

В этой статье мы рассмотрим:
- Что такое сервер Playwright MCP и как его можно использовать для веб-скрапинга
- Различные инструменты, доступные в сервере Playwright MCP
- Как MCP-сервер Bright Data Web может стать более простой альтернативой для веб-скрапинга.
Давайте погрузимся!
MCP-сервер Playwright
Playwright широко известен как инструмент автоматизации браузера, часто используемый для тестирования и автоматизации задач браузера. Сервер Playwright MCP Server развивает эту функциональность, только на этот раз он предназначен не для непосредственного использования человеком, а для агентов искусственного интеллекта.
Запустив сервер, вы можете подключить любой MCP-хост и предоставить агентам ИИ доступ к полному набору инструментов автоматизации Playwright.
Это означает, что ваш ИИ-агент может взаимодействовать с веб-браузером так же, как и человек, выполняя такие действия, как совершение онлайн-покупок, поиск последних новостей, ответы на электронные письма и многое другое.
В этой статье мы сосредоточимся на веб-скреппинге. С помощью сервера Playwright MCP Server вы получаете низкоуровневые инструменты, необходимые не только для автоматизации браузера, но и для того, чтобы позволить LLM скрести и извлекать данные непосредственно из Интернета.
Сервер Playwright MCP
Как и любой MCP-сервер, MCP-сервер Playwright поставляется с набором инструментов, которые могут быть открыты для агента ИИ. Эти инструменты напрямую связаны с API Playwright, которые разработчики уже знают и используют. Давайте рассмотрим некоторые из наиболее важных:
- Browser_click: Позволяет агенту ИИ нажимать на элементы, подобно человеку, использующему мышь.
- Browser_drag: Позволяет перетаскивать элементы.
- Browser_close: Закрывает экземпляр браузера.
- Browser_evaluate: Позволяет агенту ИИ выполнять код JavaScript непосредственно на странице.
- Browser_file_upload: Обработка загрузки файлов через браузер.
- Browser_fill_form: Заполнение форм на веб-странице.
- Browser_hover: Перемещает указатель мыши по элементам.
- Browser_navigate: Переход по любому URL-адресу.
- Browser_press_key: Имитирует нажатие клавиш, предоставляя агенту полный доступ к клавиатурному вводу.
Имея в своем распоряжении все эти инструменты, агент ИИ может легко перемещаться по сети и собирать данные. Давайте посмотрим, как это можно сделать.
Веб-скраппинг с помощью сервера Playwright MCP
В этом разделе мы выполним задачу веб-скрапинга с помощью сервера Playwright MCP. Наш агент искусственного интеллекта будет собирать последнюю информацию о ценах на модели iPhone 16. Чтобы не усложнять задачу, мы ограничимся одним источником: Best Buy.
Настройка сервера
Чтобы запустить сервер Playwright MCP, нам нужен MCP-хост. Вы можете использовать любой хост по своему выбору, например Claude Desktop, Cursor или Gemini CLI. В этой статье мы будем использовать VS Code.
MCP-сервер Playwright – это локальный MCP-сервер, реализованный на Node.js, поэтому прежде чем приступить к работе, убедитесь, что у вас установлен Node.
Чтобы настроить сервер, нам нужно добавить следующую конфигурацию на наш MCP-хост:
{
"servers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Эта конфигурация относится к тому, как настраиваются MCP-серверы в VS Code, хотя в других MCP-хостах она может немного отличаться. После завершения настройки наш агент ИИ получит доступ к инструментам, предоставляемым сервером. После этого мы можем приступить к скраппингу.
Скраппинг с помощью сервера MCP
Первым шагом будет переход на сайт BestBuy. Для этого мы просто дадим агенту AI команду открыть сайт, и он воспользуется инструментом Browser_navigate, чтобы перейти на него.
