

В этой статье вы узнаете:
- Что представляет собой инструмент Anthropic web fetch и каковы его основные ограничения.
- Как он работает.
- Как использовать его в cURL и Python.
- Что предлагает Bright Data для достижения аналогичных целей.
- Как сравниваются инструменты Anthropic и Bright Data для получения веб-данных.
- Сводная таблица для быстрого сравнения.
Давайте погрузимся!
Что представляет собой инструмент Anthropic Web Fetch Tool?
Инструмент Anthropic web fetch позволяет моделям Клода извлекать содержимое веб-страниц и PDF-документов. Этот инструмент был бесплатно представлен в бета-версии Claude 2025-09-10.
Включив этот инструмент в запрос API Claude, сконфигурированный LLM может получить и проанализировать полный текст с указанных URL веб-страниц или PDF-файлов. Это дает Claude доступ к актуальной, основанной на источниках информации для обоснованных ответов.
Примечания и ограничения
Вот основные примечания и ограничения, связанные с инструментом извлечения информации из веб-страниц Anthropic:
- Доступен в API Claude без дополнительной платы. Вы платите стандартную плату за токены только за извлеченный контент, который включен в контекст вашего разговора.
- Получает полный контент с указанных веб-страниц и PDF-документов.
- В настоящее время находится в стадии бета-версии и требует бета-заголовок
web-fetch-2025-09-10. - Claude не может динамически конструировать URL. Вы должны явно указать полные URL-адреса, или он может использовать только URL-адреса, полученные из предыдущих веб-поисков или результатов выборки.
- Claude может получать только те URL, которые уже появлялись в контексте беседы. Сюда входят URL-адреса из сообщений пользователя, результаты работы клиентского инструмента или предыдущие результаты веб-поиска и выборки.
- Работает только со следующими моделями: Claude Opus 4.1
(claude-opus-4-1-20250805), Claude Opus 4(claude-opus-4-20250514), Claude Sonnet 4.5(claude-sonnet-4-5-20250929), Claude Sonnet 4(claude-sonnet-4-20250514), Claude Sonnet 3.7(claude-3-7-sonnet-20250219), Claude Sonnet 3.5 v2 (deprecated)(claude-3-5-sonnet-latest), и Claude Haiku 3.5(claude-3-5-haiku-latest). - Не поддерживает динамически отображаемые веб-сайты на JavaScript.
- Может включать необязательные цитаты для найденного контента.
- Работает с оперативным кэшированием, так что кэшированные результаты могут быть использованы повторно во время разговора.
- Поддерживает параметры
max_uses,allowed_domains,blocked_domainsиmax_content_tokens. - Распространенные коды ошибок:
invalid_input,url_too_long,url_not_allowed,url_not_accessible,too_many_requests,unsupported_content_type,max_uses_exceededиunavailable.
Как работает веб-выборка в моделях Claude
Вот что происходит за кулисами , когда вы добавляете инструмент веб-выборки Anthropic к вашему API-запросу:
- Claude определяет время получения контента на основе запроса и предоставленных URL.
- API извлекает полнотекстовый контент из указанного URL.
- Для PDF-файлов выполняется автоматическое извлечение текста.
- Claude анализирует полученный контент и генерирует ответ, по желанию включая цитаты.
Полученный ответ возвращается пользователю или добавляется в контекст беседы для дальнейшего анализа.
Как использовать инструмент Anthropic Web Fetch Tool
Два основных способа использования инструмента веб-выбора – это включение его в запрос к одной из поддерживаемых моделей Claude. Это можно сделать одним из следующих способов:
- Через прямой вызов API к API Anthropic.
- Через один из клиентских SDK Claude, например библиотеку Anthropic Python API.
Узнайте, как это сделать в следующих разделах!
В обоих случаях мы продемонстрируем, как использовать инструмент веб-скетча для соскабливания домашней страницы Anthropic, как показано ниже:

Предварительные условия
Основное требование для использования инструмента Anthropic web fetch – наличие доступа к ключу API Anthropic. Здесь мы предположим, что у вас есть учетная запись Anthropic с ключом API.
