

В этом руководстве вы узнаете:
- Что такое Agno и почему он является отличным выбором для построения агентных рабочих процессов.
- Почему веб-скраппинг играет такую важную роль для агентов ИИ.
- Как интегрировать Agno со встроенными инструментами Bright Data для создания агента для веб-скреппинга.
Давайте погрузимся!
Что такое Агно?
Agno – это полнофункциональный фреймворк на Python для создания мультиагентных систем, использующих память, знания и расширенные рассуждения. Он позволяет создавать сложные агенты искусственного интеллекта для широкого круга задач. От простых агентов, использующих инструменты, до совместных команд агентов с состоянием и детерминизмом.
Agno не зависит от модели, обладает высокой производительностью и ставит рассуждения в центр своего дизайна. Он поддерживает мультимодальные входы и выходы, сложную мультиагентную оркестровку, встроенный агентный поиск с векторными базами данных и полную обработку памяти/сессий.
На данный момент Agno – одна из самых популярных библиотек с открытым исходным кодом для создания агентов искусственного интеллекта, имеющая более 29 тысяч звезд на GitHub:
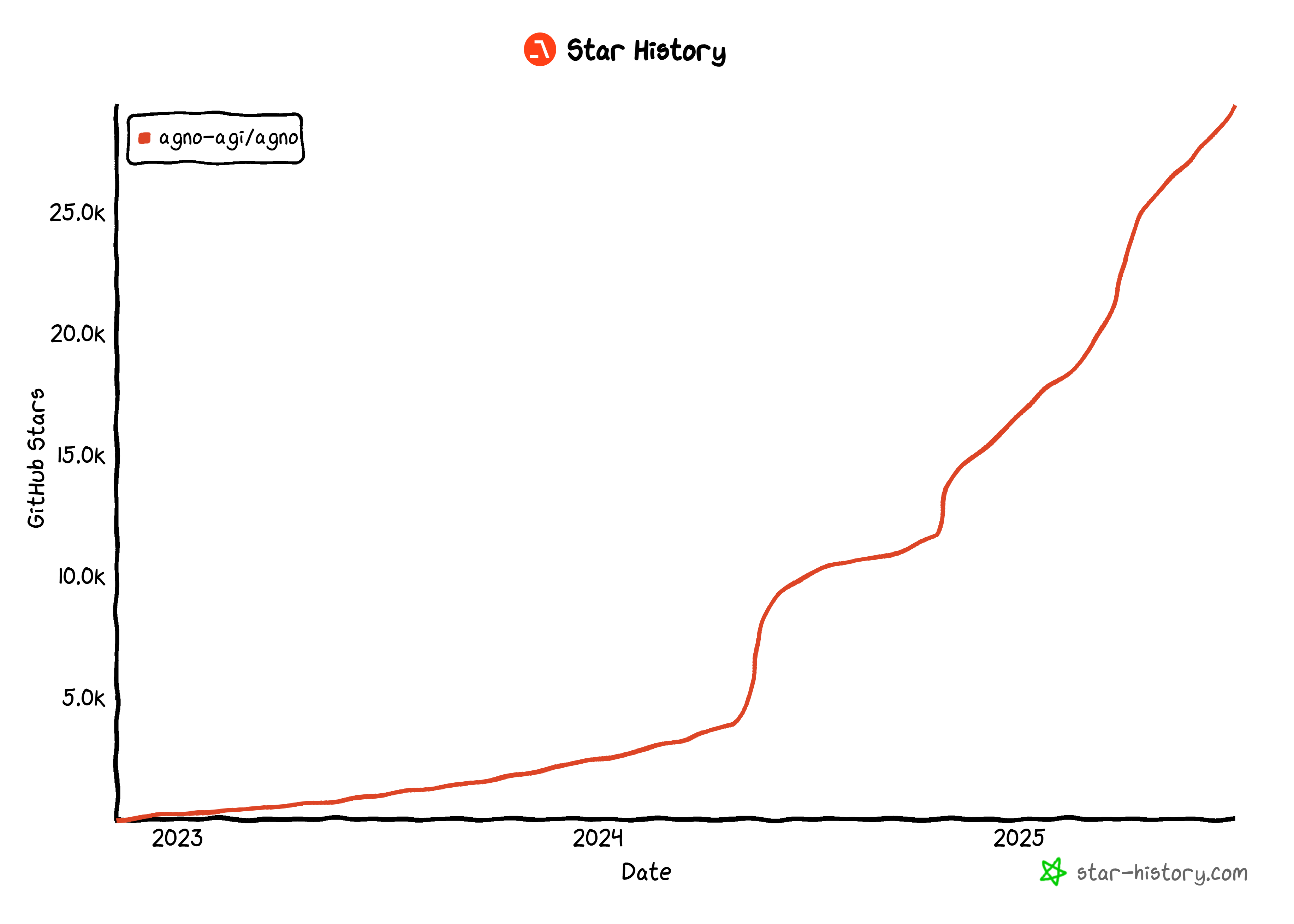
Его стремительный рост свидетельствует о том, как быстро Agno набирает обороты в сообществе разработчиков и ИИ.
Почему агентурный веб-скрепинг так полезен
Традиционный веб-скрепинг основан на написании жестких правил разбора данных для извлечения информации с определенных веб-страниц. Проблема? Сайты часто меняют свою структуру, а значит, вам постоянно приходится обновлять логику работы со скрапом. Это приводит к высоким эксплуатационным расходам и хрупким конвейерам.
Именно поэтому веб-скрепинг с использованием искусственного интеллекта находит все большую поддержку. Вместо того чтобы создавать собственные скрипты парсинга, вы можете использовать модель искусственного интеллекта для извлечения данных непосредственно из HTML веб-страницы с помощью простого запроса. Этот подход настолько популярен, что в последнее время появилось множество инструментов для ИИ-скреппинга.
Тем не менее, ИИ-скребок становится еще более мощным, если его встроить в архитектуру агентного ИИ. В частности, вы можете создать специального агента для веб-скреппинга, к которому смогут подключаться другие агенты ИИ. Это возможно в многоагентных рабочих процессах или с помощью протоколов ИИ, таких как A2A от Google.
Agno делает все вышеперечисленное возможным. Она позволяет создавать как автономные агенты ИИ для скраппинга, так и сложные мультиагентные экосистемы. Однако обычные LLM не предназначены для квалифицированного веб-скрапинга. Они часто не могут подключиться к сайтам с сильной защитой от ботов или, что еще хуже, могут “галлюцинировать” и возвращать фальшивые данные.
Чтобы устранить эти ограничения, Agno интегрируется с Bright Data с помощью специальных инструментов для соскабливания. С помощью этих инструментов ваш агент искусственного интеллекта может собирать свежие структурированные данные с любого веб-сайта.