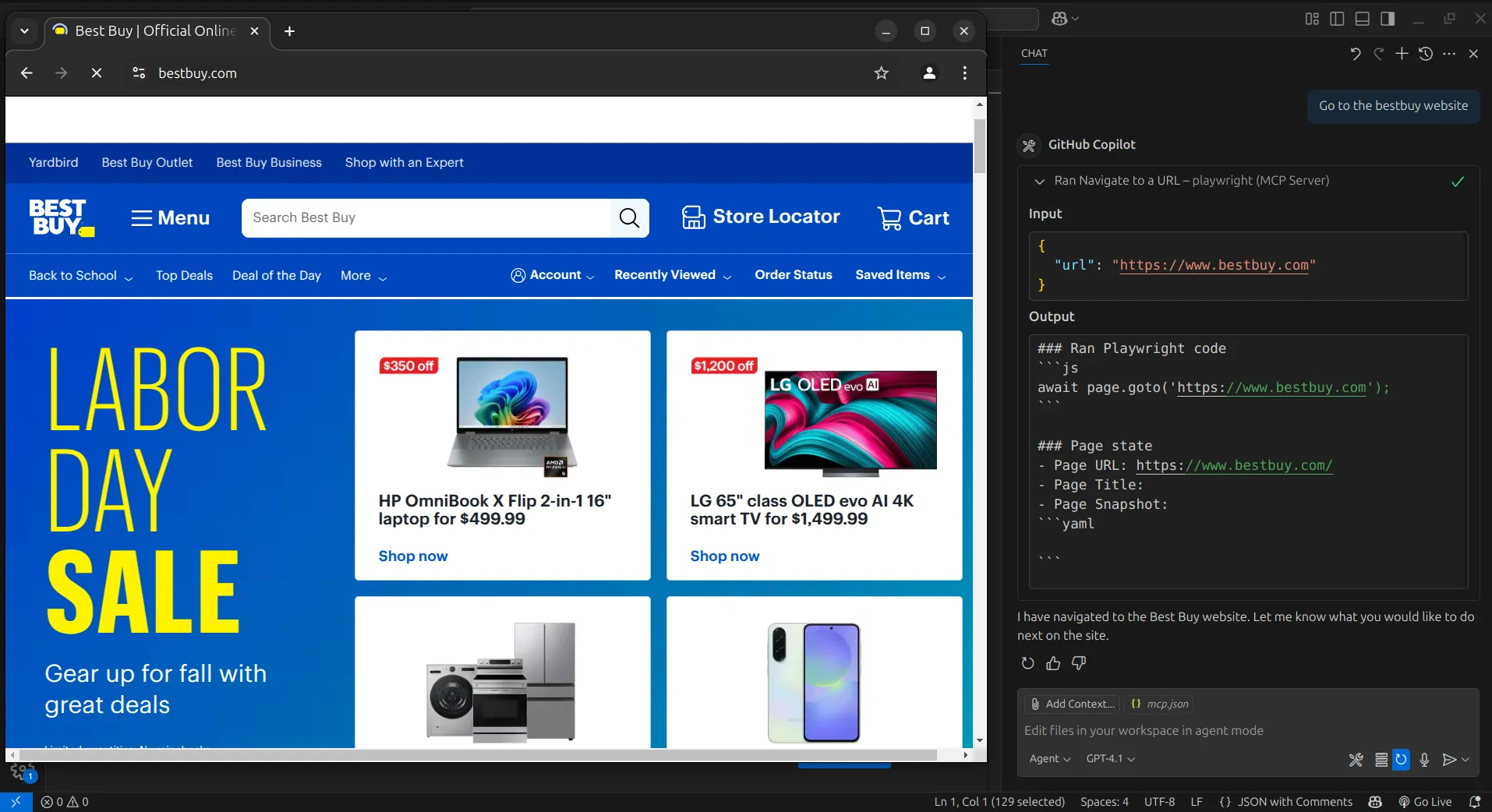
Далее мы поручим агенту ИИ выполнить поиск iPhone 16. Для этого он воспользуется инструментом Browser_press_key, чтобы ввести поисковый запрос.