Через прямой вызов API
Воспользуйтесь инструментом веб-выбора, сделав прямой вызов API к API Anthropic с одной из поддерживаемых моделей, как показано ниже в запросе cURL POST:
curl https://api.anthropic.com/v1/messages
--header "x-api-key: <YOUR_ANTHROPIC_API_KEY>"
--header "anthropic-version: 2023-06-01"
--header "anthropic-beta: web-fetch-2025-09-10"
--header "content-type: application/json"
--data '{
"model": "claude-sonnet-4-5-20250929",
"max_tokens": 1024,
"messages": [
{
"role": "пользователь",
"content": "Соскребите содержимое с 'https://www.anthropic.com/'"
}
],
"tools": [{ {
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5
}]
}'Обратите внимание, что claude-sonnet-4-5-20250929 – это одна из моделей, поддерживаемых инструментом web fetch.
Также обратите внимание на необходимость наличия двух специальных заголовков, anthropic-version и anthropic-beta.
Чтобы включить инструмент веб-выборки в настроенную модель, необходимо добавить следующий элемент в массив tools в теле запроса:
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5
}Поля type и name имеют значение, а max_uses необязательно и определяет, сколько раз инструмент может быть вызван в течение одной итерации.
Замените заполнитель <YOUR_ANTHROPIC_API_KEY> на ваш реальный ключ API Anthropic. Затем выполните запрос, и вы должны получить что-то вроде этого:
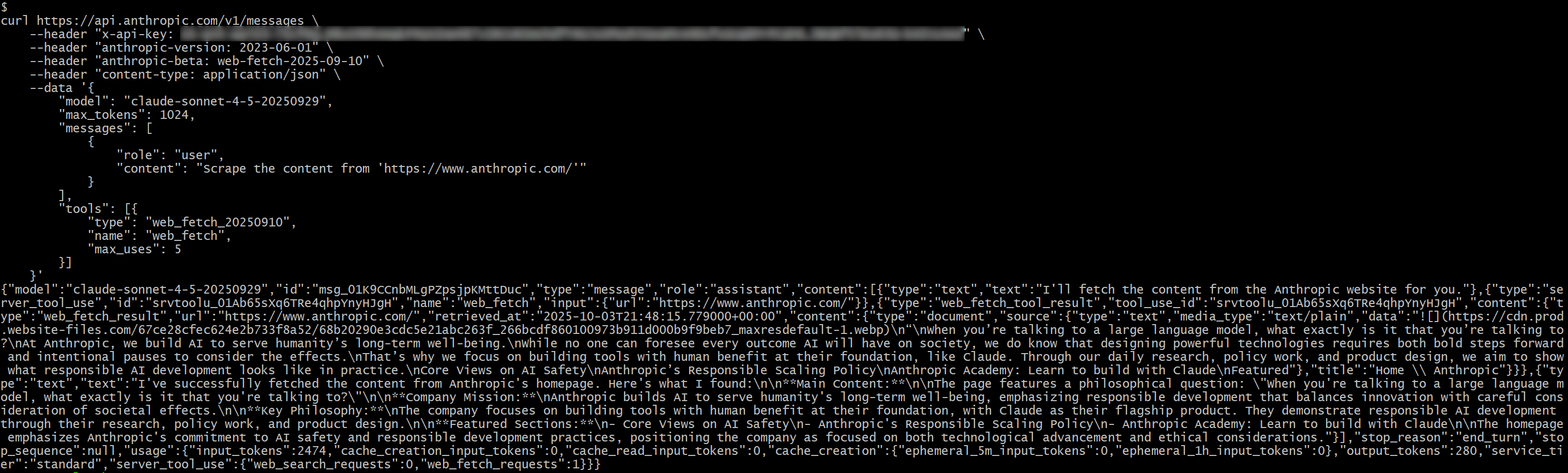
В ответе вы должны увидеть:
{"type": "server_tool_use", "id": "srvtoolu_01Ab65sXq6TRe4qhpYnyHJgH", "name": "web_fetch", "input":{"url": "https://www.anthropic.com/"}}.Это указывает, что LLM выполнил вызов инструмента web_fetch.
В частности, результат, выданный инструментом, будет иметь вид:

"Когда вы разговариваете с большой языковой моделью, с чем именно вы разговариваете?
В Anthropic мы создаем ИИ для долгосрочного благополучия человечества.
Хотя никто не может предугадать все последствия, которые ИИ окажет на общество, мы знаем, что разработка мощных технологий требует как смелых шагов вперед, так и намеренных пауз, чтобы обдумать последствия.
Именно поэтому мы уделяем особое внимание созданию инструментов, в основе которых, как в Claude, лежит польза для человека. Благодаря ежедневным исследованиям, работе над политикой и дизайну продуктов мы стремимся показать, как выглядит ответственное развитие ИИ на практике.