Чтобы избежать блокировок и сбоев, Bright Data преодолевает такие проблемы, как отпечатки пальцев TLS, отпечатки пальцев браузера и устройства, CAPTCHA, защита Cloudflare и многое другое. После получения данных они поступают в LLM для интерпретации и анализа, следуя вашим первоначальным инструкциям.
Узнайте, как интегрировать инструменты Bright Data в агент Agno для веб-скреппинга нового уровня!
Как интегрировать инструменты Bright Data для веб-скрапинга в Agno
В этом пошаговом разделе вы увидите, как использовать Agno для создания агента ИИ, занимающегося веб-скреппингом. Интегрировав инструменты Bright Data, вы дадите своему агенту Agno возможность соскребать данные с любой веб-страницы.
Следуйте приведенным ниже инструкциям, чтобы создать в Agno своего агента для скраппинга на базе Bright Data!
Пререквизиты
Чтобы следовать этому руководству, убедитесь, что у вас есть следующее:
- Локально установленный Python 3.7 или выше (мы рекомендуем использовать последнюю версию).
- Ключ API Bright Data.
- API-ключ для поддерживаемого LLM-провайдера (здесь мы используем Gemini, потому что он бесплатен для использования через API, но подойдет любой поддерживаемый LLM-провайдер).
Не волнуйтесь, если у вас еще нет API-ключа Bright Data или API-ключа Gemini. Мы расскажем вам о том, как их создать, в следующих шагах.
Шаг №1: Настройка проекта
Откройте терминал и создайте новую директорию для вашего проекта Agno AI agent, который будет использовать Bright Data для веб-скрапинга:
mkdir agno-web-scraperВ папке agno-web-scraper будет храниться весь Python-код для вашего агента Agno, занимающегося скраппингом.
Затем перейдите в каталог проекта и создайте в нем виртуальное окружение:
cd agno-web-scraper
python -m venv venvТеперь загрузите проект в вашу любимую Python IDE. Мы рекомендуем Visual Studio Code с расширением Python или PyCharm Community Edition.
В папке проекта создайте новый файл с именем scraper.py. Структура каталогов должна выглядеть следующим образом:
agno-web-scraper/
├── venv/
└── scraper.pyАктивируйте виртуальную среду в терминале. В Linux или macOS выполните команду:
source venv/bin/activateАналогично, в Windows запустите эту команду:
venv/Scripts/activateВ следующих шагах вам будет предложено установить необходимые пакеты Python. Если вы предпочитаете установить все сейчас, в активированной виртуальной среде, выполните команду:
pip install agno python-dotenv google-genai requestsПримечание: Мы устанавливаем google-genai, потому что в этом руководстве Gemini используется в качестве провайдера LLM. Если вы планируете использовать другой LLM, обязательно установите соответствующую библиотеку для этого провайдера.