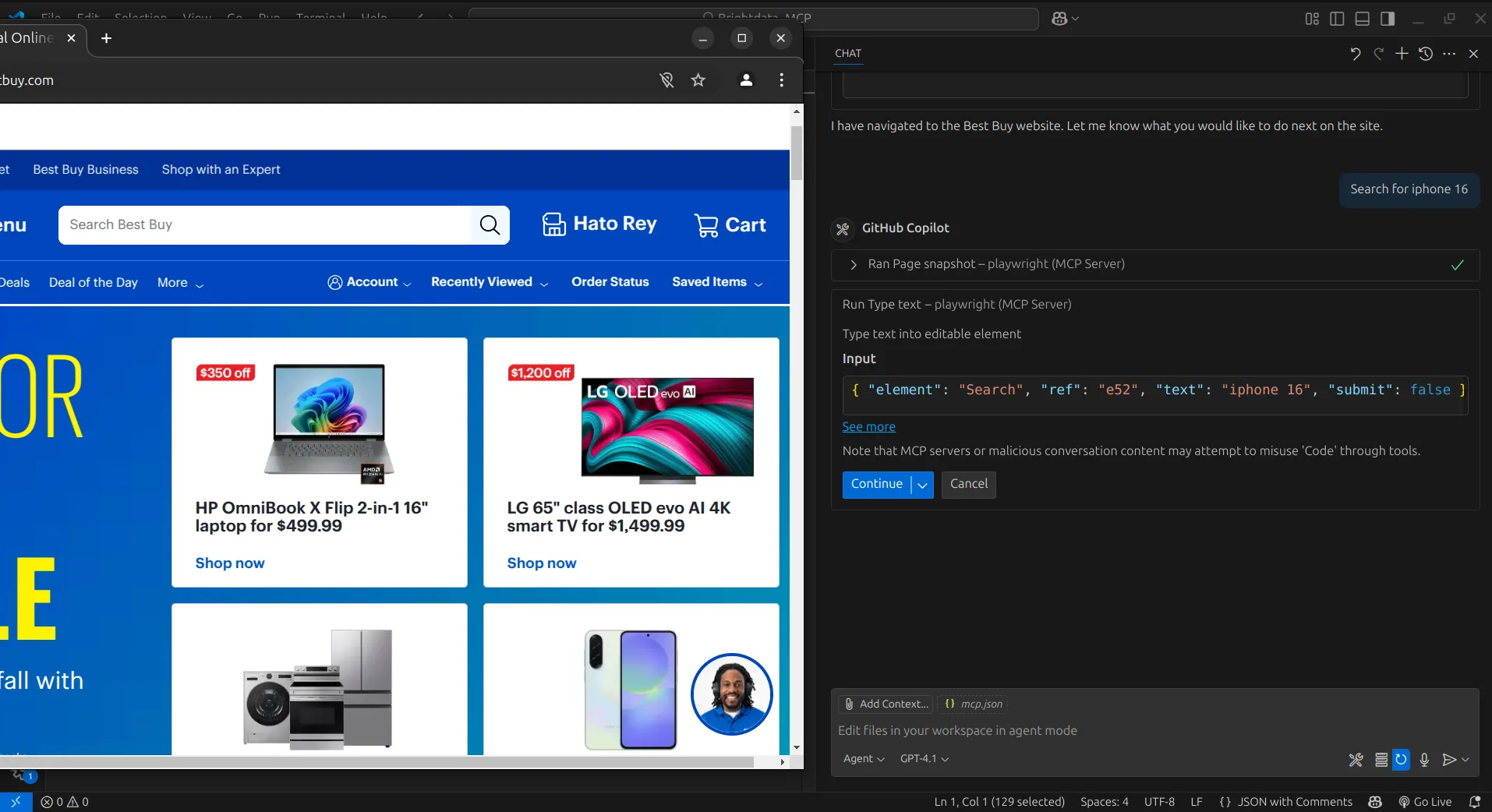
Затем агент ИИ воспользуется инструментом Browser_click, чтобы нажать на кнопку поиска.
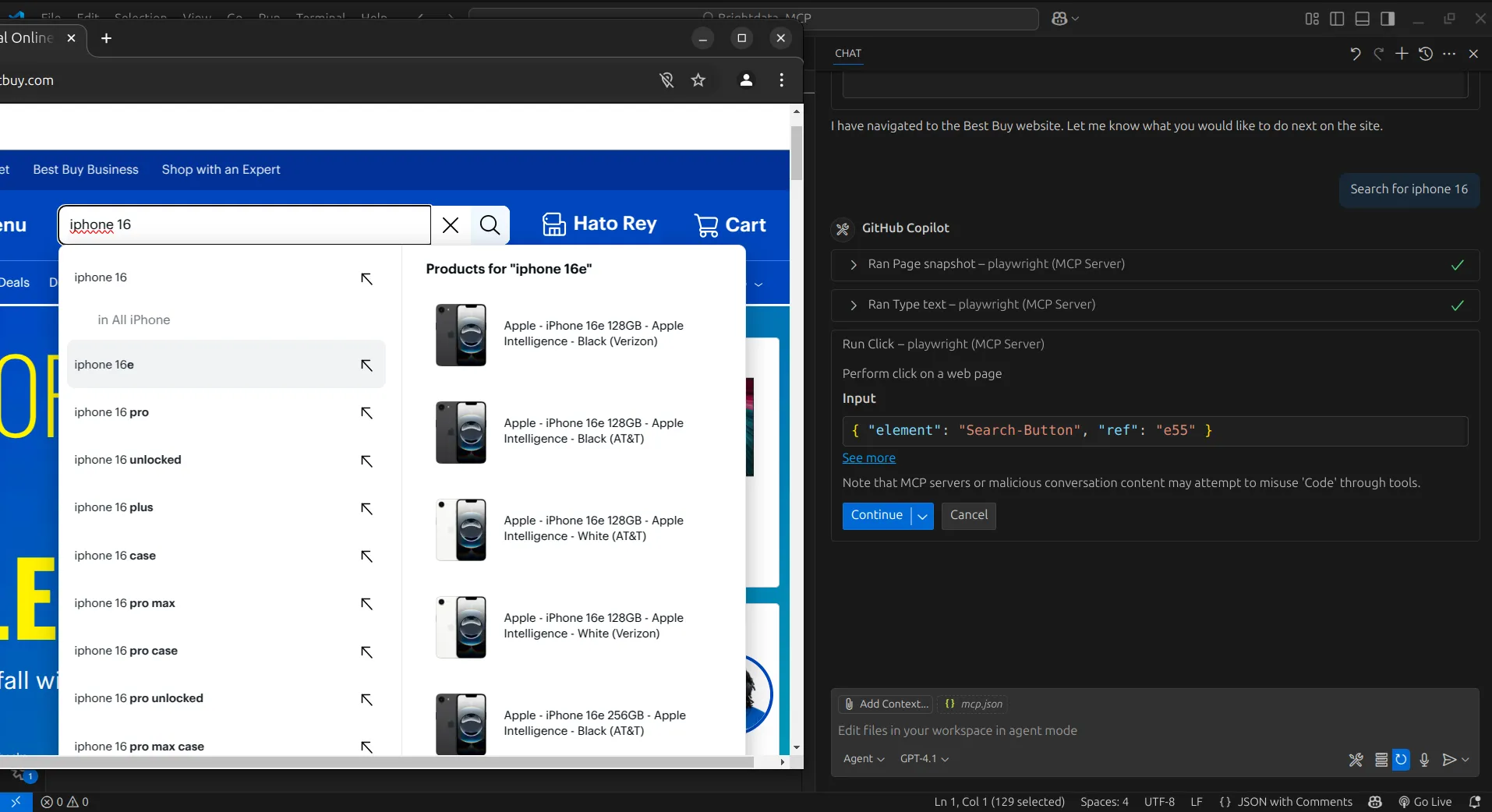
Таким образом, мы получаем результаты. На каждом шаге, когда агент перемещается по странице, он делает снимок текущего состояния. Затем мы можем использовать эти снимки, чтобы поручить агенту извлечь нужную нам информацию и организовать ее в структурированном формате.
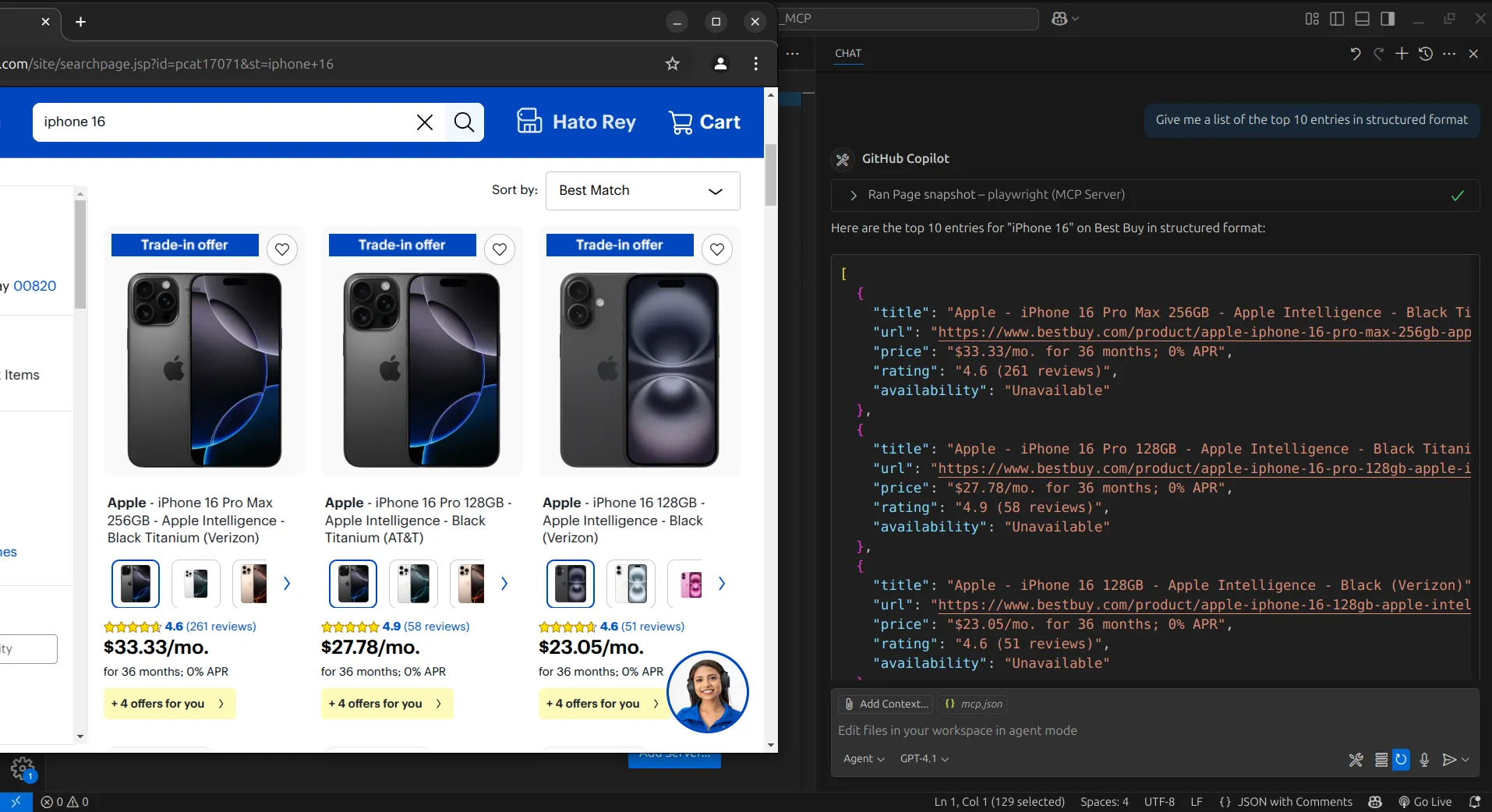
Благодаря такому подходу мы успешно отсканировали сайт. Однако, несмотря на то что он дает нам полный контроль, позволяющий делать практически все, что мы хотим, он все же довольно низкоуровневый. Это может показаться чрезмерным, если наша единственная цель – соскоб данных, поскольку нам могут не понадобиться более широкие возможности веб-автоматизации.
