

В современных проектах по работе с данными сопоставление данных приводит к согласованию полей и записей в разных системах, чтобы информация сохраняла свое значение при перемещении между базами данных и приложениями. Когда-то этот процесс был ручным и хрупким, теперь же он выигрывает благодаря искусственному интеллекту. В этом руководстве мы рассмотрим, как ИИ преобразует сопоставление данных, какие ключевые техники лежат в его основе и как превратить публичные веб-данные в готовые для анализа наборы данных.
Что такое отображение данных и почему оно является сложной задачей?
Сопоставление данных просто указывает системам, как соотносятся поля данных. Например, электронная почта клиента в одной базе данных сопоставляется с адресом электронной почты в другой. Без надлежащего сопоставления данные, передаваемые между системами, могут потерять контекст или привести к дублированию. Картирование необходимо для интеграции, миграции и аналитики: оно помогает гарантировать, что при переносе данных в новый инструмент или хранилище каждое значение окажется в нужном месте.
Однако традиционное картирование выполняется медленно и чревато ошибками. На крупных предприятиях данные хранятся в сотнях различных источников и форматов. Командам часто приходится писать пользовательские сценарии или использовать сложные инструменты ETL, вручную подгоняя каждое поле. Такой метод не подходит для масштабирования: проекты могут занимать месяцы, а человеческие ошибки – обычное дело.
Еще больше проблем возникает при работе с веб-данными – неструктурированные HTML-страницы, непоследовательное именование полей и неаккуратное форматирование создают дополнительные сложности. Некачественные исходные данные приводят к плохим результатам сопоставления, независимо от того, насколько совершенны ваши инструменты искусственного интеллекта.
Как ИИ преобразует картирование данных
При сопоставлении данных с помощью ИИ используется машинное обучение и обработка естественного языка для анализа исходных и целевых схем, интерпретации названий полей и контекста, а также изучения опыта предыдущих сопоставлений, чтобы предлагать точные соответствия вместо необходимости ручного кодирования полей.
ИИ распознает, что cust_ID, customerID и customer_id представляют собой одно и то же понятие. Платформы обнаруживают сигналы типа данных и предлагают целевые поля в соответствии с ними, сокращая задачи по сопоставлению с нескольких часов до нескольких минут.
Вот основные преимущества сопоставления данных с помощью искусственного интеллекта:
- Скорость и эффективность. Автоматизация решает повторяющиеся задачи по сопоставлению и преобразованию данных, сокращая ручные операции.
- Точность и обучение. Системы учатся на основе ваших вариантов принятия/отклонения, улучшая предложения с течением времени.
- Масштабируемость. Картографирование с помощью искусственного интеллекта позволяет обрабатывать большие и сложные массивы данных. По мере роста объема и разнообразия данных современные инструменты могут одновременно анализировать несколько схем и источников.
- Адаптивность. В отличие от статичных скриптов, AI mapping адаптируется к изменениям. Когда появляются новые поля или форматы, ИИ устанавливает взаимосвязи на основе контекста или отзывов пользователей. Система изучает шаблоны данных вашей организации, что со временем требует меньше человеческих корректировок.
- Улучшение качества данных и управления. Автоматизированное отображение помогает обеспечить согласованность и управление. Документируя соответствие полей, инструменты искусственного интеллекта сохраняют историю данных и поддерживают нормативно-правовое соответствие, отслеживая маршрутизацию конфиденциальных данных.
- Снижение затрат. Эти преимущества позволяют снизить затраты за счет сокращения ручного труда, уменьшения количества ошибок, требующих доработки, и ускорения завершения проекта.
Технологии, лежащие в основе сопоставления данных с помощью искусственного интеллекта
Современное сопоставление данных основано на нескольких технологиях ИИ:
- Обработка естественного языка (NLP). NLP интерпретирует смысл названий и меток полей (например, Email Address по сравнению с e-mail) и может обрабатывать документацию для извлечения контекста, что делает отображение более надежным даже при значительных различиях в названиях.
- Модели машинного обучения. Модели машинного обучения классифицируют и предсказывают отображения на основе изученных шаблонов. Каждое прошлое сопоставление служит основой для модели: если многие наборы данных показывают, что account_manager сопоставляется с sales_rep в биллинговой системе, модель будет отдавать предпочтение этому предложению в следующий раз, улучшая рекомендации с течением времени при участии человека.
- Графы знаний. Некоторые платформы поддерживают внутренние графы знаний, связывающие сущности и отношения между системами. Граф может показать, что идентификатор клиента в одной системе совпадает с номером счета в другой, и что оба они относятся к биллинговой ссылке, что помогает сделать вывод о косвенных сопоставлениях и обеспечить согласованность схем.