Все готово! Теперь у вас есть среда разработки на Python, готовая к построению агентурного рабочего процесса с использованием Agno и Bright Data.
Шаг №2: Настройка переменных окружения Чтение
Ваш агент Agno будет подключаться к сторонним сервисам, таким как Bright Data и Gemini, через API-интеграции. Чтобы сохранить безопасность, избегайте жесткого кодирования ключей API непосредственно в коде Python. Вместо этого храните их как переменные окружения.
Чтобы упростить загрузку переменных окружения, воспользуйтесь библиотекой python-dotenv. Активировав виртуальную среду, установите ее, выполнив команду:
pip install python-dotenvДалее в файле scraper.py импортируйте библиотеку и вызовите load_dotenv() для загрузки переменных окружения:
from dotenv import load_dotenv
load_dotenv()Эта функция позволяет вашему скрипту считывать переменные из локального файла .env. Создайте файл .env в корне каталога вашего проекта:
agno-web-scraper/
├── venv/
├── .env # <-----------
└── scraper.pyЗамечательно! Теперь вы настроены на безопасную работу с секретами интеграции с помощью переменных окружения.
Шаг № 3: Настройка ярких данных
Инструменты Bright Data, интегрированные в Agno, предоставляют вам доступ к нескольким решениям для сбора данных. В этом руководстве мы сосредоточимся на интеграции этих двух продуктов, предназначенных для сбора данных:
- Web Unlocker API: Продвинутый API для скраппинга, который преодолевает защиту от ботов и предоставляет доступ к любой веб-странице в формате Markdown.
- API для веб-скреперов: Специализированные конечные точки для этичного извлечения свежих структурированных данных с популярных сайтов, таких как LinkedIn, Amazon и многих других.
Чтобы использовать эти инструменты, вам необходимо:
- Настройте решение Web Unlocker в своей учетной записи Bright Data.
- Получите токен API Bright Data для аутентификации запросов к API Web Unlocker и Web Scraper.
Следуйте инструкциям ниже, чтобы сделать это!
Во-первых, если у вас еще нет учетной записи Bright Data, зарегистрируйтесь бесплатно. Если вы уже зарегистрированы, войдите в систему и откройте панель управления. Здесь нажмите кнопку “Получить прокси-продукты”:
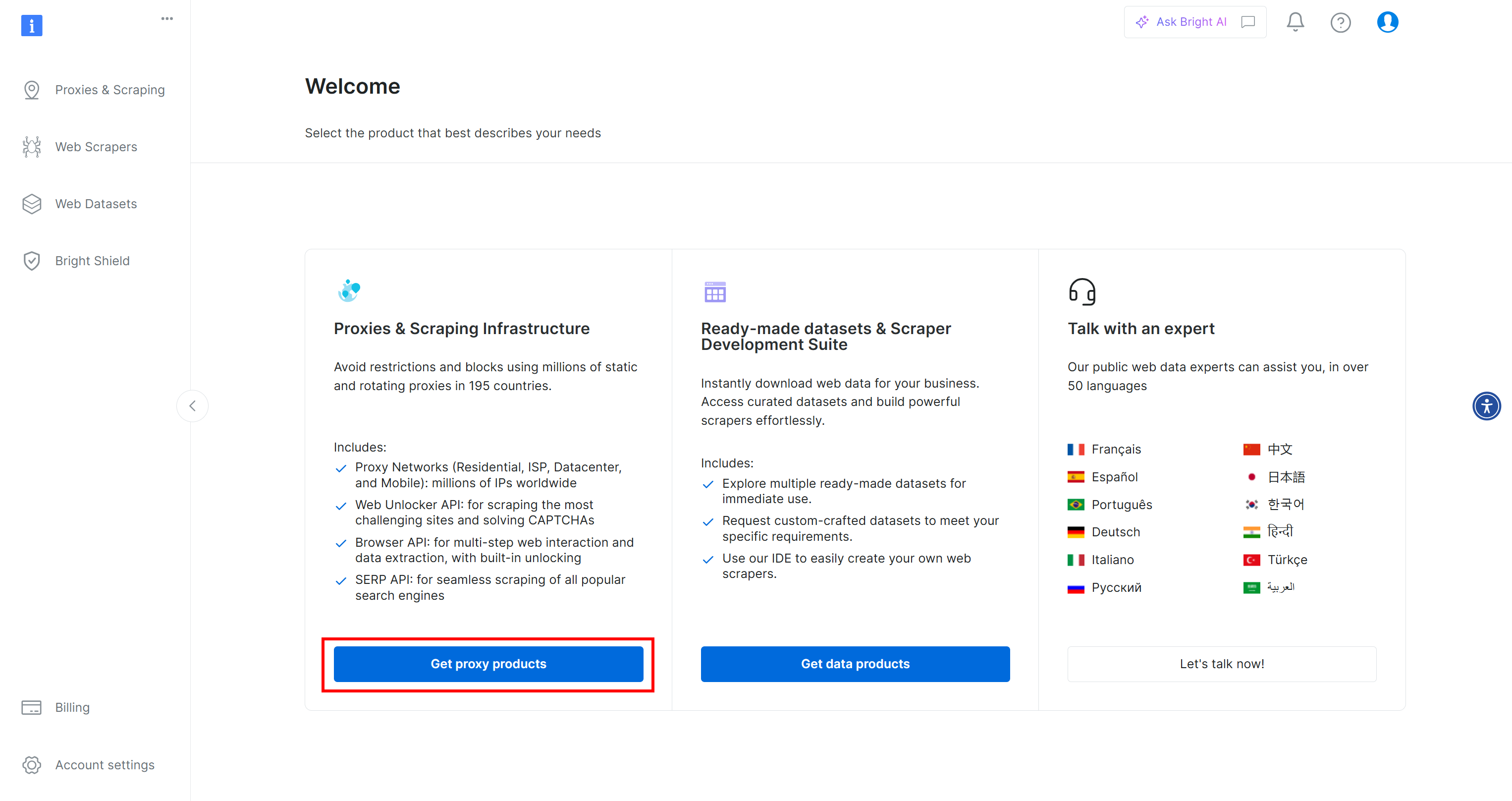
Вы будете перенаправлены на страницу “Прокси и инфраструктура скрапинга”:
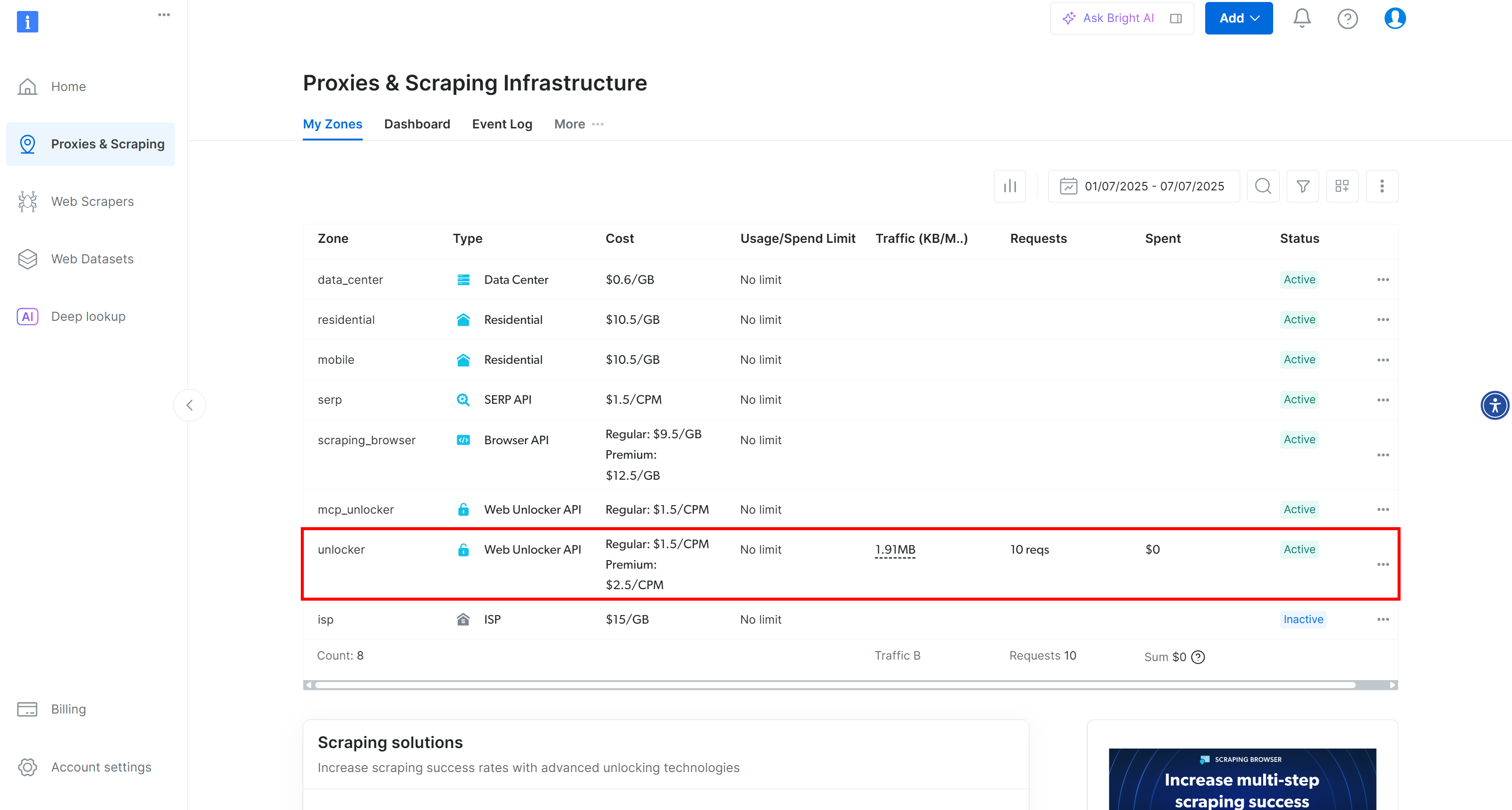
На этой странице вы увидите уже настроенные решения Bright Data. В этом примере активирована зона Web Unloker. Имя этой зоны – “unblocker” (оно понадобится вам позже, когда вы будете интегрировать ее в свой скрипт).