Далее рассмотрим, как сервер Bright Data Web MCP может решить ту же задачу с гораздо более высокой точки зрения.
Bright Data Web MCP Server: Высокоуровневый MCP-сервер для веб-скрепинга
MCP-сервер Bright Web Data поставляется с рядом высокоуровневых инструментов, созданных специально для веб-скрапинга. Среди них инструменты для извлечения данных с таких платформ, как Amazon, получения профилей отдельных людей и компаний и даже сбора профилей, постов и роликов Instagram.
В отличие от Playwright MCP, который работает на более низком уровне, сервер Bright Data Web MCP упрощает процесс сбора данных для вашего агента ИИ. Он даже обрабатывает веб-страницы, защищенные системой обнаружения ботов или CAPTCHA, предоставляя вашему агенту надежный доступ там, где традиционные методы могут не сработать.
В этом обзоре мы будем использовать сервер Bright Data Web MCP для выполнения той же задачи, которую мы решали ранее с помощью Playwright MCP. Из коробки он предоставляет два основных инструмента:
- Инструмент поисковой системы
- Инструмент для соскабливания данных в формате markdown.
Дополнительные инструменты можно разблокировать, включив режим Pro Mode, но пока мы остановимся на этих двух. Более подробную информацию вы можете найти в этой статье.
Настройка сервера
В отличие от MCP-сервера Playwright, который работает локально, MCP-сервер Bright Data Web является удаленным MCP-сервером. Это означает, что процесс настройки немного отличается. Вот как его можно настроить в VS Code:
"BrightData": {
"url": "https://mcp.brightdata.com/mcp?token=YOUR_API_KEY",
}Для подключения вам понадобится ключ API Bright Data. После настройки ваш агент готов приступить к скраппингу.
Скраппинг с помощью сервера MCP
Сначала мы поручим агенту выполнить веб-поиск по цене iPhone 16.