Основные взгляды на безопасность ИИ
Политика ответственного масштабирования Anthropic
Академия Anthropic: Учитесь строить вместе с Клодом
Featured
Это своего рода Markdown-подобная версия домашней страницы указанного входного URL. Это “как бы” Markdown, поскольку некоторые ссылки опущены, и, за исключением первого изображения, вывод в основном сосредоточен на тексте, что как раз то, что должен возвращать инструмент веб-выбора.
Примечание: В целом результат точный, но в нем определенно отсутствует часть контента, который мог быть потерян при обработке инструментом. На самом деле, исходная страница содержит больше текста, чем было получено.
Использование библиотеки API Anthropic Python
В качестве альтернативы вы можете вызвать инструмент веб-выборки, используя библиотеку Anthropic Python API:
# pip install anthropic
import anthropic
# Замените его своим ключом API Anthropic
ANTHROPIC_API_KEY = "<ВАШ_ANTHROPIC_API_KEY>"
# Инициализация клиента API Anthropic
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# Выполните запрос к Claude с включенным инструментом веб-выборки
response = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
messages=[
{
"role": "пользователь",
"content": "Соскребите содержимое с 'https://www.anthropic.com/'"
}
],
tools=[
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2025-09-10"
}
)
# Выведите результат, полученный ИИ, в терминал
print(response.content)
На этот раз результат будет таким:
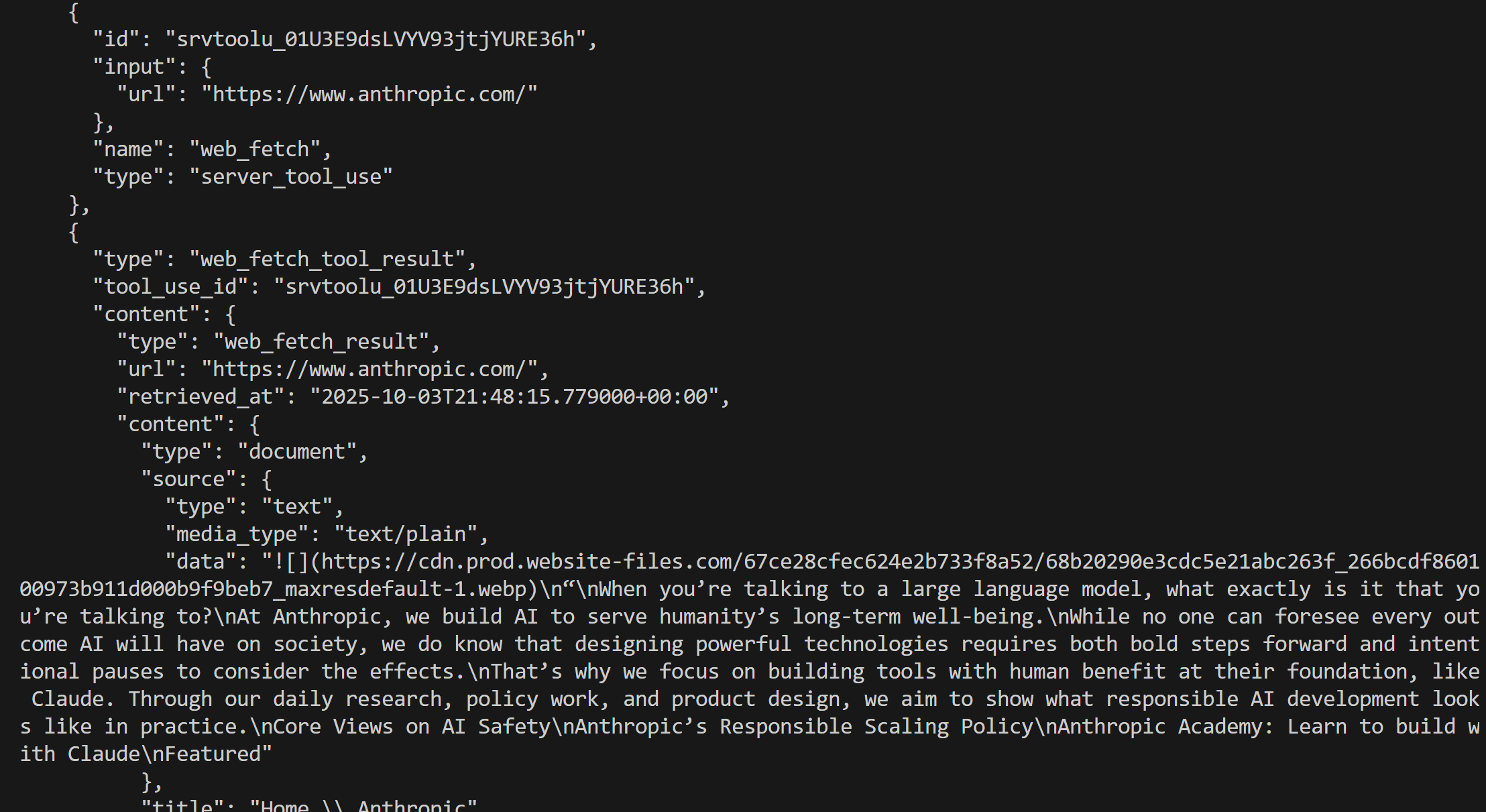
Отлично! Это эквивалентно тому, что мы видели ранее.
