
В этой статье вы узнаете:
- Что такое Ctush и почему он стал таким любимым CLI-приложением для помощи в кодировании с помощью ИИ.
- Как расширение его возможностей за счет веб-взаимодействия и извлечения данных делает его гораздо более эффективным.
- Как подключить Crush CLI к серверу Bright Data Web MCP для создания усовершенствованного агента кодирования ИИ.
Давайте погрузимся!
Что такое Crush?
Crush – это агент кодирования ИИ с открытым исходным кодом для вашего терминала. В частности, Crush CLI – это приложение CLI на базе Go, которое привносит помощь искусственного интеллекта непосредственно в вашу терминальную среду. Оно предлагает TUI(Terminal User Interface) для взаимодействия с несколькими LLM для помощи в кодировании, отладке и других задачах разработки.
В частности, именно это делает Crush особенным:
- Кроссплатформенность: Работает во всех основных терминалах macOS, Linux, Windows (PowerShell и WSL), FreeBSD, OpenBSD и NetBSD.
- Поддержка нескольких моделей: Выбирайте из широкого спектра LLM, интегрируйте свои собственные с помощью OpenAI- или Anthropic-совместимых API или подключайтесь к локальным моделям.
- Работа на основе сеансов: Поддерживайте несколько рабочих сессий и контекстов для каждого проекта.
- Высокая гибкость: Возможность переключения между LLM в середине сессии с сохранением контекста.
- LSP-ready: Crush поддерживаетпротоколы LSP(Language Server Protocols) для дополнительного контекста и интеллектуальных возможностей, как и современная IDE.
- Расширяемость: Поддержка интеграции со сторонними функциями через MCP(HTTP, stdio и SSE).
Проект уже набрал более 10 тысяч звезд на GitHub и активно поддерживается активным сообществом разработчиков, насчитывающим более 35 участников.
Преодоление пробела в знаниях LLM в Crush CLI с помощью Web MCP
Общей проблемой для всех LLM является наличие разрыва в знаниях. LLM, который вы настраиваете в Crush CLI, не является исключением. Поскольку эти модели обучаются на фиксированном наборе данных, их знания представляют собой статичный снимок прошлого. Это означает, что они не знают о последних событиях или разработках.
Это важный недостаток в быстро меняющемся мире технологий. Не имея обновленной базы знаний, LLM может предлагать устаревшие библиотеки, устаревшие методы программирования или просто не знать о новых функциях и инструментах.
А что, если бы ваш помощник по кодированию Crush AI умел не только вспоминать старую информацию? Представьте, что он может искать в Интернете самую свежую документацию, статьи и руководства, а затем использовать эти данные в режиме реального времени для предоставления более точной и качественной помощи.
Этого можно достичь, подключив Crush к решению, которое предоставляет LLM возможности доступа к Интернету и поиска данных. Именно это вы получите с помощью сервера Web MCP от Bright Data. Этот сервер с открытым исходным кодом(теперь с бесплатным уровнем!) оснащает вас 60+ инструментами для взаимодействия с Интернетом и сбора данных.
Интеграция Bright Data Web MCP
Ниже перечислены два основных инструмента, которые вы можете найти на этом MCP-сервере:
search_engine: Подключается к SERP API для выполнения поиска в Google, Bing или Yandex и возвращает данные страницы результатов поисковой системы в формате HTML или Markdown.scrape_as_markdown: Использует Web Unlocker для извлечения содержимого одной веб-страницы. Поддерживает расширенные опции извлечения, обходит системы обнаружения ботов и решает CAPTCHA за вас.
Помимо этих, существует 55+ специализированных инструментов для взаимодействия с веб-страницами (например, scraping_browser_click) и сбора структурированных данных с различных доменов, включая Amazon, LinkedIn и TikTok. Например, инструмент web_data_amazon_product может получить подробную структурированную информацию о продукте непосредственно с Amazon, используя URL-адрес продукта.
Учитывая наличие этих инструментов, вот некоторые способы использования Bright Data Web MCP с помощью Crush:
- Получение актуальной информации для своих проектов, например, цен на акции из Yahoo Finance или подробных сведений о товарах с сайтов электронной коммерции. Храните эти данные в локальных файлах для анализа, тестирования, подражания и т. д.
- Позвольте искусственному интеллекту получить последнюю документацию по используемой библиотеке или фреймворку, чтобы убедиться, что предлагаемый им код актуален и не устарел.
- Собирайте контекстно-зависимые ссылки и интегрируйте эти ресурсы в файлы Markdown, документацию или другие результаты – и все это не выходя из редактора кода.
Приготовьтесь узнать, как Web MCP может расширить возможности вашего агента Crush CLI!
Как подключить Crush к Web MCP от Bright Data
В этом руководстве вы узнаете, как установить и настроить Crush локально и интегрировать его с Web MCP Bright Data. В результате вы получите усовершенствованный агент кодирования AI, способный:
- Скрапировать страницу товара Amazon на лету.
- Хранить данные в локальном JSON-файле.
- Создавать сценарий Node.js для загрузки и обработки этих данных.
Следуйте инструкциям ниже!
Предварительные условия
Прежде чем приступить к работе, убедитесь, что у вас есть все необходимое:
- Node.js, установленный локально (рекомендуется последняя версия LTS).
- API-ключ от одного из поддерживаемых LLM-провайдеров (в этом руководстве мы будем использовать Google Gemini).
- Аккаунт Bright Data с готовым API-ключом (не волнуйтесь, если у вас его еще нет, вам помогут его создать).
Кроме того, необязательные, но полезные базовые знания:
- Общее понимание того, как работает MCP.
- Некоторое знакомство с сервером Bright Data Web MCP и его инструментами.
- Знание работы агентов кодирования CLI и того, как они могут взаимодействовать с вашей файловой системой.
Шаг № 1: Установка и настройка Crush
Установите Crush CLI глобально на вашу систему с помощью пакета @charmland/crush npm:
npm install -g @charmland/crushЕсли вы не хотите устанавливать CLI через npm, ознакомьтесь с другими вариантами установки.