Если у вас еще нет зоны Web Unlocker, прокрутите страницу вниз до карточки “Web Unlocker API” и нажмите “Создать зону”:
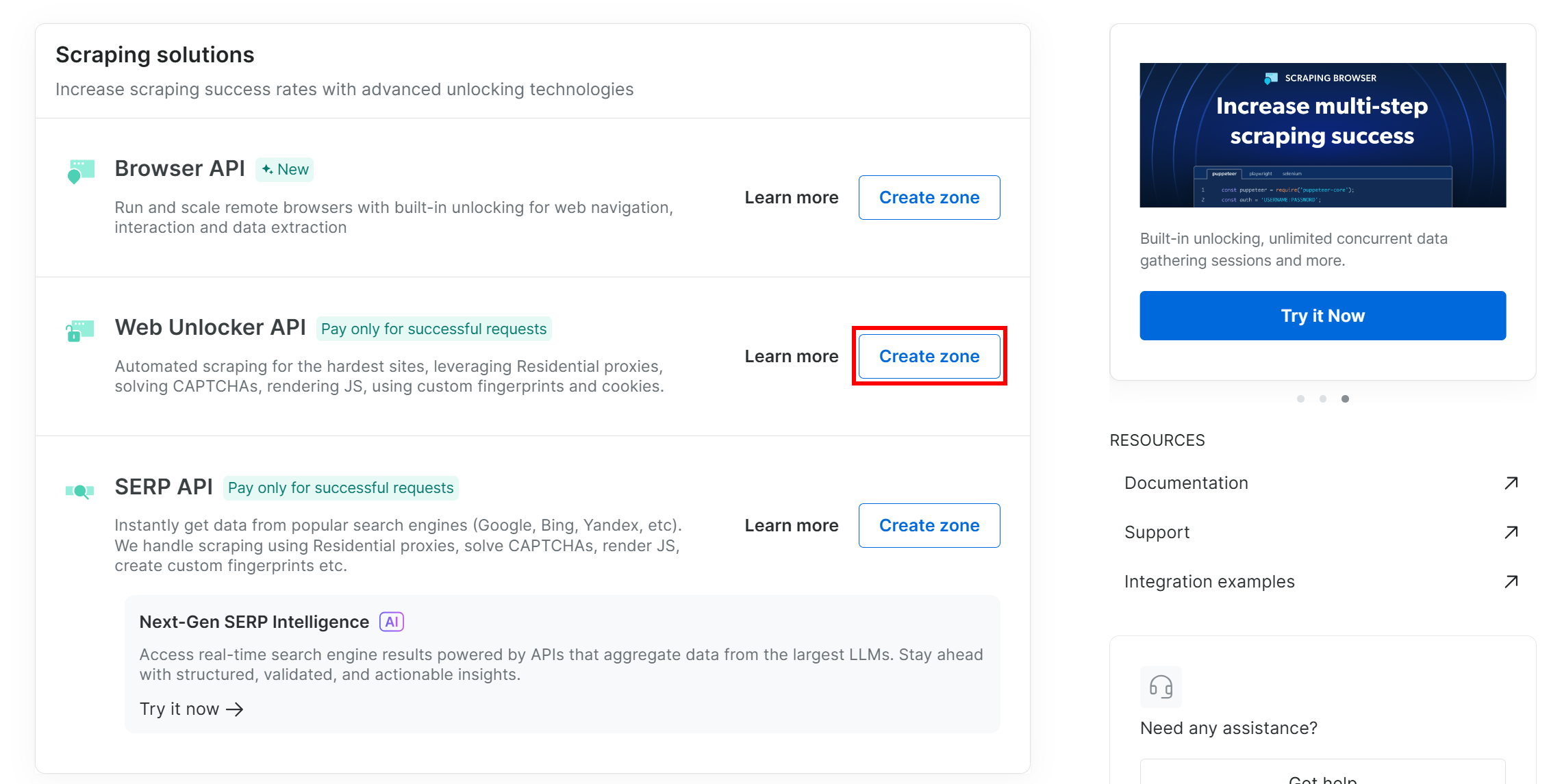
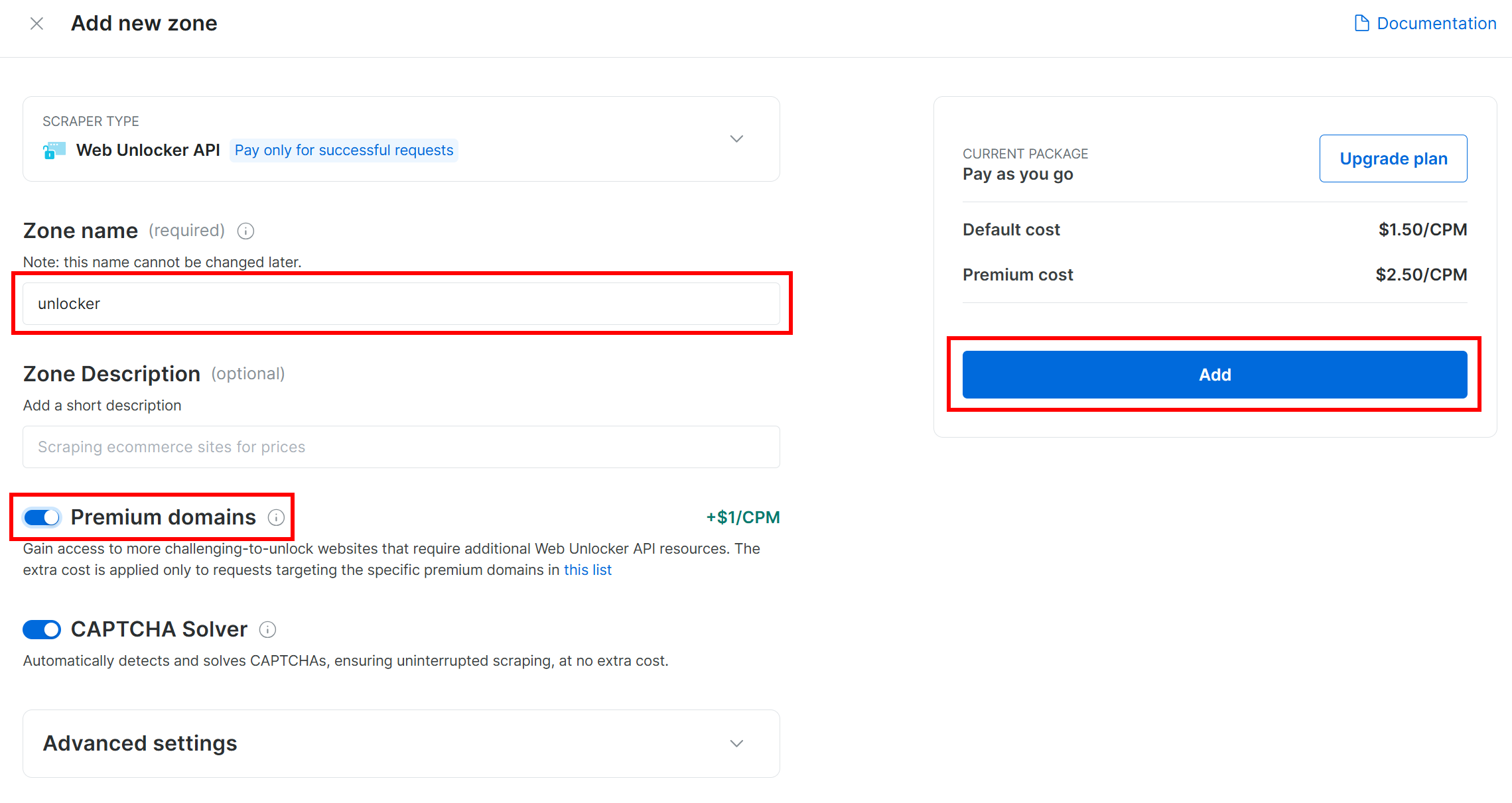
Дайте своей зоне имя (например, “разблокировщик”), включите дополнительные функции для лучшей производительности и нажмите кнопку “Добавить”:
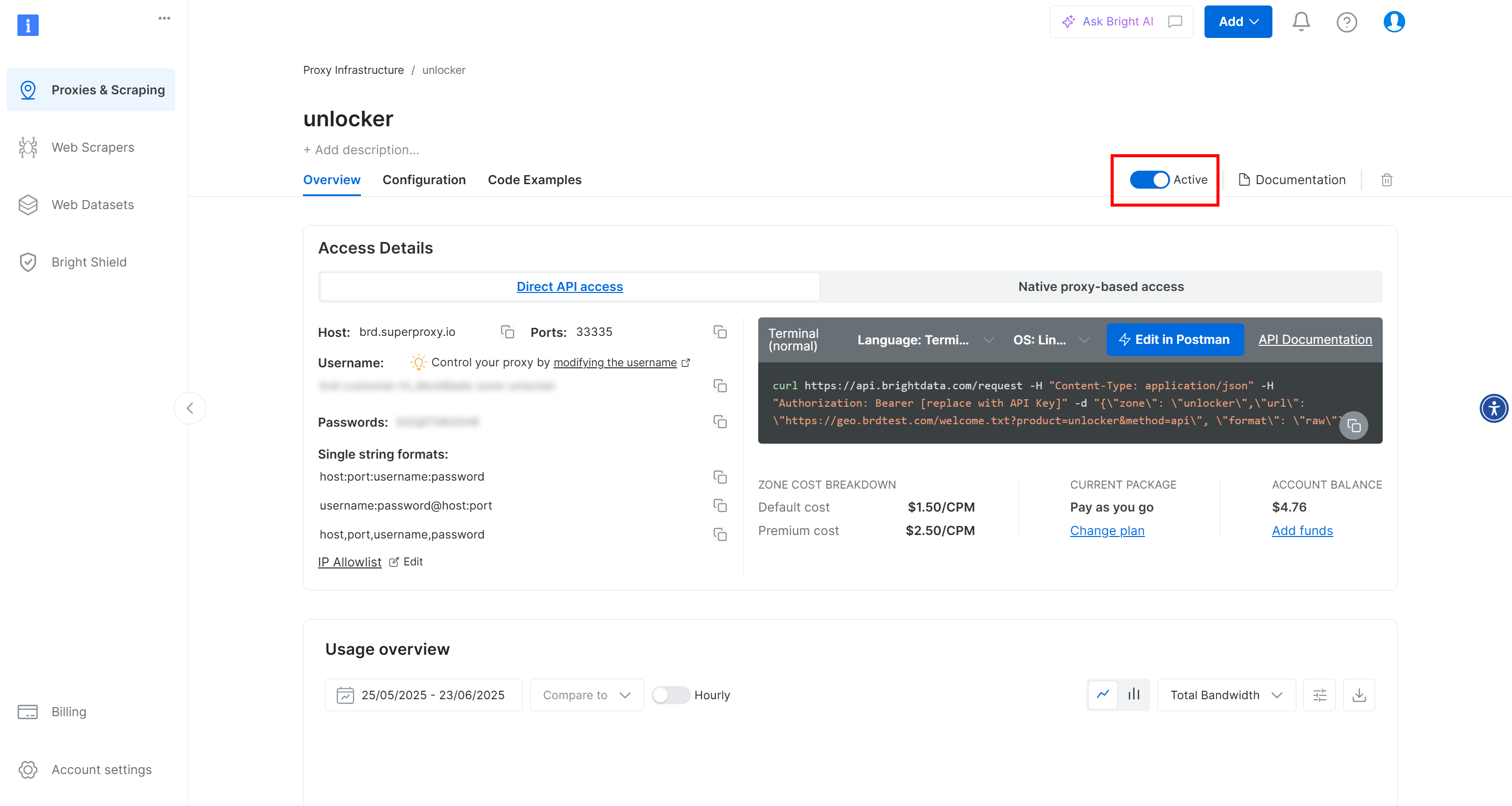
Вы попадете на страницу новой зоны. Убедитесь, что тумблер установлен в статус “Активно”, что подтверждает готовность продукта к использованию:
Теперь следуйте официальной документации Bright Data, чтобы сгенерировать ключ API. Как только он будет получен, добавьте его в файл .env следующим образом:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Замените на фактическое значение ключа API.
Отлично! Пора интегрировать инструменты Bright Data в сценарий агента Agno для агентурного веб-скрапинга.
Шаг №4: Интеграция инструментов Agno Bright Data Tools для веб-скрапинга
В папке проекта с активированной виртуальной средой установите Agno, выполнив команду:
pip install agnoПомните, что пакет agno уже включает встроенную поддержку инструментов Bright Data. Поэтому вам не нужны дополнительные пакеты для интеграции.
