктурой. Это позволит вам сосредоточиться на использовании возможностей ИИ, а не на управлении базовой инфраструктурой.
- Расширяемость: Легко расширяйте функциональность с помощью плагинов и пользовательских инструментов от сторонних поставщиков. Это делает Dify адаптируемым к широкому спектру вариантов использования.
Необходимость специализированного плагина для скрапинга в Dify
Крупномасштабный веб-скрепинг представляет собой множество проблем. Веб-сайты используют средства защиты от ботов, которые могут легко блокировать простые попытки извлечения данных. В результате создание и поддержка системы для преодоления этих препятствий является сложной и ресурсоемкой задачей.
Именно здесь на помощь приходит плагин Bright Data Dify. Плагин обрабатывает все базовые сложности, от ротации прокси и управления IP-адресами до решения CAPTCHA и разбора данных. Другими словами, он гарантирует, что ваш агент Dify получает последовательные и высококачественные веб-данные.
В деталях плагин Bright Data предоставляет такие инструменты:
- Структурированные данные: Получение структурированных, упорядоченных данных с более чем 50 платформ, таких как страницы товаров электронной коммерции или объявления о продаже недвижимости.
- Соскоб в формате markdown: Он удаляет рекламу, навигационные панели и другие несущественные элементы, предоставляя чистую, отформатированную в формате markdown версию текста.
- Инструмент для работы с поисковыми системами: Выполняйте запросы непосредственно в поисковых системах, таких как Google, Bing, Yandex и многих других. Вы можете использовать его для мониторинга поисковых рейтингов по определенным ключевым словам, обнаружения контента конкурентов или в рабочих процессах SERP RAG.
Преимущества интеграции Dify с плагином Bright Data Plugin
Когда вы соединяете возможности оркестровки искусственного интеллекта Dify с возможностями скриптинга Bright Data, вы раскрываете эту функциональность:
- Доступ к данным в режиме реального времени: Вместо того чтобы полагаться на устаревшие данные, ваш агент ИИ может запрашивать актуальную информацию в Интернете. Это гарантирует, что ваши приложения ИИ будут работать с самыми актуальными данными.
- Автоматизируйте сложные исследования и анализ: Подавая данные непосредственно в LLM в рамках рабочего процесса Dify, вы можете автоматизировать задачи, которые в противном случае потребовали бы многочасовой ручной работы. Например, вы можете построить рабочий процесс RAG для мониторинга списка товаров конкурентов на сайте электронной коммерции.
- Упрощение технических сложностей: Веб-скрейпинг – непростая задача, поскольку сайты используют сложные методы блокировки. Плагин Bright Data избавит вас от этих блокировок. При этом Dify предоставляет простой интерфейс для использования этой мощности.
- Универсальность для различных вариантов использования: Плагин предоставляет вам множество инструментов, включая получение структурированных данных, соскабливание любой страницы в чистый маркдаун и выполнение запросов к поисковым системам. Это делает интеграцию Dify + Bright Data адаптируемой для нескольких вариантов использования.
Интеграция Dify с Bright Data для обобщения информации о продуктах: Пошаговое руководство
Пора пройти пошаговое руководство, чтобы узнать, как использовать интеграцию между Dify и Bright Data.
Цель рабочего процесса, который вы будете создавать, – предоставить продукт Amazon в качестве входных данных и получить его резюме. Продукт, который вы будете использовать, – это Apple AirTag от Amazon:

Для достижения цели AI scraping вы построите четырехэтапный рабочий процесс, соединив различные узлы. Каждый узел выполняет определенную работу:
- Узел “Start” для определения входной переменной, которая представляет собой URL страницы товара Amazon.
- Узел “Структурированные данные” возьмет этот URL-адрес и выскребет его содержимое, извлекая все структурированные данные со страницы Amazon.
- Узел “LLM” для обработки полученных данных. Вы зададите ему определенный запрос на создание краткого описания продукта.
- Узел “End” для представления обобщенного текста, созданного LLM.
Весь этот четырехэтапный процесс AI-скреппинга полностью визуален. Вы соедините эти узлы в простой поток, и вам не придется писать ни строчки кода.
Следуйте инструкциям, чтобы создать в Dify свой рабочий процесс ИИ для веб-скрапинга без кода на базе Bright Data!
Требования
Чтобы воспроизвести это руководство по интеграции Dify с Bright Data, вам понадобятся:
- Учетная запись Dify (достаточно бесплатной учетной записи).
- Ключ API Bright Data.
Если у вас их еще нет, воспользуйтесь приведенными выше ссылками и следуйте инструкциям, чтобы все настроить.
Пререквизиты
Чтобы использовать узел LLM, сначала необходимо настроить интеграцию LLM в Dify. Для этого нажмите на изображение своего профиля и выберите опцию “Настройки”:

Вы будете перенаправлены на страницу, позволяющую выбрать модель (вкладка “Model Provider”). Например, вы можете установить плагин-провайдер OpenAI:

Очень хорошо! Теперь вы готовы приступить к работе с веб-скраппингом в Dify.
Шаг № 1: Загрузите плагин Bright Data и интегрируйте его
Загрузите последнюю версию пакета плагинов Bright Data из официального репозитория Dify. Затем нажмите кнопку “PLUGINS” и выберите опцию “Install from Local Package File”:
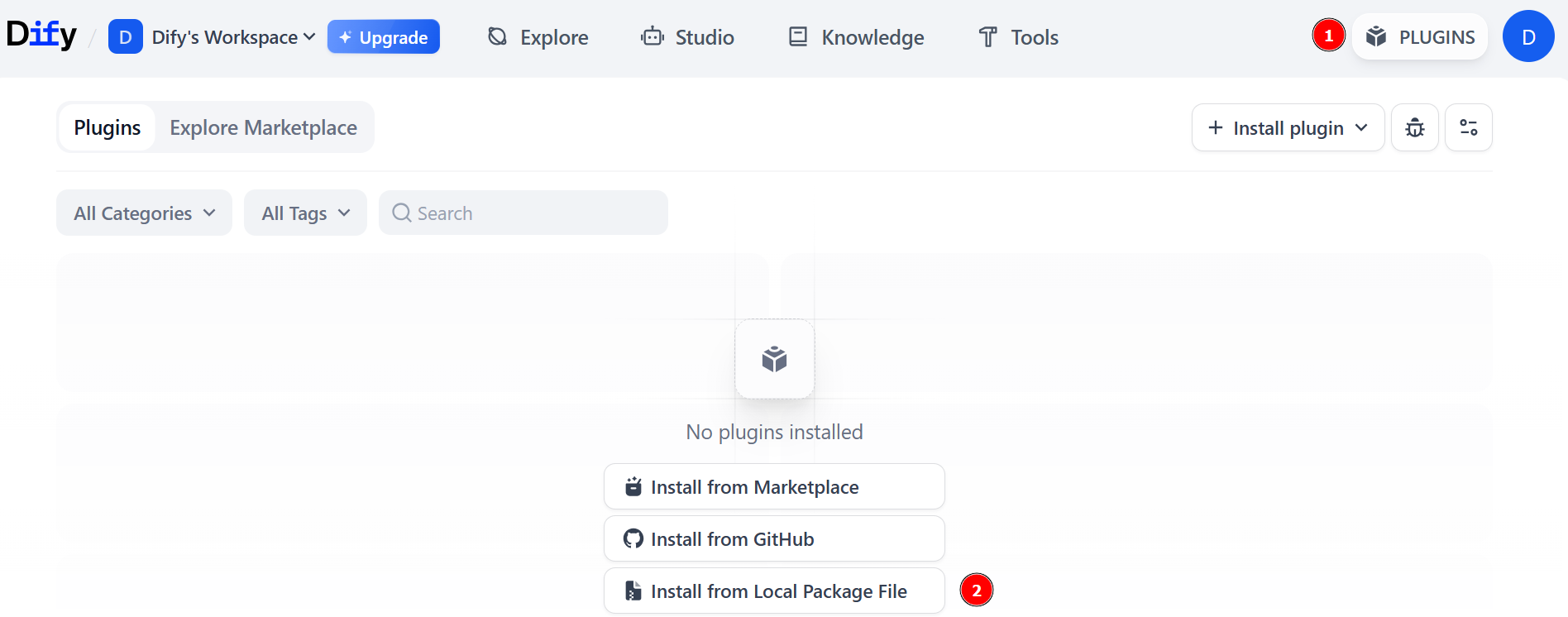
Выберите локальный файл, который вы загрузили ранее, и нажмите кнопку “Установить”:

Отлично! Пакет интеграции Bright Data теперь загружен и установлен на Dify.
Шаг № 2: Создайте новое приложение Dify
На главной странице рабочей области Dify создайте новое приложение с нуля, выбрав “Создать из пустого места”, как показано ниже:

Затем выберите тип “Рабочий процесс” и нажмите кнопку “Создать”:

Ниже показано, как будет выглядеть новый, пустой рабочий процесс:

Потрясающе! Вы только что создали новый рабочий процесс Dify. Пора добавить необходимые узлы для веб-скреппинга.
Шаг № 3: Настройка узлов для веб-скрапинга
Теперь вы можете добавить узлы в рабочий процесс и задать необходимые параметры для рабочего процесса Dify web scraping через Bright Data.
Начните с нажатия на узел “Start”, затем на “INPUT FIELD”:

Выберите в качестве типа “Параграф” и дайте имя полю “Имя переменной”. Например, product_url. Измените значение “Максимальная длина”, чтобы оно было не менее 200. Это представляет собой URL-адрес целевой страницы для сканирования. Вам нужно будет передать его на вход, чтобы запустить рабочий процесс.
Подтвердите нажатием кнопки “Сохранить”:

Отлично! Узел “Старт” настроен правильно.
Продолжите, нажав на “+” в узле “Пуск”. Выберите “Инструменты” > “Bright Data Web Scraper” > “Структурированные потоки данных”:

Узел Bright Data служит мостом, соединяющим ваш рабочий процесс Dify с инфраструктурой [Bright Data AI](
/ai). Он дает вашему агенту искусственного интеллекта возможность соскребать необходимую информацию из Интернета.
Выбрав инструмент “Структурированные потоки данных”, вы превратите беспорядочную страницу товара Amazon в структурированный JSON-вывод с предсказуемыми полями данных.
Теперь нажмите на кнопку “Авторизация”, чтобы ввести свой API-токен Bright Data:

Выберите product_url в качестве входной переменной. Таким образом, узел “Начало” будет передавать фактическое значение URL-адреса продукта в качестве входной переменной узла “Яркие данные”.
Для этого введите “/” в поле “Целевой URL”, и вам будет показан список доступных переменных. Также добавьте описание в поле “Описание запроса данных”:

Очень хорошо! Узел Bright Data настроен. Вы можете перейти к следующему узлу.
Нажмите на “+” и добавьте узел LLM:

В разделе “MODEL” выберите “Configure model” и выберите модель LLM из списка:

В разделе “SYSTEM” добавьте подсказку, например:
You are an expert e-commerce analyst. Based on the following structured data from an Amazon product page, write a concise and helpful summary for a potential buyer.
Include the following:
- Product name.
- A one-sentence summary.
- 3-5 key features in a bulleted list.
- The overall star rating and number of reviews.
- A brief concluding sentence about who this product is for.
Data:
{{Structure_Data_Feeds.text}}Эта подсказка предлагает LLM выступить в роли аналитика электронной коммерции и создать краткое описание отсканированного продукта. В нем также содержится просьба указать конкретные детали, например название продукта и его ключевые характеристики. Обратите внимание, что в конце содержится текстовый результат, полученный с помощью узла плагина Bright Data.
Вот как будет выглядеть заполненный раздел:

В разделе подсказки “Данные” добавьте текст в качестве входной переменной. Это позволит LLM использовать содержимое, которое узел Bright Data извлек из целевого URL. Если вы нажмете на “/”, вы получите список доступных переменных, которые вы можете выбрать.
Отлично! Теперь вы можете добавить последний узел в рабочий процесс.
Выход рабочего процесса можно получить, добавив узел “End”:

Выходная переменная должна быть строкой, поступающей из узла LLM. Для этого щелкните на разделе “OUTPUT VARIABLE” и выберите “text” в разделе “LLM”:

Потрясающе! Ваш рабочий процесс правильно настроен. Теперь вы готовы к его запуску.
Шаг № 4: Запустите рабочий процесс
Ниже представлен рабочий процесс веб-скреппинга в Dify с помощью плагина Bright Data:
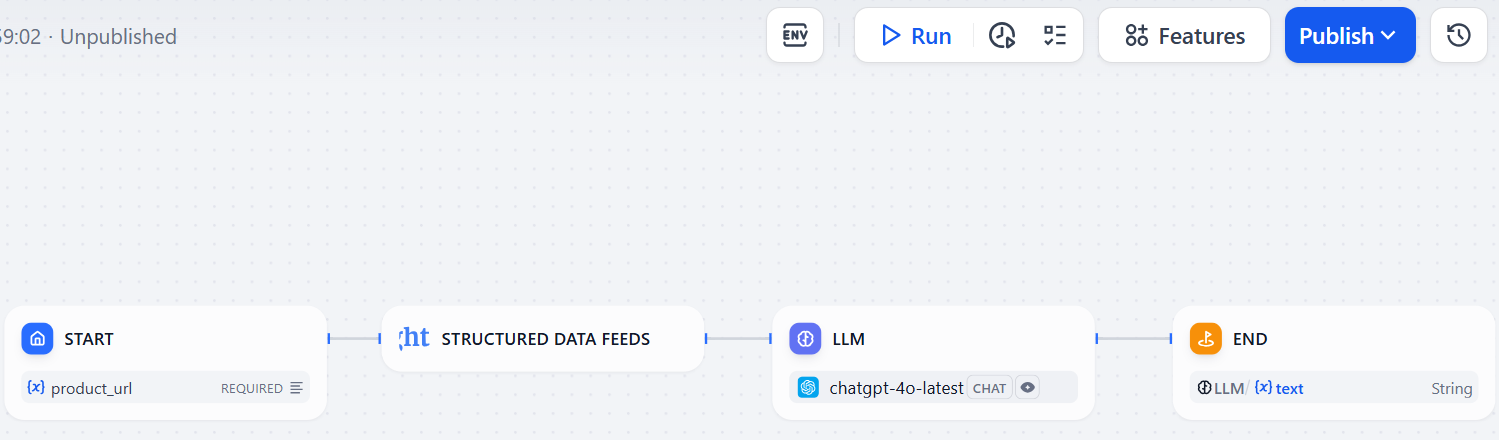
Как видите, он состоит всего из четырех узлов – как и предполагалось во введении к этой главе. Кроме того, для достижения цели вам не потребовалось написать ни строчки кода!
Чтобы запустить рабочий процесс, нажмите на кнопку “Запустить”. На этом этапе вам нужно добавить URL-адрес продукта Amazon в поле “product_url”. Затем нажмите “Start Run”, чтобы запустить рабочий процесс Dify для веб-скреппинга:

Результат будет доступен на вкладке “Результат”:

Ниже приведен результат в виде текста:
**Product Name:** Apple AirTag
Stay connected to your valuables with the Apple AirTag — a small, stylish tracker designed to help you locate personal items like keys, wallets, luggage, and even pets with ease using your iPhone or iPad.
**Key Features:**
- Seamless one-tap setup with iPhone or iPad via the Find My app.
- Precision Finding with Ultra Wideband technology (on compatible iPhone models) for accurate item location.
- Can be shared with up to 5 people, great for tracking shared items like keys or bags.
- Loud built-in speaker to help you locate your item or use voice commands with Siri.
- Water and dust resistant (IP67 rated) with a replaceable battery lasting over a year.
**Rating:** ⭐ 4.6 out of 5 stars, based on 32,227 customer reviews
This is an ideal purchase for Apple users who frequently misplace items or need a smart, subtle way to keep tabs on essentials — from travel gear to curious pets.Как и просили, LLM сообщил то, о чем вы просили в подсказке:
- Краткое описание продукта в одном предложении.
- 5 ключевых особенностей.
- Рейтинг.
- Заключительное предложение, рассказывающее о том, для кого предназначен этот продукт.
Если вы когда-нибудь пытались скреативить крупные сайты электронной коммерции, такие как Amazon, вы знаете, как это сложно:

Именно здесь интеграция с Bright Data сыграла решающую роль. Она справляется со всеми сложными мерами по борьбе со скрапингом за кулисами, обеспечивая, чтобы процесс получения данных работал как положено.
И вуаля! Вы успешно завершили свой первый проект по интеграции Dify с Bright Data.
Заключение
В этой статье вы узнали, как использовать Dify для создания рабочего процесса AI-скреппинга без кода. Это было бы невозможно без плагина Bright Data Dify. Как показано здесь, этот плагин открывает несколько продвинутых инструментов для веб-скрапинга в рамках рабочих процессов ИИ.
Одной из главных проблем при построении надежного рабочего процесса скраппинга для ваших агентов ИИ является доступ к высококачественным веб-данным. Для этого необходимы инструменты для получения, проверки и преобразования веб-контента, а это именно то, для чего создана инфраструктура ИИ Bright Data.
Создайте бесплатную учетную запись Bright Data и начните экспериментировать с нашими инструментами для работы с данными с искусственным интеллектом уже сегодня!