Теперь вы можете запустить Crush с помощью:
crush .Вы должны увидеть экран выбора LLM, показанный ниже:
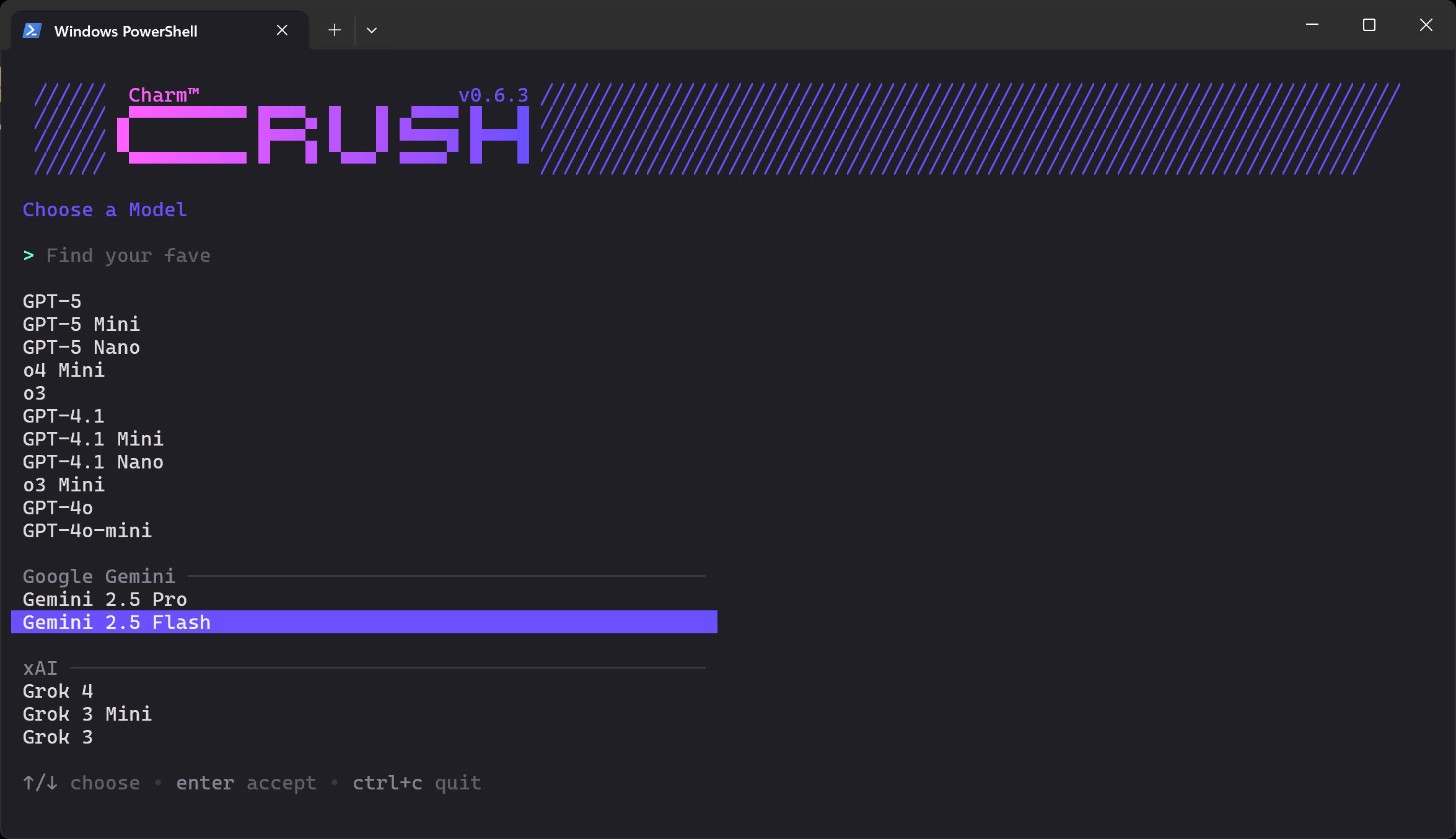
Существуют десятки провайдеров и сотни моделей на выбор. Используйте клавиши со стрелками для навигации, пока не найдете нужную вам модель у того провайдера, у которого у вас есть API-ключ. В данном примере мы выберем “Gemini 2.5 Flash” (которая по сути бесплатна для использования через API).
Далее вам будет предложено ввести свой API-ключ. Вставьте его и нажмите Enter:
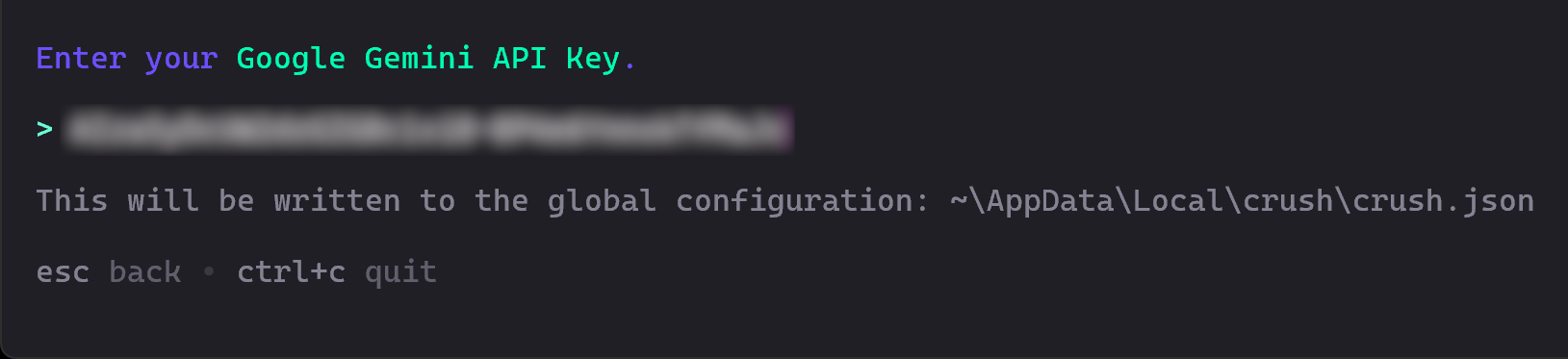
В данном случае вводим API-ключ Google Gemini, который можно бесплатно получить в Google Studio AI.
Затем Crush проверит ваш API-ключ, чтобы подтвердить его работоспособность.