Введение в инструменты веб-данных Bright Data
Инфраструктура ИИ Bright Data предлагает богатый набор решений, позволяющих вашему ИИ свободно искать, ползать и перемещаться в Интернете. Сюда входят:
- API Unlocker: Надежное получение контента с любого публичного URL, автоматический обход блокировок и решение CAPTCHA.
- API Crawl: Легко просматривайте и извлекайте целые веб-сайты, предоставляя результаты в форматах, готовых к LLM, для эффективных выводов и рассуждений.
- SERP API: Получение в реальном времени результатов поисковых систем с учетом географических особенностей для обнаружения релевантных источников данных по определенному запросу.
- API браузера: Обеспечьте взаимодействие ИИ с динамическими сайтами и автоматизируйте агентские рабочие процессы в масштабе с помощью удаленных невидимых браузеров.
Среди множества инструментов, сервисов и продуктов для поиска веб-данных в инфраструктуре Bright Data мы остановимся на Web MCP. Он предоставляет инструменты для интеграции ИИ, построенные на базе продуктов Bright Data, которые напрямую сопоставимы с теми, что предлагает Anthropic. Обратите внимание, что Web MCP также функционирует как Claude MCP, полностью интегрируясь с любыми моделями Anthropic.
Из всех 60 с лишним доступных инструментов для сравнения идеально подходит инструмент scrape_as_markdown. Он позволяет соскребать URL одной веб-страницы с расширенными опциями для извлечения контента и возвращает результаты в формате Markdown. Этот инструмент может получить доступ к любой веб-странице, даже к тем, которые используют обнаружение ботов или CAPTCHA.
Важно отметить, что этот инструмент доступен на Web MCP даже в бесплатном варианте, то есть вы можете использовать его бесплатно. Таким образом, он обеспечивает функциональность ретриавала веб-данных, аналогичную инструменту Anthropic для сбора веб-данных, что делает Web MCP идеальным для прямого сравнения.
Anthropic Web Fetch Tool против Bright Data Web Data Tools
В этом разделе мы построим процесс сравнения инструмента для получения веб-данных Anthropic с инструментами для получения веб-данных Bright Data. В деталях мы:
- Использовать инструмент для получения веб-данных через библиотеку Anthropic Python API.
- Подключаться к Web MCP Bright Data с помощью адаптеров LangChain MCP (но подойдет и любая другая поддерживаемая интеграция ).
Мы запустим оба подхода, используя один и тот же запрос и модель Claude для следующих четырех входных URL:
"https://www.anthropic.com/""https://www.g2.com/products/bright-data/reviews""https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/""https://it.linkedin.com/in/antonello-zanini"
Они представляют собой хорошее сочетание реальных страниц, с которых ИИ мог бы автоматически получать контент: главная страница сайта, страница продукта G2, страница продукта Amazon и публичный профиль LinkedIn. Обратите внимание, что G2, как известно, сложно скрафтить из-за защиты Cloudflare, поэтому он был намеренно включен в сравнение.
Давайте посмотрим, как работают эти два инструмента!
Предварительные условия
Прежде чем приступить к выполнению этого раздела, вам необходимо:
- Локально установленный Python.
- Ключ API Anthropic.
- Учетная запись Bright Data с ключом API.
Чтобы создать учетную запись Bright Data и сгенерировать ключ API, следуйте официальному руководству. Также рекомендуется ознакомиться с официальной документацией Web MCP.