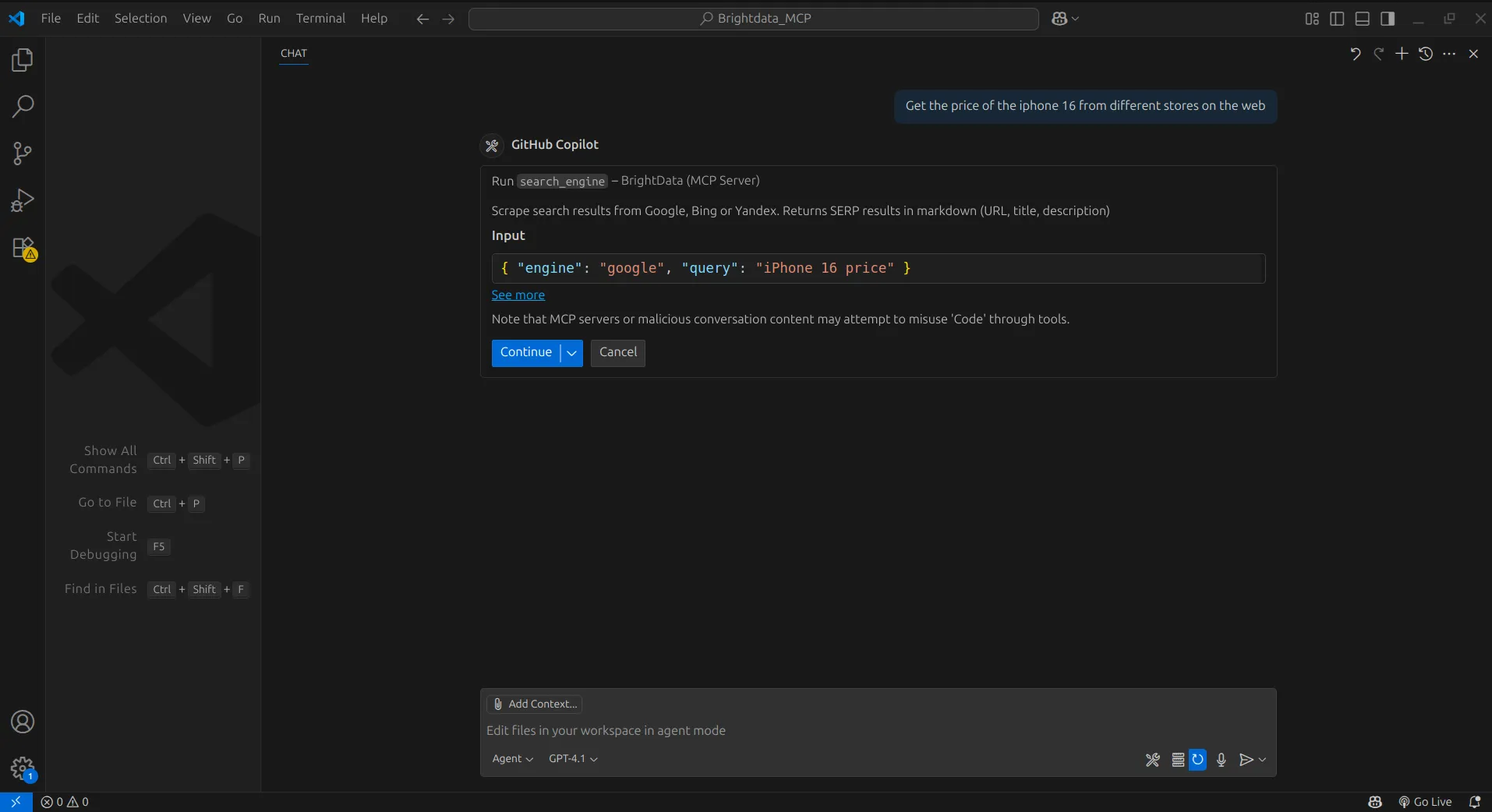
Для выполнения запроса агент использует инструмент поисковой системы сервера.