После завершения проверки вы должны увидеть что-то вроде этого:
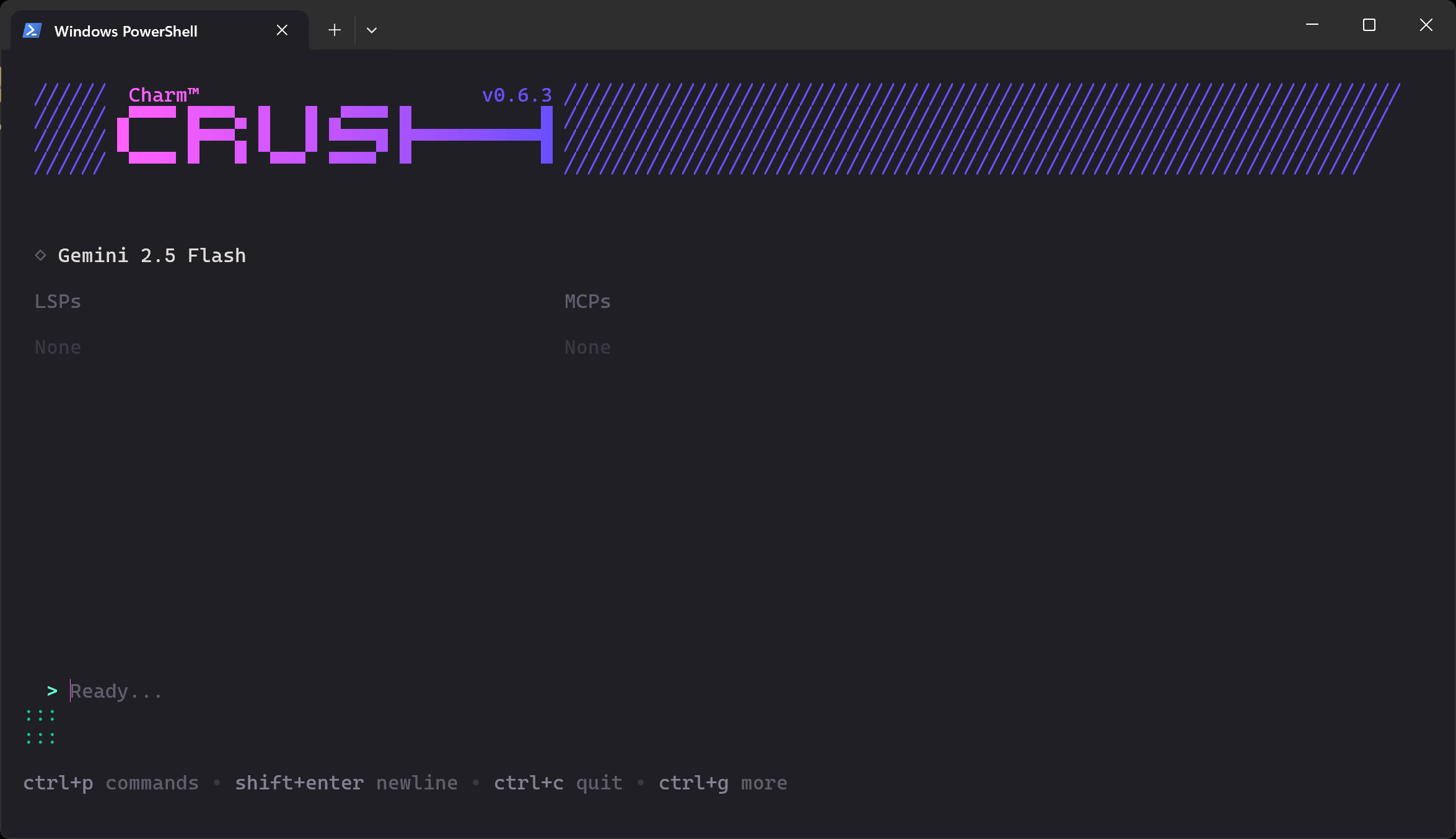
В разделе “Готов…” теперь можно ввести подсказку.
Примечание: Если вы снова запустите Crush CLI, вам не будет предложено установить LLM-соединение во второй раз. Это связано с тем, что настроенный вами ключ LLM автоматически сохраняется в глобальном конфиге $HOME/.config/crush/crush.json (или в Windows – %USERPROFILE%AppDataLocalcrushcrush.json).
Откройте глобальный файл конфигурации crush.json в Visual Studio Code (или вашей любимой IDE), чтобы просмотреть его:
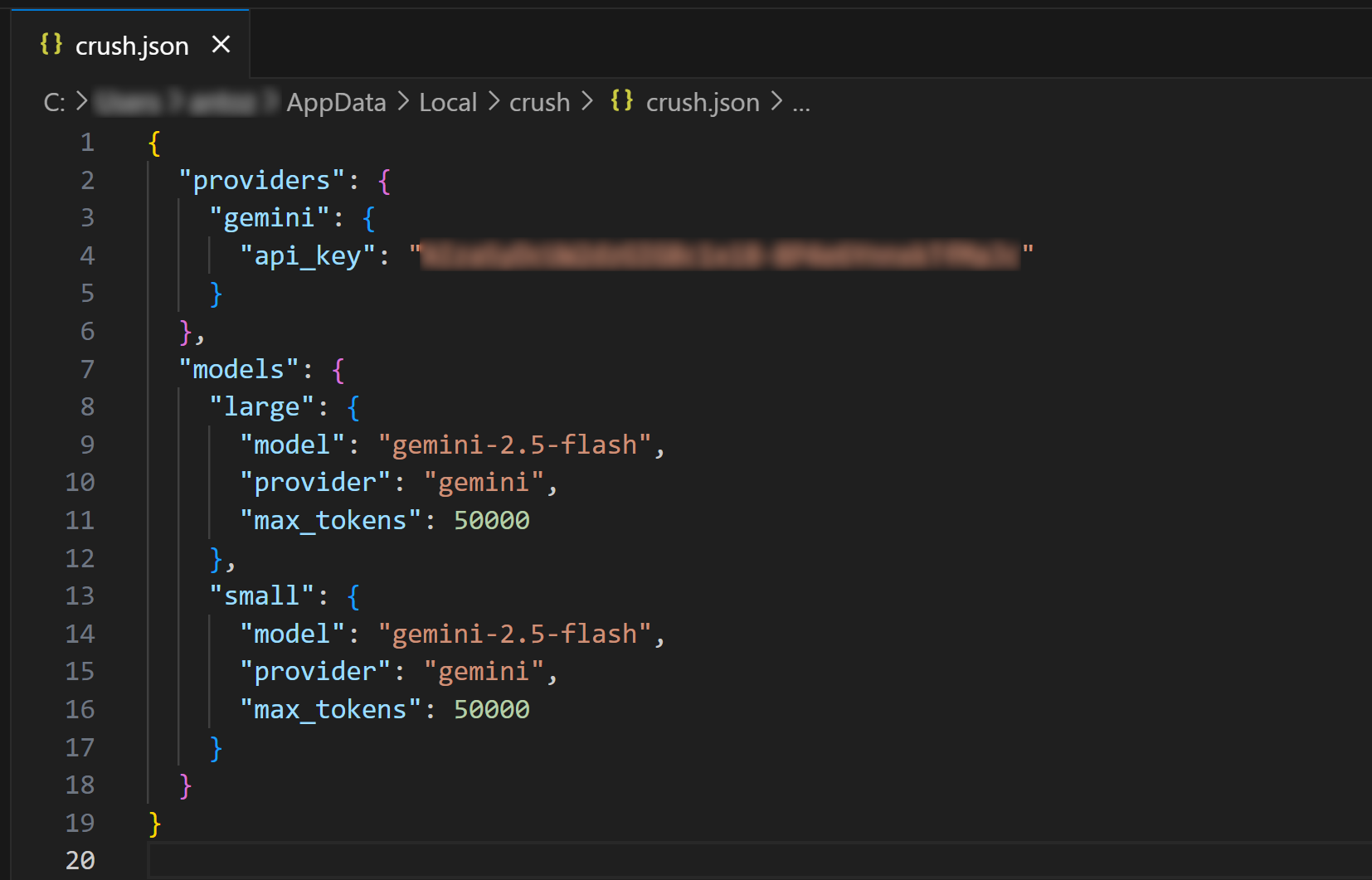
Как вы можете видеть, файл crush.json содержит ваш API-ключ и конфигурацию для выбранной модели. Он был заполнен Crush CLI, когда вы выбирали LLM. Вы также можете редактировать этот файл для настройки других моделей ИИ(даже локальных).
Аналогично, вы можете создать локальные файлы crush.json или .crush.json в каталоге вашего проекта, чтобы переопределить глобальную конфигурацию. Более подробную информацию можно найти в официальной документации.
Потрясающе! Crush CLI теперь установлен и работает в вашей системе.
Шаг № 2: Протестируйте Web MCP от Bright Data
Если у вас его еще нет, создайте учетную запись Bright Data. В противном случае просто войдите в существующую учетную запись.
Далее следуйте официальным инструкциям, чтобы сгенерировать свой ключ API Bright Data. Сохраните его в надежном месте, так как он вам скоро понадобится. Для простоты мы будем считать, что вы используете API-ключ с правами администратора.