Единственный необходимый дополнительный пакет – библиотека Python Requests, которая используется инструментами Bright Data для вызова продуктов, настроенных вами ранее, через API. Установите requests с помощью:
pip install requestsВ файле scraper.py импортируйте инструменты для скраппинга Bright Data из agno:
from agno.tools.brightdata import BrightDataToolsЗатем инициализируйте инструменты следующим образом:
bright_data_tools = BrightDataTools(
web_unlocker_zone="unlocker", # Replace with your Web Unlocker API zone name
search_engine=False,
)Замените "unlocker" на фактическое имя вашей зоны Bright Data Web Unlocker.
Также обратите внимание, что для параметра search_engine установлено значение False, поскольку в данном примере мы не используем инструмент SERP API, который ориентирован исключительно на веб-скраппинг.
Совет: Вместо жесткого кодирования имен зон вы можете загрузить их из файла .env. Для этого добавьте эту строку в файл .env:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"Замените заполнитель на реальное имя зоны Web Unlocker. Затем вы можете удалить аргумент web_unlocker_zone из BrightDataTools. Класс автоматически подберет имя зоны из вашего окружения.
Примечание: Чтобы подключиться к Bright Data, BrightDataTools ищет ваш ключ API в переменной окружения BRIGHT_DATA_API_KEY. Именно поэтому мы добавили ее в файл .env в предыдущем шаге.