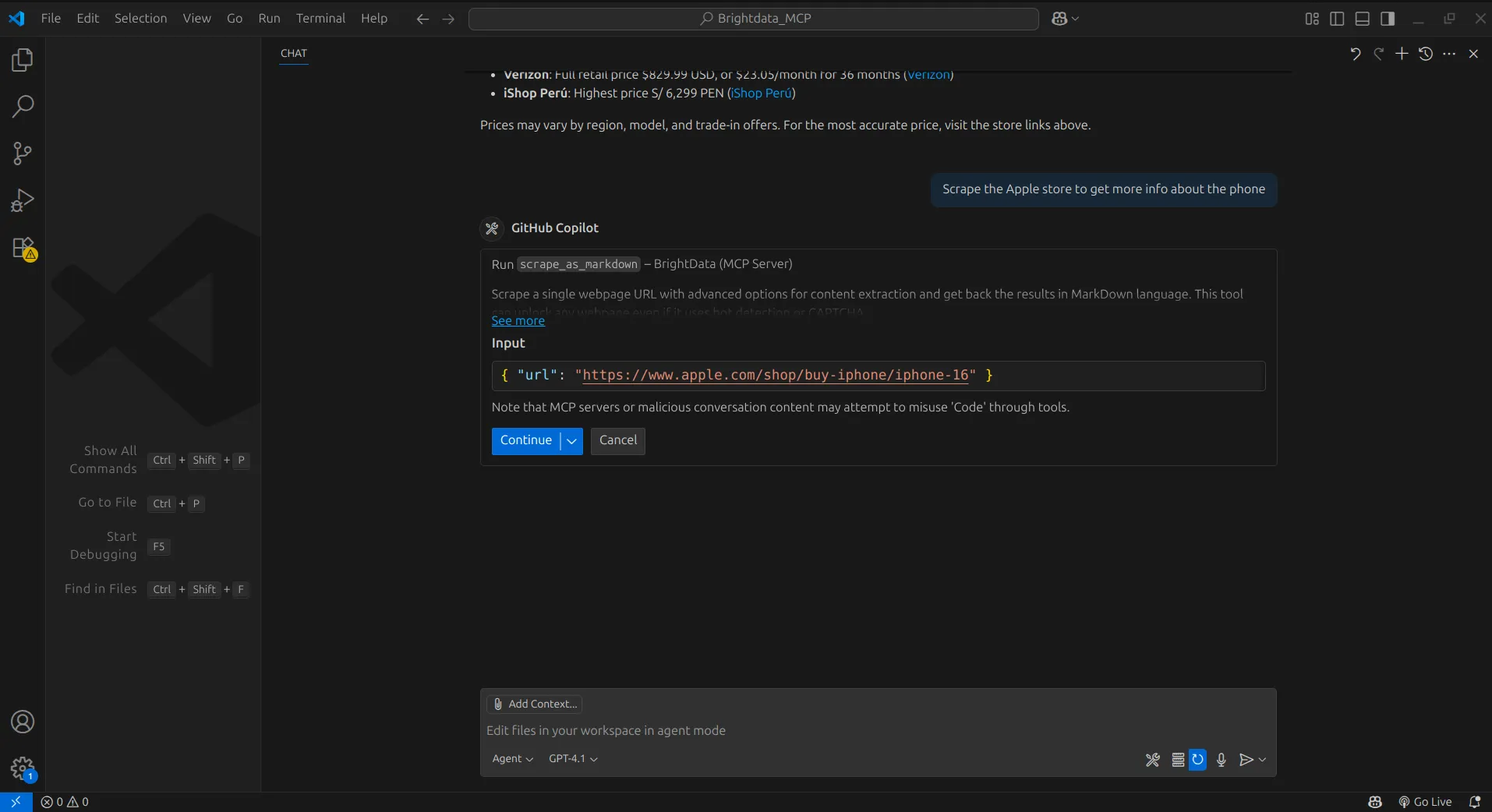
После получения результатов мы поручаем агенту извлечь информацию с выбранного нами сайта, в данном случае Apple Store. Затем агент использует инструмент scrape data as markdown для извлечения содержимого, возвращая его в формате Markdown, который агент может легко обработать и понять.