Установите Web MCP глобально, используя пакет @brightdata/mcp с помощью:
npm install -g @brightdata/mcpЗатем проверьте, что сервер работает, с помощью этой команды Bash:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpИли, эквивалентно, в Windows PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpЗамените место <YOUR_BRIGHT_DATA_API> на фактический API-токен Bright Data, который вы сгенерировали ранее. Приведенные выше команды устанавливают необходимую переменную окружения API_TOKEN и запускают MCP-сервер через пакет @brightdata/mcp npm.
Если все работает правильно, вы должны увидеть такие журналы:

При первом запуске MCP-сервер автоматически создает две зоны в вашей учетной записи Bright Data:
mcp_unlocker: Зона для Web Unlocker.mcp_browser: Зона для Browser API.
Эти зоны необходимы для использования всего спектра инструментов сервера MCP.
Чтобы убедиться в том, что они созданы, войдите в панель управления Bright Data и перейдите на страницу “Proxies & Scraping Infrastructure“. Вы должны увидеть эти две зоны в списке:
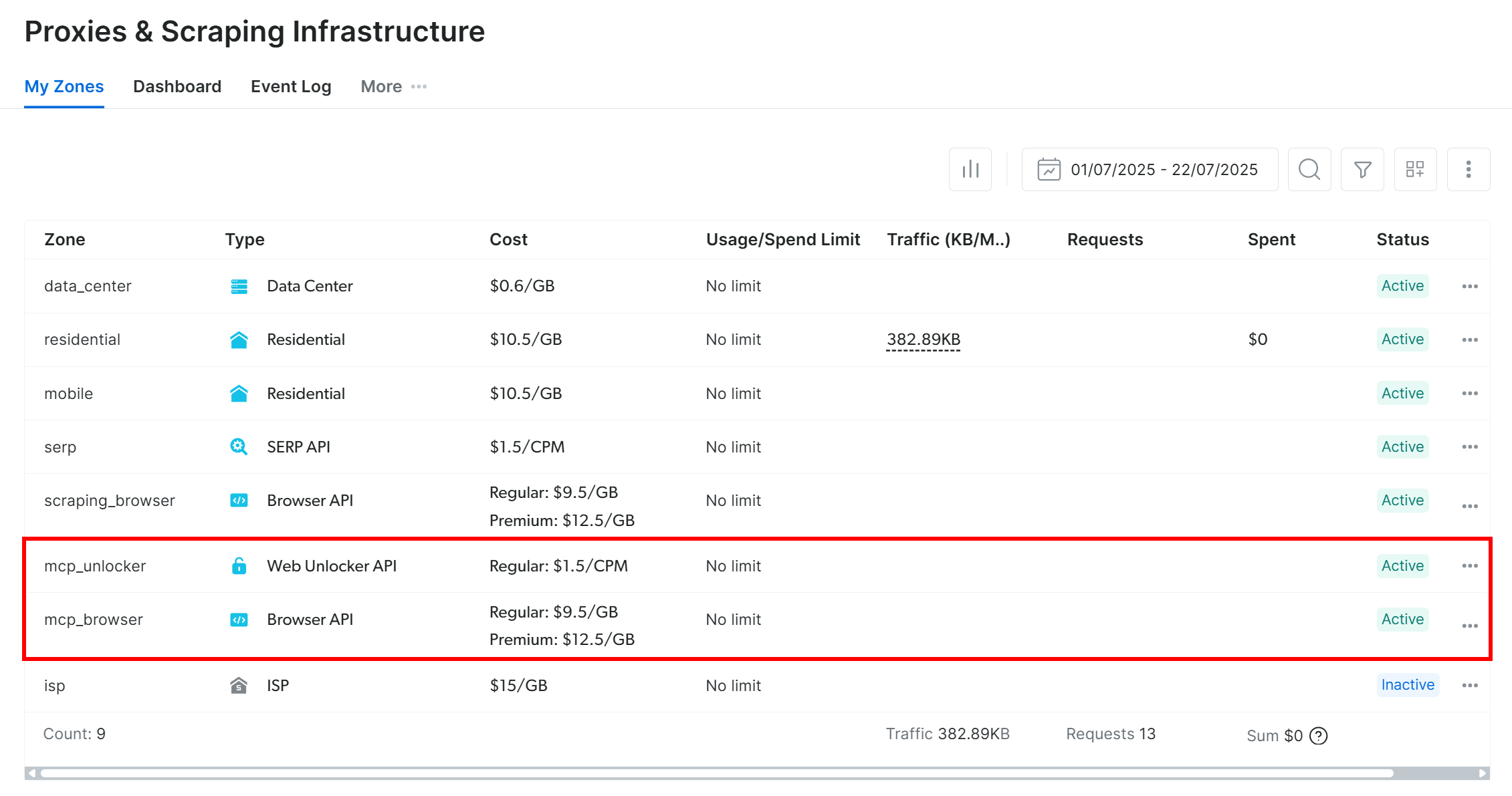
Примечание: Если ваш API-токен не имеет прав администратора, эти зоны могут быть не созданы для вас. В этом случае вы можете настроить их вручную и указать их имена с помощью переменных окружения, как показано в официальной документации.