Потрясающе! Интегрируйте Gemini в свой агентурный рабочий процесс Agno, связанный с веб-скреппингом.
Шаг #5: Настройте модель LLM из Gemini
Пора подключиться к Gemini, провайдеру LLM, выбранному в этом руководстве. Начните с установки пакета google-genai:
pip install google-genaiЗатем импортируйте класс интеграции Gemini из Agno:
from agno.models.google import GeminiТеперь инициализируйте вашу модель LLM следующим образом:
llm_model = Gemini(id="gemini-2.5-flash")В приведенном выше фрагменте gemini-2.5-flash – это имя модели Gemini, которую вы хотите, чтобы использовал ваш агент. Не стесняйтесь заменить его на любую другую поддерживаемую модель Gemini (только имейте в виду, что некоторые из них не могут свободно использоваться через API).
Под капотом библиотека google-genai ожидает, что ваш ключ API Gemini будет храниться в переменной окружения GOOGLE_API_KEY. Чтобы настроить ее, добавьте следующую строку в ваш файл .env:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Замените на ваш реальный API-ключ. Если у вас его еще нет, следуйте официальному руководству по генерации API-ключа Gemini.
Примечание: Если вы хотите подключиться к другому провайдеру LLM, ознакомьтесь с инструкциями по настройке в официальной документации.
Фантастика! Теперь у вас есть все основные компоненты, необходимые для создания агента скрапинга Agno.
Шаг #6: Определите агента для скрапирования
В файле scraper.py настройте агента скрапинга Agno следующим образом:
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)Это создает объект Agno Agent, который использует настроенный LLM для обработки запросов и использует инструменты Bright Data для веб-скреппинга.
Не забудьте добавить этот импорт в начало файла:
from agno.agent import AgentПотрясающе! Осталось только отправить запрос своему агенту и экспортировать полученные данные.
Шаг #7: Запросите агента для скрапирования Agno
Прочитайте запрос из CLI и передайте его для выполнения агенту скраппинга Agno:
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)В первой строке используется встроенная в Python функция input() для чтения запроса, введенного пользователем. Подсказка должна описывать задачу или вопрос, который вы хотите, чтобы агент выполнил. Вторая строка [вызывает run()] на агенте для обработки запроса и выполнения задачи](https://docs.agno.com/agents/run#running-your-agent).
Чтобы отобразить ответ в красивом формате в терминале, используйте:
pprint_run_response(response)Импортируйте эту вспомогательную функцию из Agno следующим образом:
from agno.utils.pprint import pprint_run_responsepprint_run_response печатает ответ агента ИИ. Но вы, вероятно, также хотите извлечь и сохранить необработанные данные, полученные с помощью инструмента Bright Data. Давайте разберемся с этим в следующем шаге!
Шаг № 8: Экспорт собранных данных
При запуске задачи скрапинга ваш агент Agno для веб-скрапинга вызывает настроенные инструменты Bright Data за кулисами. Убедившись, что ваш скрипт экспортирует необработанные данные, возвращаемые этими инструментами, вы получаете много полезного для своего рабочего процесса. Причина в том, что вы можете использовать эти данные в других сценариях (например, для анализа данных) или в дополнительных сценариях использования агента.
В настоящее время ваш агент по скраппингу имеет доступ к этим двум инструментальным методам из BrightDataTools:
scrape_as_markdown(): Соскребает любую веб-страницу и возвращает ее содержимое в формате Markdown.web_data_feed(): Получает структурированные JSON-данные с таких популярных сайтов, как LinkedIn, Amazon, Instagram и других.
Таким образом, в зависимости от задачи, полученные данные могут быть представлены в формате Markdown или JSON. Чтобы справиться с обоими случаями, вы можете прочитать необработанный вывод из результата работы инструмента по адресу response.tools[0].result. Затем попытайтесь разобрать его как JSON. Если это не удастся, вы будете рассматривать полученные данные как Markdown.
Реализуйте описанную выше логику с помощью следующих строк кода:
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data) Не забудьте импортировать json из стандартной библиотеки Python:
import jsonОтлично! Ваш рабочий процесс с агентом веб-скреппинга Agno завершен.
Шаг № 9: Соберите все вместе
Это финальный код вашего файла scraper.py:
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.google import Gemini
from agno.agent import Agent
from agno.utils.pprint import pprint_run_response
import json
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
web_unlocker_zone="web_unlocker", # Replace with your Web Unlocker API zone name
search_engine=False, # As the SERP API tool is not required in this use case
)
# The LLM that will be used by the AI scraping agent
llm_model = Gemini(id="gemini-2.5-flash")
# Define your Agno agent with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)
# Print the agent response in the terminal
pprint_run_response(response)
# Export the scraped data
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data)Менее чем за 50 строк кода вы создали управляемый искусственным интеллектом рабочий процесс скраппинга, который может извлекать данные с любой веб-страницы. Такова сила сочетания Bright Data и Agno для разработки агентов!
Шаг #10: Запустите агент для скрапирования Agno
В терминале запустите агента веб-скреппинга Agno, выполнив команду:
python scraper.pyВам будет предложено ввести запрос. Попробуйте что-нибудь вроде:
Give me a short summary from "https://www.reuters.com/sports/formula1/hulkenberg-rids-himself-unwanted-record-239th-attempt-2025-07-06/"Вы должны увидеть вывод, похожий на этот:
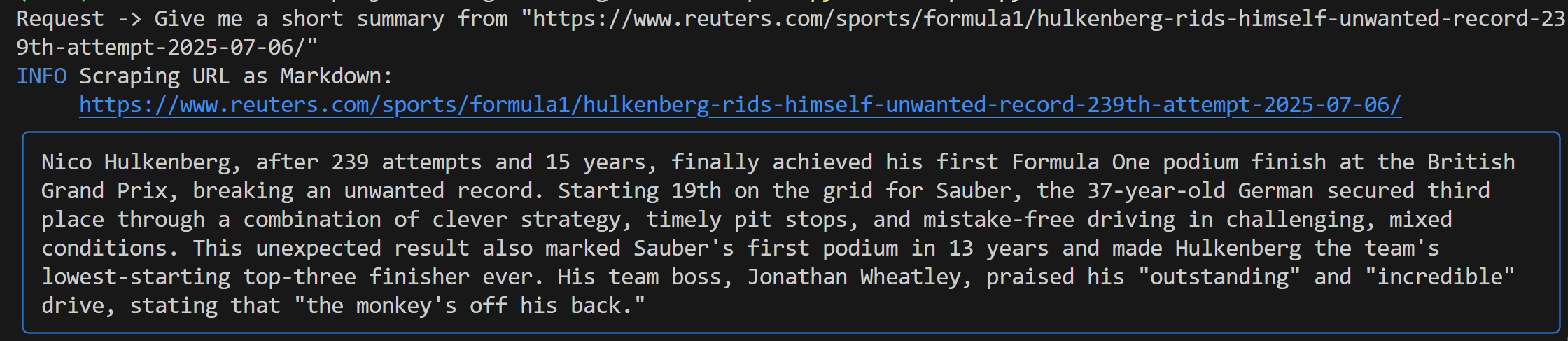
Этот выход включает в себя:
- Оригинальная подсказка, которую вы отправили.