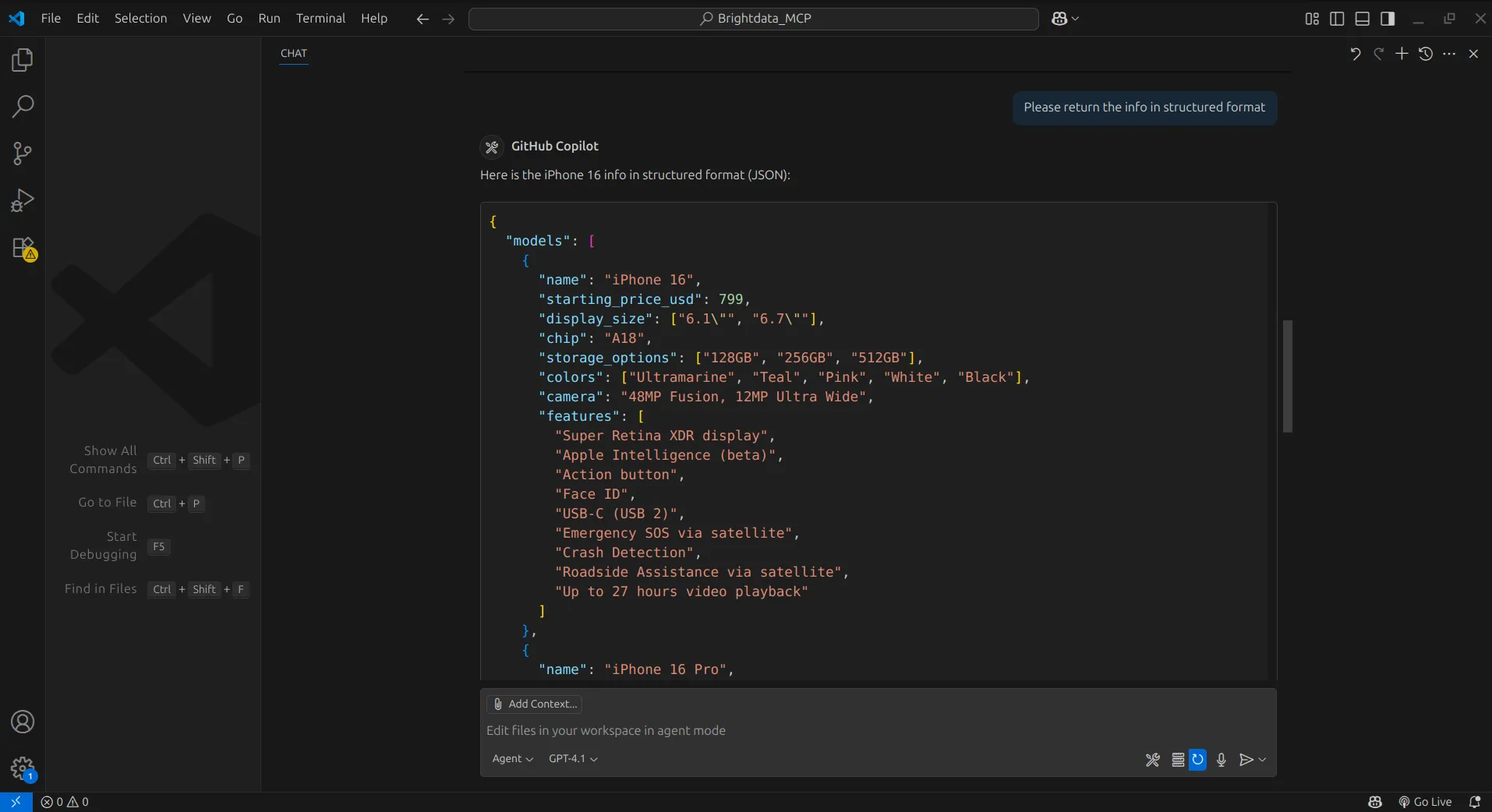
Извлеченную информацию мы можем поручить агенту организовать в структурированный формат, и вот у нас уже есть данные.
В этом примере мы использовали только два инструмента для выполнения задачи скрапинга. Однако сервер Bright Data Web MCP также предлагает дополнительные инструменты в режиме Pro Mode, которые вы можете использовать для более сложных случаев. Другие примеры вы можете найти в этой подробной статье.
Заключение
В этой статье мы рассмотрели, как MCP-серверы можно использовать для поиска информации в Интернете с помощью агентов искусственного интеллекта. Сначала мы рассмотрели MCP-сервер Playwright, который обеспечивает низкоуровневый доступ к автоматизации браузера, предоставляя агенту полный контроль над каждым взаимодействием. Затем мы рассмотрели MCP-сервер Web компании Bright Data, который работает на более высоком уровне и оснащает агента специализированными инструментами, разработанными специально для веб-скрапинга, даже на сайтах, защищенных от обнаружения ботов.
Оба подхода имеют свои сильные стороны: Playwright идеален, когда вам нужен тонкий контроль над браузером, а Bright Data упрощает процесс, позволяя сосредоточиться исключительно на извлечении нужной информации.
Теперь настала ваша очередь поэкспериментировать с обоими MCP-серверами и решить, какой из них лучше всего подойдет для вашего следующего проекта.