Кроме того, полезными будут знания о том, как работает интеграция LangChain, и знакомство с инструментами, предоставляемыми Web MCP.
Сценарий интеграции инструмента Web Fetch
Чтобы запустить инструмент Anthropic для выборки веб-страниц по выбранным входным URL, вы можете написать логику на Python следующим образом:
# pip install anthropic
import anthropic
Замените его своим ключом API Anthropic
ANTHROPIC_API_KEY = ""
Инициализируйте клиент API Anthropic
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def scrape_content_with_anthropic_web_fetch_tool(url):
return client.messages.create( model="claude-sonnet-4-5-20250929",
max_tokens=1024,
messages=[
{
"role": "user",
"content": f "Scrape the content from '{url}'"
}
],
tools=[
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2025-09-10"
}
)
Далее вы можете вызвать эту функцию на входном URL следующим образом:
scrape_content_with_anthropic_web_fetch_tool("https://www.anthropic.com/")
Сценарий интеграции с инструментами Web Data Tools компании Bright Data
Web MCP может быть интегрирован с широким спектром технологий, как описано в нашем блоге. Здесь мы продемонстрируем интеграцию с LangChain, так как это один из самых простых и популярных вариантов.
Прежде чем приступить к работе, рекомендуем ознакомиться с руководством: “Адаптеры LangChain MCP с Web MCP от Bright Data“.
В этом случае у вас должен получиться такой фрагмент Python:
# pip install "langchain[anthropic]" langchain-mcp-adapters langgraph
import asyncio
from langchain_anthropic import ChatAnthropic
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
из langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
импортировать json
# Замените на ваши ключи API
ANTHROPIC_API_KEY = "<ВАШ_ANTHROPIC_API_KEY>"
BRIGHT_DATA_API_KEY = "<ВАШ_BRIGHT_DATA_API_KEY>"
async def scrape_content_with_bright_data_web_mcp_tools(agent, url):
# Описание задачи агента
input_prompt = f "Scrape the content from '{url}'"
# Выполнение запроса в агенте, потоковая передача ответа и возврат его в виде строки
output = []
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
content = step["messages"][-1].content
if isinstance(content, list):
output.append(json.dumps(content))
else:
output.append(content)
return "".join(output)
async def main():
# Инициализируем движок LLM
llm = ChatAnthropic(
model="claude-sonnet-4-5-20250929",
api_key=ANTHROPIC_API_KEY
)
# Конфигурация для подключения к локальному экземпляру сервера Bright Data Web MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "false" # Опционально устанавливается значение "true" для режима Pro
}
)
# Подключение к серверу MCP
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Инициализация сессии клиента MCP
await session.initialize()
# Получение инструментов Web MCP
tools = await load_mcp_tools(session)
# Создание агента ReAct с интеграцией с Web MCP
агент = create_react_agent(llm, tools)
# scrape_content_with_bright_data_web_mcp_tools(agent, "https://www.anthropic.com/")
if __name__ == "__main__":
asyncio.run(main())
Это определяет агента ReAct, который имеет доступ к инструментам Web MCP.
Помните: Web MCP предлагает режим Pro, который предоставляет доступ к премиум-инструментам. В данном случае использование режима Pro не является обязательным. Таким образом, вы можете полагаться только на инструменты, доступные в бесплатном режиме. В число бесплатных инструментов входит scrape_as_markdown, которого вполне достаточно для данного бенчмарка.
Проще говоря, с точки зрения затрат, использование Web MCP в бесплатном режиме обойдется не дороже, чем использование токена для самой модели Claude (что одинаково в обоих сценариях). По сути, структура затрат при такой настройке такая же, как и при прямом подключении к Claude через API.