- Журнал, показывающий, какой инструмент Bright Data использовался для соскабливания. В данном случае подтверждается, что была вызвана функция
scrape_as_markdown(). - Резюме в формате Markdown, созданное Gemini, выделенное синим прямоугольником.
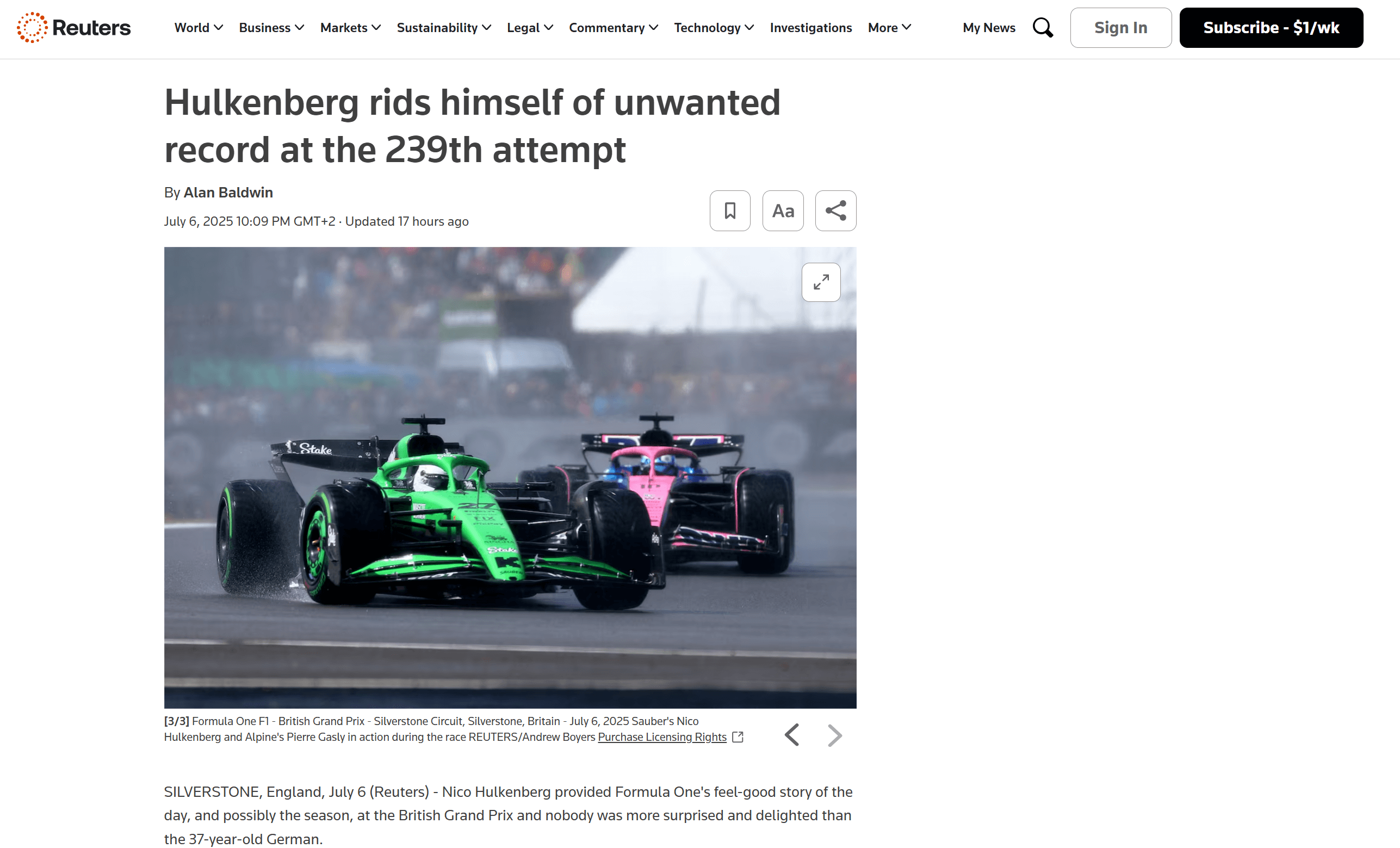
Если вы заглянете в корневую папку вашего проекта, то увидите новый файл с именем output.md. Откройте его в любой программе просмотра Markdown, и вы получите Markdown-версию содержимого отсканированной страницы:

Как вы можете видеть, вывод в формате Markdown от Bright Data точно передает содержимое исходной веб-страницы:
Теперь попробуйте снова запустить агента для скраппинга с другим, более конкретным запросом:
Summarize the main features of the product on this Amazon page: "https://www.amazon.com/PlayStation%C2%AE5-console-slim-PlayStation-5/dp/B0CL61F39H/" На этот раз вывод может выглядеть следующим образом:
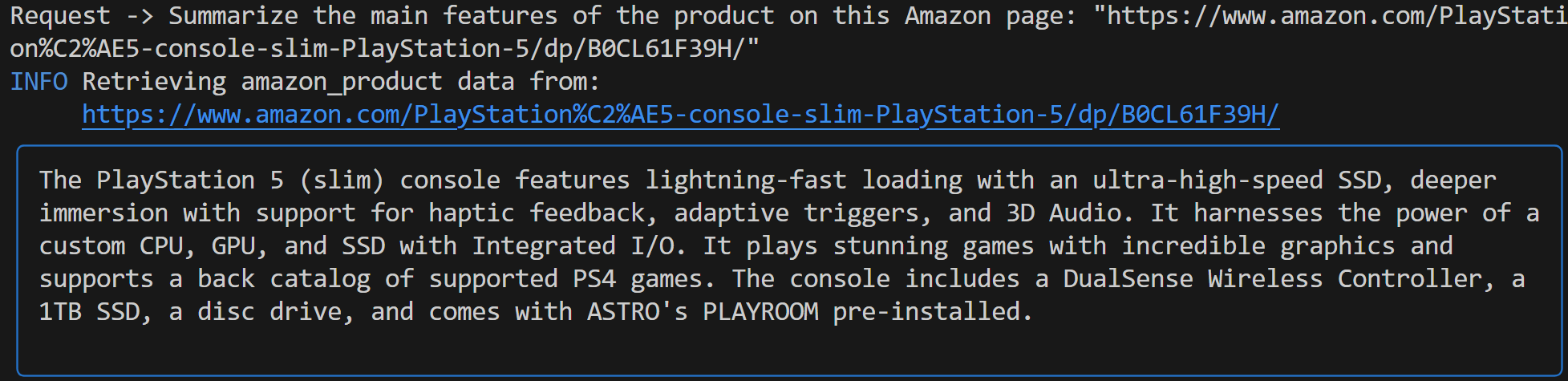
Обратите внимание, что агент Agno на базе Gemini автоматически выбрал инструмент web_data_feed, который правильно настроен для структурированного соскабливания страниц товаров Amazon.