Помните: по умолчанию на сервере MCP доступны только инструменты search_engine и scrape_as_markdown.
Чтобы открыть расширенные инструменты для автоматизации браузера и структурированных данных, необходимо включить режим Pro. Для этого перед запуском сервера MCP установите переменную окружения PRO_MODE=true:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpИли в Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpВажно: В режиме Pro вы получите доступ ко всем 60+ инструментам. Однако дополнительные инструменты в режиме Pro не включены в бесплатный уровень, и за них придется платить.
Узнайте больше о Web MCP-сервере Bright Data в официальной документации.
Отлично! Вы убедились, что сервер Web MCP корректно работает на вашей машине. Остановите сервер, поскольку следующим шагом будет настройка Crush на его запуск и подключение к нему при запуске.
Шаг № 3: Настройка Web MCP в Crush
Crush поддерживает интеграцию MCP через запись mcp в локальном или глобальном файле конфигурации crush.json.
В этом примере предположим, что вы хотите глобально настроить Web MCP от Bright Data в среде Crush CLI. Итак, откройте глобальный файл конфигурации:
- В Linux/macOS:
$HOME/.config/crush/crush.json. - В Windows:
%USERPROFILE%AppDataLocalcrushcrush.json.
Убедитесь, что он содержит следующее:
"mcp": {
"brightData": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<ВАШ_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}В этой конфигурации:
- Запись
mcpуказывает Crush, как запускать внешние MCP-серверы. - Элемент
brightDataопределяет команду и переменные окружения, необходимые для запуска Web MCP. (Помните: УстановкаPRO_MODEнеобязательна, но рекомендуется. Также замените<YOUR_BRIGHT_DATA_API_KEY>на свой ключ API Bright Data).
Другими словами, эта конфигурация добавляет пользовательский MCP-сервер под названием brightData. Crush использует переменные окружения, которые вы задали в файле, и запускает сервер с помощью указанной команды npx (которая соответствует команде, показанной в предыдущем шаге). Проще говоря, теперь Crush может запускать локальный процесс Web MCP и подключаться к нему при запуске.
Потрясающе! Пора протестировать интеграцию MCP в Crush CLI.
Шаг № 4: Проверка MCP-соединения
Закройте все запущенные экземпляры Crush и запустите его снова:
crush Если соединение с MCP работает как ожидалось, вы должны увидеть запись brightData в разделе “MCPs”:
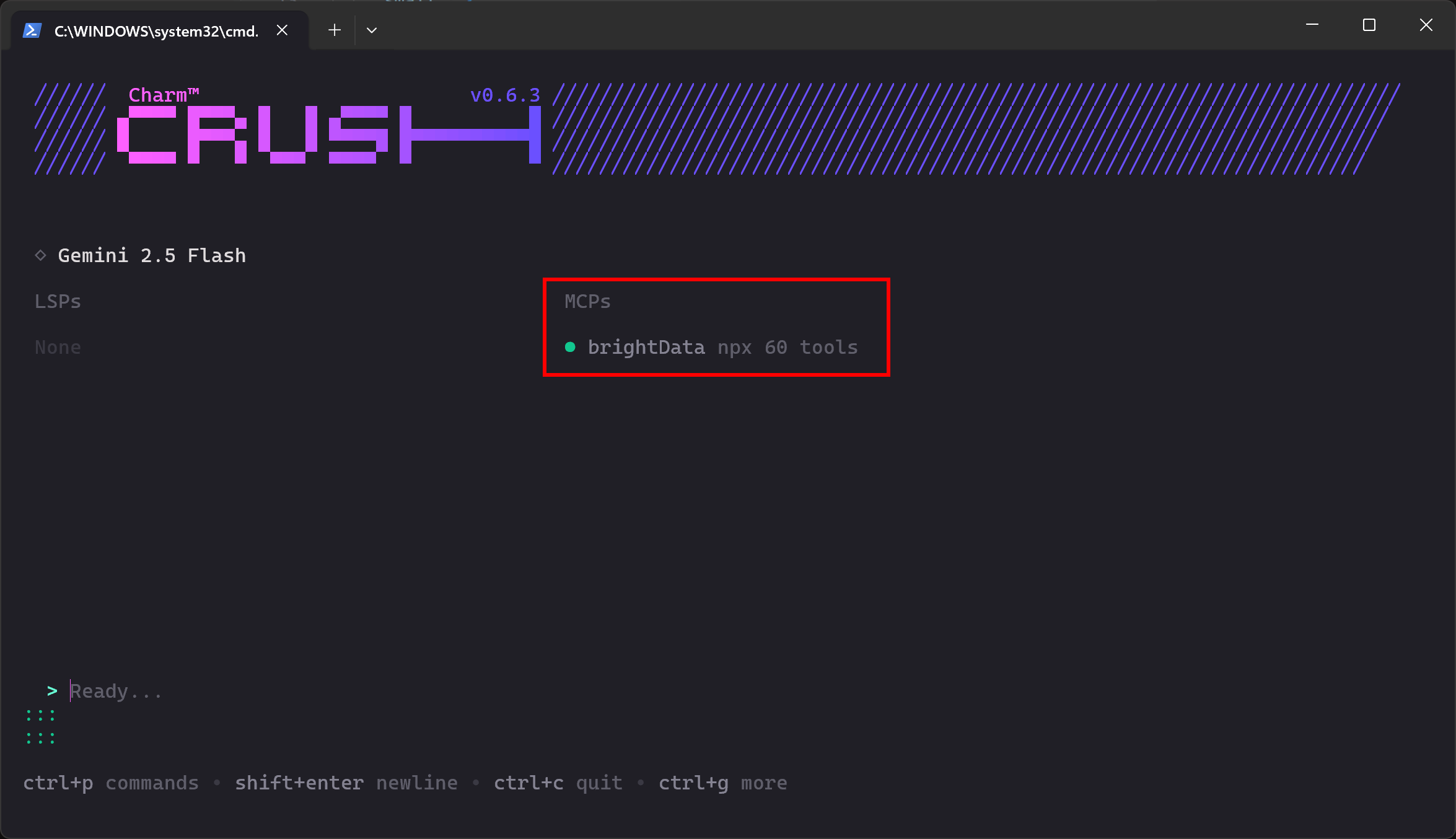
CLI показывает, что доступно 60 инструментов. Это потому, что мы настроили его на работу в режиме Pro Mode. В противном случае вам были бы доступны только 2 инструмента(scrape_as_markdown и search_engine). Отлично!