Результаты бенчмарка
Теперь выполните две функции, представляющие два метода поиска веб-данных для ИИ, используя следующую логику:
# Где хранить результаты бенчмарков
benchmark_results = []
# Входные URL-адреса для тестирования двух подходов
urls = [
"https://www.anthropic.com/",
"https://www.g2.com/products/bright-data/reviews",
"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/",
"https://it.linkedin.com/in/antonello-zanini"
]
# Проверьте каждый URL
for url in urls:
print(f "Тестирование двух подходов на следующем URL: {url}")
anthropic_start_time = time.time()
anthropic_response = scrape_content_with_anthropic_web_fetch_tool(url)
anthropic_end_time = time.time()
bright_data_start_time = time.time()
bright_data_response = await scrape_content_with_bright_data_web_mcp_tools(agent, url)
bright_data_end_time = time.time()
benchmark_entry = {
"url": url,
"anthropic": {
"время_выполнения": anthropic_end_time - anthropic_start_time,
"output": anthropic_response.to_json()
},
"bright_data": {
"время_выполнения": bright_data_end_time - bright_data_start_time,
"output": bright_data_response
}
}
benchmark_results.append(benchmark_entry)
# Экспорт данных бенчмарка
with open("benchmark_results.json", "w", encoding="utf-8") as f:
json.dump(benchmark_results, f, ensure_ascii=False, indent=4)
Результаты можно свести в следующую таблицу:
| Anthropic Web Fetch Tool | Инструменты для получения веб-данных | |
|---|---|---|
| Домашняя страница Anthropic | ✔️ (частичная текстовая информация) | ✔️ (полная информация в формате Markdown) |
| Страница обзора G2 | ❌ (инструмент не сработал через ~10 секунд) | ✔️ (полная версия страницы в формате Markdown) |
| Страница товара Amazon | ✔️ (частичная текстовая информация) | ✔️ (полная версия страницы в формате Markdown или структурированные данные о товаре в формате JSON в режиме Pro) |
| Страница профиля LinkedIn | ❌ (инструмент сразу не сработал) | ✔️ (полная версия страницы в формате Markdown или структурированные данные профиля в формате JSON в режиме Pro) |
Как видите, инструмент Anthropic не только менее эффективен, чем инструменты для получения веб-данных Bright Data, но даже когда он работает, он дает менее полные результаты.
Инструмент Anthropic в основном фокусируется на тексте, в то время как инструменты Web MCP, такие как scrape_as_markdown, возвращают полную версию страницы в формате Markdown. Кроме того, с помощью инструментов Pro, таких как web_data_amazon_product, можно получить структурированные данные с таких популярных сайтов, как Amazon.
В целом, инструменты для работы с веб-данными Bright Data являются явным победителем как по точности, так и по времени выполнения!
Резюме: сравнительная таблица
| Anthropic Web Fetch Tool | Инструменты для работы с веб-данными Bright Data | |
|---|---|---|
| Типы контента | Веб-страницы, PDF-файлы | Веб-страницы |
| Возможности | Извлечение текста | Извлечение контента, веб-скрейпинг, веб-скроллинг и многое другое |
| Выходные данные | В основном обычный текст | Markdown, JSON и другие форматы, пригодные для LLM |
| Интеграция моделей | Работает только с определенными моделями Claude | Полностью интегрируется с любым LLM и более чем 70 технологиями |
| Поддержка сайтов с JavaScript-рендерингом | ❌ | ✔️ |
| Обработка обхода анти-ботов/CAPTCHA | ❌ | ✔️ |
| Надежность | Бета-версия | Готовность к производству |
| Поддержка пакетных запросов | ✔️ | ✔️ |
| Интеграция агентов | Только в решениях Claude | ✔️ (в любом решении для создания агентов ИИ, поддерживающем MCP или официальные инструменты Bright Data) |
| Надежность и полнота | Частичное извлечение контента; может не работать на сложных страницах | Полное извлечение контента; обрабатывает сложные сайты и страницы с защитой от ботов |
| Стоимость | Только стандартное использование токенов | Только стандартное использование токенов в бесплатном режиме; дополнительные расходы в режиме Pro |
Об интеграции Web MCP с технологиями Anthropic и моделями Claude читайте в следующих руководствах:
- Интеграция кода Claude с Web MCP от Bright Data
- Веб-скрейпинг с Claude: парсинг с помощью ИИ на Python
- Как использовать Bright Data с Pica MCP в Claude Desktop
Заключение
В этом сравнительном блоге вы увидели, как инструмент для получения данных из Интернета Anthropic сравнится с возможностями поиска и взаимодействия с данными из Интернета, предлагаемыми Bright Data. В частности, вы узнали, как использовать инструмент Anthropic в реальных примерах, а затем провели сравнительный анализ с использованием эквивалентного агента LangChain, взаимодействующего с Web MCP от Bright Data.
Явным победителем стали инструменты Bright Data, которые включают в себя целый ряд продуктов и сервисов, готовых к работе с ИИ и способных поддерживать самые разные сценарии и случаи использования.
Создайте бесплатную учетную запись Bright Data и начните изучать наши инструменты для работы с веб-данными, готовыми к ИИ!