В результате в папке проекта появится файл output.json. Откройте его и вставьте его содержимое в любую программу просмотра JSON:
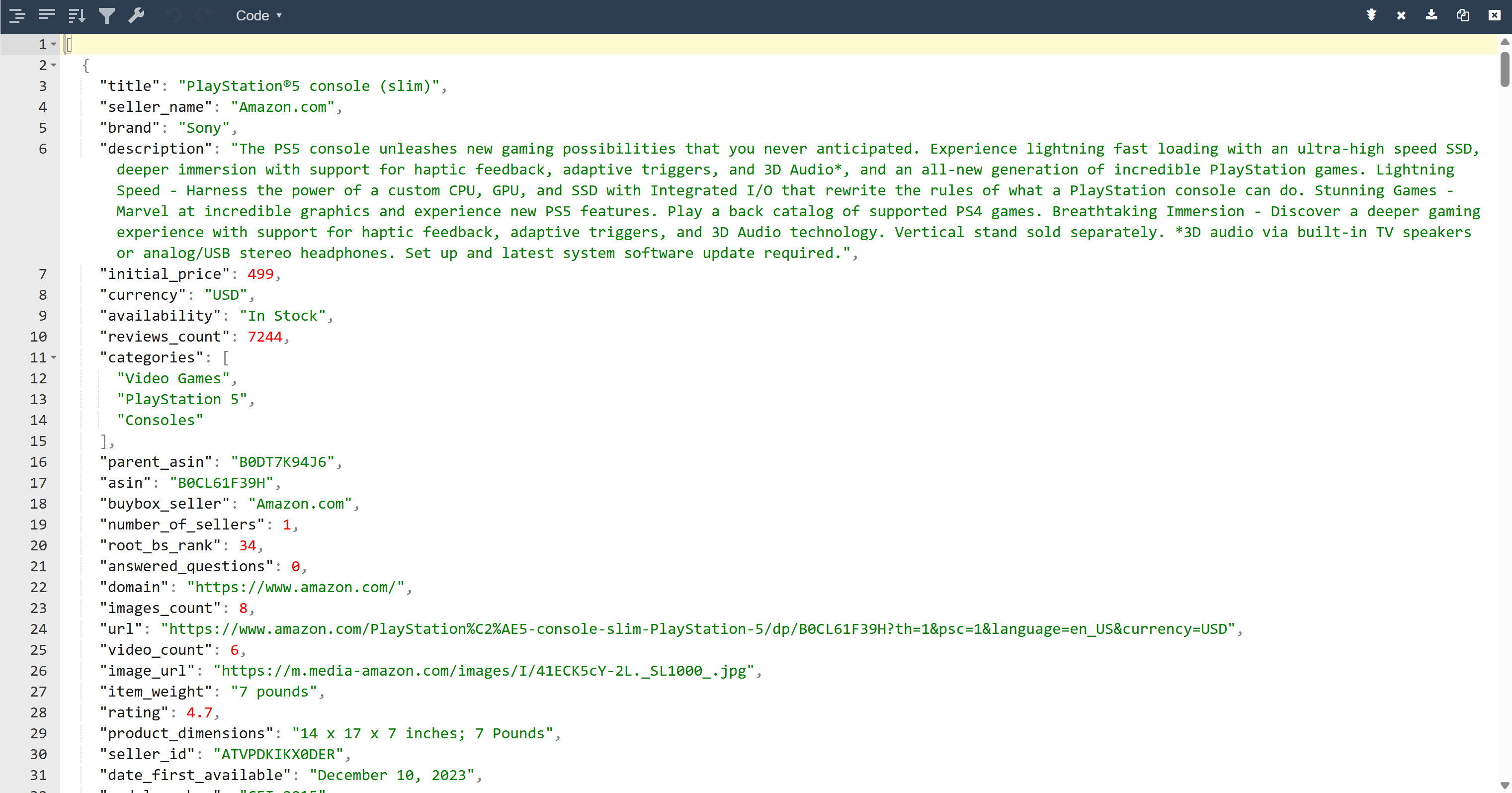
Посмотрите, как аккуратно инструмент Bright Data извлек структурированные JSON-данные со страницы Amazon:
Оба примера показывают, что ваш агент может получить данные практически с любой веб-страницы. Это справедливо даже для таких сложных сайтов, как Amazon, которые известны своей жесткой защитой от скаппинга (например, пресловутая Amazon CAPTCHA).
И вуаля! Вы только что испытали бесшовный веб-скраппинг в своем агенте искусственного интеллекта, работающем на основе инструментов Bright Data и Agno.
Следующие шаги
Веб-скребок, который вы только что создали с помощью Agno, – это только начало. Дальше вы можете изучить несколько способов расширения и улучшения вашего проекта:
- Включите слой памяти: Используйте собственную векторную базу данных Agno для хранения данных, которые агент собирает с помощью Bright Data. Это обеспечит агенту долговременную память, что откроет путь к расширенным возможностям использования, таким как агентский RAG.
- Создайте удобный интерфейс: Создайте простой веб- или настольный пользовательский интерфейс, чтобы пользователи могли общаться с вашим агентом в естественной, разговорной манере (подобно взаимодействию с ChatGPT или Gemini). Это сделает ваш инструмент для скраппинга гораздо более доступным.
- Изучите более богатые возможности интеграции: Agno предлагает множество инструментов и возможностей, которые могут расширить возможности вашего агента, выйдя за рамки поиска. Погрузитесь в документацию Agno, чтобы узнать, как подключить больше источников данных, использовать различные LLM или организовать многоэтапные рабочие процессы агента.
Заключение
В этой статье вы узнали, как использовать Agno для создания агента искусственного интеллекта для веб-скрапинга. Это стало возможным благодаря встроенной интеграции Agno с инструментами Bright Data. С их помощью выбранный LLM может извлекать данные с любого веб-сайта.
Помните, что это был лишь простой пример. Если вы хотите разработать более сложные агенты, вам понадобятся решения для получения, проверки и преобразования живых веб-данных. Именно это вы найдете в инфраструктуре Bright Data AI.
Создайте бесплатную учетную запись Bright Data и начните экспериментировать с нашими инструментами для сбора информации с помощью искусственного интеллекта!