- Глубокое обучение и компьютерное зрение. Для неструктурированных или полуструктурированных документов (например, PDF-файлов, отсканированных форм) глубокое обучение позволяет извлекать текст, таблицы и пары ключ-значение, чтобы сопоставить их со структурированными объектами.
- Семантическое соответствие и выравнивание схем. В современные инструменты интегрированы алгоритмы сопоставления схем (включая выравнивание графов/онтологий), которые объединяют лексические, структурные и основанные на экземплярах данные, а также словари домена, если таковые имеются, для поиска соответствий.
Как происходит сопоставление данных с помощью ИИ (шаг за шагом)
Инструменты для сопоставления данных ИИ работают по следующей схеме:
- Подключение источников данных. Инструмент подключается к вашим исходным и целевым системам (базам данных, файлам, API), проверяет имена полей, типы данных, значения образцов и метаданные, а также использует NLP для чтения меток/описаний, чтобы понять контекст, прежде чем предлагать соответствия.
- Анализирует и предлагает совпадения. Применяется автоматическое сопоставление по имени/положению и семантическому сходству для создания пар-кандидатов, часто с оценкой достоверности. Например, он может сопоставить country_code с CountryID. Если обнаружится несоответствие типов (текст типа “Qty: 12” против числового значения), то перед окончательным сопоставлением будет предложено преобразование разбора/кастинга.
- Просмотр и уточнение. Совпадения с высокой степенью достоверности могут быть приняты автоматически, а неоднозначные помечаются для проверки стюардом. Действия по принятию/отклонению фиксируются для аудита и используются для улучшения будущих предложений.
- ИИ учится на основе обратной связи. Система учитывает ваши решения (ваша институциональная память), поэтому в следующий раз аналогичные наборы данных будут сопоставляться быстрее, а рекомендации будут соответствовать вашим соглашениям об именовании и политике.
- Развертывание преобразований. После утверждения сопоставлений платформа генерирует и вводит в действие необходимые преобразования (преобразования, конкатенации, стандартизации) и запускает их в управляемых конвейерах ETL/ELT с планированием, мониторингом и отслеживанием истории.
Получение готовых к отображению данных из Интернета
Прежде чем ИИ сможет эффективно сопоставить данные, необходимо получить чистые, структурированные исходные данные. Веб-данные часто бывают беспорядочными – непоследовательное форматирование, вложенный HTML, меняющаяся структура страниц. Именно поэтому правильный сбор веб-данных становится решающим фактором для успешной реализации картографических проектов.
Bright Data предоставляет платформу для извлечения и подготовки веб-данных для ИИ, поэтому картирование начинается с более чистых исходных данных:
- AI Web Scraper. Определяет структуру страниц и извлекает структурированные данные с современных сайтов; предоставляет JSON/CSV через API или веб-крючки.
- Наборы данных (предварительно созданные). Готовые, обновляемые наборы данных с документированными схемами (например, продукты Amazon), чтобы имена и типы полей соответствовали друг другу.
- Прокси-сервер и веб-разблокировщик. Надежный доступ к публичным сайтам с помощью блокировок и CAPTCHA – так что вы можете собирать данные перед отображением даже на сложных сайтах.
- Браузерный API и бессерверные функции. Запускайте программируемые рабочие процессы скрапинга на хостинге для многоэтапного сбора данных перед составлением карты.
- Интеграции. Подключайте результаты сбора или наборы данных к фреймворкам приложений искусственного интеллекта (например, LangChain, LlamaIndex) или к вашим объектам хранения.
Взяв на себя сбор и первоначальное структурирование, Bright Data позволяет вам сосредоточиться на отображении и преобразовании.
Простой пример – отображение набора данных товаров Amazon
Давайте рассмотрим практический пример с использованием данных о товарах Amazon. Вместо того чтобы вручную перелопачивать беспорядочные страницы товаров, мы воспользуемся набором данных Amazon Product Dataset от Bright Data, который содержит чистые структурированные записи, идеально подходящие для ИИ-маппинга.
Набор данных включает такие поля, как название, бренд, начальная_цена, валюта и наличие. Пример записи выглядит следующим образом:
{
"title": "Hanes Girls' Cami Tops, 100% Cotton Camisoles...",
"brand": "Нижнее белье Hanes для девочек 7-16",
"initial_price": 10.00,
"currency": "USD",
"availability": true
}Предположим, что наша целевая схема аналитики нуждается в ProductName, Brand, PriceUSD и InStock. Инструмент отображения ИИ предложит следующие преобразования:
- title → ProductName (высокодостоверное семантическое соответствие)
- бренд → бренд (точное совпадение названия)
- initial_price + currency → PriceUSD (объединить поля, нормализовать к USD)
- наличие → InStock (булево преобразование)
После сопоставления и преобразования:
{
"ProductName": "Hanes Girls' Cami Tops, ...",
"Brand": "Нижнее белье Hanes для девочек 7-16",
"PriceUSD": 10.00,
"InStock": true
}Инструмент сопоставления AI автоматически предложил большинство вариантов, поскольку исходные данные были чистыми и последовательно отформатированными.