Шаг № 5: Запустите задачу в Crush
Чтобы проверить новые возможности в настройках Crush CLI, попробуйте запустить задачу следующим образом:
Соскрести данные с сайта "https://www.amazon.com/Microfiber-Cleaning-Cloth-Performance-Washes/dp/B08BRJHJF9/", сохранить их в локальном файле "product.json" и определить скрипт Node.js "script.js" для загрузки этого файла и вывода его содержимого в терминал.Это отличный тестовый пример, поскольку в нем требуется получить свежие данные о продукте, что можно сделать с помощью инструментов, предоставляемых Web MCP Bright Data. Кроме того, он демонстрирует реалистичный рабочий процесс, который вы можете использовать при имитации или настройке проекта по анализу данных.
Вставьте запрос в Crush и нажмите Enter, чтобы выполнить его. Вы должны увидеть нечто подобное:
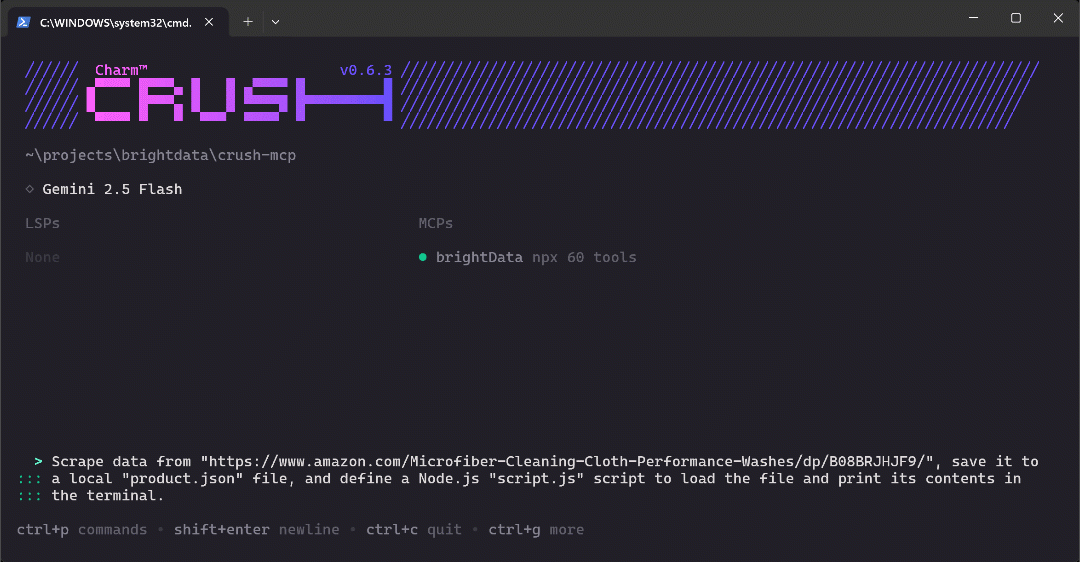
Приведенный выше GIF был ускорен, но вот что происходит шаг за шагом:
- Crush идентифицирует инструмент
web_data_amazon_product(в CLI он упоминается какmcp_brightData_web_data_amazon_product) как правильный для задачи и запрашивает ваше разрешение на его запуск. - После получения разрешения задача скрапинга запускается через интеграцию MCP.
- Полученные данные о продукте в формате JSON отображаются в терминале.
- Crush спрашивает, может ли он сохранить эти данные в локальный файл
product.json. - После одобрения файл создается и заполняется отсканированными данными.
- Затем Crush CLI генерирует логику JavaScript для
script.js, который загружает и печатает содержимое JSON. - После одобрения файл
script.jsбудет создан. - Вам будет предложено получить разрешение на выполнение сценария Node.js.
- После получения разрешения
script.jsвыполняется, и данные о продукте выводятся в терминале.
Обратите внимание, что CLI попросил запустить созданный сценарий Node.js, хотя вы не запрашивали его явно. Такое поведение было намеренным, поскольку оно облегчает тестирование (а значит, и исправление в случае ошибок) и добавляет ценности рабочему процессу.
В конце в вашей рабочей директории должны быть эти два файла:
├──── prodcut.json
└──── script.jsОткройте файл product.json в VS Code, и вы увидите:
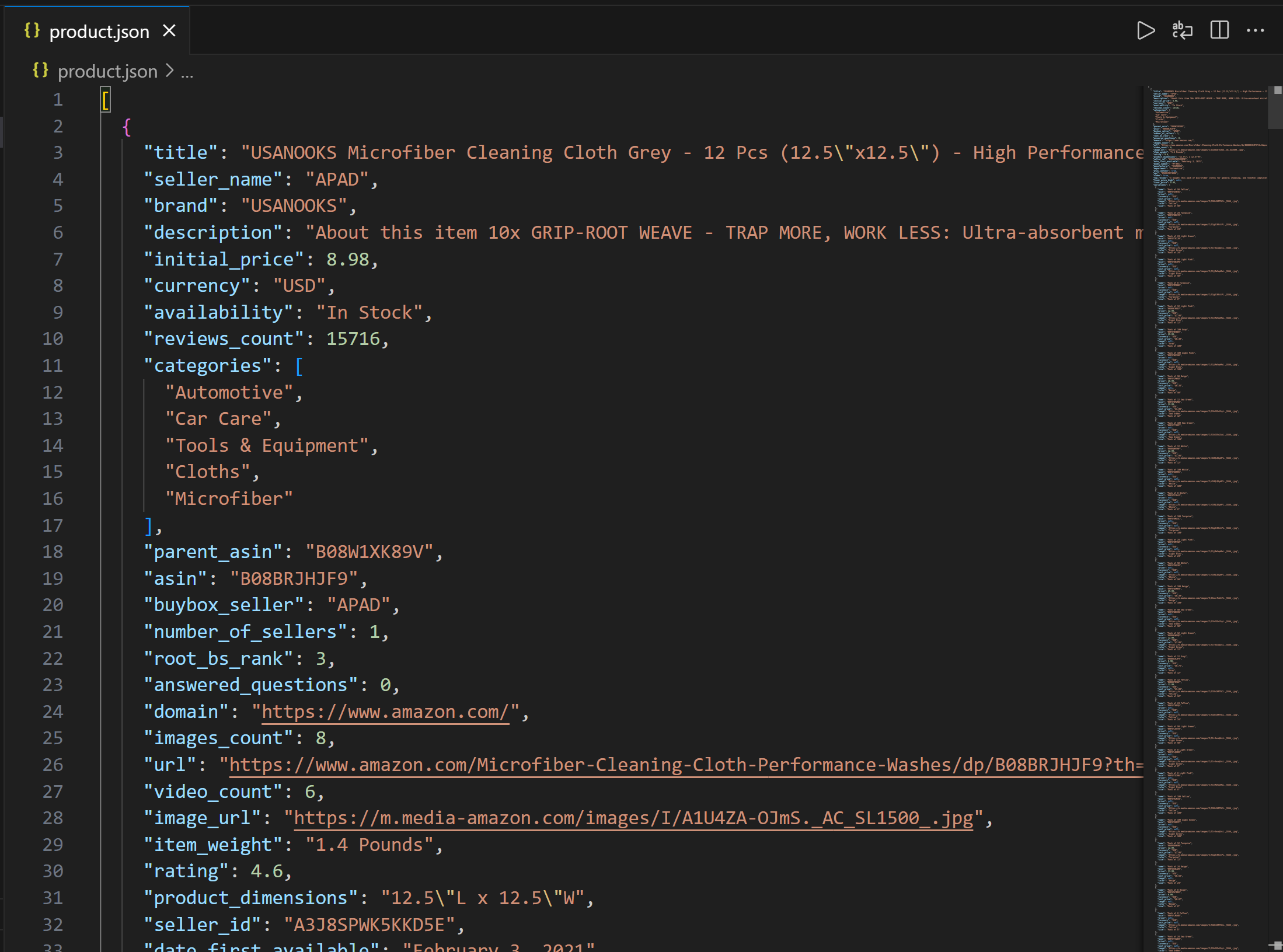
Этот файл содержит реальные данные о товарах, полученные с Amazon через Web MCP Bright Data.
Теперь откройте script.js:
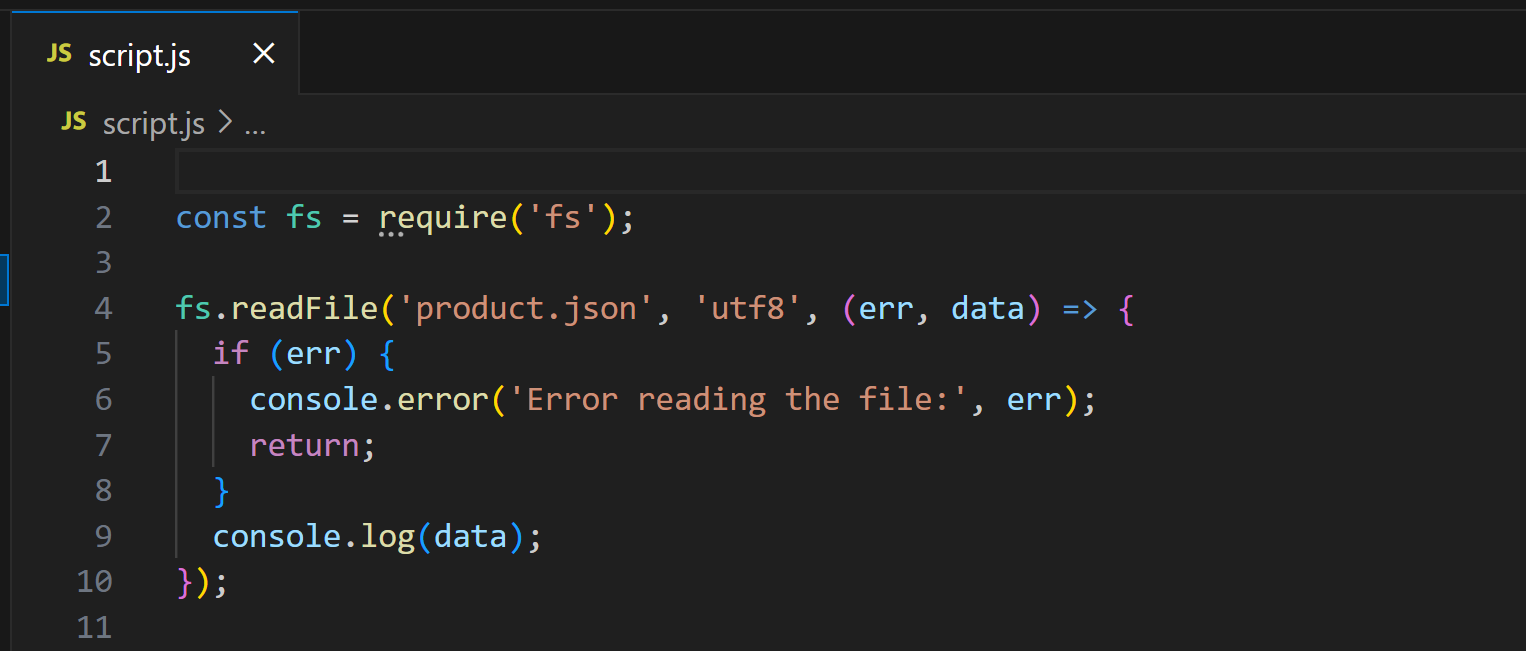
Этот скрипт использует Node.js для загрузки и отображения содержимого product.json. Запустите его с помощью:
node script.jsНа выходе должно получиться следующее:
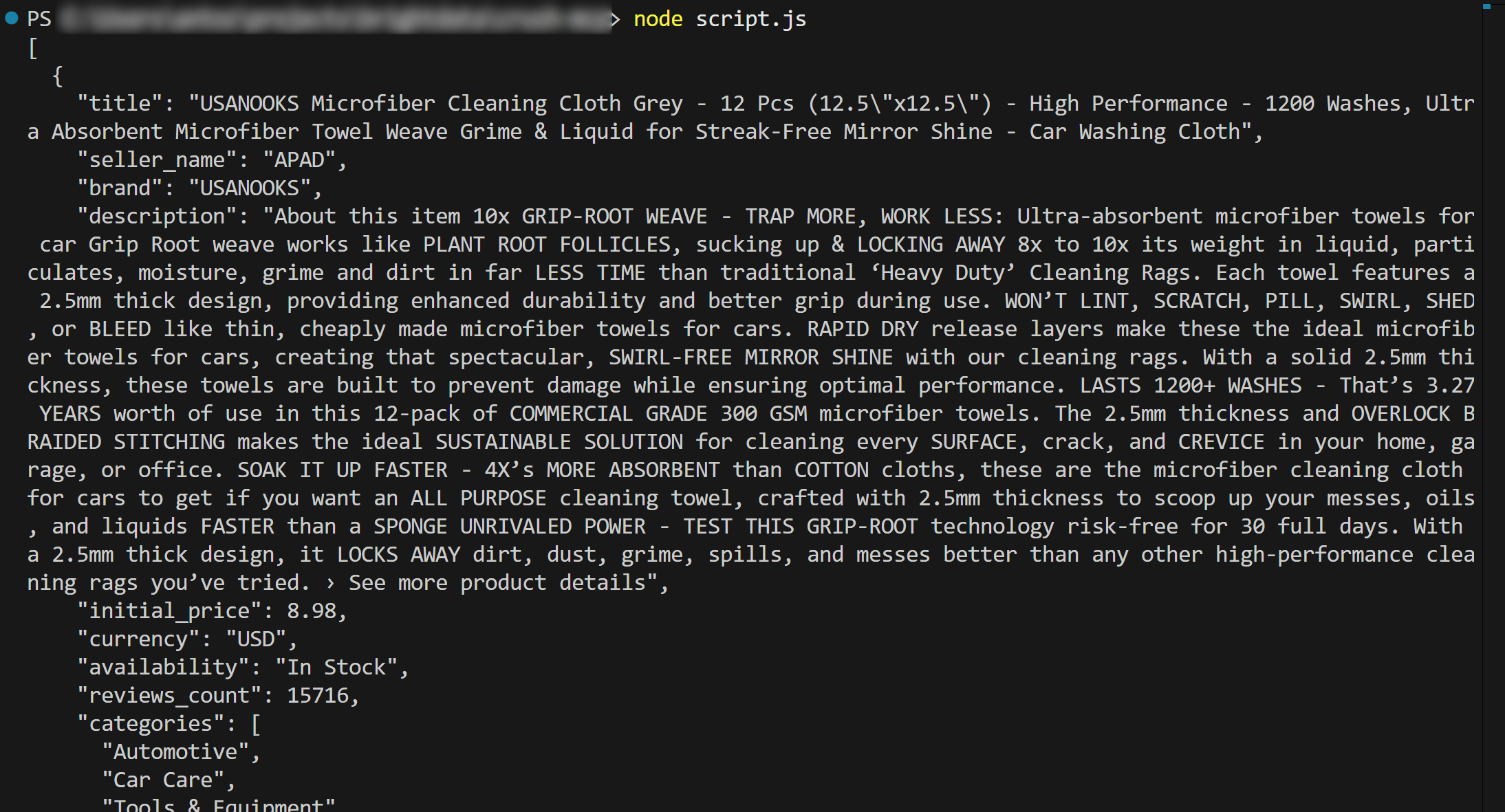
Et voilà! Рабочий процесс прошел успешно.
В деталях, содержимое, загруженное из product.json и выведенное в терминале, соответствует реальным данным, которые вы можете найти на оригинальной странице товара Amazon.
Важно: product.json содержит настоящие данные, а не галлюцинации или выдуманный контент, созданный искусственным интеллектом. Это важно отметить, потому что скраппинг Amazon, как известно, очень сложен из-за его продвинутой защиты от ботов (например, из-за Amazon CAPTCHA). Таким образом, обычный LLM в одиночку не смог бы достичь этой цели!
Этот пример демонстрирует истинную силу сочетания Crush с MCP-сервером Bright Data. Теперь попробуйте поэкспериментировать с новыми подсказками и изучить более продвинутые, управляемые LLM рабочие процессы с данными непосредственно в CLI!
Заключение
В этом руководстве вы узнали, как подключить Crush к Web MCP от Bright Data(который теперь предлагает бесплатный уровень!). В результате получился мощный CLI-агент для кодирования, способный получать доступ и взаимодействовать с Интернетом. Такая интеграция стала возможной благодаря встроенной в Crush CLI поддержке MCP-серверов.
Пример задачи в этом руководстве был намеренно простым. Однако не стоит забывать, что с помощью этой интеграции вы можете решать гораздо более сложные задачи. В конце концов, инструменты Bright Data Web MCP поддерживают широкий спектр агентских сценариев.
Для создания более сложных агентов изучите весь спектр услуг, доступных в инфраструктуре Bright Data AI.
Зарегистрируйте бесплатную учетную запись Bright Data и начните экспериментировать с веб-инструментами, поддерживающими ИИ, уже сегодня!