Для индивидуальных требований можно использовать веб-скребок AI для извлечения определенных полей Amazon в предпочтительный формат, а затем сопоставить их с целевой схемой.
Примечание: не забывайте о людях. Картирование с помощью искусственного интеллекта лучше всего работает в качестве интеллектуального помощника, а не как замена экспертной оценки данных. Всегда проверяйте критически важные сопоставления, особенно для чувствительных полей или соответствия нормативным требованиям.
Расширенное сопоставление с помощью запросов на естественном языке
Иногда вам нужно найти и сопоставить данные, которые не существуют в готовых форматах. Deep Lookup от Bright Data позволяет генерировать пользовательские наборы данных с помощью запросов на естественном языке, а затем сопоставлять результаты с целевой схемой. Например:
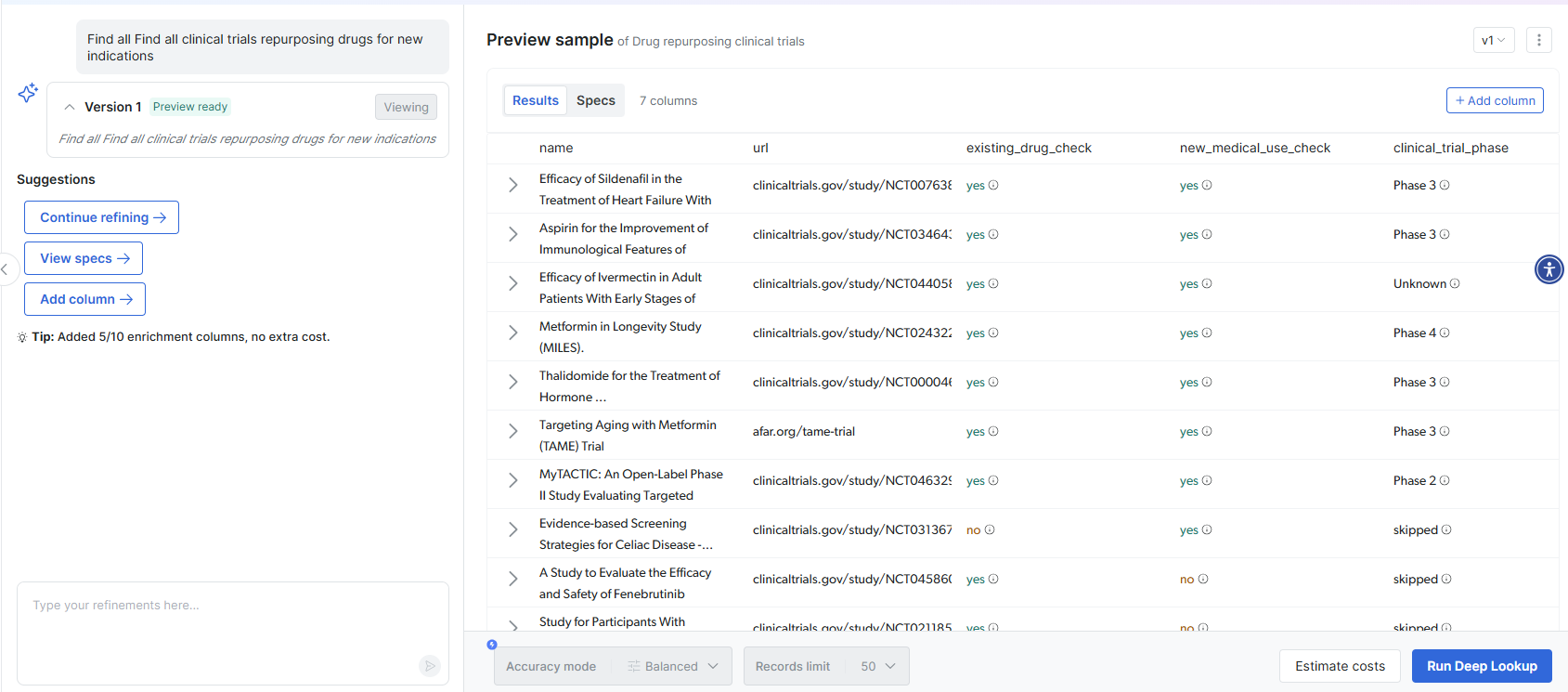
Deep Lookup просматривает веб-данные в поисках подходящих компаний и возвращает структурированные результаты, готовые к отображению:
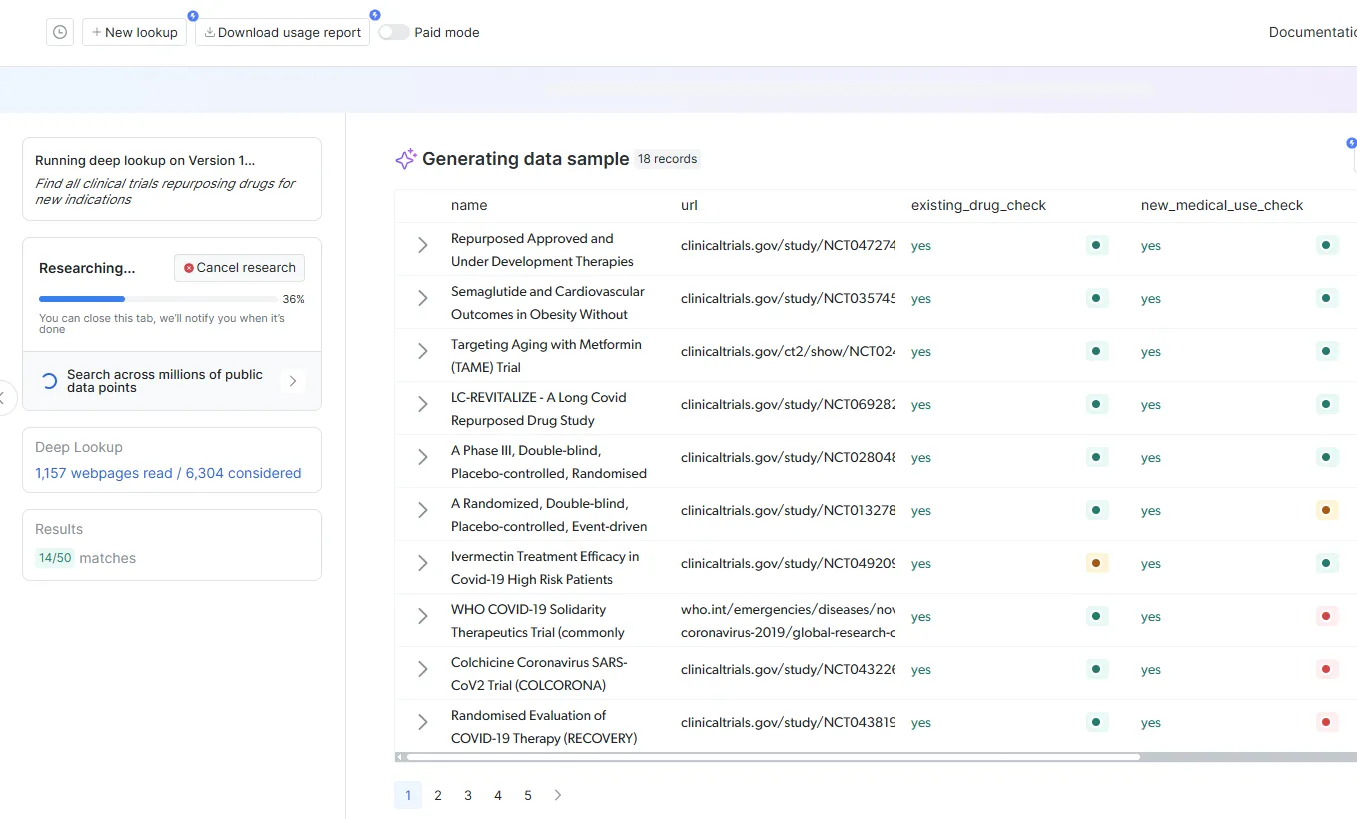
Это позволяет отказаться от традиционного рабочего процесса “исследование – затем структура – затем отображение”, предоставляя готовые к отображению данные непосредственно из запросов на естественном языке.
Заключение
Картирование данных с помощью искусственного интеллекта меняет способы интеграции публичных веб-данных в аналитику и рабочие процессы искусственного интеллекта. Успех начинается еще до картирования – высококачественные, хорошо структурированные исходные данные повышают точность картирования и сокращают ручное вмешательство.
Решения Bright Data занимаются сбором и структурированием данных, поэтому вы можете сосредоточиться на сопоставлении веб-данных с вашими конкретными бизнес-потребностями и аналитическими схемами.
Готовы оценить влияние чистых веб-данных на ваши картографические проекты? Свяжитесь с нами, чтобы быстро получить структурированные, готовые к картографированию наборы данных.





